基于支持向量機的多傳感器船舶火災探測技術
2021-01-05 03:03:18夏德斌李亞東
造船技術 2020年6期
夏德斌, 李亞東, 丁 彬, 辛 鵬, 楊 洋
(山東海洋工程裝備有限公司, 山東 青島 266555)
0 引 言
船舶通常具有結構緊湊、設備密集、通道狹窄的特點,加之船舶內部潛在火災發生源較多,易發生火災事故,而船舶火災又具有擴展快、撲滅難度較大、人員逃生困難等特點[1],易造成嚴重的后果。火災報警系統作為發現火災的眼睛,其可靠性與準確性直接影響著火災防控效果。目前,船舶火災探測通常采用傳感器的方式。
船舶上常用的火災探測器有感煙型、感溫型、感光型及氣體探測型等[2],為克服單一型式探測器的不足,提高火災早期探測準確率,通常根據艙室特點,常采用多傳感器組合的方式進行探測。這種多傳感器組合探測方式可以避免單一傳感器對不同火災類型探測的盲區,提高火災探測的可靠性。但目前船舶多傳感器組合的控制邏輯通常采用1oo2、2oo3等簡單控制方式,沒有有效融合各傳感器的參量信息,存在報警系統智能化程度低和火災自動報警系統誤報、漏報問題較多等主要問題[3]。
目前,正在進行雙船拆解系統(Twin Marine Lifter, TML)的研究,為提高TML系統在海上油田設施拆除作業過程中的安全性,需要一套高效可靠的火災報警系統。因此,結合現有火災探測系統的特點,提出一種基于支持向量機(Support Vector Machine, SVM)的多傳感器火災探測技術,通過對多傳感器探測信息的有效融合,形成多傳感器火災探測方案,從而減少由單火災探測器所導致的漏報、誤報等情況的發生,提高火災報警系統的可靠性與及時性,并將此方案在TML火災報警系統中加以應用。
1 SVM算法介紹
支持向量機是一種有監督的分類模型,其通過對輸入數據進行學習,構建出最優分類函數,從而實現智能分類。給定訓練樣本集D=(x1,y1),(x2,y2),…,(xm,ym),其中yi∈{-1,+1}]。SVM的基本思想就是基于訓練集D在樣本空間中找到一個劃分超平面,將不同類別的樣本分開[4],且使得樣本到劃分超平面之間的間隔最大。圖1是SVM的基本形式。然而,通常輸入樣本并不是線性可分的,此時可通過將低維的原始樣本空間向更高維度映射,實現樣本在更高維度空間內線性可分,即引入核函數k(xi,yi)=Φ(xi)TΦ(xj) 來代替xi與xj在特征空間的內積。
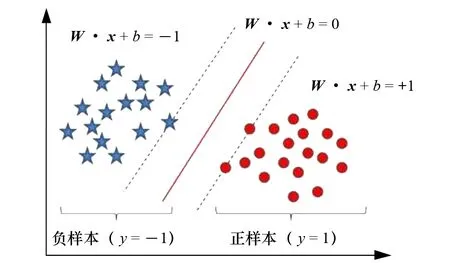
圖1 SVM基本形式
此時,SVM的求解問題變為

(1)
式中:Φ(xi)為將xi映射到更高維度的特征向量;w=(w1,w2,…,wd)為劃分超平面的法向量,決定了劃分超平面的方向;b為劃分超平面與原點之間的距離。
對式(1)使用拉格朗日乘數法可求得其對偶問題,并引入懲罰因子C以防止過擬合產生,于是求解問題變為

(2)
求解后可得分類函數為
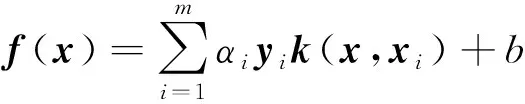
(3)
2 基于SVM算法的火災識別
火災初期發生的陰燃階段,產生大量的煙和少量的熱,很少或沒有火焰輻射,而在明火階段,可產生大量的熱、煙和火焰[5]。因此,可以綜合考慮多個火災特征來識別火災,通過CO、CO2氣體濃度和環境溫度的變化區分陰燃火和明火。
基于SVM的多傳感器火災探測系統模型如圖2 所示。通過多傳感器探測環境變量,將采集到的數據經過預處理輸入SVM模塊,由SVM模塊判斷是否有火災發生并輸出到火災報警系統。

圖2 SVM多傳感器火災探測模型
2.1 數據預處理
傳感器所測不同參量的數值具有較大的差異性,如溫度數值與CO氣體濃度數值相比并不在一個數量級上,若是不經處理直接輸入SVM,會使溫度信息在判斷中占絕對主導地位,導致模型無法有效融合多信息參量,因此,有必要對輸入數據進行預處理。
如若選用CO濃度、煙霧濃度和環境溫度作為火災探測的依據,考慮CO濃度和煙霧濃度的取值范圍都在[0,1],只需將溫度范圍也歸一至[0,1],采取的轉換函數為y=(x-min)/(max-min)。
經過歸一化處理后的訓練數據如表1所示(選取前10組數據)。
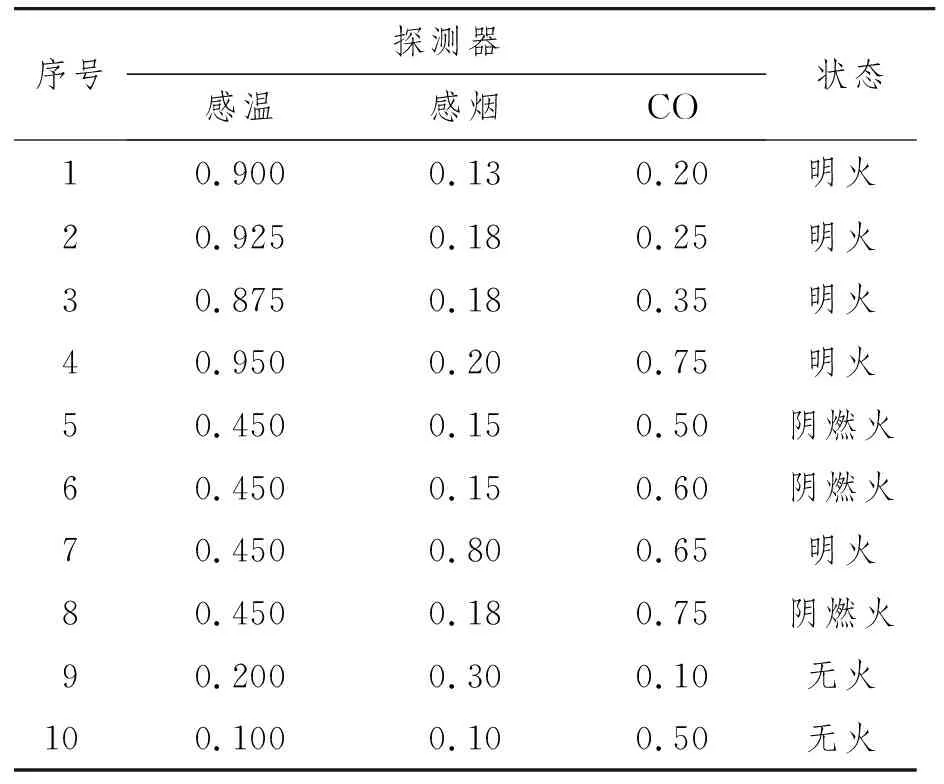
表1 歸一化后的火災樣本數據
2.2 SVM分類模塊
考慮到二維圖像顯示更為直觀,選用感溫探測器和感煙探測器2個數據進行程序編寫與驗證。程序編寫采用Python語言,調用Scikit-learn模塊,由于多傳感器火災預測并無先驗信息,因此核函數選用高斯核函數,同時將懲罰因子C設為10,將數據樣本中的70%作為訓練數據對程序進行訓練以獲得合適的α和b值,同時將數據樣本中的30%作為測試數據進行程序驗證,以測試程序的分類效果,如圖3所示。
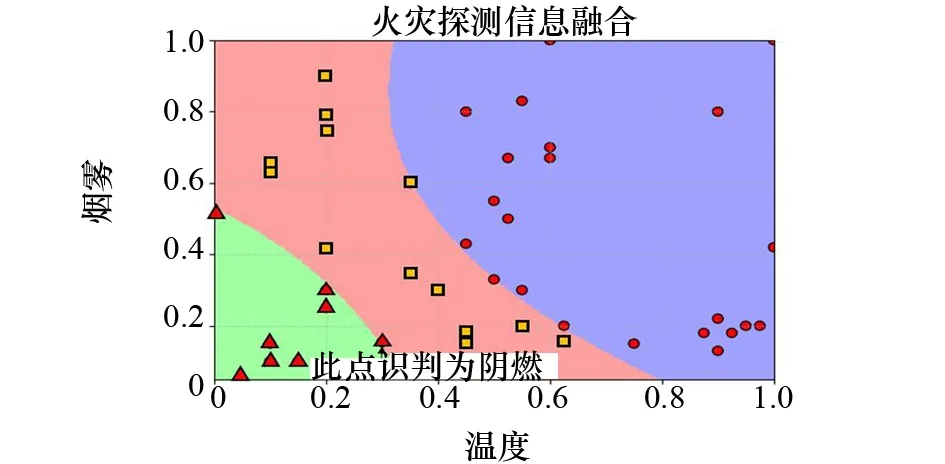
圖3 基于感溫和感煙探測器的判斷結果
節選程序如下:
file_path=‘fire_train_data.xlsx’
data=pd.read_excel(io=file_path)
fire.x=data.iloc[:,0:2]
fire.y=pd.Categorical(data[‘fire’]).codes
fire.x_train, fire.x_test, fire.y_train, fire.y_test = train_test_split(fire.x, fire.y, random_state=2, test_size=0.28)
svm_clf = svm.SVC(C=10, gamma=1, kernel=‘rbf’, decision_function_shape=‘ovo’)
decision = svm_clf
decision.fit(fire.x_train,fire.y_train.ravel())
圖3中,三角形點表示無火災發生,正方形點表示發生陰燃火,圓形點表示發生明火。由圖3可以看出:除將一例無火災發生狀態誤判為陰燃火狀態外,其余狀態均落在相應區域內,準確率較高。造成這一例判斷錯誤的原因有樣本采集誤差、火災邊界并不絕對等。為了進一步提高火災探測的可靠性,可以適當增加CO探測器,通過3個參量可以有效降低樣本誤差帶來的干擾,基于3個參量的SVM火災探測只需在程序中增加CO探測數據即可,節選程序如下:
file_path=‘fire_train_data.xlsx’
data=pd.read_excel(io=file_path)
fire.x=data.iloc[:,0:3]
fire.y=data.iloc[0:,3:4]
fire.y=pd.Categorical(data[‘fire’]).codes
fire.x_train, fire.x_test, fire.y_train, fire.y_test = train_test_split(fire.x, fire.y, random_state=2, test_size=0.28)
svm_clf = svm.SVC(C=10, gamma=1, kernel=‘rbf’, decision_function_shape=‘ovo’)
decision = svm_clf
decision.fit(fire.x_train,fire.y_train.ravel())
仿真結果如圖4所示。
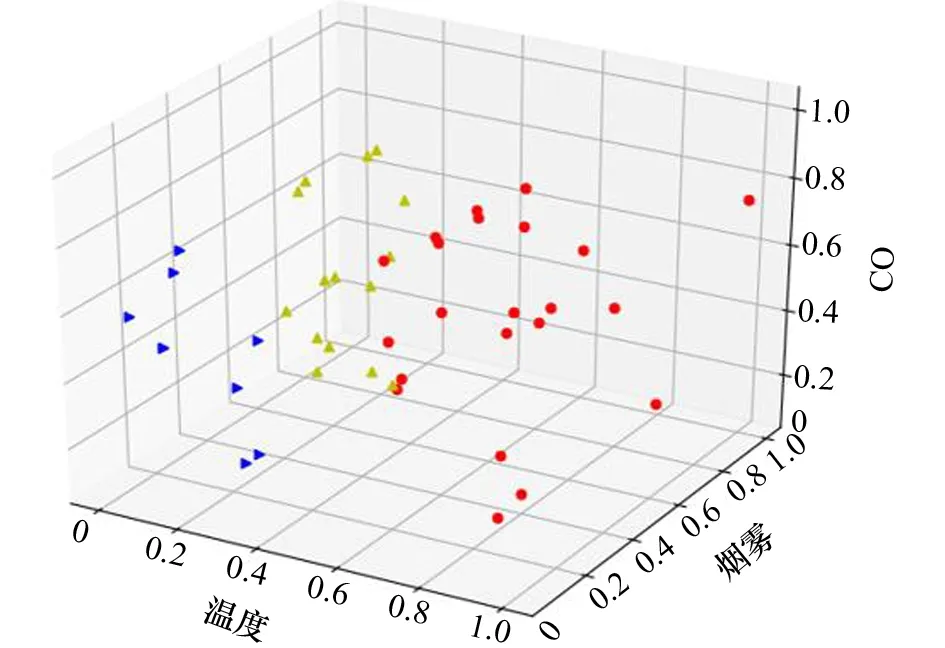
圖4 基于感溫、感煙和CO探測器的判斷結果
圖4中,橫三角表示無火災發生狀態,上三角表示發生陰燃火狀態,圓點表示發生明火。與實際結果對比,分類準確率為100%。可見,采用完善后的SVM多傳感器火災探測方法可以大幅提高火災探測的準確性。
3 結 論
火災發生時的環境多變,火災發生狀態也存在較多差異性,難以用一般的數學模型來描述,這給火災探測帶來了一定難度。通過分析SVM分類特點,將多傳感器信息輸入SVM模塊進行判斷,利用SVM間隔最大和具有自學習等特性,可以大幅提高系統的準確率。將SVM多傳感器火災探測技術運用到船舶火災探測中,特別是作業工況復雜的海上油田設施拆解平臺上,對船舶火災的防治具有積極意義。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
工業設計(2022年8期)2022-09-09 07:43:20
船舶(2021年4期)2021-09-07 17:32:22
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
