支持向量機在物品智能推薦中的應(yīng)用
2020-12-28 01:46:38張澤瑞陳杰宋楚平
現(xiàn)代計算機 2020年31期
張澤瑞,陳杰,宋楚平
(南京科技職業(yè)學(xué)院信息工程學(xué)院,南京 210048)
0 引言
校園網(wǎng)二手商品的交換和買賣旨在發(fā)揮舊物的剩余價值,以商品流通來促進學(xué)生間情感交流、文化交流和社團活動,對培養(yǎng)學(xué)生的環(huán)保理念、商業(yè)意識和溝通能力都有很大的裨益。這其中,將物品推薦給學(xué)生的準確率高低直接影響用戶的體驗,對微校園App 的推廣起著決定性的作用。物品推薦和效果評價一直是一個比較復(fù)雜的問題,由于校園物品的多種類、多屬性和難描述的特點,另受學(xué)生個性、喜好和周圍環(huán)境的影響,目前還沒有完善的技術(shù)手段對學(xué)生的物品搜索進行準確的智能推薦,導(dǎo)致系統(tǒng)的搜索結(jié)果往往與學(xué)生的需求相差甚遠,影響了系統(tǒng)的口碑和市場競爭力。
隨著數(shù)據(jù)挖掘和人工智能技術(shù)的發(fā)展,多種推薦算法如協(xié)同推薦、關(guān)聯(lián)規(guī)則、分類聚類和神經(jīng)網(wǎng)絡(luò)等在物品推薦方面得到應(yīng)用,相關(guān)的深入研究也隨之展開,如利用關(guān)聯(lián)規(guī)則算法計算與推薦預(yù)測評分最高商品具有關(guān)聯(lián)關(guān)系的關(guān)鍵節(jié)點,以此關(guān)鍵節(jié)點作為多樣性商品推薦依據(jù)的推薦方法[1];將圖像匹配應(yīng)用到圖像推薦模型中,與傳統(tǒng)推薦模型結(jié)合以提高推薦結(jié)果準確度的LSH 算法[2];一種融合知識圖譜與用戶評論的根據(jù)商品推薦價值進行Top-k 推薦商品的推薦算法[3];通過數(shù)據(jù)預(yù)處理建立分散類,得到目標用戶所在區(qū)域,計算相似度來實現(xiàn)商品個性化推薦的方法[4];以及優(yōu)化讀者評價矩陣和相似度模型的協(xié)同過濾改進算法等[5]。考慮到校園二手物品數(shù)量規(guī)模不大、門類不多、物品特征容易定義的實際情況和兼顧推薦的計算效率,決定采用基于統(tǒng)計學(xué)習(xí)理論發(fā)展起來的支持向量機(Support Vector Machine,SVM)來解決物品推薦的不穩(wěn)定問題。盡管在小樣本分類方面,SVM 已被證明是一種非常有效的方法,具有良好的泛化能力和全局最優(yōu)解[6],但該方法的模型參數(shù)仍沒有具體理論來指導(dǎo)選擇,需要根據(jù)實際應(yīng)用做進一步優(yōu)化處理。
1 支持向量機推薦模型的構(gòu)建
SVM 的基本思想是通過非線性映射(稱為決策函數(shù)),把樣本空間映射到一個高維的特征空間,將原本空間線性不可分的問題,轉(zhuǎn)化成在高維空間通過一個線性超平面將樣本完全劃分開,從而得到分類的最優(yōu)解。決策函數(shù)由位于超平面附件的幾個支持向量決定,因此該方法不僅算法簡單,而且具有較好的魯棒性,特別適合解決樣本數(shù)據(jù)較少、先驗干預(yù)少的非線性分類問題,物品推薦模型符合上述問題特征,可采用SVM 來實現(xiàn)微校園App 中二手物品的智能推薦。
物品的學(xué)習(xí)樣本集表示為{x1,x2,…,xi,yi}(xi∈Rn為輸入變量,yi∈N+為對應(yīng)輸出值),SVM 模型通過核函數(shù)φ(x)將輸入空間向量x→映射到高維空間以構(gòu)建一個線性分類函數(shù)f(x),來實現(xiàn)物品的分類。

式中w 為權(quán)值矢量,b 為閾值。問題的求解關(guān)鍵是找最小w,可將找最小w 表示成凸優(yōu)化問題,即:

為提高模型的魯棒性,引入懲罰因子C>0。利用Lagrange 乘子向量、對偶原理及核函數(shù)方法,將SVM 的約束問題最終轉(zhuǎn)化得到如下回歸函數(shù):
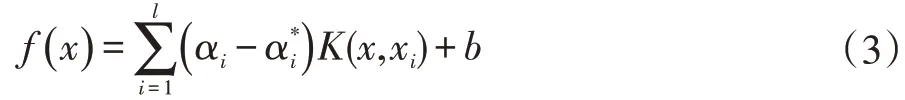
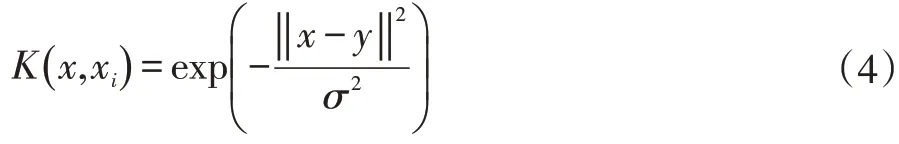
式中σ為徑向基核帶寬的調(diào)節(jié)參數(shù),結(jié)合(3)式得到以下的支持向量機物品推薦模型。
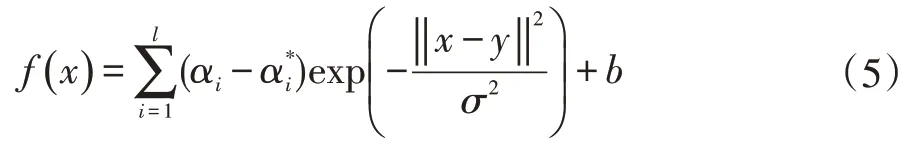
由式(5)可以看出,SVM 模型的性能和泛化能力主要取決于參數(shù)C和σ,常采用試驗法或網(wǎng)格搜索法來確定合適的參數(shù),但這些方法效率低且容易陷入局部解,最終導(dǎo)致模型精度不高和穩(wěn)定性不夠。為此本研究考慮到遺傳算法(GA)的全局搜索能力和全局最優(yōu)解的特點,決定采用遺傳算法在一定范圍尋找參數(shù)C和σ,來保證模型的有效性和準確性。
2 推薦模型的參數(shù)優(yōu)化
推薦模型的參數(shù)優(yōu)化問題是結(jié)合校園網(wǎng)的應(yīng)用實際情況,以及物品的特征屬性和師生的查詢方式,通過合理設(shè)計遺傳算法的編碼方式、適應(yīng)度函數(shù)和遺傳算子,尋找支持向量機的最優(yōu)參數(shù),主要工作有:
(1)實數(shù)編碼。由于SVM 的調(diào)參染色體基因X 的編碼形式可表示為 {Ci|σi},其中Ci、σi∈R+。任何一組參數(shù)(Ci、σi)一個染色體,Ci、σi為染色體上的 2 個基因,取值為實數(shù),因此此處采用實數(shù)編碼,符合參數(shù)大空間搜索過程,克服了二進制碼搜索效率低、精度不高的缺點。
(2)適應(yīng)度函數(shù)。遺傳算法在進化搜索中是利用適應(yīng)度值選擇個體的,適應(yīng)度值大的個體將有更多的機會繁衍下一代,使優(yōu)良特性得以遺傳。適應(yīng)度函數(shù)是算法演化過程的驅(qū)動力,其好壞直接影響后續(xù)的遺傳算子操作,此處采用SVM 的均方根誤差的倒數(shù)作為適應(yīng)度函數(shù),即:

式中ti為樣本的真實值,yi為樣本的預(yù)測值,l 為樣本個數(shù)。為避免樣本各特征數(shù)據(jù)量差太大而影響模型精度,同時有利于提高模型訓(xùn)練速度,此處采用歸一化對所有樣本數(shù)據(jù)進行了處理。
(3)選擇算子。用輪盤賭方式按個體的選擇概率大小選擇出第一代樣本。利用6 式計算各個體的適應(yīng)度值,然后利用7 式計算個體被選中的概率pi。顯然那些誤差值小的個體被選中的可能性大,選中的個體染色體的遺傳性正比于其選擇概率pi,這樣樣本中的個體均有較高的適應(yīng)度和生存優(yōu)勢。
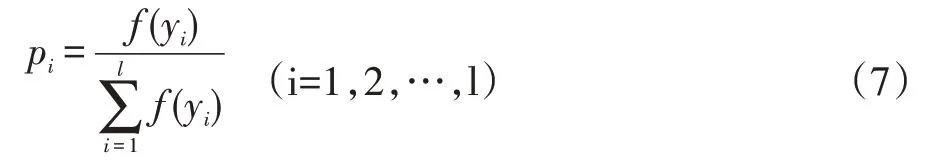
(4)交叉算子。染色體 (Ci、σi)采用實數(shù)編碼,用線性組合方式進行個體交叉操作。設(shè)兩個體對應(yīng)染色體 Xi和 Xj進 行 交 叉 操 作 ,則Xi=μXi+(1-μ)Xj,Xj=μXj+(1-μ)Xi。交叉系數(shù)μ在每次交叉時隨機取值,一般取缺省值μ=0.75。
(5)變異算子。幾種常用的變異算子主要有基本位變異、均勻變異和高斯變異等,因為(Ci、σi)是在一定范圍內(nèi)選擇的,這與均勻變異在某一范圍內(nèi)均勻產(chǎn)生隨機數(shù)相吻合,因此采用均勻變異以某一較小概率替換個體編碼中各個基因座上原有的基因值。如隨機選擇待變異染色體X 中變異位j,將它置成以概率β(一般取β=0.01)均勻出現(xiàn)的隨機數(shù)Uj,Uj的取值范圍為[mini,maxi]。
參數(shù)C、σ尋優(yōu)的具體步驟如下。
Stepl:算法參數(shù)初始化。染色體按實數(shù)編碼,隨機產(chǎn)生種群數(shù)50,最大遺傳迭代次數(shù)200,收斂系數(shù)T=0.5,指定C、σ的搜素范圍。
Step2:對種群中的每個染色體,利用6 式計算它的適應(yīng)值fi。
Step3:如果Pk<=T,或者到達最大迭代次數(shù),則搜索停止并輸出當代中最大適應(yīng)度的個體;否則以概率pi從種群中隨機選擇一些染色體構(gòu)成新的種群。
Step4:利用交叉、變異算子對當代進行處理,以產(chǎn)生新的染色體種群;返回步驟2,直至迭代終止。
將輸出最優(yōu)解參數(shù)C、σ來訓(xùn)練SVM 模型,然后利用訓(xùn)練好的模型進行物品推薦。
3 推薦模型的訓(xùn)練與應(yīng)用
3.1 模型的訓(xùn)練
樣本數(shù)據(jù)來自如圖1 所示的微校園App 后臺數(shù)據(jù),樣本的特征為{價格,新舊度,顏色,大類,推薦系數(shù)},其中,新舊度取值(0,1),值越大表示物品越新。顏色也取值(0,1),值越大表示該顏色越受用戶歡迎,根據(jù)物品銷售情況動態(tài)調(diào)整某一顏色的值。大類取值[1-15],分別表示書、筆記本、臺式機、手機、iPad 和自行車等物品。推薦系數(shù)是人工標注的模型輸出值,其整數(shù)部分為物品大類標號,小數(shù)部分表示匹配度,該值越大表示被推薦的機會越大。
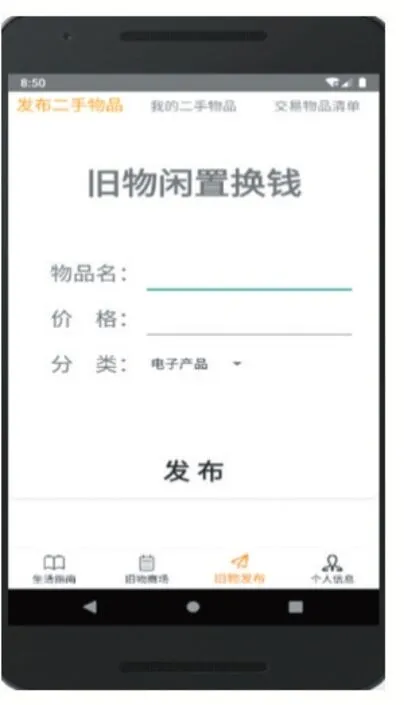
圖1 微校園App
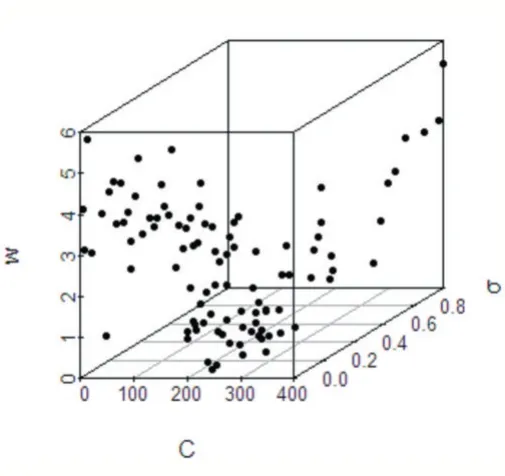
圖2 訓(xùn)練絕對誤差分布圖
樣本數(shù)據(jù)準備好后,然后利用MATLAB 2012b 的遺傳算法工具來尋求最優(yōu)解參數(shù)(C,σ),初始化參數(shù)見表1。

表1 CA 主要參數(shù)
而SVM 的訓(xùn)練采用林智仁教授開發(fā)的LIBSVM軟件包來完成,由于物品的推薦系數(shù)與物品大類、顏色、新舊度及價格有關(guān),將這四個指標作為SVM 模型的輸入,推薦系數(shù)作為模型輸出。圖2 是參數(shù)(C,σ)在搜索范圍內(nèi)訓(xùn)練模型時推薦系數(shù)的誤差值w(w=|ytyp|,yt為實際值,yp為預(yù)測值)。
由圖2 可以看出,參數(shù)對(C,σ)的最優(yōu)組合在(240,0.05)附近。經(jīng)過迭代訓(xùn)練后,得到SVM 模型的最優(yōu)參數(shù)為C=231.58,σ=0.047。
3.2 模型的應(yīng)用效果
為進一步檢驗?zāi)P偷膽?yīng)用效果,隨機選取曾經(jīng)瀏覽過微校園App 的100 名學(xué)生為推薦對象,其中男生59 名,女生41 名。讓他們按物品的大類、價格、顏色和新舊度搜索自己心儀的物品,看模型據(jù)此推薦的物品是否得到學(xué)生的認可和滿意。此場景的推薦結(jié)果性能評價有別于有樣本標簽的分類評價,因為無法事先通過標簽來標注某一物品是否被學(xué)生認可,只有經(jīng)過統(tǒng)計學(xué)生的真實體驗和感受才能計算出模型的準確率和滿意度,準確率P 和滿意度R 的計算公式如下:

其中g(shù)j是被學(xué)生接受的第j 個推薦物品,N 是推薦物品總數(shù),fi是學(xué)生對第i 個推薦物品的滿意度(用滿意、基本滿意和不滿意來表示),分別取值為(1|0.5|0),取前3 個最大推薦系數(shù)的物品給學(xué)生,現(xiàn)場統(tǒng)計并計算P 值和R 值,計算結(jié)果如表2 所示。
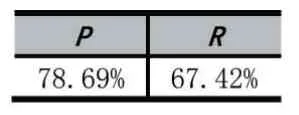
表2 準確率和滿意度統(tǒng)計結(jié)果
由表2 可以看出,學(xué)生認可了約79%的物品,滿意率為67%,說明系統(tǒng)推薦取得了較好的效果,這主要得益于學(xué)生事先通過App 對可能推薦的物品進行了特質(zhì)指向,有利用模型直接利用這些特征來計算物品的推薦系數(shù),從而保證了推薦的精度和可信度。本應(yīng)用采用k=3 個最大系數(shù)來推薦,如果數(shù)據(jù)庫中物品種類和數(shù)量不足夠大,有可能這k 個近鄰的物品相似度并不高,就會降低模型的推薦效果。
4 結(jié)語
本文在SVM 的基礎(chǔ)上,針對普通App 不能主動推薦搜索結(jié)果的缺點,將遺傳算法的全局參數(shù)尋優(yōu)與SVM 的小樣本最優(yōu)解相結(jié)合,解決了微校園App 中二手物品的推薦困難和不準確性問題。初步的應(yīng)用結(jié)果顯示,本推薦模型無論是在準確率還是滿意度方面都得到用戶的認可。但本模型沒有考慮物品的點擊率和用戶特征,后續(xù)的研究將一并考慮這些因素對模型進行優(yōu)化,來進一步提高模型的適應(yīng)性和推薦滿意度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學(xué)版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
