基于FPGA 的LDPC 編譯碼的高速并行化設計與實現*
2020-12-23 06:12:34吳文俊程敏敏
通信技術 2020年10期
關鍵詞:信息
吳文俊,張 銳,程敏敏
(中國電科第五十研究所,上海 200331)
0 引言
低密度單奇偶校驗碼(Low-Density Parity-Check,LDPC)具有接近香農限的性能[1-4],碼率具有很大的靈活性,能夠在不進行打孔的條件下得到合適的碼率,以降低系統性能的損失。LDPC 譯碼速度快,適用于高吞吐量和低時延系統,但是對硬件資源需求開銷較大。此外,全并行化的譯碼結構對計算單元和存儲單元的需求都很大。根據硬件資源量,可以選擇不同的并行實現層次,以滿足高速率需求,實現資源和速率上的平衡。本文采用可配置的并行化LDPC 譯碼實現結構,根據不同的芯片和速率需求對其進行應用。
1 LDPC 編譯碼器實現結構
1.1 LDPC 碼基礎知識
LDPC 碼定義為具有如下結構特性的奇偶校驗矩陣H的零空間:
(1)每一行含有ρ個1;
(2)每一列含有γ個1;
(3)任何兩列之間位置相同的1 的個數不大于1;
(4)與碼長和H的行數相比,ρ和γ都較小。
對于一個(n,k)的LDPC 碼,編碼長度為n,信息數為k,校驗為r=n-k個比特,以使得碼字滿足H×CT=0,H為一個(n-k)×n的校驗矩陣。每個校驗矩陣可以分為大小為b×b的循環子矩陣,這種子矩陣為單位矩陣的循環矩陣或者零矩陣。
8×8 的單位循環矩陣實例為:


1.2 準循環QC_LDPC 碼
確定性結構的LDPC 碼也稱為準循環碼(Quasi-Cyslic Low-Density Parity-Check,QC-LDPC)。相對于隨機結構的矩陣,人們很容易獲得確定性結構矩陣,使得矩陣可以通過更少的參數來定義LDPC碼[5]。QC-LDPC 碼是一種特殊結構化的LDPC 碼,校驗矩陣Hqc形式如下:
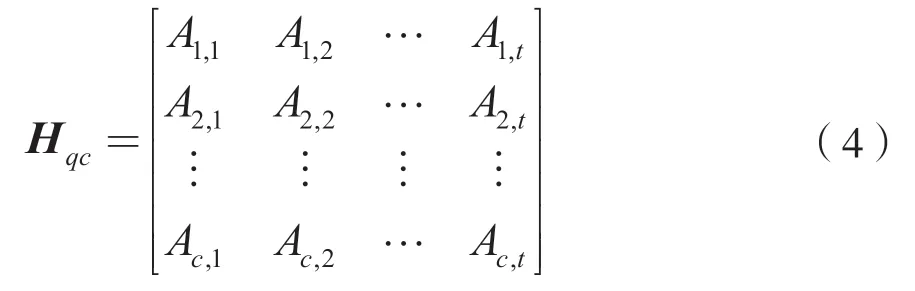
校驗矩陣由大小相同的循環子矩陣構成。循環矩陣是一個方陣,且每行都是前一行的循環右移動,每列都是前一列的循環下移。它的行重和列重都相同。這種循環矩陣的信息便于實現后續的編譯碼。
1.3 LDPC 編碼器設計及實現
1.3.1 編碼器基本結構
本文中LDPC 支持的編碼速率、信息塊長度以及編碼塊長度如表1 所示。
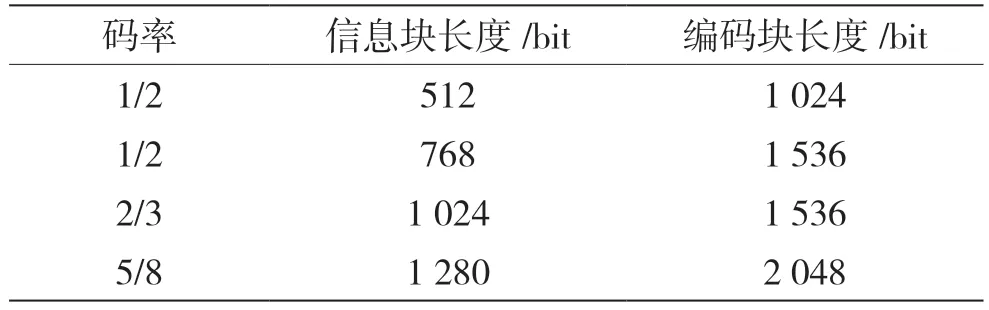
表1 LDPC 編碼參數
通信系統的編碼器對實時性要求較高,本文根據QC_LDPC 準循環矩陣采用全并行化的處理實現方式,信息段按照8 bit 位寬進入編碼器,碼字長度按照8 位劃分即為輸入的信息長度,編碼后的碼字也按照8 bit 位寬送出。
編碼預處理可以通過軟件將生成矩陣提前寫入FPGA 的緩存區,根據不同的編碼速率調用不同的生成矩陣。由于是準循環矩陣,根據處理流程的規格化方式相同,可將可以同時計算的內容進行并行化處理。圖2 為實現的編碼器結構。

圖2 FPGA 實現編碼器結構
根據準循環矩陣的特性,基于不同碼率的需求,LDPC 編碼的碼長較長,如果存儲整個生成矩陣會造成巨大的資源開銷,也會增大處理延時。因此,編碼器根據生成矩陣需進行并行化處理。按照64路并行化處理方式,只存儲非零元素的位置信息,存儲信息量小于原矩陣的1/64,極大地降低了存儲資源消耗。本文中針對(1 536,1 024)2/3 碼率、(1 024,512)1/2 碼率和(2 048,1 280)5/8 碼率3 種不同碼率進行實現。
圖3 為實現時調用的生成矩陣,編碼塊(2 048,1 280)。
圖3 存儲簡化的編碼矩陣塊
編碼器的實現流程描述如下。
(1)將需要編碼的信息按照每段8 bit 位寬進行劃分即u=(u0,u1,…,uk/b-1),其中ui=(u(i-1)b+1,u(i-1)b+2,…,uib)。編碼后的碼字為v=(u,p1,p2,…,pr),r=n-k為校驗位,其中pj=(pj,1,pj,2,…,pj,b)。
(2)預先通過軟件將矩陣寫入緩沖區,待編碼使用。由于QC-LDPC 的循環特性,只需存儲原矩陣信息的1/64,大大降低了對資源的占用。
(3)根據輸入比特位寬,通過移位寄存器實現校驗位的輸出,編碼電路如圖4 所示。
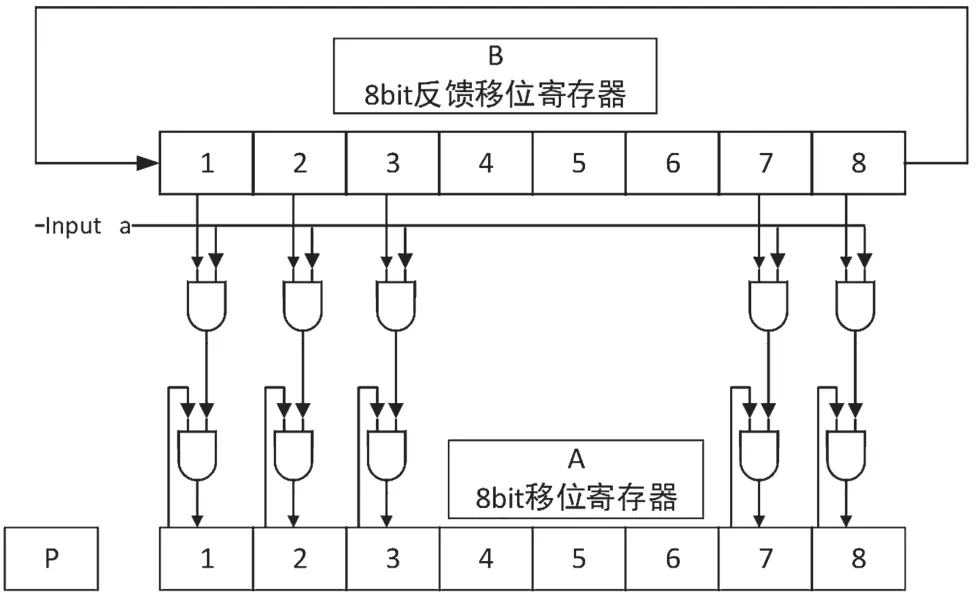
圖4 編碼電路
對編碼速率(2 048,1 280)進行詳細分析。編碼塊矩陣為2 048×1 280,根據描述的矩陣存儲規則,存儲矩陣大小為20×12(行數=n/64,列數=r/64),輸入信號位寬為8 bit。圖4 中B 是一個反饋移位寄存器,A 是普通寄存器。開始編碼時,通過讀取ROM 中的預存矩陣因子,B 載入第一個8 bit 的生成因子,A 開始依次輸入第一個8 bit 信息段。根據預先存儲好的對應信息段,每個比特的生成因子循環移位,同時進行8 bit 信息的編碼操作,矩陣以64 長度為循環劃分,每載入8 個8 bit 數據,加載下一個矩陣因子。12 行操作同時并行進行,完成20 次列操作,最終生成對應信息的編碼數據。該編碼實現結構簡單速度快、效率高且可復用性強。
1.3.2 編碼器的FPGA 仿真
為提高編碼效率,按照數據位寬8 bit 進行64路并行化處理。編碼器資源情況如圖5 所示,編碼時序圖和仿真結果如圖6 和圖7 所示。根據不同的碼率,只需根據參數調用不同的生成矩陣,即可快速完成編碼,適用于實時性要求較高的通信系統。
從圖5 編碼器資源使用情況可以看出,該編碼器的資源占用率較低,所以具有很強的適用性。根據編碼實現流程進行數據仿真分析,圖6 是編碼處理過程中的矩陣載入情況,按照每64 位循環載入,輸入數據從0~159 共8×160=1 280 bit 編碼,wea_done_out_o 是編碼輸出使能信號,地址從160開始到255 都是編碼校驗位的輸出。可以看出,待編碼數據輸入完畢后,8 個clk 開始輸出校驗結果。由于是線性分組碼,前面輸出數據個數和輸入編碼數據一致,后面輸出增加校驗位r(r=n-k)。本文所實現的編碼方案針對不同速率速度快且效率高。
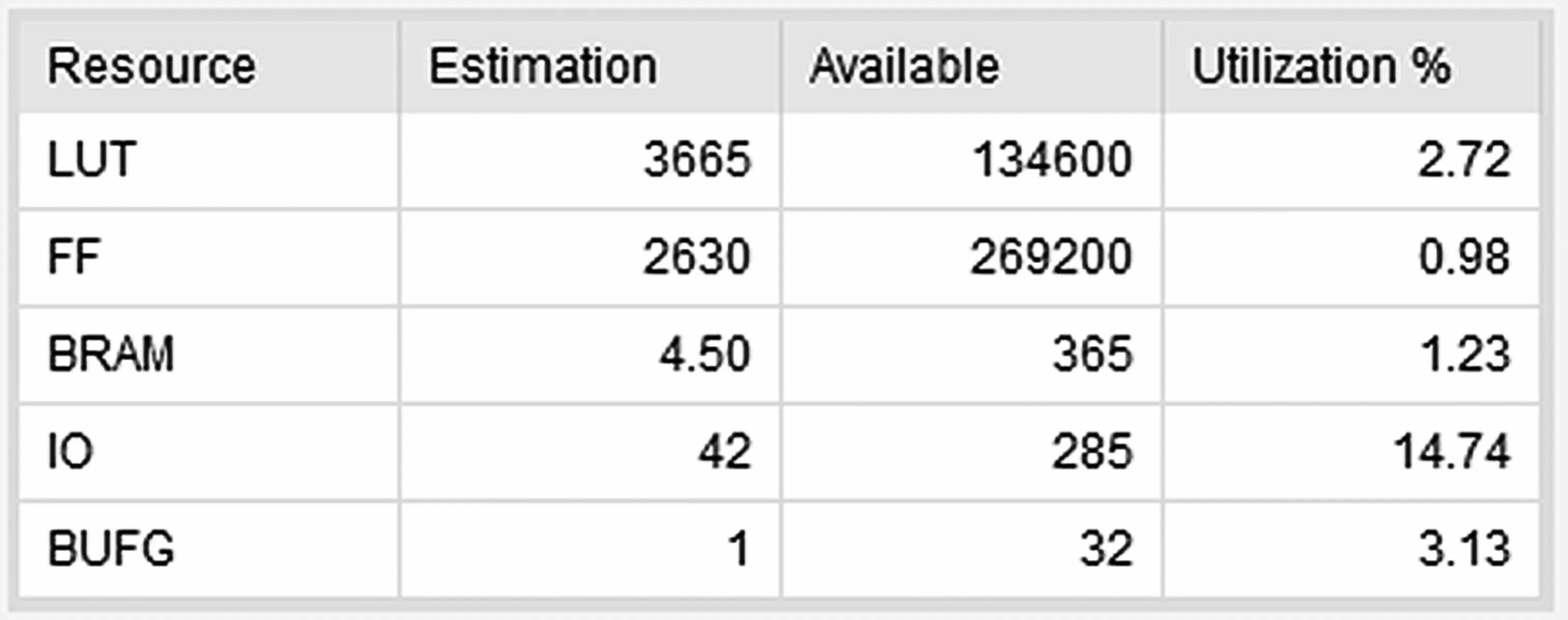
圖5 編碼器資源情況

圖6 矩陣載入

圖7 編碼仿真實例
1.4 LDPC 譯碼算法及譯碼器結構
譯碼器算法采用最小和積算法MSPA(Min-Sum Product Algorithm),通過分層的并行化來實現譯碼功能[6]。具體算法步驟如下。
(1)初始化信息。根據校驗矩陣H中1 的位置信息(i,j),初始化對應變量qi,j為輸入的待譯碼信息源。
(2)校驗節點計算。本文中采用分層修正的最小和譯碼算法,所以對應的計算校驗信息ri,j為:
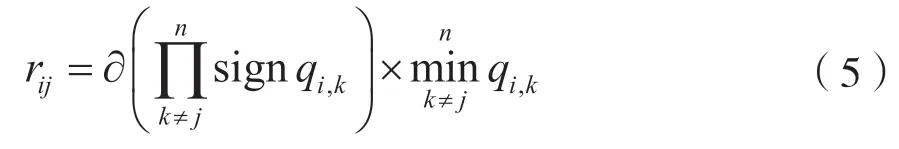
其中?參數用來減小迭代過程中的擺幅,且在每次完成校驗節點計算后更新似然比,然后參與下一次校驗計算。
(3)比特節點計算。對于校驗矩陣H中的每一列中的非零項,計算變量信息qi,j:

(4)迭代譯碼。對于校驗矩陣H中的每一列,任取一個非零元素(i,j),則第j個比特的對數似然比為llrj=qi,j+ri,j。根據似然比得到碼字的硬判結果,如果,則通過校驗或者達到最大迭代次數,譯碼結束;否則,繼續進行校驗節點計算。
1.4.1 譯碼器基本結構
首先解調后的數據通過硬判和軟判結果送入譯碼模塊,譯碼模塊根據需求選擇待譯碼數據源,然后進入分層修正最小和計算模塊開始進行最大迭代次數的迭代計算。譯碼器結構如圖8 所示。
分層修正最小和計算的內部實現模塊如圖9 所示。核心計算模塊中存儲校驗矩陣的行重信息和每行中1 所在的位置信息。通過訪問這兩個模塊,核心計算模塊可以計算出校驗信息。R_MATRIX 中存儲的是校驗信息ri,j,APP_BUF 中存儲的是所有信息的對數似然比llrj,即為后驗概率。
核心計算模塊首先通過讀取校驗矩陣H相應行1 的位置,通過式(6)計算該行變量信息qi,j;其次,通過式(5)計算得到校驗信息ri,j;再次,計算第j個比特的對數似然比為llrj=qi,j+ri,j,更新相應的APP_BUF 中的數值。最后,當校驗矩陣遍歷一遍后,迭代次數加1,重復上述過程,直至完成譯碼或者達到最大迭代次數。

圖8 譯碼器結構
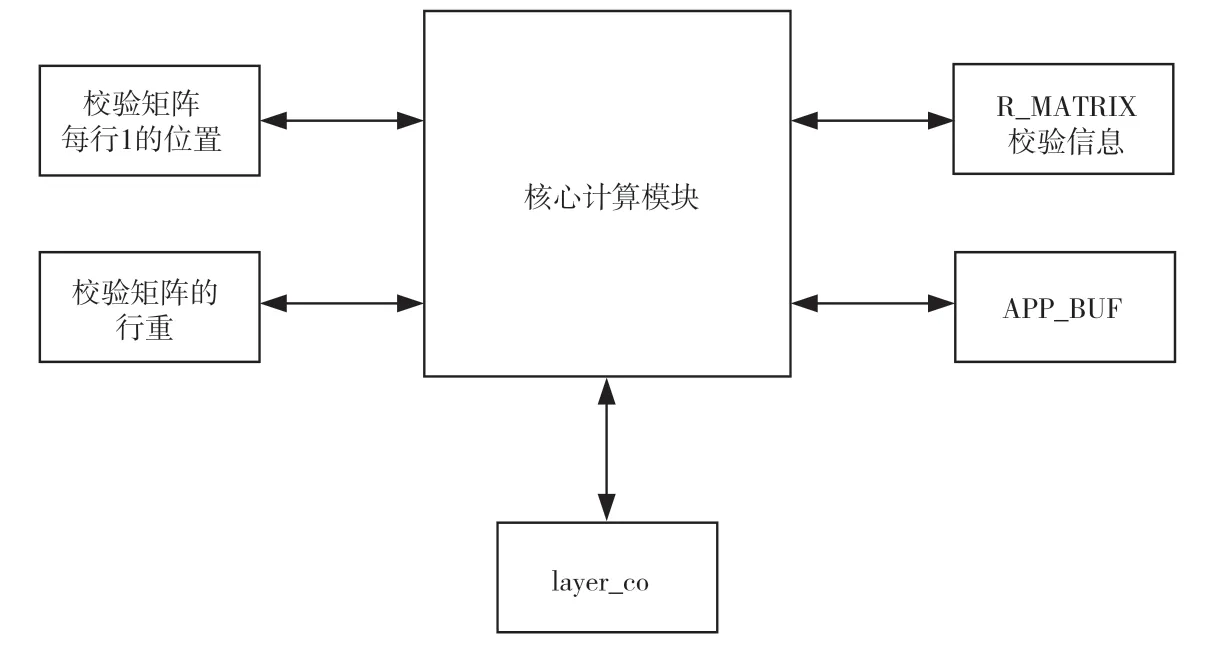
圖9 分層修正最小和計算模塊內部
1.4.2 譯碼器的擴展結構
本文基于最小和譯碼算法設計了一種可配置并行化的層次譯碼器結構,具體算法采用分層模式,但是對數據處理按照并行化方式進行,即一次迭代同時對N個待譯碼數據進行計算,以提高吞吐量。
為滿足多種速率需求,將不同速率的校驗矩陣按照64 間隔劃分,并通過外部接口寫入內部存儲,需要時從緩沖區中讀取校驗矩陣,節省資源,提高靈活度。
存儲譯碼需要H矩陣時,利用準循環矩陣的循環特性,只存儲矩陣信息的1/64 以及對應的行重,并且采取全并行化實現。李江林等人實現的并行化方案按照單位矩陣為粒度進行[7],實現靈活度較低,且根據不同的碼率還需要重新修改代碼。該方式依據準循環矩陣的特性以及其正交性,只需獲知極少的有效信息便可進行譯碼操作,極大地降低了資源存儲的消耗,根據不同的碼率調用不同的矩陣即可。經過仿真驗證對比,在處理速度上碼率的影響并不是很大,只有不同的并行化方式對處理速度影響較大。本例中依據(2 048,1 280)碼率進行分析,根據校驗矩陣H,在FPGA 中預先存儲行重以及每一行中1 的位置,如表2 所示。
本文在FPGA 實現中采用了軟判決和硬判決都可選的譯碼方式。硬判決是對信道的輸出做出是0還是1 的判決;軟判決不作出0、1 判決,只輸出有關信息,如0、1 的后驗概率。具體應用中,可根據需求可以選擇不同的譯碼判決方式進行對比。硬判決譯碼算法是通過傳遞比特信息進行解碼,如比特翻轉譯碼算法。雖然它具有譯碼算法簡單的優勢,但是達不到最佳的譯碼性能。軟信息是譯碼算法傳遞和后驗信息相關的置信度信息,通過置信傳播譯碼具有優秀的糾錯性能。
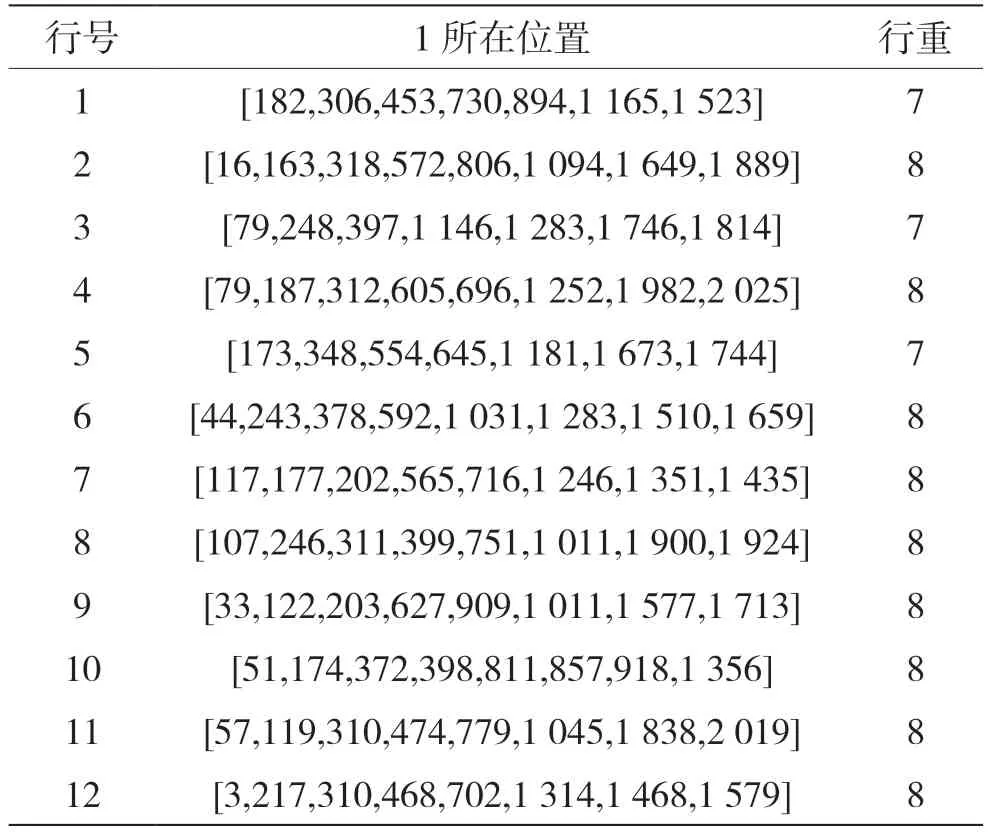
表2 校驗矩陣
1.4.3 譯碼器實現結構比較
本文中譯碼器實現采用了16 路、32 路、64 路并行的3 種并行化實現方式,通過在模塊外部配置參數,改變#defineN的值來改變并行化處理路數模式,從而實現3 種并行化可選。圖10~圖13 依次列出了16 路并行實現方式的仿真結果,包括資源使用情況、16 路矩陣、一次譯碼迭代時間以及一次譯碼成功時間。仿真條件:時鐘頻率61.44 MHz,編碼速率(2 048,1 280),譯碼數據錯誤率50%以下均可譯碼成功。
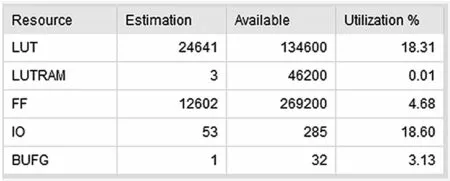
圖10 譯碼器資源使用情況
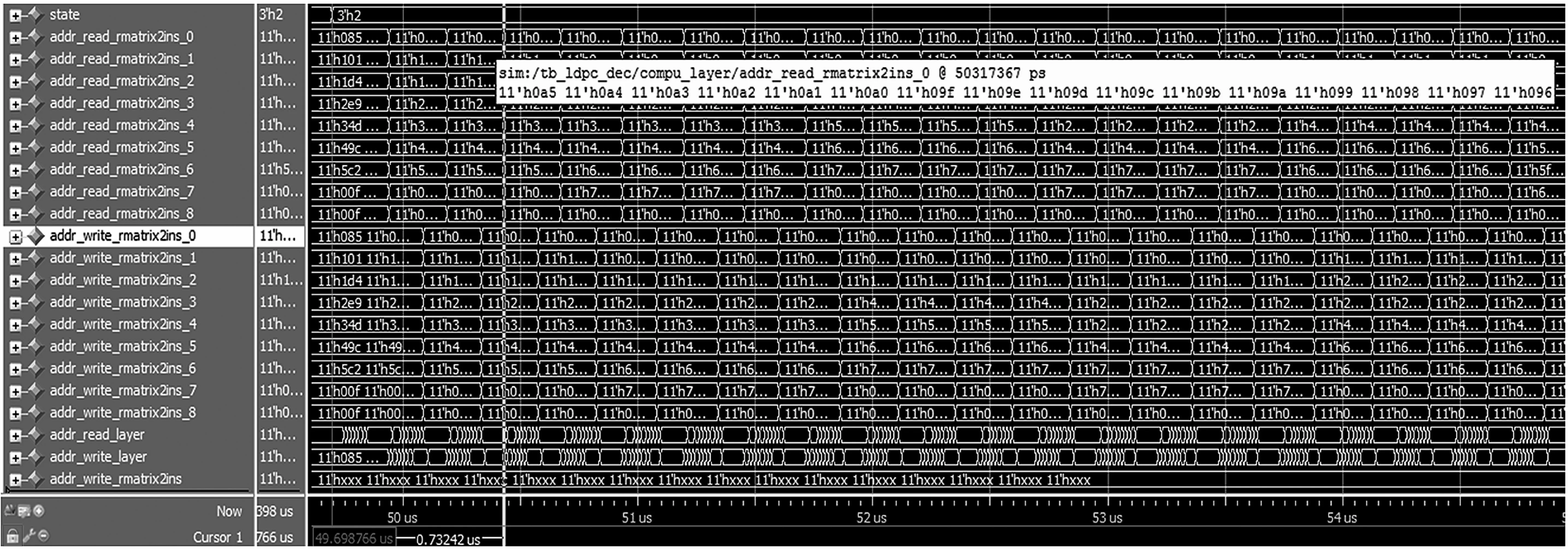
圖11 16 路矩陣
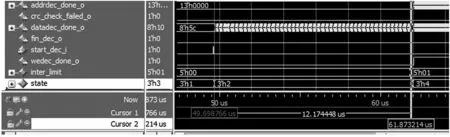
圖12 一次譯碼迭代時間(12 μs)
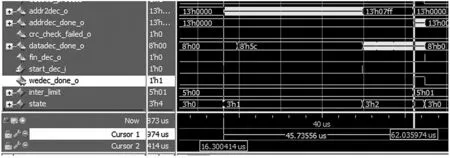
圖13 一次譯碼成功時間(45.7 μs)
同時,本文對3 種并行化實現方式的結果進行對比,如表3 和表4 所示。
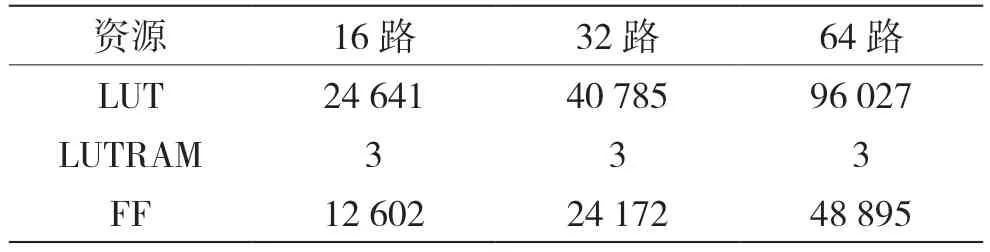
表3 資源使用情況對比

表4 譯碼時間對比
通過ModelSim 仿真對比分析可以看出,資源使用和譯碼效率成反比,需根據需求選擇不同的譯碼方式。該實現方式能夠滿足多種速率的需求,提高波形的靈活性和可靠性。實際驗證平臺中,模塊的工作時鐘是61.44 MHz,編碼方式(2 048,1 280),譯碼最大迭代次數16 次,并行方式為64路,最長譯碼時間為98 μs;同試驗平臺原糾錯方案RS 編解碼實現相比有2 dB 左右的編碼增益,意味著采用該實現方式后可以大大提高系統的抗干擾性能和糾錯性能。
2 LDPC 碼和Turbo 碼性能比較
LDPC 的譯碼算法是一種基于稀疏矩陣的并行迭代譯碼算法,運算量低于Turbo 碼的譯碼算法。由于結構并行的特點,在硬件實現上比較容易。因此,在大容量通信應用中,LDPC 碼更具有優勢。LDPC 的碼率具有很大的靈活性,而Turbo 需要打孔來提高碼率,導致選擇打孔圖案的十分謹慎,否則會造成較大的性能損失。
3 結語
本文基于xilinx-A7 平臺實現了基于LDPC 的編譯碼器的并行化可配置的設計與實現,并在ModelSim的仿真環境下對該實現進行仿真。對(1 536,1 024)、(1 024,512)、(2 048,1 280) 這3 種碼率進行編譯碼仿真聯試,主要針對0.625 碼率的(2 048,1 280)進行編譯碼分析,結果顯示編碼器占用資源開銷較小,譯碼器在高度并行化、較高吞吐量情況下占用資源較多,但是具有較高的數據吞吐量,能夠達到40 MHz,滿足不同速率的編譯碼需求和靈活的資源利用率。根據設計需求,采用不同的譯碼器并行實現結構應用于不同場景,證明本文的設計具有較高的靈活性。最后,通過試驗驗證了本文編譯碼算法實現的有效性,它在高速率傳輸中具有很好的可靠性和優越性。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
