視覺識別在自動駕駛中的應用
2020-12-15 07:00:46周奇豐
汽車實用技術 2020年22期
周奇豐
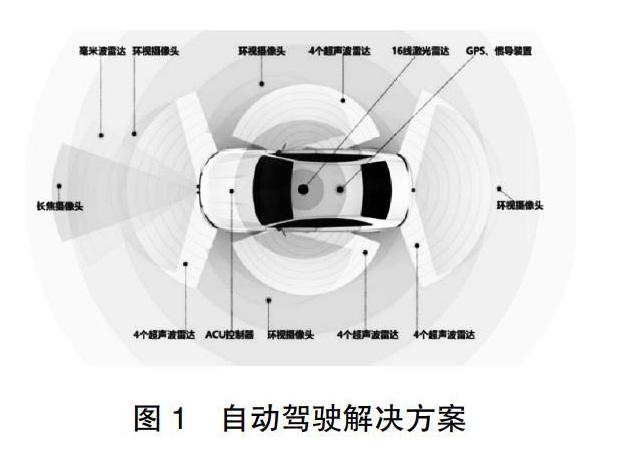


摘 要:文章從自動駕駛汽車的基本解決方案分析,講述了視覺識別在自動駕駛車輛中的重要性。從傳統模式識別框架分析汽車是如何利用攝像頭來區分障礙物。介紹了人的視覺機理和深度學習的相關理論。從過程中分析圖片數據庫的重要性。文章主要介紹了視覺識別技術在自動駕駛汽車中的應用和發展。
關鍵字:視覺識別;自動駕駛
中圖分類號:U495? 文獻標識碼:A? 文章編號:1671-7988(2020)22-29-03
Abstract: This paper analyzes the basic solutions of self-driving cars and describes the importance of visual recognition in self-driving vehicles. Analysis of how cars use cameras to distinguish obstacles from traditional pattern recognition frameworks. This paper introduces the relevant theories of human visual conception and deep learning. Analyze the importance of a picture database from the process. This paper mainly introduces the application and development of visual recognition technology in self-driving cars.
Keywords: Visual recognition; Self-driving
CLC NO.: U495? Document Code: A? Article ID: 1671-7988(2020)22-29-03
前言
近年來,隨著人工智能技術快速發展,無人車和自動駕駛這種跨行業的應用場景得到了長足的進步。國內百度,騰訊,阿里等企業紛紛進入到了無人車的研發中,國外的Google,Uber等也投入了大量的精力到無人車的研發。本文僅僅淺談視覺技術在自動駕駛汽車中的應用。
1 視覺識別與自動駕駛
目前車企采用的無人駕駛方案所采用的傳感器基本上都是超聲波傳感器,毫米波雷達,激光雷達和視覺攝像頭。其中超聲波雷達一般用在倒車雷達等輔助裝置上,高速情況下會失效。毫米波雷達(Radar)主要是遠距離探測,探測距離可以達到250m左右。激光雷達(Lidar)也是目前使用最多的傳感器,可以實現360°,三維探測,但是造價較高。本文重點攝像頭成本適中,可以分辨出障礙物的大小,采用雙目攝像頭可以識別距離,并且通過圖像處理學習,可以識別出物體種類[1]。但是攝像頭和人眼一樣,會受到視野的影響,也會受到惡劣天氣的影響從而造成誤判。比如2016年特斯拉Autopilot模式下全速撞上左拐白色大貨車,事后分析原因,一個是大貨車底盤較高,特斯拉未檢測到,還有一點就是特斯拉視覺系統在強光下把白色拖車的白色車身誤認為是一朵白云。在經過這次事件后,特斯拉升級了Autopilot2.0版本,環繞車身共配備了8個攝像頭,視野范圍達到了360°,對周圍的環境檢測距離最遠可達250米,12個新版超聲波雷達作為視覺系統的補充,可以探測柔軟或者堅硬的物體,傳感距離和精確度比上一代提升了1倍。增強版本的前置雷達,可以穿越雨,霧,灰塵,甚至前車的下方空間進行探測,為視覺系統提供更加豐富的數據。2018年大疆發布了無人機Mavic Air,其中搭載了7個攝像頭的視覺感知系統,實現了三維環境的感知。所以無論是無人車還是無人機,視覺感知都起到了無比重要的地位[2]。在自動駕駛中,視覺識別為何如此重要?雷達的立體全方位探測,精度高,但是由于計算量大,有延時,價格昂貴,短期內無法大范圍普及。而采用雙目攝像頭,可以將拍到的景物實時轉化為距離,從而實現碰撞預警,車道偏離預警等功能,并且價格低廉,適合目前車輛。
2 計算機視覺與傳統模式識別框架
汽車是如何通過攝像頭識別區分障礙物的呢?
首先我們需要了解一下基本概念。計算機視覺,就是用各種成像系統代替視覺器官,作為輸入手段,由計算機代替大腦完成處理和解釋。模式識別,一是研究生物體是如何感知對象的,二是在給定的任務環境下,如何用計算機實現模式識別的理論和方法。
傳統的模式識別方法分為4個步驟。低維感知,一般通過矩陣,像素的方式使圖片可以被計算機所識別獲取,即把圖片讀入電腦,是信息獲取的過程。預處理指的是把圖片進行矯正,解決圖像的傾斜,噪點等問題。特征提取選擇是傳統的模式識別非常重要的一個步驟。例如,對于數字的識別,每一個阿拉伯數字都有相應的特征,如何選取每一個數字的特征是關鍵。舉個例子,對于0和1的識別,我們實際處理中可以提取在x軸上的像素投影特征就可以區分0或1。對于其他的數字識別,可以選擇其他的特征進行提取,比如X軸,Y軸,投影特征,幾何重心特征,旋轉不變性特征等,或者幾個特征綜合運用。在特征提取選擇過后,我們才可以對圖像進行預測感知識別等操作[3]。
對于傳統的模式識別,有以下幾點需要注意。傳統的模式識別方法必須依賴良好的特征提取選擇,這個對于最終識別的準確性起到了關鍵性的作用。識別系統的主要計算集中在特征提取選擇部分。特征的樣式目前都是人工設計的,靠人工來提取特征,如果人工提取特征有缺失,那么我們模式識別的準確性也會降低。
3 人的視覺機理和深度學習
計算機視覺技術的研究框架和人類的學習框架類似。1981年諾貝爾醫學獎獲得者David Hubel發現了視覺系統的信息處理機制。(1)人腦視覺系統的信息處理是分級的。(2)并且通過層次網絡結構逐層傳遞,從低層到高層,特征表示越來越抽象,越來越能表現語義。(3)抽象層面越高,存在猜測的可能性就越小,就越利于分類。所以人類視覺信息的傳遞不是單純的幾何特征或者物理特征來實現對物體的視覺感知或者識別,而是通過逐層的映射形成抽象的特征最終實現物體的識別。這個發現給計算機視覺技術提供了巨大的啟示。加拿大科學家Geoffrey Hinton把視覺系統的信息處理機制和計算機學習結合起來,提出了深度學習的觀點:人工神經網絡多感知層次的比單感知層次的好,更接近于人大腦的神經元的結構;深度學習可以通過逐層初始化(逐層初始化可以通過無監督學習實現)解決訓練的難度。說的通俗一點,就好比第二段中提到的模式識別,傳統的模式識別必須依賴人工設計的特征,這需要大量的專業領域知識,而特征提取的好壞直接影響到到了結果。深度學習作為一種自動特征學習方法,把原始數據通過一些簡單的但非線性的模型轉變成為更高層次的、更加抽象的表達。通過足夠多的轉換組合,非常復雜的函數也可以被學習。簡單來說,深度學習使用一種通用的學習過程從數據中學習各層次的特征,而不是手工設計特征提取。
4 圖像數據與物體識別
隨著互聯網的快速發展,在互聯網中產生了大量的圖片,這些圖片其實就是一個龐大的數據庫。汽車之所以可以通過攝像頭識別出各種障礙物,識別出路面上物體的種類,這個要歸功于深度學習的快速發展。而深度學習則需要大量的數據來進行訓練來提高視覺識別的準確性。華裔科學家李飛飛發布了包含了1500萬張圖片,2.2萬個類別的IMAGENET數據集,用于視覺識別的研究。自動駕駛技術和視覺識別技術的融合提高了現代汽車智能化。
5 總結
筆者在本文中主要講述了:
(1)自動駕駛的基本解決方案;
(2)通過案例講述了視覺識別技術在自動駕駛中的重要作用;
(3)傳統模式識別的基本框架;
(4)人體的視覺機理和深度學習的起源;
(5)圖像數據庫對于視覺識別重要性。
視覺識別技術只是自動駕駛感知系統中的一部分,目前車輛上主要用于輔助駕駛,距離真正意義上的自動駕駛還有很長的一段路。并且其本身對于光線要求高、只能獲得2D平面數據、數據處理延遲、地面異形識別障礙、工作易受外部條件干擾等等缺陷,均需要毫米波雷達、激光雷達等硬件補足。只有和其他傳感器共同作用時,才可以構建出真正的自動駕駛車輛。
參考文獻
[1] 蔣文斌,彭晶,葉閣焰.深度學習自適應學習率算法研究[J].華中科技大學學報(自然科學版),2019,(5).79-83.
[2] 姜灝.一種自動駕駛車的環境感知系統[J].電子制作,2018,(15). 70-73.
[3] 譚力凡.機器視覺與毫米波雷達融合的前方車輛檢測方法研究[D].湖南大學,2018.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
電子制作(2019年15期)2019-08-27 01:12:00
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子測試(2017年23期)2017-04-04 05:06:50
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
智能系統學報(2017年5期)2017-01-22 11:21:30
智能系統學報(2015年3期)2015-01-29 15:20:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
