SPGAPSO-SVM:一種城市公交客流量預測算法
2020-12-11 01:49:58李雷孝
小型微型計算機系統 2020年11期
林 浩,李雷孝,王 慧
1(內蒙古工業大學 數據科學與應用學院,呼和浩特 010080) 2(內蒙古自治區基于大數據的軟件服務工程技術研究中心,呼和浩特 010080)
1 引 言
在現代交通系統中,城市公交交通發揮著重要職能.相對于其他出行方式,公共交通具有載客量大、排污量小、成本較低等優勢.為了保障城市公交高效有序的運營,不僅需要良好的公交運營管理方案,有效的運營調度同樣必不可少.利用公交相關信息數據進行準確公交客流量預測可以為城市公交車的運營調度提供有效的決策支持.
目前國內外學者在公交客流量預測領域已經取得了一定的研究成果,研究成果可分為兩類,一類是用數學方法建立數學規劃模型或線性預測模型來實現對城市公交客流量的預測.文獻[1]利用多元線性回歸方法建立公交車各個時間段的客流量預測模型,并通過城市一卡通數據對模型進行了驗證[1].文獻[2]采用乘積差分整合移動平均自回歸模型(Autoregressive Integrated Moving Average model,ARIMA)對城市軌道交通的客流量進行預測,實驗結果表明該模型具有良好的適用性[2].另一類是通過機器學習的相關算法構建預測模型,利用訓練數據對模型進行訓練,從而預測出客流量.文獻[3]使用長短時記憶網絡(Long Short-Term Memory,LSTM)實現對多個公交站點的客流量預測,并分析出多個站點的客流量數據間存在相關性[3].文獻[4]采用基于黃金分割的粒子群算法對支持向量機(Support Vector Machine,SVM)的參數進行尋優,構建了混合核SVM客流量預測模型[4].文獻[5]根據徑向基(Radial Basis Function,RBF)神經網絡的特點構建了多尺度RBF神經網絡的客流量預測模型.實驗結果顯示,RBF神經網絡的學習速度快于BP神經網絡,更適用于客流量預測領域[5].
由于公交客流量日間變化較大,其數據具有非線性、非平穩性、潮汐性等特點[6].而SVM作為經典的機器學習算法之一,通過尋求結構風險最小化(Structural Risk Minimization,SRM)來最小化實際風險,能夠較好地解決非線性數據、小樣本和維數災難等問題[7].故本文采用SVM進行城市公交客流量預測.SVM算法的性能受其核函數以及核函數參數值的影響.針對傳統SVM預測模型準確率不高的問題,本文在SVM的參數尋優階段采用基于遺傳算法(Genetic Algorithm,GA)和粒子群算法(Particle Swarm Optimization,PSO)的混合啟發式算法輔助SVM確定核函數參數.混合啟發式算法相比單一啟發式算法,計算量必定更大,耗時必定更長.針對混合啟發式算法速度較慢的問題,分析了影響算法速度的原因,對混合啟發式算法基于Spark平臺進行了并行化設計,并以此提出了SPGAPSO-SVM算法.使用SPGAPSO-SVM算法訓練公交客流量預測模型,進而預測公交客流量可以在提高預測準確率的同時減少算法運行時間,進一步提高公交客流量預測的效率.
2 SVM算法優化
2.1 支持向量機
支持向量機是Vapnik等提出的一種基于統計學習理論的機器學習方法,根據用途可分為支持向量回歸機(SVR)和支持向量分類機(SVC).基本思想是在空間中尋求最優分類面,使得距離超平面最遠的樣本點之間距離最大.設n個樣本集為{((xi,y1)|i=1,2,…,n)},xi∈Rn,其中xi為輸入樣本,yi為輸出樣本.此時的決策邊界超平面表示如公式(1)所示.
ωTxi+b=0
(1)
通常樣本往往是非線性且不可分的,故需引入懲罰因子C與松弛因子ξ,從而得到非線性SVM,如公式(2)所示.
(2)
其中懲罰因子C的作用是調整誤差,其取值決定了模型因為離群點而帶來的損失.針對公式(2)所描述的非線性問題,可以通過引入核方法(KernelTrick)解決.RBF核是實際中最常用的核函數,其對應的映射函數可以將樣本空間映射至高維空間,RBF的解析式如公式(3)所示.
(3)
g為核函數半徑,是RBF函數自帶的一個參數.g隱含地決定了數據映射到新特征空間后的分布,g越大,支持向量越少,而支持向量的個數又影響著訓練與預測的速度.g和公式(3)中σ的關系如公式(4)所示.
(4)
懲罰因子C與核函數半徑g是SVM模型兩個非常重要的參數,C和g的取值很大程度上決定了SVM模型的復雜程度和性能.為了優化SVM模型性能,提高回歸預測準確率,本文采用GA和PSO混合優化算法輔助SVM尋找最優的C與g.
2.2 遺傳算法優化支持向量機
遺傳算法是Holland等人受達爾文進化論的啟發,通過模擬自然界和生物進化而被提出的一種元啟發式算法.GA過程簡單,多用于函數優化、數據挖掘、機器學習等領域.但GA的種群個體沒有記憶,遺傳操作盲目無方向,故所需要的收斂時間更長.
對于SVM參數尋優問題,二進制編碼是最常用的編碼方法.二進制的編碼、解碼操作簡單易行;交叉、變異操作便于實現.遺傳算法通過適應度函數評價每一組參數的適應度,來引導迭代過程向好的方向進行.計算適應度后,根據個體的適應度選擇個體,并借助于組合交叉和變異等操作,產生出新的解集種群.
2.3 粒子群算法優化支持向量機
PSO是Eberhart博士和Kennedy博士于1995年提出的一種元啟發式算法.該算法的思路源于鳥群捕食行為,通過群體中個體之間的信息傳遞和信息共享來尋找最優解.相較于其他優化算法,PSO參數選取簡單、收斂速度快,但是PSO也存在著精度較低、易發散等缺點.
PSO同樣使用適應度評價粒子的優劣程度,通過適應度函數尋找個體極值和全局極值,隨后根據公式(5)、公式(6)更新各粒子的速度及位置.
v=v1+c1r1(pbest-xi)+c2r2(Gbest-xi)
(5)
x=xi-vi
(6)
在公式(5)、公式(6)中,v是更新后粒子速度;x是更新后粒子位置;vi是粒子當前速度;xi是粒子當前位置;c1和c2分別為學習因子;r1和r2為(0,1)之間的隨機數;pbest為個體極值;Gbest為全局極值.公式(5)中3項相加反映了粒子間的信息共享,通過個體的經驗和種群的經驗來決定下一步活動.
2.4 GAPSO-SVM預測模型
單一智能算法優化SVM在解決復雜問題時存在許多不足,利用算法之間互補性的混合算法成為近年來的研究熱點.啟發式算法的混合大體上可分為3類:串行式混合,嵌入式混合,并行式混合.本文根據文獻[8],總結PSO算法和GA算法的混合方式、優勢和應用如表1所示[8].

表1 PSO和GA的混合方式、優勢和應用Table 1 Hybrid mode,advantages and applicationscenario of PSO and GA
由表1可知,并行式混合適用于參數優化等問題.GA和PSO同為元啟發式算法,二者均具有智能性和隨機性.并且GA和PSO都有種群、適應度函數、更新操作、迭代操作等概念,可以共用一個種群,且均具有并行性.GA比PSO種群更多樣,搜索更全面;PSO比GA算法思想更簡單,收斂更快速.將GA和PSO結合成GAPSO-SVM算法,兩者的異同點使得兩種算法在性能上可以克服局限性,實現互補[9,10].
2.4.1 GAPSO-SVM算法設計
SVM參數尋優問題的關鍵是尋找最優的C與g[11],因此SVM參數尋優問題的數學模型可以表示為:
P={gbest,Cbest}
(7)
GAPSO-SVM算法將種群分成兩部分,分別進行GA操作和PSO操作,每次迭代比較出兩者中較優值作為本次迭代的結果進入下次迭代,如公式(8)、公式(9)所示.
(8)
(9)
利用GA和PSO都是通過迭代尋優的共性,將兩個算法混合并共用一個最優個體,迭代中充分利用GA的搜索范圍大和PSO快速收斂的能力.將參數尋優后得到C與g作為SVM的運行參數輸入,訓練新的SVM預測模型,進而可求出SVM預測模型的準確率Accuracy.將Accuracy定義為SVM參數尋優問題的目標函數,則可將GAPSO-SVM算法參數尋優問題描述為:
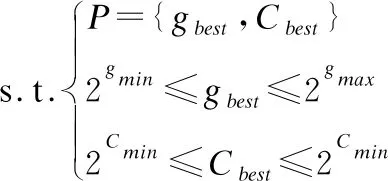
(10)
其中gmin和gmax為RBF核參數g的變化范圍,Cmin和Cmin為懲罰參數的C變化范圍.最后判斷所得結果是否滿足終止條件.當滿足終止條件時,終止GAPSO-SVM算法的迭代.終止條件如公式(11)所示.
min{fitnessgabest,fitnesspsobest}≤fitnessmin
orT≤Tmax
(11)
其中finessmin為最小適應度,即可接受的最小誤差,T為迭代次數,Tmax為最大迭代次數.
GAPSO-SVM算法根據訓練數據規模將實驗數據切分為訓練集和測試集.對初始種群分別進行GA操作和PSO操作,如果當次迭代GA適應度優于PSO適應度,則將GA的最優個體保存下來用到下一次迭代中.當二者的最小值小于最小的適應度或迭代次數超過了最大迭代次數,則終止迭代,返回最優C、最優g作為SVM運行參數.
2.4.2 GAPSO-SVM算法耗時分析
GAPSO-SVM算法的GA操作和PSO操作均可分為初始化種群、種群更新、計算適應度3部分.初始化種群部分包括參數初始化、隨機生成初始化種群、計算初始化種群適應度.種群更新部分包括選擇操作、交叉操作、變異操作、速度更新、位置更新、種群更新.計算適應度部分包括遍歷種群中的所有個體,并調用svm_train函數計算個體適應度.分別運行GA操作和PSO操作20次,其中最大迭代次數為50,種群規模為20,計算并記錄各部分消耗時間的平均值.運行結果如圖1所示.

圖1 GAPSO-SVM算法各部分耗時Fig.1 Time consumptionabout each part of GAPSO-SVM
由圖1可知,針對GAPSO-SVM算法而言,種群內所有個體適應度的計算約占總體算法運行時間的91.4%,計算邏輯較為復雜的種群更新耗時約占總體算法運行時間的5.72%,初始化種群約占總體算法運行時間的3.4%.計算適應度耗時過長是因為每個個體都需要進行一次交叉驗證來計算樣本均方誤差(Mean Square Error,MSE).如最大迭代次數為50,種群規模為20,交叉驗證參數為5,則要進行5000次交叉驗證.
針對計算適應度消耗時間過長的問題,本文將采用Spark平臺對算法進行并行化處理來減少計算適應度運行時間.
3 SPGAPSO-SVM算法的提出
與GA-SVM、PSO-SVM等單一算法優化SVM相比,GAPSO-SVM算法邏輯更加復雜,計算量必然更大,算法運行時間也必然更長,尤其是計算適應度階段[12].所以本文將GAPSO-SVM算法基于Spark平臺進行并行化處理,提出SPGAPSO-SVM算法,以提高算法的運行速度.
3.1 Spark平臺
Spark是專為大規模數據處理而設計的快速通用的計算引擎.Spark擁有MapReduce所具有的優點,并且中間輸出結果可以保存在內存中.因此Spark能更好地結合數據挖掘與機器學習等需要迭代的MapReduce的算法.在內存計算下,Spark比Hadoop快100倍;在硬盤計算下,Spark比Hadoop快10倍[13].
3.2 SPGAPSO-SVM算法設計
SPGAPSO-SVM算法設計主要是依賴Spark所特有的彈性分布式數據集(Resilient Distributed Datasets,RDD)來進行種群的構建、切分和并行化處理.針對計算適應度耗時過長的問題,將種群切分為多個子種群,并行計算子種群內個體的適應度.本文采用SVM的MSE作為適應度函數,適應度函數的計算公式如公式(12)所示.
(12)
3.2.1 SPGA操作
在SPGA操作開始階段,首先設置SparkConf參數,用于Spark集群應用提交.使用二進制編碼將變量編碼成染色體用于隨機初始化種群.將種群轉化為RDD,通過map(getFitness())并行計算種群內個體的適應度.通過collect()合并所有個體適應度,隨后比較出最優適應度.使用輪盤賭方法對當前種群進行選擇操作、交叉操作和變異操作以產生新的種群,每個個體進入下一代的概率如公式(13)所示[14].
(13)
反復以上操作直至滿足終止條件.算法偽代碼如下所示.
算法1.SPGA
輸入:conf:Spark初始化參數
lenchrom:染色體長度
bound:染色體取值范圍
sizepop:種群規模
k:數據分區個數
pcross:交叉概率
pmutation:變異概率
輸出:newChrom:迭代后種群
bestFitness:最優個體適應度
1.ProcedureSPGA(conf,lenchrom,bound,sizepop,k,pcross,pmutation)
2.sc← sparkConf(conf)
3.foriinsizepopdo
4.chrom[i] ← Code(lenchrom,bound)
5.endfor
6.populationRdd←sc.parallelize(chrom,k)
7.times← 0
8.while(minFitness≥bestFitnessortimes≥maxTimes)do
9.FitnessRdd←populationRdd.map(getFitness(),k)
10.fitness←FitnessRdd.collect()
11.bestFitness← min(fitness)
12.newChrom← SelectCrossMutation(chrom,fitness,sizepop,pcross,pmutation)
13.chrom.clear()
14.times←times+ 1
15.endwhile
16.endprocedure
3.2.2 SPPSO操作
SPPSO操作的流程和SPGA操作的流程相似.首先設置SparkConf參數,并隨機初始化個體位置和速度.將種群轉化為RDD,再通過map(getFitness())并行計算種群內個體的適應度.SPPSO中適應度函數與SPGA中適應度函數相同,這樣便于比較兩種算法產生的解集種群.通過collect()合并所有個體適應度.以當前種群為基礎,據公式(5)、公式(6)更新個體位置和速度,隨后比較出個體最優適應度和全局最優適應度[15].反復以上操作直至滿足終止條件.算法具體偽代碼如下所示.
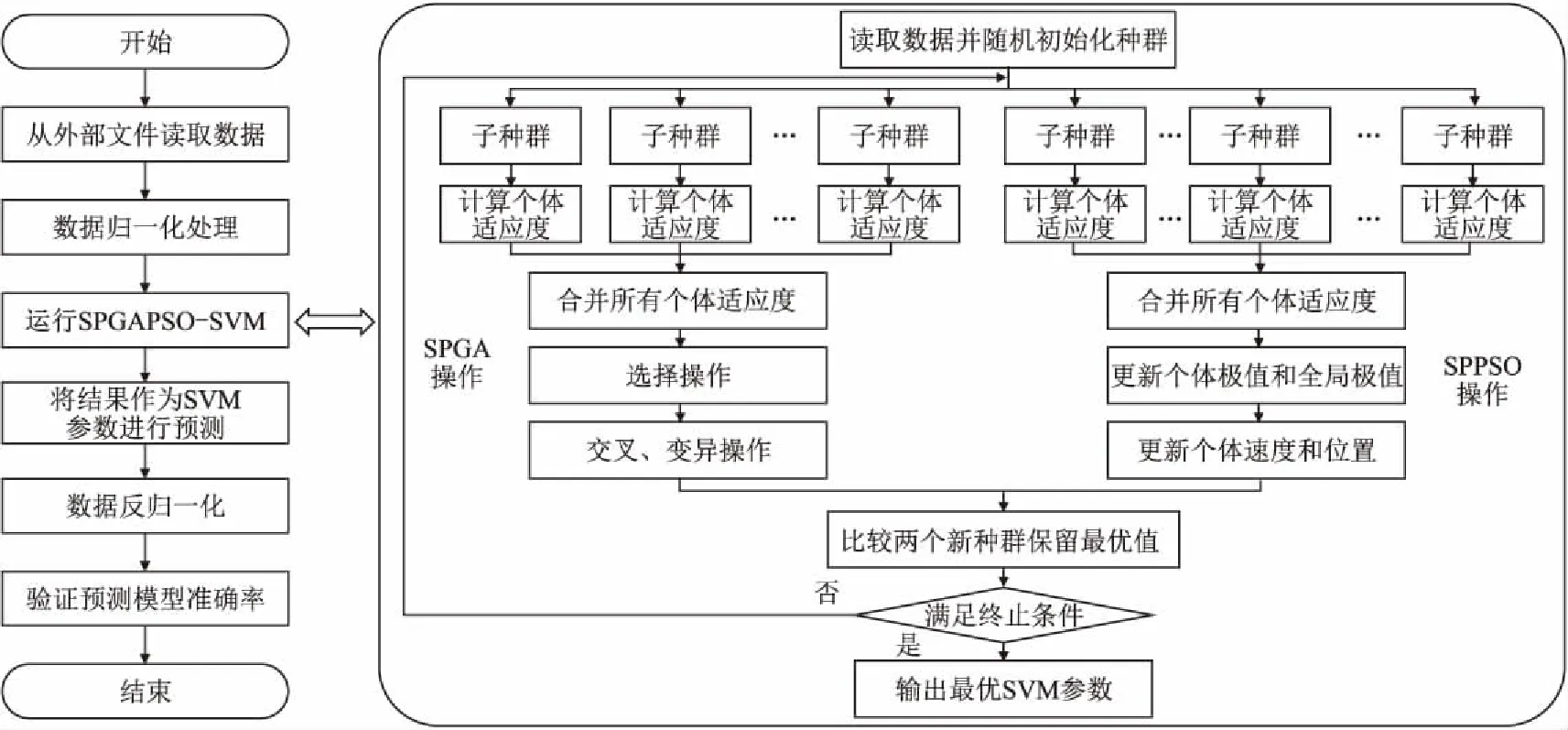
圖2 SPGAPSO-SVM算法Fig.2 Flow chart of SPGAPSO-SVM
算法2.SPPSO
輸入:conf:Spark初始化參數
popmax:粒子位置上界
popmin:粒子位置下界
sizepop:種群規模
k:數據分區個數
Vmax:粒子最大速度
Vmin:粒子最小速度
c:學習因子
輸出:newPop:迭代后種群
bestFitness:最優個體適應度
1.ProcedureSPPSO(conf,popmax,popmin,sizepop,k,Vmax,Vmin,c)
2.sc← sparkConf(conf)
3.foriinsizepopdo
4.pop[i] ←np.random.rand(2)* (popmax-popmin)+popmin
5.V[i] ←np.random.rand(2)* (Vmax-Vmin)+Vmin
6.endfor
7.populationRdd←sc.parallelize(pop,k)
8.times← 0
9.while(minFitness≥bestFitnessortimes≥maxTimes)do
10.FitnessRdd←populationRdd.map(getFitness(),k)
11.fitness←FitnessRdd.collect()
12.bestFitness,bestFitnessForPop← min(fitness)
13.newPop,V← PopVelocityUpdate(pop,V,c)
14.Pop.clear()
15.times←times+ 1
16.endwhile
17.endprocedure
4 相關實驗與結果分析
4.1 實驗環境
本文利用libSVM(libraryforsupportvectormachines,LIBSVM)實現SVM,編程語言為Python.libSVM是一個支持向量機的軟件庫,是由臺灣大學林智仁教授研發的SVM分類與回歸的軟件包,其高效易用性得到了廣泛認可[16].
本文通過虛擬機搭建的8個節點的Spark集群來驗證SPGAPSO-SVM算法性能,每個節點CPU數量為1,節點內存為1G.集群詳細配置為:CentOS-6.10-x64,Spark-2.1.1-bin-hadoop2.7,hadoop-2.7.2.tar,pyspark-2.3.2,py4j-0.10.8.1,libSVM-3.2.3.SPGAPSO-SVM算法的參數設置如表2所示.
4.2 數據預處理
本文收集廣州市19路公交車2018年1月-6月6個月(20180101-20180631)的IC卡交易數據作為所用的實驗數據. 廣州市19路的運行時間為06時-22時30分, 故本文只對該時間段預測.原始數據共有10個字段,包括交易時間、線路名稱、卡片ID等信息.
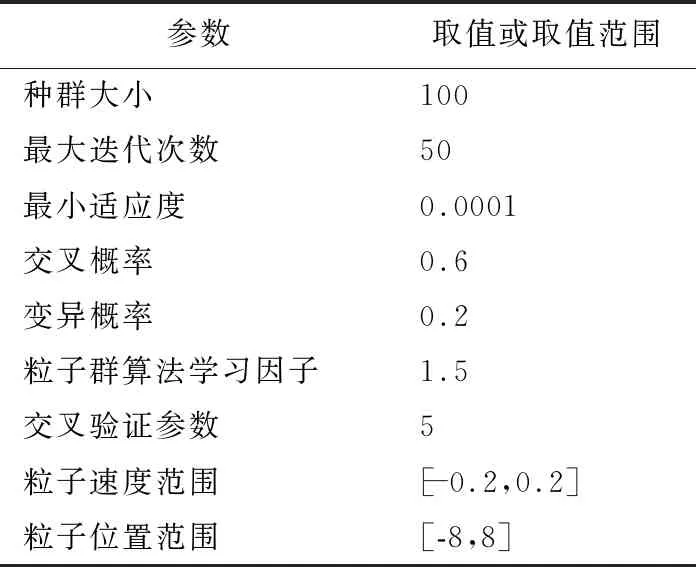
表2 SPGAPSO-SVM算法參數設置Table 2 Parameters setting of SPPSO
為了提高數據挖掘的質量,需要利用Spark對數據進行預處理[17].首先通過rdd:[(str,str)] = rdd1.zip(rdd2)將數據整合為key-value的RDD,其中key為線路編號,value為交易時間;然后通過rdd= filter(lambda keyValue:str(keyValue[0])== Line_name)將客流量信息根據線路編號分組.在節假日期間,城市公交客流量相較平日有明顯不同,以旅游、購物為目的的出行將明顯增多.因此,需通過rdd= filter(lambda keyValue:lp<= keyValue[1] <= up)將節假日的數據去掉以提高預測的準確率.由于SVM對零一之間的數據較為敏感,訓練速度較快,故對數據進行歸一化處理[18].常用的基于極值歸一化公式如公式(14)所示.
(14)
其中X為原始數據,Xmax、Xmin分別為原始數據集的最大值和最小值.
使用libSVM作為SVM的實現工具,還需要將進行篩選過的數據整理為libSVM的輸入格式.libSVM的輸入格式如下.
Label index 1:value index2:value index3:value
對于客流量預測,Label應為目標值,index是以1開始的整數,value為訓練數據.
4.3 實驗結果分析
4.3.1 算法準確率和效率
算法準確率采用平均絕對百分誤差(MAPE)和均方誤差(MSE)評價,算法效率是指算法執行速度的快慢,使用算法程序運行消耗的時間衡量.
在上述實驗環境下,采用Python語言對SVM、PSO-SVM、GA-SVM和SPGAPSO-SVM算法進行了實現,并將這4種算法運行效果進行對比,以此驗證算法的準確率和效率.采用4.2中經過預處理的數據,將每個算法分別運行20次,計算并記錄其中MAPE的最優值、最差值和平均值.運行結果如表3和圖3所示.
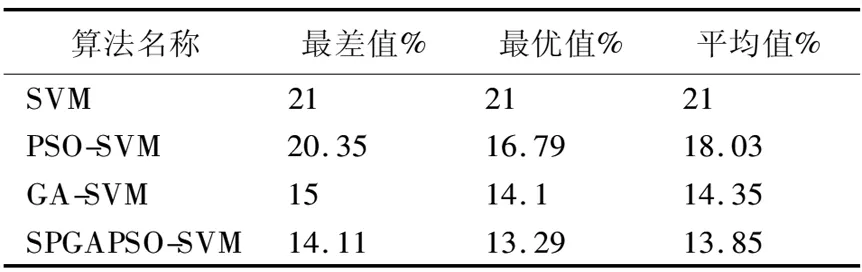
表3 算法的準確率對比Table 3 Accuracy comparison of algorithms
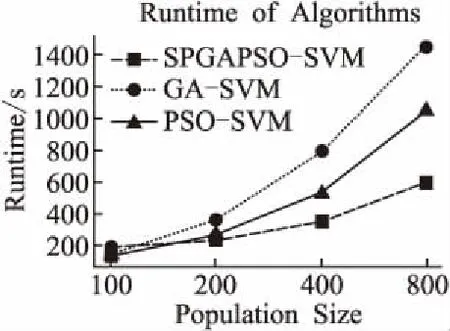
圖3 算法的運行時間對比Fig.3 Running time comparison of algorithms
由表3可以看出,針對客流量預測問題,傳統SVM算法預測準確率穩定在79%;PSO-SVM的最差值與最優值相差接近4%,這表明PSO-SVM陷入局部最優的概率很高且非常不穩定;GA-SVM的表現優于PSO-SVM,平均準確率為85.5%左右;SPGAPSO-SVM算法相比PSO-SVM和GA-SVM準確率更好,并且平均最優值與最差值相差更小證明了其尋優穩定性更佳,整體預測準確率可以達到86.71%.實驗結果表明本文提出的SPGAPSO-SVM算法在客流量預測的準確性上優于其他方法.
對于GA和PSO來說,種群的大小決定了整體算法的計算量.由圖3可以看出,在計算量小的情況下,SPGAPSO-SVM算法運行所用時間最長.這是因為申請資源、啟動作業、劃分任務等基礎消耗時間大于每個節點任務的計算時間.隨著計算量的增加,3個算法的運行時間呈近線性增加,并行計算的優勢越來越明顯,SPGAPSO-SVM算法運行所用時間將遠遠少于GA-SVM和PSO-SVM.實驗結果驗證了本文提出的SPGAPSO-SVM算法比GA-SVM和PSO-SVM運行速度更快,算法運行所用時間更短,計算效率更高.
本文利用Python語言實現了RBF神經網絡和LSTM作為典型機器學習算法與本文提出的算法進行對比.其中LSTM的學習率為0.01、timestep為32、batchsize為5,RBF神經網絡的參數通過網格搜索確定,計算結果如表4所示.
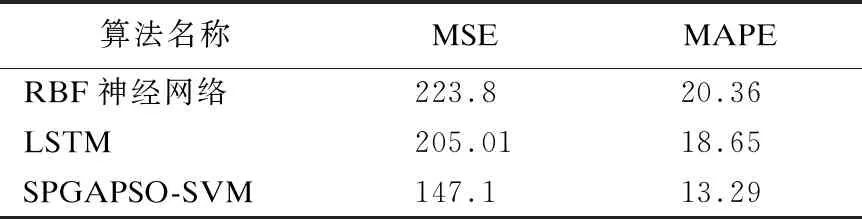
表4 SPGAPSO-SVM與典型機器學習算法對比Table 4 Comparison between SPGAPSO-SVM and othertypical machine learning algorithms
由表4可知,本文提出的SPGAPSO-SVM算法的預測效果優于RBF神經網絡和LSTM.
4.3.2 收斂曲線對比實驗
收斂曲線對比實驗使用均方誤差(MSE)作為評價指標,用于觀察SPGAPSO-SVM算法在每次迭代中SPGA操作和SPPSO操作的誤差變化和參數尋優的整體收斂速度,從而驗證混合算法的是否跳出了局部最優.在8個節點的集群中運行SPGAPSO-SVM算法,其中種群大小為100,最大迭代次數為50,記錄每次迭代的MSE.運行結果如圖4所示.
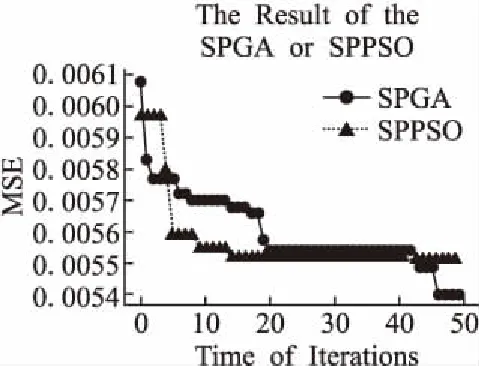
圖4 SPGA操作和SPPSO操作的收斂曲線Fig.4 Convergence curve of SPGA and SPPSO
從圖4可以看出,算法在20代以前收斂速度較快,算法在20代以后收斂速度逐漸變慢.在迭代開始階段,SPGA操作幫助整體算法跳出了局部最優.在第5次迭代時,SPGA操作陷入了局部最優,而SPPSO操作幫助整體算法跳出了局部最優;在第42次迭代時,SPGA操作再次幫助整體算法跳出局部最優;至此參數尋優算法在最大迭代次數的限制下收斂至全局最優解.實驗結果驗證了SPGAPSO-SVM算法與GA-SVM、PSO-SVM等單一算法優化SVM相比具有兩個優點:SPGAPSO-SVM算法可以有效克服GA-SVM、PSO-SVM等單一算法優化SVM易陷入局部最優的問題,預測的準確率更高;在最小適應度相同的情況下,SPGAPSO-SVM算法比GA-SVM、PSO-SVM等單一算法優化SVM所需的迭代次數更少.
4.3.3 算法可擴展性驗證
算法可擴展性實驗用于測試是否可以通過增加節點來提高算法運行速度.實驗基于單個節點、2個節點、4個節點和8個節點,采用4.2中經過預處理的數據,將SPGAPSO-SVM算法運行20次,計算并記錄平均值和加速比.運行結果如圖5和圖6所示.
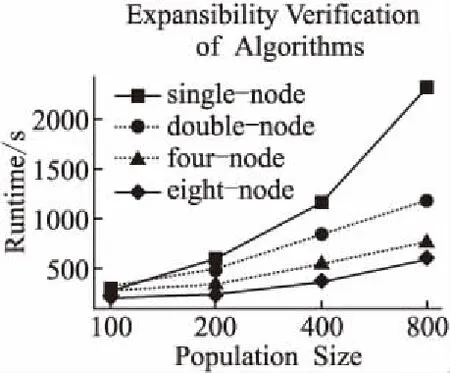
圖5 SPGAPSO-SVM算法可擴展性實驗Fig.5 Experiments on scalability of SPGAPSO-SVM
由圖5可以看出,隨著計算量逐步增加運行時間呈線性增長.當種群大小為100時,單個節點、2個節點、4個節點和8個節點差別較小.這是因為多節點集群運行程序時,需要申請資源、啟動作業、劃分任務和分配資源等操作,存在一定的基礎消耗.隨著計算量的增大,8個節點的運行時間將遠遠低于4個節點、2個節點和單個節點.這是因為節點數越多,每個計算節點負責處理的計算量就越小.
加速比是同一個任務串行運行時間和并行運行時間的比值,是衡量可擴展性的一個重要指標.由圖6可以看出,在計算量小的情況下,加速效果不明顯,這是因為集群基礎消耗的時間較多,集群未發揮到理想的效果.隨著計算量的逐步增加,加速比呈增長趨勢并逐漸趨于理想值.通過上述實驗結果分析,進一步說明了SPGAPSO-SVM算法具有較好的可擴展性.
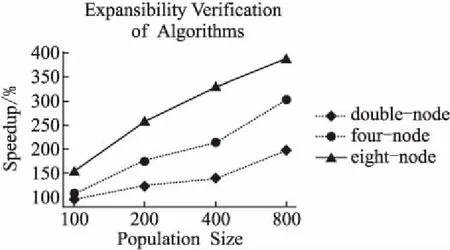
圖6 SPGAPSO-SVM算法加速比實驗Fig.6 Speedup experiment of SPGAPSO-SVM
4.3.4 客流量預測結果
使用4.2中經過預處理的數據作為實驗數據,采用SPGAPSO-SVM算法對數據集最后14天(20180617-20180630)06時-22時的公交客流量進行預測,共224小時.將每小時的預測結果按時間順序拼接,預測結果與真實值對比如圖7所示.
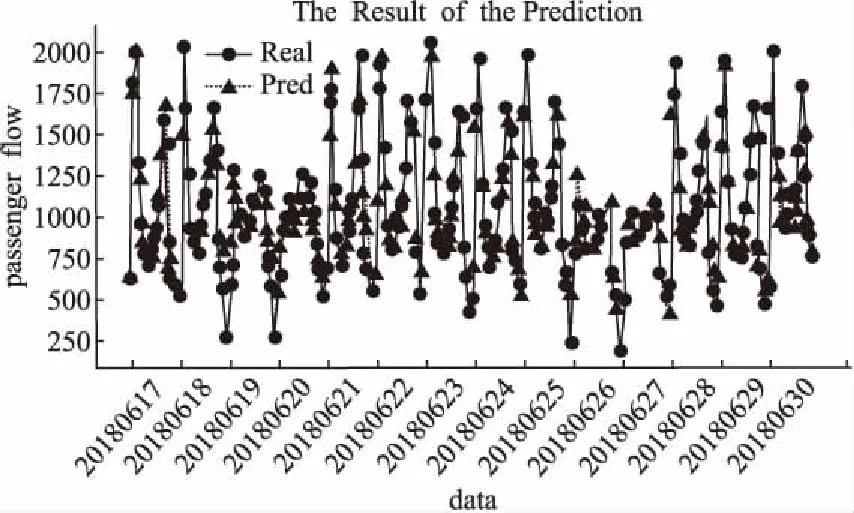
圖7 客流量預測值與實際值對比Fig.7 Comparisons between predicted passenger flow and real passenger flow
通過圖7可以看出,SPGAPSO-SVM算法對高峰期客流量預測有較高的準確率,對低谷期客流量預測存在一定偏差.當次整體預測準確率為86.71%,當次參數尋優后最優為0.68,最優為15.4873.
5 結 論
本文在對公交客流量預測領域相關研究成果進行深入分析研究的基礎上,針對GAPSO-SVM算法復雜度較高和運行速度過慢的問題,對GAPSO-SVM算法基于Spark平臺進行了并行化處理,提出SPGAPSO-SVM算法,該算法有效提高了運行速度和效率.選取2018年廣州市19路公交車6個月的IC卡交易數據作為實驗數據,并根據實際需求對該數據集進行了預處理,設計GAPSO-SVM算法耗時分析、SPGAPSO-SVM算法準確率和效率、算法可擴展性等多組實驗對SPGAPSO-SVM算法進行了驗證.實驗結果表明,SPGAPSO-SVM算法具有較高的預測準確率、較快的運行速度和良好的可擴展性,預測效果由優于RBF神經網絡和LSTM等傳統機器學習算法.
