一種基于差分進化改進的深度神經網絡并行化方法
2020-12-11 01:49:26朱光宇謝在鵬朱躍龍
小型微型計算機系統 2020年11期
朱光宇,謝在鵬,朱躍龍
(河海大學 計算機與信息學院,南京 211100)
1 引 言
神經網絡[1]是對于人腦認知能力的近似和模擬,通過模仿生物神經網絡的特性來處理各類非線性復雜問題.多年來,神經網絡在模式識別、圖像處理、語音識別、文本處理、目標檢測、人臉識別等多個領域取得巨大成就[2-7].
神經網絡在高速發展的同時也面臨著挑戰[8].目前已有的深度神經網絡,其網絡模型結構及相應參數量日趨龐大.在如此復雜的網絡模型下,訓練數據量增長的同時,往往帶來的是訓練過程中各類計算量的指數增長,這也意味著傳統在單機上進行訓練的方式變得緩慢而又沉重,其所引起的后果將是巨大的時間成本開銷和訓練質量的下降[9,10].因此,研究者們[11-20]提出了多種針對神經網絡并行化改進的方法,其所關注的問題主要包括兩個方面:一是如何通過并行化方式加速模型收斂進程,減少訓練時間;二是在并行化過程中如何提高訓練模型的精度,減少因并行化所帶來的模型精度下降.
2 相關工作
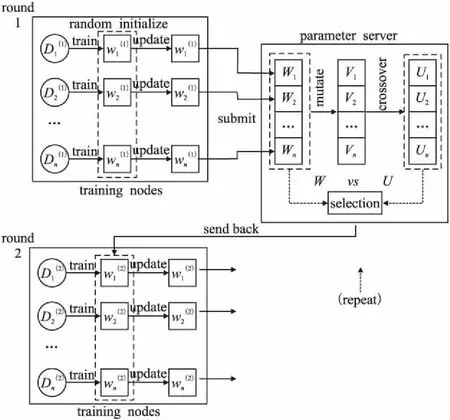
為了解決神經網絡訓練效率的問題,研究者們提出了多種并行化策略,如表1所列,具體可分為兩類:硬件架構層面的改進和軟件體系層面的改進.

表1 神經網絡并行化策略Table 1 Parallel strategies of neural network
在過去一段時間,雖然CPU性能得到較大提升,但依舊難以支撐復雜的深度神經網絡模型訓練,研究者們開始將模型訓練所依托的硬件體系重心轉向其他高并行度、高吞吐量的硬件架構以提高模型訓練過程中的并行處理能力.文獻[11]提出在多GPU下的并行優化策略,提高GPU利用率的同時減少數據傳輸開銷.文獻[12]將神經網絡模型分別在CPU,GPU,ASIC,FPGA上進行了實現并做出了比較,實驗結果表明,FPGA和ASIC表現的性能遠優于CPU和GPU,相比之下ASIC效率更高一些,但FPGA具備更加靈活的策略.雖然硬件可以在一定程度上提高神經網絡的效率,但是成本較高,而且需要對現有架構做較大的改變,如何尋求當前分布式架構下的一種高效方法更加經濟科學.
各種并行模型及各類算法的出現使這一問題得到有效改善.文獻[13]和文獻[14]分別通過MapReduce及Spark模型實現了神經網絡的數據并行化訓練.文獻[15]提出一種基于差分進化的并行方案,但僅對算法內部計算適應度的過程進行了并行化.文獻[16]提出在神經網絡數據并行化過程中,階段性地獲取每個子模型,然后通過參數平均法得到一個全局模型并分發給各子節點進行后續訓練.文獻[17]提出一種基于模型平均的框架,與文獻[16]不同,僅當每個子模型訓練至收斂后,才取平均后的結果作為最優模型.雖然模型平均是并行訓練過程中獲取全局模型可行的方案,但得到的全局模型往往效果一般,模型精度甚至低于其子模型,文獻[18]對此進行了論證,同時提出了一種壓縮算法,該方法獲得的全局模型相較于均值方法獲得了更高的精度,但增加了額外的學習過程.除了模型精度問題之外,還要考慮由于并行化所帶來的額外時間開銷問題.文獻[19]對深度神經網絡在并行化訓練過程中的數據通信開銷進行了研究,提出了一種自適應量化算法實現了接近線性的加速.文獻[20]提出了一種根據數據稀疏性優化數據傳輸量的混合方法.上述研究均未考慮到并行訓練過程中,由于節點計算能力不平衡所造成節點等待的額外時間開銷.本文基于以上存在問題提出新的解決方案.
3 深度神經網絡與并行化
3.1 深度神經網絡
深度神經網絡是一個包含輸入層、輸出層以及多個隱藏層的神經網絡,如圖1所示.神經網絡自底向上逐層完成計算和傳遞,最終在輸出層得到結果,這樣一個過程稱之為前向計算.
前向計算完成的同時,反向自頂向下通過例如隨機梯度下降法來完成參數的更新,如公式(1)所示:
(1)
公式(1)中netj表示神經元ej的輸入,δj表示神經元ej的誤差敏感度,ai表示神經元ei的輸出,η表示學習率,Err表示誤差.對訓練樣本按照上述訓練過程進行數輪迭代,每完

圖1 深度神經網絡Fig.1 Deep neural network
成一輪訓練,模型會得到一次參數更新.訓練DNN的目標就是盡可能發揮其非線性逼近能力,使模型朝著正確的方向收斂,從而提高輸出結果的精確度.
3.2 并行化
深度神經網絡的并行化行式主要包含兩類:數據并行化和模型并行化[1,9].模型并行化指將DNN模型內部中各部分結構分別映射到多個節點上實現并行計算,該方式所帶來的影響是節點間頻繁的數據通信開銷.數據并行化指將訓練數據劃分到多個節點,由各節點分別訓練其所獲得的本地數據.參數服務器階段性地收集各節點訓練出的本地模型并聚合出一個新的全局模型,再將其分發到各個節點上用于之后的訓練.目前采用較多的方式為后者,通過數輪迭代的并行化訓練,在達到終止條件后結束獲得最終模型,如圖2所示.

圖2 數據并行化Fig.2 Data parallelism
一個典型的DNN數據并行化訓練過程可以被描述為如下步驟:
1)數據劃分.訓練數據集D被劃分成n塊分配到集群中的n個訓練節點上,D={D1,D2,…,Dn}.


(2)
公式(2)中f(·)為聚合函數,αk為權重.一般常用聚合方法有,model averaging,即取αk=1/n,對模型參數進行平均;回歸方法,即單獨將聚合過程看作一次線性回歸問題,通過學習得到各模型的加權比重.
4)迭代訓練.在進行第t+1輪訓練前,參數服務器會將上一步得到的全局模型分發給各個節點作為其新一輪訓練時的初始本地模型,如公式(3)所示:
(3)
模型按照上述步驟重復進行多輪迭代訓練,訓練結束后獲得最終DNN模型.
4 DE-DNN
本文提出了一種在現有分布式環境下進行深度神經網絡并行化訓練的方法DE-DNN.該方法提供兩種策略從模型和數據兩個層面對DNN數據并行化過程進行優化.
4.1 DE模型優化策略
在階段性的模型聚合過程中通過一般方法得到的新全局模型往往效果一般[18],從而影響整個并行訓練過程的收斂速度,本文對該步驟進行改進.差分進化(Differential Evolution,DE)是一類基于群體差異的全局優化方法[21],相較于其他方法[22],具備全局收斂快、算法穩定、結構簡單的優點.一個典型的差分進化算法形式為“DE/rand/1/bin”,包括變異、雜交、選擇步驟.其基本思想是每次隨機選取三個個體,其中兩個進行向量差操作后結果加權并與第三個求和來產生新個體,最終通過將適應度高的新個體淘汰適應度低的舊個體來完成種群的更新.本文將基于此對DNN并行訓練過程中獲取全局模型的關鍵步驟3進行優化,以達到改善全局模型精度進而加快收斂速度的目的,具體實現見算法1.
算法1.DE模型優化算法

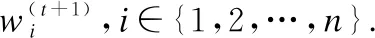
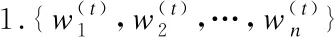
2.forifrom 1 tondo
3. generate new solutions by mutation:

5. generate new solutions by crossover:
6.forjfrom 1 toddo
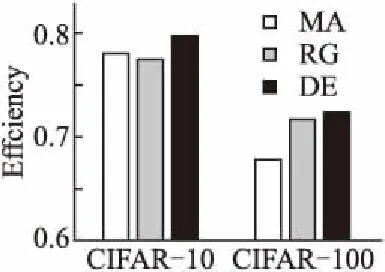
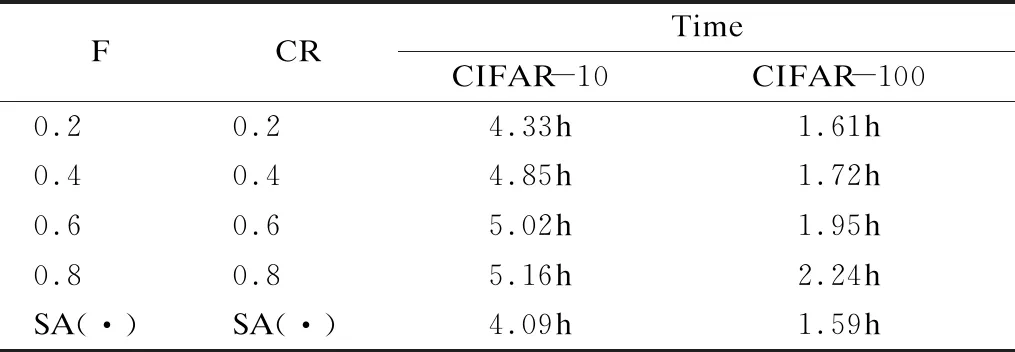
7.ifrandj 9.else 11. get selection for next round: 13.ifAccuu>Accuwthen 15.else 19.end. 假設當前處于第t輪,且各節點已完成本輪的本地訓練,算法具體可以描述為以下幾個步驟: (4) (5) (6) 往后每一輪各節點完成本地訓練后,重復上述步驟,直到達到終止條件,此時參數服務器從當前種群中選擇最優個體作為最終模型.整體過程如圖3所示. 圖3 DE模型優化過程Fig.3 DE model optimization 算法的性能很大程度上取決于縮放因子F和雜交因子CR的設定,由于不同的參數設定會造成不同的影響,我們采用一種自適應控制參數法[23]進行調控,如公式(7、8)所示: (7) (8) 公式(7、8)中randi,i∈{1,2,3,4}是0~1范圍內的隨機數,代表隨機概率;τ1和τ2分別代表調整F和CR的概率.設置τ1=τ2=0.1,Fl=0.1,Fu=0.9.因此,新的縮放因子F是0.1~1范圍內的隨機值,新的雜交因子CR是0~1范圍內的隨機值,通過此方式實現了訓練過程中每代因子的動態優化. 在現有分布式環境下進行DNN數據并行化同樣面臨著訓練節點計算能力不均的問題.考慮到各節點在同一時段可能存在性能差異,并行訓練過程中易出現在某一輪中,已完成本地訓練的節點需要等待少數性能不佳的節點完成其本地訓練后才可以繼續后面工作,從而造成額外的節點等待時間開銷,這與數據在各節點分配的數量有關.本文中DE-DNN提出一種新的基于批處理的自適應數據分配策略BSDA,將訓練數據逐批次并根據各節點當前性能分配適量的數據,從而實現訓練過程中各節點樣本數量的動態優化,具體實現見算法2. 算法2.BSDA數據分配算法 輸入:訓練數據集D,集群節點數n,劃分批次m,新批次數據b 輸出:新批次數據各節點分配量 1.B{B1,B2…Bm}←divide the data set equally intombatches; 2.ifb=B1then 5.else 7.forifrom 1 tondo 9. predict new training time for roundt+1 by efficiency: 12. develop new divisions forbto each node: 15.end. 假設當前的分布式集群中存在n個訓練節點,訓練數據總量為d.BSDA將數據分成m個批次,每次只將d/m個數據劃分給集群,再由BSDA決定分配到各個節點的數量.首批次分配采用均勻劃分,各節點分配到的數據量如公式(9)所示: (9) (10) (11) 以此類推,逐批次為各節點分配適量訓練數據,用公式(12)統一表示.每批次各節點分配數據量依據最近一輪各節點訓練效率進行裁定,本文稱之為自適應分配策略. (12) (13) 文中實驗所采用的環境配置如表2所示.實驗采用CIFAR-10和CIFAR-100數據集[24]進行測試.CIFAR-10是一個由10類共60000張彩色圖像構成的數據集,該數據集中50000張為訓練數據,10000張為測試數據.CIFAR-100數據集大小和格式與CIFAR-10相同,但標簽為100個類別,每類圖像數量僅CIFAR-10數據集的1/10. 表2 實驗環境Table 2 Experimental environment 實驗中基于NiN[25]深度神經網絡模型進行實現,該模型所實現的網絡結構如圖4所示,各層參數信息見表3,共包含966986個參數.實現過程中,同時采用了隨機初始化參數和對網絡內部進行Dropout的操作.以上NiN模型及相應操作皆通過TensorFlow實現并應用于CIFAR-10數據集的測試中.而對于CIFAR-100數據集,其所實現的NiN網絡模型結構相同,唯一區別是Mlpconv3層會輸出100個特征映射. 圖4 NiN實驗模型Fig.4 NiN experimental model 表3 參數信息Table 3 Parameters information 實驗根據目標不同分為兩個部分: 1)模型收斂速度實驗.在并行化訓練過程中,對于階段性獲取全局模型的方法,這里將本文提出的模型優化方法稱為DE,同時將一般常用的Model Averaging方法稱為MA,回歸方法稱為RG,對于傳統串行訓練稱為SE.DE方法增加測試F、CR因子的設定對實驗產生的影響,對于本文采用的自適應參數控制法稱為SA(·),同時測試全過程對F、CR設定固定值產生的結果.實驗中會記錄不同階段各方法得到的模型參數以及所用時間,并通過測試集的分類準確率進行實驗對照. 2)數據分配方法實驗.對DE-DNN采用一般等量分配方法實現,這里稱為EDA,并與本文提出的BSDA方法進行實驗比較.同時考慮分布式環境下訓練節點數量對實驗的影響,我們對節點數量進行調整,比較在不同訓練節點數量下各方法的訓練時間. 實驗1結果反映了各階段,使用傳統串行訓練SE方法以及并行訓練過程中使用DE方法和MA、GR方法得到的全局模型在測試集上的分類準確率.圖5、圖6分別記錄了各方法在CIFAR-10和CIFAR-100數據集上的表現.結果顯示,傳統SE訓練方法在訓練各階段所表現出的模型分類準確率皆遠低于三種并行訓練方法;DE方法在并行訓練過程中,表現出了高于其他方法的分類準確率,在訓練中前期收斂速度明顯加快,可以在較短時間內收斂到更高精度的全局模型,在后期雖然收斂速度放緩,但依舊表現出較高的分類準確率.為了更直觀比較各方法收斂速度,實驗過程中記錄了各方法訓練出的模型在收斂到一定精度時所產生的時間開銷,如表4所示.結果表明,對于實驗中的兩類數據集,DE方法在訓練過程中的模型收斂可以產生較少的訓練時間. 圖5 CIFAR-10測試集準確率 圖6 CIFAR-100測試集準確率 表4 各方法達到不同準確率所用時間Table 4 Time for each method to achieve different accuracy 實驗中同時比較了并行訓練過程中各階段,參數服務器內不同聚合方法所產生的全局模型是否優于各本地模型的平均水平.即在并行訓練各階段,獲得所有本地模型精度和的平均值,并統計各聚合方法獲得的全局模型精度大于該平均值次數的比例,本文將該實驗指標稱為全局模型優越度,用effciency表示,在CIFAR-10和CIFAR-100數據集上分別統計達到0.8和0.6分類準確率時的effciency值.實驗結果如圖7所示,DE聚合方法在CIFAR-10測試集上全局模型優越度接近0.8,在CIFAR-100上超過0.7,且高于MA和RG方法的effciency值,表明DE方法在并行訓練的多數階段,模型精度總體高于各訓練節點的平均水平,有助于在并行化過程中促進全局模型向正確方向收斂,提升訓練效率. 圖7 全局模型優越度Fig.7 Global model effciency 實驗中同時注意到,DE方法在訓練過程中所獲模型精度時出現波動,為測試算法內部F和CR兩個因子的選定對DE過程的影響,表5記錄了實驗中當F、CR選取固定值時和通過SA(·)動態變化時DE-DNN產生的時間開銷.結果表明,當F、CR兩個因子在訓練全過程始終不變時模型的收斂速度,皆低于動態SA(·)方法;且通過調整兩個因子的設定值發現,隨著F、CR增大,對訓練效率造成的影響越大. 表5 不同FCR因子值所用時間Table 5 Time for different FCR factor values 實驗2分別在CIFAR-10和CIFAR-100數據集下進行測試,比較了兩種數據分配方法BSDA和EDA所引入的訓練時間開銷.其中,根據數據集不同,CIFAR-10以分類準確率達到0.8時所引用的時間進行參照,CIFAR-100以分類準確率達到0.6時所引用的時間進行參照.實驗中,設置一臺參數服務器,分別調整訓練節點的數量進行多次測試,比較不同節點數量下各方法的變化情況.實驗結果如圖8、圖9所示. 圖8 CIFAR-10訓練時間 圖9 CIFAR-100訓練時間 由實驗結果可知,本文提出的BSDA數據分配方法在多訓練節點環境下,相較于一般等量分配EDA表現出了更少的訓練時間開銷,且隨著節點數量增多,兩種方法的時間差越明顯,表明出自適應數據分配策略的優異性.但在少量節點環境下效果一般,圖9中顯示在僅有兩個訓練節點的條件下,BSDA較EDA反而產生了更長的時間開銷.同時注意到,在訓練節點數量大于6后,兩種方法對應的時間減少幅度放緩,這表明在一定數據量下,通過增加訓練節點數量可以在有效范圍內提升效率,但持續增加下去所帶來的額外開銷也會對整體進程產生制約. 深度神經網絡在高速發展的同時面臨著訓練效率、模型質量等諸多挑戰,對于深度神經網絡的并行化研究成為熱點.在現有分布式環境下進行數據并行化訓練是DNN并行化的一種有效方案,但其存在全局模型精度不佳、訓練節點性能不平衡的問題.針對該上述問題,本文提出了一種基于差分進化改進的深度神經網絡并行化方法DE-DNN.DE-DNN利用差分進化算法全局收斂快、實現簡單的優點對DNN并行化訓練過程中獲取全局模型的關鍵步驟進行改進和優化;同時提出自適應數據分配算法減少多節點訓練過程中的額外等待時間開銷.實驗中,在CIFAR-10和CIFAR-100數據集上基于NiN深度網絡模型對DE-DNN進行了實現和測試.實驗結果表明,DE-DNN中提出的DE模型優化方法在訓練過程中相較于一般方法SE、MA、RG表現出了更快的收斂速度和更高的全局模型精度;同時,自適應數據分配算法BSDA相較于一般等量分配方法EDA花費了更少的訓練時間,減少了因節點性能不平衡所產生的額外等待時間,加速了訓練進程.未來我們將基于其他不同復雜程度的神經網絡進行實驗,并嘗試分離出一套通用的DE-DNN框架以適應更多類型的深度神經網絡進行并行化接入和測試.

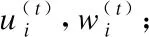


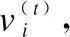


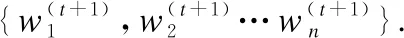
4.2 BSDA數據分配策略



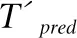

5 實驗評估
5.1 實驗設置



5.2 結果分析





6 總 結
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
