消除測試代碼異味對代碼質量的影響分析
2020-12-11 01:49:48黃華俊吳海濤高建華黃子杰
小型微型計算機系統 2020年11期
黃華俊,吳海濤,高建華,黃子杰
(上海師范大學 計算機科學與技術,上海 200234)
1 引 言
軟件測試是保障軟件質量的重要手段,通過發現軟件缺陷,軟件測試能確保生產代碼在復雜使用條件下的健壯性[1,2].大型商業軟件中包含數量龐大的測試代碼[3],維護工作成本高昂,需要理論和自動化工具的支持.
測試驅動開發(TDD)[4]是一種敏捷開發方法,它提倡在實現業務代碼前編寫對應的測試用例,以保障代碼組件的設計符合預期.作為測試驅動開發的重要組成部分,自動化測試可以在保障軟件系統質量的前提下,高效地避免開發過程中出現功能回退和設計錯誤等問題,從而極大地提高了開發效率[1,2,5].
自動化測試代碼是軟件系統的重要組成部分,編寫和維護具備和生產代碼類似的挑戰性[6].然而,研究發現開發人員傾向于忽視測試代碼的重要性.他們認為,相比生產代碼,編寫和維護測試代碼是一種成本高于回報的負擔.因此,測試代碼缺乏嚴謹的重構計劃[7],其質量普遍低于生產代碼[8-11].提升測試代碼質量的實際意義主要基于主觀經驗得出,仍未被量化研究充分驗證和討論,導致軟件測試的意義未被充分重視.因此,選取一個可量化的角度分析測試質量提升的意義是迫在眉睫的.
代碼異味(Code Smell)是代碼中潛在的不良設計和不良實現[12],它可以衡量生產代碼的質量.測試異味(Test Code Smell,簡稱Test Smell)是代碼異味在軟件測試中的衍生概念[7],它是軟件測試中存在不良設計和不良實現的征兆,使用測試異味度量可以量化測試代碼的質量.
目前,已有工作討論了測試異味的量化檢測方式和部分性質[13-15],但缺乏從異味重構的視角探討其對代碼質量的影響,也未能指出對代碼質量提升最為有效的測試重構操作[14,15],使開發者難以權衡消除代碼異味的代價和收益.
本文檢測了6個開源軟件的93個發布版本,涉及5種測試異味,包括神秘客人(Mystery Guest)、資源樂觀(Resource Optimism)、餓漢測試(Eager Test)、斷言輪盤(Assertion Roulette)和敏感恒等(Sensitive Equality).對于軟件歷史版本中的測試異味消除操作,本文使用SZZ算法量化了測試代碼及其關聯生產代碼(簡稱測試及生產代碼)的缺陷傾向,并利用相對風險RR指標分析缺陷傾向數據,計算測試及生產代碼在異味消除前后存在缺陷傾向的可能性,以量化消除異味對代碼質量的影響.
本文的主要貢獻為:
1)通過對6個開源軟件系統中的5種測試異味進行分析和探討,發現消除測試異味前,測試代碼存在缺陷傾向的概率是消除異味后的一倍,驗證了消除測試異味可以顯著提升測試代碼質量;
2)對比分析了測試異味消除前后生產代碼的缺陷傾向變化,得出消除測試異味能使生產代碼存在缺陷傾向的概率減少59%;
3)分別對5種測試異味分組研究,發現消除餓漢測試異味可以最顯著地提升生產代碼的質量.
本文的章節安排如下:第2節介紹測試異味的相關術語;第3節詳細闡述所提出的方法流程;第4節設計實驗并對結果進行分析;第5節總結本文內容并討論將來的工作.
2 相關工作
2.1 測試異味的定義和檢測
參考代碼異味的研究成果,Van Deurson等人[7]定義并提出了11種測試異味及其重構方法.Meszaros等人[16]基于Van Deurson等人的成果,針對他們在開發過程中遇到的實際問題,擴充了另外18種測試異味.在18種測試異味的基礎上,Tufano等人[14]調查了開源軟件中5個常見測試異味即斷言輪盤、餓漢測試、通用固件(General Fixture)、神秘客人和敏感恒等的性質.
表1給出了本文所涉及的測試異味,它們源于Van Deursen等人[7]定義的異味目錄,包括神秘客人、資源樂觀、餓漢測試、斷言輪盤和敏感恒等.選擇以上5種測試異味的原因包括:

表1 測試異味及其描述Table 1 Description of test smells
1)它們常見于相關研究[17]和開源軟件系統(OSS)項目中[15];
2)這些測試異味的產生原因不同,不存在顯著的共現性,且與測試代碼的不同特征有關.
在研究測試異味自動化檢測工具的相關文獻中,最為常見的是Bavota等人[15]實現的異味檢測工具,研究指出其精確率能達到88%,召回率能達到100%,但該工具非開源軟件.因此,本文選擇開源的tsDetect異味檢測工具作為替代,在檢測測試異味時,它能夠達到至少85%的準確率和90%的召回率,其F-Score為96.5%[18].相較于Bavota等人的工具,tsDetect更易獲取和驗證,且與Bavota等人的工具有著相仿的精確率與召回率.
2.2 測試異味的性質和影響分析
Palomba等人[19]調查了EvoSuite自動生成的測試代碼,發現自動測試生成工具沒有考慮生成代碼的質量,斷言輪盤和餓漢測試的問題在生成測試代碼中很普遍.
Tahir等人[20]調查了測試異味和類的復雜度、內聚性度量的關系,研究發現復雜性度量,即環路復雜性和加權方法個數,是存在測試異味的強烈信號.
Bavota等人[15]進行了第一次大規模的研究實驗.研究發現,測試異味對測試代碼的可理解性和可維護性會產生負面影響,軟件規模越大,測試異味的影響越嚴重,且敏感恒等和神秘客人的強度同軟件系統的壽命正相關.然而,測試異味對代碼質量影響研究仍不夠充分.Spadini等人[17]發現測試異味中的測試代碼會使關聯生產代碼產生更高的易錯性,但并未論證消除測試代碼異味帶來的影響.
測試異味使生產代碼更易錯,但不當的重構可能事倍功半.由于重構測試代碼異味的價值不明,開發人員通常難以確定是否應該進行重構,這一現狀對測試質量產生長期的負面影響.Hasanain等人[21]發現,愛立信的工業測試代碼中普遍存在代碼拷貝問題,且測試規模越大,代碼拷貝越多.研究還揭示了測試代碼拷貝的生成機理,因為測試代碼規模龐大、邏輯復雜且長期疏于維護,其可理解性極差.與其重構一個測試方法,不如重新實現,然而,重新實現的測試方法無法避免的再一次引入了代碼拷貝問題.因此,明確消除測試異味給代碼質量帶來的收益,是確定測試異味重構價值的必要條件.
3 分析方法和過程
本文分析測試異味消前后測試及生產代碼的缺陷傾向變化,圖1給出了分析過程,包括以下3個步驟:
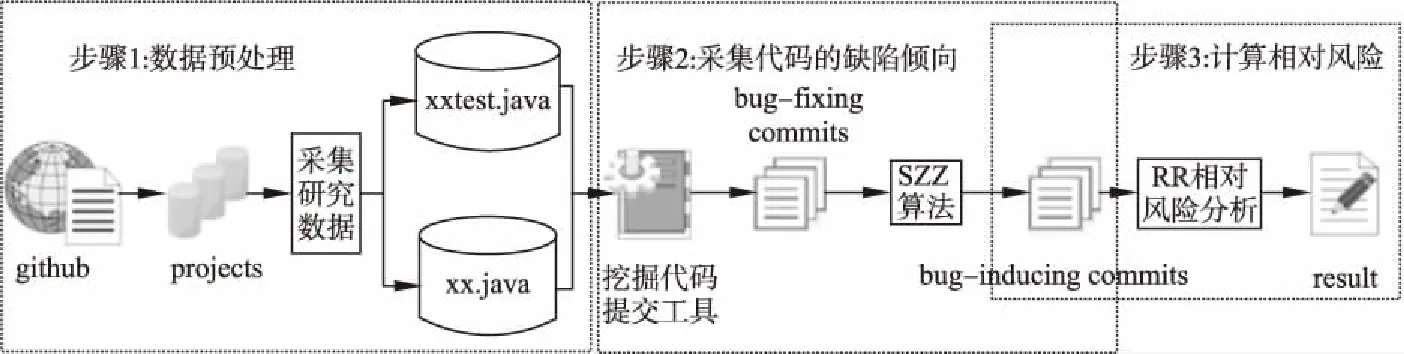
圖1 實驗步驟Fig.1 Experimental steps
1)數據預處理.本文通過挖掘開源項目中各個歷史發布版本的測試代碼,對其中存在測試異味,并在而后的歷史版本中被消除的測試代碼進行收錄,以獲取測試代碼數據集.對測試代碼數據集中的測試代碼,通過測試代碼組件的命名特征,來獲取相關聯的待測生產代碼的數據集;
2)采集代碼的缺陷傾向.將缺陷傾向作為代碼質量的一般度量,使用挖掘項目歷史提交記錄工具采集相關的所有修復bug的代碼提交(bug-fixing commits),并通過SZZ算法來追溯修復bug的代碼提交的源頭,即引入bug的代碼提交;
3)計算相對風險RR.采用相對風險RR指標來分析異味消除前后缺陷傾向的變化情況.
3.1 測試及生產代碼數據預處理
為了獲取研究所需的數據集,本文對采集到的開源數據進行了加工,其過程如圖2所示.
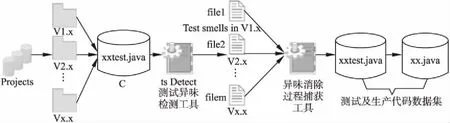
圖2 測試及生產代碼數據預處理過程Fig.2 Test and production code data preprocessing process
收集數據集中涉及異味消除的測試代碼需要3個步驟:
首先,收集項目P中的測試類集合C.根據相關文獻[14,22],當類名以“Test”或“Tests”結尾時,可判定它是測試類.
其次,使用tsDetect檢測C中的異味,對于C中的任意元素ci,可獲得ci在P全部發布版本1至m中的異味分布情況文件集合Fci= {fileci,1,fileci,2,…,fileci,m},其中列出了每個測試類中5種測試異味的分布情況.
最后,本文實現了對測試異味消除過程的捕獲工具.如圖3所示,對于任意的Fci,該工具可對比和記錄fileci,1至fileci,i之間每種異味狀態的變化情況,并收集測試異味被消除時的發布版本號.其工作原理如下:
1)當測試類中的其中一種異味滿足:在{fileci,1,fileci,2,…,fileci,n}中的該種異味狀態為“true”,而在 {fileci,n+1,fileci,n+2,…,fileci,m}中為“false”時,分別分析其他4種異味的分布變化情況;
2)若其他四種異味在{fileci,1,fileci,2,…,fileci,m}中異味狀態全為“true”或全為“false”,則記錄該異味類型和fileci,n+1對應的發布版本號.
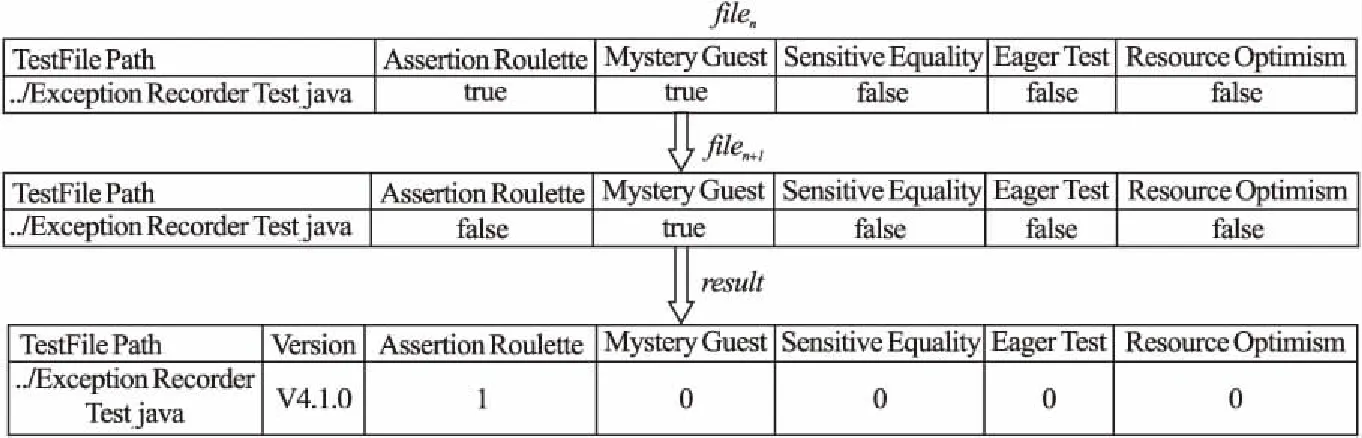
圖3 測試異味消除過程捕獲工具的輸出示例Fig.3 Output example of test smell elimination process capture tool
對于涉及異味消除的測試代碼,本文利用一種基于約定俗成的命名方式追溯生產代碼,以獲取與測試代碼對應的生產代碼數據集,即通過從JUnit測試類的類名中刪除字符串“Test”或“Tests”來識別被測試的生產代碼類.Van Rompaey和Demeyer[23]證明該技術與其他可跟蹤性方式(例如,基于切片的方式[24])相比,其準確性和可伸縮性最優.
3.2 計算缺陷傾向
缺陷傾向的量化基于SZZ算法的.缺陷傾向又稱易錯性,文件的缺陷傾向是指文件在兩個版本之間的引入bug的代碼提交.對于系統的發布版本集合R= {r1,r2,…,rj}中的任意發布版本rv,計算發布版本rv下某個文件的缺陷傾向,是在rv的上一個修訂版本至rv之間進行的,這是因為對于修復文件bug的代碼變更提交,旨在修復rv與rv之后的修訂版間的bug,而其中的bug是在rv之前引入的.
SZZ算法[25,26]是由Sliwerski、Zimmermann和Zeller提出的,用以追溯引入bug的代碼提交的方法,它依賴于版本控制系統的追溯指令annotate或blame指令[26],追溯指令可以查詢文件的作者、修訂信息、相關URL和歷史修改記錄,這些信息會以注釋的形式展示在對應的文件中.SZZ算法計算類缺陷傾向的思路是:根據代碼發生bug時版本控制系統對bug所在類的變更記錄,估計bug被引入的時刻.
如圖4所示,SZZ的運行原理可以理解為四個步驟:
1)提取更改記錄,以查找修復bug提交的變更信息;
2)對比修改前后版本代碼差異,并精確定位涉及的源代碼行;
3)追溯修改后的代碼的上一個修訂版本代碼提交信息及版本號;
4)輸出代碼提交的ID列表.
對于發布版本rv下的任意bugB,識別修復B的代碼提交,以確定修復操作所涉及到的類集合Cfixed= {c1,c2,…,ck}以及類中變更的源代碼行位置集合linecj= {l1,l2,…,li},SZZ算法的工作原理如下:
算法1.SZZ(Sliwerski、Zimmermann and Zeller)算法
輸入:發布版本rj下任意的B
輸出:引發B的n個代碼變更提交
Step 1.對于修復B的代碼變更提交,令發生該操作的修訂版為rv,提取涉及到的類集合Cfixed.
Step 2.對于其中任意一個類cj,修復B時涉及到cj的源代碼行變更集合linecj,通過annotate或blame指令操作標識類中每行代碼最后一次更改發生的時間,找到linecj中每個元素lnum對應的上一個修訂版本rlnum.
Step 3.將rlnum至rv間的所有代碼提交標記為引入bug的代碼提交.
Step 4.使用island語法分析器[27]捕獲空白行和只包含注釋的行,輸出引入bug的代碼提交列表和數量n.
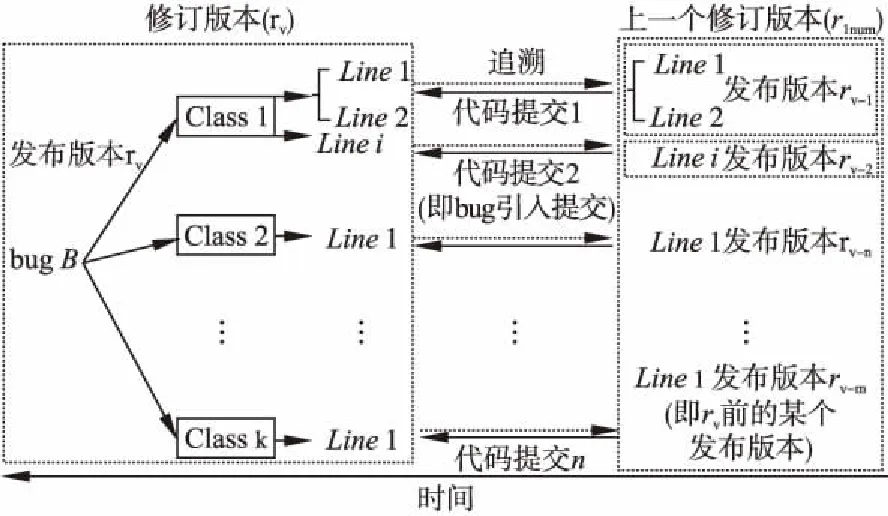
圖4 SZZ算法獲取缺陷傾向工作原理Fig.4 SZZ algorithm obtains the working principleof defect-prone
至此,SZZ算法可以找到引發B的,所有引入bug的代碼提交的相關信息,例如代碼提交的ID列表及個數.針對rv中所有修復bug的代碼提交修復了的bugbugfixed= {bug1,bug2,…,bugb}.
rv缺陷傾向的計算方式為:對于bugfixed中的每一個bug,SZZ算法所獲得的代碼提交ID個數的總和.
版本rv下cj缺陷傾向計算方式為:對于bugfixed中的每一個bug涉及到cj的所有引入bug的代碼提交個數總和.
3.3 相對風險RR
相對風險是暴露組發生概率與非暴露組發生概率的比值,即一個群體暴露在一定風險下,與未暴露在該風險下某事件的比值.在本文中暴露組是測試異味消除前代碼存在缺陷傾向,非暴露組是測試異味消除后代碼存在缺陷傾向.RR常被用于前瞻性研究,本文用它衡量測試異味消除前相較于消除后,代碼具有更多或更少的缺陷傾向可能性.相對風險RR的計算公式如(1)所示:
(1)
當相對風險RR等于1時,在兩個樣本中,事件發生的可能性相同.RR大于1時,第一個樣本中更有可能發生該事件,例如:測試異味消除前,代碼有缺陷傾向.RR小于1時,第二個樣本中更有可能發生該事件,例如:測試異味消除后,代碼有缺陷傾向.本文采用該方法分析異味消除前后代碼發生缺陷情況原因有:1)統計領域報告的結果顯示,在進行大規模實證性研究時,這種方法應該是首選[28,29];2)RR相對風險分析等同于優勢比分析[30],且可解釋性更高[17].
4 實驗設計
4.1 實驗環境和數據集
實驗在Windows 10和Java 8環境下進行.對于tsDetect[18]的有效性,tsDetect工具的開發團隊進行了一次大規模的手工驗證,在此期間,他們在656個開源Android應用程序中,隨機選擇測試文件及其相應的生產文件,并邀請了羅切斯特理工學院軟件工程系的39名研究生和本科生,來手動檢查選出的文件文件是否存在測試氣味.所有參與者都是自愿參加的,并且熟悉Java編程,和單元測試.這些參與者在Java開發方面的經驗從2到11年不等,其中包括開發單元測試的經驗,以此驗證了tsDetect能正確識別測試代碼異味.
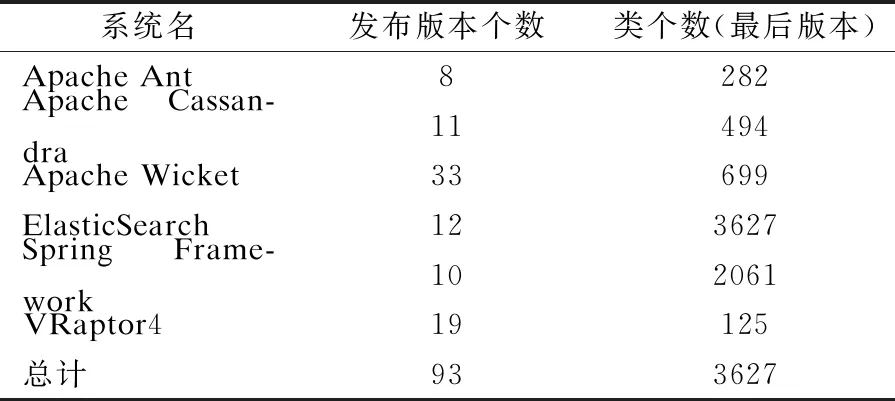
表2 實驗數據集Table 2 Experiment dataset
如表2所示,本文參考文獻[17],選擇了其中的6個規模不同的開源軟件系統作為測試數據集,所有版本中都有大量的JUnit測試用例.考慮到次要發布版本(Minor Releases)之間的變更不顯著且過于頻繁,本文只考慮每個系統主要發布版本(Major Releases).
4.2 問題設計
本文挖掘測試代碼中的異味,對比異味在消除前后,測試代碼以及受測的生產代碼的缺陷傾向的變化,并根據結果評估測試異味消除后多大程度的影響軟件的代碼質量.實驗回答以下3個研究問題:
RQ1:測試異味消除前后,測試代碼的缺陷傾向呈現何種變化?
RQ2:測試異味消除前后,生產代碼的缺陷傾向呈現何種變化?
RQ3:是否存在影響實驗效度的因素?
4.3 實驗過程
1)首先對開源數據進行預處理,獲取所有待研究的測試類,并將這些測試類作為測試異味檢查工具的輸入數據.
2)對于每個測試類,使用靜態分析工具tsDetect檢測每個發布版本中測試代碼的測試異味,并采用測試異味消除過程捕獲工具,收集在版本迭代中測試異味被消除的測試代碼,并通過命名跟蹤技術,找到關聯的生產代碼的類,作為生產代碼數據集.
3)按照5種測試異味類型,對所有的數據集進行歸類,將其分為5組.
4)確定測試異味被消除的版本,使用SZZ算法計算該版本前后,所有主要發布版本的測試及生產類的缺陷傾向.本文復現了SZZ算法,根據Fischer等人[31]的方法確定提交是否修復了缺陷,該方法基于版本控制系統在代碼提交時記錄的消息進行分析.如果提交消息與問題跟蹤器中存在的問題ID匹配,或當它包含“bug”,“fix”或“defect”等關鍵字時,將其視為錯誤修復提交.為獲取錯誤修復提交,本文使用RepoDriller[32]挖掘所有的代碼提交.RepoDriller是一個用來幫助研究人員挖掘軟件代碼倉庫以做研究的Java框架.一旦通過RepoDriller獲取到所有涉及的修復bug的代碼提交,SZZ算法將通過Git的blame特性記錄所有可能的引入bug的代碼提交.
5)最后根據SZZ量化的缺陷傾向,計算出測試異味消除前后,代碼有缺陷傾相對風險RR指數,通過分析該指數,得出了消除測試異味對代碼質量的影響.
4.4 實驗分析及結果
RQ1:測試異味消除前后,測試代碼的缺陷傾向呈現何種變化?
為了回答RQ1,本文從3個角度分析缺陷傾向呈現何種變化,即:1)整體變化的趨勢;2)測試異味消除后,測試代碼存在缺陷傾向的可能性變化多少;3)消除不同種類的測試異味對測試代碼缺陷傾向的影響,分別對應圖5、表3和圖6.
圖5展示了測試異味消除前后,測試代碼缺陷傾向數量分布的對比.觀察圖5的箱線圖,可以看到,相較消除之前,消除異味之后測試代碼含有的缺陷傾向數量顯著減少.箱線圖中也出現了幾個異常值,如異味消除前一個測試類最多含有27個缺陷傾向,消除之后最多也是27個,這個結果是由于測試異味的特性所導致的.例如:斷言輪盤包括不止一種斷言用來檢查不同的行為,餓漢測試需要調用生產對象的多個方法,它們所涉及的文件多消除這些異味往往變更量大,所以統計含有這些異味的測試代碼的缺陷傾向數量時可能出現異常大的值.這些異味特性的本質使得它們難以被開發人員所理解,進而導致開發人員更容易引入缺陷.

圖5 測試異味消除前后測試代碼的缺陷傾向數量分布對比Fig.5 Number distribution of defect-proneness in test code before and after test smell removal
表3中統計了180條測試異味被消除的記錄,其中暴露組(測試異味消除前)生產代碼存在缺陷傾向概率為81%,非暴露組(測試異味消除后)生產代碼存在缺陷傾向概率為36%,RR值為2.26,即消除測試異味之后,測試代碼有缺陷傾向的可能性較消除之前減少126%.

表3 測試異味消除前后測試代碼有缺陷傾向的相對風險Table 3 Test smell elimination before and after the test code with defect-prone′RR
圖6展示了按消除異味的種類分成5組的實驗數據,從圖中觀察的結果可知測試異味消除后,測試代碼的缺陷傾向都趨向減少,表明消除測試異味對測試代碼的質量起到提升的作用.其中,敏感恒等(Sensitive Equality)的變化趨勢非常明顯,造成這一現象的原因可能是數據集中軟件壽命較長.Bavota等人[15]研究發現敏感恒等的強度同軟件系統的壽命呈正相關,本文數據集中軟件系統的最早版本發布時間可追溯到10至20年前.在這類系統中,一旦該異味被消除,異味消除前后,缺陷傾向的變化會很大.
利用和RQ1類似的方法,回答RQ2:測試異味消除后,生產代碼的缺陷傾向呈現何種變化?
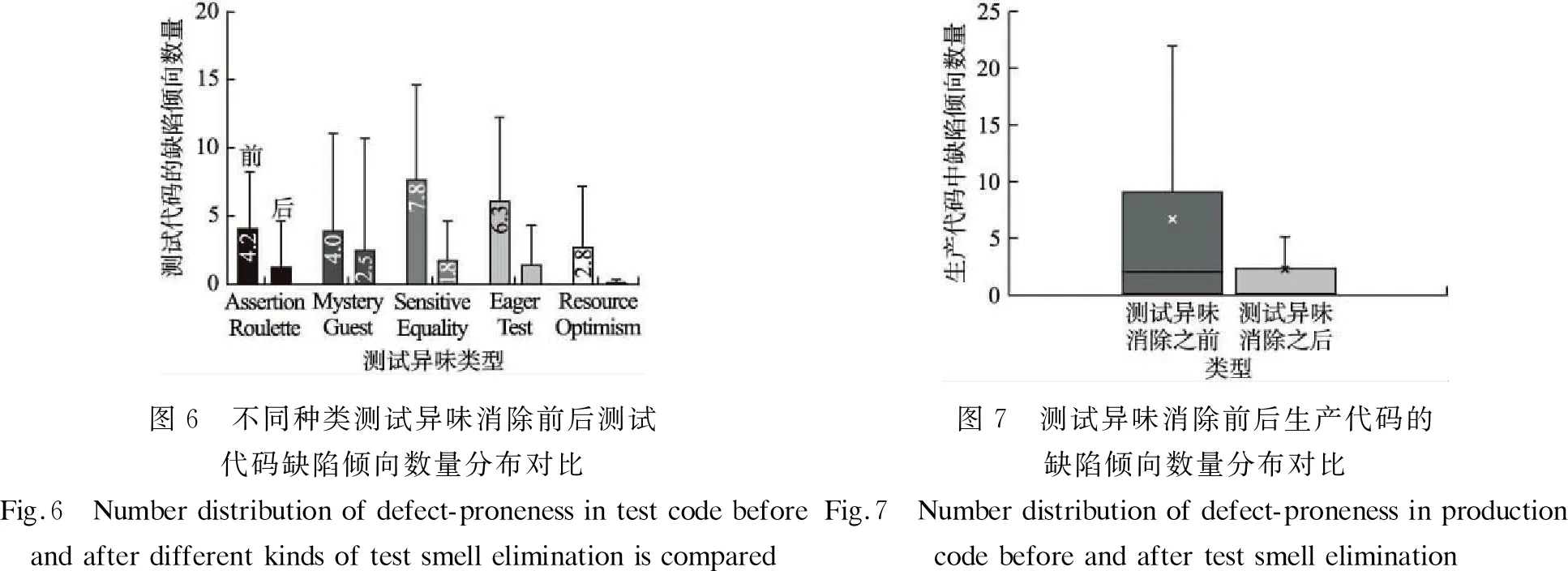
圖6 不同種類測試異味消除前后測試代碼缺陷傾向數量分布對比圖7 測試異味消除前后生產代碼的缺陷傾向數量分布對比Fig.6 Number distribution of defect-proneness in test code beforeand after different kinds of test smell elimination is comparedFig.7 Number distribution of defect-proneness in production code before and after test smell elimination
如圖7的箱線圖,易見測試異味消除前后,生產代碼中的缺陷傾向數量下降,表明相較于測試異味消除后,生產代碼質量得到了一定的提升.
據表4,測試異味消除前后生產代碼有缺陷傾的相對風險RR值為1.59,表明消除測試異味使生產代碼有缺陷的概率降低了59%.

表4 測試異味消除前后生產代碼有缺陷傾向的相對風險Table 4 Test smell elimination before and after the production code with defect-prone′RR
圖8描述了5組實驗數據集的生產代碼中缺陷傾向數的分布情況.5種測試異味消除后,生產代碼的整體缺陷傾向數量都趨向于減少.相較于其它4種測試異味,餓漢測試的減少趨勢最為顯著.餓漢測試被消除后,生產代碼缺陷傾向的平均值從7.8降低至2.4,減少了69.2%.餓漢測試的存在,可能是待測生產代碼質量降低的重要原因.
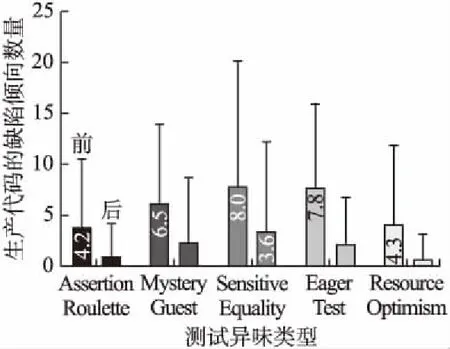
圖8 不同種類測試異味消除前后生產代碼缺陷傾向數量分布對比Fig.8 Number distribution of defect-proneness in production code before and after different kinds of test smell elimination is compared
4.5 影響實驗效度的因素
對于RQ3,影響實驗效度的因素有以下幾點:
1)不同規模的軟件系統、不同開發團隊的代碼風格和開發習慣,可能造成測試異味分布不均影響結論的數值.
2)本文的結論基于測試異味檢測工具的準確程度,檢測工具的質量可能影響實驗效度.為了獲得有關測試異味的信息,本文使用tsDetect測試異味檢測器.盡管此工具精確率能達到85%以上,且召回率在90%以上,非常之高,但數據集中仍然可能存在一些誤報.
3)Fischer等人[31]提出的確定提交是否修復了bug的方法,它基于版本控制系統在代碼提交時記錄的消息進行分析.這種方法在過去被廣泛用于識別bug修復[34,35],其精確率接近80%[31,33,35],Spadini等人[17]在實現SZZ算法時使用的是該方法,并認為對于實現SZZ算法這種技術足夠準確,因此本文也采用了相同的技術.
4)另一個威脅在于基于命名約定的可追溯性技術,該方法通過測試代碼檢測相關聯的生產代碼,但這種關聯方式,可能因為開發人員缺乏經驗或人為錯誤導致結果的不準確.這種技術在相關研究中被大量采用[13,14,22].Van Rompaey和Demeyer[23]也對該技術進行了評估,結果報告平均精度為100%,召回率為70%.
5)本文僅討論了Java項目的測試異味,對于其它使用弱類型系統的動態語言,例如JavaScript,其測試異味與代碼質量的關系可能具備不同性質.
5 總結及展望
軟件測試代碼的重要性經常被忽視,明確測試異味對代碼質量的影響,可以降低軟件重構和維護的成本,并提升軟件代碼質量.本文使用SZZ算法量化測試及生產代碼的缺陷傾向,并利用RR相對風險計算測試異味消除前后測試及生產代碼存在缺陷傾向的可能性,以分析消除測試異味對軟件代碼質量的影響.本文通過實驗研究得出以下結論:
1)消除測試異味能使測試代碼的質量得到顯著的提升.在測異味消除之后,測試代碼存在缺陷傾向的可能性較之前減少約一倍(126%);
2)消除測試異味,能提升生產代碼的質量.消除測試異味后,生產代碼存在缺陷傾向的概率較之前少59%;
3)相較于其他4種測試異味,重構餓漢測試對生產代碼質量的提升更大.
后續工作有三個方向.其一,本文的研究基于Java項目開展,可以基于其他編程語言的開源項目進行研究;其二,本文的研究粒度限制在類級別,可以進一步細化到方法級別,以探究開發人員是在方法級別進行編碼的情況;其三,因為測試異味的生命周期很長,項目中消除測試異味的數據較少,可以進一步對各種不同規模的開源項目開展研究.
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
中國化肥信息(2020年7期)2020-03-19 01:54:02
中國生殖健康(2019年2期)2019-08-23 08:12:08
中國軍轉民(2017年6期)2018-01-31 02:22:28
產品可靠性報告(2017年7期)2017-09-05 09:49:12
汽車觀察(2016年3期)2016-02-28 13:16:26
汽車零部件(2014年11期)2014-09-18 11:57:16
機械制造文摘(焊接分冊)(2014年5期)2014-03-20 13:57:44
