基于英語樞軸的漢-越雙語詞典構建方法
2020-12-10 10:05:32陳亞豪張亞飛余正濤文永華朱俊國
小型微型計算機系統 2020年11期
關鍵詞:方法
陳亞豪,張亞飛,2,余正濤,2,文永華,朱俊國,2
1(昆明理工大學 信息工程與自動化學院,昆明 650500) 2(昆明理工大學 云南省人工智能重點實驗室,昆明 650500)
1 引 言
隨著經濟全球化的深入及我國“一帶一路”合作倡議的提出,中國與越南之間的交流日益頻繁,對兩國的語言處理產生了迫切的實際需求.漢-越雙語詞典是實現漢語和越南語之間信息檢索、機器翻譯等自然語言處理(Natural Language Processing,NLP)任務的重要雙語資源,雙語詞典的質量對漢語與越南語的語言處理任務具有重要的影響[1].因此,對漢-越雙語詞典進行研究具有較大的價值.然而,針對漢-越雙語詞典構建的研究較少,且現有方法的詞典構建效果有待提高.
近年來,國內外學者對雙語詞典的構建方法進行了大量研究.按照語料庫資源的不同主要分為四類:基于平行語料庫的方法、基于可比語料的方法、基于種子詞典的方法、基于對抗網絡的方法.
第一類為基于平行語料庫的方法.該類方法以平行語料作為語料資源,利用語料中的文檔對齊信息來進行雙語詞典提取.莫媛媛等人[1]、Gouws等人[2]及Luong等人[3]提出使用大型平行語料進行雙語詞典的抽取.由于平行語料中包含有高質量的對齊信息,因此基于平行語料構建雙語詞典的效果較好.但是,基于平行語料的方法通常只適用于大語種的部分領域,而小語種的平行語料非常稀缺甚至不存在,采用這類方法難以構建小語種雙語詞典[4].因此基于平行語料庫的雙語詞典構建方法在實際應用中具有較大的局限性.
第二類為基于可比語料的方法.李艦等人[5]和Mogadala等人[6]提出基于可比語料來構建雙語詞典的方法.可比語料中含有大量交叉并非嚴格的互譯信息,這些互譯詞語基本出現在語義相近但語言不同的上下文環境中,可在一定程度上緩解對平行語料的依賴,但針對低資源語言可比語料同樣非常稀缺.
第三類為基于種子詞典的方法.該方法通過大量單語語料來學習語言結構,并且使用少量的種子詞典來學習映射關系,基于映射關系抽取雙語詞典[7-10].Mikolov等人[7]、Wick等人[8]通過大量單語語料來學習語言結構,并使用少量的種子詞典來學習映射關系,提出了基于映射關系抽取雙語詞典的方法.Artetxe等人[9]提出了迭代自學習的方法從對齊數字的并行詞匯表開始,逐級對齊嵌入空間.Cao等人[10]提出了一種分布模型,其利用單語數據學習雙語詞嵌入,將學習得到的雙語詞嵌入在共享向量空間中對齊,將每個單詞與其對應翻譯進行組合,以此實現雙語詞典的構建.基于種子詞典的方法需要較為成熟的雙語詞典作為種子詞典,但是由于受到小語種雙語詞典規模和質量的限制,性能還有很大的提升空間.
第四類為基于對抗網絡的方法.Zhang等人[11]提出通過對抗網絡對齊跨語言的詞向量空間,同時提出了一種基于EMD(Earth Mover’s Distance)抽取雙語詞典的方法.而Alexis等人[12]在Zhang等人的基礎上改進了對抗網絡,并解決了hubness問題.由于兩種語言的單語詞向量空間表現出近似的同態性,存在線性映射能夠近似地連接這兩個空間,通過對抗網絡來學習該映射關系,然后基于該映射關系抽取詞典.同時提出了一個與詞翻譯準確性高度相關的無監督模型選擇標準.該方法在有同源詞的語言中表現良好,但是,由于漢語和越南語之間的語言差異性較大,直接通過對抗網絡構建漢-越雙語詞典效果有待提高.
另外,相關學者提出基于樞軸語言進行雙語詞典構建的方法.吳華和王海峰提出了基于樞軸語言的詞翻譯模型[13],在源語言和目標語言雙語資源有限的情況下,該模型通過源語言-樞軸語言和樞軸語言-目標語言來對齊雙語語料,最終構建出源語言到目標語言的詞對齊模型.該模型仍需要源語言-目標語言的雙語詞典作為監督信號,且該監督信號決定了誘導模型的好壞,即決定了最終的詞典抽取質量.之后他們利用基于規則的機器翻譯方法對基于樞軸的短語翻譯模型進行了優化[14],提出了三種基于樞軸的詞翻譯模型.第一種為三角剖分法,它在源-樞軸和樞軸-目標翻譯模型中乘相應的翻譯概率和詞法權重,以得出新的源-目標短語表.第二種為轉移法,利用翻譯模型將源語言翻譯成樞軸語言最后再翻譯成目標語言來獲得源語言到目標語言的句子,并且利用規則機器翻譯的方法填補源語言到樞軸語言的數據空白.第三種為合成法,使用現有模型合成源語言到目標語言的可比語料.這三種方法都需要大量的監督信號及翻譯性能較好的模型,且在翻譯傳遞過程中易產生錯誤累積,導致最終的詞典抽取結果不準確.
綜上所述,針對漢-越雙語詞典的構建任務而言,漢-越平行語料稀缺且獲取成本高昂,使得采用基于平行語料的方法難以得到較高的詞典準確率.同時,基于種子詞典的方法受限于低資源語言漢-越種子詞典的規模及質量,其模型容易陷入局部最優,使得構建效果不太理想.基于對抗網路的方法在兩種語言的差異性較小時,由其構建的雙語詞典準確率較高,但在語言差異性較大時詞典準確率不高.基于樞軸的方法通常用于加強源語言到目標語言的對齊關系,再結合其他模型構建源語言和目標語言的詞典.相關學者的研究表明了基于樞軸語言的可行性.
受到對抗網絡和樞軸思想[11,14]的啟發,同時考慮到漢語、英語、越南語單語語料比較豐富且具有漢-英、越-英雙語詞典,本文提出了一種基于英語樞軸的漢-越雙語詞典構建方法.該方法首先以英語作為樞軸語言,引入漢-英詞典和越-英詞典作為樞軸模型的弱監督信號,將漢語和越南語詞向量均映射到英語詞向量共享空間以減小漢語和越南語的語言差異性.然后將漢-英詞向量和越-英詞向量的映射建模為一個對抗游戲,通過平衡對抗網絡學習漢-越的映射矩陣.最后通過相關抽取策略構建漢-越雙語詞典.本文將漢-英、越-英詞典作為弱監督信號,避免了方法對平行語料的依賴.而且方法采用對抗網絡模型,不需要任何漢-越監督信號.實驗結果表明與現有方法相比本文方法明顯地提升了漢-越雙語詞典的準確率.
2 基于英語樞軸的漢-越雙語詞典構建方法
目前自動構建漢-越詞典的研究相對較少,大多方法需要平行語料或可比語料等監督信息的參與,費時且成本較高,且現有無監督模型對語言差異性較大的語言構建效果不佳[1,11].同時考慮到互聯網中存在豐富的漢語、英語、越南語的單語語料以及漢-英、英-越雙語詞典.因此,本文提出了一種基于英語樞軸的漢-越雙語詞典的構建方法.首先通過基于種子詞典的方法分別學習漢-英、越-英的映射矩陣Wxz和Wyz,然后在英語詞向量共享空間中通過對抗網絡進一步學習漢-越之間的映射矩陣Wxy,最后通過NN/CSLS方法[15]抽取漢-越詞典.
基于英語樞軸的漢-越雙語詞典構建方法的基本思路可分為以下四個步驟:首先,分別對源語言、目標語言及中間語言的語料進行預處理;然后將這些已經處理好的語料分別表示為詞向量;其次,以種子詞典作為弱監督信號,并利用基于種子詞典的方法分別學習漢-英及越-英的關系矩陣;最后,利用對抗網絡進一步學習漢-越的映射矩陣,并通過不同抽取詞典策略抽取詞典.該構建方法的具體流程圖如圖1所示.

圖1 基于英語樞軸的漢-越雙語詞典構建方法Fig.1 Construction method of Chinese-Vietnamese dictionary based on English pivot language
在圖1中,在本文方法中源語言為漢語,目標語言為越南語,中間語言為英語.方法的具體步驟及分析如下:
1)對源語言、目標語言及中間語言的語料進行預處理.首先分別去掉漢語、越南語及英語的語料中無用的標點符號,然后分別下載這三種語言的停用詞表以去掉停用詞,最后對漢、越、英語料進行分詞操作,將中文句子通過結巴分詞工具做分詞處理,將越南語句子和英語句子通過空格切分.最終得到預處理之后的漢語、越南語和英語的句子,并且統計詞頻與單詞數.其中,n為源語言的單詞數,m為目標語言的單詞數,u為中間語言的單詞數.{xi|i=1,2,…,n}為源語言單詞集合,{yj|j=1,2,…,m}為目標語言單詞集合,{zk|k=1,2,…,u}為中間語言單詞集合.
2)通過Fasttext模型[16]分別學習漢語、英語、越南語的詞向量空間,并將漢語、英語、越南語的單詞表示為詞向量v.詞向量維度表示為d,源語言單詞對應的詞向量表示為{vx1,vx2,vx3,…,vxi},其中vxi∈Rd,i∈{1,2,…,n}.中間語言單詞對應的詞向量表示為{vz1,vz2,vz3,…,vzk},其中,vzk∈Rd,k∈{1,2,…,u}.同樣,目標語言單詞對應的詞向量可以表示為{vy1,vy2,vy3,…,vyj},其中,vyj∈Rd,j∈{1,2,…,m}.
3)采用基于種子詞典的方法分別學習漢-英的映射矩陣Wxz及越-英的映射矩陣Wyz.基于種子詞典的雙語詞典構建方法的前提需要源語-目標語言的雙語詞典,然而對于漢語和越南語來說很難獲取現成的漢-越雙語詞典,但漢-英及越-英雙語詞典很豐富且易獲取.因此,我們借鑒樞軸的思想基于種子詞典的方法來分別學習漢-英的映射矩陣Wxz及越-英的映射矩陣Wyz,將其映射到英語詞向量的共享空間中.
獲取5000個漢-英的單詞對{xi,zi}i∈[1,5000]及5000個越-英的單詞對{yi,zi}i∈[1,5000],作為弱監督信號,學習漢-英的線性映射關系矩陣Wxz及越-英的映射關系矩陣Wyz.映射關系矩陣Wxz和Wyz可由同一個模型通過設置不同的參數獲得.該映射關系計算如公式(1)所示.
(1)
其中,d表示詞向量的維度,X和Y是兩個大小為d×n的平行詞典對齊矩陣,包含了平行詞典中單詞的詞向量,W為訓練過程中源語言到目標語言的映射矩陣,大小為d×d,Md(R)表示d×d的實數矩陣.W*表示最小化源語言到目標語言距離的映射矩陣,這里分別對應漢-英的線性映射關系矩陣Wxz及越-英的映射關系矩陣Wyz.
在獲取映射矩陣W后,對于任意一個未翻譯的單詞s,可以通過NN最近鄰搜索方法到源語言對應目標語言的詞翻譯.根據映射后的空間余弦相似度來進行詞對齊.任意源詞s對應的翻譯t定義如公式(2)所示.
t=arg maxtcos(Wxs,yt)
(2)
在此基礎上,通過在映射矩陣W上增加正交約束條件實現了更好的效果.將問題轉化為Procrustes問題,并將YXT進行奇異值分解(SVD)得到一個近似解,具體公式如公式(3)所示.
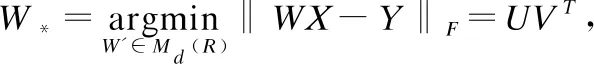
(3)
通過公式(3)可以得到源語言與目標語言距離最小化的漢-英的映射矩陣Wxz以及越-英的映射矩陣Wyz.
4)利用對抗網絡進一步學習漢-越的映射矩陣Wxy.通過上述步驟將漢語及越南語的詞向量均映射到英語詞向量共享空間中,并把漢-英詞向量和越-英詞向量的映射建模為一個對抗游戲,通過平衡對抗網絡最終學習到漢-越的映射矩陣Wxy.
在對抗網絡中假設含有兩個集合,一個集合為χ={Wxzvxi|i=1,2,…,n},表示漢語詞向量映射到英語詞向量空間的n個詞向量的集合,可簡化為χ={xi|i=1,2,…,n}.另一個集合為Ψ={Wyzvyj|j=1,2,…,m},表示目標語言越南語映射到英語詞向量空間的m個目標語言的詞向量的集合,可簡化為Ψ={yj|j=1,2,…,m}.
對抗網絡的模型分為兩個部分,一個是生成器G,另一個是判別器D.判別器負責判別詞向量來自源語言還是目標語言,它的目標是盡可能準確的判別詞向量.生成器負責學習聯系兩個空間的線性映射,它的目標是讓判別器無法判別詞向量是來自源語言還是目標語言.生成器與判別器形成相互對抗的關系,從而提升生成器和判別器的性能.本文的對抗網絡結構如圖2所示.

圖2 對抗網絡的基本結構Fig.2 Basic structure of the adversarial network
在圖2中,將漢-英的詞向量表示為源語言詞向量,將越-英的詞向量表示為目標語言的詞向量.方塊的分布代表源語言的詞分布,圓圈的分布代表目標語言的詞分布.生成器G與判別器D形成相互對抗的關系,訓練判別器來區分隨機采樣的元素是來自集合χ還是集合ψ,最終通過對抗網絡學習得到源語言到目標語言的映射矩陣Wxy.綜上,對抗網絡的目標函數表示為minGmaxDV(D,G)的形式,其中函數V(D,G)表示為公式(4).
V(D,G)=Ey~py[logD(y)]+Ex~px[log(1-D(G(x)))]
(4)
在公式(1)中x是源語言詞向量,px表示源語言詞向量服從的分布,y是目標語言的詞向量,Py表示目標語言詞向量服從的分布.對抗網絡中的判別器目標函數和生成器目標函數分別如公式(5)和公式(6)所示.
logPθD(s=0|yi)
(5)
logPθD(s=1|yi)
(6)
在訓練對抗網絡模型時,對于每一個輸入樣本需最小化判別器和生成器的目標函數,利用梯度下降方法更新各自的網絡參數及映射矩陣W.然而,由于對抗網絡的思想為對齊所有的詞,并沒考慮詞頻的高低,而詞頻低的詞可能出現在不同語料庫的上下文中.在這種情況下,通過對抗網絡學習到的W的性能低于有監督學習性能.為了得到性能更好的映射矩陣W,本文通過由對抗訓練學習到的W來構建合成并行詞匯表,即考慮常用詞的相互最近鄰來確保獲取一個具有較高質量的字典[17].最后通過對映射矩陣W添加正交約束限制進一步提升映射矩陣的質量及訓練的穩定性.本文使用了更新規則來確保訓練過程中映射矩陣W近似正交矩陣,如公式(7)所示.
W←(1+β)W-β(WWT)
(7)
Alexis等人的實驗表明參數β為0.01時具有更好的效果,該更新方法使得每次更新后的矩陣都近似為正交矩陣.通過上述步驟可以獲得一個源語言到目標語言的映射矩陣Wxy.
5)在英語詞向量空間中抽取漢-越雙語詞典.將介紹兩種抽取詞典的方法:NN方法和CSLS方法.NN方法通過計算源語言詞向量乘映射矩陣與目標語言的余弦距離,其計算如公式(2)所示.CSLS方法用于衡量兩個單詞之間(不同語言)的相似度.對每一個單詞,通過CSLS方法可在另一語言中找到其K近鄰,分別將源語言和目標語言用NT(s)和NS(t)表示,并定義源語言詞向量為xs,目標語言詞向量為yt,源語言到目標語言的距離為rT,目標語言到源語言的距離為rS.源語言到目標語言的距離通過公式(8)進行計算.
(8)
同上,用類似的方法計算rS,距離r可衡量每個單詞的hubness.如果只考慮Wxs與yt的余弦關系,會產生hubness問題.為解決該問題,重新定義了CSLS距離如公式(9)所示.
CSLS(s,t)=2cos(Wxs,yt)-rT(Wxs)-rS(yt)
(9)
最后根據上述不同的抽取方法抽取相應的詞向量構成漢-越詞典.
3 實驗結果與分析
3.1 實驗數據
本文實驗語料的獲取主要利用網絡爬蟲技術從相關新聞網站中分別獲取漢語、英語和越南語的單語語料數據,源語言為漢語,樞軸語言為英語,目標語言為越南語.實驗語料的具體規模如表1所示.
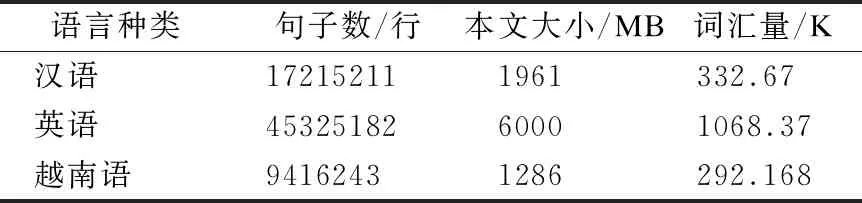
表1 實驗語料規模Table 1 Size of corpus for experiment
為驗證方法的有效性,本文將Alexis等人構建的漢-英詞典和英-越詞典作為驗證詞典.考慮到無法獲取到可用的漢-越驗證詞典,重新構建了漢-越驗證詞典[11].具體步驟如下:第1步構建詞表;第2步,通過一銘翻譯平臺(1)http://dmfy.emindsoft.com.cn/翻譯該詞表,將源語言單詞進行翻譯得到目標單詞的多個候選翻譯;第3步,將所有候選詞逐個翻譯為源語言單詞,若候選詞與源語言單詞相同,則構建的詞典為真實詞典,若不同則舍棄該詞對,進行下一個候選詞的翻譯,重復此步驟直到完成所有候選詞的翻譯;第4步,翻譯完成所有的候選詞后進行下一個源單詞的翻譯,重復第2步與第3步,直到翻譯完所有的詞表.通過上述方法構造的驗證詞典規模如表2所示.
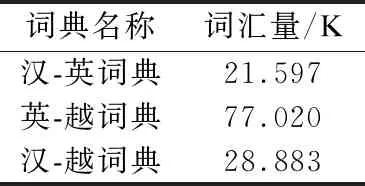
表2 驗證詞典規模Table 2 Size of verification dictionary
本文將準確率P@N(前N個候選翻譯的準確率)作為衡量雙語詞典好壞的評價指標.其中通過隨機抽取驗證詞典的1.5K個源語言單詞和對應的目標詞,RT為抽取結果中單詞的數量,T(wi)為抽取方法在單詞wi上的抽取結果,d(wi)表示單詞wi在詞典中的翻譯集合,具體計算公式(10)所示.
(10)
3.2 實驗結果與分析
在實驗中,利用Fasttext模型將漢語、越南語、英語單詞轉換為300維的詞向量,漢-英、越-英的的映射矩陣分別為Wxz和Wyz,矩陣大小均為300×300,漢-英和越-英的種子詞典分別為5000對.本文使用具有4096個隱藏層的多層感知機作為判別器,其激活函數為Leaky-ReLU.其中,Leaky-ReLU激活函數定義為:當輸入值大于等于0時,輸出值與輸入值一致,當輸入值小于0時,輸出值為輸入值與超參數leak的乘積.在本文中設置超參數leak=0.1,并在判別器預測中加入平滑系數s=0.3.使用隨機梯度下降法對對抗網絡的參數進行更新,批值大小為32,判別器和生成器的學習率均為0.1,衰減率均為0.8,對抗網絡迭代次數100000次,迭代輪數10輪.每次實驗的無監督驗證標準降低時,學習率減半.本文將基于英語樞軸的漢-越雙語詞典構建方法記為EPAN.
為了驗證樞軸語言的規模對本文方法準確率的影響,設置了該方法在不同英語語料規模下的實驗,實驗結果如圖3所示.

圖3 本文方法在不同樞軸語料規模下的準確率Fig.3 Accuracy of the method in this paper at different pivotal corpus sizes
由圖3可知,當將英語作為樞軸語言時,隨著英語語料規模的增加,漢-越雙語詞典在P@1的準確率先上升后趨于平緩.當其規模為5000MB時本文方法的準確率曲線逐漸平滑,因此,后續實驗將樞軸語料規模均設為5000MB.
接下來實驗將本文方法與基于種子詞典方法及基于對抗網絡的方法進行對比,進一步驗證本文方法的有效性.分別記錄每組實驗在P@1(即抽取1個候選詞)時的準確率,實驗結果如表3所示.
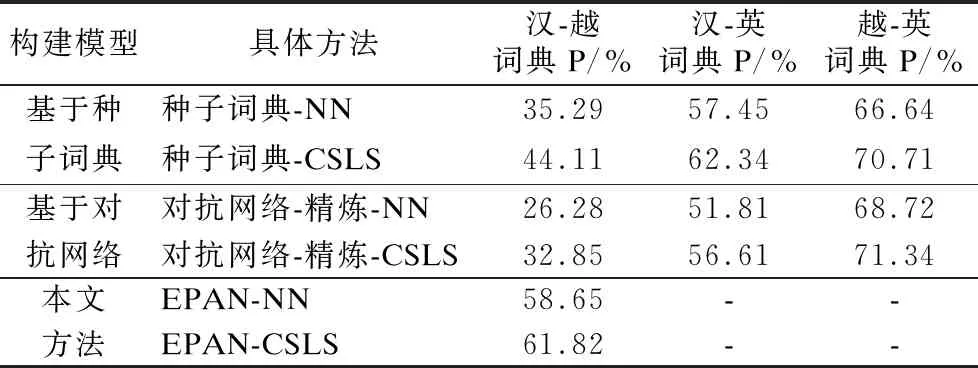
表3 本文方法與傳統方法構建雙語詞典的準確率Table 3 Accuracy of our method and traditional methods in constructing bilingual dictionaries
分析表3的實驗數據可知,基于對抗網絡的方法效果接近甚至優于基于種子詞典的方法的效果,驗證了本文無監督模型選擇標準的有效性.另外,直接采用基于種子詞典的方法和基于對抗網絡的方法構建漢-越雙語詞典的準確率較低,而本文方法下的兩種抽取方法得到的漢-越詞典準確率明顯提高.該結果表明本文結合樞軸語言和對抗網絡的方法有效提高了漢-越雙語詞典的準確率.
為驗證方法的準確率與抽取的候選詞個數之間的關系,得到漢-越詞向量在英語樞軸共享空間中的具體映射情況,實驗還比較了P@1、P@5和P@10的準確率.具體實驗結果如表4所示.

表4 本文方法在不同P@N值下的準確率Table 4 Accuracy of the method in different P@N values
分析表4可知,本文方法的準確率均隨候選詞的增多而逐漸提高,候選詞數量僅為1時便可獲得較高的準確率,當候選詞達到10個時,最高準確率可以達到80%以上.這進一步說明了不同語言在詞向量空間中的同構性.
最后我們將本文方法與目前較為常用的自動構建雙語詞典的方法進行對比.本文利用Artetxe等人基于種子詞典的迭代自學方法和Alexis等人基于對抗網絡的方法以及莫媛媛等人基于平行語料的方法進行漢-越雙語詞典的構建實驗,并與本文方法進行準確率的對比.實驗選擇在P@1的情況下進行準確率評價,具體實驗結果如表5所示.

表5 不同方法下的漢-越詞典準確率Table 5 Chinese-vietnamese dictio-nary accuracy for different methods
分析表5可知,由本文方法構建的漢-越雙語詞典的準確率明顯優于其它三種方法.本文方法利用少量的漢-英,以及越-英監督信號,便可很好地將漢語、越南語詞向量對齊到英語詞向量空間,在缺少高質量大規模漢-越監督信號時,通過無監督模型選擇標準能夠很好的抽取漢-越詞典.
4 結 論
為了提升自動構建漢-越詞典的準確率,本文提出了一種基于英語樞軸的漢-越詞典構建方法.在使用更少的監督信號以及不使用漢-越雙語詞典的情況下,本文方法能夠有效的提高漢-越詞典的準確率.同時也證明了在構建低資源語言詞典這個任務中借鑒樞軸與對抗網絡的思想可以使漢-越雙語詞典的構建方法具有更好的性能.下一步將繼續研究詞典在無監督神經機器翻譯中的應用.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
