一種粒度融合的新聞文本主題分類模型
2020-12-10 10:05:30楊春霞秦家鵬
小型微型計算機系統 2020年11期
楊春霞,李 銳,秦家鵬
1(南京信息工程大學 自動化學院,南京210044) 2(江蘇省大數據分析技術重點實驗室,南京 210044)
1 引 言
新聞文本的主題分類是當前信息爆炸時代的熱點問題之一,也是自然語言處理的關鍵技術之一.針對每天產生的數以萬計的新聞文本,如何能準確的對產生文本的主題進行分類,在用戶推薦系統等領域中都有著重要作用.
文本分類是自然語言處理最經典的任務場景之一,文本分類首先要對相關文本進行文本處理.傳統的文本處理方法有基于字符串匹配、TF-IDF等方法.隨著近年來深度學習的興起Embedding成了自然語言處理最受歡迎的文本處理方法,目前由谷歌提出的Word2Vec的Word Embedding方法由于能夠較好的體現上下文信息,因此被大量的應用到自然語言任務中.Kim[1]利用CNN在Word2Vec詞向量上進行特征提取,并在多個英文分類任務上進行實驗.黃磊[2]等利用Word2Vec進行詞向量訓練并在大規(guī)模中文新聞分類任務中使用BiLSTM進行文本分類.姜恬靜等[3]使用Word Embedding結合卷積和長短期記憶神經網絡,通過遍歷全文捕獲全局信息對中文文本進行分類.而文本通常由字符組成,許多較為細膩的語義信息被蘊含在字符中,因此近年來自然語言處理中Char Embedding的方法被越來越多的人研究.Santos等[4]提出了一種基于Char Embedding的詞性標注的方法,并證明了Char Embedding可以達到最新水平.Zhang[5]等提出了一種獨立于語言的Char Embedding CNN模型,并在40多種混合語言信息分類任務中得到了較好的效果.Zhu等[6]用Char Embedding結合自注意力機制、卷積神經網絡、門控遞歸單元捕獲相鄰字符和句子的上下文信息,并在多個數據集上進行測試得到較好的效果.
本文結合Word Embedding與Char Embedding提出一種基于字粒度與詞粒度融合的新聞文本主題分類模型.通過字嵌入、詞嵌入將字詞轉換為向量的形式,并將詞中所包含字符的字向量與該詞向量進行融合,構建出既包含字符屬性又包含詞屬性的向量,再將這些向量構建成包含整個新聞文本信息特征的矩陣.然后設計卷積結構從特征矩陣中提取有效信息對新聞文本進行主題分類.由于中文獨特的句法關系,文本中每個字符有其細膩的語義信息.而詞語中也包含了大量的實體信息和更好的上下文信息.因此本文提出粒度融合模型能夠更好的理解中文文本的語義、實體信息,同時兼顧文本上下文信息,從而獲得較好的主題分類結果.
2 相關研究基礎
2.1 新聞文本主題分類
新聞文本主題分類是指通過自然語言處理技術將整篇文章蘊含的主題類型進行分類.其主要過程有文本處理、模型構建、特征提取、分類、結果評估.目前有兩種主流的新聞文本主題分類方法.一是基于BERT[7]、XLNET[8]這種龍骨級模型的方法,這類方法雖然有很好的效果,但由于模型過為復雜,需要非常大的算力和龐大的數據源且模型訓練時間較長,故本文并未選用這種方法.二是基于詞向量設計模型并提取文本特征,根據文本特征對新聞文本主題進行分類,這類方法也能達到非常好的分類效果且無需大量計算資源,故本文選用此類方法.
2.2 Word2Vec
Word2Vec是谷歌提出的一種產生詞向量的模型,其通常分為CBOW與Skip-Gram兩種訓練模型.CBOW是根據某一詞語上下文相關詞向量輸出該詞的詞向量,Skip-Gram是根據某一詞語的詞向量輸出其上下文詞的向量.本文選取CBOW模型作為實驗詞向量訓練模型.其原理如圖1所示.
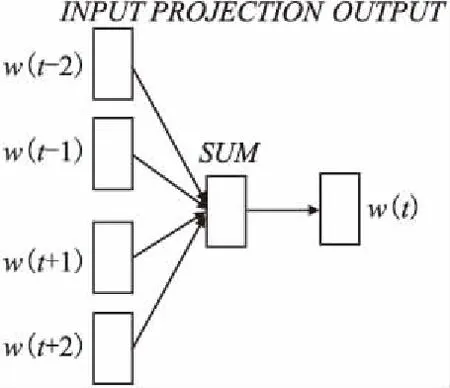
圖1 CBOW模型Fig.1 CBOW model
從圖1中可以看出CBOW模型包括輸入層、投影層和輸出層.CBOW模型根據選定詞w選定一個上下文窗口(圖1所示選定窗口為2),將窗口中上下文詞向量w(t-2)、w(t-1)、w(t+1)、w(t+2)輸入至投影層,這些上下文詞向量會被投影成一個向量,然后將投影層輸出向量輸入softmax分類層,通過softmax預測是否是當前詞w,并將投影向量作為詞w的詞向量.
該模型的學習目標是最大化對數似然函數,計算公式如公式(1)所示.
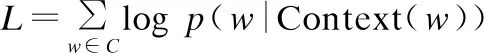
(1)
公式(1)中C是文本庫中所有詞語集合,w是選定詞,Context(w)是選定詞w的上下文詞語,模型通過隨機梯度上升法對詞w的詞向量進行訓練更新.
3 模型實現
為了更好的將文本中細膩的語義信息與上下文信息進行融合,提高新聞文本主題分類準確率,本文提出了一種基于粒度融合的卷積神經網絡模型.其結構包括:詞粒度輸入、字符粒度輸入、字詞融合結構、卷積結構、拼接融合結構、softmax分類層,模型結構如圖2所示.
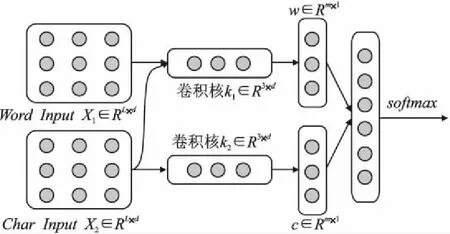
圖2 粒度融合模型Fig.2 Granular fusion model
本文提出的模型主要呈一個流式結構,主要包括了4個部分內容:
1)向量輸入:從圖2中可以看到,向量輸入部分有兩個輸入,其中Word InputX1∈RL×d是詞粒度的向量輸入,Char InputX2∈RL×d,是字符粒度的向量輸入,L是分詞、字后的序列長度,d是嵌入之后詞向量、字向量的深度.
2)字詞粒度融合:本文的字詞粒度融合通過字、詞、字符位置信息進行不同粒度的融合,融合過程如圖3所示.
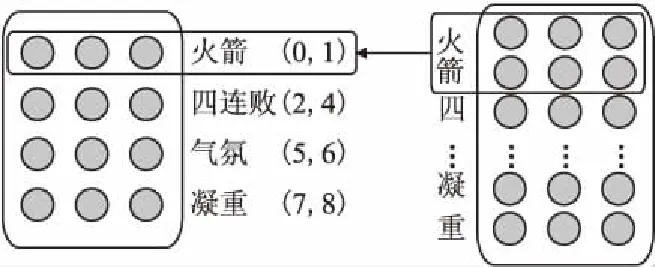
圖3 粒度融合過程Fig.3 Granular fusion process
在圖3中,以“火箭/四連敗/氣氛/凝重”為例,通過jieba分詞并記錄分詞結果中每個詞首末字符在本句話中的位置信息.如圖3中“火箭(0,1)”,其中0代表“火”處于本句話第0個位置,1代表“箭”處于本句話中第1個位置.在融合過程中通過這些位置信息將每個詞包含的所有字符的向量相加,再加上詞向量本身得到融合后的向量.通過不同粒度的向量疊加,這樣輸入的特征矩陣中就能夠包含字、詞兩種粒度屬性的特征,這使得卷積層能夠更好的在特征矩陣中提取到文本中的有效信息.其計算公式如公式(2)、公式(3)、公式(4)所示.
(2)
(3)
(4)
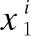
3)卷積特征提取:雖然融合后的向量已經蘊含了許多信息,但由于信息過于冗余我們無法直接使用這些向量進行主題分類.因此本文使用k∈R3×d大小的卷積進行窗口滑動提取特征,以去除冗余信息并獲得一定的上下文信息與語義信息.為了得到多個卷積結果以進一步提升主題分類的準確率,我們同時對字符輸入矩陣與融合后的詞輸入矩陣進行卷積,這樣會在提取特征后得到兩個相應的特征向量.計算公式如公式(5)、公式(6)所示.
w=Convk1(W1,X1)+b1
(5)
c=Convk2(W2,X2)+b2
(6)
公式(5)、公式(6)中Conv是卷積運算函數,k1、k2分別是詞輸入矩陣與字符輸入矩陣的卷積核代稱,W1、W2為卷積權重矩陣,b1、b2為偏置項.卷積后得到字符粒度與詞粒度的特征向量,w∈Rm×1、c∈Rm×1是卷積后大小為m×1包含新聞文本特征的向量.
4)分類器:模型的最后將經過卷積提取的詞粒度與字符粒度特征向量拼接融合形成拼接向量,再將該向量經由一個全連接層壓縮至主題類別個數相同維度,然后使用softmax對文本的主題進行分類,softmax具體計算公式如公式(7)所示.
(7)
公式(7)中Si為第i個主題類別的概率得分,mi為模型輸出向量第i維的值.分類器輸出維度與主題類別個數相同的概率向量,每一個維度對應一個主題類別,我們將分類器所得最大概率維度對應的主題類別認定為分類主題結果.
4 實 驗
4.1 實驗數據與實驗平臺
本文使用了2個公開數據集對提出的字詞粒度融合模型進行性能測試,包括THUCNews新聞文本數據集、搜狗新聞數據集.
THUCNews新聞文本數據集是由清華大學公開的大規(guī)模新聞文本數據集,THUCNews是根據新浪新聞RSS訂閱頻道2005-2011年間的歷史數據篩選過濾生成,包含74萬篇新聞文檔,共有14個新聞類別.本文選用其中10個類別的樣本分別為:體育、財經、房產、家居、教育、科技、時尚、時政、游戲、娛樂.每個類別都選取5000條訓練樣本,500條驗證樣本,1000條測試樣本.

表1 實驗平臺設置Table 1 Experimental platform settings
搜狗新聞數據集是由Sogou Lab提供的國內、國際2012年6月-7月期間體育,社會,娛樂等18個頻道的新聞數據.本文選用其中9個類別樣本分別為:娛樂、房地產、旅游、科技、體育、健康、教育、汽車、文化.每個類別都選取2500條訓練樣本,500條測試樣本.
本文實驗環(huán)境配置如表1所示.
4.2 模型超參數設置與模型復雜性分析
本文采用Adam作為模型優(yōu)化器,使用mini-Batch進行批量訓練.模型主要超參數如表2所示.
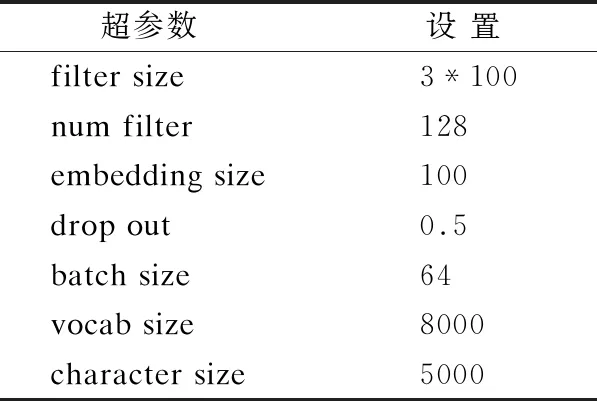
表2 超參數設置Table 2 Hyperparameter setting
本文模型總參數個數為1.42M,與BERT(110M、340M)等復雜的模型參數量相比非常精簡.本文模型在GTX1080ti的GPU上每批次的訓練時間為0.042s,在運行時間上也有著一定的優(yōu)勢.本文模型總復雜性較低,算力要求適中,在復雜性上具有很好的優(yōu)勢.
4.3 實驗結果與分析
為了驗證本文提出的基于粒度融合模型的有效性,本文選擇了多個經典模型與多個目前在THUCNews新聞文本數據集、搜狗新聞數據集上效果較好的先進模型進行對比.對比模型包括:單層CNN、單層LSTM、單層NLSTM、CNN+NLSTM、Attention LSTM[9]、Attention BiLSTM[10]、BiLSTM+max-pooling[11]、Attention+CNLSTM[12].測試實驗對比結果如表3所示.

表3 不同模型的分類結果Table 3 Classification results of different models
從表3中可以看到,本文提出的模型在兩個數據集上都能夠得到較為領先的準確率.從CNN與本文模型對比可以看出,本文模型在使用了粒度融合后能夠大幅度的提升模型的準確率.同時本文提出的字、詞粒度融合模型通過與Attention BiLSTM、Attention+CNLSTM等最新模型的對比結果可以看出,不同粒度的融合確實能夠更有效的提取出文本中的有效信息.
本文將THUCNews新聞文本數據集每個主題類別測試實驗中的3個評價指標:精確率(precision)、recall值、f1-score分別輸出,3個評價指標的結果如表4所示.
從表4中可以看出除家居主題類新聞外其余主題類別的3項評價指標均高于0.95,且各個類別的3項指標都達到了相當高的水平.
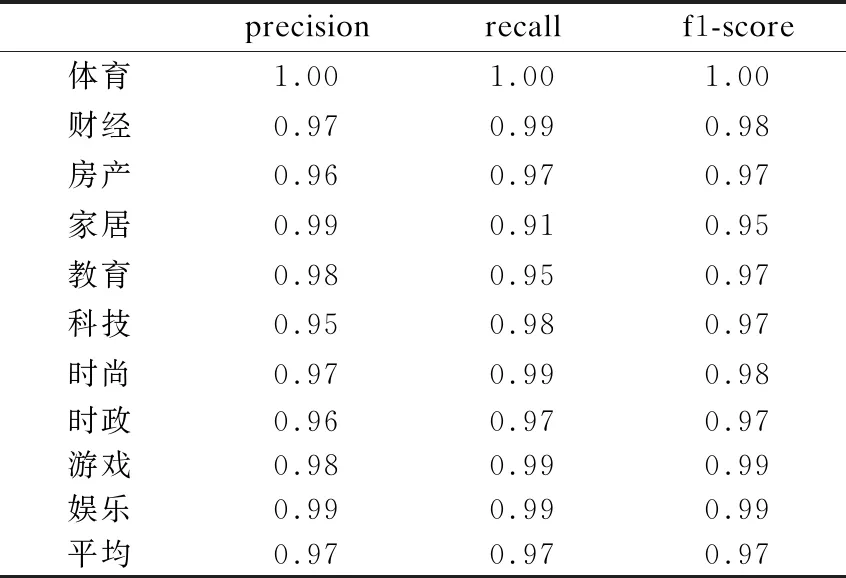
表4 各類別3項評價指標Table 4 Three evaluation indicators for each category
本文將THUCNews新聞文本數據集10個主題類別的分類測試結果的混淆矩陣進行統計,結果如表5所示.
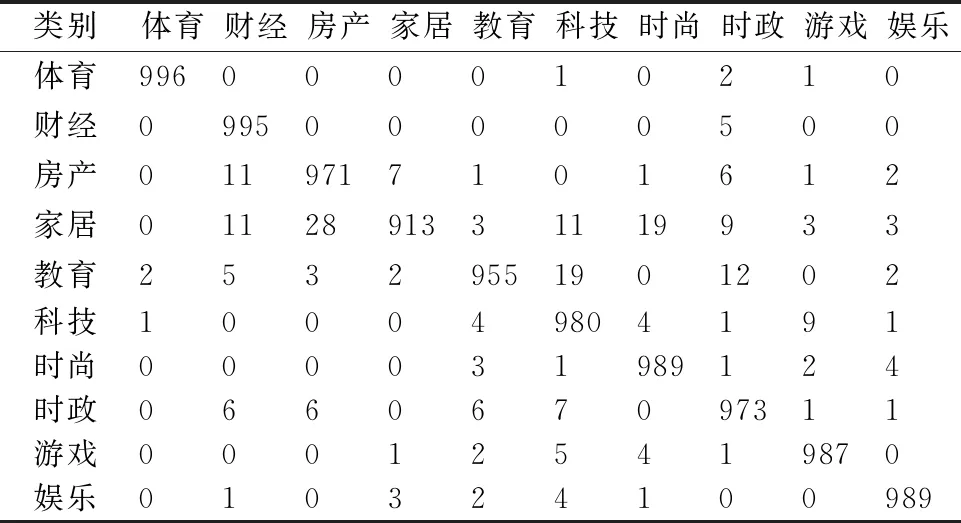
表5 各類別分類結果混淆矩陣Table 5 Classification result confusion matrix
從表5中可以看到除家居類新聞外,其余每個主題類別(每個類別1000條新聞文本)被本文提出模型分類后分到正確類別中均超過950條,家居類別為913條.各主題類別分錯類的情況非常少,其中體育、財經類的主題更是接近100%的精確率.
結合表3、表4、表5上的數據看,本文提出的字、詞粒度融合模型,在結合了字符粒度細膩的語義信息、詞粒度的實體信息與上下文信息后確實能更好的對文本信息進行提取并且在絕大部分類別下都有著非常優(yōu)秀的主題分類效果.
5 結束語
本文將新聞文本進行分字、分詞并使用Word2Vec進行嵌入.對嵌入后的字向量、詞向量利用字-詞的包含關系進行不同粒度上的融合.通過粒度融合將字符粒度中細膩的語義信息與詞粒度中的實體信息有效的結合,在此基礎上通過卷積神經網絡進行特征提取減少了文本中的冗余信息.在公開數據集THUCNews、搜狗新聞上進行模型性能測試,實驗表明,本文提出的模型能夠有效的提升中文新聞文本主題分類任務的準確率.但通過研究發(fā)現,本文提出的模型在語義特征提取時采用的CNN結構存在一定的無序性缺陷,CNN并不能理解文字中每個字符、詞語的順序輸入關系以及字符、詞語之間的關注關系,因此本文下一步研究將嘗試解決上述問題.
猜你喜歡
今日農業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
