一種改進的高維孤立點挖掘入侵檢測方法
2020-12-09 09:47:08申利民孫中魁馮佳音李志明
小型微型計算機系統(tǒng) 2020年12期
關(guān)鍵詞:檢測
申利民,孫中魁,2,陳 磊,馮佳音,李志明
1(燕山大學(xué) 信息科學(xué)與工程學(xué)院,河北 秦皇島 066004) 2(華北理工大學(xué)輕工學(xué)院 電氣信息學(xué)院,河北 唐山 063000) 3(華北理工大學(xué) 研究生院,河北 唐山 063000)
1 引 言
隨著現(xiàn)代信息技術(shù)的發(fā)展,賽博空間安全問題的重要性也隨之凸顯出來.2019 年全年超過 6,200 萬個計算機惡意程序樣本被捕獲,日均傳播次數(shù)達(dá) 824 萬余次,涉及計算機惡意程序家族 66 萬余個(1)https://www.cert.org.cn/ publish/main /upload /File/2019-year.pdf.截止2019年12月,CNCERT接收到網(wǎng)絡(luò)安全事件報告107801件,較2018年底增長1.0%(2)http://www.cac.gov.cn.為了適應(yīng)日趨復(fù)雜化、多樣化的網(wǎng)絡(luò)環(huán)境和各種各樣的網(wǎng)絡(luò)入侵手段,入侵檢測系統(tǒng)(Intrusion Detection System,IDS)通過分析網(wǎng)絡(luò)連接和系統(tǒng)審計數(shù)據(jù),生成安全策略并發(fā)現(xiàn)入侵攻擊,已經(jīng)成為賽博空間安全不可或缺的組成部分.
在現(xiàn)實網(wǎng)絡(luò)中,入侵檢測系統(tǒng)面對的數(shù)據(jù)大都是高維數(shù)據(jù),部分研究者們對高維數(shù)據(jù)首先采用特征提取或特征選擇的方法降低數(shù)據(jù)維度,再采用傳統(tǒng)的數(shù)據(jù)挖掘方法進行處理.Tian等提出了一種基于PCA的分層孤立點檢測模型,首先基于PCA進行特征提取,然后利用正常數(shù)據(jù)建立一個異常檢測模型,再分析異常數(shù)據(jù)類型[1];Zyad等在PCA的基礎(chǔ)上提出了利用修剪后的平均向量來估計平均向量,從而使Trimmed PCA具有更好的魯棒性[2].降維的方法可以剔除某些特征,降低計算的時間復(fù)雜度,但每個特征代表不同的孤立值,如果錯誤的選擇特征就會得到錯誤的孤立值,從而產(chǎn)生不適合未來計算的近似結(jié)果.基于低維數(shù)據(jù)的挖掘算法在面對高復(fù)雜性、稀疏性和多樣性的高維數(shù)據(jù)時往往無能為力,適用于低維數(shù)據(jù)的數(shù)據(jù)挖掘算法在處理高維數(shù)據(jù)時通常會遇到算法效率降低,存在傳統(tǒng)的基于距離和密度的定義失效等問題,降低了入侵檢測準(zhǔn)確性[3].研究者們提出了針對高維數(shù)據(jù)的入侵檢測方法.Zhang等針對高維數(shù)據(jù)網(wǎng)絡(luò)數(shù)據(jù)流中的異常檢測,提出了SPOT技術(shù),具有良好的檢測效果[4];Prajapati等針對高維數(shù)據(jù)中的數(shù)據(jù)不均勻和剛性聚類問題,利用K-mean算法和模糊C-Mean(FCM)算法的優(yōu)點,提出了一種最近鄰搜索算法,能在更短的時間內(nèi)實現(xiàn)最近鄰搜索[5].
入侵行為中的“攻擊”數(shù)據(jù)通常被視為異常數(shù)據(jù),而孤立點數(shù)據(jù)挖掘是對大規(guī)模數(shù)據(jù)中偏離正常行為的異常數(shù)據(jù)進行的挖掘,因此孤立點數(shù)據(jù)挖掘?qū)θ肭中袨榉治鼍哂兄匾饬x.針對高維孤立點挖掘,研究者提出了幾種典型的孤立點挖掘算法:基于空間投影[6,7]、基于超圖模型[8,9]和基于頻繁模式的算法.基于頻繁模式的孤立點挖掘算法簡單、易于理解,并且比前兩種算法,有著更低的時間復(fù)雜度,研究者做了廣泛的研究.早期,He等提出了頻繁模式孤立因子(FPOF)的度量概念,并提出了基于頻繁模式的孤立點挖掘算法(FindFPOF),通過計算每條數(shù)據(jù)的頻繁模式因子來發(fā)現(xiàn)孤立點[10];周等在FindFPOF的基礎(chǔ)上提出了加權(quán)頻繁模式孤立因子的概念,并在此基礎(chǔ)上給出一種快速數(shù)據(jù)流孤立點檢測算法,該算法具有良好的適用性和有效性[11];王等提出了一種新的算法NFPOF(New Frequent Pattern Outlier Factor),通過頻繁模式的相關(guān)屬性進一步精確定位每一條孤立點數(shù)據(jù)的異常屬性[12];Yuan等針對權(quán)值嚴(yán)重影響孤立值檢測結(jié)果的問題,提出了一種加權(quán)頻繁模式孤立點挖掘方法(WFP-Outlier),用于從加權(quán)數(shù)據(jù)流中發(fā)現(xiàn)隱式孤立點[13].
綜上所述,基于頻繁模式的高維孤立點挖掘在入侵檢測中具有非常重要作用,但在基于頻繁模式算法及其改進算法中存在兩個問題,首先上述算法需要獲取完全頻繁模式,但是在高維數(shù)據(jù)中,發(fā)現(xiàn)頻繁模式的完全集是非常困難的;其次頻繁模式的挖掘算法的時間復(fù)雜度與頻繁模式的數(shù)量有直接關(guān)系,頻繁模式的數(shù)量越多,時間復(fù)雜度越大.針對基于頻繁模式的高維孤立點挖掘算法中存在的不容易獲取完全頻繁模式和時間復(fù)雜度高等問題,引入關(guān)聯(lián)規(guī)則中的最大頻繁模式因子的概念,提出一種基于最大頻繁模式因子的高維孤立點挖掘(MFPOF-OM)算法,并把其和入侵檢測結(jié)合起來,在保證檢測性能優(yōu)良的前提下,降低了時間復(fù)雜度.
2 基于最大頻繁模式因子的高維孤立點挖掘生成入侵檢測模式
設(shè)D={tl,t2,…,tn}為一個包含n個網(wǎng)絡(luò)行為記錄t的數(shù)據(jù)集,tk稱為事務(wù).I={il,i2,…,ip}是網(wǎng)絡(luò)行為記錄中所有屬性的集合,im稱為項目.
定義1.項目集:I的任何子集X稱為D的項目集.
定義2.支持度:項目集X的支持度記為support(X):
(1)
其中:‖D‖表示數(shù)據(jù)集D的事務(wù)總數(shù),‖X‖表示項目集X的支持?jǐn)?shù).
定義3.頻繁模式:如果項目集X的支持度support(X)≥MinSP,則X為頻繁模式,否則稱為非頻繁模式,其中MinSP表示用戶定義的最小支持度.
定義4.超集:若一個集合S2中的每一個元素都在集合S1中,且集合S1中可能包含S2中沒有的元素,則集合S1就是S2的一個超集.S1是S2的超集,則S2是S1的真子集,反之亦然.
定義5.最大頻繁項模式:頻繁項集X,如果其所有超集都是非頻繁項集,那么稱X為最大頻繁模式.
定理1.設(shè)X、Y是數(shù)據(jù)集D中的項集,如果X?Y,若Y是頻集,則X也是頻集.
設(shè)Y為最大頻繁模式,由定義5可知Y必為頻繁模式,如果X?Y成立,則有定理1可知,X必為頻繁模式,也即是最大頻繁模式中已經(jīng)包含了所有的頻繁模式.
由以上分析可知,基于最大頻繁模式的孤立點挖掘算法中只需要發(fā)現(xiàn)最大頻繁模式集,而不是完全頻繁模式集,既解決了發(fā)現(xiàn)頻繁模式的完全集的困難問題,又因為最大頻繁模式的數(shù)量遠(yuǎn)遠(yuǎn)小于頻繁模式的數(shù)量,從而可以降低算法的時間復(fù)雜度.
2.1 數(shù)據(jù)離散化
入侵檢測的數(shù)據(jù)類型可分為文本型數(shù)據(jù)、離散數(shù)值型數(shù)據(jù)和連續(xù)數(shù)值型數(shù)據(jù)3大類,而最大頻繁模式的挖掘要求數(shù)據(jù)類型必須是離散數(shù)值型,因此需要對連續(xù)數(shù)值型數(shù)據(jù)進行離散化處理,轉(zhuǎn)化成為可靠的精確的適合進行高維孤立點挖掘的數(shù)據(jù).
連續(xù)數(shù)據(jù)的離散化就是將連續(xù)數(shù)據(jù)分割為有限個相互獨立的區(qū)間.離散化的方法有多種,其中基于聚類分析的方法因其可以根據(jù)數(shù)據(jù)的分布特點自行決定屬性值如何劃分區(qū)間,能夠盡量減少人工的干預(yù),在實際中得到廣泛的應(yīng)用.聚類形成模式類之后,同一個模式類內(nèi)的對象因其高度相似可當(dāng)成一個對象來對待,而不同模式類的對象因其迥異性而被看作不同的離散值.
基于聚類分析的離散化方法有兩個步驟:
1)對連續(xù)數(shù)據(jù)類型的屬性值進行聚類.
2)聚類后,同一個模式類所包含的連續(xù)屬性值作為一個對象,統(tǒng)一標(biāo)記,而不同模式類的數(shù)值分別標(biāo)記,完成離散化處理.
其中,基于聚類分析離散化的關(guān)鍵步驟是是對屬性值的聚類挖掘.
K-means算法作為一種基于劃分的無監(jiān)督的經(jīng)典算法,在實踐應(yīng)用被廣泛應(yīng)用,但K-means算法也有其本身的缺點,就是對聚類個數(shù)K和初始聚類中心的選擇非常敏感.
針對K值敏感的問題.因為在離散化過程中K值并不是固定和唯一的,所以可采用手肘法確定最優(yōu)的K值.手肘法的核心思想是:當(dāng)K小于最優(yōu)聚類數(shù)時,增大K值會大幅增加每個模式類的聚合程度,聚合程度的好壞由樣本的聚類誤差平方和(SSE)來表示,SSE會大幅下降,當(dāng)K達(dá)到合理數(shù)量的模式類時,SSE將急劇下降,最后,SSE值趨于平坦,即SSE和K之間的函數(shù)關(guān)系呈肘形,并且對應(yīng)于肘部的K值是最佳的簇數(shù).
誤差平方和(SSE)定義為:
(2)
其中,Ci為第i個簇,p為Ci中的樣本點,mi為Ci的質(zhì)心(Ci中所有樣本的均值).
針對初始聚類中心的選擇敏感的問題,采用最大距離法選取K個樣本作為初始中心點.最大距離法的核心思想是認(rèn)為所有樣本中距離最遠(yuǎn)的樣本點最不可能被分到同一個模式類中.
3https://www.unb.ca /cic/datasets/index.html
2.2 基于最大頻繁模式因子的高維孤立點挖掘算法思想
基于FindFPOF算法中頻繁模式因子(FPOF)的概念,提出最大頻繁模式因子(MFPOF)的定義.
定義6.最大頻繁模式因子:對于數(shù)據(jù)集中D中的每個網(wǎng)絡(luò)行為記錄t,MFPOF(t)定義為:
(3)
其中:
MFPs(D,MinSP)表示滿足給定最小支持度閾值MinSP的數(shù)據(jù)集D的最大頻繁模式集合;
‖MFPs(D,MinSP)‖表示最大頻繁模式集合中最大頻繁項的個數(shù);
support(X)表示一個最大頻繁模式X的支持度.
基于最大頻繁模式因子的高維孤立點挖掘(MFPOF-OM)算法描述如算法1所示.
算法1.MFPOF-OM算法
輸入:D//網(wǎng)絡(luò)行為數(shù)據(jù)集
MinSP//最小支持度閾值
k//孤立點個數(shù)閾值
輸出:k個網(wǎng)絡(luò)行為孤立點數(shù)據(jù)記錄
Begin:
//基于PF-Tree挖掘出最大頻繁模式集合
1.對于D,生成滿足MinSP的項頭表HeaderTable(D);
2.對于D,采用PF-Tree算法生成滿足MinSP的頻繁項樹,記為:T;
3.采用一種改進的高效最大頻繁模式因子挖掘算法,獲取MFPs(D,MinSP)和support(X);
//基于生產(chǎn)的最大頻繁模式,開始孤立點挖掘
4.foreachtinD
5.依據(jù)公式(3),計算每個記錄t的最大頻繁模式因子值:MFPOF(t);
6.end foreach
7.獲取所有t的MFPOF值;
8.對所有t,按照MFPOF值升序排序;
9.return MFPOF值最小的前k網(wǎng)絡(luò)行為記錄,即k個網(wǎng)絡(luò)行為孤立點數(shù)據(jù)
End
MFPOF-OM算法分3個部分:1)從數(shù)據(jù)庫中挖掘最大頻繁模式;2)計算每個網(wǎng)絡(luò)行為記錄的MFPOF(t);3)發(fā)現(xiàn)k個孤立點數(shù)據(jù).總的時間復(fù)雜度為O(n2+n*l+n*logn),其中n表示數(shù)據(jù)量的個數(shù),l表示最大頻繁模式的個數(shù).
2.3 基于關(guān)聯(lián)分析自動構(gòu)建誤用檢測模式
采用關(guān)聯(lián)分析可以自動發(fā)現(xiàn)網(wǎng)絡(luò)行為的數(shù)據(jù)特征,關(guān)聯(lián)分析產(chǎn)生的最大頻繁模式能夠反映網(wǎng)絡(luò)行為數(shù)據(jù)的最大共同特征,最大共同特征又是通過網(wǎng)絡(luò)行為數(shù)據(jù)的屬性值表示出來的,可利用這些屬性值來構(gòu)建具有很強分類能力的入侵檢測模式[14].
以MFPOF-OM算法所獲取的孤立點數(shù)據(jù)集作為輸入,并設(shè)定一個最小支持度閾值,算法可參考算法1的1-3步,可以獲取孤立點集的最大頻繁模式,即為網(wǎng)絡(luò)攻擊的入侵檢測模式.
3 實驗分析
為了對所提出的方法進行驗證,本文使用NSL-KDD數(shù)據(jù)集3作為實驗數(shù)據(jù),該數(shù)據(jù)集包含了12多萬條連接記錄,每條連接記錄包含41個表示連接記錄特征的條件屬性和1個表示連接記錄攻擊類型的決策屬性.其中第20個屬性(num_outbound_files)的屬性值全為0,依據(jù)信息論理論,信息熵為0,因此剔除第20個屬性.
NSL-KDD的訓(xùn)練數(shù)據(jù)集包含24種攻擊類型分類標(biāo)識,所有的分類標(biāo)識都可以根據(jù)其攻擊特點映射為4種攻擊類別:Probing、DoS、U2R和 R2L,及一種正常類別:Normal,共5大類.
所有的實驗在MATLAB 2012中實現(xiàn),對4組樣本數(shù)據(jù)Normal+DoS,Normal+Probing,Normal+R2L,Normal+U2R從準(zhǔn)確度和復(fù)雜度兩個方面進行分析.
3.1 準(zhǔn)確度分析
4組樣本數(shù)據(jù)分析獲取的DoS、Probing、R2L、U2R入侵檢測模式實驗結(jié)果如圖1所示.對4種攻擊的入侵檢測模式進行綜合分析,并以檢測率(DR)和誤報率(FPR)作為判定入侵檢測模式的性能評價標(biāo)準(zhǔn).
檢測率、誤報率分別定義為:
檢測率=(檢測出的異常攻擊數(shù)/異常攻擊總數(shù))*100%
誤報率=(錯誤分類的進程總數(shù)/正常的進程總數(shù))*100%
1)4種網(wǎng)絡(luò)攻擊模式測試結(jié)果分析
通過比較4種網(wǎng)絡(luò)攻擊在不同MinSP閾值情況下的檢測率和誤報率,來說明所提算法的檢測效果,進而驗證所提算法的可行性.入侵檢測攻擊模式由一條或多條規(guī)則組成:每條規(guī)則內(nèi)部各屬性是“與”的邏輯關(guān)系,即所有的屬性取值都滿足要求則本條規(guī)則成立;規(guī)則之間是“或”的邏輯關(guān)系,即多條規(guī)則只要其中一條成立則可判定本條記錄為一個網(wǎng)絡(luò)攻擊行為.
實驗結(jié)果從檢測率、誤報率兩個性能指標(biāo)來綜合衡量入侵檢測模式的檢測效果.以Probing攻擊入侵檢測模式為例進行數(shù)據(jù)分析.實驗過程中MinSP所取閾值不同,則獲取的入侵檢測模式也不同,實驗結(jié)果如圖1(b)所示.圖1(b)表示MinSP分別為58000和59000兩個閾值下獲取的入侵檢測模式,并用獲取的Probing入侵檢測模式分別對5種數(shù)據(jù)類型(即DoS、Probing、R2L、U2R 4種攻擊數(shù)據(jù)和Normal類型)進行檢測.分析發(fā)現(xiàn),在閾值為59000的情況下,Probing入侵檢測模式對Probing數(shù)據(jù)的檢測率為95%,但是用Probing入侵檢測模式來檢測其它類型數(shù)據(jù)會存在一定誤差,如檢測Normal數(shù)據(jù),會把3%的Normal數(shù)據(jù)誤檢測為Probing類型數(shù)據(jù),對DoS數(shù)據(jù)誤檢率為2%,對R2L數(shù)據(jù)誤檢率為1%,對U2R數(shù)據(jù)誤檢率為10%.閾值為58000時各檢測結(jié)果如圖1(b)中白色柱體所示,不再一一描述.通過對多個閾值下的檢測結(jié)果綜合分析,閾值為59000時的檢測結(jié)果最好,因此把閾值為59000時的入侵檢測模式作為Probing攻擊的入侵檢測模式,模式規(guī)則如表1所示.
比較圖1中的4種攻擊入侵檢測模式發(fā)現(xiàn),當(dāng)最小支持度閾值較大時都會有更好的檢測率,對其它類型數(shù)據(jù)的檢測誤差則大小變化不一,但基本持平.這正是孤立點挖掘的特點決定的,閾值越大孤立點的個數(shù)越少,更能反映攻擊類型數(shù)據(jù)的特征.當(dāng)然閾值也有一定的限定,如果閾值取值過大反而會對降低檢測率造成不良影響.

表1 閾值等于59000時Probing攻擊的入侵檢測模式Table 1 Misuse detection patterns of Probing attack when the threshold is 59000
比較圖1中的4個子圖發(fā)現(xiàn)U2R類型數(shù)據(jù)在DoS、Probing和R2L攻擊入侵檢測模式中都有較高的檢測誤差,分別為4%、10%和33%;U2R攻擊入侵檢測模式的檢測率相較于其它3種攻擊入侵檢測模式,它的檢測率也相對不高,只有87%的檢測率.這是由NSL-KDD數(shù)據(jù)集中U2R類型數(shù)據(jù)的特點決定的,U2R的數(shù)據(jù)量太少,只有52條,以至于數(shù)據(jù)挖掘無法充分發(fā)現(xiàn)其數(shù)據(jù)特征,導(dǎo)致檢測性能不盡完善.
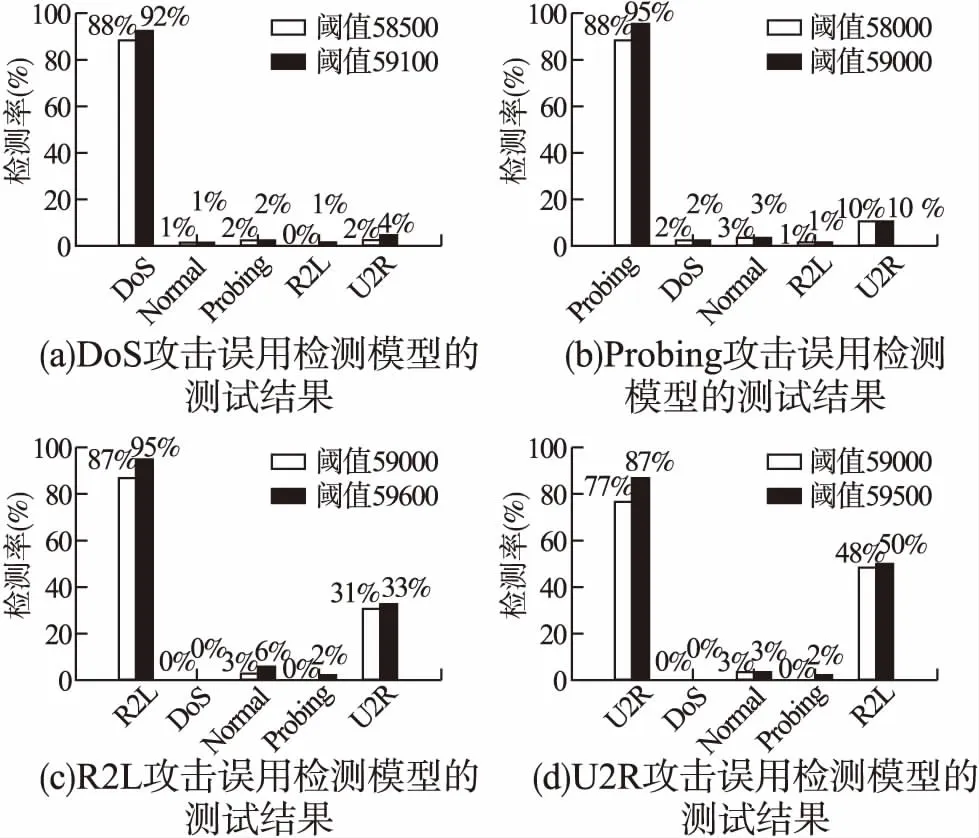
圖1 4種網(wǎng)絡(luò)攻擊模式的測試結(jié)果Fig.1 Test results of four network attacks
比較圖1(c)和圖1(d)發(fā)現(xiàn),利用R2L攻擊入侵檢測模型檢測U2R數(shù)據(jù)和利用U2R攻擊入侵檢測模型檢測R2L數(shù)據(jù)都有較高的誤差,這說明R2L類型數(shù)據(jù)和U2R類型數(shù)據(jù)之間相較于其他3種類型數(shù)據(jù),具有較高的數(shù)據(jù)相似性,這與現(xiàn)實中2種網(wǎng)絡(luò)攻擊的特點相符.
2)基于高維數(shù)據(jù)下入侵檢測結(jié)果對比分析
為了測試所提算法的準(zhǔn)確度,把所提MFPOF-OM算法與FindFPOF算法[10]、NFPOF算法[12]、AOD-FP-MaxFPOF算法[15]、ADASYN-SDA算法[16]進行比較,其中FindFPOF、NFPOF、AOD-FP-MaxFPOF是3種基于頻繁模式或改進的基于頻繁模式孤立點檢測算法,ADASYN-SDA是基于深度學(xué)習(xí)的算法,比較結(jié)果如圖2所示.結(jié)果表明MFPOF-OM算法優(yōu)于FindFPOF和NFPOF算法;和AOD-FP-MaxFPOF算法比較,檢測率上非常接近,誤報率比后者相比偏高;和基于深度學(xué)習(xí)的ADASYN-SDA算法相比,兩個性能指標(biāo)都稍有不如,但ADASYN-SDA算法需要復(fù)雜的前期數(shù)據(jù)處理,首先需要使用ADASYN算法進行數(shù)據(jù)過采樣處理,然后使用Adam優(yōu)化算法,以及Dropout正則化對SDA深度學(xué)習(xí)模型進行改進,提取出低維的集成特征,最后再在Softmax分類器中進行入侵檢測識別,會大大增加算法的時間復(fù)雜度.從總體性能上分析顯示,所提算法和有監(jiān)督的深度學(xué)習(xí)方式相比性能稍有不如,但在無監(jiān)督的檢測算法中性能表現(xiàn)較佳,網(wǎng)絡(luò)中的入侵行為能夠被有效地檢測出來,可以滿足實際的運行需求.
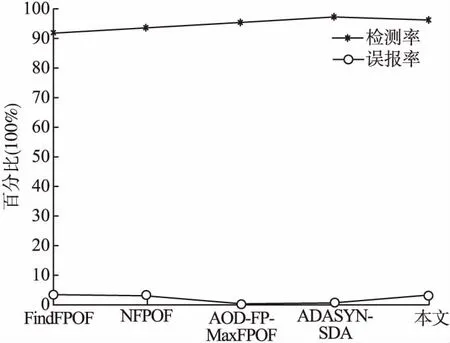
圖2 其它入侵檢測方法和所提方法的比較Fig.2 Comparison between other intrusion detection methods and the method proposed
3)高維入侵檢測和降維入侵檢測的對比分析
入侵檢測系統(tǒng)中的數(shù)據(jù)是高維的,高維數(shù)據(jù)表達(dá)能力較強,能夠刻畫入侵檢測系統(tǒng)內(nèi)部復(fù)雜的結(jié)構(gòu).但在入侵檢測分析中,很多方法都使用了降維的概念,進行維度的約簡.而某些看似不重要的維度,特別是在孤立點挖掘算法中,更可能代表著有用的信息,而這些維度的消除,可能會影響到入侵檢測結(jié)果準(zhǔn)確度.且原始數(shù)據(jù)處理過程中的降維也會增加入侵檢測的時間復(fù)雜度.為了比較高維數(shù)據(jù)入侵檢測和數(shù)據(jù)降維入侵檢測對檢測性能的影響,利用MFPOF-OM算法和兩種基于降維的方法基于PCA的特征提取[1]、截斷均值LDA方法[17]進行對比分析,結(jié)果如圖3所示.從中可以看出,MFPOF-OM算法和文獻[1]中檢測性能基本一致,而又明顯的優(yōu)于文獻[17]所提出的方法,說明不適當(dāng)?shù)臄?shù)據(jù)降維方法會把某些含有重要孤立點信息的特征剔除掉,從而大大降低入侵系統(tǒng)的檢測性能.
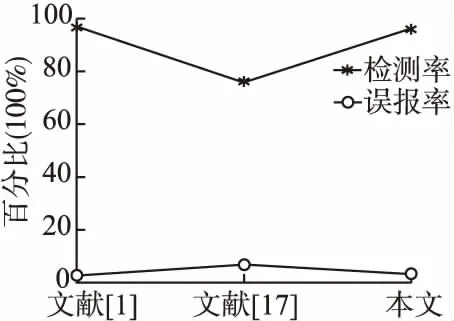
圖3 降維挖掘和高維挖掘測試比較Fig.3 Comparison dimension reduction methods with the method proposed in this paper
3.2 時間復(fù)雜度分析
對4組樣本數(shù)據(jù)Normal+DoS、Normal+Probing、Normal+R2L、Normal+U2R進行復(fù)雜度分析.FindFPOF、NFPOF、AOD-FP-MaxFPOF這3種基于頻繁模式及其改進算法的流程類似,都可以分為3步,其中第1步從數(shù)據(jù)庫中挖掘頻繁模式和第3步發(fā)現(xiàn)k個網(wǎng)絡(luò)行為孤立點數(shù)據(jù),這兩步基本雷同,只有第2步因為算法重點不同而不太一樣.FindFPOF算法第2步是計算每個網(wǎng)絡(luò)行為記錄的FPOF(t);NFPOF算法是計算新頻繁模式離群因子NFPOF(t);AOD-FP-MaxFPOF算法是計算最大頻繁孤立點因子MaxFPOF(t).依據(jù)所給算法分析,時間復(fù)雜度也可根據(jù)算法流程分為3部分,且3種算法的時間復(fù)雜度基本一致,總的時間復(fù)雜度為O(n2+n*m+n*logn),其中n表示數(shù)據(jù)量的多少,m表示頻繁模式的多少.
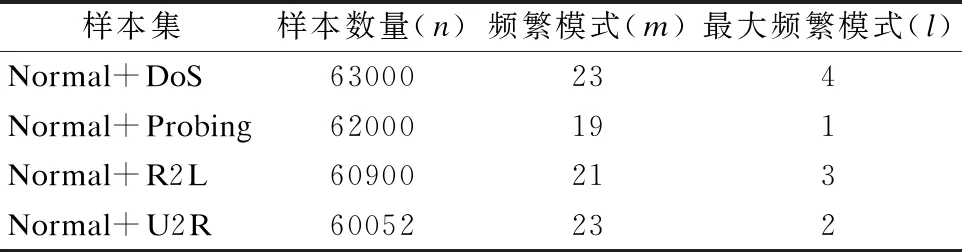
表2 兩類挖掘算法結(jié)果比較Table 2 Compared the results of two mining algorithm
與上述算法一樣,MFPOF-OM算法流程圖也分3步,如2.2節(jié)中所述,總的時間復(fù)雜度為O(n2+n*l+n*logn),其中m表示數(shù)據(jù)量的個數(shù),l表示最大頻繁模式的個數(shù).對于海量數(shù)據(jù)來說,n取值足夠大,兩種算法的時間復(fù)雜度從理論計算上都可以簡化為O(n2).但在實際運行中,當(dāng)n取值一定時,會因為l?m,4組樣本數(shù)據(jù)獲取的頻繁模式個數(shù)(m)和MFPOF-OM算法中的最大頻繁模式個數(shù)(l)如表2所示,從而使MFPOF-OM算法比上述3種算法具有更優(yōu)的時間復(fù)雜度.
4 結(jié) 論
針對現(xiàn)實中入侵檢測系統(tǒng)中多為高維數(shù)據(jù)這一現(xiàn)實問題,利用基于頻繁模式高維孤立點挖掘的相關(guān)技術(shù),本文提出了一種基于最大頻繁模式因子的高維孤立點挖掘算法(MFPOF-OM).MFPOF-OM算法只需挖掘出最大頻繁模式集,解決了基于頻繁模式孤立點算法中挖掘完全頻繁模式比較困難的問題,也因頻繁模式的數(shù)量的大幅減少,從而降低算法的時間復(fù)雜度.實驗表明,所提出的方法是可行的,相較于對比算法,在保證了檢測性能優(yōu)良的前提下,進一步降低了時間復(fù)雜度.
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
