一種改進灰狼算法優化LSSVM的交通流量預測
2020-12-09 09:46:28戴麗珍徐芳萍
小型微型計算機系統 2020年12期
戴麗珍,付 濤,楊 剛,楊 輝,徐芳萍
(華東交通大學 電氣與自動化工程學院,南昌 330013) (江西省先進控制與優化重點實驗室,南昌 330013)
1 引 言
智能交通系統[1]的一個關鍵部分—交通流預測,在信號燈控制、交通擁堵疏導、駕駛路線引導等方面均發揮著重要作用.高效、準確的交通流預測可以保障ITS的準確運行,也為交通管控部門提供決策依據.隨著全球ITS技術的飛速發展,交通流預測技術的研究成為一個熱點問題.
研究表明,城市路面交通網中某一時間點的交通流量與前幾個時間點的交通流量有映射關系,并且交通流量具有周期性[2].為了提高交通流量預測的準確性,常采用時間序列技術和回歸模型等[3-9]方法.由于交通流有不確定性、復雜性和非線性等特點,導致其精確預測存在一定的難度.隨著優化算法的發展,基于神經網絡和群體智能優化的方法也被廣泛應用于交通流量的預測.Chan[10]等人提出了一種基于粒子群優化算法的短時交通流預測方法,提高了預測的穩定性和可靠性.王凡[11]等人提出了一種基于AOSVR的交通流預測及參數選擇的方法.Li[12]等人提出基于了粒子群優化混沌BP神經網絡的短時交通流預測.Xu[13]等人提出了利用分類和回歸樹進行短期交通量預測.楊凡[14]等人研究了一種混合神經網絡挖掘模型方法用于交通流預測.以上方法均在某種程度上提升了交通流的預測精度,但由于構建模型的差異,性能優劣無法判定.可以明確的是:基于群體優化的預測技術已被應用于交通流量預測,以提高預測模型的準確性.
在解決樣本數量少、非線性系統以及模式識別等方面擁有諸多優勢的SVM被Cortes和Vapnik提出,并能將其推廣到線性擬合等其他機器學習問題中[15].Suyken為了解決SVM求解二次規劃問題帶來的訓練時間過長等問題,提出用求解線性方程組問題代替求解二次規劃問題的最小二乘支持向量機(Least Square SVM,LSSVM)[16].因此,LSSVM也被用于交通流量的預測[17,18].最小二乘支持向量機的性能在很大程度上依賴于它的兩個核心參數(懲罰因子γ和核函數參數σ).其中,γ是平衡了對樣本的擬合性能(經驗風險)和測試樣本的預測性能(結構風險),即結構風險隨著γ的增大而上升,經驗風險卻相反;且γ越大,模型將過擬合,而γ越小,模型將欠擬合.而σ的情況與γ相反.為了確定這兩個關鍵參數,粒子群優化算法PSO、遺傳算法GA、差分進化算法DE、人工蜂群算法BA和模擬退火算法SA等多種啟發式算法已被嘗試[19-23].灰狼優化算法(Grey Wolf Optimization,GWO)是模擬狼群的種群地位和捕獵行為的一種新群體智能優化算法,常用于模型的參數優化.當優化目標只有一個峰值時,GWO算法收斂速度較快;但當優化目標有多個峰值時,盡管GWO算法全局搜索性能比PSO和GA等算法高,而易造成局部最優(即早熟現象)[24],從而導致模型陷入欠擬合或過擬合.由于在GWO算法中,控制距離參數a與迭代次數是線性關系且成反比,忽略了工程應用中優化問題的多樣性,尤其是優化目標有多個峰值時,易陷入早熟.因此,為了實現交通流的精確預測,本文擬研究基于LSSVM的交通流預測建模方法,并通過增加GWO算法的種群多樣性和改進GWO算法的控制距離參數a來優化LSSVM的參數,提高模型的預測精度.
2 最小二乘支持向量機模型
最小二乘支持向量機是對支持向量機改進得到的(不等式約束問題簡化為等式約束問題).考慮數據樣本(xt,yt)(t=1,2,…,l),其中xt∈Rn,yt∈Rn分別為樣本輸入和樣本輸出,l為樣本的數量.通過非線性變換,可將樣本輸入x映射到高維空間:
f(x)=wTφ(x)+c
(1)
其中:w為超平面的權值,c為常數,φ(·)為空間轉換函數.
最小二乘支持向量機的目標函數定義如下:
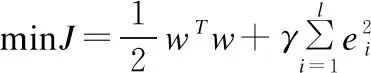
(2)
其中:ei為誤差,γ為懲罰因子.
構造拉格朗日函數如下:
(3)
其中:ai為拉格朗日乘子.根據KKT條件可得:
(4)
求解式(4),可得LSSVM數學模型如下:
(5)
其中:K(·)為模型核函數,通常采用RBF核函數,即:
(6)
其中:σ為核函數參數.
因此LSSVM模型的性能主要取決于γ和σ.
3 基于改進GWO的LSSVM模型
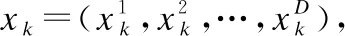
(7)
(8)
(9)
A=a(2r1-1)
(10)
C=2r2
(11)
其中:t為當前迭代數;Dp(t)(p=α、β、η)為灰狼與獵物之間的距離;A和C為系數向量;Xp為當前獵物位置;Xl(l=1,2,3)為普通灰狼根據Xp更新的位置;a為控制距離參數,為由2-0的線性遞減量;r1和r2為[0 1]隨機數.
綜上,灰狼優化算法的主要步驟如下:
Step 1.參數初始化.
Step 2.初始化種群個體并計算函數目標值,選擇最優個體α、β和η.
Step 3.計算a、A和C的值,按照式(7)計算種群個體與最優個體的距離并根據式(8)-式(9)更新個體位置.
Step 4.更新最優個體位置.
Step 5.判斷是否達到要求.如果達到設定值,則運行結束,否則轉至Step 3繼續迭代.
GWO算法在尋優過程中能自動調整控制距離參數a,且自身的參數具有良好的魯棒性能,能夠較好地平衡算法中種群的全局搜索能力和局部搜索能力[25].因此,控制距離參數a的設計,在一定程度上會影響到算法的全局搜索能力與局部搜索能力之間的平衡性.通常情況下,控制距離參數a隨著迭代次數的增大,從2-0線性遞減.當算法處于尋優初期時,搜索步長較大,全局搜索能力較強,不易陷入局部最優,且隨機參數r1在一定范圍時,|A|≥1,表明算法進行全局搜索;而當算法處于尋優后期時,搜索步長較小,局部搜索能力較強,易于收斂,且隨機參數r1在一定范圍時,|A|<1,表明算法進行局部搜索[26].
4 改進灰狼算法優化LSSVM交通流預測模型
對于GWO算法而言,探索能力對于其優化性能至關重要[27].GWO算法容易出現早熟現象,要想避免該現象,通常可采用豐富種群多樣性、自適應變異、處理重復個體等方法[28].針對灰狼優化算法因種群多樣性低以及控制距離參數a與迭代次數是線性關系且成反比的問題,忽略了工程應用中優化問題的多樣性,尤其是優化目標有多個峰值時,存在早熟的缺點,結合差分進化算法和控制距離參數非線性化提出了改進的灰狼優化算法.為增加算法種群多樣性進行如下改進:
1)變異操作:
Di(t)=xα+B(xβ-xη)
(12)
其中:Di(t)為變異個體位置,xp為當前種群中隨機的3個個體位置,B為收縮因子.
2)交叉操作:
(13)
其中:R為交叉概率;yi為新個體.
3)選擇操作:
(14)
其中:f(·)為評價函數.
對于控制距離參數a我們作如下改進:
a=cos(tπ/(2T))+(1-t/T)1.1
(15)
其中:T為最大迭代次數.
應用改進灰狼算法優化LSSVM模型參數進行交通流預測的流程如圖1所示.
綜上,改進的灰狼優化算法主要步驟如下:
1)構建數據集(即訓練集與測試集),并對數據預處理,得到路段的歷史交通流量數據的時間序列.
2)利用改進灰狼優化算法對LSSVM參數優化(即懲罰因子γ和核函數參數σ),主要步驟如下:
Step 1.參數初始化.
Step 2.初始化種群并計算函數目標值,選擇最優個體α、β和η.
Step 3.計算a、A和C的值,根據式(7)計算種群個體與最優個體的距離并根據式(8)、式(9)更新個體位置.
Step 4.由式(12)-式(14)對當前種群執行變異、交叉和選擇操作,計算個體的目標函數值.
Step 5.更新最優個體位置.
Step 6.判斷是否達到要求.如果達到設定值,則運行結束,否則轉至Step 3繼續迭代.
3)根據最優參數得到最優模型后進行交通流量預測.
由于初始化的種群可能不能滿足要求,這時候就需要擴充種群,而算法采用交叉、變異、選擇操作,為算法種群增加了變異種群,因此,可以極大的改善算法的早熟現象.且通過對式(15)所示的控制距離參數a的非線性化的調整,與傳統的GWO算法相比,非線性的控制距離參數a隨著迭代次數的增加,斜率先遞減后遞增,且比傳統a的斜率小,當t在0.8T到0.9T之間,a的斜率開始上升,如圖1所示.因此,控制距離參數的非線性化能夠保證在部分情況下,算法依然處于全局搜索,例如:當t=2/T,且隨機數r1在一定范圍內時,非線性化a=1.17,而傳統a=1,這時改進GWO參數|A|≥1,而傳統的GWO參數|A|<1;而當t接近最大迭代次數時,a以非線性遞增的衰減速度趨于0且比傳統的a衰減慢,這樣也能保證局部搜索的充分性.
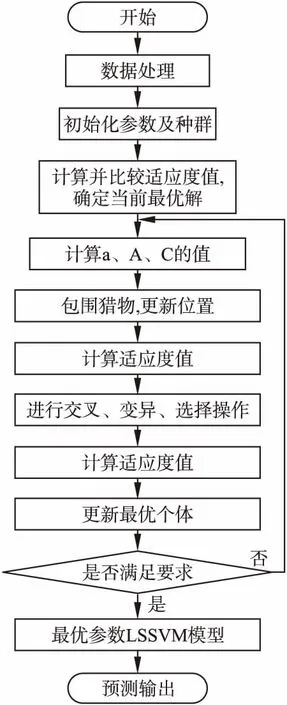
圖1 改進灰狼算法優化LSSVM流程Fig.1 Improved grey wolf algorithm to optimize LSSVM process
5 仿真實驗
5.1 實驗數據來源與處理
本文采集了4天山東省某路段交通流量數據樣本,每隔15分鐘采集一次,共采集384組數據樣本.
由于是數據驅動建模,首先需要確定模型輸入與輸出.依據相空間重構確定時間序列的遲滯時間及鑲嵌維度,并建立數學模型:
y(n+k)=[x(n),x(n-t),…,x(n-(d-1)t)]T
(16)
其中:y(·)=x(·)為模型的輸出,x(n)為時間序列,k為預測步長.
因為是對交通流時間序列進行預測,則令k=1,且每15min預測一次交通流量.由差分熵可以確定該時間序列的遲滯時間t=7,鑲嵌維度d=4.訓練和測試數據樣本分別為276組和92組.
5.2 參數選擇
使用改進GWO算法優化LSSVM模型參數前,定義改進GWO算法的優化目標函數為平均相對誤差emape,如式(20)所示.改進GWO算法可調參數設置如下,種群數量npop=20,種群參數上、下界分別為ub=[1000,1000]、lb=[0.01,0.01],縮放因子B∈(0.3,0.7),交叉概率為R=0.1,最大迭代次數T=50等,其他模型同類型參數均一致.
5.3 實驗結果分析
對預測結果采用如下指標進行評價:
最大絕對誤差:
(17)
歸一化均方根誤差:
(18)
均方差:
(19)
平均相對誤差:
(20)
為評價本文提出方法的優勢,采用GWO-LSSVM、PSO-LSSVM、小波神經網絡和ELM與本文方法對比,各自獨立運行100次取評價指標平均值,對比結果如表1所示.
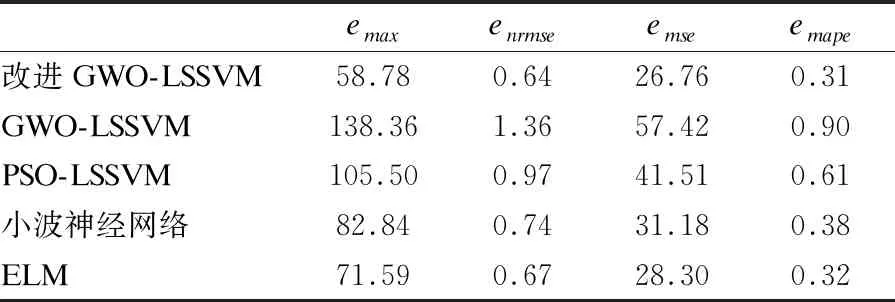
表1 模型評價指標結果對比Table 1 Comparison of model evaluation index results
仿真結果如圖2-圖6所示(其中圖3-圖6圖例一致).對比分析如下:
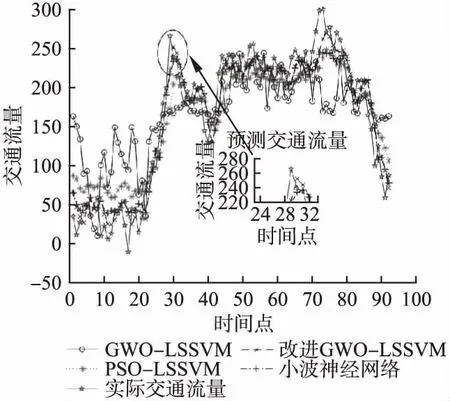
圖2 模型平均預測值對比Fig.2 Comparison of model average predictions
1)改進GWO-LSSVM模型對交通流量預測與其他算法相比,評價指標明顯高于其他4種算法.
2)圖3-圖6中GWO-LSSVM的結果是由于GWO算法在尋優過程中,γ很大,σ很小導致模型出現過擬合現象,陷入局部最優.
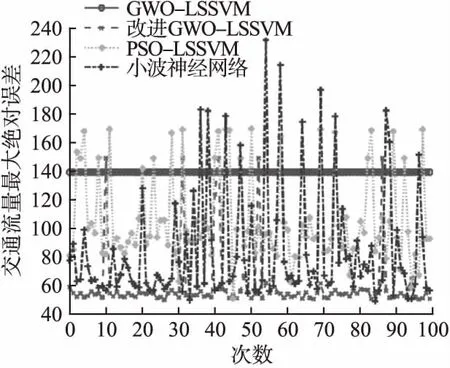
圖3 最大絕對誤差Fig.3 Maximum absolute error
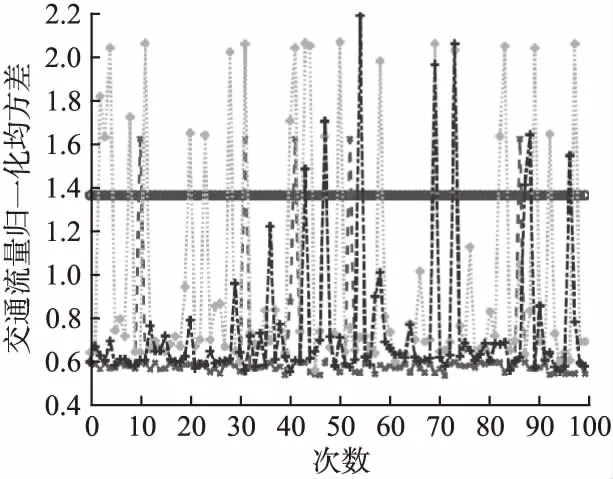
圖4 歸一化均方差Fig.4 Normalized mean square error
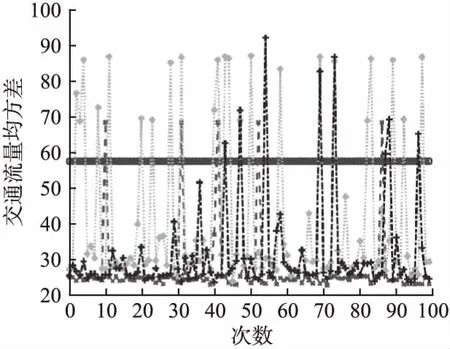
圖5 均方誤差Fig.5 Mean square error
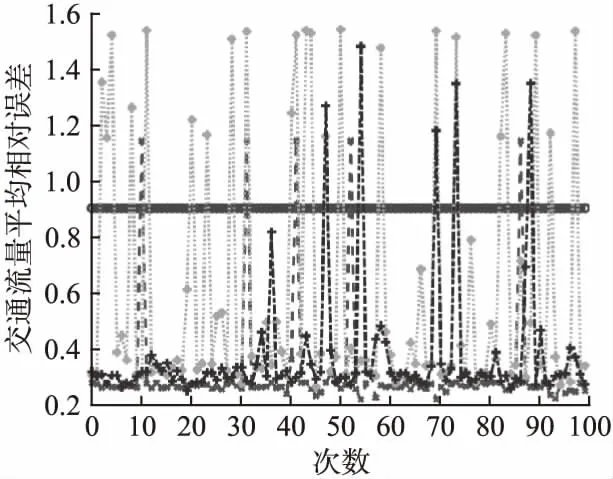
圖6 平均相對誤差Fig.6 Mean relative error
3)值得注意的是,與PSO-LSSVM、小波神經網絡相比,雖然本文提出方法性能指標發生5次較大幅度跳躍(可接受范圍)如圖3-圖6,但是泛化性能明顯提升.
6 結束語
為提高基于LSSVM的交通流量預測精度,本文提出了改進灰狼優化算法對LSSVM參數(懲罰因子γ和核函數參數σ)進行優化.為了提高算法全局搜索能力,避免過早陷入局部最優,設計了灰狼優化算法內部的交叉、變異和選擇操作,并且使得控制參數a的非線性化,豐富了灰狼優化算法中種群的多樣性,提升了算法的搜索性能.仿真結果顯示,改進GWO優化LSSVM與GWO-LSSVM相比增強了泛化能力,能夠獲得較高的預測精度;與PSO-LSSVM相比,魯棒性和泛化能力均有提升;與小波神經網絡和ELM相比,雖然模型有所差別,但是泛化能力和魯棒性有所提升.此外由于改進GWO算法加入了交叉、變異、選擇操作,導致尋優時間較長,不符合實時性要求,因此本文方法通過歷史數據建立模型,獲得模型參數后預測當前交通流量.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
