融合改進LBP和SVM的偏光片外觀缺陷檢測與分類
2020-11-18 09:15:20黃廣俊鄧元龍
計算機工程與應用 2020年22期
黃廣俊,鄧元龍
深圳大學 機電與控制工程學院,廣東 深圳518060
1 引言
隨著社會的快速發(fā)展,人們的生活方式也發(fā)生了顯著變化。人們更多地使用電子產品,如智能電視、手機、電腦等,它們已經成為人們日常生活中不可或缺的一部分。偏光片是薄膜晶體管液晶顯示器(TFT-LCD)面板的核心部件,它大約占顯示器面板總成本的10%[1]。一般而言,TFT-LCD 型偏光片的厚度大約0.3 mm,由5 層透明聚合物薄膜和1 層壓敏膠水層組成。在生產過程中,偏光片極其容易出現異物、劃痕、氣泡、凹凸點、缺膠等外觀缺陷。這些缺陷可能存在于薄膜的任何一層,降低液晶面板的質量,甚至導致其失效。偏光片缺陷類別的快速、準確檢出,有利于控制產品質量,減少缺陷成品的出現。因此,生產企業(yè)對偏光片缺陷檢測和分類非常重視。然而,人工目視離線檢測存在著勞工強度大、實時性差、準確性不高等問題,而基于機器視覺的檢測方法可以很大程度上克服上述弊端。
目前偏光片缺陷檢測方法主要有傳統圖像處理和人工神經網絡。Sohn等人提出一種新的穩(wěn)定檢出各種TFT-LCD偏光片缺陷的方法,并設計算法,根據自適應閥值判斷偏光片缺陷二值圖中是否有缺陷。在種類為6,數量為131的缺陷數據庫中,其算法檢出率為90.8%,其中暗區(qū)II 型缺陷和移除保護膜缺陷檢錯率較高[2]。Kuo 等人在較早時使用拉普拉斯算子和閥值統計決策方法進行自動檢測,在200 張缺陷圖像分類中,分類準確率達到98.0%,僅有4 張劃痕缺陷被誤分到點缺陷[3]。后來則提出使用最大灰度、離心率、對比度和灰度共生矩陣作為缺陷圖像特征,輸入到徑向基神經網絡和后向傳播神經網絡分類器中,在96 張訓練樣本和84 張測試樣本中,分類準確率達到98.9%,單張圖像處理時間為2.57 s[4]。Won等人在數量為210的偏光片缺陷數據庫中,使用卷積神經網絡,正確分類精度達到95.0%[5]。Lei等人使用Faster R-CNN深度學習神經網絡來進行偏光片缺陷目標檢測,實驗結果顯示,在使用VGG 模型時,其平均精度均值為67.5%,取得了非常好的檢測精度,且檢測速度幾乎達到實時[6]。然而,傳統圖像處理方法容易受噪聲等影響而降低處理精度和可靠性,而人工神經網絡則需要大量的訓練樣本才可以保證足夠的泛化能力,并且學習時間長,容易出現“過學習”等現象,這些問題在一定程度上限制了該方法的應用。支持向量機(Support Vector Machine,SVM)在解決小樣本、非線性及高維模式識別問題中具有獨特的優(yōu)勢[7]。本文對基于支持向量機的偏光片外觀缺陷檢測進行研究。實驗結果表明,該方法能有效快速地實現偏光片外觀缺陷的檢測和分類。
2 偏光片外觀缺陷檢測及其特征提取
2.1 缺陷圖像采集
根據暗場成像原理,使用工業(yè)相機獲取偏光片缺陷圖像,選擇高斯濾波器作為圖像預處理,然后進行缺陷可疑區(qū)域的快速檢測和分割處理。常見的4 類偏光片缺陷和無缺陷背景圖如圖1所示。

圖1 常見的偏光片外觀缺陷類型
2.2 外觀缺陷特征提取
2.2.1 LBP描述符及其常用變形
傳統局部二值模式(Local Binary Pattern,LBP)描述符是將圖像中每一個像素點的灰度值作為閥值,并與所在的3×3 鄰域內像素灰度值相比較。為滿足更大的區(qū)域覆蓋,Ojala等人將3×3鄰域擴展到任意鄰域,并用圓形鄰域代替正方形鄰域。圓形LBP 描述符允許在半徑為R 的圓形鄰域內有任意多個像素點。對于鄰域內未直接落在像素方格中央的點的灰度值,通過線性插值完成。為解決圓形LBP描述符過于稀疏的直方圖問題,Ojala 等人提出了采用等價模式LBP 描述符來進行降維,特征向量維度由原來的256 維降至59 維。然而,等價模式LBP描述符是假設圖像中LBP二進制編碼僅存在1和0轉換不超過2次的情況。由于圖像紋理的多樣性,每一類圖像都有其各自的特點和關鍵信息,固定的等價模式并不適用于任何種類的圖像,等價模式LBP描述符的特征表達能力有所降低[8]。為克服等價模式LBP的缺點,黃飛飛等人提出使用主成分分析方法對LBP進行維數約簡,并命名為LBP 子模式。在ORL 數據庫中的實驗表明,LBP子模式無論在識別率還是維數方面都要優(yōu)于LBP等價模式。為進一步豐富LBP描述符的描述能力,避免復雜的變換引起的計算復雜度的增加,張敦鳳等人融合圖像分區(qū)均值和傳統圓形LBP 描述符的方法,相對單一LBP描述符,在YALU和ORL人臉數據庫上,識別率分別提高9.28%和11.50%[9]。LBP 描述符及其變形形式示意圖如圖2所示。
2.2.2 改進LBP描述符
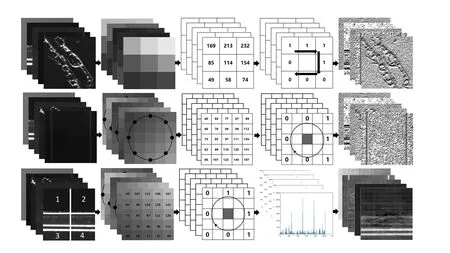
圖2 傳統LBP描述符及其變形形式示意圖
ILBP具體步驟如下:
(1)特征提取。將預處理后的缺陷圖像劃分為不同分區(qū),計算每個分區(qū)LBP 特征和均值特征,將所有分區(qū)提取特征連接成一個新的特征向量。
(2)數據歸一化。為了能夠更好地統一兩種特征,測試樣本單獨使用訓練樣本上最大-最小值來歸一化,將新的特征向量映射到[-1,1]之間。
(3)主成分分析。設歸一化后的特征向量矩陣為X ,其列向量為xk=(x1k,x2k,…,xjk)T,缺陷的某一類型可由xk描述,協方差矩陣為:
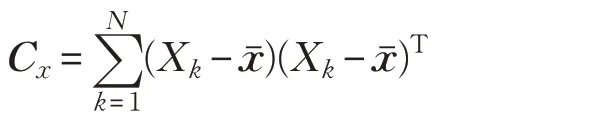
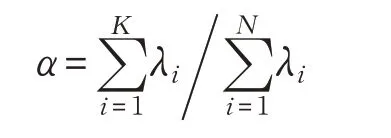
取其所對應的特征向量組成主成分方向,將缺陷圖像變換到新的特征空間Y 中:Y=UTX 。
(4)線性判別方法。經PCA(Principal Component Analysis)降維后的缺陷圖像特征向量Y=(y1,y2,…,yn)為n 維向量,共有5類,每類缺陷的個數為ni,第i 類的樣本均值為,總體缺陷均值為缺陷類內散度矩陣Sw和類間散度矩陣Sb分別為:
融入語境設想,讓學生有更多對話文本的機會。如在《天游峰的掃路人》教學中,針對天游峰的奇特景象,不妨建議學生思考:如果你在游覽天游峰的時候,見到了這些掃路人,你想與他們暢談什么呢?很顯然,這樣的開放性話題,讓學生能夠有更多自我對話文本的機會,能夠讓他們在主動融入文本中形成更多的深刻感知。很多同學在設想中認為,自己真想與掃路人一起掃路,體驗其中的生活,感受他們的艱辛。有的同學說,掃路人每日登山不是為了賞風景,而是專門尋找敗筆,我們游客應該換位思考,不能再隨手亂丟垃圾。有的同學說,閱讀了此文,讓自己感受到勞動最偉大,只有尊重別人的勞動果實,才能收到別人的尊重,等等。
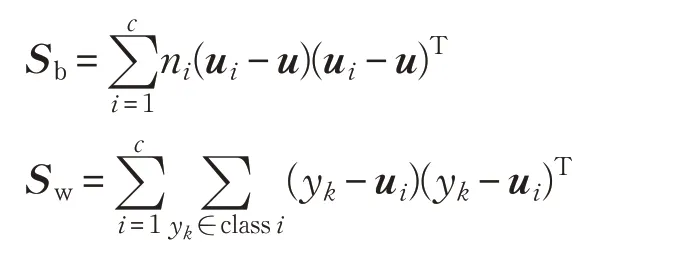
為得到最優(yōu)投影矩陣,Sw、Sb滿足如下準則:
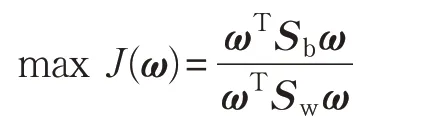
目標函數形式為廣義瑞利商,是參數為投影向量ωT的函數。一般而言,經PCA降維后,樣本個數大于樣本維數,散度矩陣Sw非奇異[10-11]。通過拉格朗日乘數法可求得:
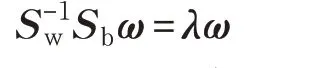
取最大的m 個特征值λi所對應的特征向量ωi構成最佳投影矩陣,將偏光片缺陷圖像變換到新的特征空間Z 中:
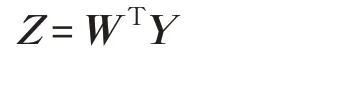
3 支持向量機分類器設計
3.1 非線性問題的支持向量機
SVM處理非線性分類問題的基本原理就是通過非線性映射算法將原樣本映射到一個更高維甚至無窮維的特征空間中,這樣就可以將原本空間線性不可分的情況變成高維空間的線性可分問題。由于SVM是二元分類器,在解決多分類問題時,須由二元SVM來構造多元分類器。本文采用一對一法來構造多分類器。至于核函數的選擇,本文選用高斯徑向基核函數。
3.2 遺傳算法參數尋優(yōu)
SVM 的識別效果不僅受核函數影響,還受懲罰因子c 和核參數g 值的影響,因此需要對參數進行尋優(yōu)。目前較常用的參數尋優(yōu)方法有網格搜索法、遺傳算法尋優(yōu)法等。相對網格搜索法,采用啟發(fā)式算法可以在更大范圍內不必遍歷網格內的所有參數點,就能找到全局最優(yōu)解,且能有效減少陷入局部最優(yōu)解的風險,具有魯棒性好、收斂速度快的特點[12]。本文使用謝菲爾德大學的遺傳算法工具箱來確定參數c 和g,具體流程如圖3所示。
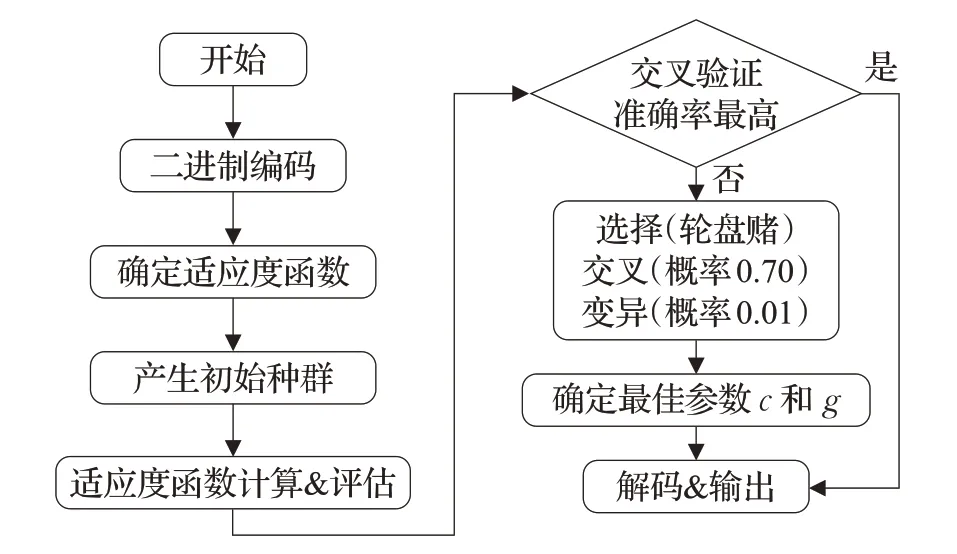
圖3 使用遺傳算法優(yōu)化SVM參數流程圖
4 仿真實驗與結果分析
4.1 實驗環(huán)境
仿真實驗環(huán)境為Intel?Xeon?CPU E5-2630 v3@2.40 GHz 2.40 GHz,64 GB內存,Win7操作系統,Matlab R2017b 軟件。為驗證本文算法的準確率,在自建偏光片缺陷數據庫和ORL數據庫上進行仿真實驗。其中,自建數據庫包含5類缺陷,每類50張,每張大小為256×256,均根據暗場成像原理,由不同的照射方位拍照獲得。隨機抽取200 張(每類40 張)缺陷圖像用于模型訓練,剩余的50 張用于測試模型的性能。另外,ORL 人臉庫有400張圖像,包含40類,每類10張,每張大小為112×92。隨機抽取240 張人臉圖像用于模型訓練,剩下的160 張用于模型測試。
4.2 實驗結果和分析
實驗將缺陷圖像劃分為2×2,4×4,6×6分區(qū),均值特征劃分為16×16,32×32分區(qū)情況下,兩兩特征組合來設計實驗。另外,還驗證了不同LBP 描述符下的識別率。為確保實驗數據的可信度,訓練樣本采用十折交叉驗證方法來進行驗證,整體數據庫的平均識別準確率如表1 所示。
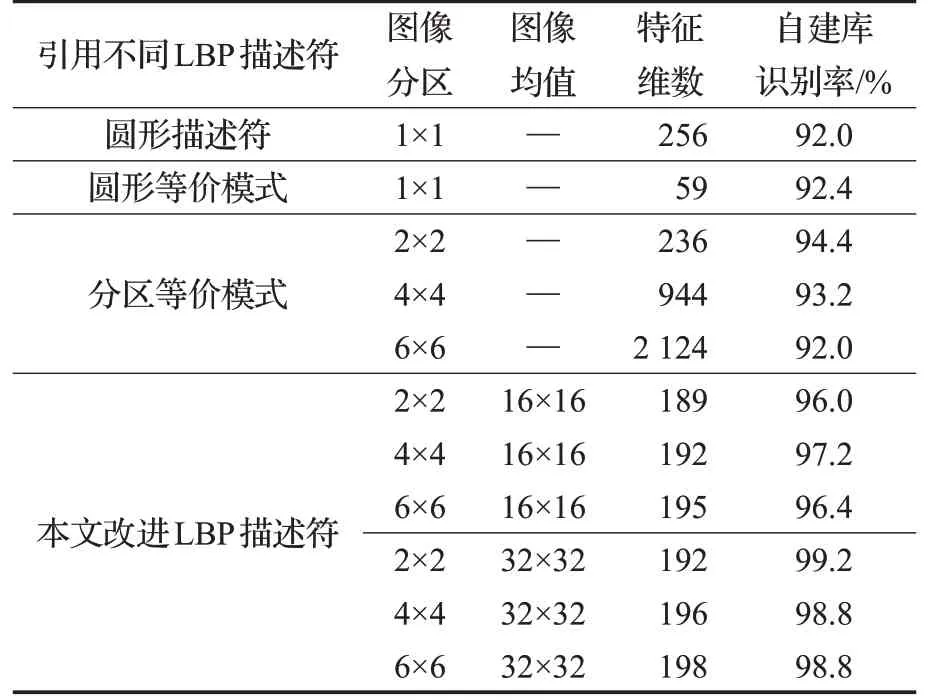
表1 不同LBP描述符及其變形形式下的識別率
從上述結果可以看出:傳統LBP描述符分類準確率不高,圖像分區(qū)在一定程度上可以提高識別準確率,但隨著分區(qū)的增多,特征維數急劇增加,圖像被分割得過于稀疏而丟失一些統計特性,導致識別率有一定程度下降。另外,當貢獻率α 取合適值時,2×2圖像分區(qū)的整體識別率為99.2%,達到最大,優(yōu)于其他分區(qū)的識別準確率,而且特征維數相對較少。在充分考慮缺陷圖像樣本的類別信息后,改進LBP 描述符能高效地表示圖像特征。針對自建數據集,通過調用SKLEARN中的集成算法,比較樸素貝葉斯、K 最近鄰、隨機森林、支持向量機等5種算法識別準確率,算法參數均調至最優(yōu)。其在整體自建數據庫上的分類結果如表2所示。

表2 不同算法下的識別率
實驗結果顯示,本文提出的ILBP描述符,在保證特征維數較低的情況下,識別率能得到很好的提高。識別準確率會隨α 和圖像分區(qū)大小變化。當貢獻率α 較小時,丟失原有缺陷圖像較多的信息,分類器識別精確度下降。當α 接近1時,缺陷圖像保持大量原有的冗余信息,分類器分類困難。同時越精細的分區(qū)意味著更高維數的復合特征和更好的局部能力。因此,對于偏光片缺陷圖像,當分區(qū)越精細時,貢獻率α 應取越大的值。偏光片缺陷數據庫識別率隨主成分貢獻率和圖像分區(qū)大小關系如圖4所示。
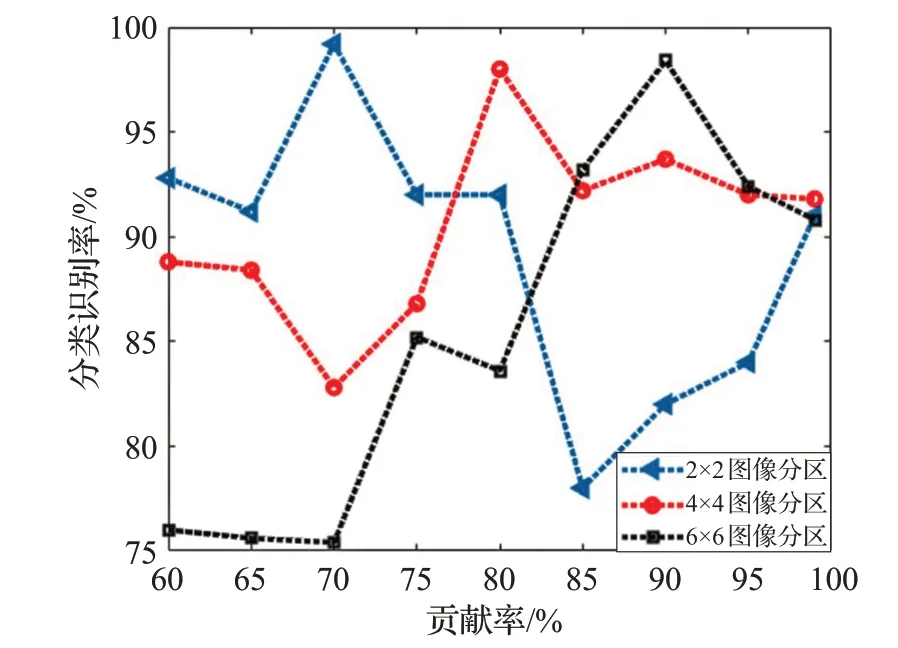
圖4 不同主成分和圖像分區(qū)下的識別率
上述實驗充分地說明,當取較大α 值時,ILBP描述符可獲得比較理想的識別效果,分類識別精確率和分類效率等綜合性能優(yōu)于傳統LBP 描述符及常用的改進LBP 描述符,且分類速度快,每張缺陷圖像由輸入到完成識別所耗時間在0.92 s,極大地減少了計算的時間復雜度,完全滿足工業(yè)生產線實際檢測需求。
4.3 遺傳算法尋優(yōu)結果
在分類器訓練過程中,使用遺傳算法對懲罰因子c和核參數g 進行尋優(yōu),搜索范圍是(2-12,212)。搜索過程中用十折交叉驗證法對SVM 分類器進行評價,得到一組交叉驗證中平均準確率最高的參數c 和g,利用最優(yōu)參數進行缺陷圖像分類。以2×2圖像分區(qū)的ILBP描述符在自建數據庫上分類為例,參數尋優(yōu)如圖5所示。
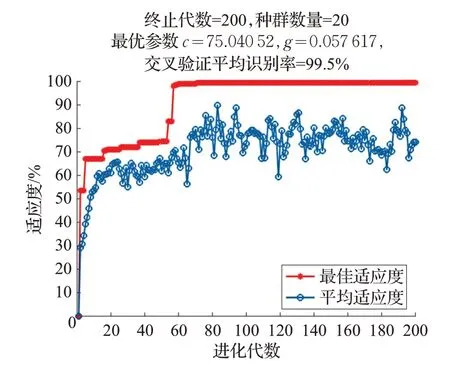
圖5 遺傳算法尋優(yōu)結果
5 結束語
(1)驗證了LBP及其常用變形形式在自建數據庫上的識別效果,并對提出的ILBP 描述符在不同分區(qū)情況和主成分比例下的識別效果進行討論。實驗結果表明,在自建缺陷數據庫中,分類正確率能夠達到99%以上,SVM在解決偏光片缺陷識別問題上有著獨特的優(yōu)勢。
(2)文中ILBP 描述符應用到ORL 數據庫中,分類正確率能夠到達99.75%,而且數據的維度僅為39維,相對于徐競澤等人提出的算法[13],本文算法分類精度更高。另外,相對于張郭鳳等人提出的描述符,雖然分類準確率同為99.75%,但是特征維數由原來1 280維降至39 維,大大降低計算復雜度。上述進一步論證了ILBP描述符的有效性。
(3)通過遺傳算法參數尋優(yōu),避免網絡重復搜索和設置。結果表明,利用遺傳算法能夠在較大范圍內有效確定SVM分類器的最優(yōu)參數。
(4)實驗所用的缺陷圖像根據透射暗場成像原理拍取,圖像數量不多,全都選取典型的缺陷圖像,分類干擾少,分類識別準確率較高。因此,接下來的工作是采用其他成像原理,如結構光成像[14]、偏振光成像[15]等來進行圖像拍取,而且研究大樣本、強干擾情況下的偏光片缺陷圖像檢測和分類。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
