高性能人臉識別加速器優化設計及FPGA實現
2020-11-18 09:14:26張偉華
計算機工程與應用 2020年22期
吳 進,張偉華,席 萌,代 巍
西安郵電大學 電子工程學院,西安710121
1 引言
卷積神經網絡(Convolutional Neural Network,CNN)是人工神經網絡的一種[1],被廣泛應用于圖像識別,其缺點是運行期間會消耗越來越多的邏輯資源和存儲器帶寬,因此基于神經網絡的計算要求,需要對不同的神經網絡提出不同的加速方法[2]。現場可編程門陣列(Field Programmable Gate Array,FPGA)被廣泛用于CNN 硬件加速的實現,特別是在移動和嵌入式設備上,為了解決FPGA平臺未能充分利用邏輯資源和內存帶寬,以及優化不全面、不能很好地實現加速效果的問題,本文設計了一個基于FPGA的人臉識別神經網絡加速器,并且和已有的GPU 實現加速的結果進行比較,在功耗以及神經網絡計算時間方面都呈現更加理想的結果。
2 卷積神經網絡模型
人臉識別中經典LeNet-5神經網絡模型示意圖如圖1所示,該網絡模型由2個卷積層、2個池化層、3個全連接層構成,其中卷積層與池化層交替出現。假設使用3×3大小的卷積核進行圖像的卷積運算,對于神經網絡的各個層采用不同的卷積核進行圖像特征提取。降采樣時的縮放程度決定了池化層提取出特征的粗糙程度,均使用大小為2的縮放因子對特征圖進行縮放,從而完成池化層操作。本文采用平均值池化方式完成池化操作,從而實現對CNN 網絡模型的加速,即對2×2 大小的鄰域求平均值,進而生成一個新的像素點,即所求的目標像素點。
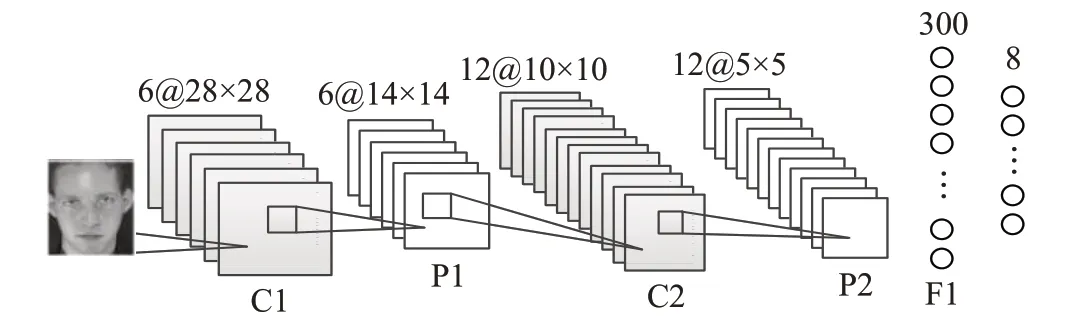
圖1 卷積神經網絡結構示意圖
3 CNN加速器設計
3.1 系統架構
圖2 所示為嵌入式平臺上的人臉識別加速器系統架構,Xilinx Zynq 系列平臺為ARM+FPGA 的異構平臺,ZC706平臺上的PS部分實現整個系統的調度功能,PS 端的DDR 用于存儲外部數據,卷積神經網絡加速器由FPGA(PL部分)實現。
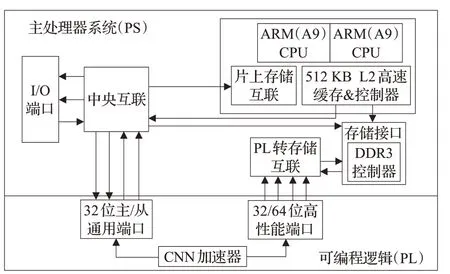
圖2 加速器系統架構示意圖
3.2 HLS優化
在FPGA 平臺上進行CNN 加速器設計時通常會遇到片上資源不足、片外帶寬不夠大、對處理的數據進行重復利用以及所設計加速器的并行度不高等設計挑戰[3]。Vivado HLS(Vivado 高層次設計工具)具有仿真方便、移植性好、描述層次高、有利于提升開發效率等優點[4]。因此本文使用HLS 工具對CNN 加速器進行性能優化。
3.2.1 存儲優化
圖像數據使用外部DDR 進行存儲,FPGA 訪問PS端的DDR會花費大量時間,本文采用在PL部分設計行緩沖區的方法來存放圖像數據。由于所設計的緩沖區的行數有限,當新的圖像數據需要進入緩沖區時,要通過對當前一行實現向上移位操作釋放一部分存儲空間來存儲新的數據,存儲優化的結果示意圖如圖3 所示。在FPGA端設計行緩沖區存放數據能夠避免FPGA訪問遠端的DDR 存儲器,其作用類似于Cache,能夠提高處理器與存儲之間的訪問速度,進而提高系統性能。
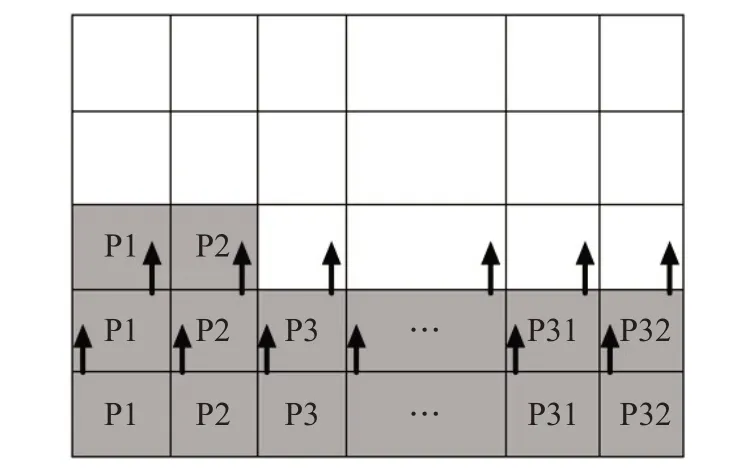
圖3 存儲優化結果示意圖
在HLS開發工具中,多維數組通常用來存放卷積核參數和特征圖數據。在HLS 綜合時,數組被實現為BRAM端口,由于所實現的BRAM端口大小的約束,讀寫操作在1 個時鐘周期內至多完成2 次[5]。當優化操作需要展開循環時,在一個時鐘周期內要對內存進行多次讀/寫。本文通過對數組降維的方法解決內存瓶頸,即將多維數組采用Block、Cyclic 以及Complete 等方式分割為低維數組。Block是將原來數組中的數據按照其順序放置在若干個BRAM 中,即對于原來的數據依照其順序進行了切割,形成多個BRAM模塊,能夠增加內存訪問帶寬,提高訪問速度。Cyclic是將原數組中的數據以交叉存儲的方式放置在若干個BRAM 中,即將原來數組中的數據按照奇偶的順序分開。Complete 是將原有數組中的數據放置在寄存器中而不是BRAM 中,Complete 分割方式適用于較小的數組。以上三種數組分割示意圖如圖4所示。
3.2.2 定點量化
在人臉識別加速器設計過程中,冗余位的存在將會造成一定程度的硬件資源浪費[6]。因此,為了合理且有效地利用硬件資源,所設計的硬件電路不能局限于特定位數的精度,即需要滿足任意精度要求。以下對定點的數據類型以及任意精度整數類型進行描述。
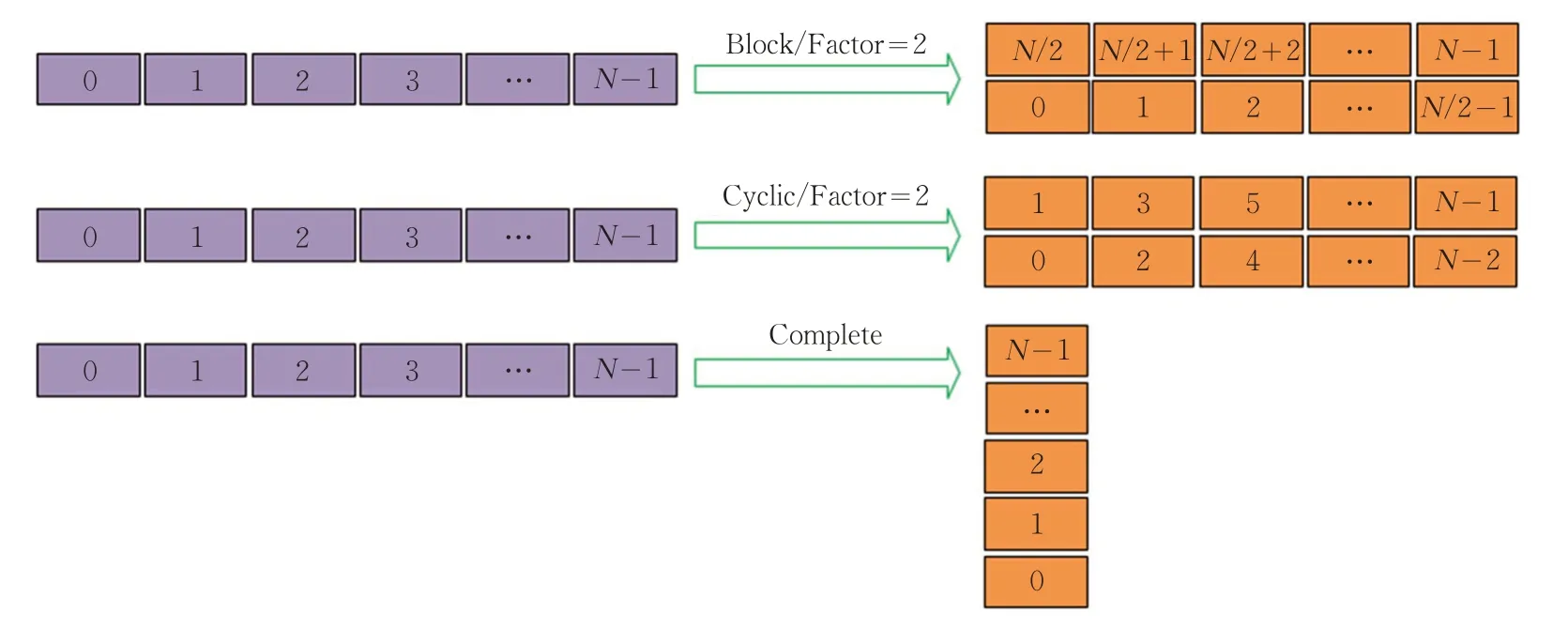
圖4 多維數組分割示意圖
(1)任意精度整數類型
在一定整數值的寬度范圍內,HLS工具能夠支持任意精度的整數數據類型。如表1 所示,C 和C++相關的庫能夠實現對任意精度整數類型的支持,其優點是具備更高的時鐘頻率、更好的數據吞吐率,并且消耗的資源較少,因此使用任意精度數據類型能用更少的資源獲得相同的精度,并且可以實現更高的工作頻率,C 和C++的字長均為1位到1 024位。

表1 任意精度整數數據類型
(2)任意精度定點類型
定點數的一般格式如圖5所示,確定位數的整數部分位于二進制小數點的左邊,小數部分位于右邊,符號位為最高有效位(MSB)。W 表示字長總位數,I 表示整數部分的位數,B 表示小數部分的位數,則W=I+B。

圖5 定點格式示例
在文獻[2]的加速器設計中,芯片的工作頻率低于100 MHz,且FPGA 資源的使用率在80%以上,對此,在無損精度的情況下,本文使用Vivado HLS 工具進行定點量化精度的探索。本文對網絡中權值和特征圖參數大小進行統計,為了防止數據溢出,將整數部分的位數設定為11 位。在權衡位寬及精度大小之后,將數據類型確定為ap_fixed<16,11>。圖6 所示為未經過任何并行優化的定點加速器的資源利用率以及時間性能的結果報告,經過優化,該加速器的總周期數降低至385 122,工作頻率提高到200 MHz。定點量化的優化結果如圖7所示,采用定點量化的方式能夠在一定程度上對CNN加速器進行優化,降低系統運行時間并且減少資源利用率,使得CNN加速器的性能更優。
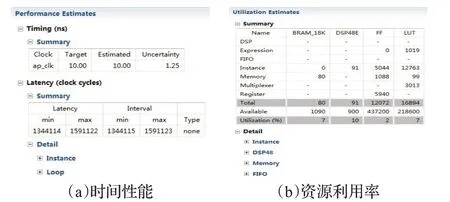
圖6 未優化時CNN浮點加速器綜合報告
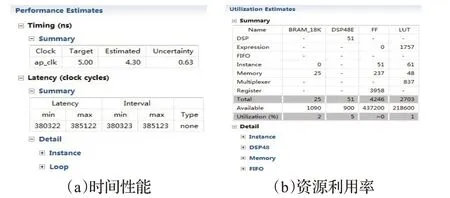
圖7 定點量化后CNN浮點加速器綜合報告
3.2.3 運算優化
(1)卷積層優化
卷積層的算法結構由多層嵌套循環組成,未經過優化之前的CNN 加速器計算時延為1 591 122 個時鐘周期,其中卷積層C1 計算時延周期為509 388,卷積層C2計算時延周期為748 022,大約占用神經網絡計算總時延的79%。因此,主要通過優化卷積層來減少加速器的時間延遲。
卷積層C1層的權值參數存放在卷積層計算的多維數組中,在HLS 工具中被綜合為FPGA 中的ROM。輸入圖像的像素值緩存在input 數組中,該數組被實現為雙端口RAM,深度為160。本文首先對于卷積層內部的并行性進行探索并分析,使用“#pragma HLS UNROLL”指令進行優化,優化之后的電路能夠同時完成25 個乘加運算。使用流水線技術對特征圖內部的像素計算進行優化,進行運算優化以及定點量化之后,卷積層C1的工作時間由138 796 個時鐘周期降低至816 個時鐘周期。同理,基于輸入特征圖的并行性,對于卷積層C2實現進行流水線以及循環展開操作,進行優化之后,卷積層C2的工作時間降低為1 644個時鐘周期。

圖8 S1層生成電路
(2)池化層優化
池化層S1在未被優化之前需要8 652個時鐘周期,相比于卷積以及全連接層,池化層大約占整個神經網絡計算時間的3%。本文對于輸出特征圖之間的并行性進行探索,圖8 所示為生成的S1 層電路,使用流水線技術對特征圖內部的像素計算進行優化,S1 層的執行時間降低為199個時鐘周期。同理,S2層的執行時間降低為29個時鐘周期。
(3)全連接層優化
本設計采用300 個神經元與8 個神經元進行全連接,對于最外層循環,使用“#pragma HLS PIPELINE”指令進行流水線優化,內部循環由系統自動展開,循環展開后能夠并行執行8次乘加操作,重疊執行不同循環的循環體能夠使用更少的硬件資源來提高整個系統的吞吐量,進一步降低系統計算時延。經過運算優化后的結果如表2所示。
3.2.4 加速器算法接口設計
本設計所實現的CNN加速IP核如圖9所示。
在ZC706 平臺中,CNN 加速器與主存儲器之間通過AXI4-Stream接口連接,使得圖像數據通過流數據的方式完成傳輸。AXI4-Stream接口與FIFO基本一致,在進行數據傳輸時不會牽扯到地址問題,因而主從設備之間能夠進行數據的不間斷傳輸。主設備之間通過握手的方式保持通信,當主設備端將發送的數據準備就緒后,主設備向從設備發出VALID 信號且一直保持該信號有效,當從設備做好接收準備時,向主設備發出READY信號,當VALID 以及READY 兩個信號同時存在時,數據開始進行傳輸,當這兩個信號一直有效時,主從設備之間將會進行數據的不間斷傳輸,當主從設備任何一端撤銷信號時,數據傳輸中斷。在Vivado HLS中,通過定義C/C++結構體來實現AXI-Stream流接口,通過結構體中的不同變量對流結構中的信號完成模擬[7]。外部IP與CNN IP 之間的數據傳輸過程通過操作不同的信號進行控制。本設計系統驗證的結果如圖10 所示,由驗證結果可知,數據的傳輸結果正確。

表2 CNN各層進行運算優化結果
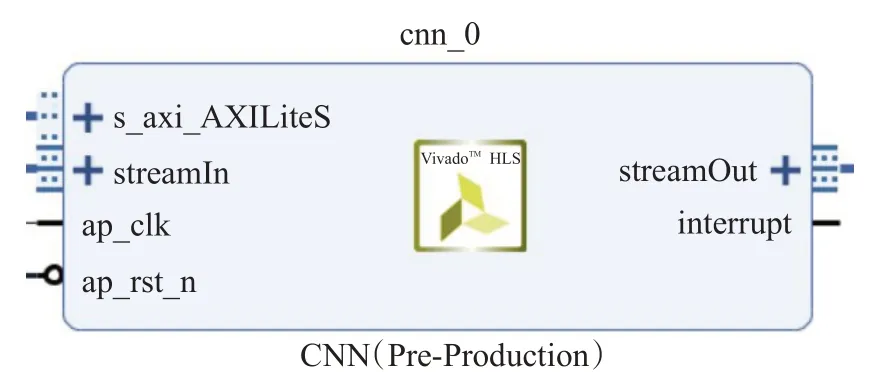
圖9 CNN加速IP核
圖10 系統驗證結果
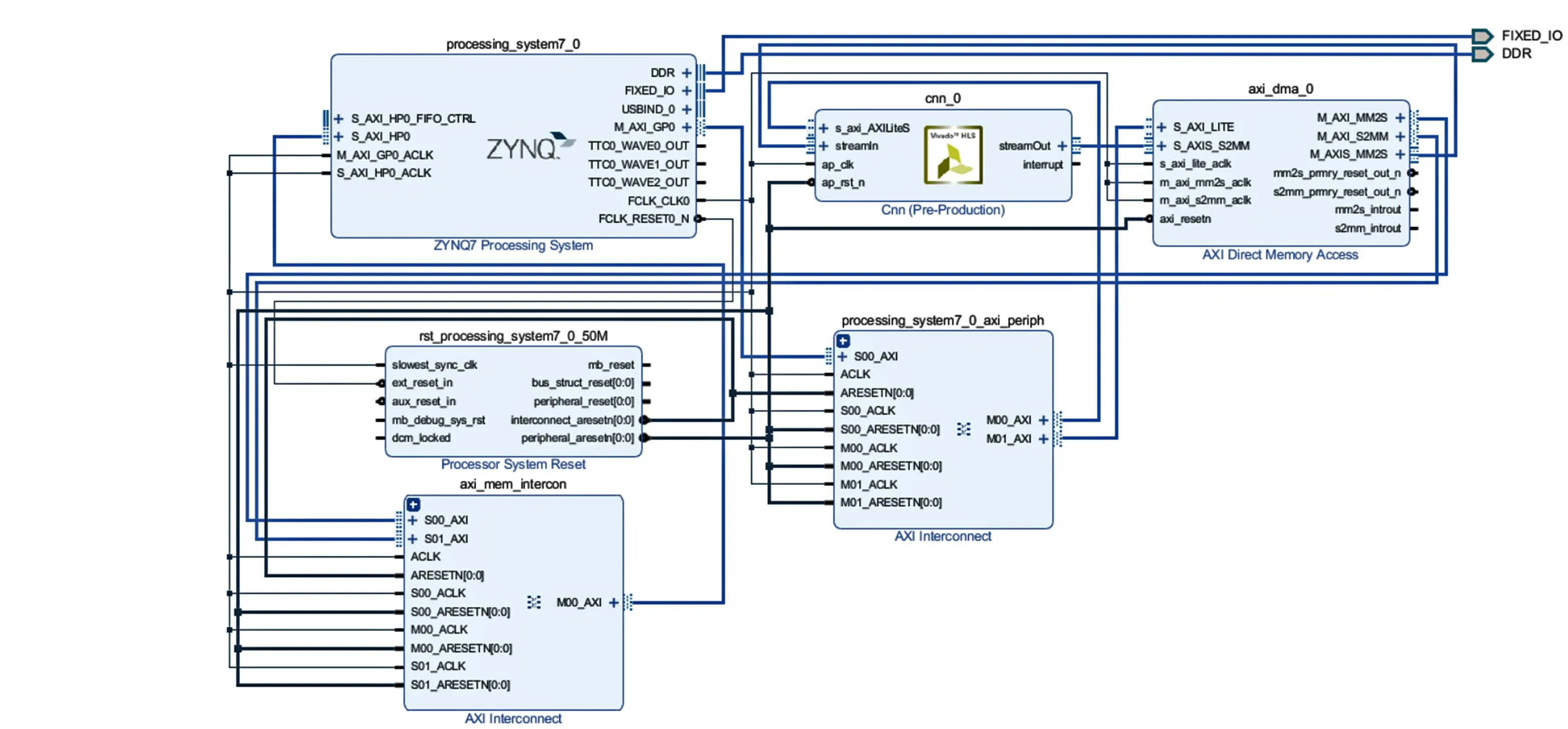
圖11 硬件連接示意圖
3.2.5 高層次綜合
在HLS中,將輸入的C/C++代碼驗證功能完整性之后,HLS 工具會將其轉化為RTL 代碼。使用HLS 優化指令對設計進行并行優化,進而得到設計回路的RTL描述以及等價的RTL模型[8]。待整個綜合結束之后,會輸出相關設計文件,同時也會產生腳本、各種日志以及測試集等,在綜合過程完成之后,通過HLS工具將RTL進行打包實現為IP 核的形式,以便后續在Vivado 設計工具中進行調用。
3.3 系統硬件設計
圖像數據采用AXI4-Stream 方式讀入,通過AXI4接口協議互聯的方式將數據傳輸到IP核并用CPU接收網絡的輸出值,對于Vivado內部封裝的IP核實現互聯,能夠使得與直接存儲器訪問(Direct Memory Access,DMA)的通信更加簡單快速。在HLS 中完成CNN IP核封裝之后將生成的IP核導入Vivado工具中完成數據通路設計[4]。本設計主要由ZYNQ 處理系統、2 個AXI互聯、AXI DMA、CNN IP 核以及處理器系統復位構成,其硬件連接示意圖如圖11所示。
圖像數據存儲于PS 端的外設DDR 中,PS 端與PL端通過芯片內部的AXI_HP高性能接口進行通信,經過AXI 互聯模塊將數據從DDR 存儲器傳輸到DMA 核的M_AXIS_MM2S接口,再通過M_AXI_S2MM接口連接到CNN加速IP核的streamIn接口,CNN IP核計算完成之后通過streamOut 接口將數據傳輸到DMA 核的S_AXI_S2MM 接口,之后再通過互聯傳回到Zynq 處理系統,完成數據的傳輸。AXI4-Stream 包含兩部分:S2MM(寫通道)和MM2S(讀通道)。CNN IP核是掛載在AXI 總線上的邏輯設備,因此需要為其分配地址空間,這樣ARM 端便可通過地址尋找到PL 端的邏輯設備,在編寫ARM程序時可以對該地址進行讀寫,實現對IP核的控制。本設計CNN IP核以及DMA核地址分配結果如圖12所示。
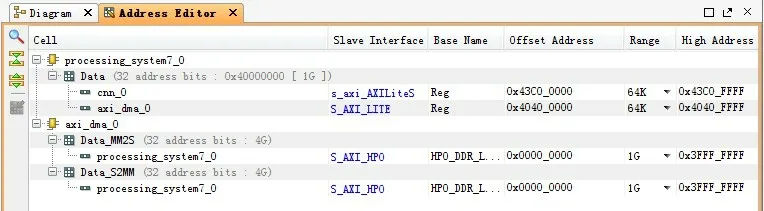
圖12 IP核地址分配結果
根據Address Editor的地址分配結果,CNN IP核以及DMA 核均分配了64 KB 長度的地址,未造成地址沖突,因此在PS端可以對其地址進行讀寫操作,實現對該IP核的正確控制。
4 實驗結果和分析
在本文設計中,將自制的40 張人臉圖像加入到ORL人臉識別數據庫中,形成了具有440張人臉圖像的數據集,其部分人臉圖像如圖13所示。

圖13 人臉識別數據集部分人臉圖像

表3 FPGA加速器性能對比
將每個樣本的人臉圖像按照4∶1 的比例對數據集進行劃分,即在Matlab R2019a 上將352 張人臉圖像用于訓練,88張人臉圖像用于測試。Matlab訓練結果和收斂曲線如圖14所示。
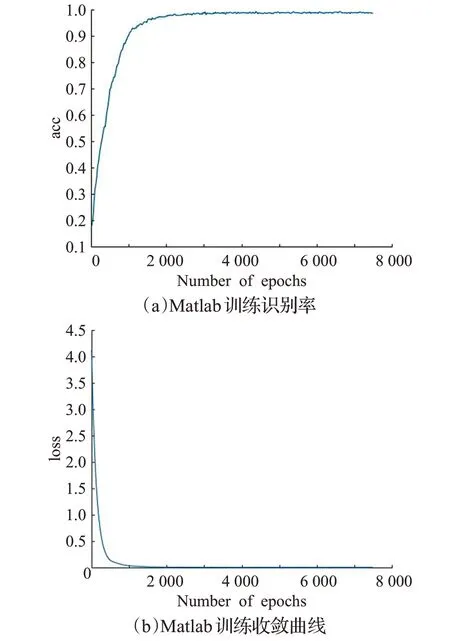
圖14 Matlab訓練結果及收斂曲線
由Matlab 訓練結果可得,當迭代次數達到7 000 次時,識別率約為98.33%并且趨于穩定。根據收斂曲線可得,當訓練迭代次數大約為2 000次時,均方誤差開始無限向0 逼近,說明該訓練過程效果較好,網絡權值趨于穩定。
加速器IP 核使用Vivado HLS 工具實現,在Xilinx ZC706 開發板上進行板級驗證,其驗證結果如圖15 所示。表3為本文FPGA加速器與其他文獻的性能對比。
圖15 板級驗證結果示意圖
根據實驗結果,本文設計的CNN 加速器識別一幅圖像僅需要0.021 ms,系統的工作頻率是200 MHz,且功耗僅為2.62 W。由于加速的CNN 網絡使用的FPGA平臺以及并行策略不同,因而不能夠直接進行性能對比。文獻[4-7]與本文的設計比較類似,均探索了在FPGA開發平臺上實現小型LeNet網絡的加速方案。通過比較,文獻[4]的能效比相對較高,但是本文在系統工作頻率以及加速器峰值性能方面優于文獻[4];文獻[5]的并行度雖然較高,但是只加速了網絡的前5 層,網絡參數較少且神經網絡規模較小,需要使用Matlab對FPGA端輸出的數據進行全連接和分類,本文設計的峰值性能為22.04 GMACS,文獻[5]的峰值性能為16.58 GMACS。文獻[8-9]只對AlexNet網絡的卷積層完成了加速,其設計的加速器峰值性能分別為61.62 GOPS和19.20 GMACS,耗時較長且FPGA資源占用率太高。
表4為本文實現的采用Xilinx嵌入式設備實現的人臉識別結果與同等網絡規模下CPU和GPU實現的結果對比。本設計通過在Matlab 平臺上對識別一幅圖像所需時間進行統計的方法來衡量CPU性能。由表4可知,在CUDA 上實現CNN 所需時間為0.646 ms,在Caffe 以及CPU上實現CNN所需時間分別為0.240 ms、2.650 ms。FPGA 加速器相比CPU 實現CNN 速度提升了126 倍,相比GPU 加速比在10 倍以上,且GPU 平臺的功耗為33 W,而本設計實現的基于FPGA 的加速器功耗僅為2.629 W。
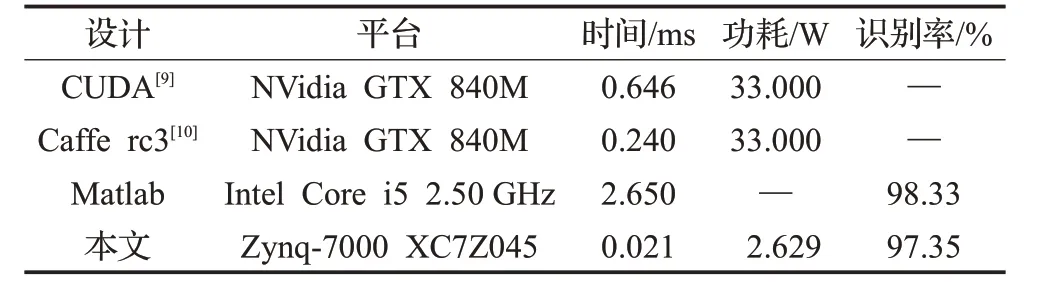
表4 人臉識別加速器結果對比
由表4 的對比結果可知,本設計在Xilinx 嵌入式設備上所實現的人臉識別加速器識別速度更高且功耗較低,并且識別率誤差不超過1%,相對于其他平臺的設計結果呈現出較為明顯的優勢,能夠滿足實際應用需求。
5 系統應用
隨著計算機視覺以及嵌入式技術的不斷發展,對于機器學習算法的可實現性要求越來越高[11-13],嵌入式產品本身就十分關注系統的功耗問題,功耗的高低直接決定了系統性能的好壞。本文在Xilinx 公司的嵌入式設備上完成了人臉識別加速器設計,相對于其他文獻設計成果,在功耗以及系統識別時間方面占據優勢,且識別誤差率不足1%,對于該技術的產品化提供了理論以及技術支撐[14-15]。本文所實現的基于FPGA的人臉識別加速器系統能夠應用于如機場、車站等許多人臉識別的場合,具備一定的硬件可實現性[16-17]。
6 結束語
本文提出了一種基于FPGA 的卷積神經網絡加速器的設計方法。首先針對與加速器設計有關的HLS 工具及其提供的優化指令進行介紹,結合ZC706異構開發平臺的特性,主處理器由PS部分實現,網絡加速模塊由PL部分實現。在HLS工具中運用存儲優化、定點量化、運算優化、接口設計等優化技術對LeNet-5 網絡進行優化,通過C 仿真、高層次綜合實現了7 層CNN 加速器設計,與該領域其他卷積神經網絡的CPU、GPU 和FPGA實現的結果進行對比,本設計實現的人臉識別神經網絡加速器的加速比在10倍以上,且所需功耗僅為2.629 W,識別一幅人臉圖像僅需0.021 ms,實現了較高的系統性能。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
作文中學版(2022年1期)2022-04-14 08:00:34
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
學生天地(2020年31期)2020-06-01 02:32:06
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
計算機工程(2015年8期)2015-07-03 12:19:07
