基于深度學習的個性化音樂推薦算法研究
2020-11-13 03:38:57余莉娟
微型電腦應用 2020年10期
余莉娟

摘要:互聯網技術和電子信息技術的迅速發展為整個時代提供了巨大的計算能力,個性化推薦系統成為時代產物的縮影。結合常用的推薦系統核心算法,設計了一種針對個性化音樂的Apriori改進算法,此算法通過用戶信息進行深度學習,利用候選矩陣壓縮的方法進行推薦優化,采用準確性、召回率等參數作為評價標準。以Last.fm音樂網站的部分數據作為分析樣本,對選定音樂按個性化音樂推薦方式進行試驗,Apriori改進算法在準確率和召回率方面均得到優化,推薦效果更優。在考慮推薦數量的前提下,Apriori改進算法的準確率和召回率均高于Plaucount算法,而相似度方面低于Plaucount算法。
關鍵詞:深度學習;推薦系統;個性化;音樂
中圖分類號:G643
文獻標志碼:A
ResearchonPersonalizedMusicRecommendationAlgorithmBasedonDeepLearning
YULijuan
(CollegeofArt,ShangluoCollege,Shangluo726000,China)
Abstract:RapiddevelopmentoftheInternettechnologyandelectronicinformationtechnologyhasprovidedhugecomputingpowerforthewholeera,andpersonalizedrecommendationsystemhasbecometheepitomeoftheproductoftheera.Combinedwiththecommoncorealgorithmofrecommendationsystem,thispaperprovidesanimprovedApriorialgorithmforpersonalizedmusic.Thisalgorithmappliesuserinformationforindepthlearning,candidatematrixcompressionforrecommendationoptimization,accuracy,recallrateandotherparametersasevaluationcriteria.TakingpartofthedataofLast.fmmusicWebsiteastheanalysissample,theselectedmusicistestedaccordingtothepersonalizedmusicrecommendationmode.TheAprioriimprovedalgorithmisoptimizedinaccuracyandrecallrate,andtherecommendationeffectisbetter.Onthepremiseofconsideringthenumberofrecommendations,theaccuracyandrecallrateofAprioriimprovedalgorithmarehigherthanthatofPlaucountalgorithm,andthesimilarityislowerthanPlaucountalgorithm.
Keywords:deeplearning;recommendationsystem;personalization;music
0引言
伴隨著互聯網技術和電子信息技術的迅速崛起,大數據技術、云計算技術、機器人技術、人工智能技術、深度學習技術[1]等方面的發展尤為突出,對整個信息時代的進步與發展提供了巨大的計算能力。在如此海量的信息中,快速準確地找到所需信息變得越來越重要,而且有價值。由此而誕生的推薦系統[23]成為了用戶需求與內容之間的橋梁,既可以滿足用戶找到感興趣的潛在內容,也能夠更好地展示冷門內容,發掘潛在用戶。
當今社會已擁有更為強大的包容性,不同領域也均呈現出獨有的個性化和多元化,個性化推薦系統則能夠滿足不同用戶的需求,精準地為用戶提供更好地體驗,由此產生了巨大的商業價值,成為互聯網企業爭相搶奪的“蛋糕”。
目前,個性化推薦系統早已得到廣泛認可,并悄然融入到我們的生活中。音樂作為一種古老的藝術形式,能夠為人們帶來愉悅,但從海量的音樂作品中精準地找到滿足用戶需求的音樂,則需要個性化音樂推薦系統根據用戶行為篩選適合用戶的個性化音樂,滿足用戶在當時情景的需求,從而達到“眾口可調”的目的。
1推薦系統及核心算法
電子商務領域的推薦系統應用最為廣泛,隨著互聯網在各領域的不斷滲透發展,音樂推薦系統也映入眼簾,根據用戶偏好、音樂描述信息等內容構建推薦模型,將滿足用戶需求的音樂內容推送出來。目前,常用的推薦方法主要分為基于內容的推薦方法、協同過濾推薦方法和混合推薦方法三種類型[4]。
(1)基于內容的推薦算法[5]
該方法為一類傳統的推薦方法,其基本思路就是根據用戶的歷史信息,對用戶的偏好行為進行特征分析,得到用戶偏好集合,將這些集合與代推薦內容進行信息匹配,從而實現推薦。常用的音樂推薦算法有基于標注內容的推薦算法和基于音樂特征的音樂算法[6]。
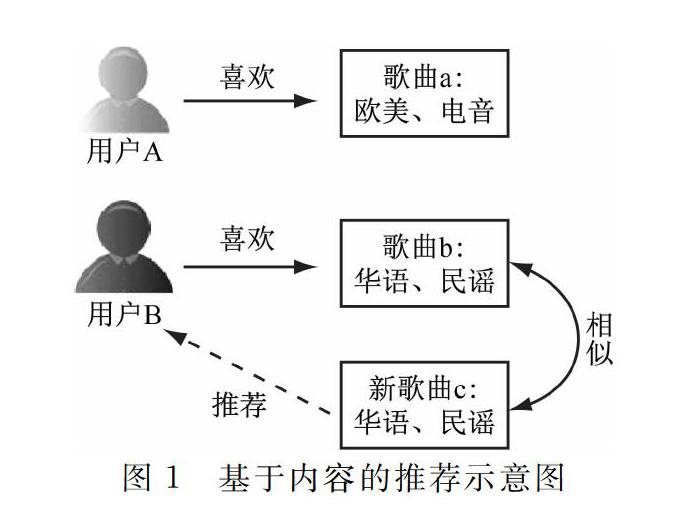
以基于音樂標注內容的推薦算法為例,用戶A和用戶B對音樂的偏好類型分別為歐美、電音和華語、民謠,其中歐美、電音、華語、民謠均代表歌曲的風格和類型,當新歌曲c出現時,華語和民謠就成為該歌曲的標注內容,屬于特征信息,推薦系統則會根據這些特征信息優先向用戶B推薦,從而實現精準推薦,如圖1所示。
(2)協同過濾推薦算法
鑒于協同過濾算法具有普遍適應性的特點,該算法被廣泛應用于眾多領域。利用用戶偏好的相同性或相似性進行內容推薦是該算法的核心思想。協同過濾推薦算法主要包含基于用戶的協同過濾推薦算法、基于物品的協同過濾推薦
算法和基于模型的協同過濾推薦算法3種類型[7]。
以基于用戶的協同過濾推薦算法為例,用戶A、C在歌曲偏好的相似程度更高,如圖2所示。
推薦系統首先了解到兩位用戶對歌曲偏好的歷史數據,再利用數據挖掘或深度學習的方式建立預測模型,雖然用戶A沒有關注歌曲d,但推薦系統仍可將歌曲d向用戶A實行預測推薦。
(3)混合推薦算法
單一的推薦算法在使用過程中都存在不足和局限性,很難滿足準確推薦的要求。隨著用戶個性化要求的日益嚴苛和數據量的激增,需結合多種推薦算法發掘用戶信息和需求信息之間的相關性。目前混合推薦算法的發展方向主要有加權的混合、切換的混合、融入其他因素的混合和分層混合四種[68]。
1)加權的混合如式(1)。
fu,i=α1s1u,i+α2s2u,i+…+αnsnu,i
(1)
式中:u——任一用戶;
i——任一物品;
αn——不同的權重系數;
sn——不同的推薦算法。
2)切換的混合如式(2)。
fu,i=β1u,is1u,i+β2u,is2u,i+…+
βnu,isnu,i
(2)
式中:β1u,i——用戶u推薦物品i時,snu,i所占的比重。
3)融入其他因素的混合如式(3)。
fu,i=∑nj=1λjsju,i,e1,e2,…,ek
(3)
式中:ek——需要特別考慮的因素。
4)分層的混合如式(4)。
fu,i=g∑nj=1λjsju,i
(4)
式中:g()——外層嵌套推薦算法;
∑nj=1λjsju,i——內層推薦算法,加權、切換或融入其它因素的混合。
2個性化音樂推薦方法
2.1改進的Apriori算法原理
關聯規則主要應用于數據挖掘中發掘用戶行為,最早由Srikan提處[8],已在教育、保險等眾多領域內得到廣泛應用。Apriori算法是關聯規則挖掘算法中的基本類型之一,屬于一類頻集理論遞推的方法,主要依靠“頻繁項集的所有非空子集必定是頻繁的”[9]這一性質得以實現。
Apriori算法通常是在首次循環實現對數據庫的掃描后得到1階大項集;在后續的第k次循環中對k-1階大項集Lk-1(第k-1次循環時產生)進行Apriori_gen運算,從而得到Ck,即k階候選項集;繼續對數據庫進行掃面后得到Ck的支持數,進一步會得到不小于最小支持數的k階大項集;對上述步驟進行重復,當出現某一階的大項集為空時,算法則會停止。
Apriori算法的詳細過程如下:
L1=large1-itemsets;
fork=2;Lk-1≠φ;k=k+1do
Ck=Apriori_genLk-1;//構造候選項集
Foralltransactionst∈Ddo
Ct=subsetCk,t;//搜索事物t中包含的候選項集
ForallC∈CtdoC.sup=C.sup+1;Endfor//計算支持數
Endfor
Lk=C∈CkC.sup≥minsup;//得到k階大項集
Endfor
L=∪kLk
Apriori算法同其他算法一樣,也具有自身的優缺點。優點在于當支持度較高時,數據庫的掃描次數會較少且空間復雜程度低,缺點就是在數據庫掃描過程中會產生海量的候選集,存在重復掃面的現象出現。由于Apriori算法存在耗時長、效率低的劣勢,本文通過候選矩陣壓縮的方法進行了優化,在準確性和效率方面均有所提升。具體步驟如下:
1)掃描整個音樂數據庫得到事務矩陣D;
2)對矩陣中的事務信息進行編碼、排序處理,記錄為一行,對于小于閾值的項進行刪除,得到只含0和1的d1,d2,d3,…,dn;
3)將矩陣H分解并升序排列為H1,H2,H3,…,Hm;
4)掃描列向量Dm,并對dnm進行判斷;
5)若dnm=1,則取前m項(含dnm在內)形成子矩陣Hm,如式(5)。
M1M2M3M4M5M6
H=110001011000110100101011010011110011000011T1T2T3T4T5T6T7
(5)
假設支持度閾值為2,則得到的個性化音樂事務如表1所示。
與權重相結合,得到子集Ti的支持度如式(6)。
SupportTi=1l∑j∈tiwj×SupportTi
(6)
其中,l表示Ti的長度。
計算得到列向量和行向量分別為4,5,2,1,4,5T和3,2,3,4,3,4,2,經降序排列得到矩陣H′,如式(7)。
M2M6M1M5M3M4
554421
H′=1100010110001101001010110100111100110000114433322
(7)
將行列和不滿足支持度閾值2的項處理后,得到矩陣H″,如式(8)。
M2M6M1M5
5544
H″=111101011110101011010101
(8)
矩陣H″經分解處理后可知,M2、M6和矩陣H″經分解處理后可知,M2、M6和M2、M1具有很強的關聯性。實際情況下,如果M2屬于用戶的關注音樂作品,即使M6、M1與M2缺乏內容上的相似性,也會因強關聯性而被推薦給用戶。
2.2個性化音樂推薦方法
個性化音樂推薦的第一步計算用戶的興趣度。為了方便計算,需先對音樂庫中樂曲進行分類編號,則用戶在第i類歌曲中第j首歌曲的欣賞時間占音樂欣賞的總時間比如式(9)。
ρij=tij-αijβij-αij
(9)
式中:βij為收聽時間最大值,αij為收聽時間最小值,tij的取值如式(10)。
tij=αij,t′ij≤αij
t′ij,αij≤t′ij≤βij
βij,t′ij≥βij
ρij,t′ij∈R,收藏歌曲
(10)
根據公式(9)中用戶對不同音樂收聽時間比例,則可計算用戶對i類音樂的興趣度,其計算如式(11)。
Inti=∑mj=1tij∑ni=1∑mj=1tij
(11)
獲取用戶興趣度后,利用音樂本身標簽等音樂信息和基于用戶興趣的音樂標簽之間的對應關系,通過音樂信息預測和用戶興趣度計算的方式,從音樂庫中將強關聯性的音樂向用戶進行推薦,滿足用戶的個性化需求,總體推薦流程,如圖3所示。
3試驗結果評估分析
(1)樣本數據集及試驗環境
為了減小數據采集對試驗結果造成的誤差,必須選用一個含有足夠數據量的數據庫,且各類算法的數據采集均出自于相同數據庫。因此本文選用了公開的Last.fm音樂網站數據,目前該數據庫已包含近40萬條用戶記錄,且該數據庫
能夠支持用戶進行自定義標簽,方便對數據進行標定。本次試驗隨機選取4281條用戶記錄,其中包含音樂信息245314條和音樂標簽14263個,利用數據處理軟件TRIFACTA軟件對數據庫進行信息統計分析后得到標簽分布情況如圖4所示。
由于本次試驗是對不同推薦系統推薦效率的橫向對比,因此對比試驗的外部環境應該是相同的,試驗的外部環境,如表2所示。
(2)試驗結果評價標準
本文是從評價的準確性作為結果評價的首要標準,在準確性相同時引入結果多樣性指標作為評價的輔助標準。根據相關研究[10],推薦系統的準確度評價標準分類較多,各種分類標準間各有優勢和不足,而本文的準確度評價采用了目前較為普遍的準確率和召回率兩個定量指標,如式(12)、式(13)。
準確率=∑u∈URu∩Tu∑u∈URu
(12)
召回率=∑u∈URu∩Tu∑u∈UTu
(13)
式中:Ru——系統向用戶u推薦音樂集;
Tu——用戶u感興趣的原有音樂集;
U——用戶集。
在某些算法中,這兩個定量指標在面對特定的數據集時的計算結果十分相近,難以對計算準確度進行客觀評價,因此本文參考相關文獻[1012],在計算準確度基礎上引入結果多樣性指標,如式(14)。
Simu,r=∑ti∈M(r)Mti1+countr∈Mti
(14)
式中:ti——音樂標簽;
Mti——采用音樂標簽ti標注的音樂集;
1+countr∈Mti——采用音樂標簽ti的總數。
(3)試驗結果分析
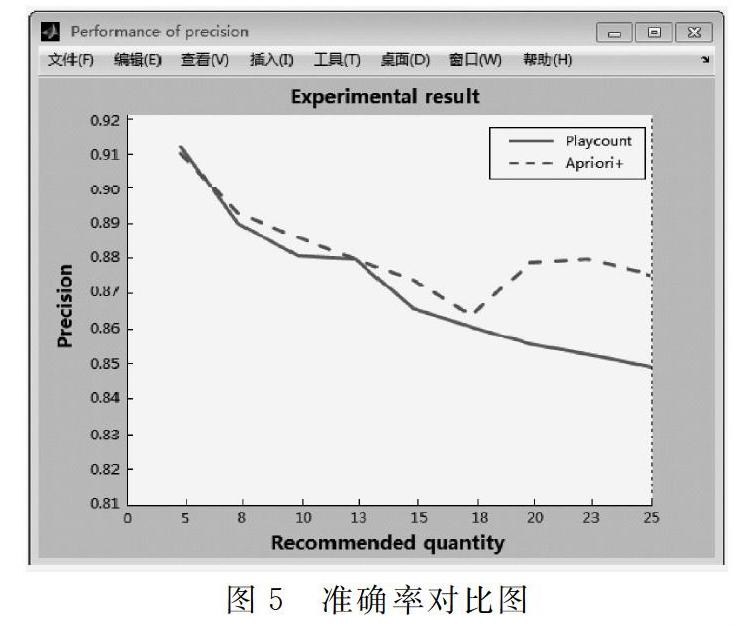
通過調查分析,目前較為受歡迎的軟件大多采用Plaucount算法,因此本文采用Plaucount算法與改進的Apriori算法進行推薦對比分析,并以準確率及召回率為判斷標準,得到的試驗結果如圖5、圖6所示。
從圖5可以看出,當音樂推薦次數不超過18次時,Plaucount算法和改進的Apriori算法在準確率方面相差不大;當音樂推薦次數超過18次時,改進的Apriori算法在準確率方面則會顯著優于Plaucount算法;對比結果表明,當音樂推薦次數相同且達到一定數量時,改進的Apriori算法的推薦效果明顯優于Plaucount算法,更容易滿足用戶的個性化要求。
從圖6可以看出,改進的Apriori算法在召回率方面優于Plaucount算法,表明改進的Apriori算法推薦的音樂在數量方面也高于Plaucount算法,更容易成為用戶感興趣的音樂。
在音樂推薦系統中,過多或過少的音樂推薦均得不到理想的效果。推薦結果過多,則需用戶在推薦音樂中進行二次篩選,系統推薦得不到認可,用戶滿意度會降低;推薦結果過少,則會出現篩選遺漏的現象,將用戶感興趣的內容直接過濾掉,造成內容缺少,達不到理想的推薦效果,如圖7所示。
從圖7可以看出,改進的Apriori算法在相似度方面低于Plaucount算法,表明改進的Apriori算法在推薦音樂時充分考慮了用戶興趣的相似性,在音樂相似性的冗余度方面做了考慮,實現了音樂推薦的多樣化,避免出現篩選遺漏現象,相比于Plaucount算法,推薦結果的同質化相對較弱。
4總結
本文在概括介紹推薦系統常用的核心算法的基礎上,結合個性化音樂推薦提供了Apriori算法的改進應用,并給出了基于深度學習的個性化音樂推薦的具體流程。通過選取Last.fm上的部分數據作為樣本,經對比分析后得到如下結論:
(1)以推薦準確度為計算標準,采用候選矩陣壓縮的方法對Apriori的計算原理進行了分析,在此基礎上設計了個性化音樂推薦的流程。
(2)考慮到推薦數量對推薦效果的影響,將改進的Apriori算法與Plaucount算法對比可知,在準確率和召回率方面,改進的Apriori算法均優于Plaucount算法,表明改進的Apriori算法推薦的音樂能容易滿足用戶需求;在相似度方面,改進的Apriori算法則低于Plaucount算法,表明改進的Apriori算法的推薦在考慮了用戶興趣的基礎上實現音樂推薦的多樣化。
參考文獻
[1]徐正巧,趙德偉.深度學習理論視角下的移動學習推薦系統的設計和研究[J].智能計算機與應用,2014,4(2):5758.
[2]GoldbergD.Usingcollaborativefilteringtoweaveaninformationtapestry[J].CommunicationsoftheACM,1992,35(12):6170.
[3]EpplerMJ,MengisJ.Theconceptofinformationoverload:Areviewofliteraturefromorganizationscience,accounting,marketing,MIS,andrelateddisciplines[J].TheInformationSociety,2004,20(5):325344.
[4]鄧騰飛.個性化音樂推薦系統的研究[D].廣州:華南理工大學,2018.
[5]朱志慧,田婧,林捷.大數據環境下基于用戶位置的個性化音樂推薦系統設計[J].無線互聯科技,2019,16(2):7980.
[6]艾筆.個性化音樂推薦系統的設計與實現[D].成都:電子科技大學,2018.
[7]楊凱,王利,周志平,等.基于內容和協同過濾的科技文獻個性化推薦[J].信息技術,2019,43(12):1114.
[8]黃立威,江碧濤,呂守業,等.基于深度學習的推薦系統研究綜述[J].計算機學報,2018,41(7):16191647.
[9]陳波.基于Apriori算法及其改進算法綜述[C].中國通信學會第五屆學術年會論文集.江蘇南京:中國通信學會,2008(2):176181.
[10]李臻.應用于音樂節目分類的Apriori挖掘算法設計[J].現代電子技術,2019,42(19):9094.
[11]王彩強,趙憲中,劉涌,等.大數據環境下改進的Apriori算法研究[J].科技通報,2019,35(7):182185.
[12]AgrawalR,ImielińskiT,SwamiA.Miningassociationrulesbetweensetsofitemsinlargedatabases[J].ACMSIGMODRecord,1993,22(2):207216.
(收稿日期:2020.02.25)
猜你喜歡
小天使·一年級語數英綜合(2020年3期)2020-12-16 02:56:12
藝術啟蒙(2018年7期)2018-08-23 09:14:16
兒童繪本(2017年24期)2018-01-07 15:51:37
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
東方藝術·大家(2016年6期)2016-09-05 07:30:56
