基于網頁挖掘的網頁作弊檢測技術
2020-11-12 12:38:32聶韶華
韶關學院學報 2020年9期
焉 凱,聶韶華
(1.萊蕪職業技術學院 信息工程系,山東 濟南 271100;2.臨沂大學 教育學院,山東 臨沂 276000)
網頁挖掘技術,就是采用數據挖掘技術來發現網頁中的蘊含模式(包括文檔、服務等).包括網頁內容、網頁結構和網頁使用方法[1].
近年來基于社會網絡的研究受到很多專家學者的重視,相關的研究也層出不窮.搜索引擎模仿了社會網絡研究的算法技術,搜索引擎在商業上取得的龐大收益,意味著社會網絡研究技術在網頁挖掘中的巨大潛力.經進一步研究發現,當前的搜索引擎在處理用戶查詢之時,也存在一個比較嚴重的問題,即便搜索引擎能分析出用戶的真是想法,它們仍然會返回一些與查詢無關的網頁信息[2].究其原因,一方面是搜索引擎自身的缺陷,確實找不到相關信息;另一方面就是網頁作弊,它在一定程度上影響了用戶的搜索意圖.
1 網頁作弊概述
網頁作弊是指采用一些欺騙搜索引擎的的方法(如改變網頁內容或者網頁之間的結構等),而不是通過提高網頁的信息含量的方式,來取得相對靠前的網頁排名,增加網頁的點擊率.
為研究方便先界定2個相關概念.網頁重要性:相對整個互聯網而言,某個網頁的受歡迎程度(與查詢無關).網頁相關性:網頁與某個查詢的相關程度.
1.1 基于內容的網頁作弊
基于網頁內容的作弊,也稱為基于文本的作弊,是通過修改網頁上的文本信息(包括背景色或者圖像等)來增加網頁相關性.此種作弊主要利用搜索引擎中文本相似性度量算法TFIDF的局限性來達到作弊的目的.TFIDF算法中的TF是指某個詞在文本中呈現的頻率.例如,“和平”在5 000個單詞的文章中出現了 300次,那么 TF(“和平”)=300/5 000=0.06 . IDF 是倒排文檔頻率,例如在 1 000篇文章中,單詞“和平”出現在其中200篇文章里.那么,IDF(“和平”)=1 000/200=5.因此,相對查詢Q,網頁P的TFIDF值的計算方法為:

上式中t代表查詢Q和網頁P共同出現的那個單詞.根據這個公式,作弊者(Spammer)有2種方式來提高網頁的訪問率.一是讓網頁包含各種單詞,從而對任何查詢,這個網頁的TFIDF值都不為零;二是針對特定的查詢,重復某些關鍵字,提高網頁的TFIDF值[3].
1.2 基于鏈接的網頁作弊
基于鏈接的網頁作弊是人為制造網頁之間的關聯性,以此來彰顯網頁的重要性.目前很多搜索引擎就是運用分析網頁之間的關聯性,來判定網頁的重要性.基于鏈接的網頁作弊手段,常見的有兩種:(1)提高出度(out-degree),以增加Hub值.例如,把雅虎中一些網站的鏈接復制到當前網頁中.(2)增加網頁的入度(in-degree),以提高PageRank值或者Authority值.例如,制作一個蜜罐(honey pot)網站,吸引用戶.其典型算法有PageRank算法、HITS算法兩種[4].
1.3 基于隱藏技術的網頁作弊
基于隱藏技術的網頁作弊手段是把用戶的關注點和搜索引擎的關注點區分開來,分別給兩者提供不同的信息.例如,作弊網頁提供給搜索引擎很多的關鍵字以使作弊網頁能獲得檢索.當用戶瀏覽網頁的時候,作弊網頁能巧妙地屏蔽這些關鍵字提供給用戶與查詢無關的廣告信息.
2 基于內容的網頁作弊檢測技術
基于內容的網頁作弊檢測技術,主要是通過比較正常網頁和作弊網頁在某些統計值上的差異,再運用這些不同值來檢測網頁是否存在作弊.
2.1 常規統計分析
利用MSN搜索引擎抓取網頁,使用了決策樹、規則分類、神經網絡和支持向量機等方法來區分作弊網頁和正常網頁,發現基于決策樹的C4.5算法效果最好,網頁作弊的召回率(Recall)和準確率(Precision)都在80%以上[5].接著融入了Bagging和Boosting算法來提高C4.5算法的效果,其中Boosting算法能夠使得作弊網頁的召回率(Recall)和準確率(Precision)提高到90%左右.而C4.5、SVM、Bagging和Boosting算法在開源軟件Weka中都有,雖然思路明確,流程清晰,但用于檢測作弊網頁的文本特征不多,且沒有考慮網頁之間存在的這種關系.
2.2 語言特征分析
借助兩個自然語言處理工具——Corleone和General Inquirer來計算網頁的特征.使用的數據集是“Webspam-UK2006”和“Webspam-UK2007”,這兩個數據集中大部分網頁都是HTML格式,他們只標注了網站(Host)是否是作弊的,而沒有具體到某個網頁是否是作弊的.因此,利用廣度優先數據搜索策略,分別從這兩個數據集中的每個網站(Host)提取400個頁面,然后以人工方式把各個網頁標記為3類:作弊網頁、正常網頁和無法確定類標簽(borderline).總共計算了208個語言屬性特征,按照網頁中標識符(token)的個數,抽取3類網頁做實驗:(1)在5萬標識符以下的網頁;(2)15萬~20萬標識符的網頁;(3)400萬 ~5 000 萬標識符的網頁[6].
實驗發現某些語言屬性對于區分作弊網頁和非作弊網頁還是很有幫助的.筆者提出兩種用于評價區分(作弊網頁和正常網頁)能力好壞的指標.
(1)絕對值差異:對于屬性h,定義代表屬性h的取值范圍,為作弊網頁在屬性h取值為i時表現出來的統計特征.相應地,代表正常網頁在屬性h取值為i時表現出來的統計特征.于是屬性h區分作弊網頁和正常網頁的能力定義為:

語言特征分析雖然做了很多基礎性的工作,卻沒有進一步討論如何有效地利用這些統計值來檢測作弊網頁.筆者認為,可采用常規統計分析的分類方法來區分作弊網頁和正常網頁.綜合采用常規統計分析和語言特征分析給出的統計指標,能夠更準確地檢測出作弊網頁.
3 基于鏈接的網頁作弊檢測技術
基于網頁鏈接的作弊行為,目標比較單一.一般都是通過增加網頁的入度來獲得較高的優先率.而且相關的研究也都集中在網頁排名算法上面,試圖提出一些改進措施,以減少基于鏈接的網頁作弊不良行為[7].筆者主要探討3種典型的基于網頁排名的算法改進.
3.1 TrustRank算法
假設作弊網頁的信息含量很低,正常網頁通常不會引用作弊網頁,于是如果剛開始挑選一批信譽良好的網頁,沿著它們的超鏈接出發,尋找其它網頁,由此找到的網頁也就會是用戶需要的網頁.一種理想的情況是,如果知道某個網頁是正常網頁,那么它的信任指數T(p)就設置為1;否則就設置為0.然而有時候事情并不是那么絕對,在運用算法來判別某個網頁是不是作弊網頁時,通過設置一個閾值δ,如果某個網頁的信任指數T(p)^δ,那么就可以認為這個網頁是可信任的. PageRank算法的公式可以簡寫為:

其中r為N×1的矩陣,代表每個頁面的網頁排名,T為各節點出度的轉移概率矩陣的轉置,為每個項都是1的N×N矩陣,為調整因子(decay factor),一般取為0.85.而TrustRank 的形式為:

其中d為N×1的矩陣,代表每個網頁的信任指數.
TrustRank算法的關鍵流程是:(1)選取種子:即選取一些信譽良好的網頁,計算各個網頁的信任指數;(2)結合各個網頁的信任值,來計算各個網頁的排名(即TrustRank值).
實驗證明,TrustRank比PageRank更能識別那些信譽良好的網頁.所以在TrustRank算法中,關鍵是挑選種子集合,如果種子集合的分布不夠廣泛或不具有代表性,那么這種算法會漏掉很大一部分正常的網頁,這也是TrustRank算法常遭人指責的地方[8-9].
TrustRank會對大規模的網頁社區有所偏重,因此把TrustRank算法中的種子集合按照不同的話題(topic),劃分成多個種子集合,按照話題類別分別計算各個網頁在不同話題下的信任指數,最后再給各個話題賦以不同的權重,獲得每個網頁綜合的信任指數.實驗結果發現,TrustRank算法能克服PageRank算法的不足,取得較好的效果.
3.2 類似BadRank算法
類似BadRank算法與TrustRank算法很相近,只是把TrustRank算法中的信任(Trust)指數改為危害(Bad)指數,即把公式(4)的d矩陣替換了一下.直觀理解就是,如果某個網頁是作弊網頁,那么它會關聯到其它的作弊網頁,形成一個作弊網頁群(spam farm).只要能夠找出作弊網站群,不對它們建立索引或者把它們的網頁排名值降低,就可以減少由它們帶來的危害.
總體流程:(1)選取種子集合:即獲取初始作弊網頁集合;(2)擴充危害指數:把種子集合中的危害指數擴充到其它網頁;(3)把危害指數整合到PageRank或者HITS排名中,獲得各個網頁的最終排名.筆者重點介紹流程(1)和(2).(1)選取種子集合.文獻中認為作弊網站群內的網頁之間會形成很稠密的相互引用關系,也就是某個作弊網頁P指向的網頁集合Do和指向作弊網頁P的網頁集合Di會包含很多相同的網頁.于是,如果某個網頁的Do和Di含有3個及3個以上相同的網頁,則把網頁P認為是作弊網頁,否則暫時認為P是正常網頁.(2)擴充危害指數.如果某個網頁P指向的網頁中有很大一部分是作弊網頁,那么網頁P是作弊網頁的幾率也不小.于是,類似BadRank算法設置一個閾值T=3,如果某個網頁P指向的網頁中有3個已經被認定為作弊網頁,那么網頁P也是作弊網頁.
實驗結果發現,類似BadRank算法中的方法確實能夠有助于發現作弊網頁.但也可能會把一些正常網頁當成是作弊網頁.例如,政府網站之間會存在較多的相互引用,根據類似BadRank算法,很可能就把政府的某些網頁當成是作弊網頁了[10].
3.3 Truncated PageRank 算法
Truncated PageRank算法的假設是:通常沒有正常網頁會指向作弊網頁,作弊網頁主要是通過與作弊網頁群(spam farm)內的其它網頁形成強聯通關系獲得較高的PageRank.于是,Truncated PageRank算法提出若臨近網頁之間的引用關系不對網頁的排名產生效益,就可極大地消除作弊網頁群的影響.
Truncated PageRank算法先定義了網頁之間引用的距離.例如,網頁A指向了網頁B,網頁B指向了網頁C,那么A和B都算作是網頁C的支持者(supporter),并且B到C的距離為1,A到C的距離為連接這兩個網站的最短距離,若A只能經過B網頁到達C,那么A到C的距離就為2.
若想讓距離在T之內的網頁間引用產生的效果盡可能地小,那么就不記錄PageRank算法在前T次迭代形成的Rank值,而把第T+1次及其以后各步計算得到的Rank增益值添加到各個頁面的Rank值中.在迭代過程中,每執行一步,Rank增益值就乘以一個調整因子α(α值小于1).此時Truncated PageRank算法有不足之處.例如:存在3個網頁A、B、C,它們兩兩之間相互引用,并且不連接其它任何網頁,那么它們最終的Rank值與T毫無關系.相比PageRank算法,Truncated PageRank算法有一定的優越性[11].
4 基于用戶行為的網頁作弊檢測技術
基于用戶行為的網頁作弊檢測技術,就是通過比較用戶在瀏覽正常網頁和作弊網頁時的行為特征,發現差異,從而提取一些規則用于檢測作弊網頁.這種作弊檢測技術跳出了基于內容或者基于鏈接的檢測分析框架,能夠檢測出各種類型的網頁作弊手段(包括基于內容、鏈接和隱藏技術),是一種新穎的方法[12].用戶是瀏覽網頁的發起者,同時又是接收者,用戶會根據自己的需要打開合適的網頁.因此,可以通過用戶行為表露出來的對網頁的評價,來判斷某個網頁是否存在作弊(見圖1~圖4).其中,圖1~圖4的縱軸代表百分比,對應的藍色條形圖代表正常網頁的百分比,紅色條形圖代表作弊網頁的條形圖;橫軸隨各圖表達的含義略有不同.
4.1 基于搜索引擎的訪問率
用戶訪問網頁一般有以下幾種方式:朋友或者信譽度比較好的廣告告知某個網站,瀏覽器的標簽或歷史記錄,當前網頁內用戶感興趣的鏈接,或者搜索引擎.如果是作弊網頁,那么用戶一般也只有通過搜索引擎去訪問.因此定義某個網頁P基于搜索引擎的訪問率SEOV(Search Engine Oriented Visiting Rate)為:搜索引擎訪問網頁P的次數/頁面P被訪問的次數.可以想象,如果某個網頁是作弊網頁,那么它的SEOV也越大,見圖1.
4.2 源網頁概率
某個網頁P作為源網頁SP(Source Page)的概率,定義為通過網頁P訪問其它網頁的次數/網頁P出現在網頁訪問rizhi日志中的次數.一般情況下,用戶一旦發現某網頁是作弊網頁,那么恨不得馬上關閉網頁,也就不會再去點擊作弊網頁中的超鏈接,見圖2.
4.3 短期導航率
如果某網站是作弊網站,那么用戶一般不會在這個網站內部訪問太多的網頁.所以,定義網站s的短期導航率SN(Short-time Navigation rate)為:在網站s內訪問了少于N個網頁的會話次數/訪問網站s的會話次數.容易理解,如果SN越大,網站s是作弊網站的可能性也就越大,見圖3.

圖1 搜索引擎訪問率

圖2 源網頁概率
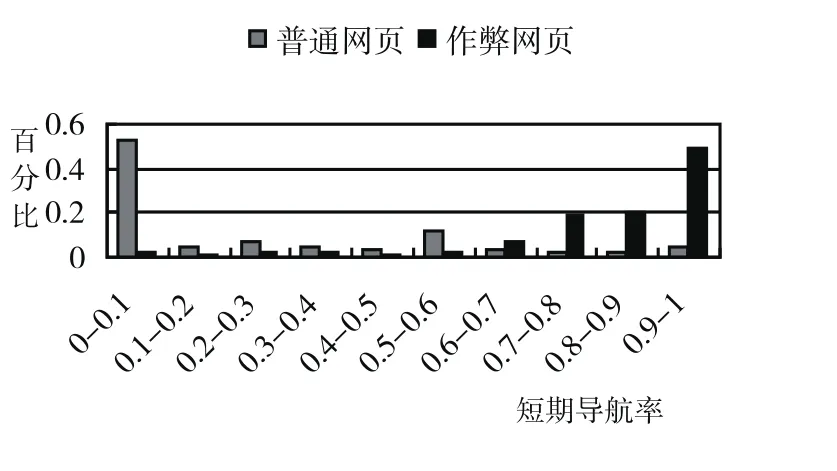
圖3 短期導航率
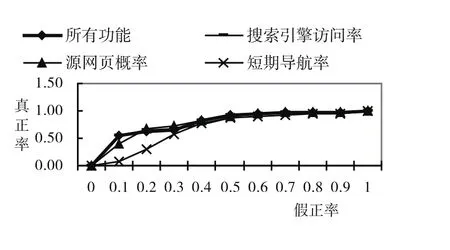
圖4 ROC曲線
選取以上3個指標(SEOV,SP和SN),采用樸素貝葉斯分類方法,構造ROC曲線.發現如果綜合這3個指標,得到的AUC的值為79.26%,也就是說可以以79.26%的概率使得正常網頁獲得比作弊網頁更好的排名[13],見圖4(其中深藍線代表了3個指標,灰線代表SP,粉紅線代表SEOV,紅線代表SN).
總之,從用戶行為角度研究作弊網頁的方法值得重視.由于分析的指標很少(只有3個),這也預示著今后還有不少相關工作.
5 結語
目前,存在各種類型的網頁作弊手段,同時,也有相應的反作弊手段.有從網頁內容著手分析的、有從網頁鏈接著手分析的,也有從用戶行為著手分析的.然而這些都只是從技術方面來抵御網頁作弊.網頁作弊行為能帶來潛在的商業價值,并且互聯網市場沒有一個統一的監管體系,各個商家各自為政,若能采取相應的懲罰措施,削減網頁作弊的商業價值,那么應該可以鏟除不少的作弊網頁.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年12期)2015-11-10 05:13:38
創業家(2015年5期)2015-02-27 07:53:25
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
