基于時空信息融合的時序動作定位
2020-11-11 08:01:36范冬艷
智能計算機與應用 2020年6期
王 倩, 范冬艷
(上海工程技術大學 電子電氣工程學院, 上海201620)
0 引 言
隨著計算機視覺等相關技術的發展,深度學習已經在視頻動作識別領域[1-5]取得了巨大成果。 但是實際應用中的視頻通常是不受約束的,包含多個動作實例和背景場景或其他活動的視頻內容。 時序動作定位是一個重要而又具有挑戰性的問題,給定一個包含多個動作實例和背景內容的長而未修剪的視頻,不僅需要識別它們的動作類別,還需要定位每個實例的起始時間和結束時間。
許多先進的系統使用段級分類器來選擇和排列預先設定邊界的建議段[6-9]。 然而,一個理想的模型應該超越節段的級別,在細粒度的時間尺度上進行密集的預測以確定精確的時間邊界。 例如SCNN[6]的C3D 卷積神經網絡[3]從conv1a 到conv5b層,將輸入視頻的時間長度減少了8 倍。 為此,Zheng Shou 等設計了一個新的convolutional-deconvolutional(CDC)網絡[10],該網絡的頂部是一個C3D 卷積神經網絡用于提取視頻的時空特征信息,用來判斷動作類型。 然后采用CDC 過濾器同時執行所需的時間向上采樣和空間下采樣操作,以在幀級粒度上預測動作。 CDC 網絡不僅在每一幀檢測行為上實現性能優越,同時也顯著提高了時間邊界的精確性。 但是CDC 網絡在候選區域的選取算法和時間邊界的定位上還有待提高,主要有兩個問題:(1)CDC 進行時序動作定位預測的輸入為原始視頻的候選片段,候選片段的選擇會影響到時序動作識別的效果和效率,若識別不準確,不僅影響識別結果的準確率,還會耗費時間去識別不準確的候選區域。S-CNN 建議片段選擇算法將密集間隔采樣的RGB圖輸入C3D 卷積神經網絡進行預測,沒有充分利用視頻的時空特征。 (2)結合候選區域與幀級分數并利用閾值定位邊界點可以得到最終的時序動作檢測結果。 然而,檢測得到的動作的起始和終止坐標與真值之間還有著較大的偏移。 基于以上兩個問題,本文提出了時空特征融合時序動作定位模型(spatio-temporal feature fusion temporal action localization model,STFF-CDC)。
針對問題1,為了充分融合視頻中的時空信息,并以相當低的成本保存相關信息,文獻[11]在TSN網絡的基礎上,結合C3D 卷積神經網絡,提出了時空特征融合動作識別模型。 該模型能夠充分利用視頻的時空特征,有效且高效的識別視頻的動作類型。將該模型用于候選區域的選擇網絡,可以充分融合視頻的時空特征,提高候選區域提取的準確率。
針對問題2,為了解決定位的動作起始和終止坐標與真實值存在較大偏移的問題,本文提出了一個動作起始終止狀態判斷網絡。 將檢測結果的時間區域擴大,之后再用起始點和結束點周圍的幀為數據集訓練DenseNet 網絡[12],利用訓練好的模型判斷起始幀和結束幀,從而重新定位得到更加精確動作起始邊界。
1 相關工作
1.1 RGB 圖和光流圖
視頻的RGB 圖像使3 個顏色通道(紅色R,綠色G和藍色B 來存儲像素信息,這些像素信息包含了視頻的外形信息,如圖1(a)所示。 由于視頻的動作識別與視頻中某些對象密切相關,外形信息是動作識別的重要信息,因此RGB 圖像可以提取視頻的空間特征。
光流場是指圖像中所有像素點構成的一種二維瞬時速度場,其中的二維速度矢量是景物中可見點的三維速度矢量在成像表面的投影。 所以光流不僅包含了被觀察物體的運動信息,而且還包含有關景物三維結構的豐富信息[13]。 視頻的光流圖包含了視頻的運動信息,如圖1(b)、1(c)所示, 分別為水平方向(x 方向)和垂直方向(y 方向)光流圖樣例。

圖1 披薩拋擲類的RGB 和光流圖示例Fig. 1 Examples of RGB and optical flow images for pizza thrower classes
1.2 時序動作檢測
時序動作檢測任務的目的是識別一段未剪輯長視頻中的動作類別以及動作的起止時間。 近年來,出現一些方法用于時序動作定位任務。 S-CNN 是較為典型的一種方法,S-CNN 框架主要分為多尺度段的生成、Segment-CNN、后處理3 個部分,Segment-CNN 包括建議網絡,分類網絡和定位網絡3 個子網絡,均使用了C3D 卷積神經網絡。 建議網絡是提取候選區域的網絡,它的輸出為兩類,即預測該片段是動作的概率及是背景的概率;分類網絡的作用是嘗試做一個用來識別動作的種類的分類網絡,為定位網絡做初始化;定位網絡的輸出為K + 1 個類別(包括背景類)的分數,這個分數是該segment 是某類動作的置信度分數。 后處理是在測試階段進行的,具體方法是對定位網絡的輸出分數進行非極大化抑制(NMS)來移除重疊,對于時序上重疊的動作,通過NMS 去除分數低的,保留分數高的。 CDC使用的候選區域選擇算法是S-CNN 建議網絡的候選區域提取算法,即改進C3D 卷積神經網絡的SoftMax 層進行候選區域的判定。
2 基于時空信息融合的時序動作檢測網絡
2.1 網絡整體框架
改進的CDC 卷積神經網絡訓練時的輸入為帶有幀級標簽的窗口訓練集,預測時的輸入為經過基于特征融合的候選片段生成算法生成的建議片段。接著經過3D 卷積神經網絡進行語義特征提取,這時視頻的時間維度會縮小為L/8。 為了恢復時間維度上的信息,來進行幀級粒度上的動作識別,再經過3D 反卷積神經網絡來對視頻的時間維度進行上采樣,空間維度進行下采樣。 輸出每幀的動作類別分數,最后訓練動作狀態檢測網絡進行時間邊界的調整。 框架流程見下圖2 所示。
2.2 動作候選區域提取算法
2.2.1 S-CNN 候選區域提取算法
S-CNN 候選區域提取算法使用Du Tran 等[3]提出的C3D 卷積神經網絡作為動作分類網絡,C3D卷積神經網絡與2D 卷積神經網絡不同,它有選擇地兼顧運動和外觀。 在跳高的例子中,特征先是集中在整個人身上,然后跟蹤其余幀上的人體跳高的動作。 同樣在化唇妝例子中,它首先聚焦在嘴唇上,然后在化妝時跟蹤嘴唇周圍發生的動作。 C3D 卷積神經網絡不僅對空間的的水平和豎直維度進行卷積,對時間維度也進行了卷積,以更好地提取時間和空間特征,保持時空特征的相關性。
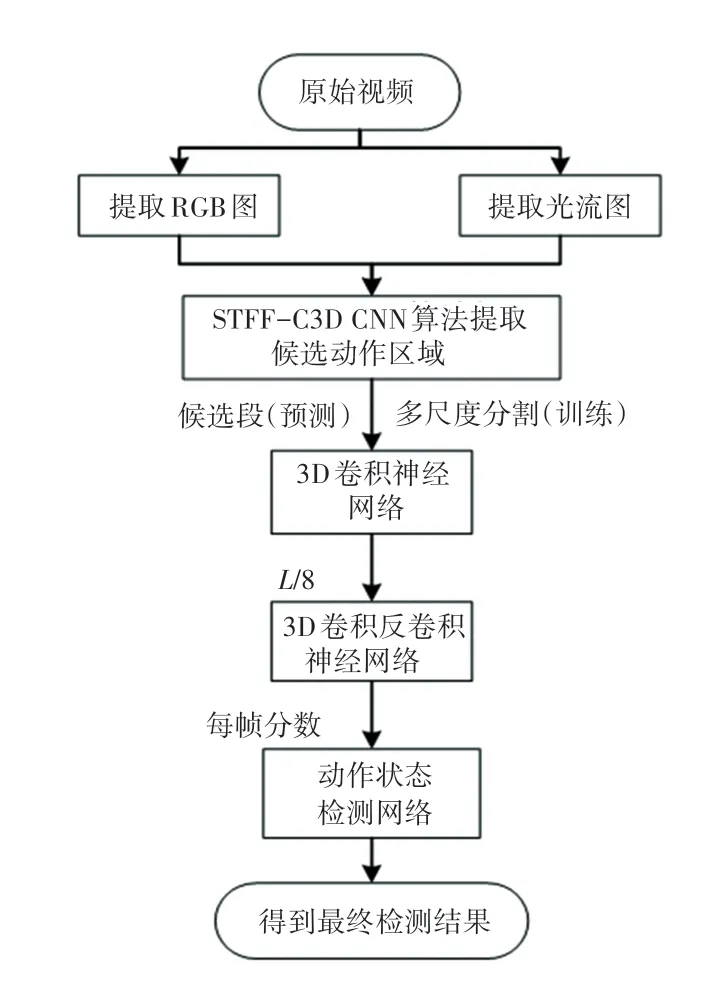
圖2 時空融合時序動作檢測網絡框架圖Fig. 2 Spatio-temporal feature fusion temporal action detection network frame diagram
S-CNN 采用的C3D 網絡結構如下圖3 所示。共具有8 個卷積層、5 個池化層、兩個全連接層,以及一個softmax 輸出層。 所有3D 卷積濾波器均為3×3×3,步長為1×1×1。 為了在時間維度不過早的進行壓縮,pool1 核大小為1×2×2、步長1×2×2,后面所有3D 池化層均為2×2×2,步長為2×2×2。 每個全連接層有4 096 個輸出單元。 C3D 最終通過softmax 層給出視頻樣本的分類。 S-CNN 候選區域提取算法具體流程圖見圖3。
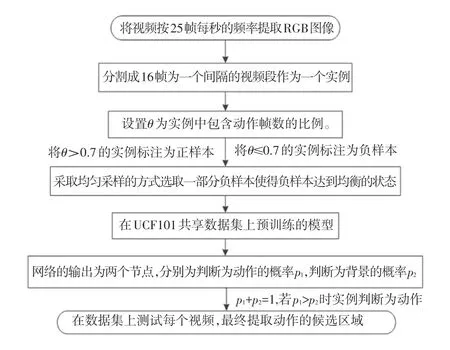
圖3 S-CNN 候選區域提取算法訓練測試過程Fig. 3 Training and testing process of S-CNN candidate region extraction algorithm
2.2.2 STFF-C3D CNN 候選區域提取算法
深度學習進行人體動作識別需要充分提取視頻中的時間特征和空間特征,并合理的利用時空特征之間的相關性。 為此,文獻[11]提出一種采用稀疏采樣方案的時空特征融合動作識別框架STFF-C3D CNN(spatio-temporal feature fusion action recognition model,STFF-C3D CNN)。 該模型不僅充分融合了視頻中時空特征,并且運用稀疏采樣方案[5]避免了冗余采樣。 主要分為4 部分:稀疏采樣生成RGB 圖和光流圖、時空特征的提取、時空混合特征圖的生成、C3D 卷積神經網絡進行動作識別,如下圖4 所示。
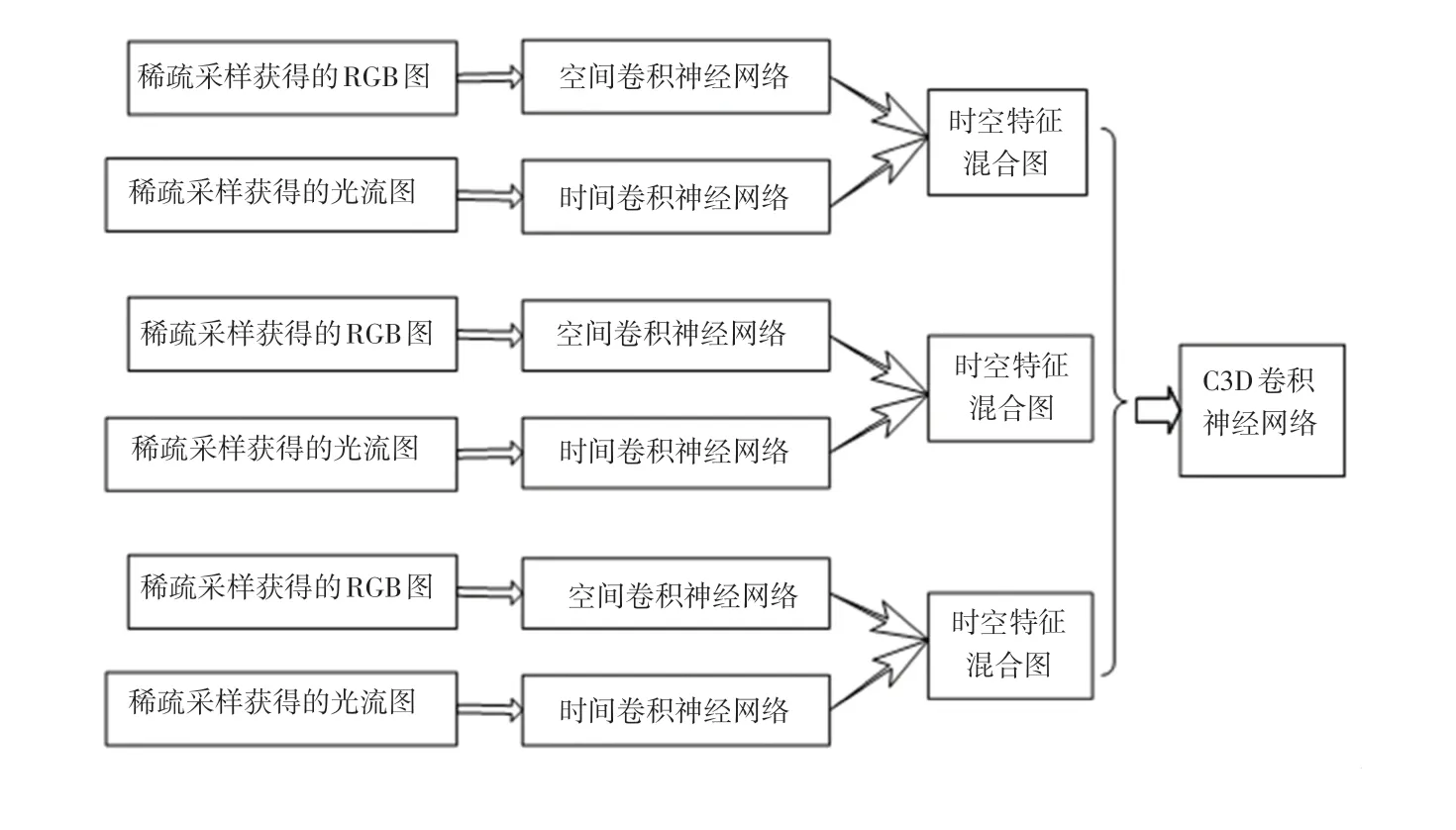
圖4 STFF-C3D CNN 框架Fig. 4 STFF-C3D CNN frame
在預測階段,建議片段(含有動作的片段)選擇會影響到時序動作識別的效果和效率,若識別不準確,不僅影響識別結果的準確率,還會耗費時間去識別不準確的建議片段。 本文提出的時空信息融合的時序動作檢測網絡采用STFF-C3D CNN[11]進行建議片段的選擇,可以充分融合候選片段的時間特征和空間特征來進行動作識別。
首先,采用稀疏采樣方案對視頻進行采樣。 一個輸入視頻被分為K 段(segment),一個片段(snippet)從它對應的段中隨機采樣得到。 對于每段snippet,提取它包含空間信息的RGB 圖像和包含時間信息的x 方向光流圖和y 方向光流圖。 接著,將RGB 圖送入空間卷積神經網絡進行訓練以提取中層空間特征,將光流圖送入空間卷積神經網絡進行訓練以提取中層時間特征。 然后,訓練時空混合卷積神經網絡提取時空融合特征,將時空中層特征圖進行融合[14],提取混合卷積神經網絡的中層混合特征,生成時空混合特征圖。 最后,將時空混合特征圖作為C3D 卷積神經網絡的輸入,在時間和空間維度分別進行卷積和池化,同時學習視頻的運動信息和靜態的圖片信息,修改STFF-C3D CNN 的輸出為兩類,即預測該片段是動作的概率以及是背景的概率。訓練時將IoU 大于0.7 的作為正樣本(動作),小于0.3 的作為負樣本(背景),對負樣本進行采樣使得正負樣本比例均衡,采用softmax loss 進行訓練來判斷動作類別。
2.3 3D 卷積反卷積神經網絡
C3D 架構,由有3 層全連接(FC)層的三維卷積神經網絡組成,在諸如識別和定位等視頻分析任務中取得了良好的結果。 CDC 網絡是基于C3D 卷積神經網絡構成的,C3D 的conv1a 到conv5b 是CDC網絡的第一部分,對于C3D 的其余層,CDC 保持pool5 在長度和寬度上執行步長為2 的最大池化,但保留了時間長度。 按照常規設置[3,6,15],設置CDC網絡輸入的高度和寬度為112×112,輸入時間長度為L 的視頻段,pool5 的輸出數據形式是(512,L/8,4,4)。 為了在幀級粒度上預測動作得分,需要在時間上進行上采樣(從L/8 回到L),在空間上進行下采樣(從4 × 4 到1 × 1)。
CDC6 將卷積核設置為(4,4,4)、步長設置為(2,1,1)、填充設置為(1,0,0),因此CDC6 可以將高度和寬度都減少到1,同時將時間長度從L/8 增加到L/4。 CDC7 和CDC8 都將卷積和設置為(4,1,1)、步長設置為(2,1,1)、填充設置為(1,0,0),因此CDC7 和CDC8 都進一步執行了步長為2 的上采樣,因此時間長度返回到L。 最后在CDC8 的頂部添加幀級SoftMax 層,以獲得每個幀的置信度分數,每個通道代表一個類別。 CDC 網絡的最終輸出形狀為(K + 1,L,1,1),其中K + 1 代表K 個動作類別加上背景類別。 網絡具體流程見下圖5。
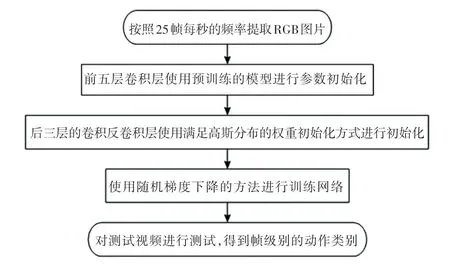
圖5 CDC 網絡流程圖Fig. 5 CDC network flow chart
2.4 動作起始邊界的調整
為了解決動作起始和終止坐標存在較大偏移的問題,本文提出了一個動作起始終止狀態判斷網絡。改進文獻[21]提出的網絡,訓練Densnets 網絡用作動作狀態檢測網絡。 Densnets 建立了不同層之間的連接關系,充分利用了特征,進一步減輕了梯度消失問題。 訓練測試過程如下:(1)首先,為了更大的間隔,將每個建議段的邊界在兩側擴展了原始段長度的百分比α。 本文把所有實驗的α 設為1/8。 (2)對擴大后的時間區域提取光流圖。 (3)訓練動作起始終止狀態判斷網絡,得到判斷模型。 假設一個動作實例S 的起始和終止坐標分別為(t1,t2),則動作的時間長度L =t2-t1。 訓練過程如圖6 所示。 (4)測試階段,對測試所得的動作實例的(t1-L/8, t1+L/8), (t2-L/8, t2+L/8)中的幀進行測試,分別輸出每一幀為開始幀,結束幀的概率,最后得到精修后的動作起始終止坐標。
3 實 驗
THUMOS'14[16]:時間動作定位THUMOS'14 數據集包含20 類行動。 本文用2 755 個修剪的訓練視頻和1 010 個未修剪的驗證視頻(3 007 個動作實例)來訓練模型。 測試使用的的213 個不完全是背景視頻的視頻(3 358 個動作實例)。
評估指標:根據傳統的度量標準[17],本文將每幀標記任務作為一個檢索問題來處理,對于每個動作類,將測試集中的所有幀按其在該類中的置信度得分進行排序,并計算平均精度均值(AP),然后對所有的類進行平均得到平均AP(mAP)。 具有正確的預測類別且其與真實值的時間重疊度大于閾值時,預測是正確的,不允許對同一真實實例進行重復檢測。
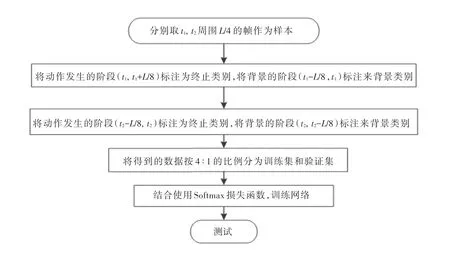
圖6 動作起始終止狀態判斷網絡Fig. 6 Action starting and ending state judgment network
每個測試結果都包含動作發生的時間區域和動作所屬的類別.重疊度IoU 計算為:
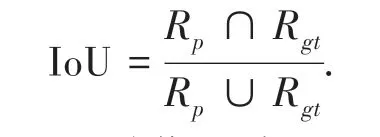
式中:Rp表示預測的動作區域,Rgt表示真實動作區域。 如果重疊度IoU 大于閾值,則表示預測是正確的。
理論上,因為卷積濾波器和CDC 濾波器都在輸入視頻上滑動,所以它們可以應用于任意大小的輸入。 因此,CDC 網絡可以在不同長度的視頻上操作。 但是由于GPU 存儲器的限制,實際上本文在視頻上滑動32 幀的時序無重疊窗口,并將每個窗口逐個送入CDC 網絡以及時獲得時間上的密集預測。從時間邊界的標簽中,知道每個幀的標簽,相同窗口中的幀可以有不同的標簽。 為防止包含太多背景幀進行訓練,只保留至少有一幀屬于動作的窗口。 因此,在給定一組訓練視頻的情況下,能獲得帶有幀級標簽的窗口訓練集。
本文實驗評估了在THUMOS'14 數據集上重疊IoU 閾值在0.3~0.7 之間變化時的mAP。 如表1 所示,CDC 獲得的結果要好于所有其他先進方法的結果。 與建議的CDC 模型相比:用FV 編碼iDTF 的系統[18]不能直接從原始視頻中學習時空模式來進行預測。 基于RNN/LSTM 的方法(Yeung 等[19],Yuan等[20])無法在時間依賴性之外明確捕獲運動信息。S-CNN 可以有效地捕捉原始視頻的時空模型,比其他3 種方法的mAP 得到了明顯的提高,但是僅在段級粒度上進行時序動作定位,缺乏調整候選建議邊界的能力。 CDC 網絡通過反卷積操作恢復時間維度上的長度,可以超出段級水平預測確定細粒度的置信度分數,在幀級粒度上進行時序動作定位的檢測,因此可以精確定位時間邊界。 比S-CNN 方法在各個閾值上的的mAP 提高了0.7% ~4.4%。
本文使用STFF-CDC 網絡,改進候選片段生成算法充分利用了視頻的時空特征。 實驗結果表明,本文方法精度比CDC 網絡約提高了2.2%。 另外,本文采用Densnets 網絡作為動作狀態檢測網絡,更有效地利用了特征,比DSTIN+CEN[21]方法相比也得到了提高。 總之,本文模型在各個閾值上均獲得了其他方法更準確的時序動作定位效果。
部分檢測結果對比展現在圖7,受益于候選區域選擇算法的改進,和動作狀態檢測網絡的貢獻,本文的方法可以得到更為精確的動作區域。
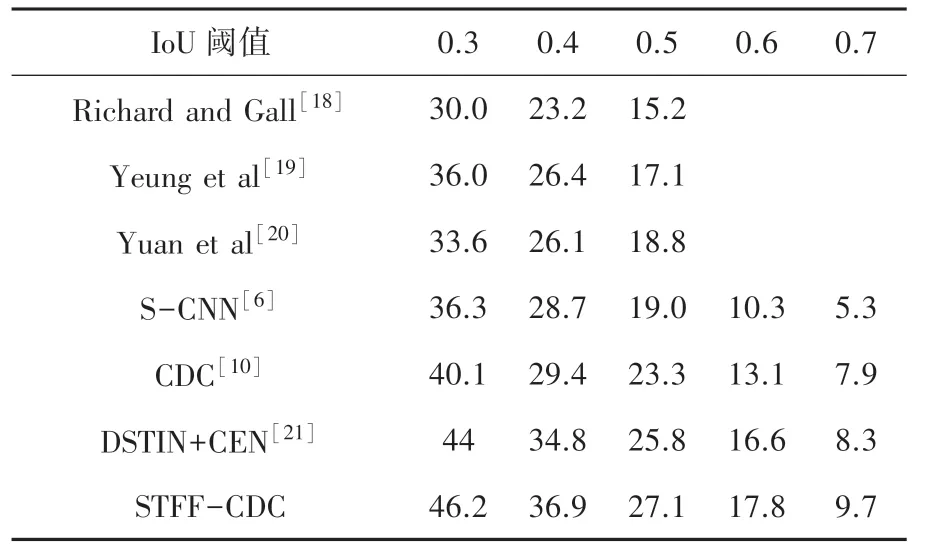
表1 本文動作識別算法和其他算法mAP(%)對比Tab. 1 The comparison of action recognition algorithm in this paper with others(map (%))

圖7 部分檢測結果對比Fig. 7 Comparison of some test results
4 結束語
時序動作定位任務需要識別出一段長視頻中的動作類別以及動作的起始時間。 為了有效的提取候選區域,本文提出了一種基于時空特征融合的候選區域提取網絡;為了提高動作起始點定位的精度,本文提出一種動作狀態檢測網絡。 在數據集THUMOS'14 上進行實驗,并與其他方法進行了對比。 結果證明,本文提出的基于時空信息融合的時序動作定位模型可以有效進行時序動作定位,達到了較好的精度。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
