基于經典算法的教育大數據挖掘實踐研究
2020-11-09 07:29:18肖中杰
計算機時代 2020年10期
肖中杰

摘? 要: 在信息技術與高等教育深度融合的背景下,高校逐漸積累了種類繁多的學生教育教學行為大數據。針對數據長期閑置,造成數據資源浪費的問題,文章以學生圖書館進出次數、圖書借閱情況、綜合測評成績、獎助學金評定數據為依據,基于SPSS Modeler關聯規則挖掘算法,對數據間潛在的關聯規則進行研究,得出了數據間的系列關聯規則,找出了學生學習行為軌跡中影響學業成績的因素。
關鍵詞: 學習行為; 信息化; 大數據; 數據挖掘; 算法
中圖分類號:TP393.04? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2020)10-09-03
Abstract: With the deep integration of information technology and higher education, colleges and universities have gradually accumulated a wide variety of student education and teaching behavior big data. In view of the problem of long-term idle data, resulting in waste of data resources, according to the library access times, book borrowing, comprehensive evaluation results and scholarship evaluation data of student, this paper studies the potential association rules between data with SPSS modeler association rule mining algorithm, to obtain the series of association rules between data and find out the factors that affect the academic achievement in the track of students' learning behavior.
Key words: learning behavior; informatization; big data; data mining; algorithm
0 引言
以數字化、網絡化、信息化技術為主要特征的教育信息化1.0,引領我國教育信息化事業實現了前所未有的快速發展,也取得了全方位、歷史性成就。在教育信息化1.0技術驅動下,高校教育信息化整體水平得到提升,與此同時也積累了大量的教學、科研、管理過程數據,并進一步形成校園特有的教育大數據資源。
從學生角度,這些數據包括學生檔案基本信息,食堂消費、公寓出入、超市購物等生活信息;圖書館進出及圖書借閱、考勤、選課、成績、獲獎等學習信息;上網情況、參加社團、競賽、講座等第二課堂信息。同時隨著移動互聯網以及物聯網等新技術的普及,由學校師生主動產生和由設備自動收集的信息越來越多,如微博、微信等社交信息,各類搜索點擊記錄信息等。
適應大數據時代教育信息化新需求,面對種類繁多、結構復雜的教育大數據,如何借助成熟的技術及算法實現數據深度挖掘并加以利用,促進教育信息化向深層發展,更好的服務于學校的教學、科研、管理及師生日常生活,已成為當下智慧校園建設的重要應用之一,也是當下高校面臨的重要課題。
SPSS Modeler是一款專門用于數據挖掘的工具,通過引入復雜的統計方法和機器學習技術,形成軟件強大的數據挖掘功能,可視化界面允許用戶充分利用統計和數據挖掘算法,而無需編程。Apriori作為SPSS Modeler 數據挖掘中簡單關聯規則技術的核心算法,可以找出數據集中有效的關聯規則,進而針對具體數據作進一步的關聯度分析[1]。
1 數據挖掘設計
1.1 原始樣本數據采集
學生圖書借閱數據及圖書館出入數據,分別從圖書借閱系統和一卡通系統中以.xlsx文件格式導出,根據需要對數據初步篩選,圖書借閱數據保留“學號(讀者條碼)、(讀者)姓名、院系、年級、借閱時間(操作時間)、借還情況(操作類型)、圖書名稱(書籍題名)”七個字段;圖書館出入數據保留“學號、姓名、院系年級、出入時間、進出情況”等五個數據項。學生綜合測評和獎助學金數據從學工系統中導出,主要選取學號、姓名、專業、測評結果、獎助級別(備注)幾個字段。本文采集了某學院某年度183名學生學習行為樣本數據。
1.2 原始樣本數據預處理
圖書借閱及圖書館出入數據文件中含有冗余數據,為便于挖掘分析,首先需要按“學號”進行查詢統計處理,分別得到學生借閱圖書次數和出入館次數。其次使用VLOOKUP()函數按照學號把學生綜合測評結果、獎助評定結果、圖書借閱次數,以及圖書館出入次數等數據關聯到一張表中,最終得到預處理后的原始數據關聯表[2],如圖1所示。
最后,對關聯表中數據做二值化變量的數據處理。主要是通過計算得到全部樣本圖書借閱次數和出入圖書館次數的平均次數,選取中間值為參照標準,再將學生圖書借閱行為和圖書館出入行為分別定義為借閱規律、出入規律,并分別用JY、JG表示。二值化的原則是大于等于中間值標準的學生其值記為“T”,小于中間值標準的學生其值記為“F”。同樣,學生綜合測評規律和獎助規律分別用ZH、JZ表示,對綜合測評數據按平均成績進行二值化,對獎助學金數據按“有”和“無”進行二值化處理。通過二值化處理后得到一張綜合數據表,刪除表中除ZH、JZ、JY、JG四個數據項之處的其他數據,最終生成一張可用于SPSS算法分析的二值化數據表[3,5]。如圖2所示。
至此,四類原始數據預處理環節完畢,接下來使用Apriori算法對二值化數據表作進一步的關聯分析及數據潛在含義的挖掘。
2 基于Apriori算法數據挖掘
根據Apriori算法原理,學生綜合測評成績排名的高和低、獎助學金評定、出入圖書館、圖書借閱行為都是一種事務。這里,構成事務的事務標識為“學號”,項目集合(簡稱項集)由ZH、JZ、JG、JY組成;如果用 I 代表包含了k個項目的總體,即I={i1,i2,…,ik},則事務 T∈I,項集 P∈I,項集 P1和P2的簡單關聯規則可表示為:P1→P2(規則支持度,規則置信度),其中P1稱為規則的前項,可以是一個項目或者項集,也可以是一個包含邏輯關系的邏輯表達式;P2稱為規則的后項,一般為一個項目,表示某種結論或事實。例如:JG(T)∩JY(T)→ZH(T),其前項是一個包括邏輯“與”的邏輯表達式,表示兩個項集(進館次數和借閱次數)之間為并且的關系,后項是一個綜合測評成績的項集,項目為好。結果表示學生進館次數和借閱次數都好的情況下,綜合測評成績排名也是好的[4]。
基于算法規則,在SPSS Modeler軟件中首先建立一個新的數據流,默認名為“流1”,通過工具面板區“源”選項卡的“Excel”數據源創建一個節點,使用節點快捷菜單的“編輯”命令將準備好的“二值化數據表”導入到數據流中;然后把“建模”選項卡中的“Apriori”節點添加到數據流中,建立該節點和Excel數據源節點間的連接;最后通過“Apriori”節點菜單中的“編輯”選項設置節點相關參數,主要是字段、模型、專家三項。
在“字段”選項中,由于數據挖掘過程中是自行指定建模變量,故選擇“使用定制設置”選項,并分別在“后項”和“前項”框中選擇關聯規則的后項和前項變量。
“模型”選項中的“最低條件支持度”描述的是指定前項的最小支持度,系統默認值為10%,也就是在進行 Apriori 關聯規則分析時,前項的數據至少要占總體數據的10%,否則,這個前項的重要程度就很低。
“最小規則置信度”描述的是指定規則的最小置信度,默認值為80%,即在進行 Apriori 關聯規則分析時,在包含前項數據的基礎上,又包含的后項數據和前項數據的比值至少是 80%,否則,生成的關聯規則的可靠性就很低。
“最大前項數”描述的是系統關聯分析時可以使用的最大前項的項目數。
“專家”選項卡用于指定關聯規則的評價指標,一般選用“規則置信度”,即提升度。
實驗中算法“最低條件支持度”設置為15%,“最小規則置信度”取默認值80%。系統分析關聯參數和評價指標設置完成后,通過“Apriori”節點“預覽”功能,即可輸出Apriori 關聯分析的結果[6]。
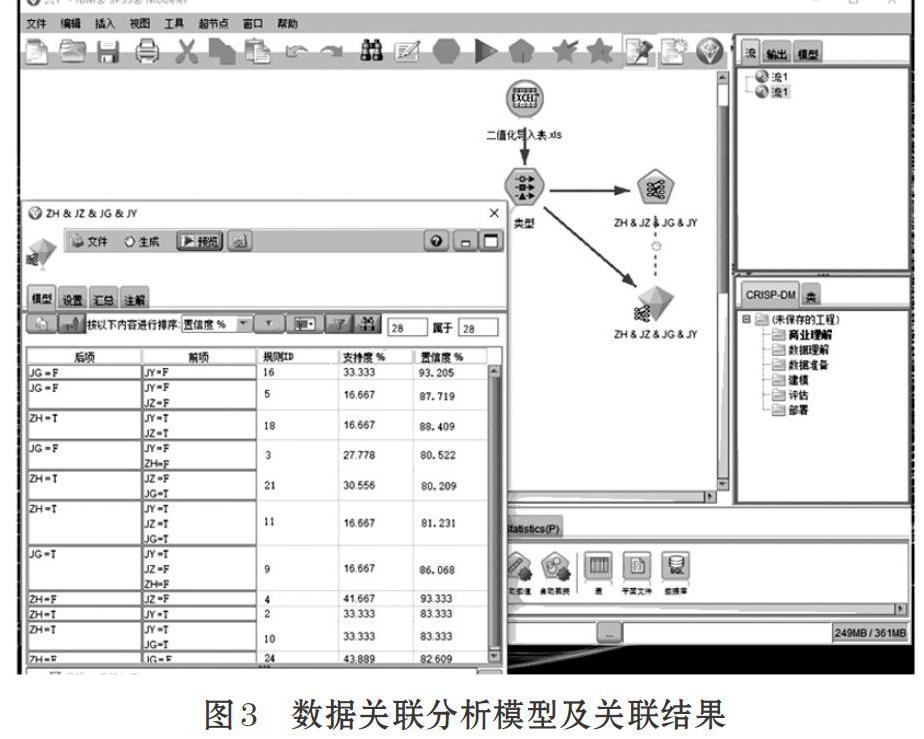
Apriori算法數據關聯分析模型及二值化數據表中四個數據項的關聯關系如圖3所示。
3 實驗結果分析
數據挖掘實驗結果中共產生 28條關聯規則,其中后項為“綜合測評”的規則共有五條,ID號分別為18、21、11、10、24。分別描述如下:
下面以ID=11的規則為例進行分析。
這條規則可描述為:借閱圖書次數多、獲得獎/助學金、進入圖書館次數多,則“綜合測評”成績排名好。此類學生樣本量為31,即總樣本數的16.667%。其中有81.231%的學生綜合測評成績排名可能是好的,即25個樣本。這條規則的支持度為13.7%,即借閱圖書次數多、獲得獎/助學金、進入圖書館次數多且“綜合測評”成績排名好的學生占總樣本數的13.7%。經過對其他規則做同樣的分析發現,ID=21及ID=24的規則中,獎/助學金情況與綜合測評成績并不是正相關關系,即獲得獎/助學金的學生并非全部都是綜合測評成績好的,實際評定中有一定的均衡因素考慮。此外,進入圖書館次數少、沒有獲得獎/助學金二個因素并不能直接影響綜合測評成績排名,每個變量都沒有單獨導致成績排名好壞。
這條關聯規則的實用性可通過簡單計算來驗證。經過統計,全部樣本中,綜合測評績排名好的學生有89 人,占總體樣本的 48.6%。而規則中成績排名好的學生比例明顯高于該比例,故此條規則的關聯是正向關聯。
從提升度來看,本條規則中綜合成績排名好的支持度為48.6%,置信度為 81.231%,則提升度為二者的商即1.677。表示在全部樣本中,排名好的樣本概率為48.6%,如果把學生限定在借閱圖書次數多、獲得獎/助學金、進入圖書館次數多的 31 人中,成績排名好的概率可提高1.677倍。
4 結束語
通過對數據關聯分析模型產生的數據關聯結果的研究分析,可以發現規則的提升度都很高,關聯規則有效,規則對學生學習行為數據分析起到了一定的指導作用,對教育教學部門工作效率的提升有一定的指導意義,成功挖掘出了數據資源中蘊藏的價值。
隨著高校信息化建設工作的逐步深入,各部門業務系統產生了大量可用的教育大數據,傳統人工數據處理方式已經遠遠無法適應大數據處理的要求,如何利用成熟的大數據處理技術,通過更加廣泛的教育大數據關聯規則分析,提升高校數據挖掘和應用能力,提升數據資源的利用率,為學校教學、科研、管理工作提供決策支持,已經成為大數據時代高校面臨的重要任務之一。教育大數據關聯規則分析對基于教育大數據的智慧校園建設有重要意義。
參考文獻(References):
[1] 蔣智鋼等.SPSS軟件及應用課程教學體系助學自訓系統設計[J].實驗室研究與探索,2019.38(3):199-202
[2] 肖宇.校園一卡通應用數據分析系統的研究與實現[D].西南科技大學碩士學位論文,2018.
[3] 馬如義.Apriori算法在詞性標注規則獲取中的應用[J].計算機時代,2016.10:32-35
[4] 丁雪梅等.SPSS數據分析及Excel作圖在畢業論文中的應用[J].實驗室研究與探索,2012.31(3):122-128
[5] 曾馨.基于數字化校園的一卡通系統設計與應用[J].電子技術與軟件工程,2016.6:57
[6] 薛頌.基于校園卡數據的學生成績關聯性因素分析[D].內蒙古師范大學碩士學位論文,2017.
猜你喜歡
中小學信息技術教育(2021年8期)2021-09-10 17:59:45
大眾投資指南(2021年35期)2021-02-16 01:06:26
甘肅教育(2020年18期)2020-10-28 09:06:02
電力與能源(2017年6期)2017-05-14 06:19:37
科技視界(2016年20期)2016-09-29 10:53:22
信息通信技術(2015年6期)2015-12-26 01:16:46
中國衛生(2014年1期)2014-11-12 13:16:34
江蘇年鑒(2014年0期)2014-03-11 17:09:40
電子設計工程(2014年18期)2014-02-27 12:00:13
