一種改進的不平衡數據過采樣算法BN-SMOTE?
2020-11-02 09:00:14楊賽華周從華蔣躍明張付全
計算機與數字工程 2020年9期
楊賽華 周從華 蔣躍明 張付全 張 婷
(1.江蘇大學計算機科學與通信工程學院 鎮江 212013)(2.無錫市第五人民醫院 無錫 214073)(3.無錫市婦幼保健院 無錫 214002)(4.無錫市精神衛生中心 無錫 214151)
1 引言
不平衡學習問題包含不同類別之間數據樣本的不均衡分布,其中大多數樣本屬于某種類別,而剩余的樣本屬于其它類別。許多實際的應用領域中都存在不均衡數據集的分類問題,例如醫療診斷[1]、信息檢索系統[2]、欺詐性電話的檢測[3]、直升機故障檢測[4]等。傳統的分類方法傾向于對多數類有較高的識別率,對于少數類的識別率卻很低。因此不均衡數據集的分類問題的研究需要尋求新的分類方法和判別準則。
目前最流行的處理不平衡學習問題的方法多是基于過采樣方法來延伸的。在本文中,首先介紹了SMOTE 算法以及它的一種改進方案Border?line—SMOTE 算法,同時指出在某些情況下,Bor?derline—SMOTE 算法無法正確識別出所有的邊界樣本。基于這一問題,我們提出一種新的過采樣方法Borderline Neighbor Synthetic Minority Oversam?pling Technical(BN-SMOTE),其目標是構建出一個難以學習的邊界少數類樣本集,再從中選擇少數類樣本參與到樣本合成中。基本思想是:1)對原始少數類樣本進行過濾操作去除噪聲;2)構建難以學習的邊界少數類樣本集;3)合成新的少數類樣本。
2 相關工作
2.1 相關算法研究
近些年關于不平衡數據分類的研究已經引起了廣泛的關注。He 和Garcia[5]將這些不同的不平衡數據研究方法主要分成了以下四類:采樣方法;代價敏感學習方法;基于核的方法與主動學習方法以及如單分類算法、新奇檢測等方法。本文將對目前已經提出的一些經典過采樣方法作簡單介紹。
最簡單的方法是隨機過采樣算法,其中合成的少數類樣本都是隨機重復的,但是這樣容易產生模型過擬合的問題[6]。過采樣中另一種主要的方法是根據數據合成樣本,其中最著名的算法就是SMOTE[7]。SMOTE 的基本思想是對少數類樣本進行分析,并根據少數類樣本人工合成新的樣本添加到數據集中。
為了提高SMOTE 算法的性能,目前已經提出了很多對于SMOTE 的延伸算法。Han[8]等提出一種命名為Borderline-SMOTE 的過采樣算法。Bor?derline-SMOTE算法最主要的目的是尋找在邊界區域類的少數類樣本,在這個方法中只使用這些邊界區域內的少數類樣本來合成新樣本,因為這些少數類樣本是最容易被誤分類的樣本。
Sáez等[9]提出了一種名為SMOTE-IPF的框架,在這個框架中,首先利用SMOTE 算法對少數類樣本進行過采樣處理,之后通過迭代分割濾波器[IPF]方法對存在的噪聲數據進行濾波操作,通過一系列的數值實驗,結果表明這個框架具有很好的效率。過采樣方法可能會對分類器產生額外的偏差,這會降低分類器在大多數類樣本上的性能。為了防止這種劣化,S. Chen 等[10]將過采樣和bost?ing 相結合,提出一種RAMOBoost 算法來有效地學習不平衡數據。H.Guo[11]等也提出DataBoost IM 方法,通過bosting和數據生成來學習不平衡數據。
2.2 Borderline—SMOTE算法
原始的SMOTE 算法對所有的少數類樣本都是一視同仁的,但在實際建模過程中,我們發現那些處于邊界位置的樣本更容易被錯分,因此利用邊界位置的樣本信息產生新樣本可以給模型帶來更大的提升。Borderline-SMOTE 便是在SMOTE 方法的基礎上進行了改進,只對少數類的邊界樣本進行過采樣,從而改善樣本的類別分布。具體步驟描述如下。
假設原始樣本集為T,其少數類樣本集P,多數類為N。P={p1,p2,…pi,…,ppnum},N={n1,n2,…ni,…,nnnum},其中ppnum,nnnum分別表示少數類樣本個數和多數類樣本個數。
1)計算少數類樣本中的每個樣本點pi與所有訓練樣本的歐氏距離,獲得該樣本點的m近鄰(m值為用戶設定)。
2)對少數類樣本進行劃分。設在m近鄰中有m'個多數類樣本點,顯然0 ?m'?m。若m'=m,即m近鄰均為多數類樣本,pi則被認為是噪聲;若0 ?m'?m2 ,則pi被 劃 分 為 安 全 樣 本;m2 ?m'<m,則pi被劃分為邊界樣本。將邊界樣本 記 為 {,…,} , 其 中 0?dnum?pnum,其中dnum為少數類樣本中邊界樣本的個數。
3)計算邊界樣本點pi' 與少數類樣本P的k近鄰,根據采樣倍率N,選擇s個k近鄰點與進行線性插值,合成少數類樣本:
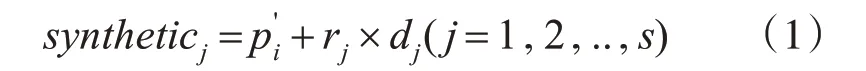
其中rj是介于0 與1 之間的隨機數;dj表示樣本點與其s個近鄰的距離。
4)將新合成的少數類樣本與原始訓練樣本T合并,構成新的訓練樣本T'。
與SMOTE 方法相比,Borderline-SMOTE 方法只針對邊界樣本進行近鄰線性插值,使得合成后的少數類樣本分布更為合理。 但是Border?line-SMOTE 算法仍存在許多缺陷,其中一個問題就是無法有效地分辨出噪聲樣本。在這個算法中,只有當最近鄰所有樣本都為多數類時,少數類才會被判斷為噪聲。然而當只有兩個少數類樣本被大多數類包圍時,依然會認為這兩個少數類樣本處于邊界區域,但是顯然它們是屬于噪聲的。
另一個主要問題則是在某些情況下,上述判定方法并不能找到邊界位置的少數類樣本點[12]。如圖1 所示,其中五角星代表多數類樣本,圓圈代表少數類樣本。從圖中我們可以看出,A、B點為離決策邊界最近的少數類樣本點,用這兩個點進行樣本生成能夠得到好的新樣本。假設m=5,可以發現少數類樣本點A與B的最近m近鄰樣本中,均為少數類樣本點而沒有多數類樣本,即m'=0。而根據上述判定方式,此時0 ?m'?m2,則A、B 點均被劃分為安全樣本,這種錯分方式將會導致之后的新樣本生成過程中,不會使用到A、B兩點進行樣本生成。由此造成的決策邊界附近的少數類樣本信息減少,會大大影響模型的性能。
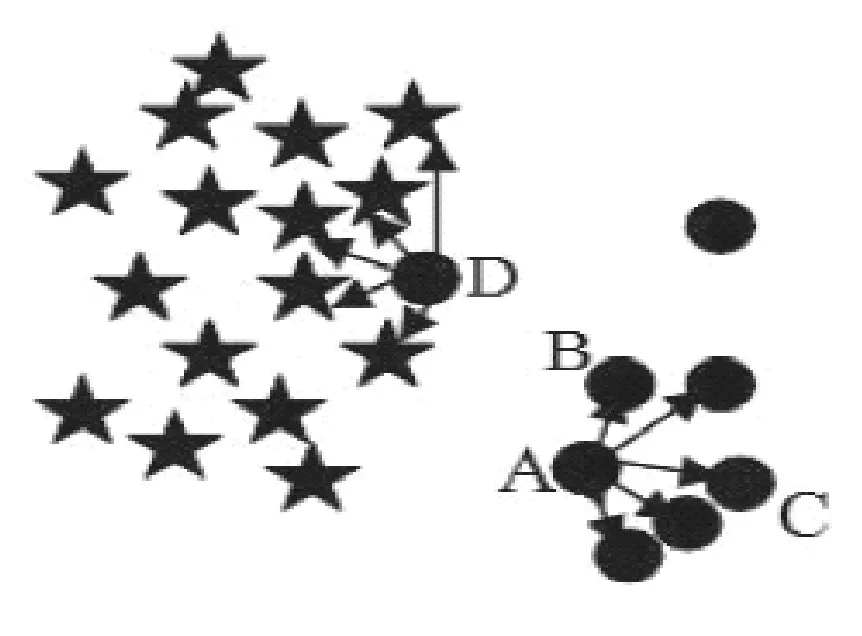
圖1 被錯分的邊界樣本少數類樣本
3 一種新的算法BN-SMOTE
在新樣本的合成過程中,并不是所有的少數類樣本都是重要的,因為其中有一部分可能很容易被學習,對于新樣本的合成提供的信息少。因此,我們有必要確定一組難以學習的少數類樣本,并通過它們合成新的樣本。這些樣本通常位于決策邊界附近,大多數現有的過采樣方法[7~8]沒有明確地識別難以學習的樣本。雖然Borderline-SMOTE 算法試圖找到一組邊界少數類(難以學習)樣本,但我們在上節已經說明了它無法正確識別出所有的邊界樣本。基于該算法的思想,我們采用一種新方法BN-SMOTE來識別難以學習的少數類樣本,并構建成一個少數類樣本集。該方法分為兩個階段:在第一階段,BN-SMOTE從原始少數類樣本集Smin中識別出最難學習的少數類樣本,并通過所識別出的樣本構建一組Simin樣本集;第二階段,BN-SMOTE 從Simin樣本集中選擇少數類樣本來進行新樣本的合成,并將合成出的新樣本添加到Smin中來生成輸出集Somin。主要步驟描述如下:
算法BN-SMOTE(Smax,Smin,N,k1,k2,k3)
輸入:
1)Smax:多數類樣本集;
2)Smin:少數類樣本集;
3)N :需要生成的新樣本數量;
4)k1:用來去除噪聲的k近鄰值;
5)k2:用來生成少數類集合的多數類集合的數量;
6)k3:用來生成少數類集合的少數類鄰居的數量。
程序開始:
1)對于每個少數類樣本xi∈Smin,計算其最近鄰集合NN(xi),其中NN(xi)包含了與xi歐式距離相距最近的k1個樣本。
2)去除掉那些在其k1 近鄰中沒有其他少數類存在的少數類樣本,組成一個過濾后的少數類樣本集Sminf:

3)對于每個少數類樣本xi∈Sminf,計算其最近鄰的多數類樣本集合Nmaj(xi),其中Nmaj(xi)包含了與xi歐氏距離最近的k2 個多數類樣本。
4)對所有的Nmaj(xi)集合作合并操作得到處于邊界區域的多數類樣本集合:
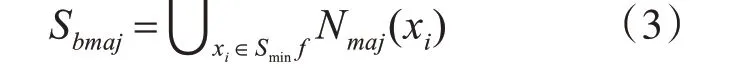
5)對于每個多數類樣本yi∈Sbmaj,計算其最近鄰的少數類樣本集合Nmin(yi)。其中Nmin(yi)包含了與yi歐式距離相距最近的k3 個少數類樣本。
6)對所有得到的Nmin(yi)少數類樣本
作并集,得到處于邊界區域最難學習的少數類樣本集Simin:
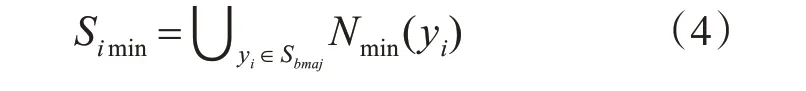
7)初始化集合Somin,使得Somin=Smin。
8)Do forj=1…N。
(1)從少數類樣本集合Simin中選擇一個樣本x,再隨機選擇另一個樣本y;
(2)生成一個新樣本s:s=x+α×(y-x),其中α是處于[0,1]的隨機數;
(3)將s放入集合Somin中:Somin=Somin∪{s} 。
9)結束循環。
輸出:過采樣處理的少數類樣本集合Somin。
4 實驗
4.1 數據集描述
本文實驗數據來自于UCI 機器學習數據庫中的3組真實數據集[13]。其中Abalone和Pima數據集是二分類不平衡數據集,Phoneme 是多分類數據集,我們將Phoneme 數據集中的Class’1’作為少數類,其他類共同作為多數類。具體描述如表1所示。
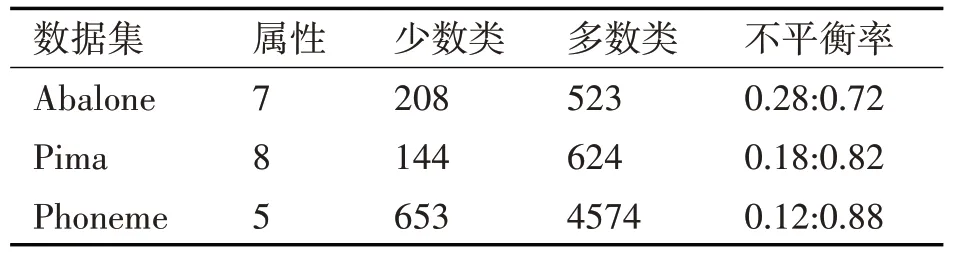
表1 數據集描述
4.2 評價指標
對一個二分問題來說,會出現四種情況,如表2所示。

表2 二分類的混淆矩陣
通過表2 的混淆矩陣,我們就可以計算出一些評價指標。其中最常見的就是正確率,通常來說,正確率越高,分類器的性能越好。但是由于分類器對少數類的不敏感,當對不平衡數據進行分類時,少數類在很大程度上被判為多數類,導致少數類樣本的識別率較低,因此正確率不適用于評價不平衡問題[14]。本文選用其它目前常用于評價不平衡問題的指標G-mean和F-measure 。
G-mean表示只有當分類器對樣本中少數類和多數類的分類效果都很好的情況下,此時G-mean的值最大[14~15]。定義如下:

F-measure 同時結合了精確度和召回率,是它們的加權調和平均,用于最大限度地提高對單個類性能的評價程度,因此可用于測量分類器在少數類樣本上的分類性能。定義如下:

4.3 實驗結果分析
本文的對比實驗主要包括三個算法的對比,分別是SMOTE、Borderline-SMOTE 和本文提出的BN-SMOTE 算法。為了測試這些算法在不同分類器下的效果,在通過算法對三組數據集過采樣處理結束后,分別利用SVM 和C4.5 決策樹對合成后的數據集進行分類,最終得到G-mean 和F-measure值對結果進行評價。
4.3.1 實驗環境和相關參數設置
本文實驗環境為操作系統Windows 8 64 bit,CPU/Intel(R)Core(TM)i5-3210M 雙核處理器,主頻2.5GHz,內存8G,硬盤容量1T,編譯工具Python 3.6.0。其中SVM 算法核函數使用RBF 核函數,系數σ=0.5,懲罰因子cost=2。對于BN-SMOTE 算法,設置k1=5,k2=3,k3=|Smin|/2,所有的這些值都是在一些初步運行后的選擇。對于SMOTE 和Borderline-SMOTE算法,近鄰個數k值都設置為5,同時評價指標F-measure 中的β取值為1,即F-Value。為避免數據重復計算,客觀評價算法的性能,實驗均采用10 次10 折交叉驗證的平均值作為數值結果[16]。
4.3.2 實驗結果對比
表3 為各算法(SMOTE、Borderline-SMOTE、BN-SMOTE)分 別 在SVM 和C4.5 決 策 樹 下 的F-Value、G-mean 結果對比。從三組不平衡數據集(Abalone、Pima、Phoneme)的實驗中可以看出,在SVM 分類器下,三個算法的F-Value 值相差不大,各有優劣,但BN-SMOTE 的G-mean 值要大于其它兩個算法,而在C4.5 決策樹分類器下,三個算法中BN-SMOTE 算 法 的F-Value 和G-mean 都 明 顯 更高,由此可知無論在SVM 和C4.5 決策樹中,BN-SMOTE 算法的表現都不差甚至更好。同時在對同一數據集的實驗中,我們發現BN-SMOTE 算法在C4.5 決策樹下的表現要更優于在SVM 分類器下的表現。
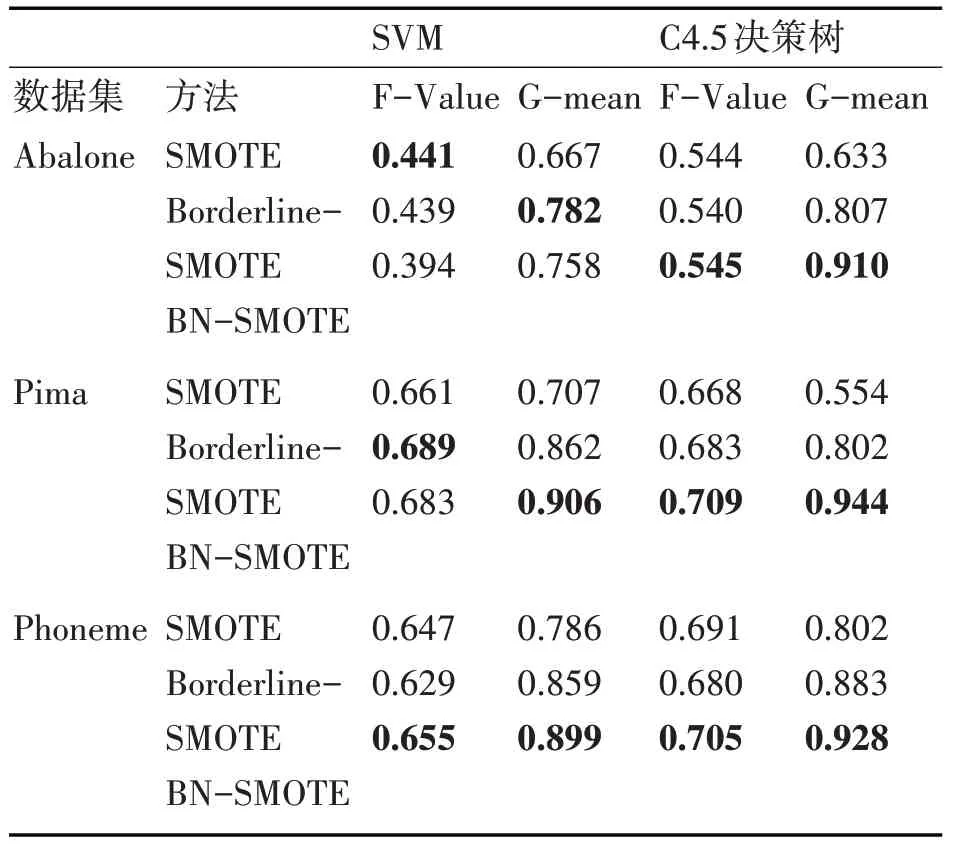
表3 SVM分類器下不同算法的F-Value和G-mean對比
4.3.3 實驗結果與過采樣率N的關系
圖2~4 分 別 表 示 的 是 在Abalone、Pima、Pho?neme 數據集的實驗中,G-mean 關于采樣率N 的變化情況。對于Abalone 數據集,當采樣率N=3 時,BN-SMOTE 算法在SVM 和C4.5 決策樹中達到最大值,此時數據集內部達到類別平衡的狀態,而隨著采樣率N 的增大,分類精度逐漸減少,原因是少數類樣本的不斷增多而產生了新的不平衡。同時從圖2(a)和圖2(b)對比中可以看出,BN-SMOTE 算法在C4.5 決策樹中表現明顯更好于SVM。同理在Pima 數 據 集 中N=4,Phoneme 數 據 集N=8 時,BN-SMOTE算法達到最大值,且整體表現優于其它兩個算法。因此從以上分析中可以得出結論:1)當采樣率N接近于數據集的不平衡率,此時數據集趨于平衡,分類效果最好;2)BN-SMOTE 算法在分類器C4.5決策樹中的表現更好。
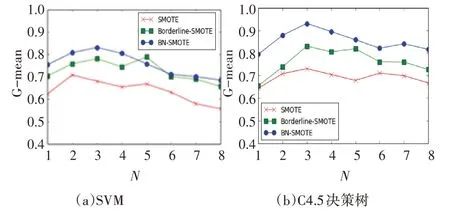
圖2 Abalone的G-mean關于采樣率N的變化曲線
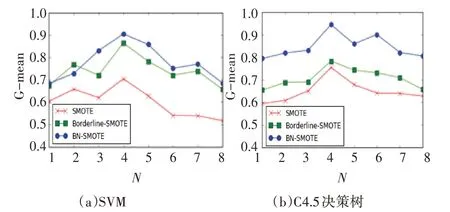
圖3 Pima的G-mean關于采樣率N的變化曲線
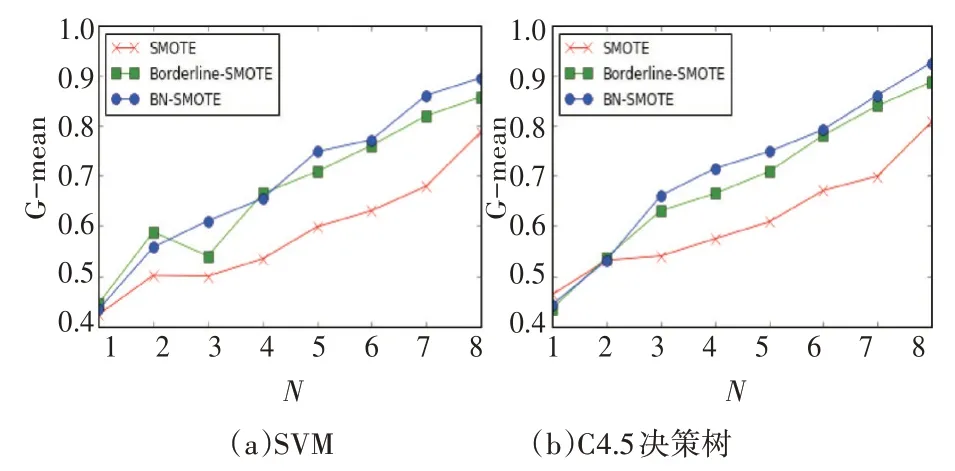
圖4 Phoneme的G-mean關于采樣率N的變化曲線
5 結語
本文進行了廣泛的實驗對BN-SMOTE 在不同數據集上的表現進行評估,并與其他方法比較,實驗表明無論在SVM 和C4.5 決策樹中,該算法都具有很好的表現。本文的后續工作主要有兩點:一是考慮使用名義特征的數據集,在本文中,我們只選用了具有連續的特征的數據集,因此可以使BN-SMOTE 通用化來處理任何類型的特征;二是BN-SMOTE 可以與其他一些欠采樣和邊界估計方法集成,以研究它們是否能夠比單個BN-SMOTE過采樣提供更好的結果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
