基于風格特征融合的文檔分割方法
2020-10-15 11:01:46劉汪洋
計算機應用與軟件 2020年10期
劉 剛 王 凱 劉汪洋 曹 揚 李 濤
1(哈爾濱工程大學計算機科學與技術學院 黑龍江 哈爾濱 150001) 2(中電科大數據研究院有限公司 貴州 貴陽 550081)
0 引 言
隨著數據時代的到來,人們獲取相關資料,相互共享信息的途徑也十分廣泛。無論是文學作品還是學術論文,所產生的剽竊行為都屢禁不止,這種行為令人深惡痛絕。更有甚者,簡單修改文章的內容以逃過現有的剽竊檢測,為當今學術界造成惡劣影響。
基于此,人們對論文的剽竊檢測研究不單單是停留在簡單的字符串判斷方面,對于作者的寫作風格和寫作習慣的研究也越來越受到人們的關注。寫作風格不僅能反映一個作者的寫作習慣,更能運用在剽竊檢測系統和用戶畫像技術上,對作者的識別也有很好的幫助,給剽竊檢測系統提供一個新的研究角度,對網上匿名文章作者的判斷也提供了強有力的支持。不同人在進行寫作時會形成自己獨特的風格特點,主要體現在用詞、句、段、修辭手法、情感等方面,這些是作者在不經意間養成的寫作習慣,所以通過對文章的寫作風格特征的提取來推斷文章的所屬是有效的。
1 相關理論與工作基礎
國外語言學學家在文本風格研究方面早已起步,1985年Cary Taylor通過寫作風格發現一首9節詩歌是莎士比亞的作品,中國的語言學家也通過寫作風格推測紅樓夢的作者原創性。中文方面,對于四大名著之一的《紅樓夢》是不是同一個人寫的問題備受爭議,華中師范大學博士生劉悅基于語料庫對四大名著《紅樓夢》的部分寫作風格進行統計[1],驗證了前80回和后40回的用詞習慣有所差異,間接地證明了后40回可能出自其他作者。
1.1 風格特征提取
早期的風格研究主要是利用統計的方法,對詞匯、句子、段落的規律進行統計,利用統計的規律來約定一個人的風格。風格特征提取最早是對單特征進行研究,隨著單特征不能滿足實驗結果,多特征融合應運而生。近年來,把機器學習和神經網絡的算法引入到風格提取和作者識別中,并且取得了好的結果。
由于中文的多變和困難,所以在對中文的風格提取上,比外文的風格提取明顯更加困難,中文需要考慮到分詞系統的準確性,句子結構也比較復雜。盡管中文的風格提取比外文更困難,但對于中文風格的研究仍然受到了廣泛的關注。
1.2 文本分割技術
文本分割技術把一篇文章根據某些特征分成幾個獨立的片段,該技術在文本預處理、自然語言處理中占用很重要的比重。由于文本分割的目的不同,所以使用的方法和特征也有所不同。Tian等[2]提出了一種多級MSER技術,該技術從一組不同顏色通道文本圖像中提取的穩定區域中識別出最優質的文本候選。為了識別最優質的文本候選,定義了一個分割得分,利用四個度量來評估每個穩定區域的文本概率。該方法在ICDAR2003和SVT數據集上進行評估,實驗表明它優于流行的文檔圖像二值化方法和最先進的場景文本分割方法[2]。
在中文方面,劉耀等[3]提出了一種基于領域本體對文本進行線性分割的方法。該方法利用初始概念自動獲取結構化語義概念集合,并根據獲取的概念、屬性及屬性詞在文本中出現的頻次、位置和關系等因素為段落賦予語義標簽,挖掘文本的子主題信息,將擁有相同語義標注信息的段落劃分為相同語義段落,實現了文本不同子主題之間的分割,分割效果能夠滿足實際應用需求,并優于現有的無須訓練語料的文本分割方法。
2 多特征提取與融合
利用網絡資源中的電子小說進行全文下載,選取風格差異比較明顯的20個文檔,作為實例進行實驗效果的風格特征分析,其中10篇來自古龍,另外10篇來自瓊瑤。
2.1 單維風格特征
2.1.1詞長度
在中文風格方面,可以使用分詞之后的詞匯長度,觀察作者在用詞方面對兩字詞語、三字詞語、四字詞語以及四字以上詞語的使用習慣。有研究發現在雙字詞語的使用頻率上,張愛玲的使用頻率是0.17,而魯迅的使用頻率高達0.43。
在英文方面是統計單詞字母個數,而在中文上統計的平均詞長度的范圍比較小,平均詞長度基本范圍在2~4之間,但是縮小比較范圍同樣可以看出實驗效果。因此把詞長度作為最后分類的一個參數。
2.1.2平均句子長度
平均句子長度是統計作者對文本句子長度的使用習慣,對比長短句的使用頻率。統計出每一個句子的長度,進行平均求和,平均句子長度以“。”、“!”和“?”為一組標記,統計句子中字數長度的平均值作為最后分類的參數,如圖1所示。

圖1 平均句子長度
可以看出,古龍文檔的平均句子長度明顯比瓊瑤的平均句子長度長,可以通過這個特征來區分出不同寫作風格。
2.1.3情感偏向
情感分析一直都是對情感詞的統計來分析文章情感,Xia等[4]在情感分析上使用神經網絡等,并且對比了實驗的結果,驗證了其有效性。Sailunaz等[5]使用機器學習基于各種基于用戶和Twitter的參數來計算用戶的影響分數,對Twitter進行情感分析。本文使用網絡中訓練的情感字典對文章進行情感分析。對使用情感詞典來進行情感分析的算法的形式化描述如算法1所示。
算法1情感分析算法
輸入:測試文本D1。
輸出:Pos,Neg,AvgPos,AvgNeg,Res。
1.BEGIN
2. 對中文語句進行分句,以句號為句子結束標志;
3. 查找分句中情感詞,記錄其是積極還是消極,及其位置;
4. 查找情感詞前的程度詞,匹配程度詞表,找到即停止搜尋;
5. 為程度詞設權值,乘以情感值;
6. 查找情感詞前的否定詞,匹配否定詞表,直至找到全部否定詞;
7. 若數量為奇數,乘以-1;
8. 若數量為偶數,乘以1;
9. 判斷分句結束處是否存在感嘆號;
10. 是,往前尋找情感詞,且相應的情感值+2;
11.每個分句計算所得的情感值,存在數組(list);
12.遍歷所有分句,計算AvgPos,AvgNeg;
13.END
14.返回所有分句的Pos,Neg,AvgPos,AvgNeg,Res;
其中:Pos表示積極參數的結果;Neg表示消極參數的結果;AvgPos表示積極參數的平均值;AvgNeg表示消極參數的平均值;Res代表最后情感偏向結果取AvgPos和AvgNeg相加的結果。通過實驗取Res作為最后的分類參數。文檔風格提取情況如圖2所示。
其中情感方差之差為積極情感方差減去消極情感方差。通過分析圖2(c),發現古龍和瓊瑤寫作時的情感傾向,大多都是消極情感,而且瓊瑤情感方差差值的波動范圍,完全包含在古龍的差值波動范圍之中。所以對于一個文檔,即便情感傾向發生變化也無法判斷是由于作者改變還是文檔情節內容改變而導致的。因此,該特征中易出現特征冗余問題。
2.2 多維風格特征
2.2.1詞匯特征
用詞方面可以體現一個人的文學功底,可以根據用詞的豐富程度去評判作者的寫作風格。詞匯特征[6]可以定義為詞的長度、詞頻、占比和密度等方向,詞匯特征如表1所示。

表1 詞匯特征表
這8個維度可以概括一個人在用詞上的習慣,把這8個特征作為最后的分類參數的其中8個。
詞長特征提取實例如圖3所示,縱坐標表示文檔中不同詞長出現的頻率。

圖3 詞匯特征
可以看出,雙字詞特征和詞匯豐富度存在與情感偏向一樣的特征冗余問題,兩個作者在對這雙字詞的使用頻率上重合范圍很大,沒有什么明顯的個人特色。古龍的詞匯豐富度大致在0.06~0.12之間,瓊瑤的詞匯豐富度大致在0.08~0.14之間,兩位作者的詞匯豐富度有很大范圍的重合,差異度不大。但是從三字詞和四字詞的使用頻率上可以看出存在差別,瓊瑤對三字詞的使用明顯沒有古龍頻繁,但是瓊瑤對四字詞使用要比古龍多得多,詞長中的三字詞和四字詞可以體現出兩位作者的寫作風格差異。
2.2.2特殊標點符號
標點符號能反映作者寫作時顯性或隱性運用銜接內容的行文習慣。作者在寫作過程中為了提高輸入效率和精簡篇幅,往往頻繁地使用標點符號以表達特殊的情緒。在作者使用短句和非正式文法時,對標點的統計可以看出作者對句型的使用習慣,比如感嘆句往往伴隨著感嘆符號一起使用,問句往往伴隨著問號一起使用,但是常用的標點符號共性太強,不能統計出一個作者的使用情況,所以需要使用特殊標點符號。
特殊標點符號特征統計冒號、分號、千百分號、單位符號、左右引號、左右括號、嘆號、省略號、破折號、問號和頓號,表示為P1-P11:
F={P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P11}
(1)
特殊標點使用簡單統計的方法,將特殊標點的統計作為最后分類算法的參數,需要刪除標點符號頻率為0的標點,所以該特征的維度最高是11維度,如圖4所示。

(a)逗號的使用比例 (b)句號的使用比例
可以看出,在感嘆號和冒號的使用比例上,可以明顯地體現出古龍與瓊瑤寫作風格的差異,其他標點符號的使用比例無法明顯分辨出寫作風格的差異,同樣存在特征冗余問題。
2.2.3同義詞
同義詞是中文文體中一個特有的分支,體現了中文的語言多樣性,在同義詞的使用上也可以體現作者的語言功底和對詞語的駕馭能力。對同義詞的使用習慣也可以看出一個作者的用詞習慣,從同義詞的使用情況出發,對同義詞的使用習慣進行統計,總結出作者的寫作習慣[7]。同義詞算法如算法2所示。
算法2同義詞特征統計
輸入:同義詞林,兩段計算文檔D1和D2。
輸出:SynVec。
1.BEGIN
2. 同義詞林預處理,加載同義詞林;
3. 對滑動窗口中的中文語句進行分詞;
3. 分裂查找文檔D1和D2中同義詞,找到同義詞表相應的位置,詞頻加1;
4. 同義詞和詞頻組成一個同義詞對,更新同義詞表,刪除詞頻為0的同義詞;
5. 比較兩個滑動窗口同義詞表,對位,0補位;
6. 刪除詞頻相同的同義詞,降維;
7. 同義詞向量集合作為最后同義詞的參數;
8. 輸出SynVec;
9.END
本文對哈工大同義詞詞林精減,通過測試文本集中的文檔,將其中從未出現的同義詞刪掉,如果一個同義詞詞組中一個也沒有出現,就將這組同義詞刪掉,形成新的同義詞詞林,最后根據測試結果將同義詞詞林精減到只有2 200組。獲得剩余同義詞和詞頻組成同義詞向量,其中D1和D2代表兩片測試文檔,SynVec代表同義詞向量結果。
本文選擇了同義詞林中的一組同義詞“人,士,人物,人士”,并統計其在10篇文檔中的使用分布情況,結果如表2所示。

表2 同義詞結果示例 %
根據表格中的數據可以看出,古龍的文檔在“人,士,人物,人士”這一同義詞組中,基本上只使用“人”這個詞語,而瓊瑤除了使用“人”這一詞語外,還少量地使用了“人物”這一詞語。因此可以通過同義詞詞組中同義詞的使用偏好,來觀察到作者的寫作特點。
2.2.4虛 詞
虛詞本身是沒有意義的,它的意義是它在句子中的地位,虛詞的數量有限,出現的頻率沒有實詞高,大約占詞匯使用率的1/3左右。可見虛詞在整個文章的占比還是很大的,并且它數量有限,容易統計,根據這個特性可以表示作者的風格特征。
本文增加虛詞的數量,通過自定義虛詞表作為基準,對虛詞表的虛詞使用情況進行計算。首先制作虛詞表,虛詞表來源是《現在漢語虛詞詞典》,虛詞表中一共有840個虛詞,和同義詞表相同,虛詞表較大,含有一些生僻和不常用的虛詞,會影響結果的計算。以搜狗新聞數據集為基準,對虛詞表的虛詞進行TF-IDF統計,刪除TF-IDF過低的詞。通過多次清洗,最后精簡到230個虛詞。選用230個虛詞首先能控制在一個合理的數量中,這230個虛詞能體現虛詞在新聞集中的重要程度,最后形成一個虛詞TF-IDF詞對表。在虛詞表中隨意選擇“被”這個虛詞,計算其在20篇文檔中的出現頻率。文檔風格提取情況如圖5所示。

圖5 虛詞特征
3 風格裂縫的識別
3.1 風格裂縫
風格裂縫指的是一個文本風格發生轉變的位置,換句話說一個文章可能由不同作者共同完成,所以在作者識別之前進行基于作者分段技術變得尤為重要,即找出這篇文章每一個行文作者對應的行文部分,風格裂縫點如圖6所示。通過寫作風格分段,目標是找到風格裂縫點,即風格發生轉變的位置。風格裂縫識別是通過風格的特征提取結合分類算法的技術,采用滑動窗口、降維等技術,找出風格裂縫點。風格裂縫是在多風格特征提取的基礎之上提出的一個概念,通過風格裂縫的識別能更好地進行分段技術。

圖6 風格裂縫示例圖
3.2 滑動窗口
滑動窗口以5個句子為一個整體,進行風格特征識別。每次向下滑動一個句子,對每個窗口進行風格統計,當風格發生轉變時,每次風格和上一次發生的結果有逐漸的變化,直到風格相似度又趨近不變,則這個位置產生風格裂縫。
但是實際情況是有極少可能出現理想狀態,為了更好地找到風格裂縫,需要在特征提取和分類算法上進行調優。因為論文篇幅較小,5個句子所含的信息量較少,很大的可能性會出現偶然現象,假定每次的風格裂縫位置有很大的可能性發生在每個段的段尾。為了提高準確率,只能犧牲召回率。假定每次風格裂縫必然會發生在段尾,即假定文章中的每一段有且僅有一個作者。滑動窗口示例如圖7所示。

圖7 滑動窗口示例圖
3.3 參數權重法
針對第2節中風格特征分析產生的特征冗余問題,每一個參數在風格裂縫識別過程中占用的權重不盡相同,所以在查找風格裂縫的時候需要找出每個參數的權重,然后通過參數調節的權重進行風格裂縫識別。
參數權重法首先對所有參數權重進行遍歷,通過多組新聞集進行遍歷,對參數進行調優,最后找出每個特征的最優參數,虛詞和同義詞精減之后分別選用同一組參數作為權重,在訓練過程中選中搜狗新聞集作為語料庫。
算法描述:首先對數據集進行預處理,對數據集合進行特征提取,把數據集打亂順序存到文件里,在其他特征參數權重不變的情況下,借用控制變量法的思想,控制詞長度參數(WLP)從0.01到0.99進行計算,其他參數為0.5,得到在其他參數不變的情況下參數WLP的最優值,最優值是以兩篇文本相似度最低為標準。再在其他參數不變的情況下,以平均句子長度參數(ASLC)從0.01到0.99進行計算,得到ASLC的最優值,以此遍歷所有的參數。然后都以上一次參數最優的結果為基準,繼續上面的方法進行循環,直到參數最優值不變為止,得到參數權重組,目的是通過參數權重法發現每一個參數的有效性,刪除無效參數。
得到的參數權重組,發現其中一些參數權重過小,這類特征對結果起到積極影響較小,但是會影響實驗的效率,所以刪除這些參數。
4 基于融合特征的風格聚類
4.1 實驗思路
文本的特征提取是風格識別的主要方法,該方法對風格特征進行了層次分類,運用層次的角度進行特征的提取,加入特征與文章之間的一個映射關系。特征提取包括單維特征和多維特征兩種,利用參數權重法對特征優化,把每個特征提取的結果作為最后K-means++分類器[8]的輸入,通過滑動窗口找到風格裂縫,通過識別的風格裂縫點進行文章分段。
語料庫選用自己構建的新聞語料庫,語料集的主題包括利用爬蟲技術在人民日報官網收集的關于時政、法制、旅游等方面的新聞,以及從虎撲新聞官網爬取關于體育的新聞。由于新聞集合中存在一些時間、圖片、圖片介紹和攝影師姓名等雜質。首先對新聞進行雜質處理,選取文中的正文。把新聞存成.csv文件,以作者姓名為新聞的標注,把1 300篇新聞分為1 150個訓練集和150個測試集,訓練集和測試集的比例約為9:1。為了驗證小篇幅的準確性能,又把150篇測試集分為100篇,并按照篇幅存儲,剩余50篇按照段落存儲,大概是215段新聞。
4.2 單特征風格裂縫識別結果
對提取的7類風格特征進行單獨實驗,分別驗證每一個風格特征對風格裂縫識別的效果,基于段落級別進行風格裂縫識別,取作者一時政編輯曹昆、作者二體育編輯郝帥、作者三法制編輯袁勃、作者四旅游編輯田虎、作者五時政編輯王政淇的新聞集融合作為測試集。實驗結果如表3所示。

表3 單特征實驗結果展示表 %
本次實驗放寬了召回率,這樣準確率會隨之減小,但是當前F值會相對增大。隨著召回率的降低,召回結果的減小,準確率也會隨之提升5~10個百分點。從結果可以看出,單維度特征維度偏少,效果不佳,情感分析結果較差,對風格裂縫識別作用較小;多維特征風格結果中,虛詞、同義詞和特殊標點的使用對風格影響較大,F值偏高,相比而言詞匯特征過于復雜,對風格裂縫識別成中性。
4.3 參數權重優化
在語料庫方面首先隨機抽取上述5名編輯作者的100篇文章形成一個小樣本的訓練集,用來對參數權重法進行訓練。對訓練集進行預處理,把每一個作者的文檔集放到一個.txt文件中,對每一個作者的文檔集風格特征進行提取,形成風格特征向量。首先提取平均句子長度參數,進行分詞處理,分詞處理過后提取平均詞長度、詞匯特征、特殊標點符號;再提取虛詞進行虛詞TF-IDF算法,提取同義詞填充同義詞向量;最后計算訓練集的情感偏向。
在計算平均句子長度時,以“。”“!”“?”作為評定句子結尾的三個標志,以每一個字作為一個長度計算。在分詞過程中采用粗粒度分詞系統,例如“北京大學”在粗粒度分詞系統中不會被拆開,在細粒度分詞中會被拆分成“北京”和“大學”兩部分。本文在長度和詞性特征上需要保證詞匯的完整性。
在訓練過程前預先設定7個參數權重,分別是平均句子長度、詞長度、情感偏向、詞匯特征、特殊標點、同義詞和虛詞,所有同義詞使用同一個特征權重,所有虛詞也使用同一權重。實驗結果如表4所示。

表4 參數權重法結果
可以看出,作者四在詞長度上明顯與其他作者不同,經過實驗發現作者四的平均詞長度為3.213 2,三字詞、四字詞占的比重較大,而其他作者都是在2~3之間徘徊。句子長度對結果影響較小,作者二、作者四和作者五句子長度較為相似,與其他句子差距也較小。情感分析對文章影響最小的原因是5名作者都是客觀的新聞,對主觀情感偏移較小。詞匯特征的參數沒有明顯的規律說明多個特征影響權重不同,但是肯定是對風格裂縫識別實驗有積極的影響。特殊標點符號的使用次數較為平均,只有作者三的特殊標點和大家較為相似。同義詞和虛詞上效果就比較明顯,參數值較大,對結果影響也較大。從實驗結果上看,同義詞和虛詞對結果影響較大,但是其他特征在特殊情況也能體現自己的寫作風格。從寫作風格提取結果進行風格相似度計算,發現作者一、作者三、作者五相似度較高。
4.4 風格裂縫識別實驗
4.4.1新聞集實驗
風格裂縫識別數據集隨機抽取上述5名編輯作者的20篇新聞,按照段落拆分,以段落為一個部分在實驗開始的階段使用滑動窗口技術,每次向下滑動一個句子,每次窗口句子數量為5個。隨著實驗的進行,在K-means++聚類的結果中聚類結果較差,因為每一次變化為一個句子,變化的幅度較小,每一次變化不明顯導致聚類時鄰近的窗口結果偏差較小。加上以段落結尾為風格裂縫出現的位置,準確率才會有所回升。在聚類過程中會導致K的結果不確定,是K-means++算法中心點不準確導致的,所以許多聚類錯誤情況出現。實驗結果如表5所示,可視化圖如圖8所示。

表5 利用滑動窗口進行風格裂縫識別結果 %

圖8 基于滑動窗口K-means可視化圖
最后,本文放棄滑動窗口改用識別段落轉換符,即把每一個段落視為一個作者完成的內容,以每個段落為單位進行風格特征提取,再根據提取的風格特征進行K-means聚類算法。實驗結果如表6所示,可視化圖如圖9所示。

表6 基于段落進行風格裂縫識別 %
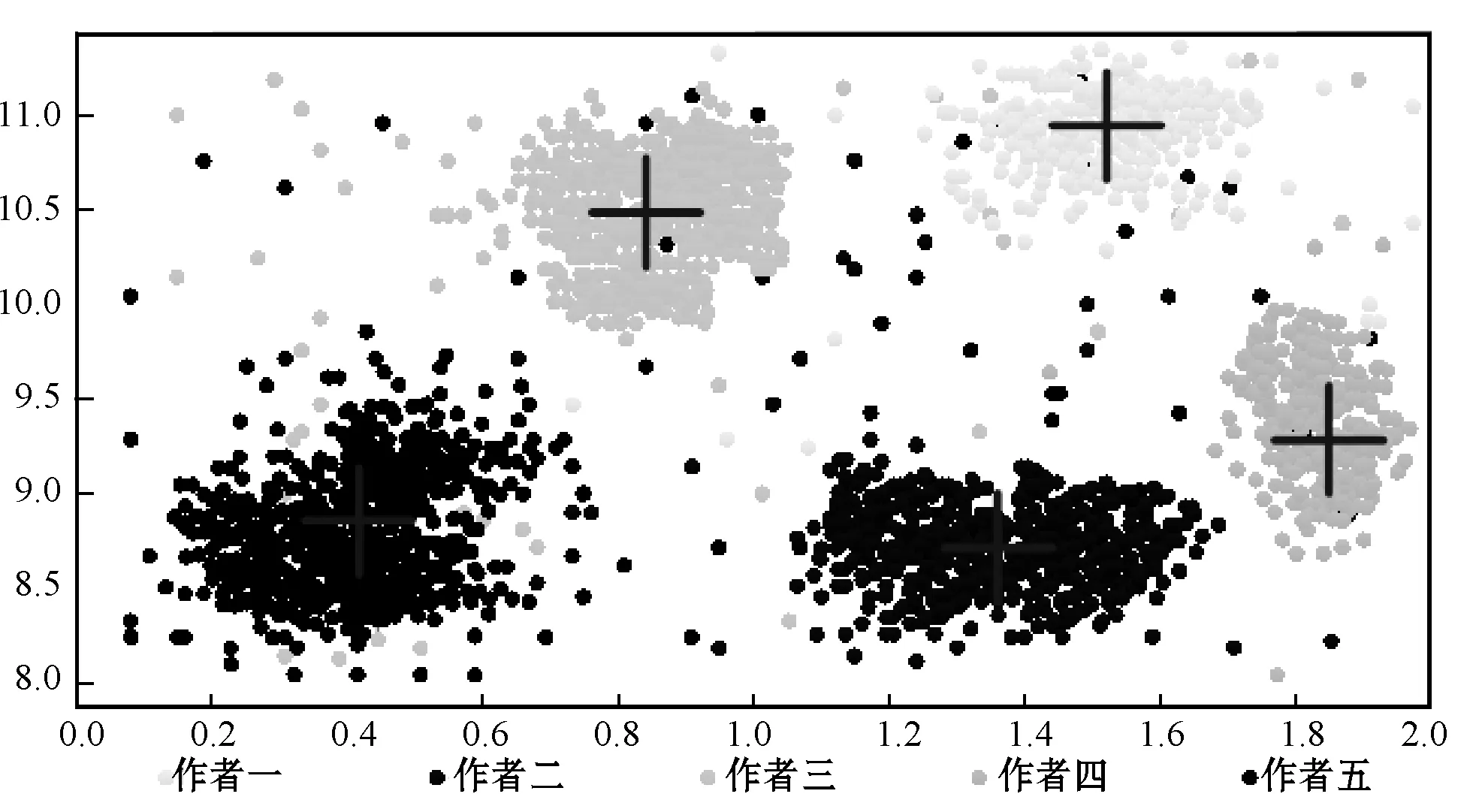
圖9 基于段落K-means可視化圖
雖然滑動窗口的提出是為了盡可能全面地找出所有的風格裂縫點,但是由于每次變化一個句子,對結果變化不明顯,風格聚類效果一般。基于段落進行風格裂縫識別效果要好于利用滑動窗口的實驗,在準確率和召回率上都有所提升,在評估值上也能提升10個百分點。
4.4.2小說集實驗
《紅樓夢》后40回原創性檢測一直是文學家討論的主要對象,本文對分割裂縫識別最后的實驗就是以《紅樓夢》為背景。使用《紅樓夢》電子小說的網絡資源進行全文下載,以每一回作為一個整體,進行風格特征提取,其中虛詞不再使用本文的虛詞表,而是使用22個文言文虛詞表。對120回進行基于風格特征提取的風格聚類,結果統計分成前40回,中間40回,后40回,K-means算法的K值為2,結果如表7所示,可視化圖如圖10所示。

圖10 紅樓夢結果分析可視化圖
從結果可以看出,前80回的準確率較高,后40回相對偏低。通過對單獨特征的實驗結果發現,平均句子長度、情感分析和虛詞對結果影響較大,前80回與后40回在句子長度上有明顯的區別。情感分析影響較大的原因是,前80回偏積極,后40回偏消極,虛詞對實驗結果影響最大,22個虛詞表對實驗結果影響較為積極。
5 結 語
本文提出一種多特征融合和無監督的機器學習算法相結合的方法進行風格裂縫識別。其中多特征融合是為了更好地提取作者的風格特征,而機器學習是以滑動窗口或段落為基準的,基于提取的特征進行分類,利用聚類算法對風格特征進行聚類,從而找到風格裂縫的位置。分別對新聞語料集和小說語料集進行實驗,得出基于段落的裂縫識別比基于滑動窗口的實驗效果在評估值上高出10個百分點,因此基于滑動窗口的實驗思路仍需進一步改進。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中國生殖健康(2020年5期)2021-01-18 02:59:48
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
