融合項目圖像的混合推薦算法
2020-10-15 12:16:38王宇飛
計算機應用與軟件 2020年10期
王宇飛 陳 璐
(浙江工業大學管理學院 浙江 杭州 310023)
0 引 言
隨著信息時代的到來,信息過載問題愈發突出,面對海量的數據,傳統信息獲取工具已無法滿足用戶個性化的需求。推薦系統使用用戶行為產生的數據來探求用戶的興趣、預測用戶行為,從大量繁雜的數據中找到符合用戶的項目(如信息,服務,物品等),并將其推薦給用戶,不僅節約了用戶篩選信息的時間,還提高了信息的利用率[1]。
傳統的推薦算法[2]必須依賴用戶評價信息。以電影推薦為例,由于電影的數量龐大,用戶只可能對其中的一部分進行評價,因此會產生用戶共同評分項目太少導致評分數據稀疏的問題,這會導致在使用用戶對項目的評分計算用戶或物品的相似度時,產生較大的誤差。這樣,就難以保證最近鄰居搜索結果的準確性,使得預測值與真實值之間可能誤差較大,從而影響推薦的效果。
針對傳統算法中存在的問題,相關領域的研究人員使用聚類[3-4]、矩陣分解[5-6]、slope one算法[7-8]等方法來解決這個問題。朱麗中等[9]將云模型方法引入到協同過濾算法中來,利用項目聚合產生預測結果,從而提高推薦結果的穩定性。韋素云等[10]利用項目屬性構造項目相似度矩陣,并與興趣度相結合,使用改進的公式重新衡量項目的相似度,提升推薦質量。魏甜甜等[11]在項目相似度計算時引入項目流行度,提升了推薦準確度。上述方法都通過分析項目,利用項目的不同特性提高推薦的質量,但并沒有很好地將項目的內容信息提取出來加以利用。
伴隨著讀圖時代的到來,快節奏的生活導致時間的碎片化程度加重,許多人沒有整塊時間去閱讀文字,人們也不愿意將注意力集中在文字上。圖像等類似媒體(包括短視頻)替代了文字,它們能讓人們以最輕松的方式快速獲取信息,人們也更加愿意通過圖像來了解信息。圖像在一定程度上可以反映項目的內容,內容信息相近的項目,其圖像往往也具有很高的相似度。本文將項目圖像與評分動態組合,得到一種新的推薦算法,從項目圖像和項目評分兩方面出發,解決傳統算法中存在的問題,提高推薦質量。
1 基于項目的協同過濾算法
1.1 數據描述
本文將用戶集合定義表示為U={u1,u2,…,um},項目集合表示為I={i1,i2,…,in},用戶-項目的評分矩陣表示為R=(rui)m×n,得到的評分矩陣R如下:
1.2 項目評分相似度計算

(1)
2 融合項目圖像的混合推薦算法
針對根據項目進行推薦時并沒有完全利用項目圖像這一因素,本文利用卷積神經網絡提取圖像特征,利用提取后的特征值得到項目圖像之間的相似度,與項目評分相似度動態結合,進而產生推薦。
2.1 VGG16卷積神經網絡
卷積神經網絡(CNN)是近年發展起來的一種圖像特征提取方法[12],由于其抽取的圖像特征是通過數據學習得來的,克服了傳統手工需要通過設計才能提取圖像特征的缺陷,節約了大量的人力和時間,因而受到廣泛的關注。VGG16是使用最多、效果顯著的卷積神經網絡模型[13],其利用卷積計算層、池化層進行圖像特征的提取[14]。
卷積層采用卷積的方式,即一種加權的方法,通過一個加權函數(卷積核)對提取特征需要的信息賦予更高的權重,進行特征提取,將卷積核重復作用于圖像的每一塊區域,即完成一次特征提取,提取出的結果稱之為特征圖。池化層的主要作用就是將經過卷積層處理后得到的特征圖進行一定程度的壓縮,防止過擬合現象的出現。
2.2 圖像相似度
經過VGG16卷積神經網絡進行特征提取,每一個電影海報輸入到VGG16模型中進行特征提取,會形成一個512×7×7的輸出,即提取到的電影海報的特征數據,把這個輸出處理為一維的形式,將每個電影海報的特征記錄下來,利用余弦相似度公式獲得項目圖像相似度sim2:
(2)
式中:ia、ja分別代表項目i和j的圖像經過特征提取后形成的向量;pik、pjk分別代表向量ia、向量ja在位置k上的取值。
2.3 混合相似度
由于電影海報中會有一些通用的元素,比如人物形象、場景等,這些元素可能使關聯性不是很強的項目具有很高的圖像相似度,因此引入項目類別屬性來對項目圖像相似度進行修正,使利用圖像相似度找到的都是項目類型、內容與目標項目更加接近的項目。電影有動作、科幻、愛情、冒險等項目類別屬性,利用數據集存儲的項目信息,提取出項目的類別屬性矩陣,如表1所示。
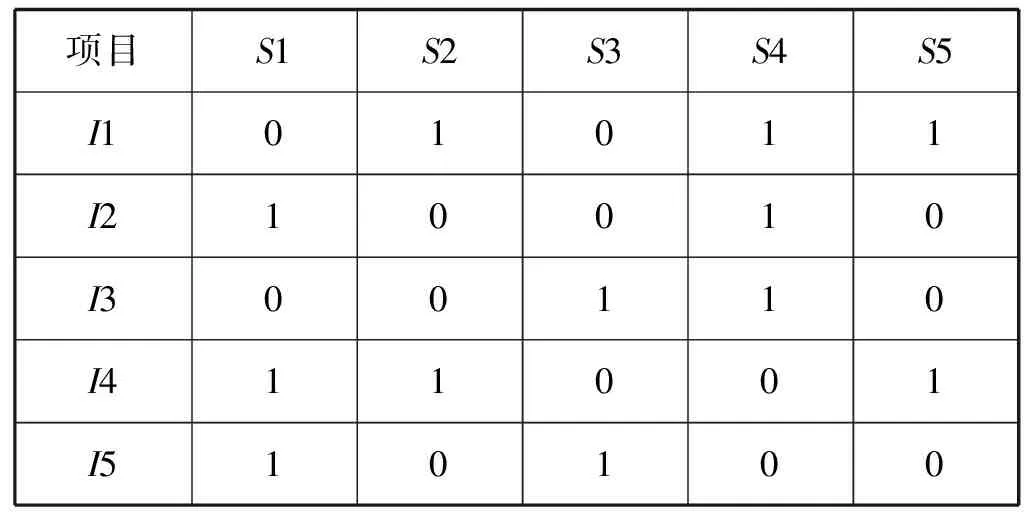
表1 項目-類別屬性矩陣
表1中:I1-I5表示項目;S1-S5表示項目類別屬性;1表示項目有這個類別屬性;0表示項目沒有這個類別屬性。通過數據集,獲取項目-類別屬性信息,可得到項目-類別屬性矩陣CN,從中可以得到每個項目的類別屬性,并利用式(3)[15]來度量兩個項目屬性相似度。
(3)
式中:CNi、CNj代表類別屬性集;CNi∩CNj是i與j都擁有的類別屬性數量;CNi∪CNj為項目i與j擁有的所有類別屬性的量。λ越大表示項目類別屬性相差越大,λ越小表示項目類別屬性相差越小。本文設計類別屬性因子λ,將評分與圖像的相似度線性結合,計算方式如下:
sim(i,j)=(1-λ)sim1(i,j)+λsim2(i,j)
(4)
引入λ來組合圖像和評分的相似度,λ與項目的屬性類別有關,利用項目類別屬性可以修正項目圖像由于圖像共有元素而導致的計算偏差,可以更好地找到與目標項目特性相同的項目。
2.4 預測評分生成
通過式(4),可獲得項目間的相似度,構造出相似度矩陣S。對于任意用戶u,根據用戶-項目評分矩陣Rmn獲得用戶u的已評分項目集合Iu,可以得到u的未評價的項目集Nu=I-Iu。對于集合中的元素i(i∈Nu),可以根據矩陣R和矩陣S選取出與項目i相似度最高且有評分的一些項目構成其最近鄰Inear={ii1,ii2,…,iim},并用式(5)來預測u對i的評分[16]。
(5)

2.5 算法流程
本文引入圖像信息,把項目圖像信息和評分信息進行線性結合,得到新的項目相似度計算方法;通過新的計算方式,得到項目的最近鄰集;通過最近鄰集,預計評價值;使用預計分值進行排序,將預計評分高的項目推薦給用戶。融合項目圖像的混合推薦算法(PB-CF)的具體流程圖如圖1所示。

圖1 PB-CF算法流程圖
由于只利用圖像信息同樣可以得到項目的相似度找到項目的最近鄰集進行評分的預測,因此本文同時提出只基于項目圖像信息的相似度計算方法,融合項目圖像的混合推薦算法(P-CF)的具體流程圖如圖2所示。

圖2 P-CF算法流程圖
3 實 驗
3.1 數據集
本文使用MovieLens100k[17]作為實驗數據集,MovieLens是推薦算法研究領域中最被人熟知、最常被使用的數據集,其中有943名測試者對1 683部影片的10萬條記錄信息,電影海報數據集來自IMBD,通過API接口找到MovieLens數據集中的相關電影海報。
實驗環境使用Windows 10操作系統,8 GB內存的Intel i5-7300處理器,在Spyder開發環境下,使用Python語言進行算法代碼的編寫和測試。將MovieLens數據集中的數據按照4∶1的比例進行隨機劃分,其中80%的數據作為訓練集數據,另外20%的數據作為測試集數據。
3.2 評價指標
實驗使用平均絕對誤差(MAE)和均方根誤差(RMSE)作為實驗的評價指標,其具體的計算公式如下:
(6)
(7)
式中:N為預測評分集合中的項目的個數;pi為通過本文算法得到的用戶對項目i的預測評分;qi表示用戶對該項目的實際評分。推薦的效果與MAE和RMSE的值呈負相關關系,MAE、RMSE值越小,表示推薦的效果越好,推薦質量越高。
3.3 最近鄰數量確定實驗
為確定本文算法中最近鄰數量的最佳值,本次試驗選取10、15、20、25、30、35、40、45、50的幾種最近鄰數量進行實驗,圖3、圖4為實驗結果。

圖3 各最近鄰數量下MAE誤差情況

圖4 各最近鄰數量下RMSE誤差情況
由圖3可知,隨著最近鄰數量的增加,MAE的值逐漸變小,最近鄰數為40時,MAE值趨于穩定,約為0.75。由圖4可知,隨著最近鄰數量的增加,RMSE的值逐漸變小,最近鄰數為40時,RMSE值趨于穩定,約為0.96。
3.4 對比實驗
為了體現本文PB-CF算法和P-CF算法的推薦結果準確性與其他算法的差別,本文選取傳統的推薦算法進行對比試驗,其中包括基于項目的協同過濾算法(IBCF)、基于用戶的協同過濾算法(UB),對比結果如圖5、圖6所示。可以看出,相較其他推薦方法,本文的PB-CF和P-CF算法推薦誤差值較小。基于圖像的P-CF算法的MAE和RMSE值比其他三種算法的準確度更高,但考慮到信息的多樣性和單一數據集數據的特殊性問題,還是利用PB-CF算法進行推薦。
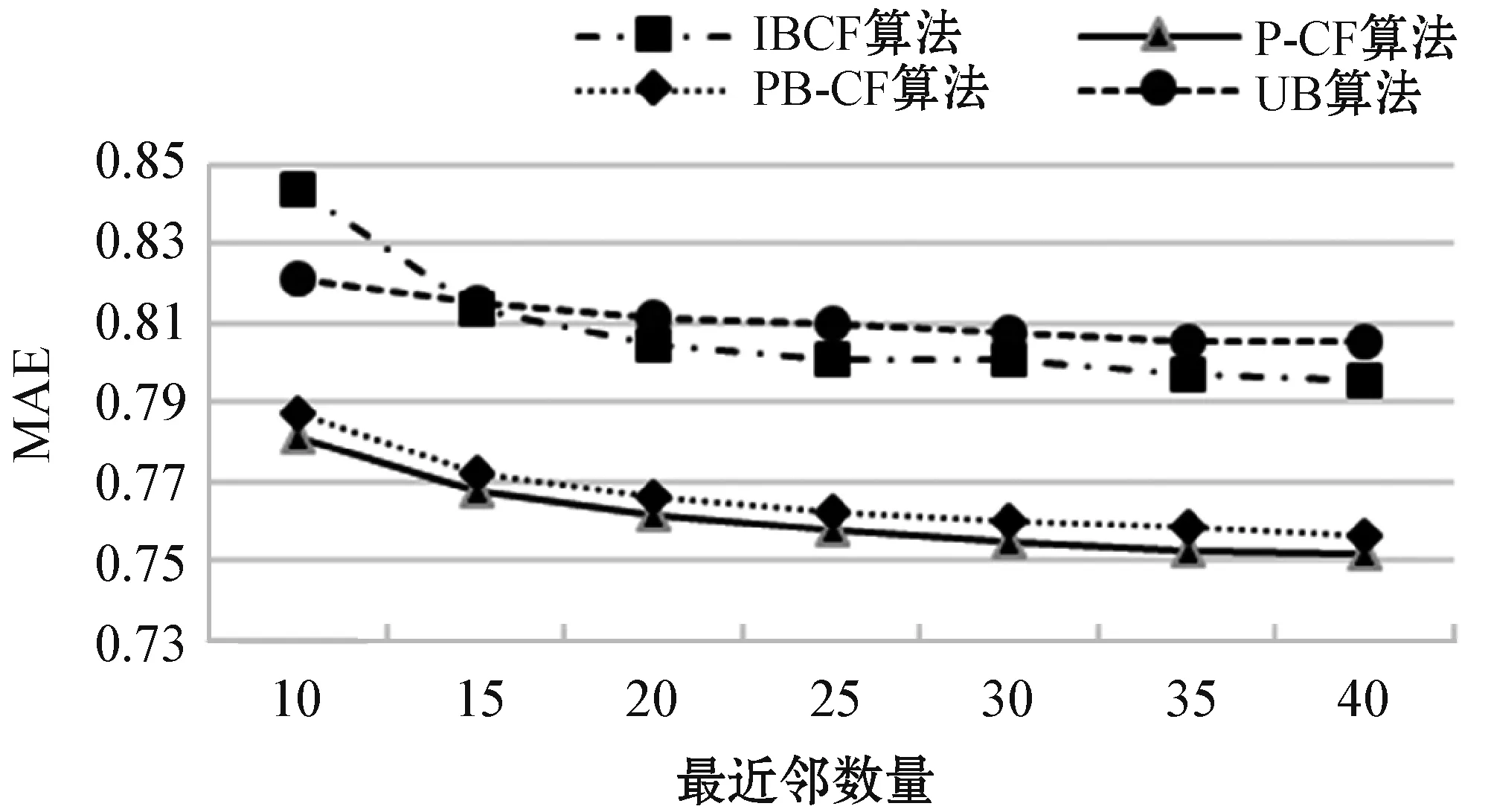
圖5 對比實驗結果1
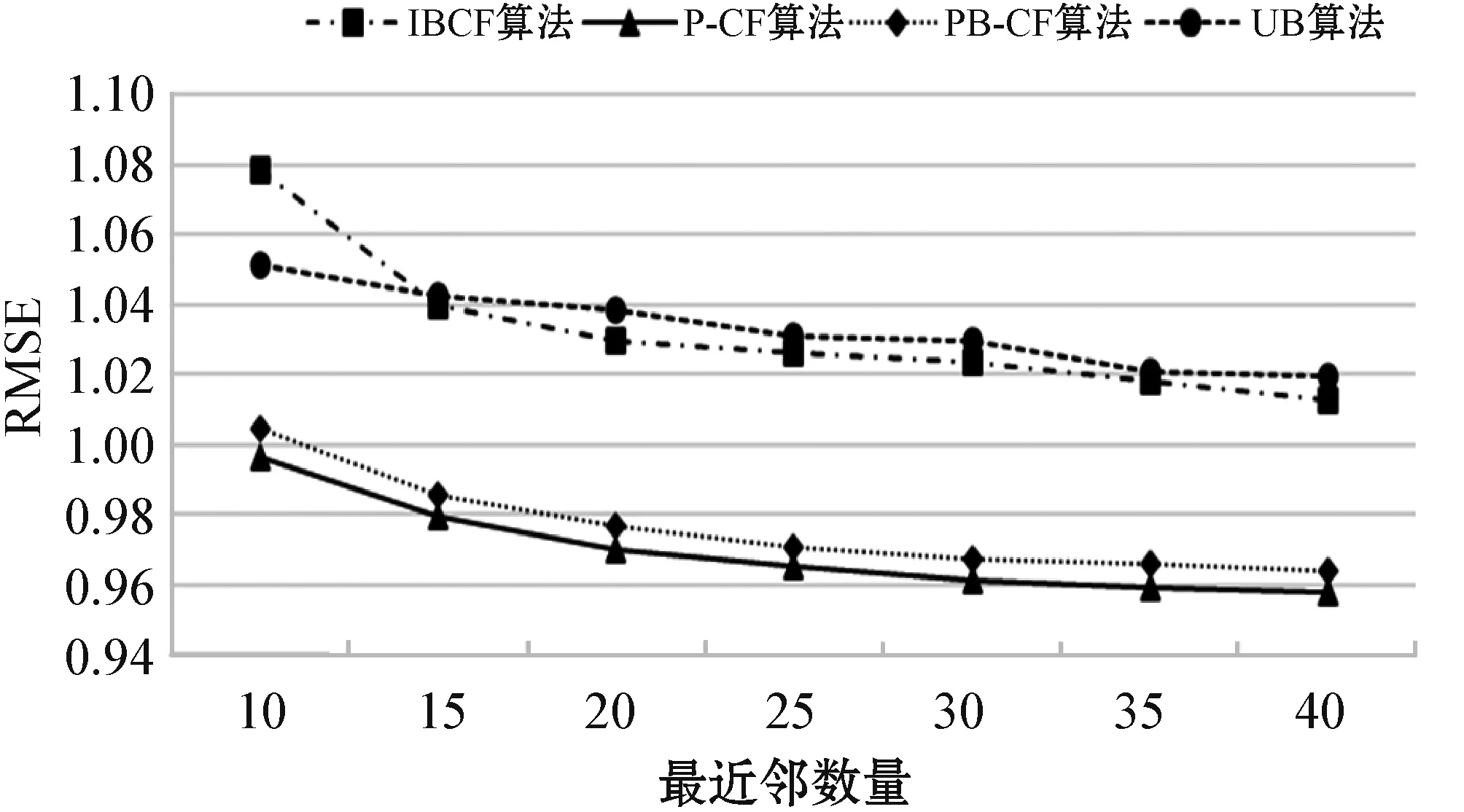
圖6 對比實驗結果2
4 結 語
本文將圖像信息引入到項目相似度計算公式中,并設計動態加權方式對其進行結合,獲得新的項目相似度衡量方式,通過算法獲得的項目最近鄰更精準。實驗結果表明,本文提出的融合項目圖像相似度計算方式,在引入項目圖像特征后有效地緩解由于數據稀疏引起的計算偏差,提升推薦的準確度,不足之處在于圖像特征提取的準確度還不夠高,針對不同的數據集利用圖像信息是否能取得同樣良好的效果,需要進一步深入研究。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
