日本國立國會圖書館人工智能實驗室的實踐與啟示
2020-10-09 13:26:20王劍
圖書館研究與工作 2020年10期
王 劍
(營口理工學院圖書館 遼寧營口 115014)
1 引言
1956年,J.McCarthy[1]在美國達特茅斯會議上正式提出人工智能(Artificial Intelligence,簡稱AI)概念。在過去的64年中,人工智能取得了國內外的廣泛關注和長足發展。我國政府非常重視人工智能的發展。2017年被稱為我國人工智能發展的元年,因為這年我國首次將人工智能寫入《政府工作報告》,并且出臺了《新一代人工智能發展規劃》[2]。人工智能已經成為第四次產業革命的核心技術,成為我國經濟發展的新動力,并影響著我們生活的方方面面。
人工智能也推動著圖書館的發展,受到了國內外圖書館界的關注。國際圖書館協會和機構聯合會(International Federation of Library Associations and Institutions,簡稱IFLA)多次提到人工智能,認為人工智能是未來發展趨勢之一[3]。美國圖書館協會(American Library Association,簡稱ALA)認為人工智能將改變高校的教學與研究模式[4]。現如今人工智能在圖書館的應用以人工智能設備為主,涉及到科研服務、檢索服務、學科服務的較少。美國羅德島大學圖書館人工智能實驗室是首個高校圖書館人工智能實驗室[5],為高校圖書館人工智能服務做出了有益的嘗試。日本國立國會圖書館在2013年成立了實驗室,并重點研究下一代數字圖書館,在實驗室中應用了許多人工智能技術。本文以日本國立國會圖書館人工智能實驗室作為研究案例,以期豐富圖書館人工智能服務方面的研究成果。
2 我國圖書館人工智能綜述
人工智能已經成為我國圖書館界的研究熱點之一,在中國知網已經收錄了200余篇相關文獻。特別是從2017年以來,我國圖書情報核心期刊發表了不少與人工智能相關的論文,且發文數量呈上升趨勢。2017年《圖書與情報》分2期發表了10篇圖書館與人工智能相關的論文,帶動了國內圖書館界人工智能的研究熱潮。這些發表的論文主要圍繞以下主題展開:一是人工智能在圖書館各服務領域的應用,董同強[6]、宮平[7]、夏晶[5]、王紅等學者[8]分別從學科服務、繪本閱讀和教育領域、服務模式等方面探索人工智能在圖書館的應用;二是空間建設的影響,蒲姍姍[9]、鄭鐵亮[10]等人從人工智能服務下的圖書館空間設計、建筑造型等方面深入研究;三是對圖書館人工智能服務的理性思考。祝鳳云[11]認為圖書館應用人工智能服務具有信息泄露、網絡攻擊、虛假信息等風險,所以圖書館應做好相應的應對措施。歐陽愛輝[12]認為圖書館應用人工智能服務存在相關法律不明、具體服務內容缺乏法律指引、損害救濟等配套機制缺失等問題,所以圖書館要做好法律困惑的解決設計。麻思蓓和許燕[13]認為人工智能存在局限性,帶來一定的倫理挑戰,所以圖書館的人工智能服務應做好相應的評估工作,規避相應的法律及倫理風險,做好館員信息素養培訓等工作。楊九成等學者[14]認為圖書館人工服務存在技術、制度、理念、倫理等方面的缺陷,建議在圖書館應用人工智能服務時從文化回歸到人本管理。王文敏和高軍[15]等人認為人工智能在圖書館領域有著作權侵權風險。綜上所述,我國有關圖書館人工智能服務的研究不少,且研究的切入點也較多,但對圖書館人工智能實驗室研究的較少。雖然有學者對美國羅德島大學圖書館實驗室進行研究,但偏向于在教育領域的應用,而日本國立國會圖書館人工智能實驗室則傾向于將人工智能技術應用到數據庫檢索、資源建設等
圖書館核心業務上。
3 日本國立國會圖書館人工智能實驗室發展概況
日本人工智能學會成立于1986年,推動著日本人工智能技術的發展,迄今已經取得第五代計算機、極限作業機器人等成就。2016年日本設立“人工智能技術戰略會議”,并在《日本再興戰略2016》中提出大力支持日本人工智能發展[16]。2017年日本推出《下一代人工智能推進戰略》,明確人工智能技術的發展方向。2018年日本在《新產業構造藍圖》中指出將人工智能應用到智能汽車、醫療等領域。可見日本對人工智能發展非常重視。
日本國立國會圖書館實驗室(Lab of National Diet library, Japan,簡稱NDL Lab)正式成立于2013年[17],利用先進的信息技術應用到新的數字圖書館服務中。由于NDL Lab使用了許多人工智能技術,本文將NDL Lab稱為日本國立國會圖書館人工智能實驗室。NDL Lab是人工智能技術實驗的場所,待技術成熟之后再推向社會。NDL Lab的人工智能服務發展不錯,于2019年應邀在IFLA做相關報告[18]。
3.1 下一代數字圖書館
“下一代數字圖書館”是NDL Lab最主要的服務內容,為日本國立國會圖書館搜索提供實驗研究而開發的數字圖書館系統,將機器學習和國際圖像互操作性框架(International Image Interoperability Framework,簡稱IIIF)應用到搜索引擎領域,目前支持全文搜索和圖像搜索兩大功能[19]。“下一代數字圖書館”能為讀者提供自動生成的檢索結果目錄,并自動判斷翻頁方向。“下一代數字圖書館”可檢索的內容為版權保護期已過,進入公有領域的數字化材料,以技術工程(NDC5類)、勞資關系(NDC6類)和藝術書籍(NDC7)為主,截至2019年有58 000種數字化材料。在2019年IFLA世界圖書館與圖書館大會《圖書館:第114屆會議的對話——信息技術和大數據的知識管理》上,日本發表論文《數字圖書館的新功能:增強國立國家圖書館的可發現性》進行了系統闡述[18]。
(1)全文搜索。全文搜索支持讀者使用OCR軟件生成帶有關鍵詞的全文材料。在關鍵詞搜索框中輸入內容即可獲得,并支持在線閱讀和下載。以輸入人工智能的英文簡稱AI為例,共檢索出7 935個相關記錄,第一條結果如圖1所示。京都高等工蕓學校1933年出版的圖書《Saibi 33》中有5處提到AI,分別出現在文字段落和圖片中。可見全文搜索不僅支持段落文字,也支持圖片中的文字部分。
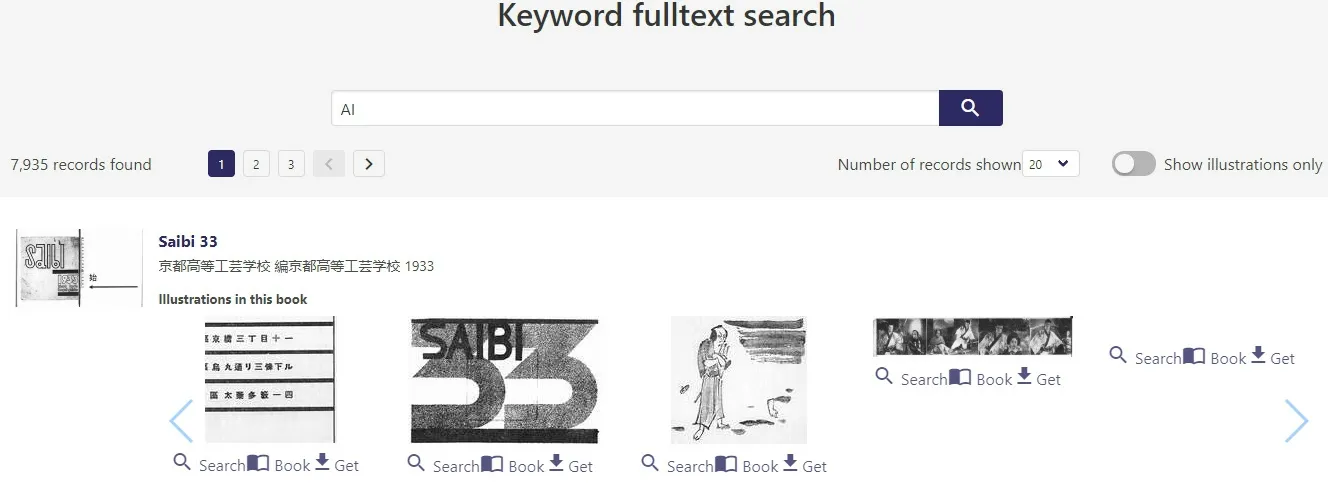
圖1 以“AI”為關鍵詞進行檢索的部分結果
(2)圖像搜索。“下一代數字圖書館”為讀者使用自動裁剪功能進行圖像搜索,從圖書館系統中自動提取相似圖像,支持4種搜索方式:從樣本中搜索圖片、從元數據中搜索圖片、從本地圖像中搜索圖片和從插圖中搜索圖片。①從樣本中搜索圖片是指為讀者提供幾張圖片,讀者選擇其中一張跟自己檢索意愿最接近的圖片進行搜索,系統將為讀者返回許多相似的圖片供讀者選擇;②從元數據中搜索圖片是指讀者輸入相應的關鍵詞,系統為讀者返回系列相關主題的圖片,如以“造船”進行檢索可獲得578個與造船有關的圖片結果;③從本地圖像中搜索圖片是指讀者可在本地上傳自己的圖片進行匹配檢索;④從插圖中搜索圖片是指讀者可在該系統進行繪畫,再根據讀者的繪畫進行系統匹配。“下一代數字圖書館”的圖像檢索技術提供多種檢索方式,并且進行圖像自動提取和匹配,滿足讀者的多方面需求。
3.2 NDC預測器
NDC預測器(NDC predictor)是NDL Lab的一項通過機器學習來猜測日語十進制分類技術[20]。NDC預測器的機器學習技術源于Facebook AI Research開發的FastText(外部站點),用于分類。一般來說,分類類型越少,NDC預測器的準確性越高。NDC預測器1~3位數的準確性分別為86%、82%和76%。讀者可在NDC預測器的搜索框中輸入自己的問題,給的信息越具體,結果的準確性越高,給的信息越寬泛,結果的準確性越低。以NDC預測器提供的案例1“Dolittle博士的《嘎巴布書》新譯本:休·洛夫廷(Hugh Lofting)的系列特別版(Shoichiro Kawai翻譯)”為例。由于該案例非常具體,具體到了作者、書籍名、譯者和版本等,所以其檢索結果的準確性也很高。檢索結果“933/美國文學—小說物語”的置信度為0.998。置信度在0~1之間,數值越大表明準確性越高。
3.3 MIMA搜索
MIMA搜索是NDL Lab為讀者提供的一種搜索和可視化系統[21],包含了日本國立國會圖書館92萬項書目信息和71萬項目錄信息,通過這些文檔的語義關系而進行數據挖掘和可視化展示。MIMA搜索檢索到文檔的結果一般由帶有“點”和“線”的圖形結構表示。文檔之間的語義關系越強,它們將越靠近圖放置,反之則更遠,以可視化的圖像直觀地理解文檔之間的關系。本次研究以“人工智能”為關鍵詞,在MIMA的搜索結果如圖2所示。從圖2可知,在MIMA搜索系統中形成了7大與人工智能相關的群組,其中圖形最大的是與“智能檢查”有關。

圖2 以“人工智能”為關鍵詞在MIMA的搜索結果
除了圖形展示,MIMA還提供了作者、出版地、出版年份、出版機構、語言分類等多種分類方式,讀者可以根據自己的需要進行精煉并形成相應的可視化圖形。
3.4 其他服務
(1)聯合錄入。Hoso-Digi[22]是NDL Lab推出用于聯合錄入和文本校對進入公眾領域的圖書。該系統由隸屬于日本數字人文學會(Japanese Association for Digital Humanities,簡稱JADH)的子委員會SIGTranscribe JP的長崎實驗室人文與信息科學研究所首席研究員開發。Hoso-Digi旨在通過眾包的方式,讓許多參與者輸入和校對文本,從而提高NDL Lab讀者的便利性。目前Hoso-Digi已經在“下一代數字圖書館”中進行應用。
(2)圖像提取。Kokudeco Image Wall[23]也是長崎實驗室人文與信息科學研究所首席研究員開發,支持讀者將圖片和圖表從日本國立國會圖書館數字館藏的頁面中提取出來,并形成縮略圖。在該縮略圖中有該書面的簡要介紹及原文獲取的相關鏈接。截至2019年3月,在Kokudeco Image Wall系統中已注冊了2 002卷(22 321例)數據。
(3)關聯搜索服務。為了讓讀者能獲取更多的文獻,NDL Lab推出了國家信息學研究所特聘副教授安部武史(Takeshi Abe)開發的電子閱讀支持系統[24],支持將來自于維基百科等非NDL自身擁有的信息源的相關參考信息推送給讀者。該系統通過OCR軟件識別處理錯誤信息,并通過人工更正錯誤,從而支持閱讀功能正常運行。
4 日本國立國會圖書館人工智能實驗室的特點
4.1 非常重視人工智能在數字圖書館建設中的作用
人工智能在圖書館的應用最為常見的是智能設備的投入,如圖書排架機器人、智能咨詢機器人等。但日本國立國會圖書館非常重視在數字圖書館建設中應用人工智能技術,并于2011年就開始嘗試,2013年更是設立專門機構NDL Lab,從而大力促進人工智能技術的應用。NDL Lab在近7年的時間里取得了“下一代數字圖書館”、NDC預測器、MIMA搜索等有代表性的人工智能技術成果。由于人工智能技術在研發和應用過程中會出現許多不確定性,可能會給圖書館帶來技術、法律和道德風險,故日本國立國會圖書館通過成立NDL Lab進行人工智能技術研發是非常有必要的。人工智能技術在NDL Lab應用成熟之后,再將其推廣到現有的數字圖書館系統中。NDL Lab幫助日本國立國會圖書館提高了數字圖書館的搜索水平,豐富了讀者的搜索結果。
4.2 需求導向的人工智能技術應用
①為了提高可搜索性,NDL Lab在“下一代數字圖書館”中使用了OCR技術,從而幫助讀者能進行全文搜索。②為了提升讀者的圖像搜索準確性,NDL Lab通過深度學習方法DeepLab V3+,首先提取讀者提供的圖像領域,再通過相似度和分辨率進行快速匹配,從而實現圖像的自動剪切搜索技術。③“下一代數字圖書館”中的書籍都是進入公共領域的,年代久遠,故存在變色而難以讀取的難題。為了解決這個問題,NDL Lab通過深度學習方法pix2pix對原圖進行矯正而獲得白度圖像,從而提升了圖像的可讀性。④日本國立國會圖書館的數字館藏通常采用縱向布局的數字化資料,但不適合智能手機和平板電腦終端使用。為了適合智能終端上查看圖像,NDL Lab使用語義分割方法在展開位置自動分割,逐頁顯示,并自動刪除多余的背景,因此圖像會顯示出更大的尺寸,從而自動適應智能終端設備。
4.3 通過活動促進數據和服務利用
NDL Lab通過“NDL數字圖書館咖啡廳”和“城市數據挑戰賽”兩種活動,促使更多人使用日本國立國會圖書館的數字資源。
(1)“NDL數字圖書館咖啡廳”。為了加強公共圖書館與科研人員、讀者的聯系,也為了將日本國立國會圖書館的各項數字資源得到充分的利用,NDL Lab于2016年以講座的形式推出“NDL數字圖書館咖啡廳”。該講座每次僅限20個人參與,受到日本高校和科研機構的歡迎。自2016年以來,NDL Lab每年都舉辦“NDL數字圖書館咖啡廳”,舉辦次數從2016年的一年一次增加到一年兩次。“NDL數字圖書館咖啡廳”主要探索數字圖書館相關的研究和最新趨勢,并介紹NDL的最新發展技術等。
(2)城市數據挑戰賽。為了讓日本國立國會圖書館的數據能夠在各個領域得到利用,日本國立國會圖書館于2019年舉辦了城市數據挑戰賽,以期利用開放數據解決區域性問題,并得到了京都市政府的大力支持。城市數據挑戰賽的數據來源廣泛,具體包括日本國立國會圖書館提供的“參考協作數據庫”中注冊的圖書館和檔案館、相關地方政府發布的數據、相關門戶網站提供的圖文博檔單位。日本國立國會圖書館希望參與者能通過這些數據解決實際問題。
4.4 聯合其他機構進行人工智能服務
NDL Lab無論是人工智能研發,還是活動舉辦都有不少強有力的合作伙伴。在人工智能研發方面,NDL Lab分別與Facebook、JADH、國家信息學研究所等合作,分別推出NDC預測器、聯合錄入、圖像提取和關聯搜索等服務。在活動舉辦方面,與京都市政府合作進行城市數據挑戰賽,并與其他機構推出各種開放數據挑戰賽。可見與其他機構進行人工智能服務,不僅可以實現技術上的強強聯合,還能降低活動經費,從而達到雙贏局面。
5 對我國圖書館人工智能服務的啟示
5.1 堅持需求導向,重視人工智能在數字圖書館建設中的作用
在我國圖書館發展中,數字圖書館建設顯得越來越重要,特別是高校圖書館越來越重視數字圖書館建設。越來越多圖書館愿意投入更多的經費購買數字資源。但在圖書館人工智能服務方面,我國圖書館更多是停留在購買智能硬件設備輔助圖書館進行讀者咨詢、圖書盤點等工作,減少圖書館工作人員的工作量。在我國,將人工智能技術應用到數字圖書館建設中的案例并不多。2017年武漢大學與百度合作建設人工智能圖書館,包括了智能檢索和數據追蹤等技術[5]。
數字圖書館建設對于我國圖書館的發展顯得越來越重要。所以我國圖書館應重視人工智能技術在數字圖書館中的應用。全文搜索與圖像搜索是提升讀者搜索體驗的重要途徑。NDL Lab通過多種機器學習方法實現了自動剪切搜索、圖像白度美化處理、智能終端屏幕自適應等功能,提升了讀者的資源可獲取性和搜索體驗。目前我國圖書館的數字資源普遍通過采購的形式而獲得,缺少自主研發,且對全文搜索及多種圖像搜索技術也相對不足。所以我國有條件的圖書館可在技術部門的基礎上成立人工智能實驗室,嘗試將人工智能技術應用到數字圖書館建設中。同時應謹慎處理可能面臨的法律、道德和技術風險,待各方面成熟之后再推向讀者。
5.2 多渠道推廣,促進數據和服務利用
圖書館人工智能建設的目的在于讓更多的讀者了解并使用這些技術,從而發揮其價值。正所謂建設是為了利用,NDL Lab為了促進數據和服務的使用打造了“NDL數字圖書館咖啡廳”和“城市數據挑戰賽”兩個活動品牌。為了促進數據和服務利用,我國圖書館可在以下渠道進行推廣:一是通過官網、微信公眾號、微博、抖音短視頻等渠道向讀者公布最新的數據資源及人工智能服務進展情況;二是定期開展人工智能論壇,邀請相關專家學者,并組織感興趣的讀者參與,形成品牌效應;三是與高校的大數據、人工智能等相關專業合作,聯合舉辦數據使用大賽,讓讀者了解數據,并掌握數據解決問題。
5.3 加強合作,應用最新技術,減少成本
人工智能是未來圖書館發展的主要趨勢,已經得到了廣泛的認可。圖書館人工智能建設,需要大量的經費和技術投入。
在技術投入方面,圖書館可能相對欠缺,需要外部技術支持。如NDL Lab就借助了Facebook、JADH、國家信息學研究所等的技術力量,聯合開發人工智能技術。我國圖書館可嘗試與百度、騰訊和阿里巴巴聯合開發數字圖書館中的人工智能技術,百度和武漢大學圖書館的合作就是個很好的案例。圖書館人工智能有助于數字人文建設,故圖書館也可爭取數字人文工作人員共同研發人工智能技術。除了加強外部合作外,我國圖書館的技術人員應掌握人工智能技術前沿及發展趨勢,讓圖書館人工智能發展與時俱進。
在經費投入方面,圖書館需要投入不少的經費用于設備采購、技術研發和活動推廣。為了減少圖書館在人工智能方面的經費壓力,我國圖書館也可加強外部合作。如在設備采購方面,圖書館可爭取智能終端廠商以提供產品免費展覽為由,降低產品的采購價格,甚至讓廠商贈送該產品;在技術研發方面,圖書館可爭取與外部機構進行聯合開發,知識產權共同所有;在活動推廣方面,圖書館可爭取相關的機構聯合開展。如NDL Lab的“城市數據挑戰賽”獲得了京都市政府的支持。我國圖書館也可邀請相關的政府機構或者智能終端廠商、數字圖書館供應商在活動推廣時進行相應的贊助活動,從而降低圖書館人工智能活動推廣經費壓力。
5.4 加強對進入公有領域文獻的開發利用
日本國立國會圖書館非常重視對進入公有領域文獻的開發利用。NDL Lab開發的“下一代數字圖書館”、NDC預測器、Hoso-Digi等服務都是面向進入公有領域的文獻。進入公有領域的文獻不會產生知識產權問題,同時也是人類文明智慧的產物。我國擁有幾千年的歷史文明,擁有豐富的進入公有領域的文獻。所以我國圖書館非常有必要對進入公有領域的文獻進行開發,并通過人工智能技術加強這些文獻的使用。有些圖書館通過數字人文技術將古籍文獻進行開發利用,如上海圖書館開發了數字人文項目的開放數據平臺,以家譜、手稿檔案、古籍等創建文獻知識庫。在對進入公有領域文獻的開發利用過程中,不僅可使用數字人文技術,也可如NDL Lab那樣使用人工智能技術。
6 結語
圖書館人工智能實驗室具有平臺優勢,可吸引國內外人工智能機構、專家學者共同參與,提升圖書館人工智能服務水平。我國圖書館可根據實際情況,在創客空間和數字人文中心等基礎上摸索出適合圖書館自身的人工智能服務發展路徑。
猜你喜歡
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小太陽畫報(2018年1期)2018-05-14 17:19:25
商周刊(2017年9期)2017-08-22 02:57:56
小康(2017年16期)2017-06-07 09:00:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
南風窗(2016年19期)2016-09-21 16:51:29
