基于MSER的自適應(yīng)學(xué)習(xí)自然場(chǎng)景文本檢測(cè)
2020-09-02 06:52:22李英杰全太鋒劉武啟
小型微型計(jì)算機(jī)系統(tǒng) 2020年9期
李英杰,全太鋒,劉武啟
(重慶郵電大學(xué) 通信與信息工程學(xué)院,重慶 400065)
E-mail:1678350588@qq.com
1 引 言
文本檢測(cè)已經(jīng)廣泛應(yīng)用于車(chē)牌檢測(cè)、實(shí)時(shí)翻譯、導(dǎo)盲導(dǎo)航系統(tǒng)、無(wú)人汽車(chē)輔助駕駛等相關(guān)領(lǐng)域[1].與文檔中的文本識(shí)別不同,自然場(chǎng)景文本檢測(cè)的難點(diǎn)[2]是圖像中的非文本元素廣泛分布,如圖像中的花草、樹(shù)木、建筑等也可能具有與文本相似的結(jié)構(gòu),在進(jìn)行檢測(cè)時(shí)很可能將其檢測(cè)出來(lái),這就對(duì)文本檢測(cè)和識(shí)別的準(zhǔn)確率以及效率產(chǎn)生了很大的影響.自然場(chǎng)景文本檢測(cè)方法主要包括:基于連通域的方法、基于紋理的方法、基于學(xué)習(xí)的方法[3].基于連接域的方法使用自下而上的策略逐步將小區(qū)域合并為更大的區(qū)域,直到識(shí)別出所有區(qū)域.文獻(xiàn)[4]提出一種基于規(guī)則的文本檢測(cè)方法,該方法通過(guò)MSER算法提取候選區(qū)域,然后使用基于規(guī)則的過(guò)濾技術(shù)消除非文本區(qū)域.文獻(xiàn)[5]提出一種基于筆畫(huà)寬度變換(SWT)和MSER的檢測(cè)方法,利用SWT和MSER同時(shí)提取候選字符,而后通過(guò)啟發(fā)式規(guī)則對(duì)候選字符進(jìn)行過(guò)濾.但是,基于連通域的方法必須計(jì)算圖像中所有像素的相似特征.根據(jù)圖像中文本和背景之間的結(jié)構(gòu)特征差異,基于紋理的方法首先對(duì)圖像做頻域轉(zhuǎn)換初步確定圖像中的文本區(qū)域,然后提取特征,最后利用分類器確認(rèn)文本.文獻(xiàn)[6]使用K-Means算法進(jìn)行聚類和特征選擇,然后使用ELM分類器獲取文本.文獻(xiàn)[7]提取MSER候選區(qū)域,并使用水平和垂直方差,筆畫(huà)寬度和幾何特征構(gòu)建AdaBoost分類器.然而,基于紋理的方法使用固定權(quán)重線性地混合提取的特征,融合策略太過(guò)單一.基于深度學(xué)習(xí)[8-11]的方法受到人們?cè)絹?lái)越多的青睞,文獻(xiàn)[12]根據(jù)RCNN具有從訓(xùn)練數(shù)據(jù)共享權(quán)重的優(yōu)點(diǎn),應(yīng)用RCNN卷積神經(jīng)網(wǎng)絡(luò)模型進(jìn)行文本識(shí)別,文獻(xiàn)[13]提供了一種完全卷積網(wǎng)絡(luò)(FCN)預(yù)測(cè)圖像中的文本行以文本行的形式檢測(cè)文本,基于深度學(xué)習(xí)的方法具有很好的檢測(cè)效果,缺陷是需要大量數(shù)據(jù)訓(xùn)練模型,時(shí)間復(fù)雜度很高,在新的場(chǎng)景圖像中檢測(cè)文本耗時(shí)很長(zhǎng),很難滿足實(shí)時(shí)性.
針對(duì)上述問(wèn)題,本文提出了一種改進(jìn)的MSER算法和一種基于SVM的多特征自適應(yīng)權(quán)重融合方法來(lái)檢測(cè)自然場(chǎng)景中的文本.首先利用改進(jìn)的MSER算法提取候選區(qū)域,然后將HOG、統(tǒng)一化LBP、CPD三種特征以不同權(quán)值相結(jié)合,最后融合特征用于訓(xùn)練SVM分類器以實(shí)現(xiàn)非文本精細(xì)過(guò)濾.
2 自然場(chǎng)景文本檢測(cè)
本文提出的檢測(cè)算法總體流程如圖1所示.首先對(duì)圖像進(jìn)行預(yù)處理,運(yùn)用改進(jìn)的MSER算法提取候選區(qū)域.根據(jù)HOG、CPD和紋理特征各自的優(yōu)勢(shì),合并得到HOG+統(tǒng)一化 LBP+CPD三通道特征訓(xùn)練分類器.加入CPD特征可以依據(jù)文本和背景的色彩差別,利用顏色特征的空域特性彌補(bǔ)濾除非文本區(qū)域時(shí)特征的不足.在三個(gè)特征融合的過(guò)程中,采用多特征自適應(yīng)權(quán)重融合策略,根據(jù)權(quán)重計(jì)算公式對(duì)不同特征進(jìn)行加權(quán),以提高較優(yōu)特征在融合過(guò)程中的權(quán)重,同時(shí)降低較差特征對(duì)融合決策的影響.

圖1 總體算法框圖Fig.1 Overall algorithm block diagram
3 MSER算法介紹
MSER[14-16]算法基于分水嶺的概念將彩色圖像轉(zhuǎn)換為灰度圖像,然后將圖像二值化,二值化閾值取[0,255]中的某個(gè)值,在閾值由0向255連續(xù)增加的過(guò)程中遍歷檢查圖像中所有像素灰度值,忽略灰度值小于閾值的像素點(diǎn),留下灰度值比閾值大的像素點(diǎn),這樣當(dāng)閾值不斷變換時(shí),相鄰像素點(diǎn)構(gòu)成的區(qū)域不斷地出現(xiàn)、生長(zhǎng)和合并形成極大值區(qū)域,當(dāng)2個(gè)不同閾值間的區(qū)域面積變化基本不變時(shí),則得到的區(qū)域即為最大穩(wěn)定極大值區(qū)域(MSER+).灰度圖像的字符有兩種,常見(jiàn)的一種是較亮字符處于較暗的背景,此時(shí)提取的區(qū)域?yàn)樽畲蠓€(wěn)定極大值區(qū)域(MSER+),為檢測(cè)出較亮背景下較暗的字符需要對(duì)灰度圖像做反操作,重復(fù)二值化過(guò)程,就可以獲取最大穩(wěn)定極小值區(qū)域(MSER-),MSER+和MSER-求和得到最大穩(wěn)定極值區(qū)域.
MSER算法的數(shù)學(xué)定義[17]:
定義1.圖像I為區(qū)域D到灰度S的映射:即D∈Z2→S,其中S是完全可排序的,對(duì)于灰度圖像,S取值為{0,1,…,255}.
定義2.像素間的鄰域關(guān)系:A?D×D.本文使用四鄰域,當(dāng)p,q∈D并且滿足式(1),則兩點(diǎn)相鄰.
(1)
定義3.圖像中區(qū)域Q?D被定義為滿足連接關(guān)系的圖像的連續(xù)子集,任何點(diǎn)p,q∈Q都有連接的路徑:
p,a1,a2,…,an,q
使得式(2)成立
pAa1,a1Aa2,…,anAq
(2)
其中ai∈Q,i=1,2…,n.
定義4.區(qū)域Q的邊界為
?Q={q|q∈D-Q,?p∈Q,qAp}
(3)
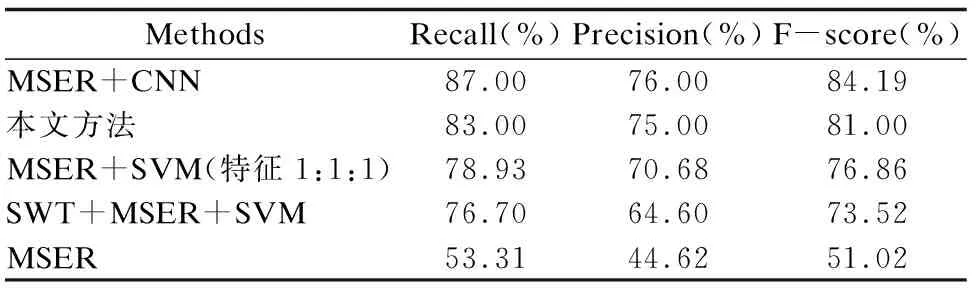
定義5.對(duì)于所有的p∈Q,q∈?Q如果滿足I(p)>I(q),則區(qū)域Q為極大值區(qū)域;如果滿足I(p) 定義6.如果Q1,…Qi-1,Qi…是一系列嵌套區(qū)域,如果在i處q(i)獲得最小變化率,則稱Qi為最大穩(wěn)定極值區(qū)域. (4) 圖2 MSER算法提取Fig.2 MSER algorithm extraction 圖3 改進(jìn)的MSER算法Fig.3 Improved MSER algorithm 采用傳統(tǒng)MSER算法提取文本時(shí),因?yàn)橐暯呛完幱埃瓐D2(a)中的“s”和“t”之間的邊緣產(chǎn)生模糊,導(dǎo)致圖2(b)中檢測(cè)到的字符區(qū)域“s”和“t”粘在一起,被當(dāng)做一個(gè)區(qū)域檢測(cè)出來(lái).特別的對(duì)于“a”、“e”等這種有孔洞的文本,其中的孔洞也會(huì)被檢測(cè)出來(lái),這些情況通常出現(xiàn)在字符內(nèi)部表現(xiàn)為嵌套區(qū)域. 如上所述,針對(duì)MSER算法存在的問(wèn)題提出改進(jìn)的MSER算法.步驟如圖3所示. 步驟1.在預(yù)處理階段加入中值濾波器對(duì)輸入圖像去噪. 步驟2.利用式(5)以不同權(quán)值對(duì)去噪后彩色圖像的R、G、B分量加權(quán)平均,將輸入圖像轉(zhuǎn)換為灰度圖像Gray. Gray=0.114B+0.587G+0.299R (5) 步驟3.在灰度圖像Gray上利用水平方向邊緣差分算子Sx和垂直方向邊緣差分算子Sy計(jì)算梯度幅度圖G. (6) (7) M為圖像中一個(gè)3×3的窗口,Gx和Gy分別表示像素點(diǎn)水平方向和垂直方向的梯度值. 步驟4.根據(jù)式(8),式(9)對(duì)灰度圖Gray進(jìn)行增強(qiáng)操作得到Gray1和Gray2,并將梯度增強(qiáng)圖Gyay1和Gray2的像素值歸一化到[1,255]區(qū)間. Gray1=Gray-α×G (8) Gray2=Gray+α×G (9) 其中0<α<1. 步驟5.在幅度增強(qiáng)圖Gray1和Gray2上利用MSER算法檢測(cè)得到MSER+、MSER-,對(duì)MSER+和MSER-區(qū)域求和得到文本候選區(qū)域. 圖4 邊緣增強(qiáng)的MSER算法提取效果Fig.4 Edge enhanced MSER algorithm extraction effect 如圖4利用邊緣增強(qiáng)的MSER算法檢測(cè)文本,圖2(b)中粘連的“s”和“t”明顯分開(kāi). 利用候選區(qū)域幾何信息設(shè)計(jì)多機(jī)制抑制策略主要處理邊緣增強(qiáng)MSER算法提取的區(qū)域,濾除其中的嵌套區(qū)域并達(dá)到對(duì)非文本區(qū)域粗過(guò)濾. 4.2.1 非文本區(qū)域粗濾除 針對(duì)非文本,本文設(shè)計(jì)了寬高比、邊緣密度、像素面積比三種特征對(duì)其進(jìn)行初步濾除. 1)寬高比 大多數(shù)字符寬高比相對(duì)固定,使用邊界框數(shù)據(jù)對(duì)提取區(qū)域的最小外接矩形做如下約束,將寬高比不在0.4和10范圍內(nèi)的區(qū)域進(jìn)行濾除. (10) 其中width和height分別代表提取區(qū)域最小外接矩形的寬、高. 2)邊緣密度 文本區(qū)域相比非文本區(qū)域,邊緣密度更加密集.利用式(11)計(jì)算極值區(qū)域的邊緣密度,將邊緣密度值小于0.2的區(qū)域進(jìn)行濾除. (11) 其中f(i,j)=1表示邊緣圖像,式中的分子表示該區(qū)域邊緣的像素個(gè)數(shù). 3)像素面積比 文本區(qū)域像素面積通常限制在一定的范圍內(nèi).提取到MSER極值區(qū)域后,計(jì)算MSER區(qū)域和外接矩形的像素比S,濾除比值小于0.3的極值區(qū)域. (12) 其中area表示圖像中MSER連通區(qū)域的像素總數(shù),convexarea表示外接多邊形中的像素總數(shù). 4.2.2 嵌套區(qū)域?yàn)V除 為刪除嵌套區(qū)域,提高后續(xù)識(shí)別準(zhǔn)確率,設(shè)計(jì)了以下濾除策略,算法詳細(xì)步驟為: 步驟1.計(jì)算所有候選極值區(qū)域外接矩形的坐標(biāo),將候選區(qū)域用式(13)四元組進(jìn)行表示. boxi(axi,ayi,bxi,byi) (13) bxi=axi+widthi (14) byi=ayi+heighti (15) 其中axi、ayi表示第i個(gè)外接矩形的左下角坐標(biāo),widthi、heighti表示第i個(gè)外接矩形的寬和高,bxi、byi表示第i個(gè)外接矩形右上角坐標(biāo). 步驟2.判斷候選區(qū)域是否有嵌套,如果兩個(gè)區(qū)域滿足包含與被包含的關(guān)系,則根據(jù)式(16)濾除候選區(qū)域中兩者面積較小的區(qū)域. 圖5 多機(jī)制抑制策略過(guò)濾Fig.5 Multi-mechanism-suppression policy filtering (16) 如圖5所示經(jīng)過(guò)多機(jī)制濾除策略,圖2(b)中的嵌套區(qū)全部被濾除掉. 改進(jìn)的MSER算法能夠檢測(cè)出大部分字符區(qū)域,但是也檢測(cè)出很多非文本區(qū)域.如圖6所示,為了完全濾除非文本區(qū)域,使用SVM分類器對(duì)候選區(qū)域再次進(jìn)行二分類,在特征提取階段,本文在HOG特征的基礎(chǔ)上合并了統(tǒng)一化 LBP特征和CPD特征,改善了單一特征的局限性.在特征融合的過(guò)程中,采用自適應(yīng)權(quán)值對(duì)不同特征進(jìn)行加權(quán)融合,以融合特征訓(xùn)練SVM分類器. 圖6 自適應(yīng)算法流程圖Fig.6 Adaptive algorithm flow chart 方向梯度直方圖(HOG)特征是目前計(jì)算機(jī)視覺(jué)、模式識(shí)別領(lǐng)域很常用的一種局部區(qū)域特征描述子,對(duì)光照比較敏感,但是對(duì)目標(biāo)形變的魯棒性較低.本文將圖片歸一化為64*64大小的圖片,每8*8像素組成一個(gè)元胞(cell),每2*2個(gè)元胞組成一個(gè)塊(block),每個(gè)元胞的梯度方向在0到360度分成9個(gè)方向塊,元胞像素在9個(gè)方向塊的梯度直方圖有一個(gè)9維的特征,每個(gè)塊內(nèi)有2*2*9=36維特征,以8個(gè)像素為步長(zhǎng),水平方向?qū)⒂?個(gè)掃描窗口,垂直方向有7個(gè)掃描窗口,檢測(cè)窗口分別在水平和垂直方向上統(tǒng)計(jì)特征,最后組合所有塊的特征得到圖片總共的特征,64*64圖片的HOG特征為36*7*7=1764維特征. 水平方向掃描窗口: (17) 垂直方向掃描窗口: (18) 局部二進(jìn)制模式(LBP)特征具有很強(qiáng)的分類能力、較高的計(jì)算效率和灰度不變性.因?yàn)長(zhǎng)BP直方圖大多是針對(duì)圖像中的各個(gè)區(qū)域分開(kāi)計(jì)算的,對(duì)于一個(gè)普通大小的分塊區(qū)域,傳統(tǒng)LBP算子得到二進(jìn)制模式數(shù)目較多,而實(shí)際的位于該分塊區(qū)域中的像素?cái)?shù)目卻相對(duì)很少,導(dǎo)致產(chǎn)生一個(gè)過(guò)于稀疏的直方圖,為減少冗余的LBP模式,同時(shí)保留足夠的具有重要描繪能力的模式,提高算法整體效率,本文將LBP算子定義在一個(gè)半徑為R的圓形區(qū)域內(nèi),對(duì)每一塊采用統(tǒng)一化LBP算子(Uniform LBP)提取紋理特征,當(dāng)某個(gè)LBP所對(duì)應(yīng)的循環(huán)二進(jìn)制數(shù)從0到1或從1到0最多有兩次跳變時(shí),該類型保存,跳變次數(shù)大于2次時(shí),均歸為一類,最后將每塊的特征做串接組合,構(gòu)建出整幅圖的特征. 自然場(chǎng)景文本檢測(cè)任務(wù)中,文本顏色和周邊區(qū)域存在一定的區(qū)別.本文將RGB色彩空間的圖像轉(zhuǎn)換到HSI色彩空間,因?yàn)镮分量與圖像的彩色信息無(wú)關(guān),所以在H和S分量上提取文本和非文本的色彩感知差異特征,最后對(duì)兩個(gè)分量的色彩感知差異特征進(jìn)行求和,得到最終的色彩感知差異特征[17]. (19) (20) 式(19)中h(k)為顏色直方圖特征表達(dá)式,k為一個(gè)區(qū)間內(nèi)相應(yīng)顏色值,m為圖像顏色范圍,nk為區(qū)間k中的像素總數(shù),n為像素總數(shù).式(20)中h(r)和h(r*)分別表示一個(gè)MSER區(qū)域矩形框中不相同的r和r*區(qū)域顏色直方圖,N為顏色直方圖中的小區(qū)間數(shù). 分別提取文本和非文本的HOG、統(tǒng)一化LBP、CPD三種特征,使用三種特征分開(kāi)訓(xùn)練SVM分類器,然后通過(guò)SVM預(yù)測(cè)的類別標(biāo)簽計(jì)算出每個(gè)特征對(duì)應(yīng)文本和非文本的分類準(zhǔn)確率,利用式(21)構(gòu)建特征權(quán)值. (21) f={HOG,LBP,CPD} (22) 其中x,y,z分別為HOG、統(tǒng)一化LBP、CPD特征向量值. ICDAR2003數(shù)據(jù)集包括1個(gè)測(cè)試集,1個(gè)訓(xùn)練集,對(duì)每個(gè)字符在像素級(jí)別上進(jìn)行了標(biāo)注,本文選取ICDAR2003訓(xùn)練集中的258張圖片作為訓(xùn)練樣本. 按照訓(xùn)練集中字符區(qū)域的位置標(biāo)注信息提取出每個(gè)字符作為正樣本.由于SVM分類器主要對(duì)邊緣增強(qiáng)MSER得到的候選區(qū)域進(jìn)行分類,所以選取候選區(qū)域中的非文本區(qū)域作為負(fù)樣本. 通過(guò)對(duì)訓(xùn)練樣本的篩選,一共選擇6220張圖片作為正樣本并標(biāo)記為“1”,5330張圖片作為負(fù)樣本標(biāo)記為“0”,然后提取樣本融合特征并采用粒子群優(yōu)化算法選擇SVM最佳參數(shù)訓(xùn)練SVM分類器. 為驗(yàn)證整個(gè)算法的有效性和實(shí)用性,本文選擇ICDAR2003圖像數(shù)據(jù)集中的測(cè)試集對(duì)所提算法進(jìn)行性能測(cè)試.表1為數(shù)據(jù)集的詳細(xì)信息.ICDAR2003數(shù)據(jù)集被分為兩個(gè)子集,其中一個(gè)用來(lái)訓(xùn)練或調(diào)整算法,另一個(gè)子集用來(lái)測(cè)試.其中的圖片通過(guò)不同性能的照相機(jī)拍攝,圖像內(nèi)容包含廣告牌、路標(biāo)、門(mén)牌等種場(chǎng)景. 表1 圖像數(shù)據(jù)集Table 1 Image data set 本文采用準(zhǔn)確率(Precision)、召回率(Recall)、綜合性能(F-score)三個(gè)指標(biāo)對(duì)算法進(jìn)行評(píng)估.分別定義如下: (23) (24) (25) 式中|D|表示算法檢測(cè)到的文本區(qū)域和非文本區(qū)域總數(shù),c為正確檢測(cè)到的文本區(qū)域個(gè)數(shù),|G|表示數(shù)據(jù)集中文本區(qū)域的總數(shù),α表示權(quán)重,本文設(shè)定α2=0.3.準(zhǔn)確率和召回率分別從誤檢和漏檢兩個(gè)角度評(píng)價(jià)算法,假如較多的區(qū)域沒(méi)有被檢測(cè)到,則算法的召回率會(huì)相應(yīng)降低;假如較多區(qū)域被錯(cuò)誤檢測(cè)到,則算法的準(zhǔn)確率會(huì)降低. 利用SVM分類器需要確定核函數(shù)和參數(shù),參數(shù)主要包含懲罰系數(shù)C和核函數(shù)參數(shù)g兩個(gè)參數(shù).由于文本和非文本的區(qū)分不是簡(jiǎn)單的線性關(guān)系,本文SVM分類器選擇徑向基核函數(shù)RBF(Radial Basis Function,RBF)將低維特征空間映射到高維特征空間.基于群體中個(gè)體之間協(xié)作和信息共享的思想,采用粒子群算法尋找最優(yōu)的C和g.粒子群算法效率塊,并沒(méi)有許多參數(shù)的調(diào)節(jié),目前已被普遍應(yīng)用于函數(shù)優(yōu)化、模糊系統(tǒng)控制以及其它遺傳算法等領(lǐng)域.本文將粒子群算法的局部學(xué)習(xí)因子和全局學(xué)習(xí)因子設(shè)為1.49445,種群規(guī)模設(shè)為20,進(jìn)化次數(shù)設(shè)為300,通過(guò)粒子群算法尋找最優(yōu)參數(shù)c為12,g為0.29.SVM參數(shù)尋優(yōu)結(jié)果如圖7所示,在進(jìn)化到100代時(shí)適應(yīng)度達(dá)到最高為97.2%,此時(shí)參數(shù)最佳,在后續(xù)進(jìn)化時(shí),適應(yīng)度一直不變趨于平穩(wěn). 圖7 參數(shù)尋優(yōu)結(jié)果圖Fig.7 Parameter optimization results 為了證明改進(jìn)算法的魯棒性,實(shí)驗(yàn)選用最新和常用的四種算法和本文算法對(duì)比,主要比較改進(jìn)算法在圖像模糊導(dǎo)致字符粘連時(shí)提取文本的適應(yīng)性、消除嵌套區(qū)域的有效性以及濾除非文本的徹底性.五種場(chǎng)景檢測(cè)實(shí)驗(yàn)結(jié)果如圖8所示. 圖8 改進(jìn)算法與其它算法對(duì)比Fig.8 Improved algorithm compared with other algorithms 在室外墻面廣告場(chǎng)景文本檢測(cè)中,SWT+MSER+SVM和傳統(tǒng)的MSER算法無(wú)法解決由于模糊導(dǎo)致字符粘連的問(wèn)題,邊緣粘連的“s”和“t”被當(dāng)做一個(gè)字符檢測(cè)出來(lái),降低了算法的準(zhǔn)確率和召回率.在室外墻面廣告和室內(nèi)標(biāo)識(shí)牌場(chǎng)景文本檢測(cè)中,傳統(tǒng)的MSER算法還會(huì)檢測(cè)到“a”、“e”、“O”、“D”、“R”這種有孔洞的嵌套區(qū)域,而本文算法不僅準(zhǔn)確檢測(cè)到文本序列,還通過(guò)多機(jī)制抑制策略消除了無(wú)關(guān)的嵌套區(qū)域,并對(duì)字符粘連現(xiàn)象進(jìn)行了有效抑制.在車(chē)牌檢測(cè)中,傳統(tǒng)的MSER算法不能檢測(cè)到車(chē)牌中的第一個(gè)漢字,本文改進(jìn)的算法可以完整地檢測(cè)到車(chē)牌號(hào)區(qū)域.除了室外墻面廣告場(chǎng)景,在其它四種場(chǎng)景中,由于圖片背景更加復(fù)雜,存在大量類似文本的干擾區(qū)域,MSER+SVM算法、SWT+MSER+SVM算法、傳統(tǒng)MSER算法檢測(cè)結(jié)果中都出現(xiàn)了較多非文本區(qū)域,而本文算法在非文本濾除階段采用SVM多特征自適應(yīng)權(quán)值融合的分類方法,按最優(yōu)的權(quán)值組合特征訓(xùn)練SVM分類器,提高了分類的準(zhǔn)確率,有效濾除掉非文本. 表2 不同算法在ICDAR2003性能參數(shù)對(duì)比Table 2 Comparison of performance parameters ofdifferent algorithms in ICDAR2003 為了驗(yàn)證本文算法的性能,本文選擇ICADAR2003數(shù)據(jù)集中的所有場(chǎng)景測(cè)試集進(jìn)行實(shí)驗(yàn).表2為改進(jìn)算法與其它算法性能參數(shù)對(duì)比,通過(guò)表2可以看到MSER+CNN的方法召回率、準(zhǔn)確率、綜合性能是最好的,該算法采用MSER方法提取候選區(qū)域,將候選區(qū)域送入卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行分類,雖然檢測(cè)性能最好,但是基于CNN的方法算法復(fù)雜度很高,卷積神經(jīng)網(wǎng)絡(luò)中每一層卷積層和池化層中的每個(gè)神經(jīng)元有很多參數(shù),每個(gè)卷積層會(huì)提取到圖像的很多特征,處理圖片時(shí)間長(zhǎng),降低了系統(tǒng)檢測(cè)的實(shí)時(shí)性.MSER+SVM(特征1:1:1)的方法在特征融合時(shí)按相等的權(quán)值進(jìn)行融合,沒(méi)有考慮某些特征對(duì)文本表現(xiàn)能力差的問(wèn)題,導(dǎo)致過(guò)濾非文本不徹底,準(zhǔn)確率和本文算法相差4.32%.SWT+MSER+SVM提取文本區(qū)域沒(méi)有考慮圖像低對(duì)比度造成圖像模糊的情況,導(dǎo)致召回率和準(zhǔn)確率較低.傳統(tǒng)的MSER算法在提取到候選區(qū)域時(shí),沒(méi)有解決MSER算法檢測(cè)存在嵌套區(qū)域的問(wèn)題,而且沒(méi)有再進(jìn)一步對(duì)候選區(qū)域進(jìn)行文本分類,準(zhǔn)確率明顯低于本文算法.通過(guò)比較本文算法檢測(cè)性能明顯優(yōu)于其它三類算法,召回率、準(zhǔn)確率和綜合性能僅低于MSER+CNN的方法,但是本文算法沒(méi)有復(fù)雜的卷積操作,檢測(cè)時(shí)間更少. 表3 各算法處理速度對(duì)比Table 3 Comparison of processing speed of each algorithm 為了證明本文算法既具有良好的檢測(cè)性能,又能滿足實(shí)時(shí)性的要求,分別使用40張不同分辨率的圖片進(jìn)行實(shí)驗(yàn),計(jì)算檢測(cè)出圖片中的文本區(qū)域所需要的平均時(shí)間.如表3所示隨著圖片分辨率的增大,MSER+CNN算法需要處理的信息越來(lái)越多,檢測(cè)耗時(shí)遠(yuǎn)遠(yuǎn)高于其它算法.由于本文算法在候選區(qū)域提取階段引入了多機(jī)制抑制策略,相比于MSER+SVM(特征1:1:1)檢測(cè)時(shí)間較長(zhǎng).SWT+MSER+SVM方法通過(guò)SWT和MSER組合來(lái)提取候選區(qū)域,而SWT方法需要計(jì)算所有像素點(diǎn)對(duì)應(yīng)的筆畫(huà)寬度,增加了文本檢測(cè)所需時(shí)間.在最高圖片分辨率下檢測(cè)文本,本文算法檢測(cè)時(shí)間為5.72s,仍能滿足實(shí)時(shí)性要求. 圖9 ICDAR2003數(shù)據(jù)集部分檢測(cè)效果圖Fig.9 ICDAR2003 data set partial detection effect diagram 本文算法為克服其它算法存在的問(wèn)題,分別在候選區(qū)域提取階段和非文本濾除階段對(duì)傳統(tǒng)算法做出改進(jìn),梯度增強(qiáng)圖改進(jìn)了傳統(tǒng)的MSER算法,改善了MSER算法不能在低對(duì)比度、字符粘連圖像上提取文本候選區(qū)域的問(wèn)題,提高了算法的召回率.基于SVM多特征自適應(yīng)權(quán)值融合的分類方法提高了分類的準(zhǔn)確率,進(jìn)而提升了算法的綜合性能.改進(jìn)的算法性能僅低于MSER+CNN的方法,其中召回率相差4個(gè)百分點(diǎn),準(zhǔn)確率相差1個(gè)百分點(diǎn),但是檢測(cè)速度明顯更快.本文算法檢測(cè)速度較低于其它三類算法,但是準(zhǔn)確率更高.綜合考慮上述主觀分析和客觀實(shí)驗(yàn)結(jié)果,本文改進(jìn)的算法可以同時(shí)兼顧檢測(cè)率和實(shí)時(shí)性.圖9展示了本文算法在ICDAR2003測(cè)試集中代表性場(chǎng)景檢測(cè)效果圖. 針對(duì)MSER算法對(duì)邊緣模糊文本比較敏感,提取的候選區(qū)域中存在字符粘連等問(wèn)題,提出改進(jìn)的MSER算法.為了更徹底高效地濾除非文本區(qū)域,考慮到單一特征對(duì)文本描述能力較弱、不同特征對(duì)文本描述能力不同的情況,本文在訓(xùn)練集上提取HOG特征的基礎(chǔ)上加入統(tǒng)一化LBP和CPD特征,然后采用自適應(yīng)權(quán)值融合策略將三種特征融合并結(jié)合粒子群算法尋找SVM訓(xùn)練的最優(yōu)參數(shù),得到一個(gè)最優(yōu)分類器,最后將提取的候選區(qū)域送入訓(xùn)練好的最優(yōu)分類器,更精確地剔除非文本區(qū)域.實(shí)驗(yàn)結(jié)果表明,本文算法可以解決字符粘連、圖像模糊難以檢測(cè)文本以及濾除非文本不徹底等問(wèn)題,提高了檢測(cè)精度,并且滿足實(shí)時(shí)性要求.

4 改進(jìn)的MSER算法
4.1 邊緣增強(qiáng)處理

4.2 多機(jī)制抑制策略

5 基于SVM的多特征自適應(yīng)權(quán)值融合

5.1 特征提取

5.2 確定最優(yōu)權(quán)值組合

5.3 訓(xùn)練SVM
6 實(shí)驗(yàn)結(jié)果及分析
6.1 數(shù)據(jù)集

6.2 算法評(píng)估標(biāo)準(zhǔn)
6.3 SVM參數(shù)優(yōu)化

6.4 實(shí)驗(yàn)結(jié)果比較與分析



7 結(jié)束語(yǔ)
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
