改進的土石壩GACO-BP滲流監控模型研究
2020-08-17 03:11:14張海龍
陜西水利 2020年5期
張海龍
(新疆維吾爾自治區烏魯瓦提水利樞紐管理局,新疆 和田 848000)
0 引言
土石壩的滲流狀態是影響其整體安全和運行的重要因素之一,對土石壩的滲流狀態進行監控并利用監測資料建立合適的模型對其進行預測分析具有重大意義[1~2]。目前,統計模型、確定性模型和混合模型在這一領域應用較多[3]。然而,這幾種傳統模型的精準度并不穩定,也經常出現回歸錯誤,且當大壩遇到環境變化惡劣的情況時,傳統模型的預測效果更為不佳。人工神經網絡適應性強,可以用來預測非線性數據,因此被運用到監控模型中。然而BP神經網絡訓練過程冗長,局部極值困擾大,因此諸多學者對其進行改進[4~6],并提出相應的改進算法。本文引入遺傳算法改進傳統蟻群算法(ACO),在此基礎上建立GACO-BP的土石壩滲流壓力預測模型。以某土石壩實測資料為例,對傳統神經網絡模型和改進模型的預測能力進行定量對比和分析。
1GACO-BP神經網絡算法
1.1 遺傳蟻群算法
蟻群算法(ACO)是由 Macro Dorigot等人[7~8]提出,起初用于解決TSP問題。TSP問題表示為:螞蟻從A地前往B地,一定要經過且只能經過一次A、B間給定的n個地點,最后從B回到A,找出一條最短閉合線路。用dij表示兩地之間的距離;τij(t)表示t時刻兩地之間信息素的濃度。
然而,蟻群算法在求解最優路徑時花費的時間長,速度慢。而遺傳算法[9]在求解大規模的最優路徑時速度快,范圍廣,較有優勢。遺傳算法可彌補蟻群算法的這一缺點,故將其引入,優化蟻群算法。
遺傳蟻群混合算法的基本思想是在算法的前期采用遺傳算法,利用遺傳算法快速隨機、全局收斂性來形成蟻群算法中的初始信息素分布情況,然后進行蟻群算法操作。這樣就克服了蟻群算法由于初期信息素匱乏而導致的收斂速度慢的缺點。
實現遺傳蟻群混合算法的主要步驟如下:
步驟1:確定遺傳算法中的編碼方式、適應度函數、種群大小,以及選擇、交叉、變異的方法與概率;確定蟻群算法中的螞蟻數量、算法迭代次數、信息素啟發式因子a的大小、期望值啟發式因子的大小、信息素殘留系數ρ的大小等;
步驟2:用遺傳算法迭代出N個較優解;
步驟3:將遺傳算法中得到的種群信息轉化為蟻群算法中所需的信息素矩陣;
步驟4:用蟻群算法繼續求解,得到新的可行解。
遺傳蟻群算法具體實現流程圖見圖1。
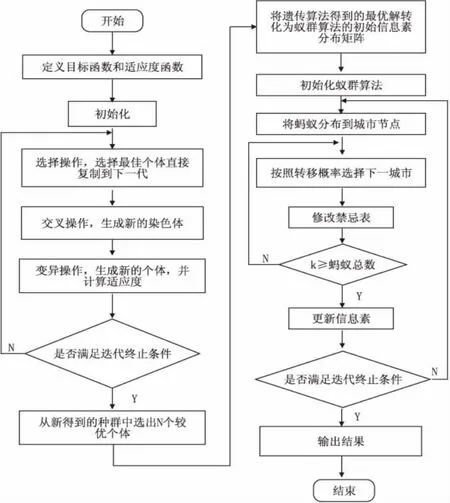
圖1 遺傳蟻群算法流程圖
1.2 改進的遺傳蟻群算法
遺傳算法與蟻群算法的混合主要包括兩個關鍵策略:一是如何確定遺傳算法停止執行進入蟻群算法的最佳時刻;二是如何將遺傳算法迭代得到的信息轉換為蟻群算法中得初始信息素的濃度矩陣。本文針對這兩點各提出一種解決方法,實現對傳統蟻群算法的改進。
1.2.1 最佳時刻的確定
通過試驗研究發現,兩種算法的關系見圖2。

圖2 遺傳算法與蟻群算法速度-時間曲線
由圖可知,GA算法在起步階段(t0~ta階段)的收斂速度明顯高于蟻群算法,但是隨著時間的推移,速度減慢,效率降低。而蟻群算法卻恰恰相反,起步時候收斂速度非常緩慢,隨著時間推移,速度迅速提高。在ta時刻之前和之后GA算法和蟻群算法分別表現出了很好的收斂效果,因此a點可以看作是兩種算法融合的最佳點。
對于最佳時刻a的確定,傳統的遺傳蟻群混合算法主要是給遺傳算法部分設置一個固定的迭代次數(例如20次),等待遺傳算法迭代完成規定次數以后才會進入蟻群算法,這種融合方法在應用實驗中取得了良好的效果,但是,這種融合方式存在盲目性,未充分考慮兩種算法的搜索特性。如果迭代次數設置不當,會造成過早(如時刻)或過晚(如時刻)地結束遺傳算法,導致兩種算法融合失敗。
考慮到GA算法在運行到一定時間后(b點以后),適應度變化緩慢,收斂速度快速降低,本文提出對遺傳算法的收斂速度曲線進行分析,通過尋找曲線的拐點而動態確定算法融合的最佳時機,以實現遺傳算法和蟻群算法的動態融合,體現了融合的靈活性。
在混合算法中,由遺傳算法轉換到蟻群算法的條件,即拐點的確定,可以簡為以下幾點:
(1)建立遺傳算法收斂速度的評價函數;
(2)設F(n)為第n代種群最優適應度函數,令:

式中:Q為常量。
(3)當連續k次出現v(n+1)-v(n)小于設定的閾值的情況,說明遺傳算法的收斂效率已經變得低下,此時可以轉入蟻群算法。
1.2.2 信息轉換
在遺傳蟻群混合算法中,蟻群算法的信息素初始分布矩陣是由遺傳算法迭代得到的優化種群經過轉換所得的。因此,將遺傳算法產生的最優解轉化為蟻群算法的初始信息素,也是算法融合的一個關鍵之處。
由于蟻群算法采用最大最小蟻群系統(MMAS,Max-Min Ant System),將蟻群算法的初始信息素矩陣設置為 τS=τC+τG,其中τC為常數,其取值根據具體問題給定,相當于MMAS系統中的 τmin,τG為信息素分布。
本文提出一種由GA算法得到信息素濃度分布矩陣的方法,具體計算步驟如下:
(1)由遺傳算法迭代求解問題;
(2)將遺傳算法終止時的種群按照適應度值由大到小排序,選擇前n/2個適應度最高的染色體(其中n為城市的數目)組成矩陣T1。矩陣中每一行是一個染色體,每一個染色體代表一個問題解的路徑,而矩陣中的每個元素又都代表了一個城市。同時,為了避免蟻群算法陷入局部最優或停滯,將再隨機生成n/2個染色體組成矩陣T2,最后將T1和T2組合為新的n×n階的矩陣T。
(3)計算矩陣T中兩個城市連接路徑e(i,j)出現的次數kij,將kij/2n作為蟻群算法中初始信息素矩陣中 τ(i,j)和 τ(j,i)的值。若兩城市沒有建立連接路徑關系則對應的信息素矩陣中的值設為0。
1.3 GACO-BP神經網絡
BP神經網絡的基本原理和訓練方法及過程已有諸多學者敘述過[10],這里不再具體闡述。
本文擬用遺傳蟻群算法優化BP神經網絡權值和閾值的更新,并通過建立的GACO-BP神經網絡模型對土石壩的滲流壓力進行預測。
2 基于GACO-BP的大壩滲流監控模型
2.1 模型的建立
根據吳中如院士提出的理論,本文建立如下的滲流壓力監控預測模型:
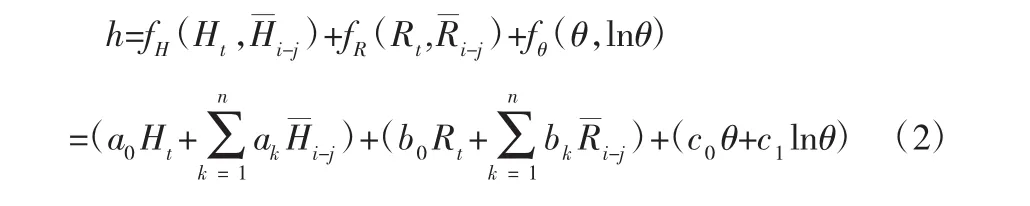
式中:h為滲流壓力水位;Ht為當天水位;Rt為當天雨量;fH、fR、fθ分別為水位因子、降水因子和時間因子;表示觀測日前的第i日到第j日的平均水位;為觀測日前第i日到第j日的平均雨量;θ為觀測日至始測日的累加日數除以 100;a0、ak、b0、bk、c0、c1為回歸系數。
對隱含層節點數的確定,至今沒有一個科學的理論能指導我們確定系統的運行性能最優對應的隱含層節點數,僅有實驗表明:如果隱含層節點數設置較少,BP網絡系統的收斂速度會相對較慢,甚至無法收斂;但是,隱含層節點數設置過多又會使BP網絡在結構上過于繁雜,導致計算量過大,學習時間過長。為了提高網絡系統的性能,可以根據式(3)來確定隱含層節點數。

式中:W為中間層節點數;x和y分別為輸入層和輸出層節點數;z為任意數,z∈(0,10)。
在三層結構中,輸出層傳遞函數選擇線性函數“purelin”,而隱含層的傳遞函數選擇“tan-sigmoid”。本文建立3層“13×10×1”的網絡結構模式,隱含層節點數為10。
2.2 預測流程
基于GACO-BP模型的土石壩滲流壓力預測流程見圖3。
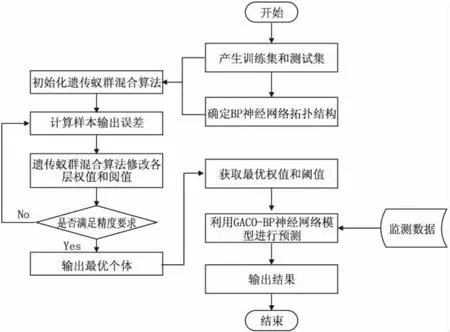
圖3 基于GACO-BP神經網絡模型的土石壩滲流壓力預測流程
3 工程實例
3.1 工程概況
某水庫位于江蘇省金壇市茅山東麓薛埠河上游丘陵地區,水庫設計洪水位28.57 m,校核洪水位29.59 m,正常蓄水位27.0 m,死水位16.70 m。水庫大壩為均質土壩,主要為粉質粘土及粘土,壩頂高程31.26 m,最大壩高約17.0 m。該水庫的大壩安全監測系統建于2006年,主要進行環境、滲流和變形監測。
3.2 算法初始化
遺傳算法中,設計變量采用實數編碼,目標函數取為:

個體適應度函數取為:

定義各參數初值:種群個體數量取為200,最大進化代數取為300,采用輪盤賭選擇法進行選擇操作,交叉概率取為0.5,變異概率取為0.25,其余參數根據經驗取相應合適值。
蟻群算法中,定義各參數初值:最大循環次數Mmax=300,螞蟻數量取為50,信息素啟發式因子α=1,期望值啟發式因子β=5,信息素殘留系數ρ=0.7,其余參數根據經驗取相應合適值。
經過對比嘗試本文將學習次數定為5000,速率定為0.02,學習目標定為0.002。
3.3 樣本選取與訓練
為了對所構建的GACO-BP預警模型的可行性和有效性進行驗證,在該土石壩的所有測點中選取兩個代表測點(命名為第一測點和第二測點)的數據進行仿真計算,以該土石壩2011年9月10日~2013年9月10日的監測資料作為訓練樣本,以2013年9月11日~2013年10月10日的監測資料作為預測樣本。
為了使輸入數據更加適合神經網絡的訓練,提高學習速度,在開始仿真計算前,先要對學習樣本進行預處理。采用極差正規化方法,對樣本輸入值及輸出值進行歸一化處理,見式(6)。

式中:為歸一化后的值;Xm為原始數據;Xmax、Xmin分別代表被處理樣本中的最大值和最小值。
給定精度0.001,利用MATLAB對GACO-BP神經網絡滲流壓力預測模型和標準BP神經網絡模型進行多次仿真試驗,對比兩者的最優訓練速度見表1。

表1 GACO-BP與標準BP神經網絡模型訓練速度對比
從表1可以看出,GACO-BP對觀測數據進行內部訓練僅5次就完成,訓練時長只需1 min,而標準BP卻需要4982次才能完成訓練,相應的時長也達到104 min,由此可以發現GACO-BP神經網絡預測模型的訓練速度比標準BP快很多。
3.4 預測結果分析
為了更清晰地了解GACO-BP神經網絡模型的預測效果,采用相同結構和參數設定的標準BP神經網絡模型通過MATLAB對相同的數據樣本進行訓練并進行仿真預測,對比兩種模型的預測效果。兩測點的預測過程線分別見圖4和圖5。

圖4 第一測點兩種模型預測結果對比
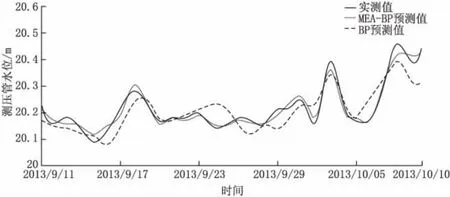
圖5 第二測點兩種模型預測結果對比
從圖4和圖5中可以明顯看出標準BP模型的預測結果相對偏離實際值,而改進的GACO-BP模型對于測壓管水位的預測結果基本與實際吻合,直觀地說明了GACO-BP模型擬合的效果更好,并且更加穩定。
以第一測點為例,對兩種模型的預測結果和預測精度進行定量的對比,具體情況見表2。
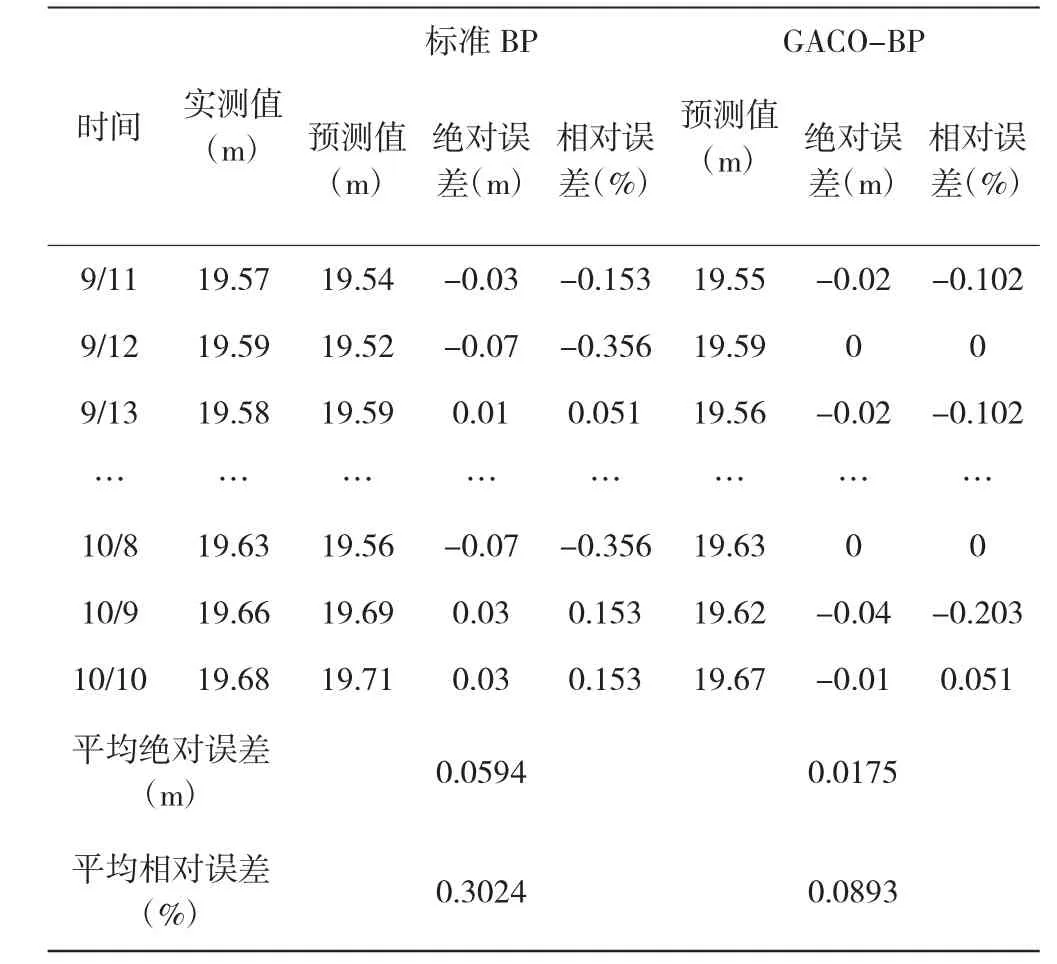
表2 第一測點兩種模型預測結果對比
從表2中可以看出經過改進的GACO-BP神經網絡模型對土石壩測壓管水位預測的平均絕對誤差和平均相對誤差都比標準BP神經網絡模型小3倍左右,說明經過改進的模型預測精度明顯提高,對標準BP神經網絡模型的改進是成功的。
綜合來看,經過改進的GACO-BP神經網絡模型對該土石壩測壓管水位的預測精度高,穩定性強,滿足要求,說明該模型是可以運用到土石壩的預測領域的。
4 結語
1)蟻群算法有強魯棒性、易于與其他算法結合以及優良的分布式計算機制等優點。將其應用于BP神經網絡預測得到的結果擬合精度較高,為以后的進一步研究奠定了基礎。
2)通過算例對比標準BP神經網絡預測模型,直觀地發現經過改進的GACO-BP神經網絡預測模型具有更高的精度和訓練效率,實例應用中的結果驗證了GACO-BP在土石壩滲流壓力預測中的實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
