基于改進(jìn)YOLOv3的合成孔徑雷達(dá)圖像中建筑物檢測算法
2020-08-14 01:48:20李響蘇娟楊龍
兵工學(xué)報 2020年7期
李響, 蘇娟, 楊龍,3
(1.火箭軍工程大學(xué) 核工程學(xué)院, 陜西 西安 710025; 2.96823部隊,云南 昆明 650000;3.96873部隊, 陜西 寶雞 721000)
0 引言
建筑物是重要的人造目標(biāo),遙感圖像中的建筑物檢測在城市規(guī)劃、災(zāi)情評估、軍事偵察等方面具有重大意義[1]。在遙感圖像處理領(lǐng)域,因合成孔徑雷達(dá)(SAR)圖像具有高分辨率、成像全天時、全天候的特性,SAR圖像中的建筑物檢測技術(shù)一直受到廣泛關(guān)注和研究。
傳統(tǒng)SAR圖像中建筑物檢測算法主要分為以下3種:1)基于先驗知識的檢測方法;2)基于模型的檢測方法;3)基于機器學(xué)習(xí)的檢測方法。其中基于機器學(xué)習(xí)的檢測方法主要基于數(shù)據(jù)驅(qū)動,通過訓(xùn)練分類器自動建立目標(biāo)模型,實現(xiàn)對目標(biāo)的檢測。Konstantinidis等[2]設(shè)計方向梯度直方圖- 局部二值模式特征描述符,用于訓(xùn)練支持向量機(SVM)分類器,實現(xiàn)對建筑物的分類。劉靜等[3]提出了馬爾可夫隨機場模型的高分辨率SAR圖像建筑物輪廓提取方法。姜萍等[4]提出將基于像素的訓(xùn)練SVM條件隨機場(SVM-CRF)模型擴展到面向?qū)ο蟮亩喑叨萐VM-CRF模型,使之能同時有效地描述建筑物突出的“面狀”特征及其層次、空間上下文相關(guān)性。上述方法提高了檢測精度和檢測效率,給建筑物檢測帶來了新的思路。缺點是模型提取的特征與分類器的設(shè)計有關(guān),導(dǎo)致提取的特征深度受到限制。
利用卷積神經(jīng)網(wǎng)絡(luò)能夠從數(shù)據(jù)中自動學(xué)習(xí)特征的深度學(xué)習(xí)算法,在計算機視覺領(lǐng)域得到廣泛應(yīng)用,基于深度學(xué)習(xí)的目標(biāo)檢測算法在可見光領(lǐng)域得到迅速發(fā)展。在SAR圖像目標(biāo)檢測領(lǐng)域,深度學(xué)習(xí)同樣被應(yīng)用在坦克目標(biāo)檢測[5]、艦船目標(biāo)檢測[6]、飛機目標(biāo)檢測[7]、SAR圖像道路分割[8]、大場景下建筑物檢測[9]、SAR圖像生成[10]等領(lǐng)域,深度學(xué)習(xí)通過卷積層的相互組合,自動提取、學(xué)習(xí)圖像中的結(jié)構(gòu)化特征,使檢測精度大大提升,克服了傳統(tǒng)檢測算法提取特征不夠深、檢測模型魯棒性差、檢測時間長等缺點。
成熟的深度學(xué)習(xí)檢測網(wǎng)絡(luò)主要分為雙階段檢測和單階段檢測。其中雙階段檢測代表算法主要有區(qū)域卷積神經(jīng)網(wǎng)絡(luò)(R-CNN)[11]、Fast R-CNN[12]、Faster R-CNN[13]等,單階段檢測代表算法主要有YOLO[14]、單次多盒檢測器(SSD)[15]、YOLOv2[16]、YOLOv3[17]等。其中YOLOv3是目前為止速度和精度最為均衡的目標(biāo)檢測網(wǎng)絡(luò),其在目標(biāo)檢測任務(wù)中性能表現(xiàn)尤為突出。
由于SAR數(shù)據(jù)獲取成本高,遙感圖像圖幅面積大、解譯所需的專業(yè)知識要求高等特點,目前已知公開的SAR圖像目標(biāo)檢測數(shù)據(jù)集主要有運動和靜止目標(biāo)的獲取與識別數(shù)據(jù)集、SAR艦船目標(biāo)檢測數(shù)據(jù)集[18]。在SAR圖像建筑物檢測領(lǐng)域,目前還沒有公開的SAR建筑物數(shù)據(jù)集(SBD)。因此SBD的制作對于SAR圖像中建筑物檢測技術(shù)的研究和發(fā)展具有重要意義。
本文將YOLOv3算法應(yīng)用到SAR圖像建筑物檢測中,針對SAR圖像領(lǐng)域公開數(shù)據(jù)集匱乏問題,自行制作SBD;改進(jìn)YOLOv3網(wǎng)絡(luò)結(jié)構(gòu),以提高建筑物檢測任務(wù)的精度。相比直接使用原始YOLOv3算法,平均檢測精度得到提高。
1 SBD制作
1.1 數(shù)據(jù)來源
搜集各類SAR圖像,通過人工查找、裁剪等方法,從大場景SAR圖像中獲取不同背景下、不同表現(xiàn)形式的建筑物數(shù)據(jù),制作SBD. 數(shù)據(jù)集共包含1 000張圖片,數(shù)據(jù)集圖片像素大小為416×416、512×512;數(shù)據(jù)來源包含X波段,C波段等Terra SAR、高分3號衛(wèi)星、美國桑迪亞國家實驗室等機載、星載平臺拍攝的經(jīng)過幾何校正的SAR圖像;圖像分辨率分別為0.5 m、1 m、1.25 m、5 m等;極化方式包括交叉極化(VH、HV)、同極化(HH、VV)。數(shù)據(jù)集中建筑物類型包括一般獨立建筑、外形不規(guī)則特殊建筑、規(guī)則建筑群,圖1所示為3種典型建筑物示例圖。
1.2 數(shù)據(jù)集標(biāo)注
利用標(biāo)注軟件LabelImg對獲取到的含有建筑物的圖像切片進(jìn)行標(biāo)注。LabelImg軟件是基于Python語言編寫的用于深度學(xué)習(xí)數(shù)據(jù)集制作的圖片標(biāo)注工具,主要用于記錄目標(biāo)的類別名稱和位置信息,并將信息存儲在可擴展標(biāo)記語言(XML)格式文件中。
具體標(biāo)注流程如下:首先對圖像中的建筑物進(jìn)行人工識別,確定其為建筑物目標(biāo);然后用垂直的最小外接矩形框?qū)⒔ㄖ锬繕?biāo)依次選中,同時設(shè)置類別標(biāo)簽為“building”。矩形框的標(biāo)記信息(x,y,h,w)儲存在標(biāo)簽XML文件中,其中(x,y)為矩形框的左上角坐標(biāo),h、w分別為矩形框高度和寬度。數(shù)據(jù)標(biāo)注示例圖如圖2(b)所示,其中綠色矩形框為標(biāo)注為建筑物目標(biāo),(x1,y1)為矩形框左上角坐標(biāo),(x2,y2)為矩形框右下角坐標(biāo)。根據(jù)YOLOv3訓(xùn)練要求,將XML文件轉(zhuǎn)化為以類別、目標(biāo)坐標(biāo)為內(nèi)容的文本(TXT)格式文件,為下一步訓(xùn)練做準(zhǔn)備。標(biāo)注數(shù)據(jù)類型轉(zhuǎn)換如圖2(c)所示,其中左側(cè)紫色文件為XML格式的標(biāo)注信息,右側(cè)TXT格式文件中第1個數(shù)值為類別對應(yīng)的序號,后4個數(shù)值分別表示以圖2(b)左上角為原點的標(biāo)注矩形框的左上角和右下角橫縱坐標(biāo)。

圖2 數(shù)據(jù)標(biāo)注示意圖Fig.2 Data labeling diagram
在數(shù)據(jù)集制作過程中,由于SAR圖像數(shù)據(jù)有限,本文盡可能加入不同尺度、不同形狀和表現(xiàn)形式的建筑物,改變同一圖像的分辨率大小,并在訓(xùn)練預(yù)處理中對數(shù)據(jù)進(jìn)行增廣處理,即進(jìn)行旋轉(zhuǎn)、獨立目標(biāo)裁剪、顏色抖動、隨機平移等操作,并修改相應(yīng)的標(biāo)簽數(shù)據(jù),最終數(shù)據(jù)集大小為1 438張圖像。數(shù)據(jù)增強效果示意圖如圖3所示。數(shù)據(jù)增強的目的是增加訓(xùn)練樣本的多樣性,避免訓(xùn)練過程出現(xiàn)過擬合,提高網(wǎng)絡(luò)泛化能力。

圖3 數(shù)據(jù)增廣示意圖Fig.3 Schematic diagram of data augmentation
1.3 數(shù)據(jù)集分析
SBD一共含有1 438張圖像,建筑物總數(shù)為13 457個。圖4(a)所示為數(shù)據(jù)集中每張圖像所含建筑物個數(shù)的統(tǒng)計直方圖,圖4(b)所示為每個目標(biāo)像素占所在圖像像素比例的統(tǒng)計直方圖。目標(biāo)平均像素大小為2 687.103 5,目標(biāo)平均與原圖的比例為0.013 2.

圖4 數(shù)據(jù)集中目標(biāo)信息統(tǒng)計直方圖Fig.4 Statistical histogram of target information in dataset
由圖4(a)可知,數(shù)據(jù)集中每張圖像上的目標(biāo)數(shù)量有較大變化,大部分圖像中有1~10個目標(biāo),其他圖像中有10個以上的目標(biāo),圖像中目標(biāo)數(shù)量較多,分布較密集。由圖4(b)可知,建筑物目標(biāo)像素大小存在多樣性且在圖像中占比很小,因此建筑物屬于小目標(biāo),圖像中存在較多背景信息。
李健偉等[18]分析了Faster R-CNN算法在可見光數(shù)據(jù)集目標(biāo)檢測中取得較好效果、在SAR圖像艦船目標(biāo)檢測中性能不佳的原因,指出SAR圖像中艦船目標(biāo)在圖像中像素占比小、預(yù)訓(xùn)練特征不適用于SAR圖像等。同理,從SAR圖像成像特性來看,相比于可見光圖像中的建筑物,SAR圖像中建筑物的成像形式不受建筑物本身外觀顏色變化的影響,主要與建筑物與雷達(dá)波束的方向夾角和自身高度有關(guān),成像模型具有規(guī)律性和穩(wěn)定性。但相比于高分辨率可見光圖像,SAR圖像中建筑物的細(xì)節(jié)紋理信息不明顯,一些非建筑金屬物體在SAR圖像中的表現(xiàn)形式類似于建筑物,從而容易導(dǎo)致檢測結(jié)果存在虛警,且SAR圖像中的斑點噪聲也會對檢測效果帶來影響,因此需要準(zhǔn)確識別建筑物,記錄正確的標(biāo)簽信息,確保訓(xùn)練模型的有效性。
針對20類目標(biāo)在圖像分類、目標(biāo)檢測、圖像分割等領(lǐng)域進(jìn)行算法評估的VOC2007數(shù)據(jù)集含有9 963張圖像,因此圖像數(shù)量為1 438,目標(biāo)類別僅有一類的SBD能夠滿足SAR圖像建筑檢測算法性能的檢驗。從SBD可知:在不同圖像中建筑物數(shù)量變化較大,同一張圖像中建筑物可能同時存在多種尺度和多種位置、朝向等分布情況;不同波段、不同極化方式下建筑物和背景噪聲的表現(xiàn)形式有所不同;不同分辨率下,建筑物尺寸大小、細(xì)節(jié)紋理的表現(xiàn)形式也會有區(qū)別;相比于圖像大小而言,建筑物屬于小目標(biāo)。結(jié)合圖4的分析可知,針對建筑物目標(biāo)的檢測需要研究多尺度檢測網(wǎng)絡(luò)模型,保留細(xì)節(jié)信息,充分利用建筑物的空間信息等。
綜上所述,SBD可應(yīng)用于SAR圖像建筑檢測模型的研究,在構(gòu)建檢測模型時,需要從建筑物的細(xì)節(jié)信息、形狀特性、多尺度特征出發(fā)。
2 SAR圖像建筑物檢測
2.1 YOLOv3算法的基本原理
YOLOv3算法是YOLOv1和YOLOv2算法的改進(jìn)版本,同時吸收了其他檢測網(wǎng)絡(luò)的優(yōu)勢特征,是目前深度學(xué)習(xí)檢測網(wǎng)絡(luò)中檢測效果最佳的單階段檢測網(wǎng)絡(luò)之一。YOLOv3算法是基于Darknet框架實現(xiàn)的,Darknet是基于C語言與CUDA運算平臺的開源深度學(xué)習(xí)框架,具有結(jié)構(gòu)清晰、可移植性強、輕量化、不依靠依賴項的特點。
YOLOv3算法采用全卷積神經(jīng)網(wǎng)絡(luò),在以殘差結(jié)構(gòu)為主體的Darknet-53骨架網(wǎng)絡(luò)基礎(chǔ)上,增加了跳過連接層和上采樣層,共75個卷積層。在特征提取過程中,輸入圖像大小默認(rèn)為416×416像素時,借鑒特征金字塔網(wǎng)絡(luò)思想,在3個尺度大小(13×13、26×26 和 52×52)的特征圖上,給每個尺度分配3個不同大小的預(yù)選框,然后基于圖像的全局信息進(jìn)行目標(biāo)預(yù)測,從而實現(xiàn)端到端的檢測。在下采樣中YOLOv3算法使用步幅為2的卷積層對特征圖進(jìn)行卷積,減少池化步驟導(dǎo)致的小目標(biāo)信息丟失。YOLOv3算法檢測流程和Darknet-53網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。圖5中,a、b為圖像大小,n為通道數(shù)。張量拼接模塊的作用是將Darknet網(wǎng)絡(luò)中間特征層與上采樣后的特征圖進(jìn)行拼接,拼接后張量維度也隨之疊加增大。
YOLOv3算法的損失函數(shù)由位置誤差(中心坐標(biāo)預(yù)測誤差、邊界框預(yù)測誤差)、分類誤差、置信度誤差3部分組成,損失函數(shù)公式如下:
Loss=5×(exy+ewh)+1×ec+
1×eoc+0.5×enc,
(1)
式中:Loss為損失函數(shù);位置誤差分為exy和ewh,exy為目標(biāo)中心相對于所在網(wǎng)格左上角的偏移量誤差,ewh為錨點框的長度和寬度誤差,位置誤差權(quán)重為5;ec為分類誤差,權(quán)重為1;置信度誤差分為eoc和enc,分別表示目標(biāo)置信度誤差和非目標(biāo)置信度誤差,權(quán)重分別為1和0.5.
2.2 改進(jìn)YOLOv3的檢測算法
2.2.1 SAR-YOLOv3算法檢測網(wǎng)絡(luò)
建筑物在圖像中的位置信息和輪廓信息豐富,這是建筑物的重要特征。深度卷積神經(jīng)網(wǎng)絡(luò)中,淺層卷積網(wǎng)絡(luò)主要是提取圖像的輪廓形狀特征,深層卷積網(wǎng)絡(luò)主要是提取語義信息。因此通過分析SAR圖像中的建筑物特性、分布規(guī)律,提出適合SAR圖像建筑物檢測任務(wù)的SAR-YOLOv3檢測算法,以下簡稱S-YOLOv3算法。S-YOLOv3算法網(wǎng)絡(luò)結(jié)構(gòu)和檢測流程如圖6所示,圖中ResX為改進(jìn)的殘差模塊,SFF為淺層特征融合模塊。在YOLOv3算法的Darknet-53網(wǎng)絡(luò)基礎(chǔ)上,增加輪廓信息比重,即將淺層特征下采樣后與原始3個尺度的特征圖進(jìn)行融合,再在新的特征圖上預(yù)測;同時改進(jìn)殘差結(jié)構(gòu),增加通道信息的利用,擴展網(wǎng)絡(luò)寬度,在不增加網(wǎng)絡(luò)計算量的基礎(chǔ)上提高檢測精度。
2.2.2 結(jié)構(gòu)改進(jìn)
2.2.2.1 SFF模塊
SAR圖像中建筑物目標(biāo)的輪廓、尺寸、灰度特性等淺層特征在目標(biāo)檢測中起到重要指導(dǎo)作用,相比于全局特征和語義特征,淺層特征在建筑物檢測過程中應(yīng)具有更大的權(quán)重。因此在兼顧計算量和特征信息保持性的同時,將原圖像下采樣4倍后大小為104×104像素的特征圖從骨架網(wǎng)絡(luò)中抽取出來,經(jīng)過3次下采樣后分別與原始3個尺度的特征層融合,再在新的多尺度特征圖上進(jìn)行檢測。待融合的淺層特征圖如圖7所示,3個尺度(13×13、26×26 和 52×52)下的特征融合圖如圖8所示。
由圖7(a)和圖8(a)可以直觀看出,通過卷積層進(jìn)行特征提取得到的特征圖與原始圖像相比表現(xiàn)形式有較大的差異,難以解釋和辨別。由圖7(c)可以發(fā)現(xiàn),淺層特征圖中建筑物邊緣輪廓和紋理信息比較明顯,隨著經(jīng)過的卷積層層數(shù)增加,圖像尺寸越來越小,多次卷積操作會導(dǎo)致原始圖像中的細(xì)節(jié)信息逐漸丟失。如圖8(a)52×52尺度所示,原始YOLOv3在52×52尺度特征圖上建筑物輪廓信息不明顯,僅剩下語義信息,但圖8(b)52×52尺度增加淺層信息后特征圖像中的建筑物輪廓紋理更加明顯,對建筑物檢測具有重要意義的輪廓紋理特征比重有所增加,使圖像所含信息更加豐富。
2.2.2.2 ResX模塊
YOLOv3算法中的Darknet-53骨架網(wǎng)絡(luò)是借鑒殘差網(wǎng)絡(luò)(ResNet)[19]模型、以多個相同的殘差單元堆疊構(gòu)成的,通過增加網(wǎng)絡(luò)深度可以獲得更大感受野,減少超參數(shù)的設(shè)計。ResNet 的定義和模型結(jié)構(gòu)如(2)式和圖9所示,將模型的學(xué)習(xí)過程轉(zhuǎn)化為對殘差F(x)的擬合,通過學(xué)習(xí)使殘差最小,最終使映射H(x)接近輸入x.

圖5 YOLOv3算法檢測流程和Darknet-53網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 Flow chart of YOLOv3 and Darknet-53 structure

圖6 S-YOLOv3算法網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.6 Network structure of S-YOLOv3

圖7 原始SAR圖像和待融合的淺層特征圖Fig.7 Original SAR image and shallow feature map to be fused
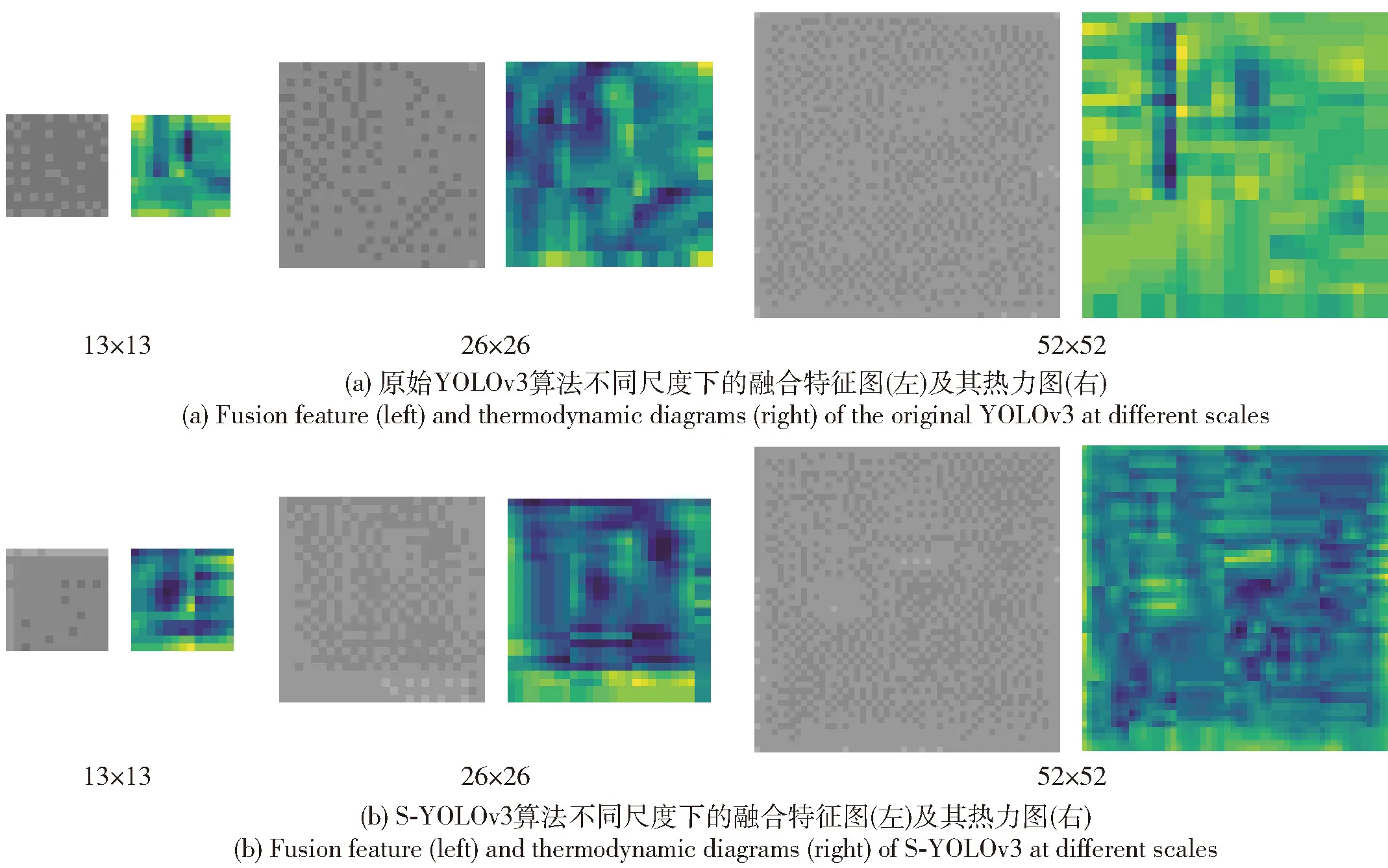
圖8 不同尺度下的待檢測融合特征圖Fig.8 Fusion features to be detected at different scales
H(x)=F(x,{wi})+x,
(2)
式中:wi為投影系數(shù),用以使殘差和輸入維度保持一致。
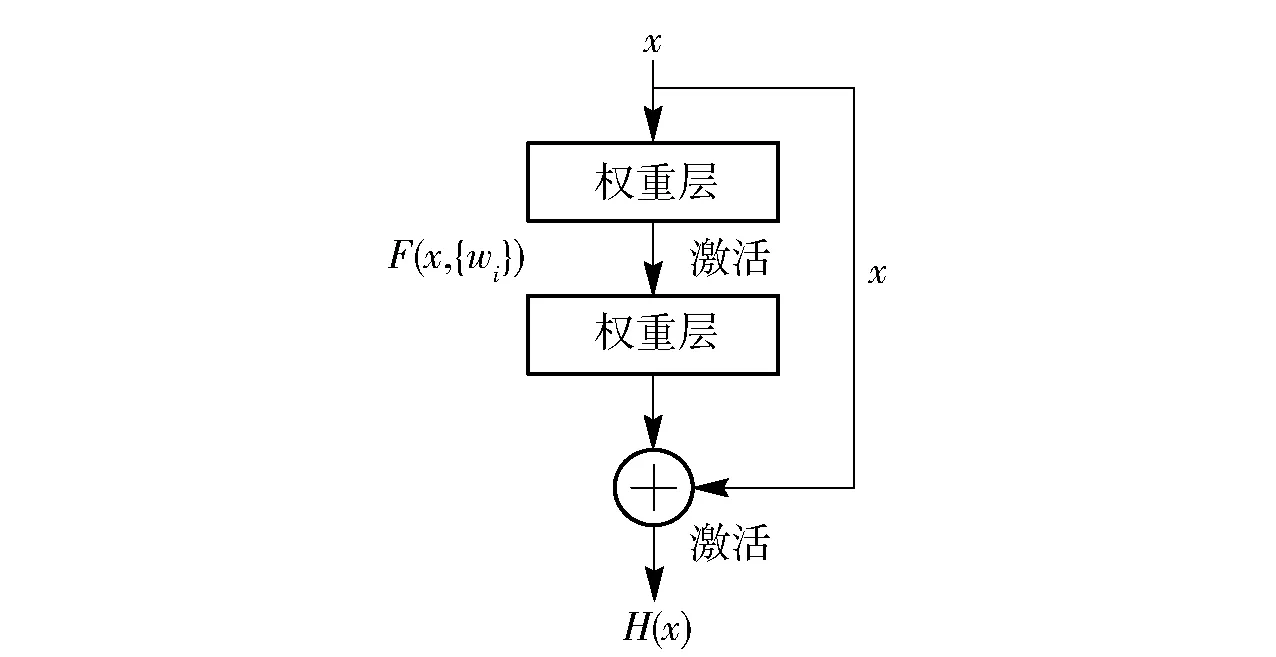
圖9 ResNet模塊結(jié)構(gòu)示意圖Fig.9 Network structure of ResNet module
相比于YOLOv2算法,YOLOv3算法引入了殘差結(jié)構(gòu),增加了網(wǎng)絡(luò)深度,取得較好的檢測效果。但隨著網(wǎng)絡(luò)深度增加,運算量也會增加,且網(wǎng)絡(luò)在增加深度的同時沒有充分利用通道信息,因此再次加深網(wǎng)絡(luò)并不是提高檢測精度和檢測效率的最佳選擇。本文借鑒深度神經(jīng)網(wǎng)絡(luò)的聚合殘差轉(zhuǎn)換(ResNeXt)[20]思想,將改進(jìn)后的殘差模塊引入YOLOv3算法中,擴展網(wǎng)絡(luò)寬度,在不增加網(wǎng)絡(luò)計算量的同時提高檢測精度。
ResNeXt模型采用拓?fù)淠K堆疊而成,是Inception[21]模塊在ResNet結(jié)構(gòu)上的應(yīng)用。ResNeXt的定義和模型結(jié)構(gòu)如(3)式和圖10所示。
(3)
式中:C為分組卷積的組數(shù);Ψi(x)為分組卷積中每一路卷積。

圖10 ResNeXt模型結(jié)構(gòu)示意圖Fig.10 Network structure of ResNeXt model

圖11 改進(jìn)后骨架網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.11 Diagram of improved skeleton network structure
ResNeXt模型中,原始ResNet網(wǎng)絡(luò)模型中的卷積被分解為以基數(shù)為單位的卷積組,然后將各通道信息進(jìn)行合并,最后與卷積前的特征圖相加。ResNeXt模型同時結(jié)合了ResNet網(wǎng)絡(luò)超參數(shù)選擇少和Inception網(wǎng)絡(luò)資源利用率高等優(yōu)點。
本文將Darknet-53網(wǎng)絡(luò)結(jié)構(gòu)中第33層~第36層、第58層~第61層、第71層~第74層之間的殘差模塊改進(jìn)為多路ResX模塊,即在原始?xì)埐罱Y(jié)構(gòu)中間增加多路卷積,得到ResX模塊結(jié)構(gòu)圖如圖11所示。
如圖11所示,將3組原始?xì)埐钅K中的單路卷積改為結(jié)構(gòu)一致的多路卷積。ResX模塊中第1層1×1卷積的目的是進(jìn)行降維、降低計算量,3×3卷積層組的目的是提高特征圖的感受野,最后1層1×1卷積目的是恢復(fù)特征圖的維度以實現(xiàn)跨通道信息融合。改進(jìn)后網(wǎng)絡(luò)深度增加了3層卷積層,ResX模塊計算量公式為
(4)
式中:amount為計算量。當(dāng)C=4、n=256時,對一個ResX模塊計算量amount和Res模塊計算量amountRes進(jìn)行比較:
amount=256×1×64+4×(64×3×3×64)+
64×1×256=180 224,
amountRes=256×1×128+128×3×
3×256=327 680.
通過計算可以發(fā)現(xiàn),改進(jìn)后一個殘差模塊的計算量減少了45%,由此可知改進(jìn)后的殘差模塊沒有引入額外的計算量。
2.2.3 非結(jié)構(gòu)改進(jìn)
2.2.3.1 預(yù)設(shè)錨點框的選擇
預(yù)設(shè)錨點框是通過K均值(K-means)聚類算法聚類得到的,聚類中心數(shù)設(shè)為9. 隨機化初始位置,計算標(biāo)注信息中每個標(biāo)注框與聚類中心點的距離,將標(biāo)注框分給距離最近的聚類中心,分配完成后重新計算聚類中心點,直至聚類中心不發(fā)生變化。而傳統(tǒng)K-means算法是采用歐氏距離作為相似性度量,但在檢測算法中,設(shè)置合理尺寸錨點框的目的,是使預(yù)測值和真實值取得更好的交并比。因此YOLOv3算法采用以交并比為距離度量的K-means算法得到,距離公式如下:
d(r,o)=1-IOU(r,o),
(5)
(6)
式中:d(r,o)為預(yù)測框r和聚類中心o之間的距離;IOU(·)為平均交并比函數(shù);rpt為預(yù)測框;rgt為實際框。
原始YOLOv3算法中的9個預(yù)設(shè)錨點框是通過對上下文中通用對象(COCO)數(shù)據(jù)集聚類得到的,分為3組:((116,90)、(156,198)、(373,326));((30,61)、(62,45)、(59,119));((10,13)、(16,30)、(33,23)),分別對應(yīng)3個尺度(13×13、26×26和52×52)特征圖,進(jìn)行目標(biāo)邊界框的預(yù)測。由于COCO數(shù)據(jù)集包含的目標(biāo)類別豐富且目標(biāo)尺寸差異較大,通過人工判讀發(fā)現(xiàn)SAR圖像中建筑物目標(biāo)外形以長而窄的矩形為主,因此原始設(shè)定的預(yù)選框不適合用于本文單類建筑物數(shù)據(jù)集,同時在實驗中發(fā)現(xiàn)訓(xùn)練過程中采用原始預(yù)選框會出現(xiàn)某一尺度上無法檢測到目標(biāo)的情況。本文通過K-means算法對SBD數(shù)據(jù)進(jìn)行重新聚類,得到適合SAR建筑物數(shù)據(jù)的預(yù)設(shè)錨點框。通過10次聚類,求得平均聚類結(jié)果為:((65,53)、(83,31)、(118,86));((36,23)、(50,19)、(56,29));((20,11)、(30,14)、(35,43))。如圖12所示,原始預(yù)設(shè)錨點框不能很好地適應(yīng)SAR圖像建筑物目標(biāo),而重新聚類后的錨點框比例大小能夠符合SAR圖像建筑物數(shù)據(jù)的形狀特點。

圖12 預(yù)設(shè)錨點框?qū)ㄖ锬繕?biāo)的作用范圍示例圖Fig.12 Example diagram of the preset anchor frame on a building target
2.2.3.2 上采樣改進(jìn)

圖13 轉(zhuǎn)置卷積原理示意圖Fig.13 Transposed convolution
由圖5可知,YOLOv3算法將底層特征圖進(jìn)行上采樣,然后與同等大小的淺層特征進(jìn)行融合,最后在融合得到的3個尺度特征圖上進(jìn)行目標(biāo)分類和位置回歸。在原始YOLOv3算法中上采樣層采用最近鄰插值算法。最近鄰插值算法主要求解步驟為:1)計算輸出圖像某一像素點在原始圖像中所對應(yīng)的坐標(biāo)點位置;2)將對應(yīng)坐標(biāo)點的相鄰4個像素點中距離最近的像素點灰度值作為插值大小。該方法簡單、易行,但容易造成上采樣后圖像灰度不連續(xù)的情況。
因此本文用轉(zhuǎn)置卷積[22]替代最近鄰插值算法,將簡單插值過程轉(zhuǎn)變?yōu)閷W(xué)習(xí)過程,通過卷積運算進(jìn)行像素插值,以減少灰度的細(xì)節(jié)特征丟失。首先對輸入圖像進(jìn)行補0,然后將卷積核按設(shè)定的步長在圖像上滑動,計算對應(yīng)像素點所需的插值。轉(zhuǎn)置卷積運算過程如圖13所示。圖13中,k為卷積核尺寸,p為補0的行列數(shù)。
轉(zhuǎn)置卷積后圖像尺寸大小計算公式為
Io=(Ii-1)×s+k-2×p,
(7)
式中:Ii和Io為輸入圖像和輸出圖像大小;s為卷積核的滑動步長。當(dāng)s=2、k=4、p=1時,輸出圖像尺寸為原來尺寸的兩倍。
3 實驗結(jié)果與分析
3.1 實驗設(shè)置
本文使用的硬件平臺有:中央處理器Intel(R) Core(TM) i5-3210M @2.50 GHz×2,圖形處理器NVIDIA GTX 1080Ti ×2,64 GB內(nèi)存;使用的網(wǎng)絡(luò)框架為Darknet;編程語言為C語言和Python語言;操作系統(tǒng)為Ubuntu 16.04;使用的數(shù)據(jù)集為本文制作的SBD.
在SBD上進(jìn)行SAR建筑物檢測模型的訓(xùn)練,并在驗證集上進(jìn)行檢測。訓(xùn)練集和驗證集按照7∶3的比例進(jìn)行隨機分配。預(yù)設(shè)訓(xùn)練參數(shù)為:動量0.9,權(quán)重衰減系數(shù)0.000 5,前1 000次迭代的學(xué)習(xí)率0.001,迭代到40 000次時學(xué)習(xí)衰減十分之一,最大迭代次數(shù)50 200,類別數(shù)1,預(yù)測層的前一層卷積核數(shù)18.
使用以對象為基準(zhǔn)的評估指標(biāo)進(jìn)行效果評估,即平均準(zhǔn)確率AP、召回率Recall、平均交并比IOU、檢測速度FPS和準(zhǔn)確率- 召回率(P-R)曲線,公式定義為
(8)
(9)
式中:TP被預(yù)測為“+”,實際為“+”;TN被預(yù)測為“-”,實際為“+”;FN被預(yù)測為“-”,實際為“-”;FP被預(yù)測為“+”,實際為“-”。
3.2 模型測試實驗
為測試本文方法在SAR圖像建筑物檢測中的效果,設(shè)置實驗1和實驗2進(jìn)行檢測效果評估。其中實驗1是預(yù)置條件和非網(wǎng)絡(luò)結(jié)構(gòu)改進(jìn)(預(yù)訓(xùn)練權(quán)重、預(yù)設(shè)錨點框、上采樣方式)對SAR圖像建筑物檢測結(jié)果的影響進(jìn)行評估,以確定最優(yōu)的初始條件并論證模型的非結(jié)構(gòu)改進(jìn)作用;實驗2是在實驗1取得最優(yōu)檢測結(jié)果的模型基礎(chǔ)上,增加網(wǎng)絡(luò)結(jié)構(gòu)改進(jìn)并與原始YOLOv3算法檢測效果的比較。通過兩個實驗評估網(wǎng)絡(luò)結(jié)構(gòu)改進(jìn)模塊對SAR圖像建筑物檢測結(jié)果的影響,以此確定最優(yōu)的檢測模型。
選取檢測精度最好的迭代次數(shù)對應(yīng)的訓(xùn)練權(quán)重作為最終訓(xùn)練好的模型。不同實驗方案對應(yīng)的實驗結(jié)果分別如表1、表2所示。表2中FPS表示每秒處理的圖片數(shù)量。

表1 實驗1結(jié)果

表2 實驗2結(jié)果
由表1第1行和第3行數(shù)據(jù)、第2行和第4行數(shù)據(jù)對比可知,根據(jù)實際數(shù)據(jù)集對預(yù)設(shè)錨框進(jìn)行重新設(shè)置,平均檢測精度和召回率均得到顯著提高,表明錨點框的設(shè)置對于檢測精度具有促進(jìn)作用。由第2行和第5行數(shù)據(jù)、第4行和第6行數(shù)據(jù)對比可以看出,采用轉(zhuǎn)置卷積進(jìn)行上采樣,對于檢測效果有0.5%~0.8%左右的略微提高。
通過比較實驗1前4行數(shù)據(jù)可以發(fā)現(xiàn),預(yù)訓(xùn)練權(quán)重的使用與否,對于SAR圖像建筑物檢測效果影響沒有較大影響。主要原因是官方提供的預(yù)訓(xùn)練模型是通過可見光數(shù)據(jù)集在Darknet-53骨架網(wǎng)絡(luò)訓(xùn)練得出的,而SAR圖像與可見光圖像在成像機理、圖像表現(xiàn)形式上有較大差異,且本文對骨架網(wǎng)絡(luò)進(jìn)行了改進(jìn),因此在實驗2中沒有使用預(yù)訓(xùn)練權(quán)重。
由表2可知,相比原始YOLOv3算法,增加了ResX模塊和SFF模塊的YOLOv3算法在保持較快檢測速度的同時提高了檢測精度。殘差結(jié)構(gòu)ResX中卷積組數(shù)的增加有利于提升模型性能,同時保持網(wǎng)絡(luò)結(jié)構(gòu)的靈活性。淺層特征融合SFF模塊對于檢測精度的提升效果顯著。表明兩個模塊相結(jié)合的S-YOLOv3算法平均檢測精度提高了9.2%,召回率提高了6.3%.
由實驗2結(jié)果可以看出:改進(jìn)后的YOLOv3算法和原始YOLOv3算法檢測速度相差不大,能夠在1 s內(nèi)實現(xiàn)40張以上數(shù)量的圖像檢測,保持較快的檢測速度。
P-R曲線可以同時衡量模型的準(zhǔn)確率和召回率,曲線與坐標(biāo)軸的面積越大,模型表現(xiàn)越佳。不同網(wǎng)絡(luò)結(jié)構(gòu)的YOLOv3的P-R曲線如圖14所示。
由圖14(a)可以發(fā)現(xiàn),YOLOv3-ResX(C=2)、YOLOv3-ResX(C=4)和YOLOv3-SFF算法的P-R曲線比原始YOLOv3算法下降趨勢更慢,在保持較高召回率的同時能夠保持較高檢測精度,表明ResX模塊和SFF模塊對檢測效果的提升有促進(jìn)作用,其中SFF模塊對檢測效果的提升作用大于ResX模塊。圖14(b)為結(jié)合ResX(C=4)和SFF兩個模塊的S-YOLOv3算法和原始YOLOv3算法的P-R曲線。由圖14(b)可以看出,S-YOLOv3算法的P-R曲線比原始YOLOv3算法的P-R曲線位置更高、下降幅度更慢,曲線與坐標(biāo)軸的面積更大,表明S-YOLOv3算法比原始YOLOv3算法在SAR圖像建筑物檢測任務(wù)上表現(xiàn)更佳。

圖14 不同算法間的P-R曲線比較圖Fig.14 Comparison of P-R curves of different algorithms
3.3 模型性能評估實驗
通過對SBD進(jìn)行學(xué)習(xí)、訓(xùn)練得到檢測模型,對模型性能進(jìn)行評估,得到建筑物檢測結(jié)果如表3所示:其中第1行為4種典型場景下待檢測建筑物的地面分布情況,圖中的矩形框為數(shù)據(jù)集標(biāo)注框,本文對于數(shù)據(jù)集中的建筑物統(tǒng)一采用垂直的外接矩形框進(jìn)行標(biāo)注,且標(biāo)注過程中將間距過小、過于密集的建筑物視為整體,檢測結(jié)果的表現(xiàn)形式與標(biāo)注情況一致;第2行圖像為原始YOLOv3算法的檢測結(jié)果;第3行圖像為S-YOLOv3算法針對同一數(shù)據(jù)的檢測結(jié)果。
根據(jù)SBD的統(tǒng)計特性可知,建筑物分布存在多樣性,目標(biāo)大小存在多尺度特性,目標(biāo)成像表現(xiàn)形式也不同。表3的結(jié)果表明:檢測結(jié)果與基準(zhǔn)標(biāo)注圖表現(xiàn)形式一致,原始YOLOv3算法和S-YOLOv3算法對SBD中分布規(guī)則且具有明顯建筑物成像特征的數(shù)據(jù)具有較好檢測效果;原始YOLOv3算法對SAR圖像中背景復(fù)雜、建筑物成像特征不明顯和大場景下建筑物目標(biāo)占圖幅比例小的數(shù)據(jù)漏檢率較高,而S-YOLOv3算法能夠克服以上缺點、降低漏檢率。由此表明改進(jìn)后的YOLOv3算法能夠更好地適應(yīng)SBD數(shù)據(jù)集的數(shù)據(jù)特性。
4 結(jié)論
本文對SAR圖像中建筑物自動檢測算法進(jìn)行了研究,通過分析SAR圖像數(shù)據(jù)集,針對SBD中目標(biāo)的特點對YOLOv3檢測算法進(jìn)行了改進(jìn),并使用改進(jìn)YOLOv3算法對建筑物進(jìn)行檢測。得到以下主要結(jié)論:
1)相比原始YOLOv3算法,改進(jìn)YOLOv3檢測算法的平均檢測精度提高了9.2%,召回率提高了6.3%.
2)ResX模塊和SFF模塊能夠在擴展網(wǎng)絡(luò)寬度、提高信息利用率的同時,保持較快檢測速度,促進(jìn)檢測模型性能的提升。
3)改進(jìn)YOLOv3算法能夠更好地適應(yīng)SBD的數(shù)據(jù)特性。

表3 建筑物檢測結(jié)果對比
總之,通過將在可見光數(shù)據(jù)集的目標(biāo)檢測任務(wù)中取得較好效果的YOLOv3檢測算法成功應(yīng)用到SAR圖像建筑物檢測領(lǐng)域,表明深度學(xué)習(xí)算法在SAR圖像建筑物檢測中的可行性,對后續(xù)SAR圖像中建筑物檢測算法的深入研究具有一定指導(dǎo)意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
