基于聯合投影字典學習的輻射源調制識別
2020-08-14 01:48:48李東瑾楊瑞娟董睿杰
兵工學報 2020年7期
李東瑾, 楊瑞娟, 董睿杰
(空軍預警學院, 湖北 武漢 430019)
0 引言
隨著新型裝備的不斷革新,多功能一體化技術因其獨特優勢備受關注[1]。一體化技術的應用將有望解決單平臺能力不足、多功能系統冗余和集約化程度不高等問題。高效的輻射源信號識別將為系統一體化功能間的柔性融合提供無源數據支持,是一體化系統智能化的關鍵環節。輻射源識別技術經歷了漫長的發展歷程,其本質在于提取信號的高穩定性特征,利用模式識別等方法實現高效分類,當前研究多聚焦于調制類型識別。早期,諸多學者致力于人工特征提取及分類識別方式研究。隨后,特征提取方式不斷增多,通過各類線性、非線性映射提取了諸如小波特征、熵特征、復雜度特征和模糊函數特征等高階特征[2-5];分類器研究也由傳統線性分類器轉向機器學習領域的非線性分類方式,特征穩定性和整體識別性能均得以提升。綜合來看,特征提取和分類器設計方式繁多,但人為干預因素較多,難以充分挖掘和利用內在特征。
近年來,稀疏表示與字典分類算法在壓縮感知、圖像識別、計算機視覺、圖像降噪等領域取得了諸多成果[6-9]。對應算法主要分為兩類:1)稀疏表示分類,聚焦于稀疏重構,采用重構誤差完成分類識別,例如稀疏表示分類(SRC)等[9];2)字典學習分類。常通過引入各類判別項強化鑒別能力,文獻[10]通過引入類別一致性約束提出了判別迭代奇異值分解(D-KSVD)字典學習方式;文獻[11]引入Fisher判別準則,綜合考慮類內與類間誤差,提出了基于Fisher判別的字典學習方法(FDDL);文獻[12]考慮編碼鑒別性和標簽連續性約束提出了標簽一致性迭代奇異值分解(LC-KSVD)字典學習方式,文獻[13]考慮高維核映射提出了核迭代奇異值分解(Kernel-KSVD)算法。字典學習能夠提取樣本數據的內在特征,得到較本質的原子特征表示,在輻射源識別領域已有部分學者開展相關研究并取得成效,所研究內容大致分為兩類:1)基于解析字典學習的輻射源識別,即通過既定線性、非線性映射得到固定原子字典表示并用于實現分類識別[14],該方式需要進行人工設計,難以適應參數變化等情況;2)基于判別約束的字典學習識別方式。文獻[15]利用Fisher判別字典進行Gabor原子特征學習,得到了較強表征能力的時頻原子字典。綜合來看,字典學習理論應用于輻射源識別領域仍有較大發展空間。現有字典學習方式對環境和各型信號的適應能力存在較大差異,尤其對于參數多變且具備較高相似度數據難以實現有效識別,因此需要判別字典具備更高的適應性和特征提取能力。
鑒于此,本文采用聯合投影字典學習(JPDL)方式進行輻射源識別。為降低信號非平穩和噪聲干擾影響,采用短時傅里葉變換(STFT)及其預處理后的淺層時頻信號作為初始特征。聯合投影字典側重特征映射及選擇能力,通過特征映射提升特征維度并增強特征辨識度,利用降維學習選擇強特征并降低高維數據冗余,完成特征的核空間非線性升維投影與線性降維投影。分類識別過程利用聯合投影字典進行稀疏編碼,并通過重構誤差完成分類識別。
1 基于JPDL的輻射源識別系統
實際應用輻射源信號面臨復雜電磁環境、信號非平穩及各類不確定性,時域信號穩定性不高且分辨能力較差,因此不利于高效識別。時頻域信號具備較好的能量聚焦性和局部頻域維稀疏特性,其中STFT時頻特征[16]復雜度較低,有助于提升分類時效性。此外,淺層時頻特征為字典學習提供一個較好的初始字典集,便于其學到更本質的分類特征。
基于字典學習的輻射源識別系統如圖1所示,其包含包括測試與訓練兩個階段。訓練階段利用已知輻射源信號及對應類別標簽離線進行降維學習和字典學習,獲取降維投影矩陣和最佳字典表示;測試階段通過無標簽數據進行稀疏編碼并完成有效性驗證。整個流程可分為3個部分,即淺層時頻特征提取、JPDL、分類識別,其中JPDL過程包括核空間映射、特征降維學習、稀疏編碼和字典學習。稀疏編碼階段完成字典原子的最優線性表示。

圖1 基于JPDL的輻射源識別流程示意圖Fig.1 Flow chart of emitter signal recognition based on joint projection dictionary learning
本文主要考慮10種調制方式,即單載頻(SCFM)信號、線性調頻(LFM)信號、非線性調頻(NLFM)信號、二相編碼(BPSK)信號、四相編碼(QPSK)信號、Frank信號、二相頻率編碼(BFSK)信號、四相頻率編碼(QFSK)信號、LFM-BPSK復合調制信號和BFSK-BPSK復合調制信號。
1.1 淺層時頻特征提取

圖2 輻射源信號時頻圖Fig.2 Time-frequency diagrams of emitter signal
圖2所示為輻射源信號STFT時頻圖,圖中時間索引值對應信號的不同時刻,且其單位間隔對應時間分辨率,頻率索引的單位間隔對應一個頻率分辨單元。時頻變換將一維信號投影至二維時頻域,具備更高的能量聚焦性和辨識度。此外,信號在時頻空間中占比較小,具備較好的稀疏性質。時頻信號直接作為特征輸入存在維度過高、信息冗余和噪聲干擾等問題,因此進行如下預處理:
2)構建濾波系數矩陣Fp×q,初始化為Fp×q=Qp×q.Fp×q=[f1,f2,…,fq]中列信號對應局部頻域維特征,具備稀疏性,逐列進行歸一化處理:
(1)
3)濾波系數優化。選取系數增強函數g(x)=x3,進行系數稀疏化表示:
(2)
式中:i∈[1,p];j∈[1,q];mean(·)為向量均值運算。

圖3所示為-5 dB時SCFM與NLFM信號預處理前后時頻圖對比,預處理較好地抑制了噪聲干擾,但特征維度仍然較大,進一步降維難以有效保留結構特征和細節特征,甚至引入了額外特征損失。因此字典分類模型同時考慮降維學習和字典學習。
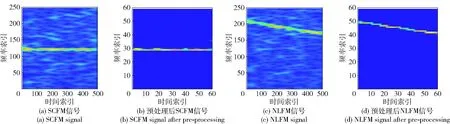
圖3 預處理前后時頻圖對比Fig.3 Comparison of time-frequency diagrams before and after pre-processing
1.2 JPDL理論


(3)
式中:y為測試樣本,y∈Rm;I為單位矩陣;T0為稀疏度;α為稀疏系數,α∈RK. 目標函數為Frobenius范數形式的重構誤差,約束條件包含稀疏度約束和投影正交約束。為保證凸優化性質,約束條件也常采用l1范數[19]和l2范數優化[9]形式。

(4)
式中:K(·)為核函數φ(·)的核矩陣表示,K(X,X)=φ(X)Tφ(X)為核Gram矩陣,K(X,X)∈RN×N;S=[α1,α2,…,αN]為稀疏系數矩陣。利用訓練樣本進行字典學習時,可分解為L類獨立問題進行聯合求解,即
(5)
式中:Si為第i類稀疏編碼。上述目標函數并非理想的聯合凸函數,因此采用分步迭代方式[20],固定其中部分變量,更新剩余變量,交替進行優化求解。具體計算流程如下:
1)初始化處理,選擇核主成分分析(KPCA)[13]方式得到偽隨機變換矩陣A;字典系數矩陣B中每列隨機一個元素置1,其余元素置0.
2)固定偽隨機變換矩陣A與字典系數矩陣B,通過字典學習得到稀疏編碼Si,采用正交匹配追蹤(OMP)[21]方式完成逐類優化更新。
3)固定偽隨機變換矩陣A與稀疏系數矩陣S,逐類更新字典系數Bi,對(5)式求導,可得
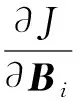
(6)

4)固定字典系數矩陣B和編碼系數矩陣S,更新偽隨機變換矩陣A,此時優化目標為

(7)
(7)式可等效為廣義特征分解問題,求解得出矩陣A由(I-BS)(I-BS)TK(X,X)Ta=μa的前n個最小特征向量構成,μ和a分別對應特征值、特征向量。
5)計算相鄰迭代誤差,當相鄰迭代誤差達到設定閾值或滿足最大迭代次數時終止,輸出偽隨機變換矩陣A與字典系數矩陣B;否則返回步驟2繼續迭代。
1.3 基于字典學習的分類識別
聯合投影字典通過核空間投影和降維投影學習獲取到冗余特征原子,其中包含豐富的二次特征。聯合投影方式能夠有效學習原子特征,進而降低各類信號重構誤差。進行分類測試時,采用子字典重構誤差進行分類判定,分類識別目標函數為
(8)
式中:si和ei分別為樣本y在第i類子字典上的編碼系數和分類誤差。因此樣本y的識別結果為
(9)
如圖1所示識別結構,具體訓練階段流程為:1)對時域信號進行STFT處理,得到二維淺層時頻特征信號;2)對信號進行時頻域降噪預處理,以增強特征辨識度;3)將二維時頻數據進行向量表示;4)聯合字典學習,利用各類訓練樣本數據對字典學習模型進行優化求解,得到偽隨機變換矩陣A與字典系數矩陣B.
測試階段流程為:1)STFT;2)預處理;3)向量化;4)特征降維及稀疏編碼,利用已有字典模型完成高維映射、特征降維和稀疏編碼;5)分類識別,利用(8)式計算重構誤差,識別結果為(9)式所得最小重構誤差類。
2 仿真實驗
2.1 參數設置
為驗證本文識別方法有效性,選取1.1節所述10類輻射源信號進行仿真實驗。充分考慮信號多樣性,選用隨機數據集模擬參數多變的復雜情況。所有信號頻段位于0~50 MHz范圍且載頻隨機變化,對應參數設置如下:SCFM、BPSK和QPSK信號載頻5~40 MHz;BPSK、BFSK和LFM-BPSK信號隨機采用7位、11位、13 位Barker碼;QFSK信號頻率編碼‘1,3,2,4,3,2,3,4,3,1,2’;QPSK信號相位編碼‘4,1,3,2,1,4,1,3,2,3,4’;LFM信號載頻5~25 MHz,帶寬5~20 MHz;NLFM信號載頻5~30 MHz,調制系數隨機取值5~10 MHz;Frank信號載頻10~30 MHz,相位調制階數隨機取值5~8;LFM-BPSK信號帶寬5~20 MHz;BFSK-BPSK信號頻率編碼隨機選取5位、7位Barker碼,相位編碼隨機選取11位、13位Barker碼。
測試環境如下:采樣頻率100 MHz,采樣時長5 μs,STFT長度為512,為保留細節特征時頻域降維參數p、q設為60. 在10~30 dB高信噪比(SNR)條件下隨機生成訓練樣本,每類信號200個樣本,數據集樣本個數為1 600;在SNR為-10~10 dB(步長2 dB)條件下隨機生成測試樣本,每個SNR下單類信號樣本為100,共計11 000個測試樣本。計算機配置為CPU i5-M480,內存6.00 GB ,數學仿真軟件MATLAB R2018b.

表1所示為降維參數對識別率影響,識別率隨著降維參數的增大而增大,且隨SNR增大平穩上升。當SNR為-8 dB時,保留100維數據進行特征表征仍能達到62.3%的識別率,可見降維學習使得低維數據具備較強特征表示能力;當SNR≥2 dB時識別率基本達到99%,維度對其影響減弱,綜合考慮選擇降維參數為300.

表1 不同降維參數對應識別率
基于稀疏表示的字典學習中,一般要求字典具備過完備性。圖4所示為300維特征下識別率隨字典原子數變化曲線,隨著原子數目增多,字典完備性越好,識別率越高。當原子數為20~40時,識別率相對較低,原因在于數據集受載頻等隨機性影響較大,且部分數據類間差異性較小,少量字典原子難以形成完備表示。當原子數大于80時效果較穩定,此時字典原子對數據隨機性和細微特征的全局表征能力較強。綜合考慮選取字典原子數為150.
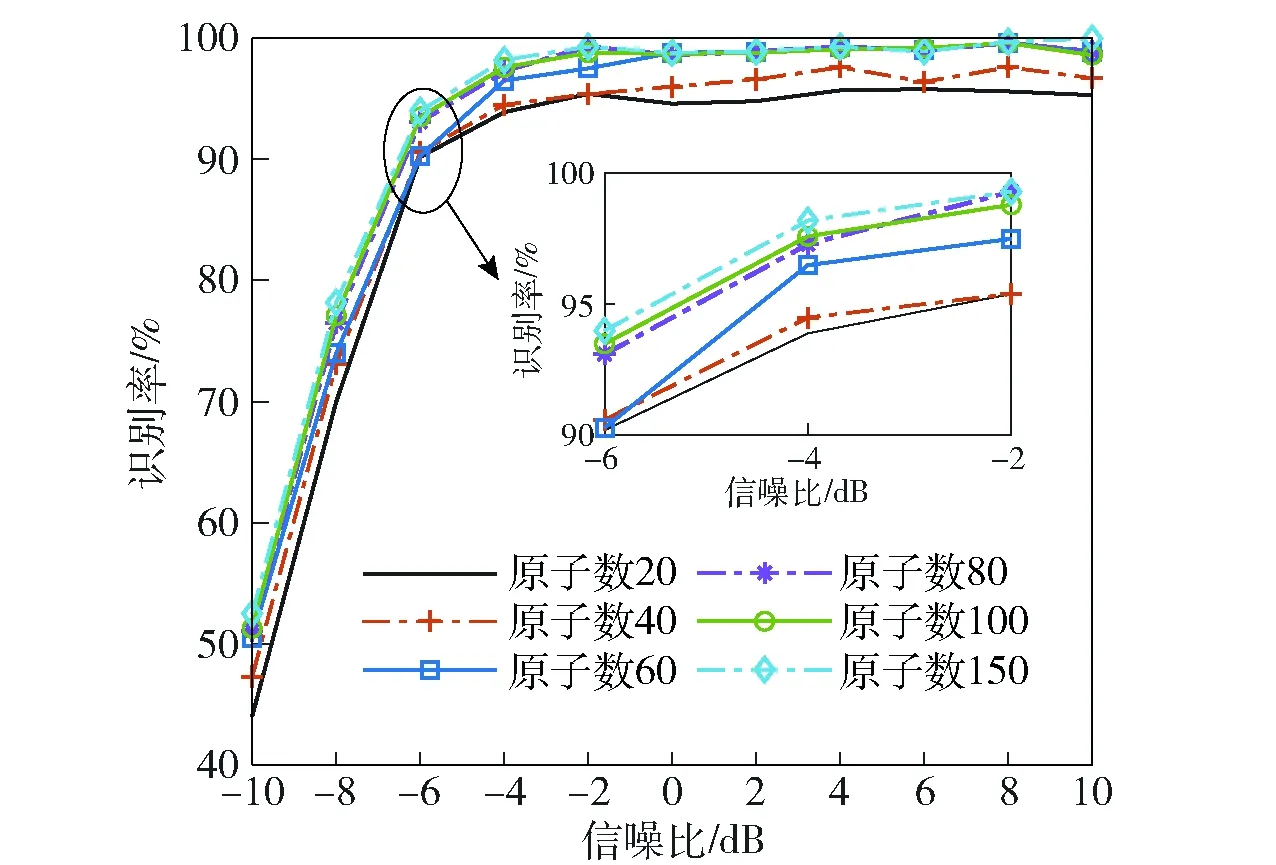
圖4 不同字典原子數下識別性能Fig.4 Recognition rates for different atom numbers
圖5所示為不同訓練集下識別率比較,字典原子在小樣本時與樣本數一致,樣本數大于150時字典原子選為150. 選擇SNR為{-10 dB,-6 dB,-2 dB}進行測試,結果表明樣本數據集越豐富識別效果越好。樣本數為40的訓練集整體平均識別率較低約為66.9%;當訓練樣本數為200時,數據所含隨機樣本較豐富,能夠為字典學習提供有效樣本支持。
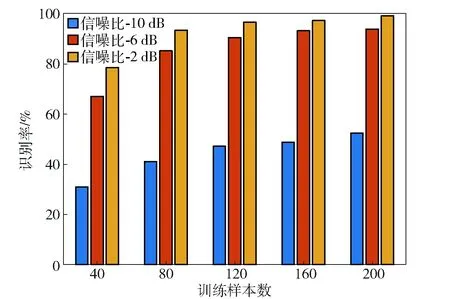
圖5 不同訓練樣本集下識別性能Fig.5 Recognition rates with different training sample sets
文獻[22]分析了小樣本數據集識別問題,但其背景為固定參數輻射源信號、種類較少且類間辨識度高,無隨機變化特征;文獻[15]選用5類輻射源信號進行識別,識別數據集隨機性和種類并不豐富,且類間差異較明顯,0 dB時平均識別率約為90%. 本文所用數據集參數隨機性較大,且部分數據類間相似度較高,加大了字典學習和原子表示難度,因此小樣本數據集下形成的字典完備性不足。
2.2 預處理前后性能對比

圖6 不同特征識別性能對比Fig.6 Recognition performance with different features
為定量分析預處理增益,選擇STFT處理后不降噪特征(記為STFT)與本文預處理后特征(記為DSTFT)在相同條件下進行訓練和識別,測試結果如圖6所示。預處理方式較好地抑制了噪聲干擾,能夠較好地保留信號時頻結構,提高了低SNR環境適應能力,SNR為-10 dB時性能增益約40.9%.
2.3 綜合識別性能對比
為驗證識別方法有效性,選擇FDDL[11,15]、LC-KSVD[12]和Kernel-KSVD[13]3類字典學習方式進行比較。為保證標準一致性,FDDL和LC-KSVD方式需在相同特征維度下進行學習,常規字典學習算法采用主成分分析(PCA)降維和隨機投影降維,其中隨機降維方式具備較大的隨機性,此處采用PCA降維處理后數據作為FDDL、LC-KSVD和Kernel-KSVD的數據集。所有識別方式統一參數為:迭代次數10次,字典原子數150,特征維度300. FDDL方式中兩項約束系數分別為0.
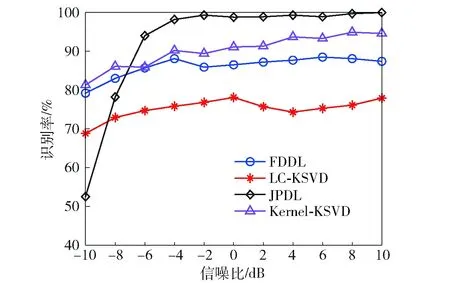
圖7 不同識別方式性能對比Fig.7 Performance comparison of different methods
005、0.05,采用l
1
范數優化方式
[23]
;LC-KSVD方式中稀疏度為12,稀疏編碼項約束系數為4,分類判別項約束系數為2;Kernel-KSVD方式核函數與JPDL方式一致。
測試結果如圖7所示,預處理使得識別性能均保持在50%以上。JPDL方式識別率在SNR為-10~-4 dB條件下快速遞增,在SNR為-4 dB時達到98.2%,隨后性能逐漸趨于穩定;FDDL、LC-KSVD和Kernel-KSVD方式識別效果相對較穩定,在SNR為-10~-8 dB環境下優于JPDL方式,但在SNR為-6~10 dB環境下識別性能較穩定且不及JPDL方式。
不同字典學習方式下各類輻射源信號識別結果如圖8所示。其中,FDDL和LC-KSVD方式識別效果相對穩定,但性能存在上限,對數據隨機性特征提取能力和高相似度信號辨識能力均存在一定局限性。FDDL方式對SCFM、QFSK、QPSK和Frank信號識別效果較好,較易混淆信號主要為LFM和NLFM信號。LC-KSVD方式受數據隨機性影響較大,所提取原子特征僅對QFSK、QPSK和Frank信號較有效,其余幾類信號原子相似度較高,誤分類概率較大。JPDL和Kernel-KSVD方式通過核映射一定程度改善了特征穩定性,較線性字典學習方式表現出一定優勢。JPDL方式在LFM、NLFM和BPSK 3類信號的識別上優勢更為明顯,但低SNR環境下性能略弱于其余3類方式。

圖8 不同識別方式下各類信號的識別結果Fig.8 Recognized results of various signals by different methods
綜合對比分析得出:1)JPDL方式的核空間映射和降維學習所獲取特征在低SNR條件下存在一定損失,隨SNR提升特征穩定性增強;2)FDDL和LC-KSVD方式能夠有效學習結構特征,對結構差異較大數據識別能力較強,結構特征經預處理后受噪聲影響不大,因此整體識別效果較平穩;3)數據隨機性和類別相似性加大了字典學習難度,識別曲線的波動主要由數據隨機性引起,隨機性起伏較大時,LC-KSVD和FDDL方式學習到的特征難以克服隨機性影響,FDDL方式對應的類心并不穩定;4)核字典學習方式在本文背景下更為有效,其中Kernel-KSVD方式僅包含字典學習,難以對高維數據形成更穩定的低維表征。而JPDL聯合學習方式能夠同時進行降維學習與字典學習,具備更強的針對性,且對多類型、相似度較高信號的判別能力較強,SNR大于-6 dB時整體性能較優。此外,JPDL方式還可針對不同應用選擇核空間樣式和降維參數,能夠有效避免高維數據樣本計算引入的“維數災難”。
表2所示為SNR -6 dB時JPDL方式識別的混淆矩陣,信號類型按圖2順序依次記為S1~S10. 其中:LFM與NLFM、LFM信號與LFM-BPSK信號相似度較高,存在2%~4%的混淆;SCFM、QPSK和BFSK-BPSK信號三者均與BPSK信號存在較大相似性,存在一定程度混淆;BFSK-BPSK和BFSK信號存在4%~7%的混淆;BPSK和BFSK-BPSK信號誤判概率相對較大。整體來看,平均識別率達到94.4%,原子特征具備較高辨識度。
表3給出了4種識別方式的計算復雜度,測試時間為單個樣本平均識別時間。其中:FDDL方式采用l1范數優化方式,訓練時間和測試時間均最長;LC-KSVD方式時間最優,但識別能力不足;Kernel-KSVD方式的訓練時效性介于JPDL方式和LC-KSVD方式之間,其測試時效性與JPDL方式相當。相比而言,JPDL方式能夠有效兼顧計算復雜度與識別精度。

表3 計算復雜度比較
3 結論
本文提出了一種基于JPDL的輻射源識別方法,時頻特征及預處理為字典學習提供初始字典集,JPDL考慮了高維核空間投影和降維投影,用于強化特征差異并降低數據冗余。仿真驗證了該方法的有效性,得出以下主要結論:
1)降噪預處理有助于改善低信噪比環境下的識別率。
2)JPDL方式所提取字典原子具備較強表征能力,能夠有效區分類間高相似度信號。
3)JPDL方式能夠有效適應高維數據樣本,通過降維學習形式降低計算開銷。
4)在輻射源調制識別背景下,JPDL方式能夠兼顧識別準確性和時效性,綜合性能較FDDL、LC-KSVD、Kernel-KSVD方式更優。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年3期)2019-02-01 06:12:26
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
