數據驅動下公共圖書館用戶信息服務閉環系統研究
2020-08-11 01:53:46郭春淼
圖書館研究與工作 2020年8期
顧 婷 郭春淼
(云南大學歷史與檔案學院 云南昆明 650091 )
1 引言
2015年9月,國務院印發的《促進大數據發展行動綱要》中提出,“大數據”已經上升為國家級的發展戰略。經過四年的發展,大數據已逐漸向各行各業、各個領域延伸,云計算、人工智能、區塊鏈、5G等新技術的發展也與大數據密不可分,共同改變了人類生活的各個領域。2018年4月,工信部總工程師張峰指出,目前,全球大數據進入到加速發展時期,數據總量逐年增長50%。Jim Gray博士[1]談到,目前我們正步入數據密集型的第四范式,關于大數據驅動的研究主要是面向個體化、全樣本的發現和預測研究。2018年米加寧等人[2]認為,“大數據”作為第四研究范式,破除了傳統社會科學目標弱化、學科學派對立、數據質量良莠不齊和統計偏誤的四大局限性,給現今的社會科學研究奠定了更高的數據起點和更廣闊的方法論。
數據驅動是指通過移動互聯網或者其他的相關軟件為手段采集海量的數據,將數據進行組織,在形成信息以后,對有用的信息進行整合和凝練,在數據的基礎上經過訓練和擬合形成自動化的決策模型。換言之,數據驅動是由數據激發信息的過程或活動,不是僅憑直覺或個人經驗形成信息的簡單范式。數據驅動包括三個特征:海量的數據、自動化的業務和強大的模型支持自動化決策。
雖然關于數據驅動下圖書館的研究已成為近年來圖情領域的研究熱點之一,甚至有些圖書館宣稱已經實現了數據驅動,但是大部分的圖書館只是以數據為中心進行決策,并非真正地實現了圖書館的數據驅動。
2 文獻綜述
2.1 數據驅動的研究
2013年,田野、祝忠明[3]提出了一種關聯數據驅動的數字圖書推薦模型,給用戶提供了跨數據源的信息推薦服務。首先,將圖書館的內部數據和外部相關的關聯數據相結合,再根據圖書館信息資源各自的特征,構建出用戶社會關系和數字圖書兩大語義本體知識庫;其次,時時觀察用戶對圖書瀏覽的頻率和頻次,針對不同的用戶采取不同的推薦手段,最終實現用戶推薦服務的全方位覆蓋。
2018年,洪亮等人[4]以大數據驅動為主要視角, 以圖書館的業務流程為導向,提供了圖書館智慧信息服務體系建構的思路,構建出大數據驅動下圖書館智慧信息服務體系。
2019年,曹樹金等人[5]談到,圖書館大數據系統的構建結構包括:多來源的數據采集層、數據預處理與存儲層、精準化的數據分析建模層和支持精準化的管理與服務的應用層等自下而上的四個層次,以求為讀者提供精準化的服務。同年,杭哲、李芙蓉[6]在基于關聯數據技術建構參考咨詢服務新模式的基礎上,通過關聯數據來實現圖書館信息資源的精準化、結構化以及關聯化的數據整合, 優化已有模式中的各個環節,增加統計分析模塊,用以改善虛擬的咨詢服務方式,提高圖書館參考咨詢的服務質量。
2.2 公共圖書館的研究
2008年,王學熙[7]對我國公共圖書館服務體系的基本特征和現狀進行了分析,提出公共圖書館具有形態性、公益性和社會性等特征,闡述了五種不同的公共圖書館服務體系建設模式。
2012年,李巖等人[8],從需求導向的角度出發,在了解和分析信息需求、服務要素以及服務方式的基礎上,構建出框架結構全面地描述和提出健康信息服務多元化服務模式,為我國公共圖書館共享現有的服務經驗與成果、加強和規劃未來的服務提供參考。
2016年,王敏[9]將大數據與小數據進行對比,研究了小數據思維在公共圖書館信息服務上應用的重要性,從小數據的服務原則、服務流程和服務措施三個方面,提出了公共圖書館信息的服務模式。
綜上所述,雖然數據驅動下公共圖書館的研究已經有了一定成果,但當前大多數的公共圖書館即使在服務模式和服務創新等方面展開了非常深入的嘗試,也提出了數據驅動圖書館系統模型的構建,但仍然存在一定的問題。本文在發現和分析問題的基礎上,為公共圖書館數據驅動下的信息服務發展提出相應的解決措施。
3 數據驅動下公共圖書館用戶信息服務問題
3.1 數據孤島化問題
在大數據時代,以大量數據為基礎的現代化圖書館會比傳統圖書館更為科學、高效[10]。但是研究發現,數據孤島化問題一直是圖書館實現數據驅動的最大難題,這一難題使得公共圖書館的“數據驅動”變為空談。
首先是數據擁有者之間存在孤島化問題。大數據時代的到來,使得其在各個學科領域形成了全方位滲透,學科間跨界融合不斷加深,用戶所求的信息服務往往需要跨學科的數據,但是由于商業領域信息不對稱性帶來的巨大經濟效益,政府領域數據存在較大的安全隱患,科研領域數據往往分散在各個研究者的手中,所以大量數據仍然集中在政府、互聯網企業、數據商和各個科研機構手中。近年來,全國各級政府貫徹執行國務院頒布的《促進大數據發展行動綱要》,初步搭建了各級政府的大數據平臺系統,但是在商業、數據商、個人數據等方面,由于缺乏統一的共享機制,導致這些數據擁有者之間形成一個個“數據孤島”,在采集數據方面有一定的難度。就公共圖書館而言,各個省市公共圖書館大多仍是獨立采購資源,獨立管理資源,獨立提供信息檢索服務。
其次是數據系統處理流程存在孤島化問題。由于數據系統在環節間沒有形成自動化對接、數據跨系統且圖書館員缺位的情況下,環節與環節之間存在不同的斷裂處。當一個環節結束或出錯,該系統便失去了對流程的掌控,導致圖書館無法為用戶提供更好的數據服務。目前而言,雖然在大數據利用方面,圖書館標榜以用戶為中心,以數據為驅動,但大多數圖書館尤其是公共圖書館尚未形成數據驅動的閉環,仍需要人力的操縱和決策,而且數據決策難免會摻雜個人意志;只要用戶信息服務系統在某一環節的節點缺位和失誤,數據流程就會產生斷裂或錯誤的風險,這對公共圖書館產生的大量數據無疑是一種資源浪費。
3.2 數據使用問題
傳統的數據庫是利用單個服務器來實現儲存和處理信息的需求,但是當數據量增大時,一臺服務器無法滿足信息處理的需求,這就需要增加更多的服務器,然而隨著近年來數據急劇增加、分區復雜化、服務器的故障率和服務器費用提高,無形中給公共圖書館的數據信息服務造成極大的壓力。海量數據不僅考驗著公共圖書館如何進行儲存,還考驗著圖書館如何對數據進行高效、快速、實時的處理。當今社會,數據量龐大、分布廣、格式多、真假混雜,且每時每刻都在急速增加。在數據驅動的背景下,公共圖書館亟需使用更先進的技術方法來進行數據管理。滿足上述需求的數據庫不僅需要巨大的儲存空間、較低的費用,還要能夠高效地進行數據處理、分析以及提供相應的數據服務。這些需求已經遠遠超出用來處理結構化、關系型數據的傳統數據庫能夠處理的范圍。
3.3 系統無法收集有效反饋數據問題
根據專家學者在數據驅動方面的研究[11],構建的公共圖書館的大數據體系框架,大致分為四個層次:數據采集層→數據處理和集成層→數據建模和分析層→數據服務層→用戶(如圖1所示)。但是由于這個系統缺少數據反饋層,使得系統無法收集反饋數據,從而無法自動進行系統的評估并進行系統優化和迭代升級。新的情況和需求發生時,僅僅依靠圖書館員的個人經驗來處理,造成信息資源使用完畢后無法對未來的使用提供有用數據。用戶為什么使用該信息資源、使用時做了什么操作、是否解決了問題、使用該資源的用戶群體有無類似條件、能否為后來使用者提供借鑒等等,這些都是可以供系統優化、提高服務的寶貴的數據。因此,就需要一個不僅能對數據進行實時采集,對數據進行自動處理、分析和輸出使用,還要對系統進行評估和反饋、對分析方法和模型進行優化的系統(如圖2所示)。
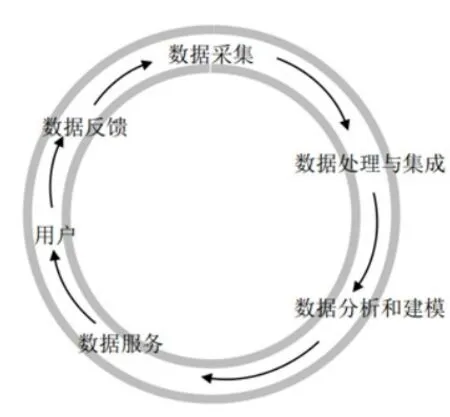
圖2 持續不斷的數據驅動閉環系統
基于數據驅動閉環系統,筆者刻畫出具體的數據驅動圖書館系統處理流程(如圖3所示)。公共圖書館通過對線上、線下及第三方數據進行采集,將采集到的數據進行處理與集成之后,建立相應的用戶標簽和數據模型,對數據進行可視化分析,可視化分析結果提供給用戶形成圖書館的數據服務,用戶又將數據反饋給圖書館,形成一個良性的閉環結構。
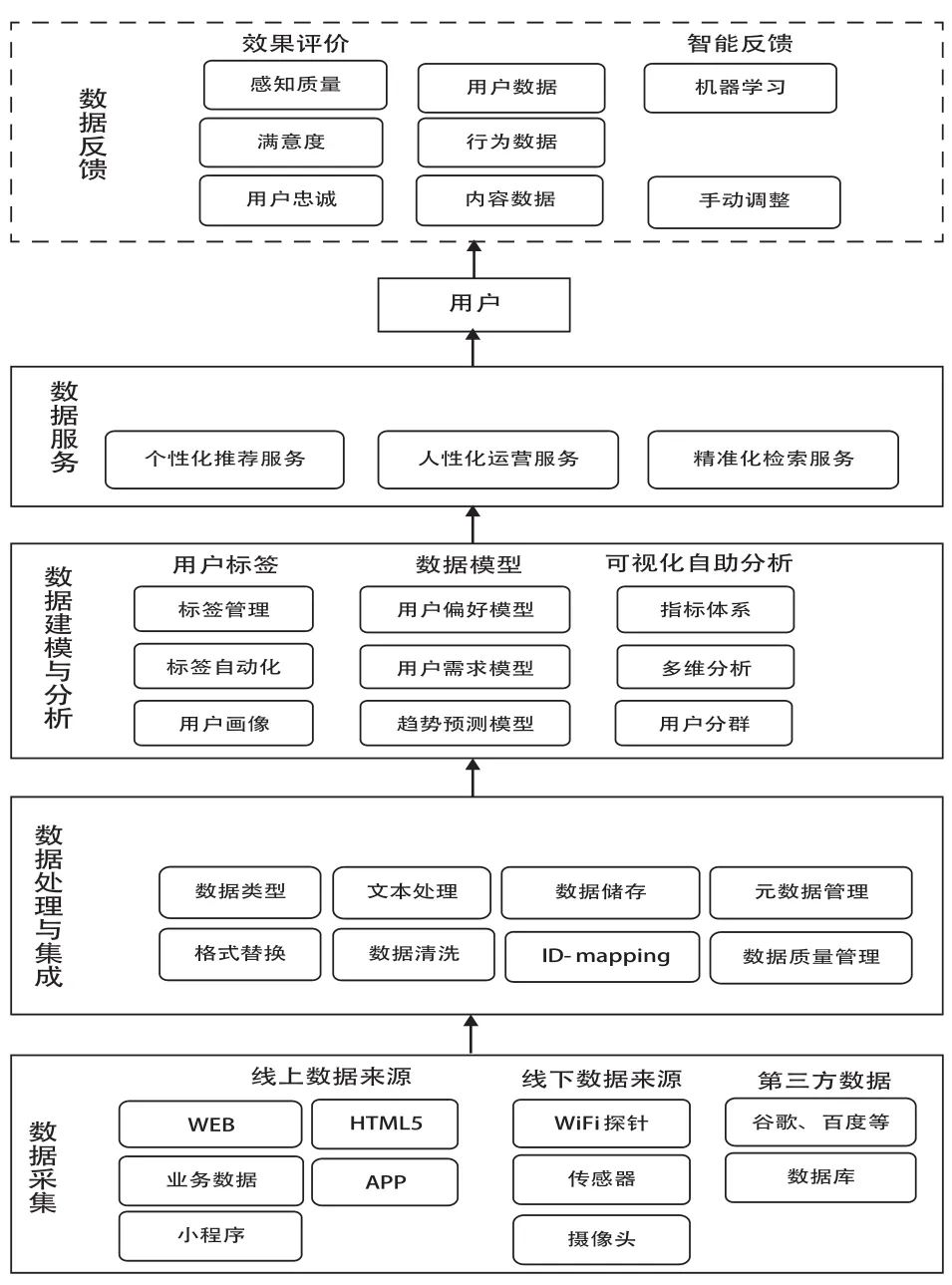
圖3 數據驅動圖書館系統處理流程
4 數據驅動下提高公共圖書館用戶信息服務水平的策略
4.1 積極響應和協助建設大數據共享平臺
2017年8月,文化部印發的《“十三五”時期公共數字文化建設規劃》中提出,要大力推動全國文化信息資源共享工程的進程。在政府的大力支持下,公共圖書館應該牢牢抓住機遇,積極投身于信息資源的共享工程中去。各級公共圖書館首先應當進行數據資源整合,打破公共圖書館之間的數據界限,與政府合作,研究出統一的框架。其次,要將公共圖書館獨立采購、獨立管理、獨立服務的模式改為由統一的數據格式、技術標準組成的數據共享平臺,并且能夠接入政府信息資源共享系統,激勵和引導各類數據持有者加入信息資源共享平臺。再次,要對數據進行融合,通過數據清洗、噪點消除、缺點補充等技術處理,生成ID儲存于統一的數據資源中心。最后,由于數據資源中心里涉及到國際、企業、機構和個人的信息安全和隱私,所以在對數據共享、開發時,應制定嚴格的制度管理規定,對數據設立安全等級,對數據的管理和使用形成規范化管理,尤其是對USB、打印設備等外接設備,要防止數據感染和泄露。
公共圖書館是獨立于數據利益相關者外的第三方機構,所以對數據應承擔監管者的角色,對數據的歸屬提供證明,保護數據提供者的權益。公共圖書館還應定期召開數據共享技術大會,邀請各類館員和專家學者探討新技術、新成果和發展建議,為數據共享平臺建言獻策,從而解決公共圖書館存在的數據孤島問題。
4.2 采用分布式文件系統
Hadoop框架是一個能夠對海量數據信息進行分布式處理的軟件框架,形成了擴充力強、成本低廉、效率高以及可靠性強等特點,目前已成為許多大型公司、科研機構等用于處理大數據的主流工具。Hadoop以HDFS(儲存)和MapReduce(計算)為核心。其中,HDFS可以協同多臺服務器共同實現海量數據存儲的目標。而MapReduce則是對離線大數據進行處理,它的計算過程被封裝得很好,用戶只需使用簡單的map和reduce函數就可以對數據信息加以處理,將數據集的大規模操作分發給網絡上的各個節點,每個節點進行周期性的工作反饋,直到任務結束,由此實現數據處理的可靠性。通過使用Hadoop框架,公共圖書館就能解決數據驅動背景下產生的數據使用問題,對公共圖書館的數據信息進行有效存儲和處理,打通數據使用的各個環節,提高公共圖書館數據信息的利用效率,提高公共圖書館的用戶服務水平。
4.3 構建數據反饋層
數據反饋是實現公共圖書館數據信息系統閉環的關鍵部分。數據驅動環境下,傳統的解析方法不足以滿足數據反饋的需求。因此,在系統面向用戶的服務結束之后,對系統使用效果構建評估優化模型就顯得至關重要。本文設計了公共圖書館基于分群標簽閉環系統的反饋系統(如圖4所示)。
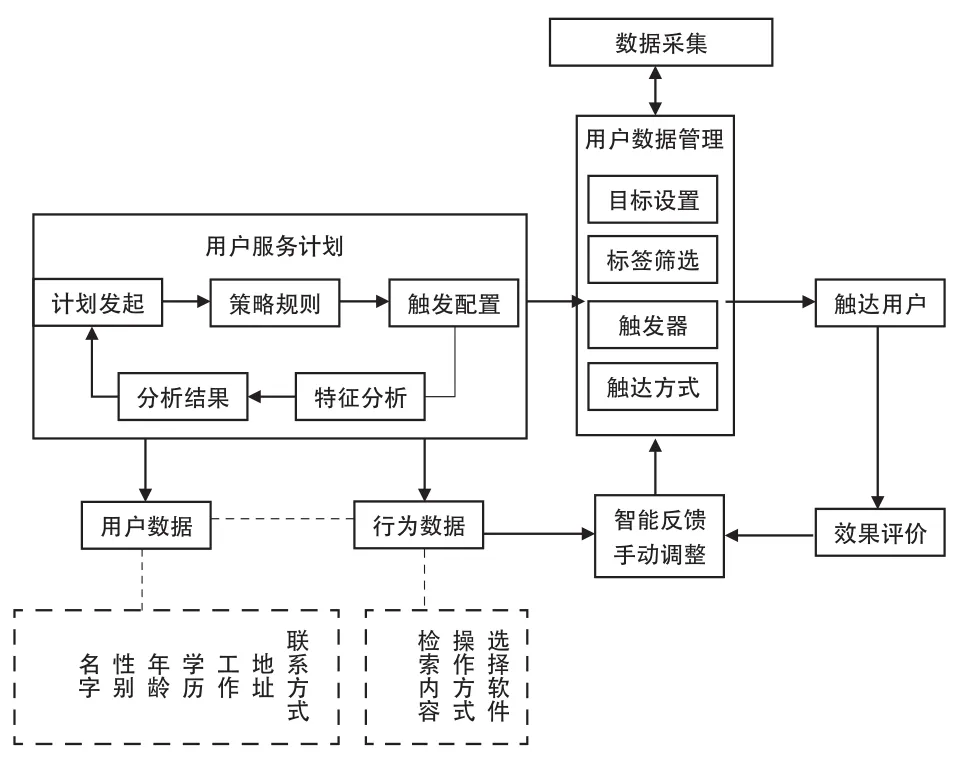
圖4 數據反饋層模型框架
閉環(閉環結構),也稱為“反饋控制系統”,是把系統輸出量的測量值與其期望的給定值做比較,從而產生的偏差信號,通過調節控制此偏差信號,讓輸出值無限趨近于期望值。在公共圖書館信息服務閉環中,該系統將自動收集公共圖書館的各項數據,按照數據模型進行分析處理,服務于用戶,然后收集反饋數據,對新的數據進行自動分析,圖書館員只需對現有數據和期望數據進行比較,調整偏差使之接近與符合期望值,形成一個閉環。數據驅動只有在實現閉環的情況下才能更好地完成數據的自動流通,將大數據融合進圖書館信息服務系統的全流程并形成閉環,不僅將圖書館員從海量的數據中解放出來,也解決了信息服務周期長、效率低的問題,提高了圖書館信息服務的水平。
(1)用戶服務。首先根據公共圖書館已有的信息屬性,將信息按屬性進行分類,構建信息特征矩陣,其后根據用戶注冊的信息以及歷史行為數據,建構出用戶目標矩陣,再針對用戶目標矩陣,生成相應的向量以及向量距離近的相鄰用戶,用當前用戶目標矩陣和相鄰用戶的目標信息進行對比,融合后形成新的用戶服務矩陣,構建用戶畫像。根據用戶畫像制定特殊的信息服務,然后將數據挖掘的結果通過直方圖、詞云圖和關系圖譜等進行可視化展示,得出結果后加入用戶的數據信息反饋,并根據用戶的數據信息反饋做出系統改進和優化。
(2)效果評價。ASCI美國顧客滿意度指數模型具有模型設計簡潔、顧客滿意界定和表示變量設計合理的優點。本文在借鑒ASCI的基礎上,構建了公共圖書館信息服務用戶的滿意模型(如圖5所示),設立了用戶期望、感知質量、用戶滿意度、用戶抱怨以及用戶忠誠五個變量。
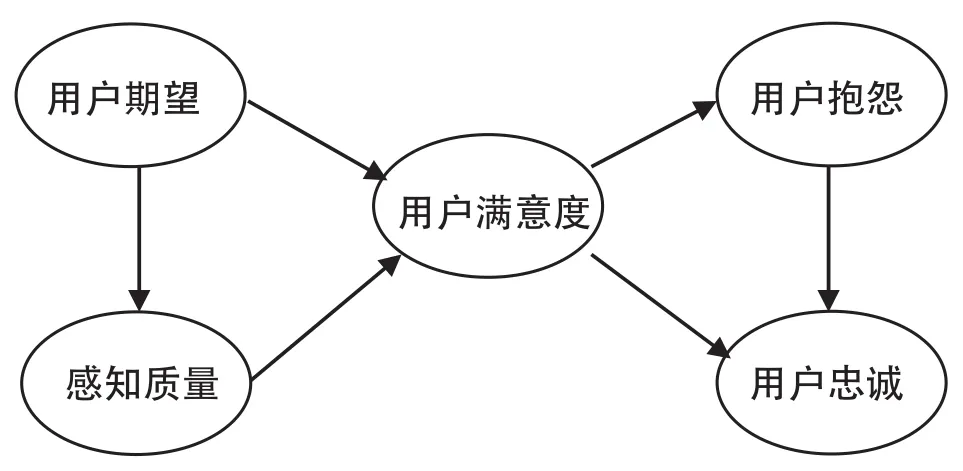
圖5 公共圖書館信息服務用戶滿意度模型
(3)智能反饋。平均絕對誤差(Mean Absolute Error,MAE)是推薦算法領域常用的評價,用它作為評價標準,將所有單個信息服務預測評分和用戶真實評分做差,求出差的絕對值的平均。平均絕對差可以避免誤差相互抵消,用來反映算法的合理性。根據服務評價、用戶數據和行為數據是否滿足期望值,進行算法和數據用戶優化,得到反饋數據,然后將反饋數據發送給數據采集環節。
當用戶使用系統時,根據用戶信息和歷史行為按策略規則構成用戶服務矩陣生成觸發配置;不同的觸發配置在觸發器中有不同的觸發方式,根據觸發條件的方式進行標簽篩選,并根據標簽提供相應的信息服務,比如個性化推薦、需求猜測等服務;服務完成之后,系統彈出服務評價界面,通過設置的選項和留言收集用戶評價,自動分析觸發效果,智能反饋到用戶服務系統進行算法優化和數據存儲,工作人員也可以根據期望進行手動調節,形成自動化、精細化的公共圖書館用戶信息服務閉環。
5 結語
數據驅動環境下,數據密集型范式改變了傳統研究方法,也推動了圖書情報領域的方法論變革。在數據信息日益密集的情況下,給用戶提供效率高、精準化、服務優的信息服務系統也越來越重要。本文通過總結圖書館在大數據環境下的系統處理流程研究的基礎上,指出了系統處理流程存在的不足之處,提出了公共圖書館信息服務閉環系統的概念,分析了系統實現的條件和系統的構建思路,從而提高公共圖書館的用戶信息服務水平和質量。
猜你喜歡
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小太陽畫報(2018年1期)2018-05-14 17:19:25
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
