基于網(wǎng)格和密度比的DBSCAN聚類(lèi)算法研究*
2020-08-11 00:46:20徐紅艷黃法欣王嶸冰
計(jì)算機(jī)與數(shù)字工程 2020年6期
徐紅艷 普 蓉 黃法欣 王嶸冰
(遼寧大學(xué)信息學(xué)院 沈陽(yáng) 110036)
1 引言
隨著大數(shù)據(jù)時(shí)代的到來(lái),數(shù)據(jù)量的不斷膨脹,如何有效地分析這些海量數(shù)據(jù)已經(jīng)成為了目前研究的熱點(diǎn)和難點(diǎn)。聚類(lèi)分析能夠有效地從海量數(shù)據(jù)中提取出有效信息[1],DBSCAN 算法(Density-Based Spatial Clustering of Application with Noise)就是經(jīng)典的基于密度的聚類(lèi)分析方法[2]。此算法能在含有噪聲的數(shù)據(jù)中識(shí)別出任意形狀的簇,能夠有效地識(shí)別出異常點(diǎn),因而在文本分類(lèi)[3]、社區(qū)發(fā)現(xiàn)[4]、垃圾郵件識(shí)別[5]等領(lǐng)域都得到廣泛的應(yīng)用。
DBSCAN算法具有很多優(yōu)點(diǎn),但也存在著難以發(fā)現(xiàn)密度相差較大的簇的缺點(diǎn)。眾多學(xué)者對(duì)該算法進(jìn)行了深入的研究和改進(jìn):Kai[6]等提出一種基于可變類(lèi)簇的密度比聚類(lèi)算法,使得當(dāng)類(lèi)簇間密度差相差較大時(shí),能夠使用單一的閾值就能夠達(dá)到比較理想的聚類(lèi)效果。然而該聚類(lèi)算法需要手動(dòng)輸入的參數(shù)過(guò)多,輸入?yún)?shù)對(duì)聚類(lèi)結(jié)果影響較大。Rodriguez[7]等提出DPC聚類(lèi)算法,它是一種依據(jù)快速搜索與密度峰值共同研究發(fā)現(xiàn)的,該聚類(lèi)算法能夠有效地檢測(cè)出任意一種形狀的簇,但該算法需要計(jì)算局部密度和數(shù)據(jù)點(diǎn)之間的相對(duì)距離,計(jì)算量較大。馮振華[8]等提出了一種貪心的DBSCAN改進(jìn)聚類(lèi)算法名為greedy DBSCAN,采用貪心策略自適應(yīng)地尋找Eps半徑參數(shù)進(jìn)行類(lèi)簇發(fā)現(xiàn),但該算法需要手動(dòng)輸入密度閾值,且聚類(lèi)效率還有待提高。蔡穎琨[9]等提出了一種能夠屏蔽參數(shù)敏感性的DBSCAN改進(jìn)聚類(lèi)算法,通過(guò)考察類(lèi)簇間的連接信息并記錄、分析這些連接信息,從而達(dá)到屏蔽鄰域半徑參數(shù)Eps敏感的目的,不過(guò)該算法未能解決參數(shù)Eps自適應(yīng)確認(rèn)的問(wèn)題。
針對(duì)上述問(wèn)題,本文提出了基于網(wǎng)格和密度比的DBSCAN聚類(lèi)算法,它根據(jù)網(wǎng)格和密度比來(lái)解決實(shí)際問(wèn)題。此算法使用網(wǎng)格劃分的技術(shù)將數(shù)據(jù)空間進(jìn)行粒化,快速找到數(shù)據(jù)點(diǎn)密度值的“峰值”和“低谷”,以確定合適的密度閾值,以糾正由于輸入密度閾值τ不當(dāng)造成聚類(lèi)結(jié)果不佳的問(wèn)題;最后對(duì)粒化后的數(shù)據(jù)空間進(jìn)行密度比聚類(lèi)。
2 相關(guān)研究
2.1 DBSCAN算法
DBSCAN算法的主要思想是:給定一個(gè)未被聚類(lèi)的點(diǎn),如果它Eps鄰域內(nèi)的密度閾值不小于MinPts,則這個(gè)點(diǎn)是核心點(diǎn)。再考察它鄰域內(nèi)的其他點(diǎn),以同樣的方式判斷其是什么點(diǎn),一直到所有的點(diǎn)被遍歷到。由于該方法只對(duì)核心對(duì)象的鄰域密度進(jìn)行擴(kuò)展,因此對(duì)于那些形態(tài)不是很規(guī)則的簇,該算法的聚類(lèi)效果較好。
盡管此算法具有能夠有效識(shí)別噪聲點(diǎn),并且能夠識(shí)別任意形狀的簇,且聚類(lèi)結(jié)果幾乎不依賴(lài)于遍歷順序的優(yōu)點(diǎn)[10]。但是它也存在較為明顯的缺點(diǎn):難以發(fā)現(xiàn)密度相差較大的簇。由于參數(shù)Eps和MinPts是全局唯一的,所以DBSCAN算法只能發(fā)現(xiàn)密度近似的簇。此外,如果類(lèi)間距離差別比較大,算法結(jié)果也會(huì)產(chǎn)生影響,容易產(chǎn)生偏差。
2.2 基于網(wǎng)格的聚類(lèi)算法
這種聚類(lèi)算法的工作原理是對(duì)數(shù)據(jù)空間進(jìn)行粒化,具體的操作是將數(shù)據(jù)空間進(jìn)行劃分并分割為有限個(gè)網(wǎng)格子單元,由此形成網(wǎng)格結(jié)構(gòu),在該網(wǎng)格結(jié)構(gòu)的基礎(chǔ)上進(jìn)行數(shù)據(jù)分析[11]。該聚類(lèi)算法只是和網(wǎng)格劃分出的個(gè)數(shù)有關(guān),而與運(yùn)行時(shí)的時(shí)間復(fù)雜度和數(shù)據(jù)點(diǎn)的個(gè)數(shù)無(wú)關(guān)。STING算法[12]是一種基于網(wǎng)格的多分辨率的聚類(lèi)技術(shù),基于網(wǎng)格的聚類(lèi)方法對(duì)數(shù)據(jù)輸入順序不敏感,可擴(kuò)展性也較強(qiáng)。
與其他聚類(lèi)算法相比,STING算法有如下優(yōu)點(diǎn):
1)查詢操作和基于網(wǎng)格劃分的計(jì)算是相互獨(dú)立的,因?yàn)橛?jì)算所需的信息只依賴(lài)于相互在每個(gè)單元中的統(tǒng)計(jì)信息,而不依賴(lài)于查詢。
2)STING算法在網(wǎng)格結(jié)構(gòu)上也優(yōu)于其他的聚類(lèi)算法,尤其是在動(dòng)態(tài)更新和處理并發(fā)進(jìn)程的方面;
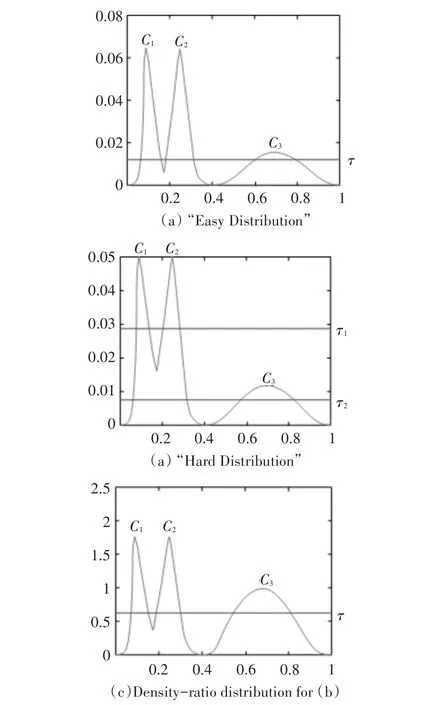
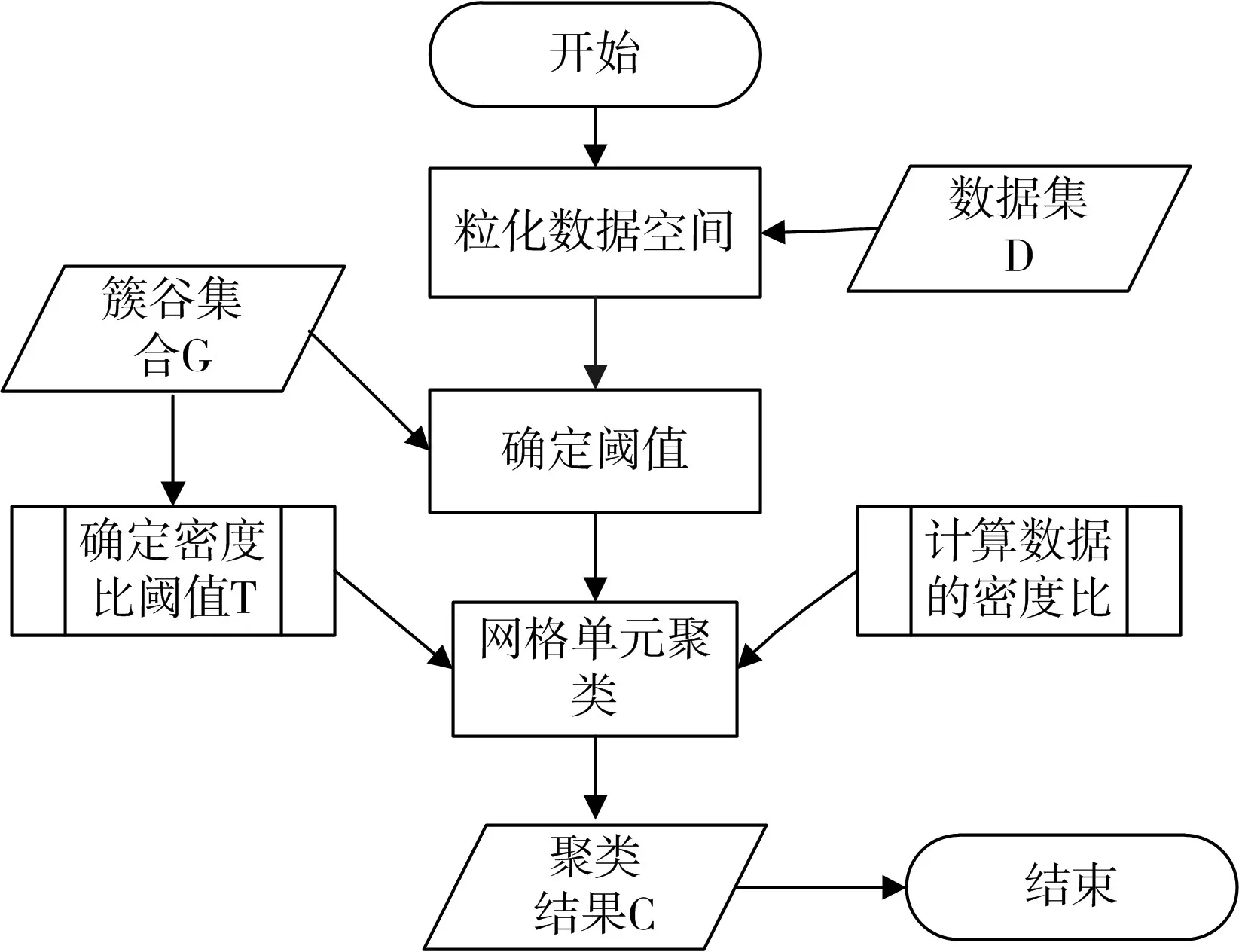
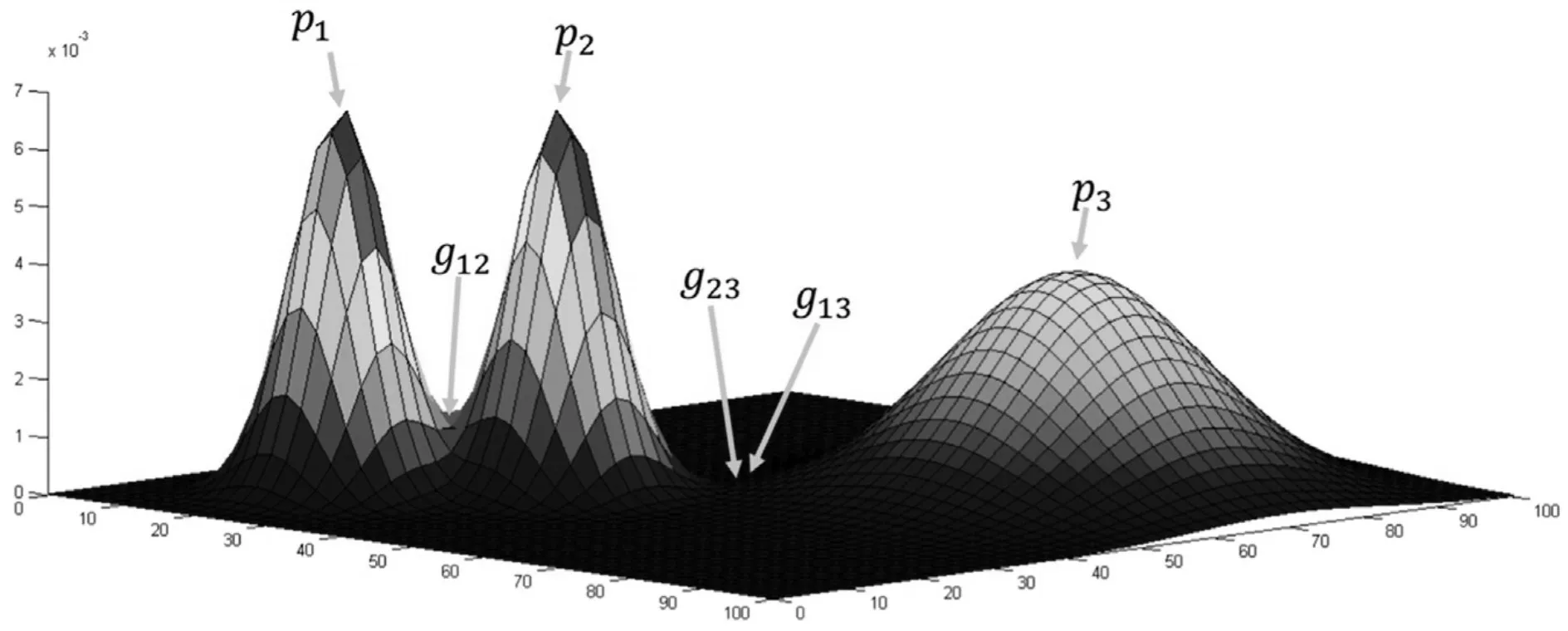
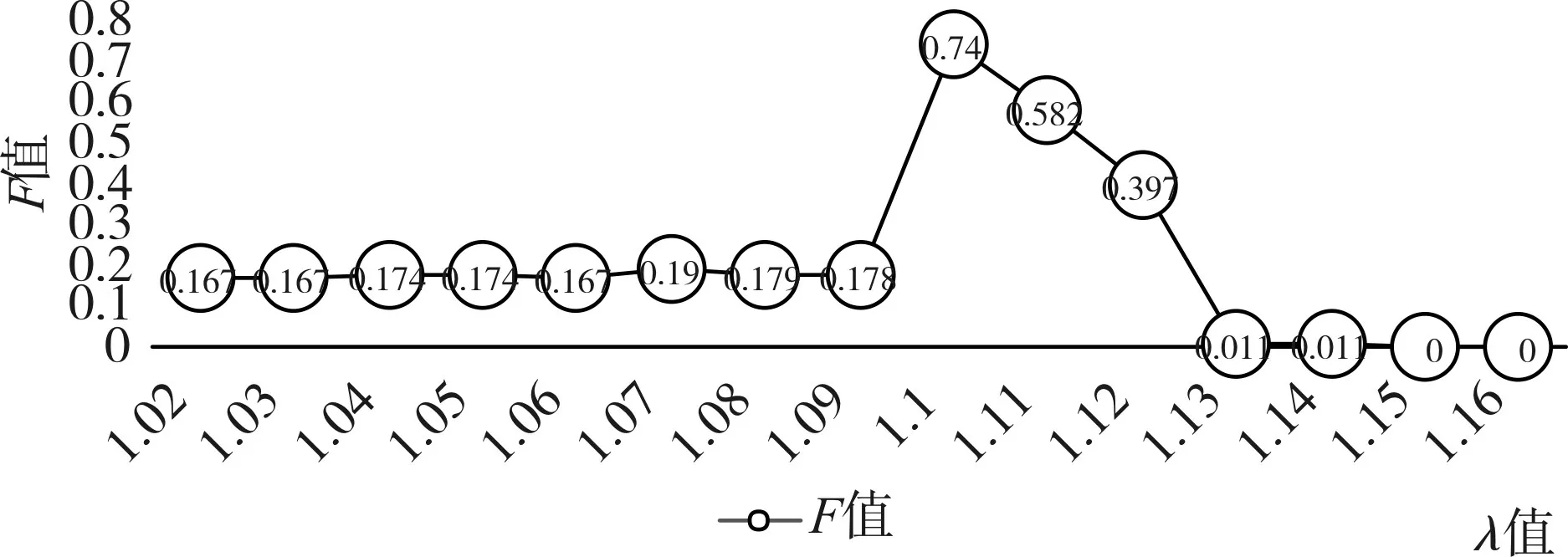
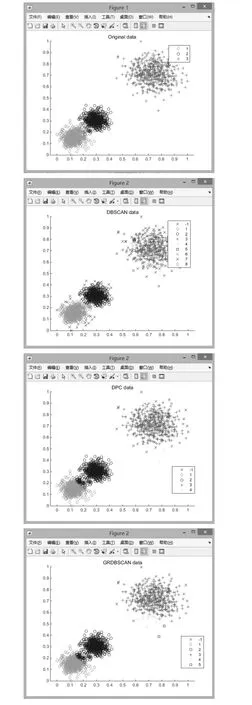
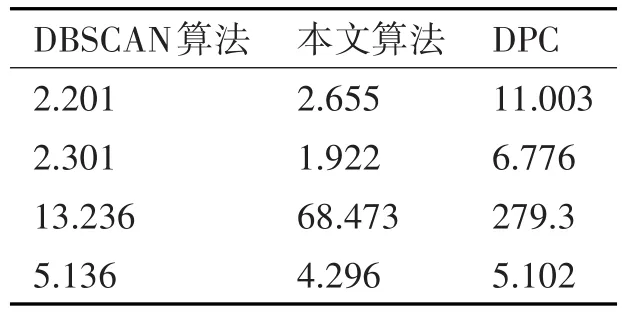
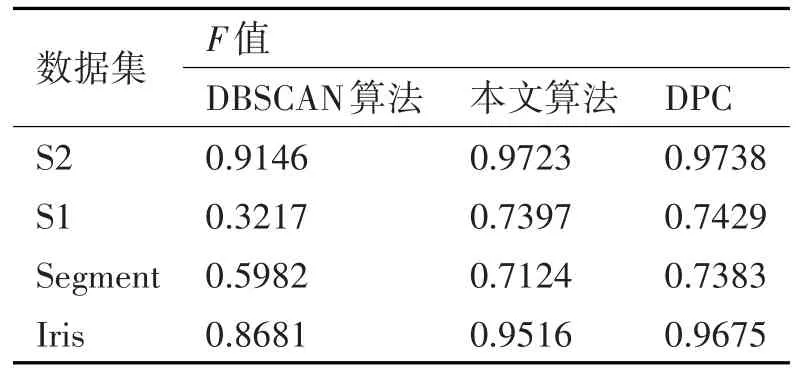
3)STING算法的效率與其他聚類(lèi)算法相比也有了很大程度的提高,使用該算法只需對(duì)數(shù)據(jù)庫(kù)的單元進(jìn)行一次掃描就可以通過(guò)計(jì)算得到相應(yīng)的信息,因此聚類(lèi)的時(shí)間復(fù)雜度是O(n)(n為數(shù)據(jù)對(duì)象的個(gè)數(shù))。在層次結(jié)構(gòu)建立后時(shí)間復(fù)雜度可表示為O(g)(g是最低層網(wǎng)格單元的數(shù)目,g< 此算法也存在下面的不足: 1)STING算法進(jìn)行聚類(lèi)分析時(shí)使用的是多分辨率分析的方法,使用STING算法時(shí)聚類(lèi)結(jié)果的質(zhì)量是由所劃分層次結(jié)構(gòu)的底層粒度來(lái)決定的。若它太細(xì),則會(huì)使聚類(lèi)的處理難度加大,采用STING算法的優(yōu)勢(shì)將無(wú)法充分發(fā)揮;若底層粒度太粗,則聚類(lèi)質(zhì)量會(huì)大打折扣。 2)此算法在父親單元的構(gòu)造上忽略了其孩子單元和其相鄰單元之間的關(guān)系,會(huì)造成簇的邊界不是水平的就是豎直的,不包含斜向的分界線。 3)盡管在選取合適聚類(lèi)粒度的情況下,STING算法能夠快速對(duì)數(shù)據(jù)集進(jìn)行聚類(lèi)處理,但是會(huì)在一定程度上犧牲聚類(lèi)的準(zhǔn)確度。 為了避免DBSCAN算法將低密度簇中的數(shù)據(jù)點(diǎn)錯(cuò)誤地歸類(lèi)為噪聲點(diǎn),Recon-DBSCAN聚類(lèi)算法[13]將密度比估計(jì)代替密度估計(jì),其數(shù)據(jù)點(diǎn)的密度是該點(diǎn)的密度相對(duì)于鄰域平均密度進(jìn)行歸一化處理后的值。類(lèi)簇實(shí)際為被低密度區(qū)域分隔開(kāi)的局部高密度區(qū)域,Recon-DBSCAN算法使得高密度簇通過(guò)歸一化后變?yōu)槊芏容^低的簇,且低密度簇通過(guò)歸一化后也變?yōu)槊芏容^高的簇,歸一化后的數(shù)據(jù)能夠被全局閾值τ區(qū)分開(kāi)來(lái)。 圖1(a)僅用DBSCAN單一閾值就能夠?qū)⑷齻€(gè)簇進(jìn)行區(qū)分;圖1(b)中的情形利用傳統(tǒng)的DBSCAN聚類(lèi)算法使用單一閾值無(wú)法將所有類(lèi)簇區(qū)分開(kāi)來(lái),若取閾值τ1則簇C3中的所有點(diǎn)都被歸為噪聲點(diǎn);若取閾值為τ2則簇C1和C2將會(huì)歸為同一個(gè)簇;圖1(c)所示為用密度比估計(jì)替換DBSCAN算法中的密度估計(jì),通過(guò)對(duì)數(shù)據(jù)點(diǎn)的密度進(jìn)行歸一化處理,使得可用單一的全局閾值對(duì)所有簇進(jìn)行有效區(qū)分。 Recon-DBSCAN聚類(lèi)算法采用數(shù)據(jù)點(diǎn)的密度比估計(jì)替換該點(diǎn)的密度估計(jì),然后再對(duì)數(shù)據(jù)集進(jìn)行聚類(lèi),從而使低密度集群不被DBSCAN算法錯(cuò)誤地歸于噪聲點(diǎn)。但是,Recon-DBSCAN聚類(lèi)算法也存在缺點(diǎn):聚類(lèi)時(shí)需要用戶手動(dòng)輸入的參數(shù)過(guò)多;得到最佳聚類(lèi)結(jié)果的過(guò)程是一個(gè)不斷嘗試的過(guò)程,無(wú)法自適應(yīng)地得到聚類(lèi)閾值。 圖1 數(shù)據(jù)高斯分布圖 針對(duì)上述聚類(lèi)算法中存在的問(wèn)題,本文使用GRDBSCAN(Grid and Density-ratio Clustering Algorithm based on DBSCAN)聚類(lèi)算法來(lái)處理這些問(wèn)題,此算法是依據(jù)網(wǎng)格的劃分和密度比的計(jì)算來(lái)解決實(shí)際問(wèn)題。首先通過(guò)自適應(yīng)多分辨率的網(wǎng)格劃分的思想把數(shù)據(jù)劃分到多個(gè)網(wǎng)格空間中,利用所劃分的網(wǎng)格加快查找到類(lèi)簇的峰值和低谷,再利用密度估計(jì)來(lái)計(jì)算密度比,從而實(shí)現(xiàn)自適應(yīng)地確定密度閾值τ和使用該全局閾值識(shí)別數(shù)據(jù)集的基于密度比聚類(lèi)的目的。 GRDBSCAN算法框架如下: 本文通過(guò)劃分網(wǎng)格將數(shù)據(jù)空間進(jìn)行粒化,旨在快速找到數(shù)據(jù)點(diǎn)密度值的“山峰”和“山谷”,以確定基于密度比聚類(lèi)算法中合適的密度閾值。該算法主要分為網(wǎng)格粒化數(shù)據(jù)空間、確定閾值和網(wǎng)格單元聚類(lèi)三個(gè)核心環(huán)節(jié)。 圖2 GRDBSCAN框架 將數(shù)據(jù)空間進(jìn)行粒化的目的是為了壓縮數(shù)據(jù),降低算法的時(shí)間復(fù)雜度。STING網(wǎng)格劃分對(duì)數(shù)據(jù)進(jìn)行粒化,以網(wǎng)格單元數(shù)據(jù)的統(tǒng)計(jì)信息代替原始的數(shù)據(jù)點(diǎn),從而達(dá)到數(shù)據(jù)壓縮的目的。數(shù)據(jù)粒化的算法為 算法1:數(shù)據(jù)粒化算法 輸入:數(shù)據(jù)樣本集D 算法步驟: 1)將數(shù)據(jù)樣本D歸一化到d維空間中; 2)設(shè)定頂層劃分尺度為l=,對(duì)數(shù)據(jù)空間進(jìn)行各個(gè)維度的劃分,且頂層網(wǎng)格單元與全局?jǐn)?shù)據(jù)空間的信息相一致; 3)從頂層至底層逐漸粒化,第i+1層的子單元為第i層單元的1/4,當(dāng)?shù)讓泳W(wǎng)格lk≤2ε時(shí)停止。 4)掃描整個(gè)數(shù)據(jù)集,把數(shù)據(jù)集中的每個(gè)點(diǎn)都放入網(wǎng)格劃分后的數(shù)據(jù)空間中,并記錄網(wǎng)格單元的信息(如:網(wǎng)格單元密度、最大值、最小值等),記錄網(wǎng)格單元的個(gè)數(shù)為n。 一個(gè)服從高斯分布的數(shù)據(jù)集,若存在密度極大值點(diǎn),則越靠近聚類(lèi)中心的點(diǎn)密度值越大,越是處于邊界的點(diǎn),密度值越小,反映在網(wǎng)格密度中也存在同樣的分布規(guī)律。因此能夠?qū)澐趾蟮木W(wǎng)格子空間進(jìn)行信息的統(tǒng)計(jì),數(shù)據(jù)壓縮等操作,選取網(wǎng)格子單元的邏輯中心點(diǎn)代表該網(wǎng)格,對(duì)數(shù)據(jù)空間進(jìn)行壓縮。壓縮后的數(shù)據(jù)點(diǎn)個(gè)數(shù)與網(wǎng)格個(gè)數(shù)相同,通過(guò)數(shù)據(jù)空間的壓縮,可以大大減小由于計(jì)算數(shù)據(jù)點(diǎn)之間的相對(duì)距離的計(jì)算量。 該步驟是為了在粒化后的所有網(wǎng)格單元中快速找出極值點(diǎn)。首先,掃描整個(gè)數(shù)據(jù)集,即將網(wǎng)格單元中數(shù)據(jù)點(diǎn)的個(gè)數(shù)作為網(wǎng)格單元的頻度;然后,利用聚類(lèi)中心網(wǎng)格單元與其他聚類(lèi)中心網(wǎng)格單元的距離大,而與其網(wǎng)格單元類(lèi)簇中其他網(wǎng)格單元的距離小的思路,確定極大值點(diǎn);最后,利用極小值點(diǎn)為極大值點(diǎn)連線上的密度最小點(diǎn),得出密度閾值。算法步驟如下。 算法2:確定閾值算法 輸出:密度閾值τ 算法步驟描述: 1)計(jì)算網(wǎng)格單元的密度ρi并降序排列 2)計(jì)算網(wǎng)格單元間的相對(duì)距離距離σi,用hi為降序排列的ρi標(biāo)記,即ρh1≥ρh2≥…≥ρhn;兩網(wǎng)格單元a和b的歐氏距離定義如式(1)所示[14]: 3)將網(wǎng)格單元的局部密度和相對(duì)距離可視化,如圖3。 圖3 網(wǎng)格局部密度和相對(duì)距離可視化 4)由圖3,得出網(wǎng)格空間極大值點(diǎn) 5)極小值點(diǎn)為極大值點(diǎn)連線上的密度最小點(diǎn),即得出極小值點(diǎn)的集合,選取極小值點(diǎn)的集合中的最大值,其密度即為密度閾值τ。 圖4 三種高斯分布組成的二維數(shù)據(jù)集估計(jì)密度分布的可視化 考慮使用一個(gè)全局密度閾值MinPts來(lái)區(qū)分所有的類(lèi)簇。如圖4所示,為了將類(lèi)簇集合C={C1,C2,C3}區(qū)分開(kāi)來(lái),則閾值的取值 MinPts大于 p(g12)時(shí)方可將三個(gè)類(lèi)簇都區(qū)分開(kāi)來(lái)。然而這樣的劃分方式下,簇C3中的很多點(diǎn)都會(huì)被歸類(lèi)為噪聲點(diǎn),達(dá)不到很好的聚類(lèi)效果。 更加糟糕的情形是,若g12處的局部密度p(g12)大于p3處局部密度p(p3)的情況。若取密度閾值MinPts>p(g12),則C3中的所有數(shù)據(jù)點(diǎn)都會(huì)被歸類(lèi)為噪聲數(shù)據(jù),聚類(lèi)的結(jié)果只能得到兩個(gè)類(lèi);若取密度閾值 MinPts<p(p3),則簇 C1和 C2將會(huì)被歸為同一類(lèi),仍然只能得到兩個(gè)類(lèi)。如果能夠用某種方式,能夠使得密度大的區(qū)域的密度降低一些,同時(shí)使得密度小的區(qū)域的密度更大一些,使得整個(gè)數(shù)據(jù)空間的數(shù)據(jù)對(duì)象密度分布更加均勻,減小類(lèi)簇間的密度差異,使得那么密度平均化之后的是數(shù)據(jù)集能夠被一個(gè)全局閾值τ區(qū)分開(kāi)來(lái)。 由基于密度比的DBSCAN算法的聚類(lèi)過(guò)程可知,知道基于密度比的DBSCAN聚類(lèi)算法需要輸入的參數(shù)包括ε,η和τ三個(gè)參數(shù),通常為了方便衡量ε和η之間的差距,令η=λε,λ∈[1.08,1.09,…,1.16],由此確定不同λ值對(duì)聚類(lèi)效果的影響。如果能夠自適應(yīng)地確定密度比閾值τ,則只需要根據(jù)λ值確定不同的鄰域密度比與其準(zhǔn)確度之間的影響。 算法3:網(wǎng)格單元聚類(lèi)算法 輸出:聚類(lèi)結(jié)果C 算法步驟描述: 1)計(jì)算各網(wǎng)格單元的密度比; 2)根據(jù)算法3得到的極大值和極小值,得到它們的密度比,選取簇谷集合密度比的最大值gij為密度閾值τ; 3)根據(jù)算法1對(duì)壓縮后的網(wǎng)格單元E進(jìn)行DBSCAN聚類(lèi),根據(jù)閾值τ剔除噪聲網(wǎng)格; 4)得到最終聚類(lèi)結(jié)果C。 本文提出算法的時(shí)間開(kāi)銷(xiāo)包括計(jì)算網(wǎng)格粒化、網(wǎng)格單元的統(tǒng)計(jì)信息、網(wǎng)格單元的相對(duì)距離和對(duì)壓縮后的數(shù)據(jù)空間進(jìn)行聚類(lèi)。其中時(shí)間開(kāi)銷(xiāo)最大的就是求網(wǎng)格單元的距離。算法的時(shí)間開(kāi)銷(xiāo)具體如下: 1)劃分網(wǎng)格時(shí)產(chǎn)生聚類(lèi)的時(shí)間復(fù)雜度為O(n),它是通過(guò)STING掃描數(shù)據(jù)庫(kù)一次計(jì)算單元的統(tǒng)計(jì)信息而得到的,層次結(jié)構(gòu)建立后,查詢處理時(shí)間為O(R),R為底層網(wǎng)格單元的數(shù)目; 2)查找簇峰和簇谷的過(guò)程需要求得相對(duì)距離,此過(guò)程的時(shí)間復(fù)雜度為O((n/ε)2); 3)基于密度的DBSCAN聚類(lèi),時(shí)間復(fù)雜度為O(R2); 總的時(shí)間復(fù)雜度如式(3): 由于R是一個(gè)遠(yuǎn)小于n的數(shù),所以算法的時(shí)間復(fù)雜度為O((n/ε)2)。 算法的空間復(fù)雜度只與網(wǎng)格單元的數(shù)目有關(guān),因此算法的空間復(fù)雜度為O((n/ε)2)。 本文實(shí)驗(yàn)所采用的計(jì)算機(jī)硬件配置為AMD E2處理器、8GB內(nèi)存;實(shí)驗(yàn)的軟件環(huán)境為Windows8操作系統(tǒng),采用Matlab 2014b編譯環(huán)境。為了證明本文所提算法的可行性和有效性,以UCI數(shù)據(jù)庫(kù)[15]中 4個(gè)公用數(shù)據(jù)集s1、s2、Iris、Segment為測(cè)試數(shù)據(jù)集,設(shè)計(jì)了以下實(shí)驗(yàn)進(jìn)行驗(yàn)證。 以UCI上的一個(gè)人工數(shù)據(jù)集s1進(jìn)行實(shí)驗(yàn),取閾值ε=0.1523,求得τ=0.8955時(shí),以分類(lèi)模型的精確率和召回率的調(diào)和平均數(shù)F值來(lái)度量本算法的精確度,得出λ和F值的關(guān)系如圖5所示。 圖5 λ與F值間關(guān)系圖 分別對(duì)另外3個(gè)數(shù)據(jù)集測(cè)試λ與F值之間的關(guān)系,得出當(dāng)λ=1.1時(shí),算法效果最好。 數(shù)據(jù)集s2為一個(gè)包含1500個(gè)數(shù)據(jù)點(diǎn)的人造數(shù)據(jù)集,ε=0.0108時(shí),求得τ=0.8820。聚類(lèi)結(jié)果對(duì)比如圖6。 圖6 聚類(lèi)結(jié)果對(duì)比 以UCI數(shù)據(jù)集上的四個(gè)人工數(shù)據(jù)集Iris、Segment、s1、s2作為實(shí)驗(yàn)對(duì)象,聚類(lèi)運(yùn)行時(shí)間比較如表1。 表1 算法時(shí)間復(fù)雜度對(duì)比 單位(s) 由表1可以得出,隨著數(shù)據(jù)點(diǎn)個(gè)數(shù)增多,三種算法下運(yùn)算時(shí)間都增大。由于本文算法與DPC算法都需要計(jì)算,運(yùn)算時(shí)間較傳統(tǒng)DBSCAN算法更長(zhǎng)。但DPC算法計(jì)算更復(fù)雜、需要被計(jì)算的數(shù)據(jù)點(diǎn)更多,故運(yùn)算時(shí)間較長(zhǎng)。 實(shí)驗(yàn)3以UCI數(shù)據(jù)集上的四個(gè)人工數(shù)據(jù)集Iris、Segment、s1、s2 作為實(shí)驗(yàn)對(duì)象,選取合適的參數(shù),求得最佳的F值,與DBSCAN算法、DPC算法聚類(lèi)準(zhǔn)確度F值比較如表2。 表2 F值比較 F值能夠度量一個(gè)算法性能的好壞,當(dāng)F值越大時(shí),算法效果越好。通過(guò)以上實(shí)驗(yàn)可知,本文算法在選擇合適參數(shù)的情形下,具有較高的F值,明顯優(yōu)于DBSCAN算法,且與DPC算法相差不大。 基于密度比的聚類(lèi)算法對(duì)于密度分布不均勻的簇有較好的聚類(lèi)效果,因此本文提出GRDBSCAN聚類(lèi)算法,它依據(jù)網(wǎng)格和密度比的計(jì)算來(lái)提高密度分布不均勻的簇的聚類(lèi)效果。同時(shí)它較比其他的聚類(lèi)算法有了新的優(yōu)點(diǎn),其一壓縮了數(shù)據(jù)空間,在此基礎(chǔ)上進(jìn)行聚類(lèi),提高了運(yùn)算效率;其二能夠自適應(yīng)地得出聚類(lèi)的密度閾值,降低了因參數(shù)選取不當(dāng)造成的聚類(lèi)效果不佳的問(wèn)題。下一步研究如何針對(duì)海量數(shù)據(jù)進(jìn)行聚類(lèi),以及利用分布式Spark平臺(tái)進(jìn)行聚類(lèi)。2.3 基于密度比的DBSCAN算法——Recon-DBSCAN
3 基于網(wǎng)格和密度比的DBSCAN聚類(lèi)算法
3.1 算法思想與框架
3.2 網(wǎng)格粒化數(shù)據(jù)空間

3.3 確定閾值

3.4 網(wǎng)格單元聚類(lèi)

3.5 算法復(fù)雜度分析
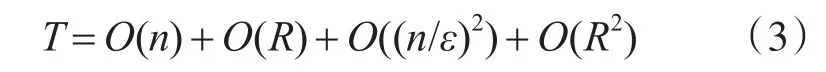
4 實(shí)驗(yàn)與分析
4.1 密度比值λ對(duì)算法的影響
4.2 聚類(lèi)結(jié)果對(duì)比
4.3 聚類(lèi)運(yùn)行時(shí)間比較
4.4 聚類(lèi)準(zhǔn)確度F值比較
5 結(jié)語(yǔ)
