考慮平板車合作運輸的船舶分段堆場間調度
2020-08-03 07:17:14李柏鶴蔣祖華陶寧蓉孟令通
上海交通大學學報 2020年7期
李柏鶴, 蔣祖華, 陶寧蓉, 孟令通, 鄭 虹
(1. 上海交通大學 機械與動力工程學院, 上海 200240; 2. 上海交通大學 高新船舶與 深海開發裝備協同創新中心, 上海 200240; 3. 上海海洋大學 工程學院, 上海 201306)
符號說明
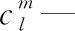
h—工廠或堆場序號,h=1,2,…,k
i—運輸任務編號,i=1,2,…,n
j—運輸任務編號,j=1,2,…,n
l—平板車編號,l=1,2,…,p
mi—第i個任務分段的質量
Q—無窮大的正數
tE—車場開放時間,即平板車最早可出發時間
tL—車場關閉時間,即平板車最晚回歸時間
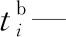
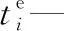
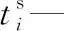
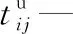
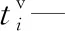
xi—第i個任務是否是超重任務,即一個平板車無法運輸,若為1表示是;若為0表示否
yil—第l輛平板車是否執行第i個任務的0-1決策變量
zijl—第l輛平板車上第i,j個任務執行順序的0-1決策變量,即如果第l輛平板車執行完第i個任務后,接著執行第j個任務,則zijl=1;否則zijl=0
zi0l—第l輛平板車執行其最后1個任務的0-1決策變量
z0il—第l輛平板車執行其第1個任務的0-1決策變量
α—平板車執行所有任務的空載行駛時間權重
β—平板車執行所有任務的等待時間權重
船舶制造是典型的拉式生產方式,船體建造工藝流程以中間產品“分段”作為組織生產的基本作業單元[1].分段在船塢之外的作業場或堆場進行組立裝配、預舾裝、涂裝和舾裝等建造工藝,最后到船塢進行總組搭載.船體分段質量較大,一般為200~300 t,個別可達到500 t.因此,分段在作業場地和堆場之間的運輸主要依靠重型平板車.
一般來說,船廠中的平板車資源都是有限的.目前,某大型船廠平板車的最大承重能力為425 t,將質量超出現有平板車最大承重能力的單個分段,稱之為大型分段.大型分段需要采用多個平板車進行合作運輸.實際中,某大型船廠每天要完成約100個分段的運輸.研究如何對船廠有限的運輸資源進行充分利用、如何運輸大型分段、如何提高平板車的利用率以及如何在保證任務準時進行的情況下,降低無效作業的等待時間等問題,具有十分重要的現實應用價值.
國內外船舶分段運輸問題的研究相對較少.Joo等[2]以拖期時間和延遲時間的權重和作為目標函數,設計了遺傳和啟發式進化兩種算法對問題進行求解.Wang等[3]以船舶分段運輸過程中平板車的空駛時間、拖期時間和延遲時間的總和作為目標函數,提出一種貪心啟發式算法對問題進行求解.Salehi等[4]認為運輸過程中排放的氣體在溫室氣體排放中占較大的比例,因此提出一個雙目標混合整數非線性規劃,目標函數為總運輸成本和總碳排放量,并提出一種構造式啟發式算法用于求解問題.Hu等[5]考慮了多個單類型平板車運輸一個大型分段的問題,建立了以最小化完工時間為優化目標的數學模型,為了提高求解方法的計算性能,用貪婪插入算法和遺傳算法生成初始解,設計順序插入法求解模型.張志英等[6]構建了考慮堆場信息、分段進出場次序等因素的最短場路模型并對其進行優化,以最小化臨時分段移動量和平板車在堆場中的行駛距離為優化目標,確定分段在堆場中的最優停放位置和進出場路.王沖等[7]為解決船廠平板運輸車搬運船舶分段的日程計劃問題,建立了利用最少數量的平板車完成分段搬運作業,以及所有分段搬運作業完成時間最小化的兩階段優化模型,提出了基于遺傳算法的兩種編碼方法以實現模型求解.
上述研究均沒有考慮當單個分段的質量超出平板車最大承重能力時,應該如何調度多種類型的平板車.而本文的研究目的是解決該運輸難點,采用多個平板車合作運輸大型分段的策略,且設定有多種承重能力的平板車可供選擇.同時,為了保證生產的準時性,引入任務時間窗緊約束作為約束條件,開展具體研究.
1 問題描述
研究的問題可描述為有n個待執行的運輸任務和p個運輸平板車,每個運輸任務包括:任務編號、分段編號、分段質量、運輸起點、運輸終點、運輸時間窗(任務最早可執行時間以及任務最晚的執行時間);每個運輸平板車包括:平板車編號、平板車承重能力.每個任務必須由滿足其分段承重需求的平板車在時間窗范圍內開始從運輸起點運送至運輸終點.其中對于大型分段,一個平板車由于承重能力限制無法運輸,此時就需要多個平板車合作運輸.某船廠的道路路口情況、堆場位置以及平板車停放位置如圖1所示.其中:虛線為平板車空載行駛的路徑;實線為平板車負載行駛的路徑.假設平板車L1的任務序列為任務Oi和Oj,任務Oi為將目標分段從平直中心運輸到涂裝平臺;任務Oj為將目標分段從9號平臺運輸至曲面車間.則平板車的實際執行流程為從平板車的停放位置出發,行駛至平直中心并提取分段,負載行駛至涂裝平臺后放下分段;然后,空駛運行至9號平臺并提取分段,負載行駛至曲面車間后空駛至平板車停放位置,結束運輸.
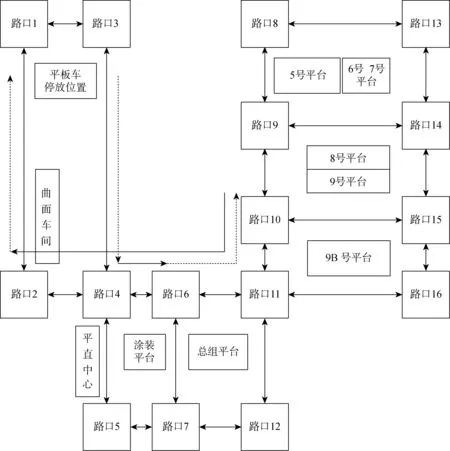
圖1 道路及堆場布局圖Fig.1 Distribution of roads and yards
對于大型分段,兩個平板車之間的合作運輸工作原理如圖2所示.其中:Ll為運輸平板車序號;Bi為船舶分段;Sh為工作場或堆場序號.以平板車L1和L2為例,平板車L1從車場出發,空駛至S1堆場,裝載分段B1后負載行駛至S3堆場,卸下分段;空駛至S5,由于分段B3是大型分段,需要L1和L2合作運輸,所以等L1和L2均到達S5后,開始運輸分段B3至S6.對于合作運輸大型分段的平板車而言,若一輛平板車早到,一輛平板車晚到,將會導致早到的平板車只能原地等待,這在生產過程中是極度浪費資源的,且等待時間也會造成生產進程的滯后.因此,從平板車運輸任務分段的全過程出發,以平板車執行任務時的空載行駛時間和平板車由于早于時間窗到達產生的等待時間,或者平板車合作運輸時產生的等待時間的權重和作為優化目標進行研究,以期達到合作運輸效率優化的效果.
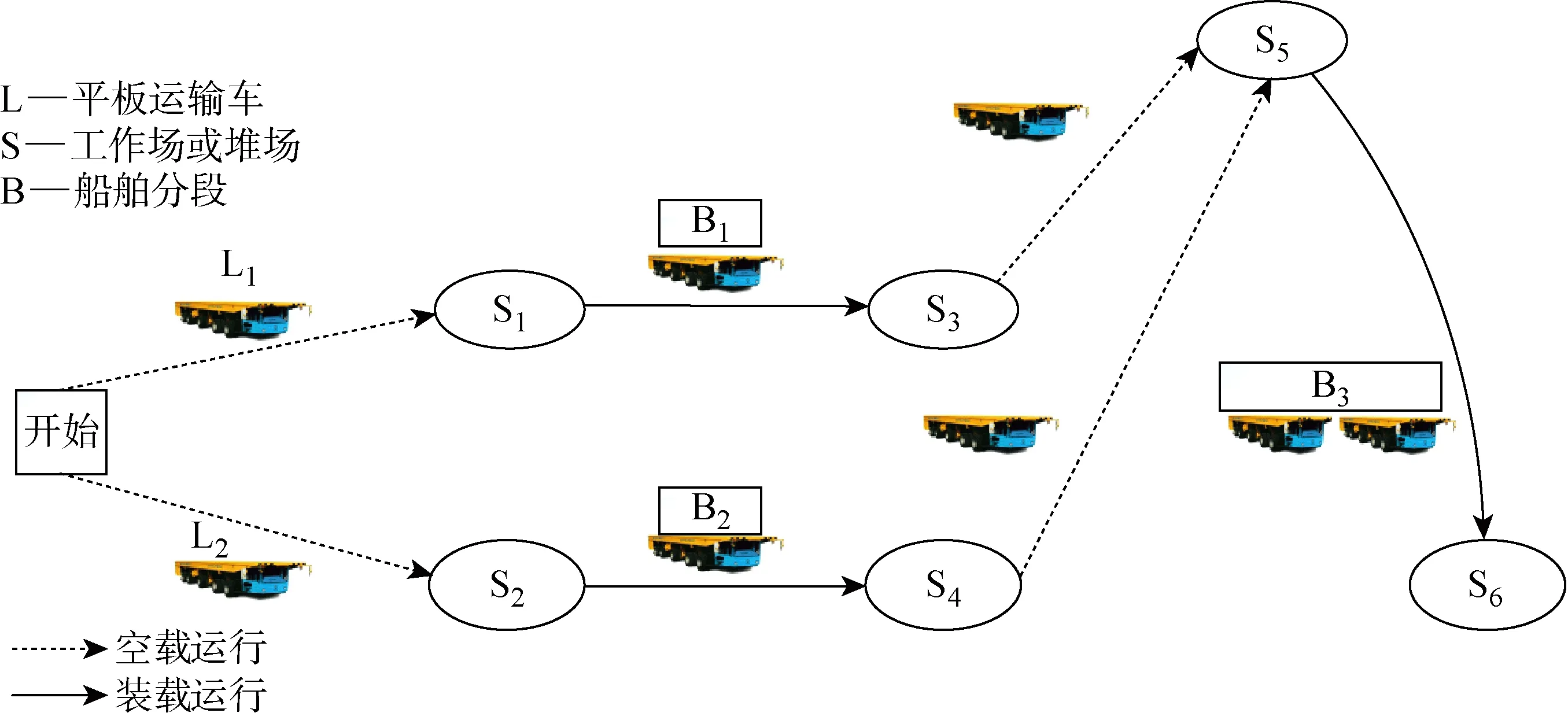
圖2 平板車合作運輸示意圖Fig.2 Diagram of multi-flatcars cooperative transportation
考慮到堆場的實際情況以及便于堆場調度問題的研究,作出如下假設:① 平板車運輸分段過程一旦開始執行, 就不可被其他任務打斷;② 平板車在同一時刻最多只能運輸一個分段;③ 不考慮道路因素 (道路上是否有平板車、道路寬度、道路上可以通行多少平板車)對平板車通行的影響;④ 為了方便說明, 假定大型分段的質量不超過兩個平板車的承重能力之和;⑤ 合作運輸的平板車可以保持一樣的速度.
本研究要解決的問題有:① 運輸任務的最優序列;② 運輸任務對應哪些平板車執行,大型任務由哪些平板車運輸;③ 各個任務的開始執行時間和完成時間.時間變量單位均為分鐘,以開始工作時間作為0點,其余時間均在此基礎上累加.
2 堆場間運輸調度模型
2.1 目標函數
建立平板車在堆場間的運輸調度模型,優化目標在調度過程中的時間因素.首先,平板車執行任務所消耗的時間是確定的,但平板車執行任務之間的空載行駛時間是不確定的,其會隨著平板車上任務序列的改變而改變;其次,平板車早到堆場或工作場時,由于時間窗緊約束的原因,會使平板車產生等待時間;再次,由于考慮的是平板車合作運輸的大型分段,合作運輸的平板車如果到達堆場或者工作場的時間不同,也會使早到的平板車產生等待時間.而等待時間會產生附加成本,即資源的浪費,進而影響生產進程.因此,模型以平板車執行任務的空載行駛時間與等待時間的權重和作為目標函數,優化運輸成本.現有研究文獻中,以最小化任務完工時間作為目標函數的也較多,本文模型中由于考慮了時間窗緊約束,嚴格控制每個任務的執行時間,所以不需要優化任務完工時間.
(1) 平板車完成所有任務的任務間空駛時間:
(2) 平板車從車場出發空駛到其第1個任務起點的時間,以及平板車執行完任務空駛返回車場的時間:
(3) 平板車早于時間窗到達或者由于協同運輸而產生的等待時間:
目標函數以上述三者的權重和作為優化目標,使其最小化.
minf=α(f1+f2)+βf3
2.2 約束條件
(1) 非大型分段由1個且只由1個平板車進行運輸,大型分段由2個平板車進行運輸:
(2) 每個平板車上的第1個任務只有1個:
(3) 每個平板車上的最后1個任務只有1個:
(4) 平板車上執行的相鄰2個任務之間的時間存在約束:
(5) 任務時間窗約束:
(6) 車場時間窗約束:
(7) 平板車承重能力與任務分段質量約束:
(8) 對于大型分段任務來說,執行任務的平板車必須都到任務始點地,任務才能開始執行:
(9) 保證平板車上執行完一個任務后接下來的任務要滿足在解中的出現次數約束:
(10) 保證平板車上執行的任務要滿足在解中的出現次數約束:
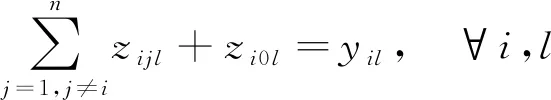
(11) 決策變量的取值范圍約束:
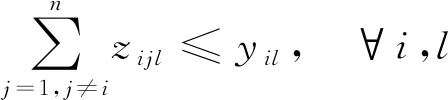
3 基于禁忌搜索的模型求解
船舶分段堆場間的運輸調度模型為混合整數線性規劃問題.對于小規模問題,可以采用商業求解器,如CPLEX求出最優解.但在實際應用中,需要搬運的分段數量較大,現有求解器很難在有限時間內求出高效解.禁忌搜索算法在組合優化問題中具有較好的效果,廣泛應用于旅行商問題以及車輛路徑問題.禁忌搜索算法依靠禁忌表的存在,可以在搜索中跳出局部最優,不同的構造鄰域方法也增加了鄰域空間的多樣性,具有較好的求解效果.因此,設計禁忌搜索算法在分鐘級別的時間內高效求解模型,具有較高的實際應用價值.
3.1 解的編碼方式
模型解的編碼與解碼方式如圖3所示.編碼方式為3個一維數組串行,表示平板車運輸的分段及其運輸順序.如圖3(a)中,第1行表示任務序列編號,第2行和第3行表示任務被執行的平板車編號.若第2行和第3行的平板車編號相同,則表示該任務是由同一個平板車執行的;若第2行和第3行平板車編號不相同, 則表示該任務是由兩個平板車合作運輸的.解碼后的運輸方案如圖3(b)所示,即平板車1執行第3、6、1、2個任務;平板車2執行第4、6、5個任務;平板車3執行第9、7、10、8個任務.其中任務6為大型任務,由平板車1和平板車2合作運輸.同理,如果考慮3個平板車合作運輸,則用4個一維數組串行表示平板車運輸的分段及運輸順序.
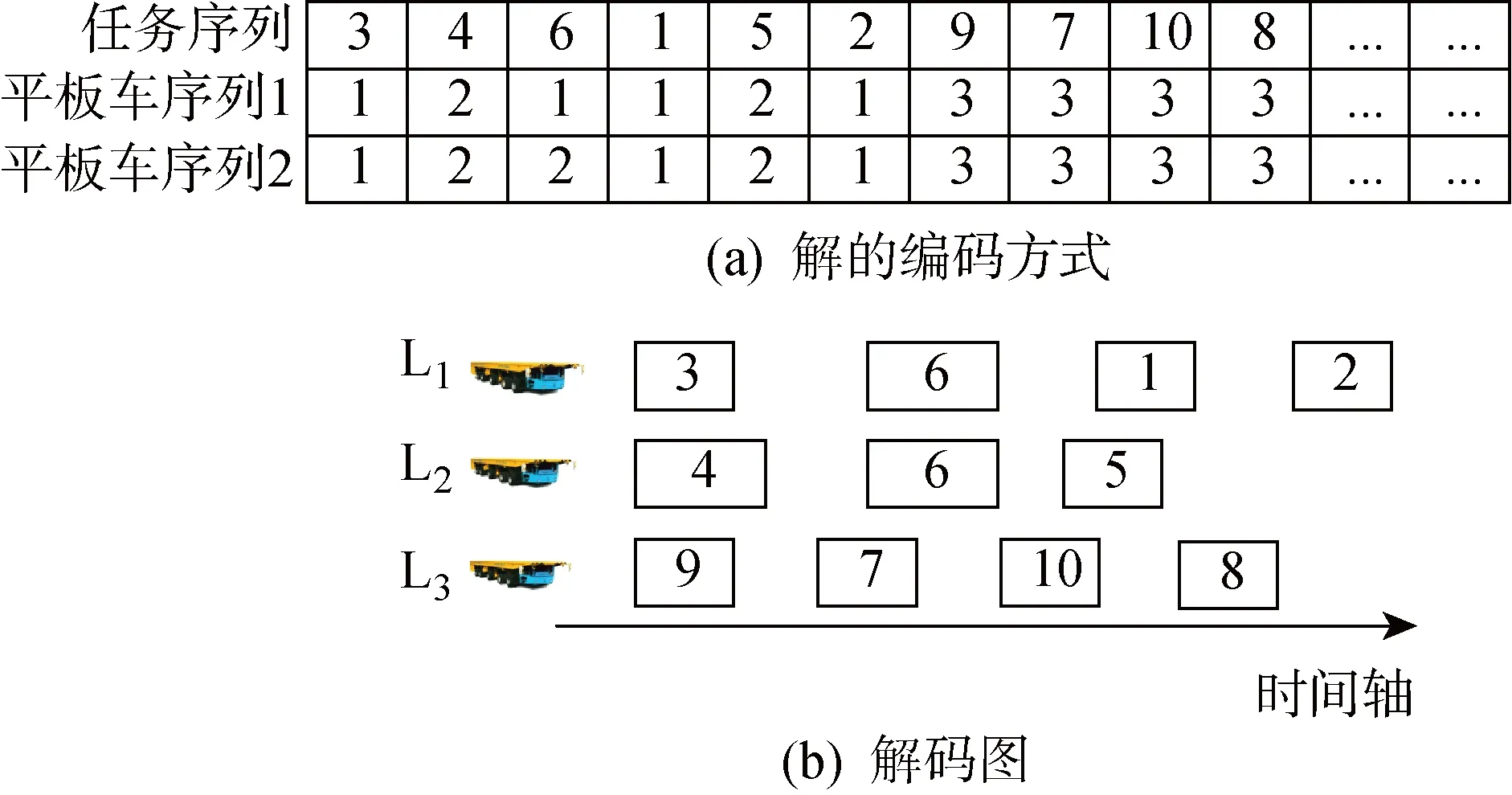
圖3 編碼與解碼圖Fig.3 Coding and decoding
3.2 構造初始種群
采用隨機構造初始種群的方式,先隨機生成任務序列,再根據承重約束為每個任務分配平板車,對于大型任務則隨機產生兩個符合其承重約束的平板車.由于模型中存在時間窗約束,很可能構造的個體是不可行的,但對于不可行解,在計算適應度時會給予懲罰,所以在迭代中,不可行解會被逐漸取代.
3.3 個體適應度評估
個體代表模型的解,個體適應度函數就是模型需要優化的目標函數,對于所提模型的適應度越低,代表個體越好.個體解碼后,可以獲得每個車的運輸方案、計算平板車從車場出發至執行第1個任務的空載行駛時間,以及執行后續任務的空載行駛時間與執行完所有任務后回到車場的空載行駛時間.在計算平板車等待時間時,首先需要注意大型任務要等到執行大型任務的所有平板車均到達其起始點才可以開始執行.大型分段的時間更新示意圖如圖4所示.由圖4可知,第1輛平板車上任務6的執行時間要后移,因為第2輛平板車還未到達.其次,需要調整每個平板車上第1個任務的開始執行時間,以最小化等待時間.由于任務6是大型任務,任務6的開始時間被延后,導致L1在執行完任務3后存在一段等待時間,此時需要對任務6之前的任務開始執行時間進行調整.將任務3的開始時間延后,此時等待時間就消除了(見圖4右框).同理,第3輛平板車也需要對任務9的開始時間進行調整,這樣可以減少平板車的等待時間.在算法求解過程中可以出現不可行解,但一定要對其適應度加上一定的懲罰,且根據不可行解的出現情況,動態改變懲罰系數.

圖4 大型分段的時間更新示意圖Fig.4 Diagram of time update of large-blocks
3.4 鄰域結構
如何從當前解出發,構造高效的鄰域解是禁忌搜索算法的核心所在.設計5種鄰域結構,具體操作過程如下.
(1) M1.讓1個任務從1輛平板車遷移到另外1輛平板車.
步驟1在解的任務序列上隨機地選擇1個任務.
步驟2若該任務是大型任務,則在滿足大型任務的承重約束下生成新的平板車賦值給解的第3行序列;若該任務不是大型任務,則在滿足任務承重約束下生成新的平板車,并賦值給解的第2行和第3行序列.
M1的具體領域結構圖如圖5所示.
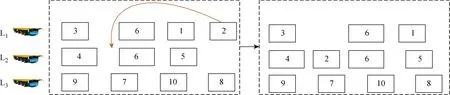
圖5 M1的鄰域結構Fig.5 Neighborhood structure of M1
(2) M2.讓1輛平板車上的2個任務的執行順序發生改變.
步驟1在解的平板車序列中隨機選擇1個平板車.
步驟2在該平板車上選擇2個任務, 交換其位置及平板車號.
M2的具體領域結構圖如圖6所示.
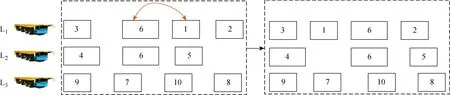
圖6 M2的鄰域結構Fig.6 Neighborhood structure of M2
(3) M3.讓兩個車之間交換任務片段,這樣更有利于保護時間窗的約束[8].
步驟1在解的平板車序列中選擇2個平板車.
步驟2選擇平板車上除了開始和末尾的1個任務序列片段,即2個連續的任務,與另外1個平板車上的任務序列片段進行交換.
步驟3檢查新的解是否滿足大型任務的承重約束,若不滿足,則返回步驟 1;若滿足則結束.
M3的具體領域結構圖如圖7所示.

圖7 M3的鄰域結構Fig.7 Neighborhood structure of M3
(4) M4.讓1輛車的上1個任務遷移到該車上的另1個任務的前面,以增加任務序列的多樣性.
步驟1在解的平板車序列中選擇1輛平板車.
步驟2選擇平板車上的1個任務,再選擇另外1個任務.
步驟3將選擇的第1個任務遷移到選擇的第2個任務位置前.
M4的具體鄰域結構圖如圖8所示.

圖8 M4的鄰域結構Fig.8 Neighborhood structure of M4
(5) M5.讓1輛車的上1個任務遷移到該車上的另1個任務之后,以增加任務序列的多樣性.
步驟1在解的平板車序列中選擇1輛平板車.
步驟2選擇平板車上的1個任務,再選擇另1個任務.
步驟3將選擇的第1個任務遷移到選擇的第2個任務位置后.
M5的具體鄰域結構圖如圖9所示.
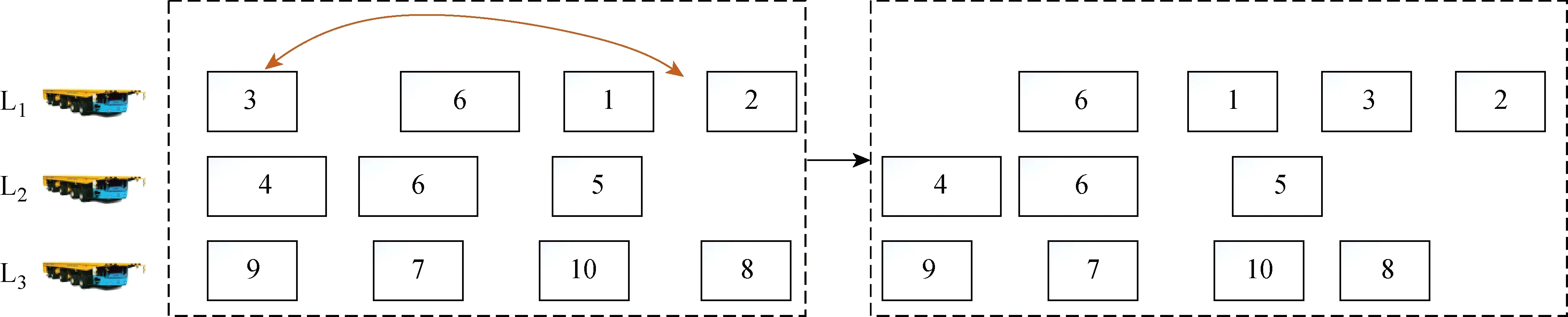
圖9 M5的鄰域結構Fig.9 Neighborhood structure of M5
3.5 懲罰系數的更新
由于模型的約束較多,很難一直在可行解空間搜索模型的解,且對于上述5種鄰域構造方法均不保證時間窗約束的成立,所以對于不滿足時間窗約束的個體,在計算個體適應度時需加上額外的懲罰.文獻[9]通過研究證明,動態系數的方式效果更好,即如果本次迭代中最好的解不是可行解,則懲罰系數應變大,以減少不可行解的存在;如果本次迭代中最好的解是可行解,則懲罰系數應變小,以增大不可行解的存在.
3.6 禁忌表及特赦規則
由于上述設定的5種鄰域結構是不同的,所以針對每個鄰域結構分別建立禁忌表,以防止每種策略產生重復的鄰域解.特赦規則為如果由禁忌表中的操作產生的解優于當前最優解,則觸發特赦規則.對于第1種鄰域結構,用(i,l1,l2)表示任務i由Ll1車遷移到Ll2車,則用(i,l2,l1)作為禁忌元素加入到禁忌表中以防止最優解的操作重復出現;同理,第2種鄰域結構用(i,j,l)表示車Ll上任務i和任務j交換,則禁忌元素為(j,i,l)和(i,j,l);第3種鄰域結構用(i1,j1,l1;i2,j2,l2)表示Ll1車上(i1,j1)任務片段與Ll2車上(i2,j2)任務片段交換,則禁忌元素為(i1,j1,l2;i2,j2,l1);第4種鄰域結構用(i,j,l)表示Ll車上任務i遷移到任務j前面;第5種鄰域結構用(i,j,l)表示Ll車上任務i遷移到任務j后面.禁忌長度與鄰域空間有關,一般為10lgn.
4 數值試驗
4.1 實例驗證
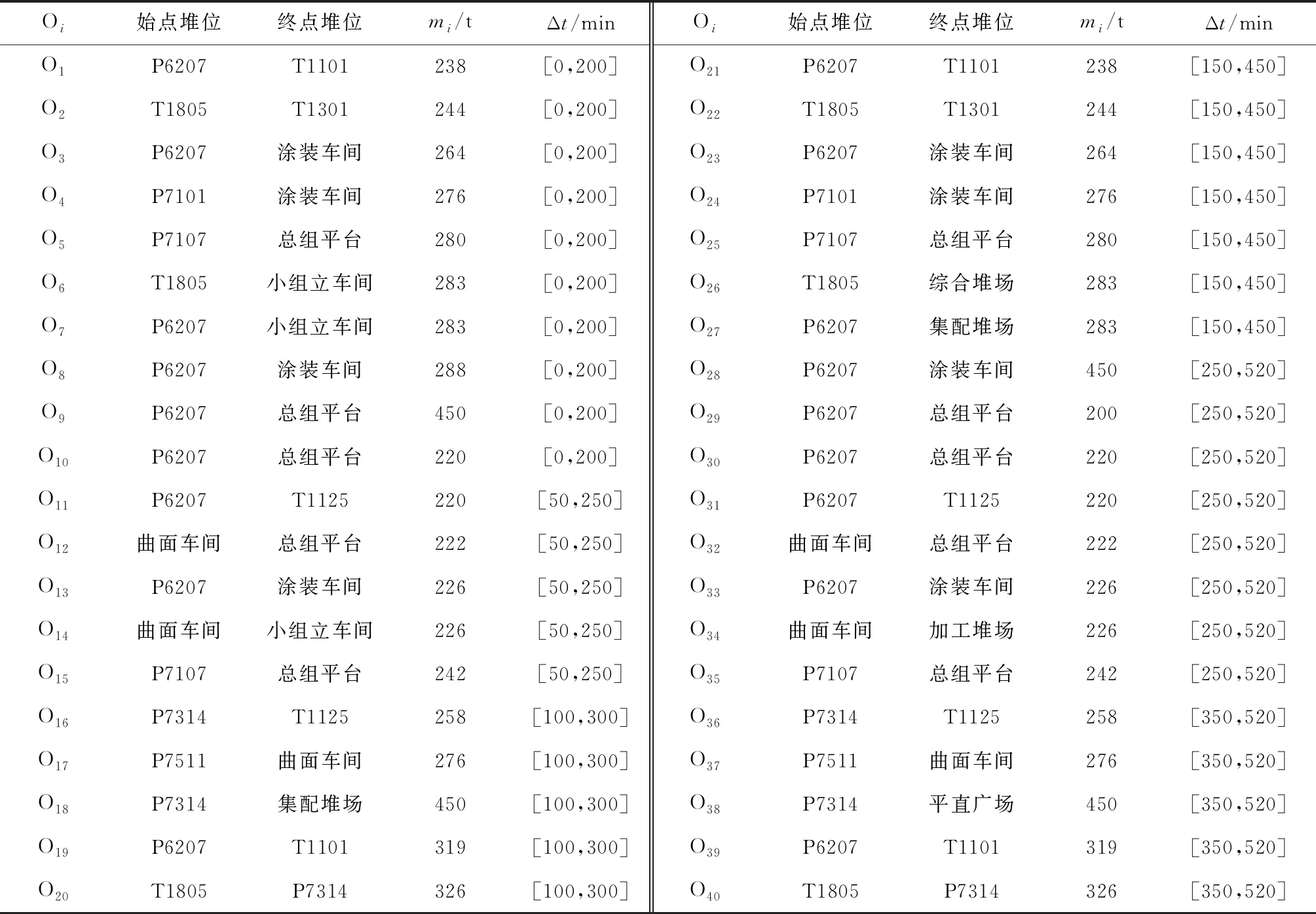
表1 運輸任務和時間窗信息表Tab.1 List of transportation tasks and time windows

表2 平板車信息Tab.2 Flatcar informations
獲得的調度結果如表3所示.由表3可知,平板車與執行任務之間滿足承重約束;任務開始執行時間滿足時間窗約束;第9、18、28、38號任務為大型任務,由兩輛平板車協同運輸.實例結果驗證了所提算法的有效性.然而,調度結果中出現了承重能力為425、380 t的平板車運輸質量為200 t分段的情況,這主要是由于調度結果是從整個調度周期的總目標函數考慮而導致的.如果質量為200 t的分段都由承重能力為250 t或270 t的平板車運輸,很有可能造成250、270 t的平板車之后的運輸任務不滿足時間窗約束或者運輸成本較高,所以算法在求解時舍棄了成本較高的解.

表3 調度結果Tab.3 Scheduling results
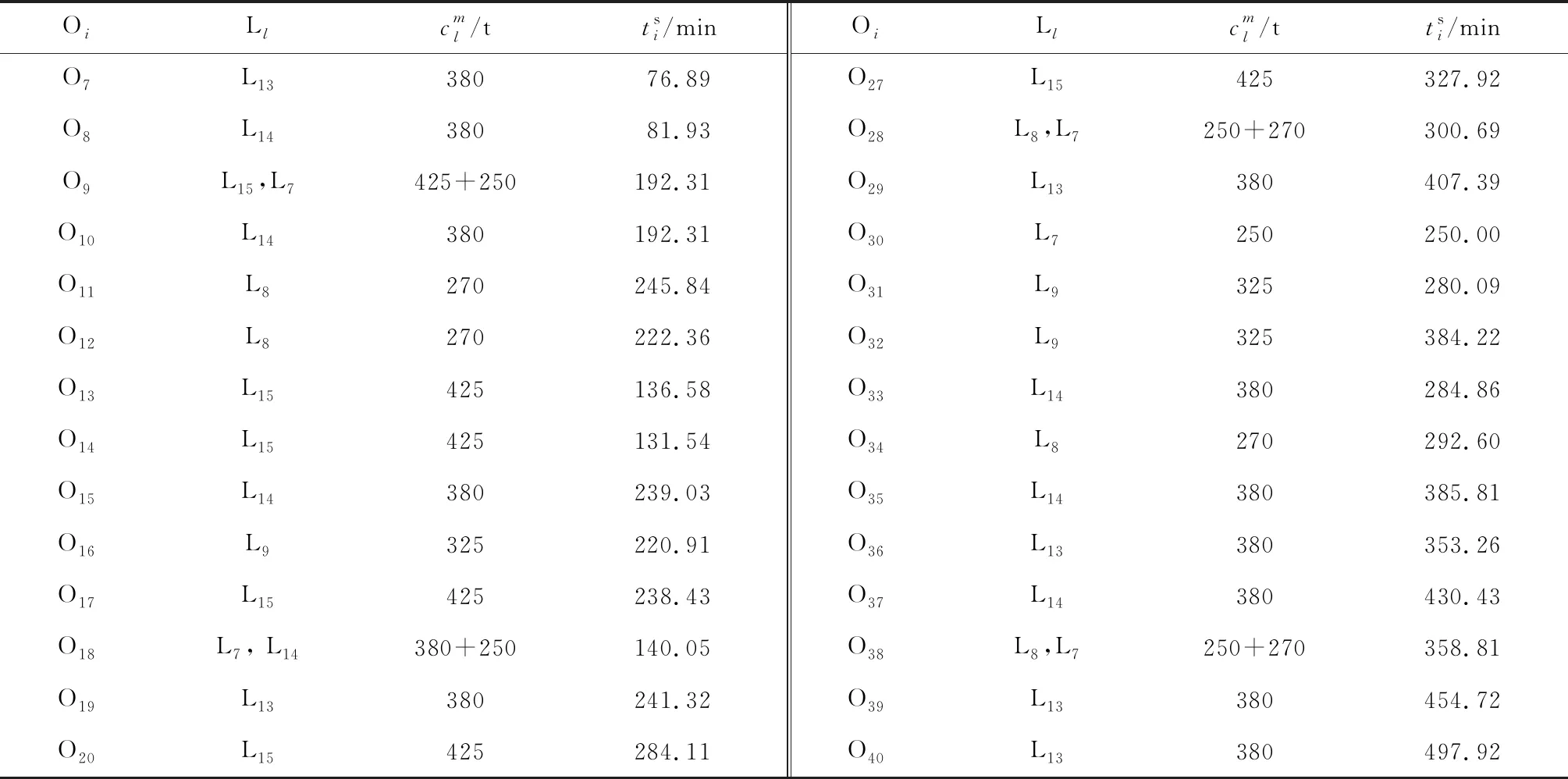
(續表)
4.2 數值實驗分析
4.2.1實驗條件 為了驗證所提禁忌搜索算法求解模型的性能,以多組船廠的實際數據進行實驗.任務數量分別為6、8、10、12、20、30、40、50;大型任務數分別為1、1、1、1、2、3、4、5;平板車數量為2、3、4、5、6、7、8.以任務執行時間、各任務之間的行駛時間作為輸入量.時間窗根據實際背景進行調整.選用IBM ILOG CPLEX優化求解器求解模型,禁忌搜索基于Java語言編寫.考慮到實際應用及便于對比等因素,設定CPLEX求解器的求解時間為 3 600 s.
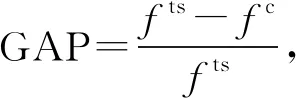
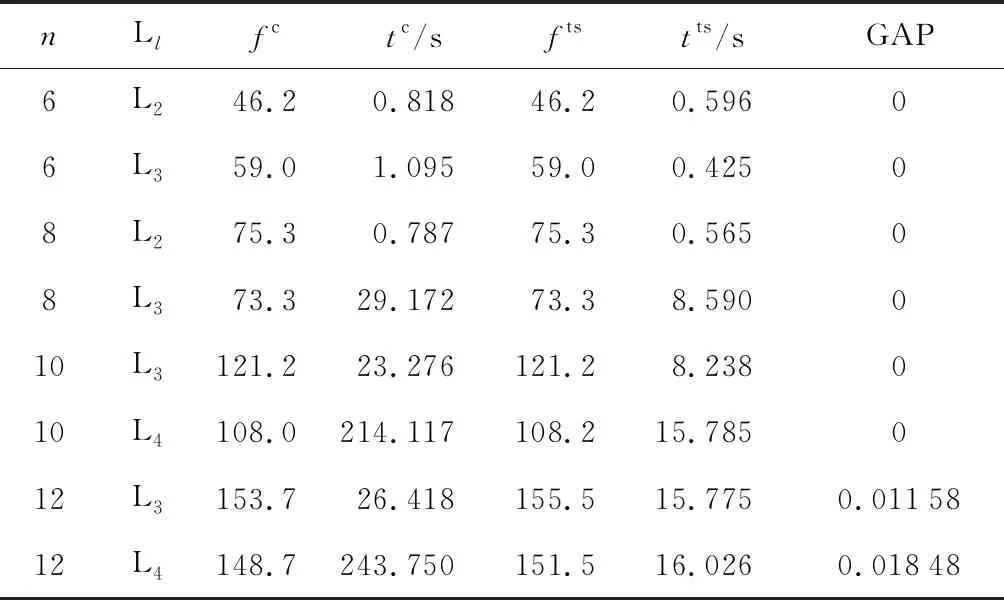
表4 小規模任務的CPLEX與禁忌搜索求解對比
由表4可知,隨著任務數和平板車數量的增加,CPLEX的求解時間急劇增加.禁忌搜索算法在任務數為6、8、10時能夠求出最優解,在未求出最優解的測試用例上求出近最優解,GAP小于0.02,同時求解時間并沒有急劇增加,證明禁忌搜索算法是有效且可行的.由表5可知,當任務數為20、平板車數為4時,CPLEX已經在 3 600 s內無法求出最優解.針對較大規模的任務數和平板車數時,禁忌搜索算法均可以在80s內求得結果,且在任務數為30、40、50時求得的結果明顯優于CPLEX.其他任務數和平板車數上GAP均小于0.04,驗證了禁忌搜索算法在實際應用中具有較好的效果.
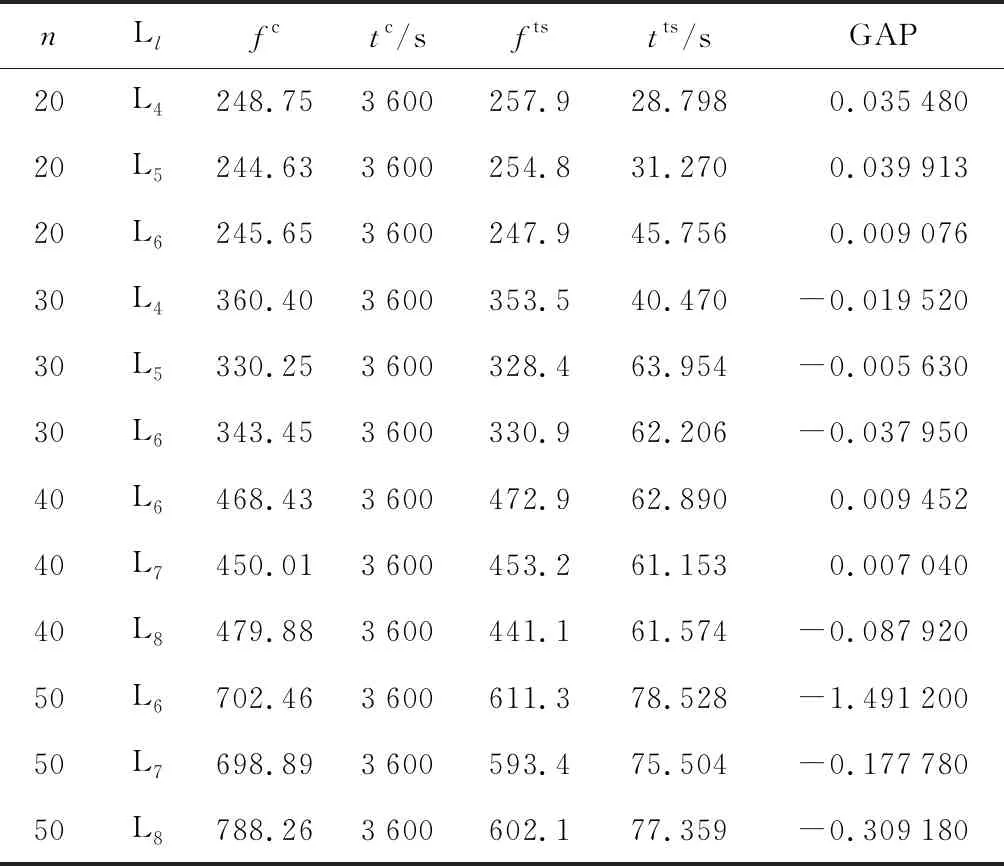
表5 中等規模任務的CPLEX與禁忌搜索求解對比
由于模型目標函數考慮了等待時間,所以需要考慮所有任務的開始執行時間,但是禁忌搜索算法卻不能遍歷所有任務的開始時間,只能根據時間窗和任務序列的時間連貫性進行微調整,這就導致了大規模任務時禁忌搜索求解結果與最優解在等待時間上會有一定的差距.
5 結語
考慮平板車合作運輸的船舶分段堆場間的運輸調度模型,通過平板車合作運輸解決大型分段的運輸難點,提出通過調整任務的開始時間以減小平板車的等待時間.從數值結果可以看出,所提算法在規模較大的情況下依然可以快速求得質量較高的解,驗證了所設計的禁忌搜索算法具有較好的效果,可用于實際生產.但如何提高大規模問題解的精度、如何使算法求解穩定、如何設計策略優化平板車的等待時間等問題仍需進一步的研究.
