面向食品安全事件新聞文本的實體關(guān)系抽取研究
2020-07-24 07:29:20鄭麗敏齊珊珊田立軍
農(nóng)業(yè)機械學報 2020年7期
鄭麗敏 齊珊珊 田立軍 楊 璐
(1.中國農(nóng)業(yè)大學信息與電氣工程學院, 北京 100083; 2.食品質(zhì)量與安全北京實驗室, 北京 100083)
0 引言
食品安全事件頻發(fā),注水肉、過期奶粉等事件嚴重影響了民眾的生活,造成了嚴重的后果[1]。網(wǎng)絡(luò)上各種新聞文本的數(shù)量迅猛增長,如何快速、準確地獲取食品安全事件新聞文本,并理清其中的關(guān)系脈絡(luò)是一項耗時、耗力的工作。食品安全事件新聞文本的分析梳理對于消費者和管理者均具有重要意義:消費者能夠從雜亂冗余的大量數(shù)據(jù)中快速獲取事件的主要信息,對事件的發(fā)展走向有系統(tǒng)的認知,提前做出正確的預防或應(yīng)對,減輕事件帶來的傷害;管理者利用梳理出來的信息快速決策,及時發(fā)布并通知、提醒各部門或消費者采取相應(yīng)措施等。實體關(guān)系抽取能夠從半結(jié)構(gòu)化和非結(jié)構(gòu)化的信息源中抽取出實體及實體之間的語義關(guān)系,在數(shù)據(jù)挖掘、問答系統(tǒng)、知識圖譜構(gòu)建等研究中均扮演著重要角色,是實現(xiàn)分析梳理的基礎(chǔ),受到越來越多研究者的關(guān)注[2-4]。
實體關(guān)系抽取方法有半監(jiān)督式、遠程監(jiān)督式和無監(jiān)督式3種[3]。其中,半監(jiān)督式的實體關(guān)系抽取需要選取少量的種子,種子的品質(zhì)會直接影響抽取效果,且受人的主觀影響明顯[5];遠程監(jiān)督式的實體關(guān)系抽取需要大規(guī)模知識庫的支撐,但適用于各領(lǐng)域的大規(guī)模知識庫很難找到,所以該方法并不適用于眾多領(lǐng)域[3,6-7];無監(jiān)督式的實體關(guān)系抽取無需任何人工標注數(shù)據(jù)、預定義關(guān)系類型等,適用于開放領(lǐng)域的關(guān)系抽取[8-9]。目前,英文的實體關(guān)系抽取研究已經(jīng)達到較高的水平,由最初的開放式信息抽取系統(tǒng)TextRunner[10]發(fā)展到O-CRF[11]、ReVerb系統(tǒng)[12]、Ollie系統(tǒng)[13]等,性能不斷提高。中文實體關(guān)系抽取卻發(fā)展緩慢,主要是由于中文語法具有復雜多變、無標準句式、實體參數(shù)位置不固定等特點,導致中文文本的實體關(guān)系抽取難度遠遠高于英文文本。文獻[14]提出第一個開放領(lǐng)域?qū)嶓w關(guān)系抽取系統(tǒng)ZORE,在語義層面進行研究,具有有效性,但隨著召回率的提高,準確率下降趨勢過于明顯。文獻[15]提出用于知識獲取的中文開放信息抽取的CORE系統(tǒng),證明了從中文語料庫中抽取關(guān)系而不向IE系統(tǒng)輸入任何預定義詞匯和關(guān)系的可行性,但并未在大規(guī)模的新聞文本數(shù)據(jù)集上進行充分的實驗。之后針對不同的數(shù)據(jù)類型,在ZORE、CORE的基礎(chǔ)上出現(xiàn)了GCORE[16]、C-COERE[17]等系統(tǒng),性能得到了優(yōu)化。
但是這些方法對所有的文本采取相同的處理方式,未充分考慮食品安全事件新聞文本的以下特性:發(fā)生主題、涉事食品、食品種類、涉事企業(yè)、企業(yè)負責人、涉事人員、發(fā)生時間、發(fā)生地點、發(fā)生原因、發(fā)生規(guī)模、導致結(jié)果、產(chǎn)生影響及危害等,無法對網(wǎng)絡(luò)上食品安全事件新聞及時預警,在一定程度上降低了事件時效性。針對這一問題,本文提出一種基于依存分析的食品安全事件新聞文本的實體關(guān)系抽取方法FSE_ERE,充分考慮中文新聞文本的語言特性,利用LTP工具[18]對句子進行分詞、詞性標注、命名實體識別處理后,對各個語言單位內(nèi)成分之間的依存關(guān)系進行分析,揭示句子的句法結(jié)構(gòu)。再結(jié)合這些知識和構(gòu)建的實體關(guān)系抽取模型抽取出其中包含的實體關(guān)系三元組,實現(xiàn)中文新聞文本中實體和關(guān)系的自動抽取,無需任何人工干預。質(zhì)量高且類別明確的文本能有效提高抽取模型和依存分析結(jié)果的匹配度,從而提高抽取性能。因此在實體關(guān)系抽取過程中引入半監(jiān)督的PU學習分類方法,創(chuàng)造性地將文本相似度結(jié)合到PU學習分類方法中,通過改進的特征選取與加權(quán)處理方法提高分類的精度,以節(jié)省時間和人力。
1 FSE_ERE方法
FSE_ERE方法主要包含兩部分內(nèi)容:①為了獲取更多高質(zhì)量的文本數(shù)據(jù),在大規(guī)模的新聞文本中利用基于PU學習的分類模型提取食品安全事件新聞文本。②在提取的文本的基礎(chǔ)上,利用基于依存分析的模型進行實體關(guān)系抽取工作。
1.1 分類模型描述
分類問題是機器學習的一個重要組成部分,目前大多數(shù)分類方法是根據(jù)已知樣本的某些特征后判定新樣本的類別[19-20]。文本分類一般要經(jīng)過文本預處理、特征選擇、分類器訓練和性能評估4個步驟[21-22]。本文主要解決的問題是在眾多互聯(lián)網(wǎng)文本中,在只含有積極樣例的情況下,快速地挑選出高質(zhì)量的食品安全事件類文本,以便進行實體關(guān)系抽取工作。本文中出現(xiàn)的積極樣例是食品安全事件新聞文本,消極樣例是非食品安全事件的其他各個類別的新聞文本,未標記樣例是大規(guī)模的網(wǎng)絡(luò)新聞文本。
1.1.1關(guān)鍵特征
在文本預處理過程中,分詞和去停用詞是主要步驟。由于目前的自然語言處理工具仍存在一定的缺陷,無法全面、準確地識別出文本中存在的領(lǐng)域?qū)S忻~,尤其是食品安全事件領(lǐng)域中特有的食品名稱、發(fā)生原因(即引起食品安全事件發(fā)生的具體因素)等。例如,“毒雞蛋”是食品安全領(lǐng)域中出現(xiàn)的一種問題食品的名稱,分詞工具通常會將其分詞為“毒”和“雞蛋”兩部分。但是“雞蛋”只是普通食品的名稱,并不能作為食品安全事件的問題食品,這就造成食品安全事件的主體食品判定的錯誤,影響事件的分析研究。因此,領(lǐng)域詞典在分詞、詞性標注、命名實體識別過程中發(fā)揮著重要作用,能夠輔助自然語言處理工具更全面地、更準確地識別出文本中的重要信息,還能夠幫助選取重要特征,提高分類精度。
通過對食品安全事件統(tǒng)計分析和對中文新聞文本表達特點進行研究,發(fā)現(xiàn)與其他類型的新聞相比,不論食品安全事件新聞文本的完整程度如何,通常會包含以下特性:涉事食品、發(fā)生原因、涉事企業(yè)和發(fā)生地點4項,因此將這4項作為關(guān)鍵特征。為了保證它們的正確性,分別構(gòu)建了關(guān)于4項關(guān)鍵特征的領(lǐng)域詞典,并將這4個詞典稱為關(guān)鍵特征詞典。關(guān)鍵特征詞典中的詞匯是從國家藥品監(jiān)督管理局、食品伙伴網(wǎng)等網(wǎng)站的相關(guān)模塊中爬取的專有名詞,共273 709個,各個特征項對應(yīng)的領(lǐng)域詞典中包含詞的個數(shù)統(tǒng)計結(jié)果如表1所示。其中發(fā)生原因包括食品添加劑、真菌毒素、污染物、農(nóng)獸藥方面的專有詞匯;發(fā)生地點包括省級行政區(qū)、地級市、縣級市和縣。
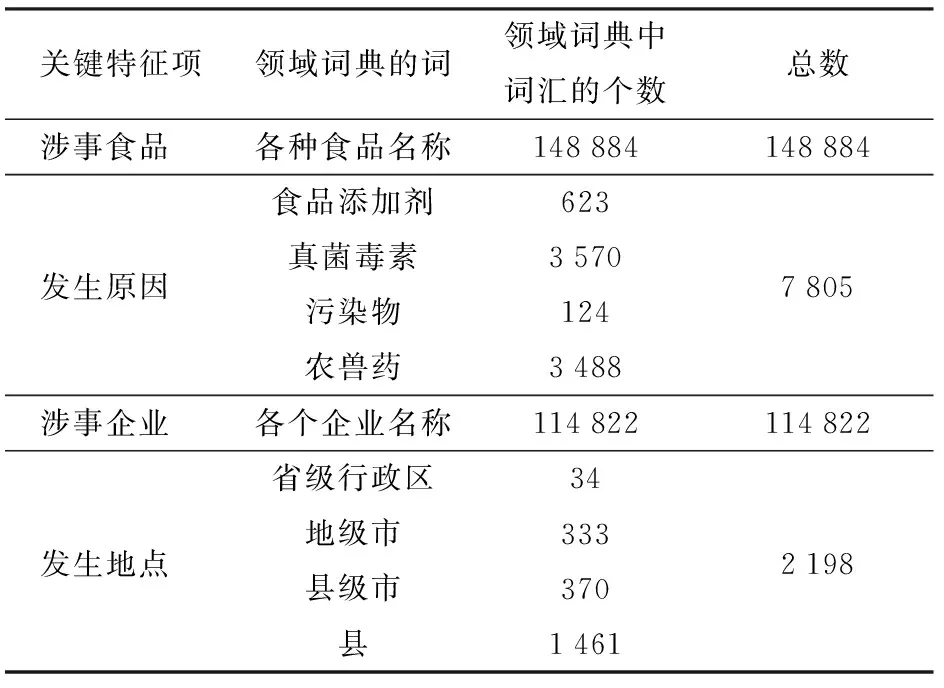
表1 各個特征項的領(lǐng)域詞典中包含的詞個數(shù)Tab.1 Number of words in domain dictionary of each feature item
預處理時,對文本進行清洗,包括去除鏈接、空格、無意義字符,并利用分詞工具對文本進行分詞操作后,在分詞系統(tǒng)中引入上述關(guān)鍵特征詞典,能夠明顯提高分詞的準確率。此外,在得到每個文本的分詞結(jié)果后,還需要進行去停用詞處理,因為這些停用詞雖然詞頻高但是對文本分類貢獻小。則文檔集所有剩余的分詞結(jié)果構(gòu)成了一個詞典向量。該詞典向量與關(guān)鍵特征詞典中存在一些相同的詞匯,為了避免特征重復,刪除詞典向量中這部分重復的詞匯。
1.1.2特征模板生成
TF-IDF算法是一種目前最為常用且非常有效的特征提取方法,根據(jù)計算的特征權(quán)重評估每個特征對文本的重要程度。本文采用TF-IDF方法計算所有特征詞在每篇文檔中的特征權(quán)重,但傳統(tǒng)的TF-IDF沒有考慮特征詞在類間分布狀況的影響。所以本文在TF-IDF中引入特征選擇效果較好的卡方統(tǒng)計量(Chi-square, CHI)方法進行修正。
CHI用于表示特征詞與類別之間的相關(guān)程度,CHI越高則表示相關(guān)程度越高,對應(yīng)的特征詞不僅更能代表某個類別,還具有更高的權(quán)重。CHI計算公式為[22-23]
(1)
式中VCHI——卡方統(tǒng)計量(CHI)
tj——第j個一般特征詞
Ci——第i個類別
|X|——數(shù)據(jù)集中的文檔總數(shù)目
其中A、B、C和D的含義如表2所示。

表2 特征與類別關(guān)系Tab.2 Relationship between features and categories
此外,文本關(guān)鍵特征也能夠明顯區(qū)分類別間的差異,對分類產(chǎn)生較好的影響。所以將涉事食品、發(fā)生原因、涉事企業(yè)、發(fā)生地點4項關(guān)鍵特征補充到選取的特征詞后面,生成特征模板。雖然關(guān)鍵特征對應(yīng)的詞匯集合與類別相關(guān)性最大,但是它們在文檔中出現(xiàn)的次數(shù)并不多,導致了其權(quán)重低。所以在改進的關(guān)鍵特征權(quán)重計算方法的基礎(chǔ)上還引入了關(guān)鍵特征因子λ,以實現(xiàn)加權(quán)處理。λ是經(jīng)過大量實驗后得出的一個經(jīng)驗系數(shù),本文取值為3。
計算關(guān)鍵特征的權(quán)重時,應(yīng)統(tǒng)計關(guān)鍵特征pg對應(yīng)的關(guān)鍵特征詞典中的詞匯在文檔xi中的頻率,并計算關(guān)鍵特征的逆文檔頻率(Inverse document frequency, IDF),最后計算出關(guān)鍵特征在文檔xi中的權(quán)重。計算公式為
D(wpg)=λ(pg)TpgIpg
(2)
式中wpg——關(guān)鍵特征的權(quán)重
D(wpg)——關(guān)鍵特征在文檔xi中的權(quán)重
Tpg——關(guān)鍵特征的TF值
Ipg——關(guān)鍵特征的IDF值
Tpg的主要思想是:關(guān)鍵特征pg是一類特征的集合,如果pg在文本中出現(xiàn)的不同詞匯數(shù)多且頻次高,說明這篇文檔描述了很多關(guān)于pg的內(nèi)容,與pg相關(guān)程度高,則可以認為文檔屬于pg相關(guān)的類別。Ipg的主要思想是:據(jù)統(tǒng)計分析,關(guān)鍵特征pg涉及的某些詞匯在大多數(shù)文檔中出現(xiàn)頻率都比較低,但這些特征詞對文本分類的作用卻十分明顯,它們對分類貢獻率高卻容易被忽略掉,所以Ipg被用于表示關(guān)鍵特征pg對于整個文檔集的重要程度,即當包含pg的文檔數(shù)目越少時,pg對文本分類貢獻率會越高。Tpg和Ipg的計算方法分別為
(3)
(4)
式中Dpg——pg對應(yīng)的關(guān)鍵特征詞典中的詞匯
n(Dpg,xi)——Dpg在文檔xi中出現(xiàn)的頻次
nk,xi——文檔xi中詞匯k出現(xiàn)的次數(shù)
N(pg)——包含關(guān)鍵特征pg的文檔數(shù)目
在式(4)中,分母項加1是對其進行了平滑處理,防止該詞語不在語料庫中時導致的除數(shù)為零現(xiàn)象發(fā)生。
最后,由于大多數(shù)文檔長度不一樣,TF-IDF算法會出現(xiàn)偏向于長文本的情況,所以需要對TF-IDF算法的計算結(jié)果作統(tǒng)一的歸一化處理。同時將特征詞的CHI進行對數(shù)化處理,以解決權(quán)重不均衡問題。綜上所述,本文改進后生成的特征模板中,一般特征權(quán)重計算公式為
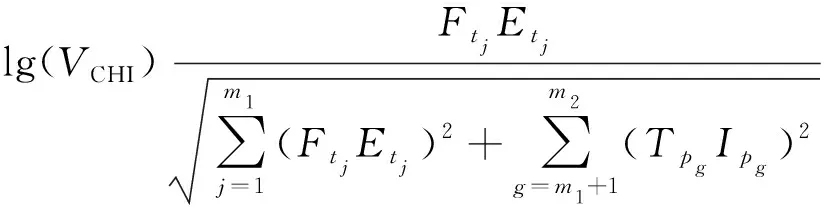
(5)
關(guān)鍵特征的權(quán)重計算公式為
(6)
式中m1——一般特征詞的數(shù)目
m2——關(guān)鍵特征的數(shù)目
Ftj——第j個一般特征詞的詞頻
Etj——第j個一般特征詞的逆文檔頻率指數(shù)
利用向量空間模型(Vector space model, VSM)方法對文本進行文本向量化表示,用于文本分類器的訓練。對于一篇食品安全事件新聞文檔xi,其向量表示為
xi=(w1,w2,…,wi,…,wm1,…,wj,…,wm1+m2)
(1≤i≤m1≤j≤m1+m2)
(7)
式中wi——第i個特征對應(yīng)的特征權(quán)重
wj——第j個特征對應(yīng)的特征權(quán)重
1.1.3尋找消極樣例和建立分類器
提出的PU學習分類模型采用兩步法實現(xiàn)。
(1)尋找消極樣例
第1步是在未標記樣例中尋找一部分與積極樣例極其不同的樣例(反差大的樣例)作為消極樣例,詳細流程如圖1所示。首先將一部分積極樣例放入未標記樣例中,然后對未標記樣例集合進行聚類。未標記樣例集合經(jīng)聚類后形成大小不同的簇。去除包含間諜樣例的簇(認為簇中不含有消極樣例),并對剩余簇內(nèi)的文本進行相似度計算,刪除相似度高的文本。因為對于大規(guī)模的網(wǎng)絡(luò)食品安全事件新聞文本,同一篇新聞有很大概率在多個網(wǎng)站上被發(fā)布,或者即使不同新聞對同一事件的表述不完全一致但相似度也很高,這樣的新聞則對于信息挖掘、關(guān)系抽取意義不大,因此這種多余的相似文本應(yīng)該被去除。最后計算各個簇與積極樣例集合之間的距離,選出差異最大的簇,將該簇中的文本標記為消極樣例。
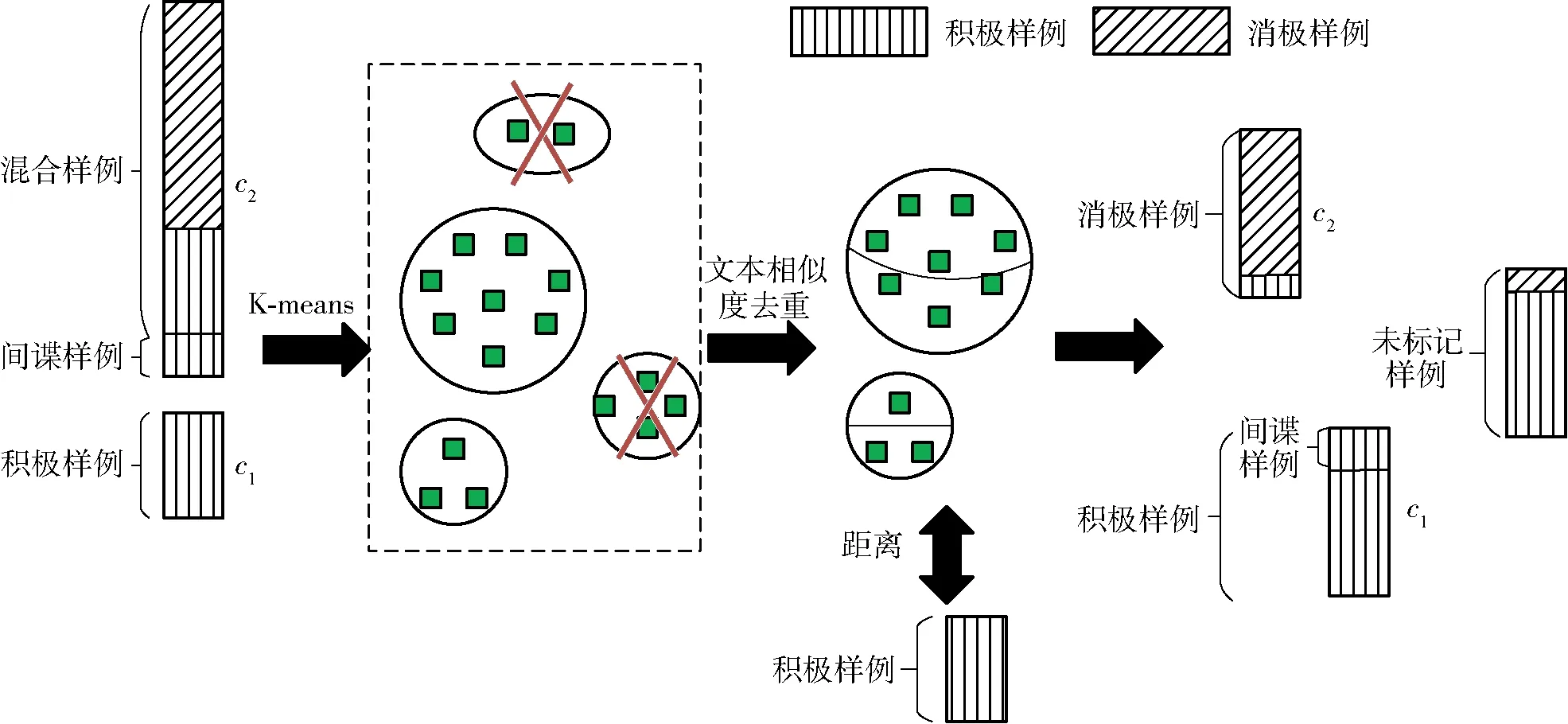
圖1 第1步的過程演示Fig.1 Process demonstration of the first step
圖1中,采用K-means算法進行聚類,由于傳統(tǒng)的K-means算法假設(shè)每個樣本對最終聚類結(jié)果的貢獻程度一樣,未考慮關(guān)鍵特征對于聚類過程的影響,導致聚類準確率低。所以應(yīng)用上述特征加權(quán)處理改進方法獲得的特征能夠有效解決這一問題。
此外,還需要去除重復文本以提高分類效果和文本質(zhì)量,例如,對于同一事件不同描述的新聞文本,其文本相似度超過閾值時認為不同文本描述了同一事件,只保留最近時間報道的且信息最豐富的新聞文本;對于同一涉事食品在不同地區(qū)發(fā)生的食品安全事件,根據(jù)文本的“發(fā)生地點”特征對應(yīng)的地點詞匯是否相同來判斷是否屬于同一個事件。所以刪除包含間諜樣例的簇后在剩下的各個簇中分別利用文本提取特征來計算文本相似度,得到的向量形式表示的文本之間以空間距離體現(xiàn)語義相似度[24]。對于向量化后的特征,采用最常用的余弦相似度計算方法,表示為
(8)
式中xj——第j個待計算文本的向量
相似度越大,說明距離越小,文本越相似。
(2)建立分類器
第2步,根據(jù)積極樣例的集合P、消極樣例的集合N和未標記樣例的集合U建立最終的分類器。具體過程如下:①將所有的間諜樣例S都放回到積極樣例集合P中。②給積極樣例集合P中的每個文檔xi都分配固定的類標簽c1,即y(c1,xi)=1,且在每次迭代EM最大期望算法時,標簽不再改變。③為消極樣例集合N中的每個文檔xj都分配初始類標簽c2,即y(c2,xj)=0,且在每次迭代EM算法時,標簽都會改變。④在未標記樣例集合U中的每一個文檔xk都沒有被分配標簽,但是在EM算法的第一次迭代后,將會分配給每個文檔一個概率標簽。在隨后的迭代過程中,集合U將通過其新分配的概率類型參與EM算法,例如y(c1,xk)。⑤在集合P、N和U中重復運行EM算法直至收斂。
當EM算法結(jié)束時,將生成最終的分類器。本文將用該分類器分類食品安全事件并進行性能評估,用于后續(xù)的實體關(guān)系抽取工作。
1.2 基于依存分析的實體關(guān)系抽取
基于依存分析的食品安全事件實體關(guān)系抽取的目標是從大規(guī)模的食品安全事件新聞文本中抽取出食品安全事件中的實體及實體之間(或?qū)嶓w與屬性值之間)的語義關(guān)系,其中實體涉及到涉事食品、涉事公司、涉事人員等;屬性包括產(chǎn)品規(guī)格、商標形式等。面對復雜多變的中文新聞表達形式,關(guān)系抽取模型需要具有廣泛性和強的魯棒性才能夠達到好的抽取效果。
(1)關(guān)系識別
動詞及動詞短語、名詞及名詞短語和位于它們前面或后面相鄰的說明性修飾符均可作為關(guān)系詞或關(guān)系短語。關(guān)系可以位于句子中的任意位置[16,25],能夠根據(jù)模型和候選關(guān)系與句子其他成分之間的依存關(guān)系來確定元組關(guān)系。一般情況下,主語和謂語之間會通過依存關(guān)系“SBV”等來連接,謂語和賓語之間會通過依存關(guān)系“VOB”、“POB”等來連接。此外,還存在一種特殊的偏正結(jié)構(gòu),如“食藥監(jiān)局長×××”一句中,“局長”、“食藥監(jiān)”和“×××”均為名詞,“局長”作為“食藥監(jiān)”和“×××”之間的關(guān)系,與它們之間的依存關(guān)系均為“ATT”,可抽取出實體關(guān)系三元組(食藥監(jiān),局長,×××)。
(2)實體和屬性識別
實體和屬性識別是為了識別出每個待處理句子中的實體對(arg1,arg2),arg1和arg2參數(shù)分別表示主語和賓語,arg1為實體,arg2為與arg1之間存在關(guān)系的另一個實體或者arg1具有的某種屬性的屬性值[3]。本文應(yīng)用LTP工具分析待處理的文本,將所有句子依次進行分詞、詞性標注、命名實體識別和依存句法分析。還引入了涉事食品、發(fā)生原因、涉事企業(yè)和發(fā)生地點4個關(guān)鍵詞典輔助分詞,提高分詞準確率和召回率,進而提高整體抽取性能。其中命名實體識別能夠識別出句子中的所有可能實體,作為實體關(guān)系三元組的候選實體,依存句法分析對句子成分及各成分之間的語義關(guān)系進行分析,確定三元組成分。
接下來計算任意2個候選實體之間存在的實體數(shù)量和其他詞語的數(shù)量。文獻[14,26]經(jīng)過統(tǒng)計和實驗研究發(fā)現(xiàn),在候選實體組成實體對后,限定每個實體對之間存在的其他候選實體數(shù)目不超過4個,詞匯總數(shù)目不超過5個時,得到的三元組的準確率達到最高。這是因為句子中2個實體距離越遠,兩者之間存在關(guān)系的可能性就越小。根據(jù)依存分析的結(jié)果,檢測關(guān)系詞或關(guān)系短語所依賴的實體。
基于模型的實體關(guān)系抽取,是將句子的依存分析結(jié)果和基于中文語法規(guī)則的模型進行匹配完成抽取工作的。本文依據(jù)大規(guī)模新聞文本的依存分析結(jié)果中所包含的語義特征提出了中文關(guān)系抽取模型ORE_Models,包含ORE_Model1、ORE_Model2、ORE_Model3,具體結(jié)構(gòu)如圖2所示,圖中各參數(shù)的含義如表3所示。

表3 ORE_Models模型中參數(shù)含義Tab.3 Meaning of parameters in model ORE_Models
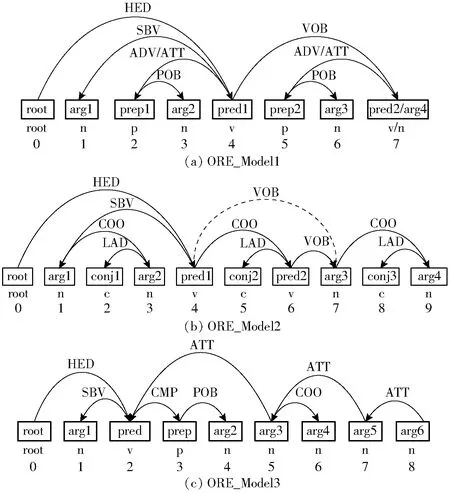
圖2 中文關(guān)系抽取模型ORE_ModelsFig.2 Chinese relation extraction model ORE_Models
在圖2中,關(guān)系抽取模型ORE_Model1多用于抽取以動詞作為關(guān)系和存在介賓關(guān)系時的句子形式;關(guān)系抽取模型ORE_Model2多用于抽取主語,或謂語,或賓語中存在一個或多個并列情況的句子形式,其中pred1和arg3 2個節(jié)點之間由有方向的實線和虛線表示的關(guān)系所連接,但實線和虛線有且僅有一種出現(xiàn),即在一個句子中不可同時存在;關(guān)系抽取模型ORE_Model3多用于抽取存在動補結(jié)構(gòu)、偏正結(jié)構(gòu)時的句子形式。每個待處理的中文句子的依存分析結(jié)果只要與模型的某一部分正確匹配且匹配成功的部分中存在可抽取的內(nèi)容,就會以實體關(guān)系三元組的形式輸出。其中節(jié)點及關(guān)系存在情況與可抽取出的實體關(guān)系三元組的情況如表4所示。為了便于展示,僅在表4的可抽取出的實體關(guān)系三元組中展示了實體和關(guān)系,但在實際抽取過程中還保存了與實體存在“ATT”等依存關(guān)系的實體修飾詞匯。
表4中的“-”表示2個節(jié)點的連接組合,共同組成三元組的主語或者謂語,“/”和圖2中的“/”均表示“或者”的含義,即兩種情況均可能出現(xiàn)(但不可能同時出現(xiàn))。從表4中可以發(fā)現(xiàn)模型ORE_Models覆蓋了多種句子形式,能夠處理具有多變的語法表達方式的新聞文本。
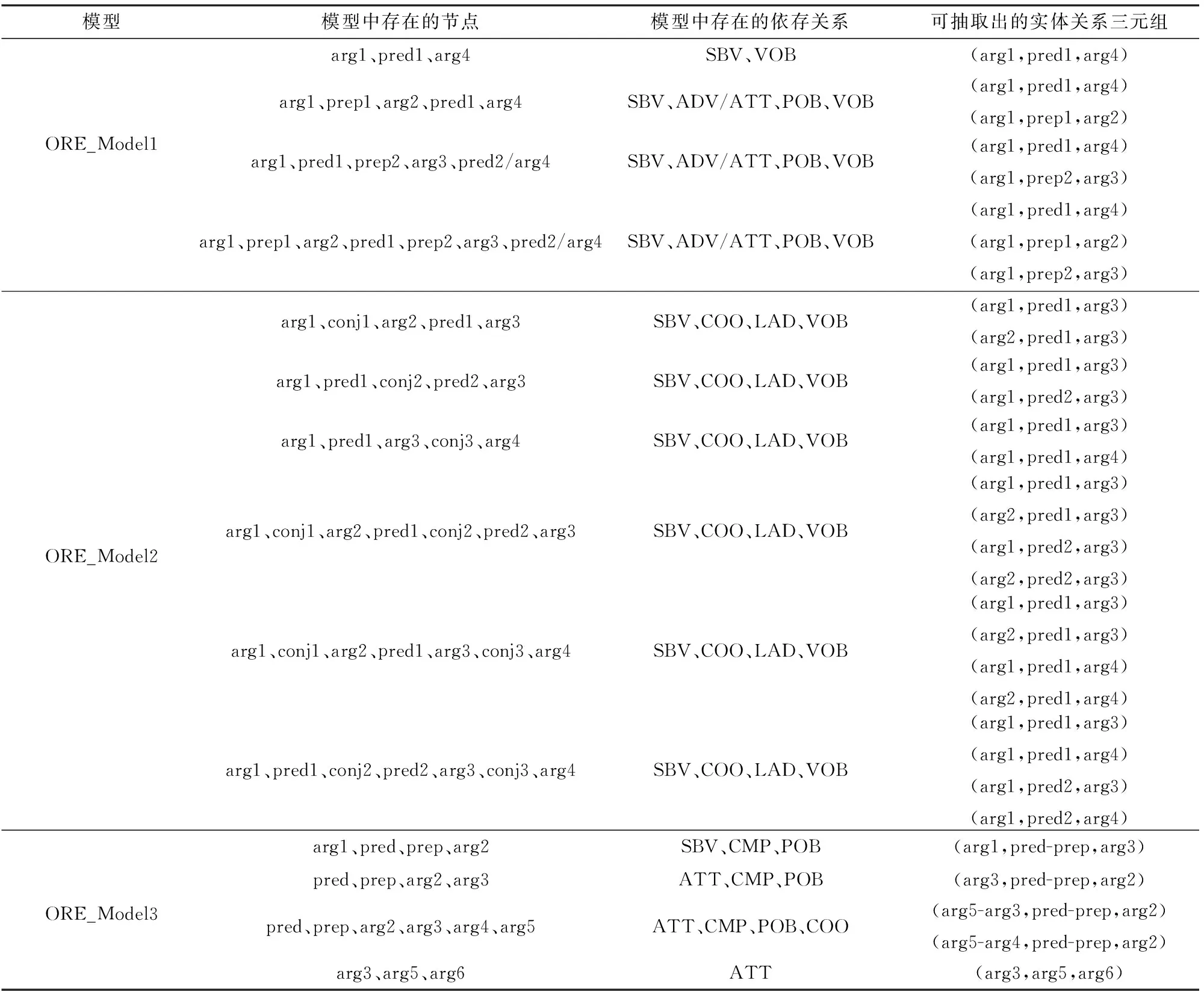
表4 ORE_Models中節(jié)點及關(guān)系存在情況不同時的可抽取的實體關(guān)系三元組Tab.4 Extractable entity relation triples with different nodes and relations in ORE_Models
例如,句子“上海市食藥監(jiān)局查封了一批毒雞蛋”的依存分析結(jié)果如圖3所示。從圖3中可以得到候選實體有“上海市食藥監(jiān)局”(機構(gòu)名稱)、“毒雞蛋”,關(guān)系詞為“查封”,它們之間的依存關(guān)系符合模型ORE_Model1的分析,最后可抽取出實體關(guān)系三元組(上海食藥監(jiān),查封,一批毒雞蛋)。
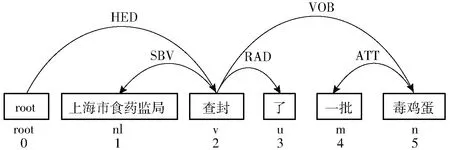
圖3 實例1的句子依存分析結(jié)果Fig.3 Sentence dependency parsing results of example 1
再如句子“上海市食藥監(jiān)局發(fā)布最新一期食品安全抽檢信息,通報了5批次不合格的食用性農(nóng)產(chǎn)品。”的依存分析結(jié)果如圖4所示。從圖4中可以得到候選實體有“上海市食藥監(jiān)局”(機構(gòu)名稱)、“信息”和“農(nóng)產(chǎn)品”;關(guān)系詞為“發(fā)布”和“通報”,且在句子中是并列關(guān)系。“上海市食藥監(jiān)局”作為句子的主語分別通過“發(fā)布”和“通報”2個關(guān)系詞與作為句子賓語的“信息”和“農(nóng)產(chǎn)品”連接,“5批次”、“不合格”和“食用性農(nóng)產(chǎn)品”之間依次存在定中關(guān)系。實體和關(guān)系詞之間的依存關(guān)系符合模型ORE_Model1、ORE_Model2和ORE_Model3的分析,最后可抽取出實體關(guān)系三元組(上海市食藥監(jiān)局,發(fā)布,最新一期食品安全抽檢信息)、(上海市食藥監(jiān)局,通報,5批次不合格的食用性農(nóng)產(chǎn)品)和(5批次,不合格,食用性農(nóng)產(chǎn)品)。
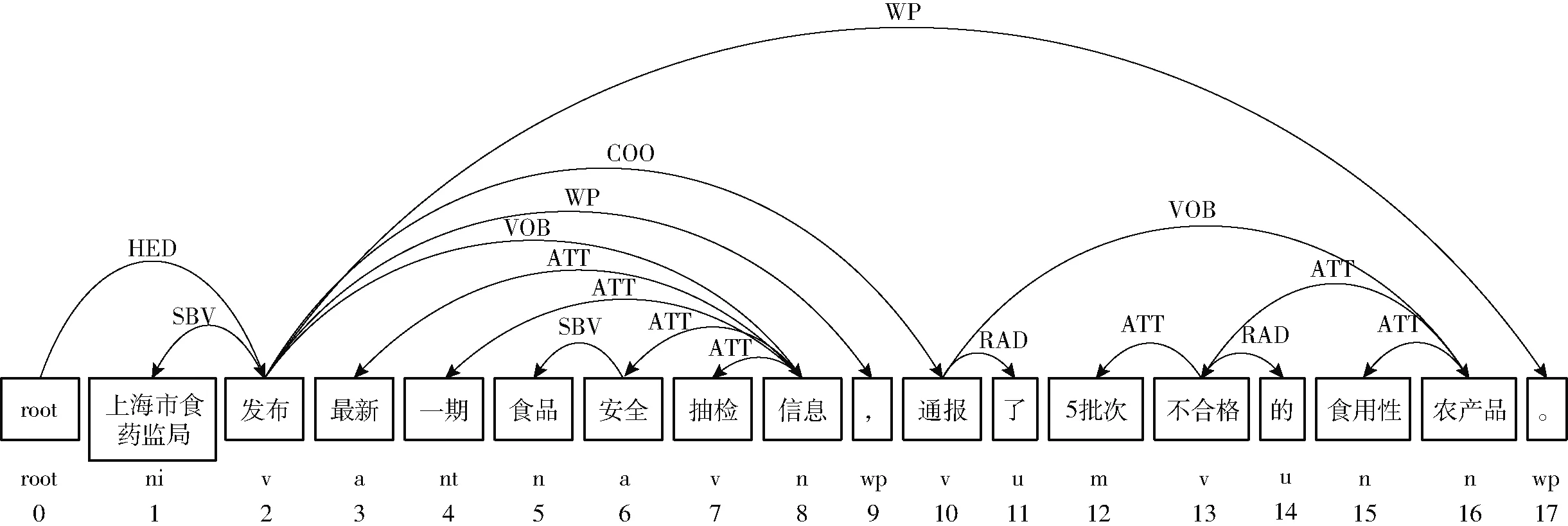
圖4 實例2的句子依存分析結(jié)果Fig.4 Sentence dependency parsing results of example 2
上述2個句子均是關(guān)于“上海市食藥監(jiān)局”相關(guān)的信息,基于實體關(guān)系抽取模型ORE_Models從不同的描述文本中抽取出了不同的實體關(guān)系三元組,這些三元組共同表述了同一主體的信息且不同三元組之間也存在關(guān)聯(lián)關(guān)系。文本中一般包含較多數(shù)量的句子,能夠抽取出大量的實體關(guān)系三元組。這些三元組高度概括了文本的主要內(nèi)容且形式精煉,梳理后能幫助快速了解文本的知識脈絡(luò),得到目標信息。
2 結(jié)果與分析
2.1 實驗設(shè)計
實驗所用的數(shù)據(jù)是利用爬蟲技術(shù)爬取的近5年全國范圍內(nèi)各大新聞門戶網(wǎng)站(包括騰訊新聞中心、搜狗新聞中心、百度新聞中心和新浪新聞中心等多個網(wǎng)站)上與食品相關(guān)的中文新聞文本,共75 214篇。這些中文新聞文本包含食品安全事件、與食品相關(guān)的非事件性新聞文本和其他領(lǐng)域的各類新聞文本,共同構(gòu)成了新聞文本語料庫,且不同類型文本的數(shù)量統(tǒng)計結(jié)果為:食品安全事件新聞文本40 427篇,與食品相關(guān)的非事件性新聞文本31 086篇,其他領(lǐng)域的各類新聞文本3 701篇。
(1)利用分類模型對語料庫中的所有文本進行分類。雖然PU學習是在含少量標記的積極樣例和大量未標記樣例情況下訓練分類器,但是為了與其他分類方法進行比較,仍需要額外做如下標記:手動標注了1 000篇食品安全事件新聞文本和1 000篇非食品安全事件的其他混合類型的新聞文本,將這2 000篇已標注的新聞文本作為數(shù)據(jù)集。隨機抽取其中的300篇食品安全事件新聞文本和300篇非食品安全事件新聞文本共600篇文本作為測試集,其余的1 400篇文本作為訓練集來訓練分類器。在測試過程中,更多關(guān)注的是準確率,其計算公式為
(9)
式中pc——分類器的準確率
Nr——正確分類的文本數(shù)量
Nclassifier——分類器分類的文本數(shù)量
(2)從分類得到的食品安全事件類別中隨機抽取1 000篇文本,用于測試模型ORE_Models在食品安全事件新聞文本上的實體關(guān)系抽取性能。由于自然語言處理工具的處理對象是完整的句子,所以利用正則表達式方法[22]按照“。”、“?”、“!”、“……”、“:”、“;”6種標點符號將這1 000篇文本分割成獨立的句子。
(3)從分割1 000篇文本獲得的句子中隨機選擇1 000個句子作為數(shù)據(jù)集news_dataset1進行實體關(guān)系抽取。注意,采用兩次隨機抽取,是為了在具有可操作性的數(shù)據(jù)量下降低新聞編輯者的語法習慣對抽取模型性能的影響,使結(jié)果具有更高的可靠性,從而更好的對食品安全事件進行實體關(guān)系抽取,有效地解決難以快速獲取事件主要內(nèi)容、脈絡(luò)聯(lián)系不明確等問題。
(4)再次從語料庫中隨機抽取1 000篇文本,這1 000篇文本中包含食品安全事件在內(nèi)的多種混合類型的新聞。采用與得到數(shù)據(jù)集news_dataset1同樣的方法得到包含1 000個句子的數(shù)據(jù)集news_dataset2,該數(shù)據(jù)集用來評估模型ORE_Models對開放領(lǐng)域混合類型的新聞文本的抽取性能,從而驗證模型ORE_Models的可移植性,使其能夠應(yīng)用于更多的研究領(lǐng)域。
在本實驗中,由兩名專業(yè)人員根據(jù)文獻[12]的標注策略分別標注句子中的實體關(guān)系元組,然后經(jīng)過匯總、糾正后,最終確定數(shù)據(jù)集應(yīng)該被正確抽取的結(jié)果。本文的評估側(cè)重于句子級別的抽取,實驗后,將實驗抽取結(jié)果與手動標注的結(jié)果進行比較,并通過3個度量標準對實體關(guān)系抽取結(jié)果進行評估,分別是準確率(P)、召回率(R)和F值(F)。P、R、F的計算公式為
(10)
(11)
(12)
式中r——模型ORE_Models抽取出的正確元組的數(shù)量
a——模型ORE_Models抽取出的所有元組的數(shù)量
W——語料庫中實際存在的元組的數(shù)量
2.2 結(jié)果及對比分析
2.2.1食品安全事件新聞文本的分類結(jié)果
為了驗證PU學習方法的食品安全事件新聞文本的分類結(jié)果,首先只保留訓練集中的200個標注的食品安全事件標簽,其余數(shù)據(jù)的標簽均隱藏(即相當于未標記數(shù)據(jù))。然后在訓練集中訓練分類模型。最后,將得到的分類模型在測試集中進行測試,得到最終的分類結(jié)果。為了進行實驗對比,在所有數(shù)據(jù)均保留了完整標注的相同數(shù)據(jù)集下,分別采用支持向量機(SVM)、邏輯回歸算法(Logistic regression)、隨機森林(Random forest)[27-28]3種監(jiān)督分類方法進行訓練,將得到的結(jié)果進行比較分析。實驗結(jié)果為:本文的分類器準確率達到82.35%,SVM準確率為75.94%,Logistic regression準確率為82.88%,Random forest準確率為83.49%。
上述結(jié)果顯示SVM的準確率在4個分類器中是最低的,Random forest分類器的準確率是最高的,但是僅比本文的分類器高出1.14個百分點。其次是Logistic regression分類器,比本文的分類器高出0.53個百分點。從這些數(shù)據(jù)中可以發(fā)現(xiàn),本文構(gòu)建的分類器準確率盡管不是最高的,但是達到了與其余3種監(jiān)督方法相似的效果,相比于這3種監(jiān)督方法需要完成的大量標注所需要的人力、時間的損耗,且在將大規(guī)模網(wǎng)絡(luò)文本全部進行手動標注幾乎不可能實現(xiàn)的前提下,半監(jiān)督分類方法更能滿足大規(guī)模數(shù)據(jù)分類研究的需要,并且降低了監(jiān)督方法中由于人的主觀因素引起的誤差,因此更適合應(yīng)用于大規(guī)模網(wǎng)絡(luò)文本的食品安全事件的分類。
將本文的分類器應(yīng)用于語料庫,共得到了37 901篇食品安全事件新聞文本。
2.2.2實體關(guān)系抽取的性能評估
從分類得到的37 901篇食品安全事件新聞文本隨機抽取1 000篇文本并分割成句子后,共得到24 015個完整句子。再按照2.1節(jié)中描述的步驟構(gòu)建數(shù)據(jù)集news_dataset1和news_dataset2。
為了評估食品安全事件新聞文本的實體關(guān)系抽取結(jié)果和混合類型新聞文本的實體關(guān)系抽取結(jié)果的質(zhì)量,得到ORE_Models抽取數(shù)據(jù)集news_dataset1和news_dataset2時的性能如表5所示。

表5 ORE_Models抽取不同數(shù)據(jù)集時的性能Tab.5 Performance of ORE_Models when extracting different datasets %
從表5可以看出,ORE_Models模型的準確率相對較高,很難有更大的改進余地,但是獲得高準確率的同時犧牲了部分召回率,使得召回率沒有達到與準確率接近的性能。
news_dataset1和news_dataset2數(shù)據(jù)集上的抽取性能相比,ORE_Models模型在食品安全事件新聞文本數(shù)據(jù)集news_dataset1上的準確率、召回率、F值均高于混合類型新聞文本數(shù)據(jù)集news_dataset2上的值,這說明ORE_Models更適用于食品安全事件新聞文本的實體關(guān)系抽取。但是在混合類型的新聞文本上的抽取性能也達到了較高的水平,與在食品安全事件新聞文本相比僅在準確率上降低了4.25個百分點,召回率上降低了3.41個百分點,F(xiàn)值上降低了3.79個百分點,與食品安全事件新聞文本的抽取效果之間的差距控制在了5個百分點之內(nèi),均未出現(xiàn)較大差異,表明了ORE_Models也可以應(yīng)用于開放領(lǐng)域的新聞文本抽取。
2.2.3實體關(guān)系抽取的性能對比
為了驗證模型ORE_Models的性能能夠滿足新聞文本關(guān)系抽取的需要,設(shè)計2組對比實驗:①ZORE系統(tǒng)、CORE系統(tǒng)與ORE_Models同時處理數(shù)據(jù)集news_dataset1。②ZORE系統(tǒng)、CORE系統(tǒng)與ORE_Models同時處理數(shù)據(jù)集news_dataset2。2組實驗的評估均對照同一標準結(jié)果進行判定。2組實驗結(jié)果如表6所示。
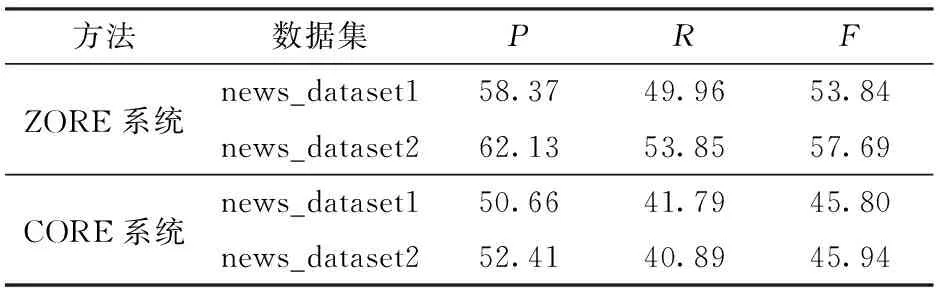
表6 ZORE系統(tǒng)、CORE系統(tǒng)抽取news_dataset1和news_dataset2的性能Tab.6 Performance of ZORE system and CORE system to extract news_dataset1 and news_dataset2 %
從表5和表6中可以看到,在數(shù)據(jù)集news_dataset1和news_dataset2上CORE系統(tǒng)的準確率、召回率和F值均是最低的,其次是ZORE系統(tǒng),各個性能最好的是ORE_Models。在news_dataset1數(shù)據(jù)集上,ZORE系統(tǒng)和CORE系統(tǒng)的各個指標均
表現(xiàn)出了類似的性能,幾乎沒有差異,這說明這2個系統(tǒng)都未對食品安全事件進行更加深入的抽取研究。雖然ZORE系統(tǒng)和CORE系統(tǒng)面向的是開放領(lǐng)域各類別的實體關(guān)系抽取,但是在news_dataset2數(shù)據(jù)集上,它們的性能仍低于ORE_Models,這表明ORE_Models雖然主要面向食品安全事件新聞文本,但是它同樣可以很好地處理開放領(lǐng)域的文本,體現(xiàn)了ORE_Models的有效性與可移植性。
對于抽取過程中出現(xiàn)的抽取錯誤問題或者未抽取出句子中存在的元組問題,主要是由以下幾方面引起的:NLP工具在分詞、詞性標注或者命名實體識別等過程中出現(xiàn)錯誤,存在未覆蓋的領(lǐng)域?qū)е聼o法正確處理句子,不能與模型匹配或匹配錯誤;新聞文本中存在復雜度很高或者口語化、不規(guī)范的句子,該類句子的依存解析在模型中未涉及到。
3 結(jié)束語
提出一種基于依存分析的食品安全事件新聞文本的實體關(guān)系抽取方法FSE_ERE,根據(jù)中文語法特性和句子的依存分析結(jié)果構(gòu)建了關(guān)系抽取模型,實現(xiàn)了無監(jiān)督的食品安全事件新聞文本的實體關(guān)系抽取。為了在高質(zhì)量的食品安全事件新聞文本上進行抽取工作,引入結(jié)合文本相似度算法和改進的特征加權(quán)方法的PU學習半監(jiān)督分類方法,對大規(guī)模網(wǎng)絡(luò)文本進行分類,準確率達到82.35%。FSE_ERE方法能夠從大規(guī)模的網(wǎng)絡(luò)文本中準確得到食品安全事件類別的新聞文本,且無需標記大量數(shù)據(jù)的類別;同時,實體關(guān)系抽取過程也打破了標注語料庫、預先定義關(guān)系類型等限制,可快速準確地抽取出文本中包含的各種信息,在食品安全事件新聞文本數(shù)據(jù)集上F值達到71.21%,在多類型混合新聞文本數(shù)據(jù)集上F值達到67.42%。FSE_ERE方法節(jié)省了大量的人力和時間,對于大規(guī)模網(wǎng)絡(luò)文本的信息統(tǒng)計分析具有重要意義,為中文的開放式實體關(guān)系抽取提供了新的思路。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
甘肅教育(2020年8期)2020-06-11 06:10:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
