采用行程跟蹤的二值圖像去毛刺算法
2020-07-23 08:57:10鐘倫超
武夷學院學報 2020年6期
鐘倫超, 何 川
(1.黃山學院 教務處,安徽 黃山 245041;2.黃山學院 信息工程學院,安徽 黃山 245041)
自1967年Blum提出骨架的概念以來,曲線骨架提取成為多領域研究的熱點。例如指紋識別方法通常是在對原始圖像進行一系列預處理之后,利用細化處理得到圖像骨架,然后進一步運用其中的細節特征點(起點、終點、結合點和分叉點)進行指紋鑒別。二值圖像細線化技術在圖像分析與形狀描述中是一個非常重要的變換,骨架是圖像幾何形態的重要拓撲描述,是進行圖像目標的特征提取[1]、模式識別[2]等應用的前提,在很多研究領域及生產生活中應用廣泛,主要用于字符識別[3]、指紋識別[4]、工程零件骨架結構識別提取[5]等,通過圖像的細化處理將圖像中的需要識別的部分進行細化,可以很清晰地得到需要的圖像“骨架”,提取出所需目標物的單像素輪廓。但是,圖像細線化帶來的問題是處理后的圖像在此“骨架”的線段分段處產生多余的點和線段,我們把這些多余的點和線稱為“毛刺”[6-8]。
毛刺在圖像中是多余的,并且會影響圖像主要部分的使用。針對去毛刺過程可能存在去除圖像結構主體部分的缺陷,寧亞輝等人提出改進的基于模板去除骨架毛刺方法[9]。該方法首先對目標點周圍像素進行統計,找到對應像素符合的類型,再結合傳統去毛刺方法中的毛刺長度設定,對毛刺進行去除。郭斯羽等人提出一種植物葉片圖像骨架提取的去毛刺方法[10],通過設定的兩個指標對骨架上的毛刺進行判斷和去除。安世全等人提出一種基于Zhang并行細化算法進行細化,在其基礎上通過改進的毛刺消除算法滿足保留較長分支為骨架主體信息的原則,最大程度地保持裂縫骨架主體信息[11]。實驗結果表明上述文獻提出的方法都可以減少圖像噪聲和毛刺,但是無法保證圖像的有效部分的完整性。通過大量的實驗程序編寫及測試,提出去毛刺算法,針對毛刺的存在問題,利用細化圖像中的交叉點和端點來確定毛刺的位置,通過端點對交叉點進行搜索,存儲搜索路徑,記錄該跟蹤路徑的方向鏈碼,通過設定毛刺長度門限值對毛刺部分進行去除,得到效果滿意的細化圖像。
1 去毛刺算法描述
基于行程跟蹤的去毛刺算法,實質上就是對目標像素的鄰近像素進行掃描,以目標像素為起始點對毛刺部分進行追蹤,通過事先設定好的長度門限,定義毛刺的長度,判斷毛刺位置,從而進行有效去除。通過對毛刺的特性進行分析,可以得出毛刺介于交叉點和端點之間,掃描毛刺的方式有兩種:(1)以端點作為起始點,通過行程跟蹤在其設定長度門限范圍內尋找交叉點,定義毛刺長度,從而找出毛刺所在;(2)以交叉點為起始點,對其連通域內的8-鄰域像素進行像素值判斷,并通過路徑跟蹤以及毛刺長度,判斷出毛刺位置。本文僅詳細介紹以端點為起始點尋找其連通域內的交叉點,進行毛刺的檢測和標記存儲并有效去除。
算法步驟:首先判斷給定的圖像是否為二值圖像,如果不是,對原圖像進行二值化處理,此時的圖像可能存在很多噪聲點,對圖像進行去噪及一系列形態學預處理,然后對給定進行細線化操作,得到初步的圖像目標物骨架,細線化處理的圖像會產生很明顯的毛刺現象。通過行程跟蹤對毛刺像素進行檢測和標記存儲,再對其進行有效去除,得到輪廓光滑且目標物結構不變的新圖像。
(1)對原圖進行去噪等預處理,采用MATLAB軟件自帶的二值化函數對給定圖像進行二值化處理,得到二值圖像;
(2)對得到的二值圖像進行細線化處理,得到像素寬度為1的目標物輪廓圖,從而提取出圖像目標物特征骨架;
(3)通過掃描,尋找到圖像中所有的端點和交叉點,對端點和交叉點進行標記并存儲,設定毛刺長度門限值L,以端點為起始點在其連通域內進行目標物行程跟蹤,直到尋找到交叉點,終止運算,存儲行程中的每一個像素點。如果跟蹤的步數M小于設定的毛刺門限值L,則該段路徑為毛刺;反之,跟蹤步數大于設定的毛刺長度L,則默認該段路徑為圖像的有效結構;
(4)通過步驟(3)確定毛刺后,根據行程跟蹤過程中存儲起來的像素點,將符合毛刺定義的端點和其對應的交叉點之間的像素去除;
(5)得到清晰的圖像骨架,結束運算。
算法流程如圖1所示。
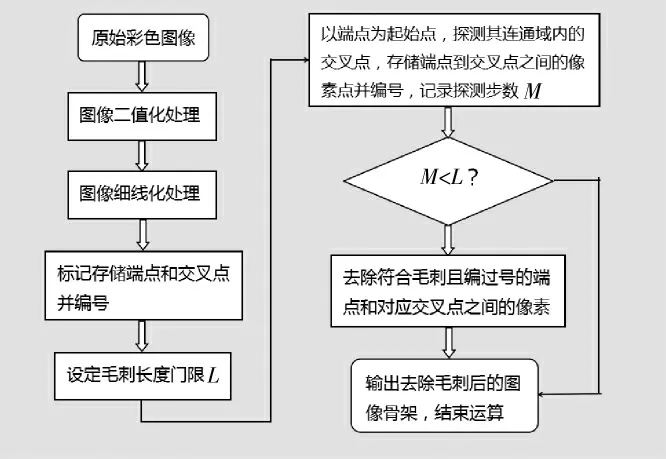
圖1 去毛刺算法流程圖Fig.1 Flow chart of deburring algorithm
2 二值圖像轉換及圖像骨架的提取
采用MATLAB R2015a軟件DIP工具箱函數im2bw使用閾值變換法把灰度圖像轉換成二值圖像:

式中:I為原圖像;J為轉化后的二值圖像。
隨即采用bwmorph函數對原二值圖像進行細線化處理,提取圖像中目標物的骨架:
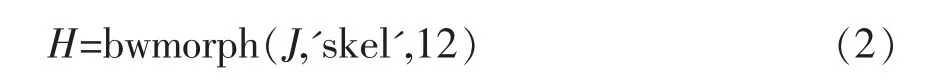
式中:J為二值圖像;運算次數n為12;H為骨架圖像。
3 毛刺的定義
3.1 端點、交叉點及毛刺模型
為了確定細線化所引起的毛刺的位置所在,需要先找到產生毛刺的根源,即交叉點和端點。不難發現,毛刺一定是始于交叉點且止于端點,存在于端點和交叉點之間。如圖2所示,對端點、交叉點和毛刺作形象說明。

圖2 端點、交叉點和毛刺示意圖Fig.2 Diagram of endpoints,intersections and burrs
圖中,可以看到A點和B點處在交叉位置,則定義A點和B點為交叉點,C、D、E3點為端點,從圖中可以看出,毛刺存在于端點和交叉點之間,則a、b、c3段都有可能是毛刺,但是考慮到有些毛刺可能是圖像的有效部分,不可去除,例如c段。因此,我們需要設置毛刺的長度,合理地對毛刺進行去除,保留圖像的有效部分。
3.2 端點、交叉點標記及存儲
3.2.1 端點
規定目標像素為黑色,像素值為1,背景色像素值為0。設N8(P0)為P0的8個鄰域中數值為1的像素個數。當P0=1,N8(P0)=1,即目標像素為黑色,它的8個鄰域中僅有1個點為黑色,則P0為端點,如圖3所示,P0為掃描到的目標像素。當P0的3×3鄰域滿足(a)~(h)8種情形中的任意一種時,則P0為端點。此時我們對P0點進行標記并存儲。
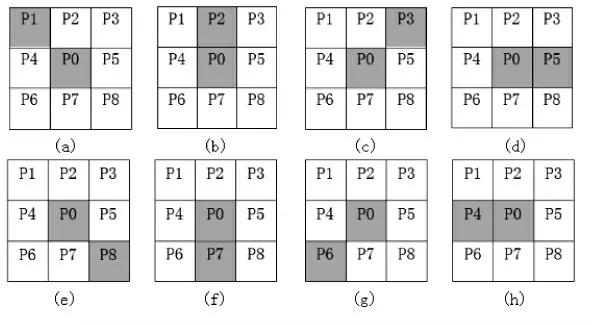
圖3 滿足端點性質的P0鄰域像素分布Fig.3 The P0 Neighborhood pixel distribution satisfying the endpoint property
3.2.2 交叉點
如果當前掃描到的目標像素P0,像素值為1,我們定義,當P0=1,3<N8(P0)時,該點為交叉點。我們可以從圖5看出,如果P0點的8-鄰域中僅有兩個點像素值為1,則該點為線段中一點,不能視為交叉點。當P0點的8-鄰域中有三個或超過三個點像素值為1,則該點為交叉點,即為毛刺產生點。如圖4為文字識別細線化的圖像,可以看出,該圖中有6處交叉點。標記所有的交叉點,并進行存儲。
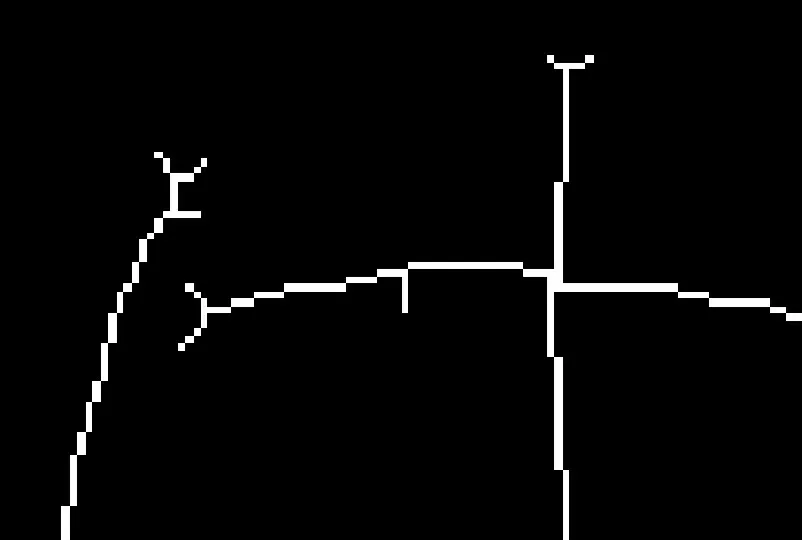
圖4 交叉點示意圖Fig.4 Cross point diagram
3.3 毛刺定義
通過大量研究可知,毛刺必然存在于端點和交叉點之間,因此,對端點和交叉點進行標記和存儲,并對每個端點和對應的交叉點進行編號,使得從某一端點進行行程跟蹤后,對其連通域內尋找到的交叉點進行對應,確定毛刺的位置,但是并不是所有的端點和交叉點之間的線段都是毛刺,我們通過限制毛刺長度門限來定義毛刺,確保圖像有效部分不被剔除。
4 基于行程跟蹤的毛刺去除
4.1 行程跟蹤
掃描全圖,以掃描到的端點P0為起始點,跟蹤P0的8-鄰域,如果掃描到黑色點,則將該黑點存儲起來,再以該黑點為起始點進行掃描,則繼續掃描如圖5所示,圖(b)為圖(a)的部分像素分布圖。
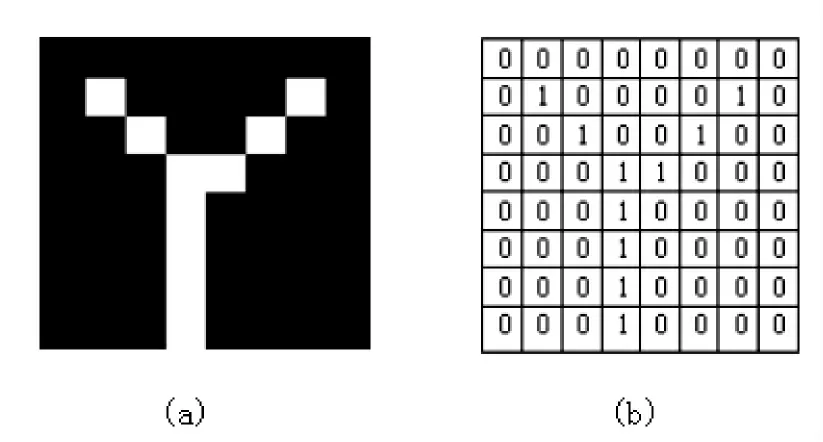
圖5 毛刺像素分布示意圖Fig.5 Schematic of burr pixel distribution
圖為8×8的區域,0代表黑色像素點,1代表白色像素點,跟蹤示意圖如框圖6所示。(1)從端點(2,2)開始搜索,根據交叉點定義,(4,4)點為交叉點,結束運算,該段路徑可能為毛刺;(2)從端點(2,7)開始搜索,直到交叉點(4,5)結束搜索,該段路徑也可能為毛刺。(3)存儲兩段路徑的所有有效點。

圖6 毛刺跟蹤流程圖Fig.6 Flow chart of burr tracking
4.2 毛刺去除
設定毛刺長度門限值L,標記存儲細線化圖像的所有端點及交叉點,其次判斷P0點的8-鄰域像素值為1的個數:如果N8(P0)=0,則該點為孤立點,結束運算;如果N8(P0)=1,則P0為端點,進行跟蹤,此時步數M=1,M=M+1,再以P0的8-鄰域內的點作為起始點,進行跟蹤,直至尋找到起始點連通域內的交叉點,結束運算。若M>L,即搜索路徑長度大于毛刺長度門限值,停止運算;若M<L,直至找到最近的交叉點。此時將存儲的起始點與尋找到的交叉點一一配對;如果搜索步數小于L,則該段路徑為毛刺,去除端點和對應的交叉點之間的像素;反之,該段路徑為圖像有效結構,不做處理。
4.3 實驗過程分析
如圖7(a)為一張簡單的線段圖,通過此圖像的操作來體現文中算法的處理結果。利用細線化技術對其進行骨架圖像提取,圖7(b)為細線化帶有毛刺的圖像,此時,標記存儲圖(b)中所有的交叉點和端點,如圖(c)(d)分別為提取的交叉點和端點,通過以端點為起始點搜尋其連通域內的交叉點,并存儲搜索路徑中所有的白色像素,通過路徑步長M和定義的毛刺長度L進行比較,去除符合毛刺定義的路徑內的所有像素即可,毛刺處理效果如圖7(e)所示。

圖7 行程跟蹤去毛刺算法處理效果Fig.7 Processing effect of stroke tracking deburring Algorithm
5 實驗結果仿真與分析
為了更好地驗證基于行程跟蹤的去毛刺算法在實際應用中的效果,以車牌骨架提取和文字骨架提取為例,對處理前后的圖像進行對比,分析去毛刺算法的特點和優勢。
圖8(a)為車牌的原始彩色圖像;圖8(b)為車牌二值化并取反的圖像;圖8(c)為二值圖像的細線化處理圖像,可以清晰的看出,圖像中出現了很多影響圖像美觀的毛刺,這些毛刺有的存在于線段中部,有的存在于線段尾部,這兩種情況的毛刺都是產生于交叉點,結束于端點;圖8(d)為本文算法處理的結果,通過與圖(c)進行比較,我們可以得出,本文基于行程跟蹤的去毛刺算法對處理細化圖像中的毛刺有著明顯的效果。

圖8 車牌骨架提取去毛刺效果圖Fig.8 The deburring effect diagram of license plate skeleton extraction
圖9為文字骨架提取過程中毛刺去除過程。圖9(a)為漢字“中國”二值化后的圖像;圖9(b)為車牌細線化處理圖像,處理結果帶來了很多毛刺;圖9(c)為本文算法處理的結果,毛刺被有效去除。通過實驗結果可以看出,“國”字右下角延伸出來的“橫”并沒有被當成毛刺去除,可見本文算法有效保證了圖像的骨架完整性。
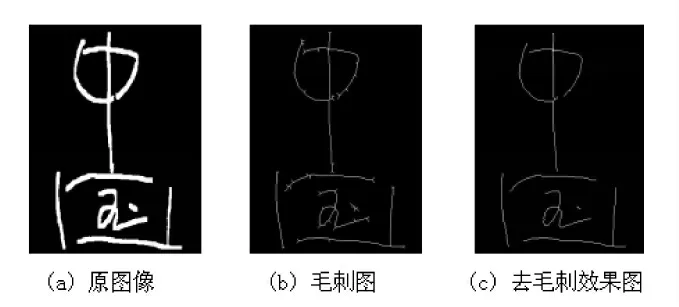
圖9 文字骨架提取去毛刺效果圖Fig.9 Image of text skeleton extraction deburring
圖8(d)和圖9(c)的實驗結果是在Intel(R)Pentium(R)CPU G2030(3.00 GHz)、內存4G的微機上采用MATLAB R2016b軟件編程實現的,算法運行時間分別為643和596 ms,完全滿足圖像處理在實際應用中的時間要求。
6 結束語
二值圖像細線化算法應用廣泛,其運算結果不可避免會產生影響圖像質量的毛刺。本文提出基于毛刺行程跟蹤的去毛刺算法,通過分析毛刺的規律、特點、性質,運用交叉點和端點定位毛刺,對細線化圖像中毛刺的有效去除。該算法能夠在不改變圖像連通性條件下,保持圖像有效部分的基本骨架,同時有效去除二值圖像細線化處理帶來的毛刺,改善了圖像視覺質量。
