物聯網邊緣計算服務容災算法分析與驗證
2020-07-20 06:16:02郭榮佐
計算機工程與設計 2020年7期
黎 明,李 露,郭榮佐
(四川師范大學 計算機科學學院,四川 成都 610101)
0 引 言
有限的網絡帶寬、云計算能力的不足已經無法滿足物聯網應用的低延遲要求[1],新興的邊緣計算是其有效解決方案[2]。然而,邊緣服務的可靠性是亟待解決的問題,服務可靠性的重要方面,就是服務數據的容災特性[3]。為提高服務的可靠性,以克服邊緣服務的不穩定性,就需要提高其服務的容災特性。
國內外研究者們對邊緣計算的可靠性研究[4-6],在小范圍的故障時可提高系統可靠性,而對地震、洪災等不可抗災難則是無效的。近年來,研究者們研究了基于集中式云計算的容災。Alexander Lenk等[7]提出了一種將云中的分布式系統復制到另一個云的新方法。Yu Wan等[8]設計了一種用于備份HDFS數據的系統,能夠以高速實現客戶端與遠程服務器之間的備份和恢復。Wang等[9]分析了云托管企業應用程序的災難恢復,提出一種調度算法。由此,現有研究主要針對集中式云計算中心而建立一套備份容災系統[10],但物聯網邊緣計算的邊緣服務器較密集,必須研究適合于物聯網邊緣計算特點的容災方案和容災算法。
綜上,為解決物聯網邊緣計算的服務容災問題,以確保邊緣服務器上的數據安全性,提出一種基于站點協作的容災方案,并對該容災方案的算法進行設計。同時,通過多臺虛擬機模擬邊緣服務器,搭建一個小型容災系統,對所提出的容災算法的執行延遲時間以及系統可靠性與增加中間件的方案進行比較,突出本文算法的優越性。
1 物聯網邊緣服務容災架構
物聯網概念從提出到應用,其體系結構亦在不斷進行演化和變遷,僅集中式物聯網已由5層系統結構演變為三層模式,又由三層向多層模式轉化。在集中式三層/多層物聯網體系結構中,感知層數據通過網絡層傳輸到云中心進行處理;而云中心存儲能力不足、骨干網絡帶寬需求高等問題,已成為物聯網發展和應用的瓶頸。
隨著邊緣計算概念的提出和不斷發展,以使物聯網由集中式向邊緣計算模式進化。物聯網邊緣計算在靠近感知層增加邊緣服務節點,能夠對大部分數據進行處理、卸載與計算任務調度等,從而使車聯網、增強現實和工業物聯網等延遲敏感型應用成為可能。此外,通過靠近用戶的邊緣服務節點處理數據,減少傳到云中心的數據流量,從而降低云中心數據存儲量和減少網絡帶寬等。物聯網邊緣計算的邊緣服務容災是針對邊緣服務節點層,通過邊緣服務節點間協作而成為一個自組織的容災子系統,以實現系統遭遇區域性災害時的保護數據,同時,提高邊緣服務的可靠性、延伸服務的連續性。因此,增加邊緣服務節點后的物聯網邊緣計算體系結構,如圖1(a)所示。
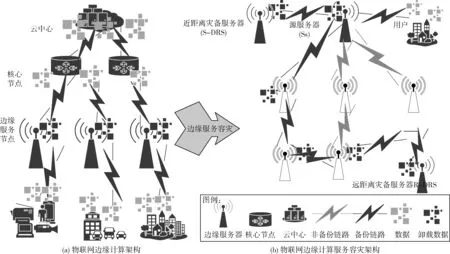
圖1 物聯網邊緣服務容災架構
物聯網邊緣計算的邊緣服務容災后,容災體系結構如圖1(b)所示。容災組成架構中的源服務器(source server,Ss),在用戶購買容災服務時,由通信人員指定,主要為用戶提供相關服務,并將用戶數據同步或異步復制到災備服務器;近距離災備服務器(short-range disaster recovery server,S-DRS),由Ss根據相鄰服務器的鏈路情況選擇,正常情況下,Ss將數據同步復制到S-DRS,保證在節點或網絡故障時RPO、RTO接近0,Ss故障時,S-DRS 接替其工作,具體如何切換到備用服務器不是本項工作的內容,可參考Ayari等[11]的研究;遠距離災備服務器(remote disaster recovery server, R-DRS)通過相鄰最遠的服務器之間傳遞Req數據報協作得到,用于異地保存Ss的數據,在發生區域性災難時,如地震、洪水、停電等,能夠根據用戶需求,不同程度地保護數據不被丟失。S-DRS 和R-DRS同時也作為其他用戶的Ss,每個邊緣服務器處于熱備用狀態,不會浪費邊緣服務器的計算能力。
2 容災算法
基于提出的容災架構,設計了相應的容災算法。本部分從DR(disaster recovery)數據報的格式、算法描述兩方面對算法進行設計。
2.1 DR數據報格式
DR數據報是本文容災算法中數據報的總稱,如表1所示,DR數據報中各個部分的含義如下:
Sid:源服務器的IP地址。Sid與普通網絡的IP地址不同,當搜尋R-DRS時,中間的邊緣服務器不能修改Sid,僅符合Sid的邊緣服務器返回ReqACK應答數據報,則返回該應答的邊緣服務器即為R-DRS。
Did:目標IP地址。
Type:DR數據報的類型,共有以下4種。
Message:普通的數據報。
ASK:鄰接服務器間間歇互發的測試服務可達性的問候數據報,并以此更新服務器的鏈路信息表。
Req:尋找R-DRS時發送的詢問數據報。
ReqACK:對于Req數據報,若當前服務器滿足容災的距離要求,則返回ReqACK應答數據報給源服務器。
Time:DR數據報發送的時間戳。
Distance:當前邊緣服務器到Ss的鏈路距離。
Dmax:容災的距離要求,由用戶購買容災服務的等級決定。
Data:數據部分。
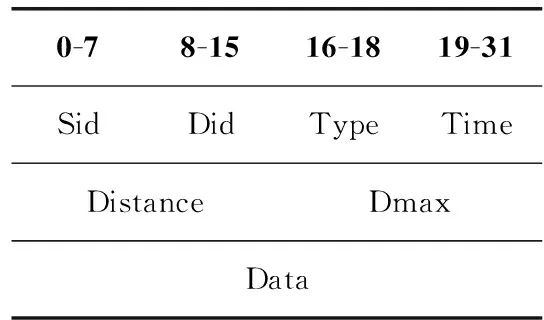
表1 DR數據報格式
2.2 數據庫表
服務器鄰接狀態表(tblNeighbor,tblNB),用于保存服務器到相鄰服務器的鏈路距離,見表2。Neighbor為鄰接服務器的IP地址,d為到對應鄰接服務器之間的距離。具體如何得到在下一節的算法描述中介紹。
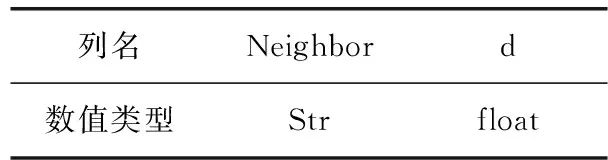
表2 tblNB
服務器容災信息表(tblDisasterRecovery,tblDR),用于保存服務器的容災對象,即服務器作為用戶的源服務器,則為該用戶添加一條數據,其結構見表3。UserIP為用戶的IP地址,IsDR表示該用戶是否購買了容災服務,Dmax為該用戶對容災距離的要求,S-DRS和R-DRS分別為相應服務器的IP地址。UserIP、IsDR和Dmax這3項是在用戶購買容災服務時告知通信人員,通信人員將信息插入數據庫表中,此時S-DRS和R-DRS為空,Ss通過執行相關的容災算法,得到S-DRS和R-DRS。

表3 tblDR
2.3 算法描述
本文采用基于事件的方式呈現算法,分別對建立tblNB表、建立tblDR表和處理Message數據報進行描述。
2.3.1 建立tblNB表
在createtblNB算法中,首先建立一個tblNB表,然后創建一個子線程,函數接口為receiveASK,主線程每隔 10 s 向相鄰服務器發送ASK數據報。receiveASK函數監聽當前服務器端口為9900處的數據報,計算接收到的數據報中的時間戳與當前時間戳之差,結合數據傳輸速率,估算出相鄰兩個服務器間的距離d,若當前tblNB表中的Neighbor不包含接收到數據報的Sid,則將Sid和對應的距離d插入tblNB表中,若包含,則更新距離d的值,同時,若長時間未再次收到表中鄰接服務器的ASK數據報,則將其從表中刪除。實現tblNB表在初始時的建立以及鏈路變化后的更新。其流程如圖2所示。
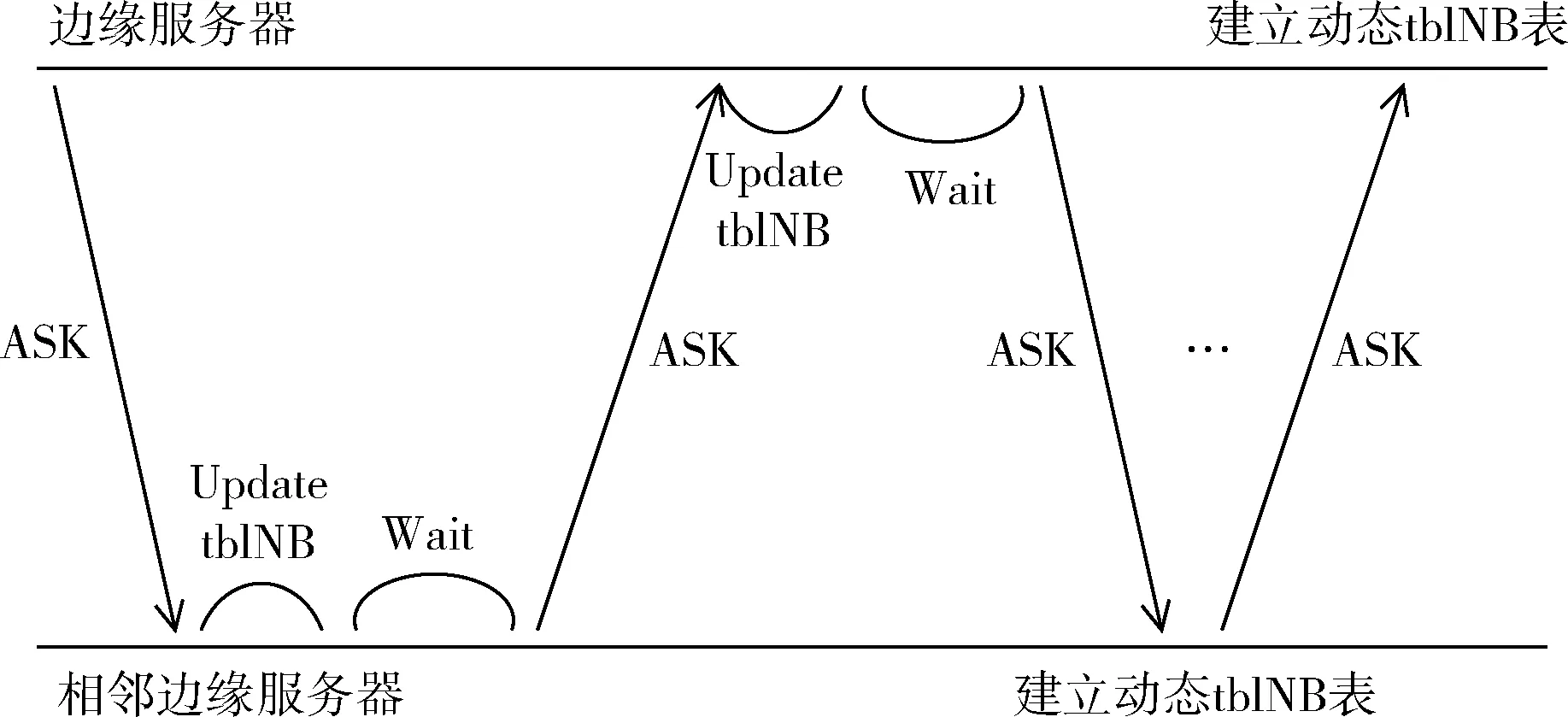
圖2 建立tblNB表的流程
建立tblNB表:
(1) create table tblNB
(2) create thread(reciveASK,&host)#線程監聽ASK并更新tblNB
(3)whiletruethen
(4) wait 10 s #發送ASK間隔時間,可根據用戶情況修改
(5)Forip in tblNB.Neighborthen
(6) Send ASK to Neighbor
(7)EndFor
(8)EndWhile
2.3.2 建立tblDR表
在create算法中,創建了一個tblDR表并插入了一條UserIP為‘192.168.56.109’的數據。源服務器通過遍歷tblNB表得到S-DRS和最遠的鄰接服務器(farthest adjacent server,Fas),再向Fas發送Req數據報,等待符合要求的服務器返回ReqACK數據報。接收到Req數據報的服務器,根據數據報中的Dmax和Distance,以及自身的存儲能力,判斷是否滿足容災要求,若滿足則返回ReqACK數據報,源服務器接收到ReqACK數據報則更新tblDR表中的R-DRS。其流程如圖3所示。
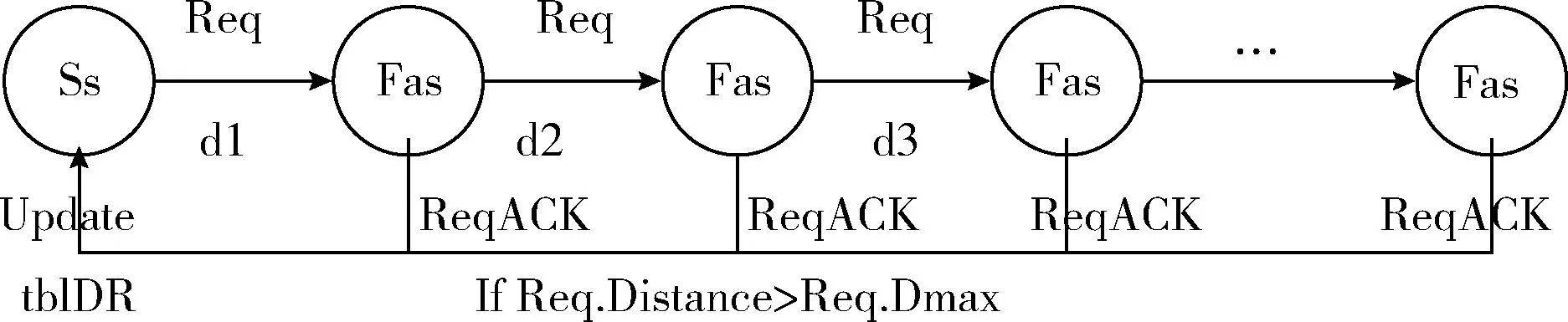
圖3 建立tblDR表的流程
建立tblDR表:
(1) create table tblDR
(2) insert (UserIp,IsDR,Dmax) into tblDR
(3)IfS-DRS and R-DRS is nullthen
(4) S-DRS←selecttblNB#查詢最近鄰接服務器
(5) Fas,d←selecttblNB#查詢最遠鄰接服務器和對應距離
(6) sendReq to Fas
(7) listening ReqACK #監聽ReqACK數據報
(8) tblDR.R-DRS←ReqACK.Sid
(9)EndIf
2.3.3 處理Message數據報
接收到Message數據報保存到“server_data”文件中。然后判斷該數據報是否來自鄰接服務器,若是,則是作為S-DRS接收到該數據,不需要做其它操作;否則,將數據再寫入“server_data_temp”文件,調用handle_Message函數處理數據,將數據同步備份到S-DRS、將“server_data_temp”中的數據異步備份到R-DRS并清空“server_data_temp”文件中的數據,保證每次備份的數據不重復。其流程如圖4所示。

圖4 處理Message數據報
處理Message數據:
(1)Whiletruethen
(2) Listening Message #監聽Message
(3) Save Message.data to ‘server_data’ #保存數據
(4)IfMessage.Sid not exits in tblNBthen#Message來自用戶
(5) Write Data.data to ‘server_data_temp’
(6) create thread(backup to R-DRS)#異步備份并清空‘server_data_temp’文件
(7) send Message to S-DRS #同步備份
(8)EndIf
(9)EndWhile
由上可知,算法的相鄰服務器之間通過交換相關數據報,建立相鄰的鏈路信息表,依次向相鄰遠端服務器發送詢問R-DRS的數據報,根據返回結果建立容災服務表,最后根據容災服務表對用戶的數據進行同步和異步的備份。該容災算法可實現[12],實現時,僅對尋找S-DRS、D-DRS以及數據備份過程進行設計即可。
3 算法分析與驗證
3.1 算法分析
3.1.1 時間消耗
在分析算法時間消耗時,假設鏈路材質與距離等引起的傳輸延遲不計。
(1)建立tblNB表:時間消耗主要是發送和更新時查詢數據庫的時間。假設建立tblNB表的執行時間為T1,相鄰服務器的數量為n,查詢tblNB表中一條數據的時間為t。則:T1=nt。
(2)建立tblDR表:時間消耗主要是遍歷tblNB表、發送Req數據報和等待ReqACK數據報。根據(1)中的假設,得到遍歷tblNB表的執行時間為2nt。假設傳輸平均速率為v,則發送Req并等待接收ReqACK數據報的執行時間為2(Dmax/v),則建立tblDR表的執行時間T2=2nt+2Dmax/v。
(3)處理Message數據報的時間消耗:主要是將數據分別同步、異步備份到S-DRS和R-DRS。根據上面的假設,發送到S-DRS的執行時間T3=d/v+t; 同時,發送到R-DRS的執行時間T4=Dmax/v+t。
綜上,執行該算法的總時間為
T總=T1+T2+T3+T4=
nt+2nt+2Dmax/v+d/v+t+Dmax/v+t=
3nt+2t+3Dmax/v+d/v
(1)
式中:v和d的值取決于邊緣計算的鏈路設計,在邊緣服務器部署后是不變的,同時,查詢表中一條數據的時間t也是不變的,則執行時間T總隨n的增加呈線性增長。
3.1.2 空間消耗
tblNB表的大小與相鄰服務器數量相關,而數量n最多不過百條,在系統上所占的開銷很小。
tblDR表的大小與用戶數量有關,當前服務器作為某一用戶的源服務器,該服務器便會新增一條相應的記錄,由于邊緣服務器的密集部署,一個邊緣服務器負責的周圍區域并不會很大,所以tblDR表所需的開銷也很小。
處理Message數據報的空間消耗主要是保存用戶數據的“server_data”和“server_data_temp”文件,“server_data”文件是必要的,則空間的額外開銷主要是“server_data_temp”文件。
綜上,該算法所需系統的空間消耗主要是“server_data_temp”文件,而“server_data_temp”文件的內容在每次向R-DRS異步備份后被清空,其大小取決于異步備份的間隔時間以及在此時間內用戶的使用情況。這是一個NP難問題,因為并不能預測用戶在此時間內的使用情況。只能通過減小時間間隔來使“server_data_temp”文件所需空間更小,但是時間間隔的縮小必然會增加網絡流量負擔,將在后面的算法驗證中得到“server_data_temp”文件大小與間隔時間以及用戶請求數量之間的關系圖,管理人員可根據邊緣設備的存儲能力以及用戶使用情況來設置異步備份的時間間隔。
3.1.3 系統可靠性
在本文提出的容災架構中,系統的失效率受邊緣節點以及鏈路故障影響,由于邊緣節點和鏈路只存在正常與故障兩種狀態,故采用故障樹(fault tree analysis,FTA)的方法來分析系統的失效率。
系統失效是在Ss、S-DRS、R-DRS服務同時故障的情況下發生,Ss、S-DRS、R-DRS服務故障分別是在對應的邊緣服務器故障或到用戶的某一鏈路故障時出現,而邊緣服務器故障可能是硬件的損壞或自然災害導致。此外,由于Ss、S-DRS距離很近,可以假定Ss和S-DRS同時遭遇自然災害的破壞。基于此,對系統可靠性進行故障樹建模如圖5所示。
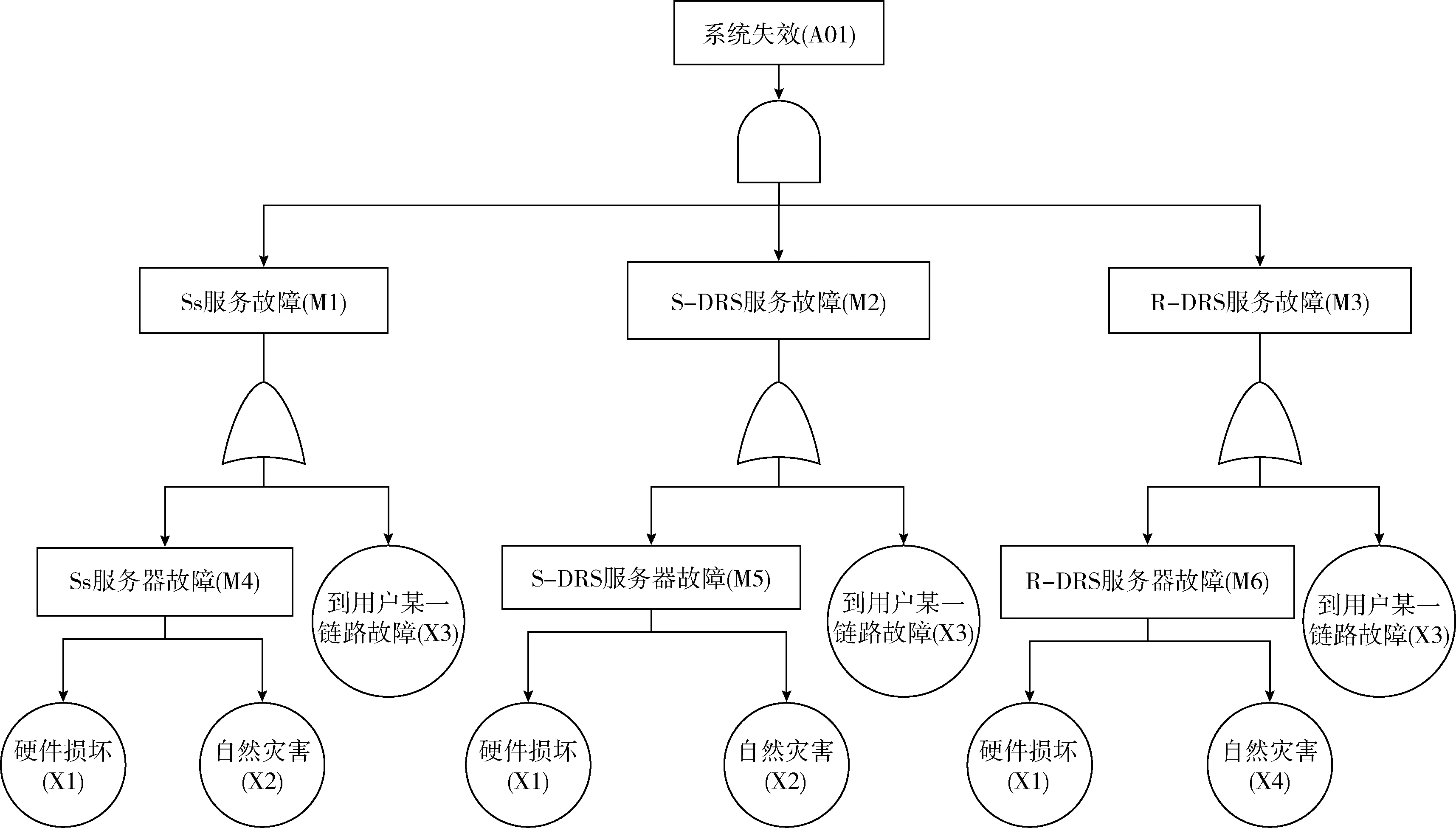
圖5 容災系統失效的故障樹
假設Ss、S-DRS、R-DRS服務器故障的概率分別為PM4、PM5、PM6,Ss、S-DRS、R-DRS服務故障的概率分別為PM1、PM2、PM3,整體系統失效的概率為PA01。根據FTA分析可得如下公式
PM4=Px1+Px2,PM5=Px1+Px2,PM6=Px1+Px4
(2)
PM1=kPx3+PM4=kPx3+Px1+Px2
(3)
PM2=mPx3+PM5=mPx3+Px1+Px2
(4)
PM3=nPx3+PM6=nPx3+Px1+Px4
(5)
PA01=PM1PM2PM3=(kPx3+Px1+Px2)
(mPx3+Px1+Px2)(nPx3+Px1+Px4)
(6)
式中:k、m、n分別代表Ss、S-DRS、R-DRS到用戶的鏈路數,與用戶的距離直接相關,此外,由圖1的物聯網邊緣服務容災架構可知,R-DRS到用戶的距離遠大于Ss和S-DRS到用戶的距離,所以k≈m?n。
3.2 算法驗證
實驗基于Debian9.6.0系統,使用Python2以及內置的sqlite3,采用socket通信編程實現。實驗在同一局域網內完成,共使用6臺虛擬機,模型如圖6所示,用戶默認的Ss是“192.168.56.101”。根據實驗的模型,通過ASK數據報建立tblNB表。設置用戶“192.168.56.109”的容災距離要求為1 000 000,通過tblNB表以及Req數據報,得到用戶的S-DRS是“192.168.56.103”,R-DRS是“192.168.56.105”。下面將從時間、空間消耗以及系統的可靠性對算法分析進行驗證。
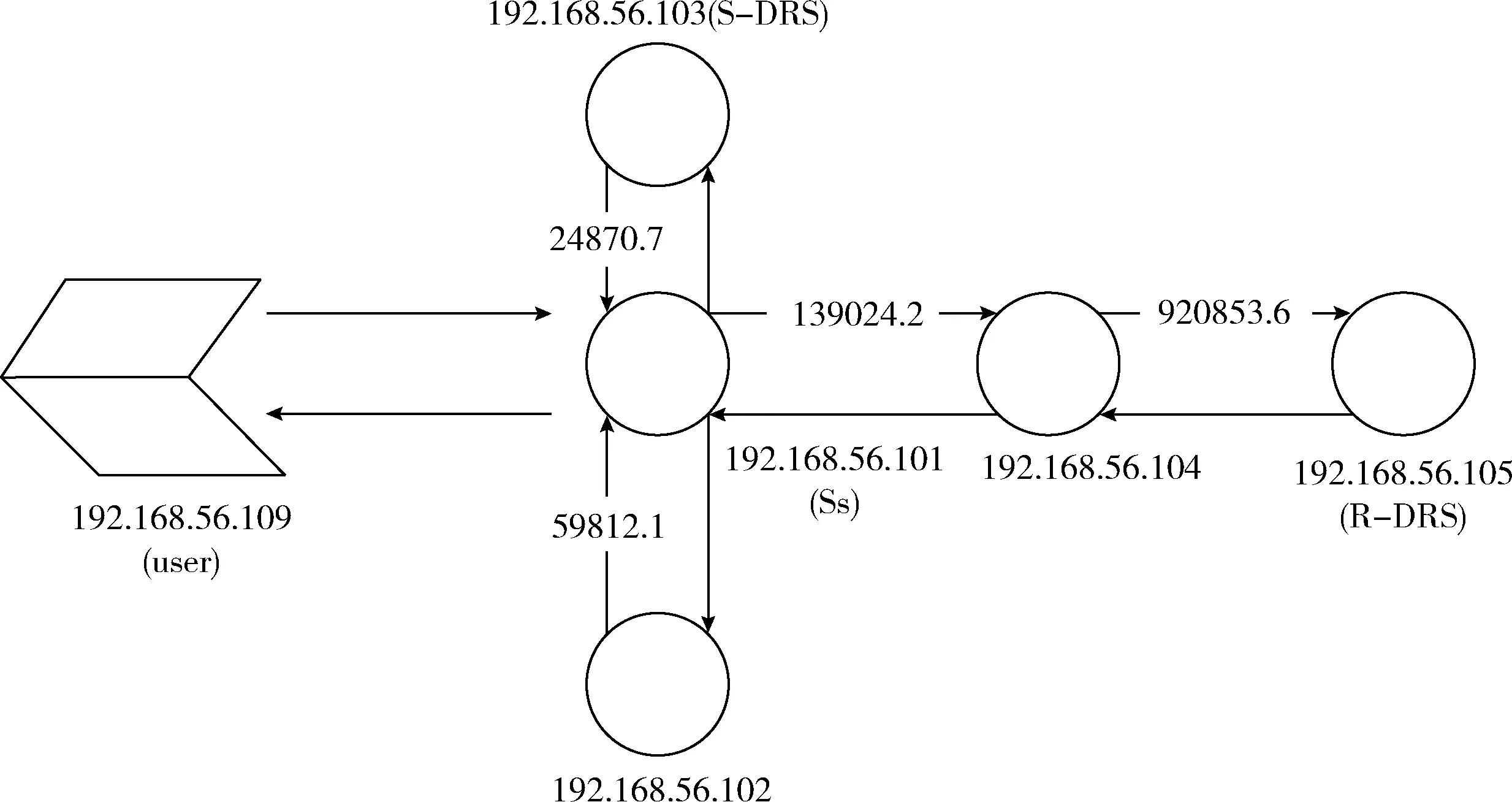
圖6 實驗模型
3.2.1 時間消耗驗證
首先模擬了相鄰服務器之間發送ASK數據報、監聽ASK數據報并更新tblNB表的過程。在實驗中,忽略數據報在鏈路上的傳輸時間以及發送ASK的間隔時間,得到發送和處理一條ASK數據報的執行時間分別為10 ms、20 ms,則T1=30n(ms)。
然后模擬了建立tblDR表的過程,根據圖6的實驗模型,在虛擬機上運行了createDR函數,根據時間戳之差,得到了在該模型中建立tblDR表所需時間約為T2=5300ms。
最后,模擬了備份數據的過程,忽略鏈路延遲,在虛擬機的理想狀態下,得到了備份一條數據到S-DRS的執行時間為10 ms,備份一條數據到R-DRS的執行時間20 ms。由于備份到R-DRS是異步進行,則處理數據的延遲時間僅跟T3有關。假設用戶的請求包含N個數據報,則在處理每條數據時,算法的執行時間T3=10N(ms)。
綜上,因為只有在初始化時才需要建立tblNB和tblDR表,則算法在初始和真正運行的執行延遲時間分別為T初=30n+5300;T延=10N。
本文算法的初始時間消耗隨相鄰服務器數量增加的變化,如圖7所示。同時,將本文算法的執行時間和文獻[5]中增加中間件方案的執行時間進行對比。顯然,本文算法雖然在初始化時需要消耗較多的時間,但是,在相鄰的邊緣服務器數量小于15臺時,本文算法的執行延遲時間遠低于文獻[5]中的方案,如圖8所示。
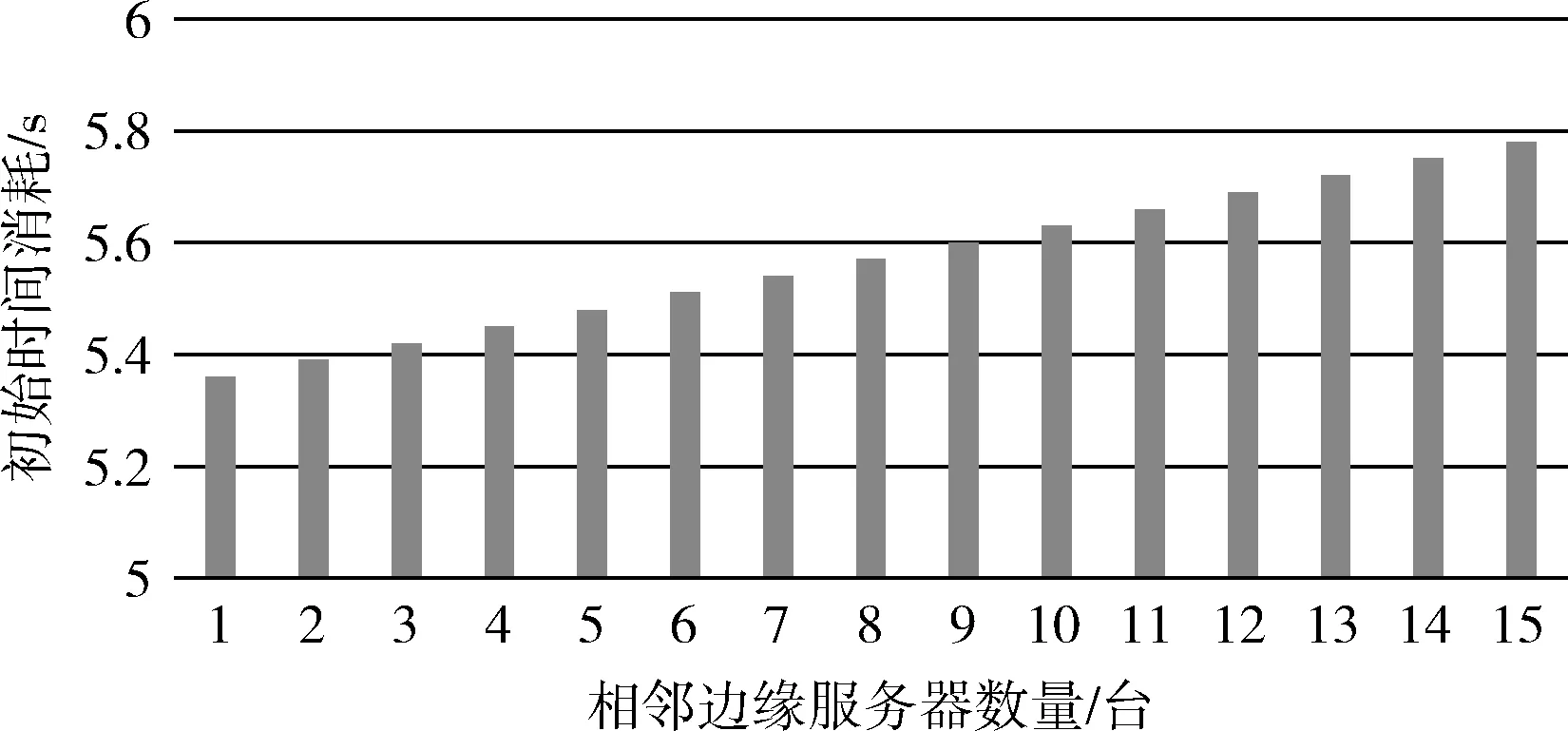
圖7 初始時間消耗
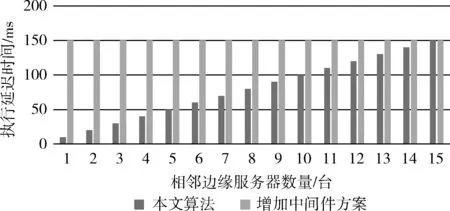
圖8 執行延遲時間對比
3.2.2 空間消耗驗證
在實驗中,通過向tblNB表中插入多條數據,發現數據庫DRserver.db的大小并不是每插入一條數據便增長,當插入的數據小于233條時,通過”ls-l”命令查看到DRserver.db的大小為12 288字節,超過233條時,DRserver.db的大小增長到20 480字節,可見,DRser-ver.db的大小是按照8192字節增長。顯然,在本文提出的容災架構中,tblNB表和tblDR表中的數據均不會超過223條,則數據庫所占空間大小為12 288字節。對于”server_data_temp”臨時文件,所占空間的大小由間隔時間以及用戶的請求頻率決定,假設異步備份間隔時間為t,請求頻率為V(次/s),每次請求包含數據量為N條,由TCP/IP通信協議可知,數據報每條不超過1460(Byte)。則文件所需大小為:S=(V*N*1460)/1024(Mbyte)。 通過模擬實驗,得到了臨時文件大小在不同的間隔時間內隨用戶請求數量的變化,單位是Mbytes。在實際應用中,異步備份間隔時間可根據用戶的使用情況以及用戶對容災系統的級別要求選擇,容災級別具有彈性。如圖9所示。
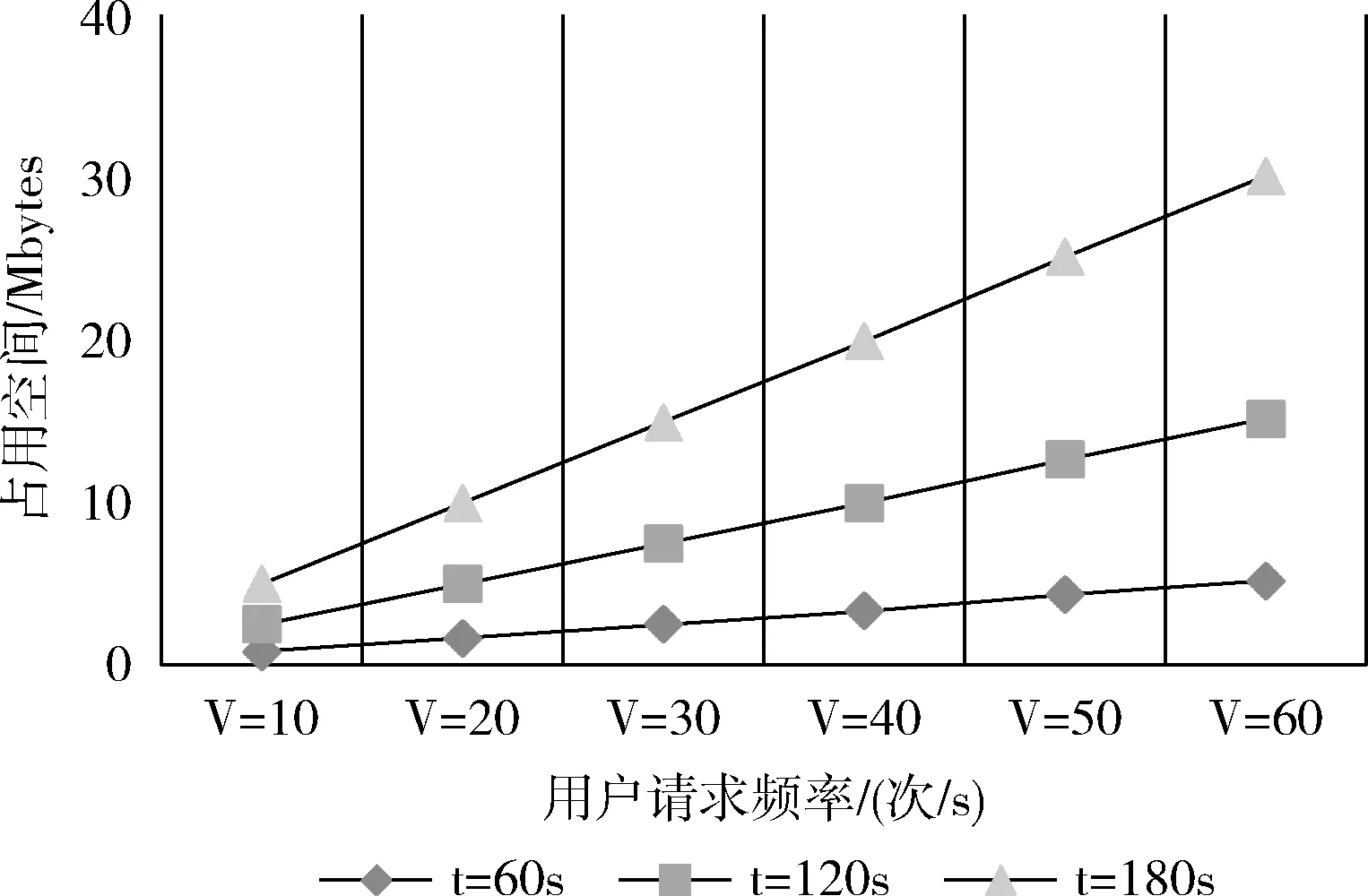
圖9 文件所占空間變化
3.2.3 可靠性驗證
假設系統失效故障樹的基本事件情況見表4,在之后的實驗中將在此假設的基礎上進行。最終得出的結果通過對比得到,所以數值本身的大小對算法分析無影響,只需關注數值之間的大小。
基于以上假設,對式(6)進行MATLAB仿真,由于k≈m?n, 可以假設k=m∈(1,10),n∈(10,50),得到系統失效率如圖10所示。
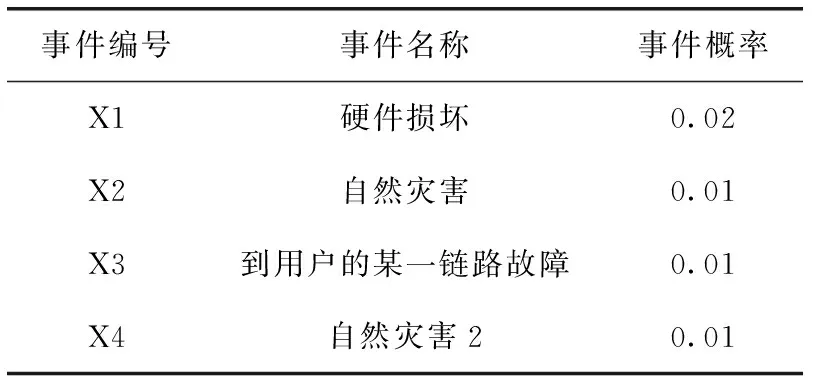
表4 故障樹的基本事件情況
對文獻[5]中增加中間件的方案進行故障樹建模,如圖11所示。假設邊緣節點和簇頭服務故障的概率分別為PM21、PM22,邊緣節點和簇頭故障的概率分別為PM23和PM24,增加中間件方案的失效率為PA02。根據FTA分析得到如下公式

圖10 本文算法
PM23=PM24=Px1+Px2
(7)
PM21=PM23+Px3=Px1+Px2+kPx3
(8)
PM22=PM24+Px3=Px1+Px2+mPx3
(9)
PA02=PM21PM22=(Px1+Px2+kPx3)(Px1+Px2+mPx3)
(10)

圖11 增加中間件方案
由于邊緣節點與簇頭到用戶的鏈路數幾乎相同,可以假設k=m∈(1,10), 通過MATLAB仿真得到如圖12所示關系。

圖12 增加中間件方案
由圖10與圖12對比可知,本文設計的容災算法在系統失效率上平均低于文獻[5]方案的系統失效率,本文算法的可靠性更高。
4 容災性能分析
4.1 網絡負載
本文采用iptables統計端口流量,得到了在建立tblNB表時,網絡負載隨著相鄰服務器數量增加的變化,如圖13所示。
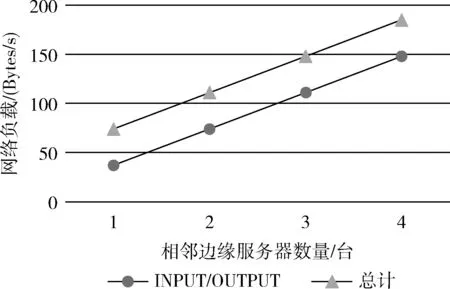
圖13 網絡負載變化
在該表中,一條是Ss在9900端口處的INPUT/OUTPUT流量,另一條是該處的總計流量。由圖13可知,ASK數據報僅以每秒幾十字節進行傳送,對網絡的負載影響很小;結合實際需求,調整發送ASK的間隔時間,以降低網絡負載或提高更新表的速度。
建立tblDR表時,網絡負載僅發送一條Req數據報和接收一條ReqACK數據報,且建立tblDR表僅在初始化時進行。Message數據報是用戶的數據報。該算法下僅ASK數據報是額外的開銷,但對整個方案在網絡負載上對通信的影響是非常小的。
4.2 RPO
RPO(recovery point objective)是針對數據丟失的指標,指災難發生時刻與最后一次備份的時間間隔。S-DRS同步復制Ss的數據,若只有Ss故障,數據的丟失接近于0。R-DRS異步復制Ss的數據,若Ss與S-DRS同時故障,則數據的丟失主要取決于在異步備份的間隔時間內,用戶傳輸到Ss的數據。
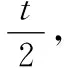

圖14 丟失數據變化
5 結束語
邊緣計算的興起是必然的,主要探討基于邊緣計算特性的容災算法。通過邊緣服務器本身進行容災,突破傳統容災的局限性,降低容災成本和復雜性,提高容災服務質量。通過算法分析和實驗驗證,從執行時間延遲和可靠性突出該算法的優越性,同時,也從空間消耗、網絡負載、RPO驗證了該算法的可行性。通過合理地部署邊緣服務器,優化容災方案,為邊緣服務器的部署提供容災措施。當然,該方案亦存在不足,如在Ss選擇R-DRS時,若Req數據報未按單方向發送,可能導致累加的鏈路距離遠遠大于Ss與R-DRS之間的地理距離,不過這種隱患很少出現,亦或存在其它方面的不足,下一步將從這些不足入手,進行深入研究。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
汽車維護與修理(2016年10期)2016-07-10 08:17:41
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
汽車維修與保養(2015年6期)2015-04-17 03:31:50
