Twitter社交網絡用戶行為理解及個性化服務推薦算法研究
2020-07-18 04:13:06于亞新張宏宇
計算機研究與發展 2020年7期
于亞新 劉 夢 張宏宇
(東北大學計算機科學與工程學院 沈陽 110169)(醫學影像智能計算教育部重點實驗室(東北大學) 沈陽 110169)
隨著互聯網的快速發展,社交網成為了人們生活中不可或缺的工具,同時,無線通信與位置采集技術使得社交網的發展更為全面.例如Twitter、微博等,用戶不僅可以發表tweets、微博等來分享他們的觀點、日常生活,還可以在興趣點(如娛樂場所、餐廳、商場等)發表帶有地理位置的狀態,展示具體的活動.這些信息不僅真實展現了人們的生活,也從側面反映了他們的興趣習慣以及生活需求.如何利用社交網的用戶數據發現用戶行為規律,同時根據用戶行為理解用戶需求從而為用戶推薦滿足需求的服務地點,已成為當前的研究熱點之一.
由于用戶發布的信息大多帶有時間戳、地理位置、文本等信息,導致了“4W”的信息布局,即某個用戶(who)在某個時間(when)、某個地點(where)產生了某種行為(what),對應4個不同層次的信息[1].這些信息反映了用戶的行為模式和需求.基于用戶需求為用戶進行個性化的服務推薦,這方面的研究還較少.
目前社交網個性化推薦面臨著一些新的挑戰.
1) 短文本下主題難于捕捉.社交網數據由于文本長度短、關鍵特征非常稀疏,導致主題挖掘困難.傳統的主題挖掘方法直接應用到短文本上效果不佳.
2) 地理位置過于稀疏.一方面用戶發布的帶有地理位置的文本數據較少;另一方面1條文本僅帶有1個地理位置,導致用戶地理位置數據稀疏,造成了用戶活動區域挖掘困難.
3) 行為要素間依賴關系缺少融合.用戶的行為要素包括活動時間、內容和區域,不同用戶在不同時間段有不同的活動區域和內容,四者間存在依賴關系.缺少對依賴關系的融合將導致用戶行為理解的片面性.
4) 服務地點屬性間的耦合性考慮不足.傳統推薦算法假設地點屬性間、地點屬性內部不存在相互影響關系,屬性值服從獨立同分布.但實際上屬性間、屬性內部存在相互影響的關系,是非獨立同分布的.對屬性間耦合性的忽略導致了推薦結果不準確.
基于上述問題,本文重點研究社交網用戶行為理解并完成了服務地點的推薦,主要貢獻有4個方面:
1) 利用社交網目標用戶的文本時間戳、內容,提出了用戶-時間-活動模型(user-time-activity model, UTAM),挖掘用戶活動時間和內容,解決了短文本下主題難于捕捉的問題;利用目標用戶的文本時間戳、地理標簽提出了用戶-時間-區域模型(user-time-region model, UTRM),挖掘用戶活動時間和區域,解決了地理位置過于稀疏導致的活動區域難以挖掘的問題.
2) 利用社交網中大眾數據的文本內容和簽到服務地點,提出了挖掘活動和服務對應關系的ASTM.
3) 將用戶的活動區域與服務地點間的距離以及地點屬性間的耦合性融合到矩陣分解中,提出了基于耦合和距離的矩陣分解(matrix factorization based on couple & distance, MFCD),旨在實現精準個性化服務場所推薦.
4) 使用真實的tweets數據集進行大量的實驗評估推薦效果,實驗表明優于傳統推薦算法.
1 相關工作
社交網用戶行為理解是當前研究熱點之一,大量關于行為理解的模型和方法被提出.通常社交網用戶行為理解包括4個方面:用戶、活動時間、活動區域和活動內容.
基于文本語義(活動內容)和基于位置(活動區域)等是研究用戶行為理解的主要手段.基于語義的用戶行為理解主要是通過對用戶的文本信息進行研究,從文本中提取出用戶的行為;基于位置的用戶行為理解主要是根據用戶的位置信息,將位置軌跡相似的用戶聚成一簇.然而,由于用戶的信息中有用的信息相比于龐大的數據量過于稀疏,并且僅僅針對于上述的方法來對用戶行為進行分析會有很大的片面性,使得這些方法在對用戶進行行為理解的效果難以有更好的突破.
文獻[2-3]僅利用時間和地理位置2個方面,研究社交網用戶移動性和時間的關系;文獻[4-5]考慮了用戶、位置、內容3個方面,文獻[4]基于LDA(latent Dirichlet allocation),提出了1個考慮位置坐標和語義信息的模型,假設每一個文檔的內容主題和活動區域分別基于全局的和用戶特定的主題、區域分布進行抽取;文獻[6]提出了基于CRF(Chinese restaurant franchise)的模型研究用戶的活動區域;文獻[7]從4個方面進行用戶行為理解,但是沒有考慮到短文本、地理位置稀疏等對模型帶來的影響.
目前,在用戶行為理解后進行服務等推薦的研究較少.個性化推薦方法主要有基于內容推薦、基于協同過濾推薦、基于隱語義推薦、基于關聯規則推薦、基于效用推薦、基于知識推薦和組合推薦.
2 問題定義
表1給出了本文使用的符號列表和描述.
1) 非獨立同分布.在概率論中,非獨立同分布指隨機過程中,隨機變量X1和X2服從同一分布,但X1的取值會影響X2的取值,同樣X2的取值也會影響X1的取值.這種變量取值間互相影響的關系稱為耦合性.圖1描述了推薦系統中用戶、項目屬性間的耦合關系.其中,I代表項目集合,A代表屬性集合,Z代表項目的屬性值集合.在一個屬性Aj內部,不同的屬性值Zlj和Zkj存在依賴關系,同時屬性Ai的屬性值Zli也受另外的屬性Aj的屬性值影響[8].
2)LDA主題模型.LDA是一種文檔主題生成模型,由參數α和β確定,α反映了文檔集合中隱含主題間的相對強弱,β刻畫所有隱含主題自身的概率分布.圖2給出了LDA模型的生成過程[9].其中θm表示文檔主題的概率分布,φk表示特定主題下特征詞的概率分布.wm,n代表第m篇文檔中的第n個詞語,Zm,n代表wm,n所屬的主題.

Table 1 Symbol List表1 符號列表
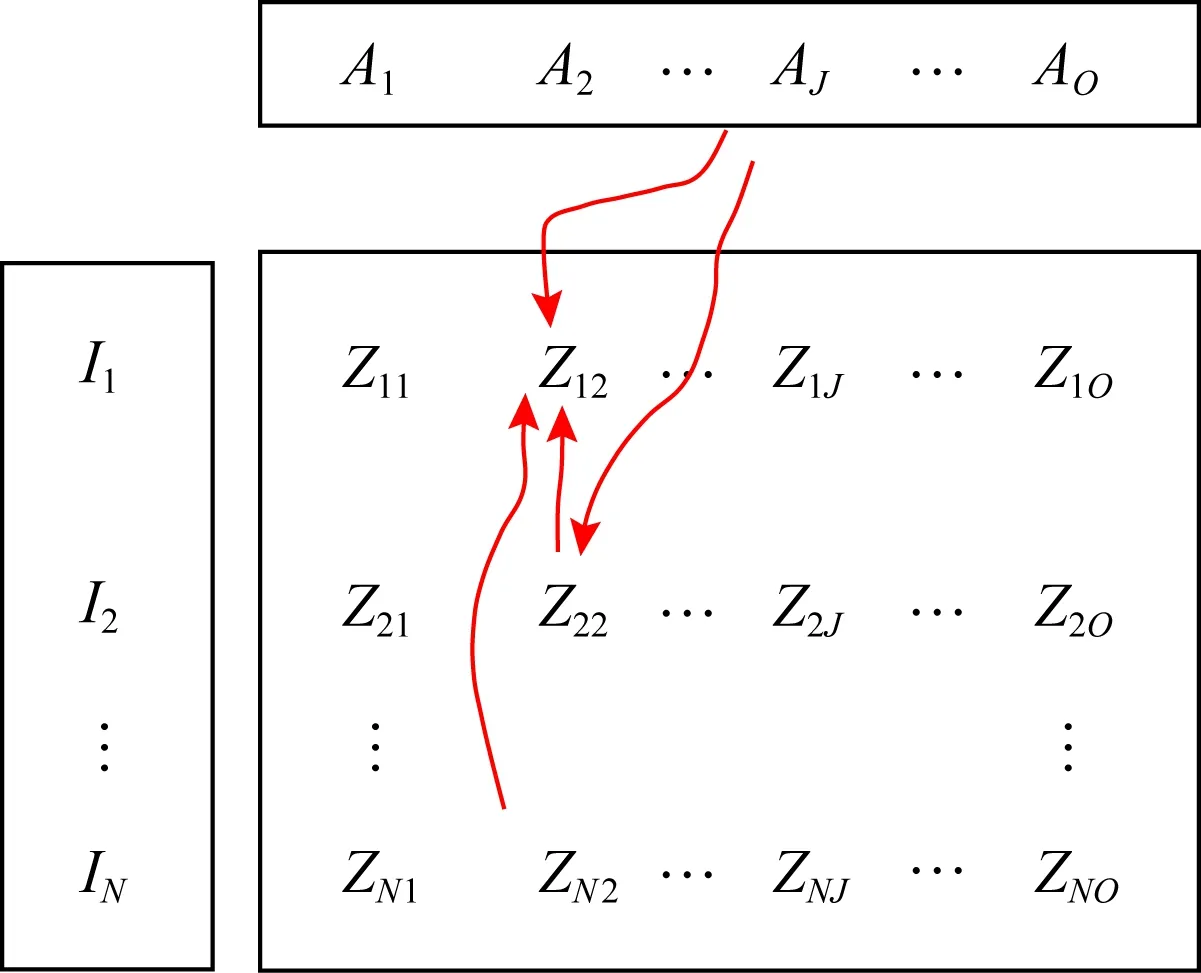
Fig. 1 Attributes coupling of items圖1 項目屬性耦合關系
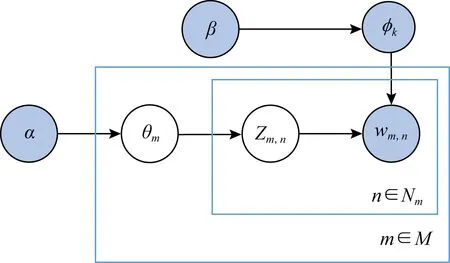
Fig. 2 Structure of LDA圖2 LDA結構圖
定義1.推薦地點屬性空間.F=I,H,Z表示推薦地點的屬性空間.其中I={I1,I2,…,Io}是推薦地點集合,H={H1,H2,…,Ho}是地點的非空屬性集合,Z表示所有服務地點的屬性值集合,Zi,j表示地點i在屬性j上的值.
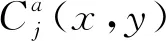
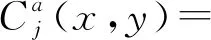
(1)
其中,|gj(x)={oi|Zi,j=x,1≤j≤M,1≤i≤N}|是屬性Hj對應屬性值為x的所有服務的個數.
定義3.屬性耦合相似度ECLS.表示2個服務地點在某個屬性下的耦合相似度(coupled location similarity, CLS),即在某個屬性所有取值下的屬性內耦合相似度:
(2)
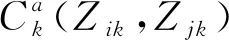
問題1.行為理解.給定用戶U發布的tweets集合D,得到用戶的4W行為模式(u,s,z,r),表示用戶u在時間段s的活動內容集合和活動區域集合.
問題2.個性化服務地點推薦.給定用戶行為模式(u,s,z,r)、服務場所集合Pl、為用戶推薦滿足其興趣的場所列表c.
3 用戶行為理解模型
利用攜帶時間戳、地理位置的短文本數據,能夠挖掘出用戶的行為模式[1],即用戶在某個時間段的活動內容和區域.該模式存在一定規律:1) 活動位置具有相對聚簇性[10].2)活動區域和內容具有時效性.比如圖3揭示了某個用戶訪問過的位置具有相對聚簇性,圖4則揭示了某個用戶訪問過的區域具有時效性.在圖3中,白色的點表示用戶在工作日訪問過的位置,黑色的點表示用戶周末訪問過的位置,通過圖3中的聚簇性可以發現該用戶在不同時間段有頻繁訪問的活動區域.在圖4中,工作日被劃分成3個時間段,可以看出該用戶在工作日的不同時段,訪問過的活動區域不同,因此時間對用戶活動區域確有一定影響.
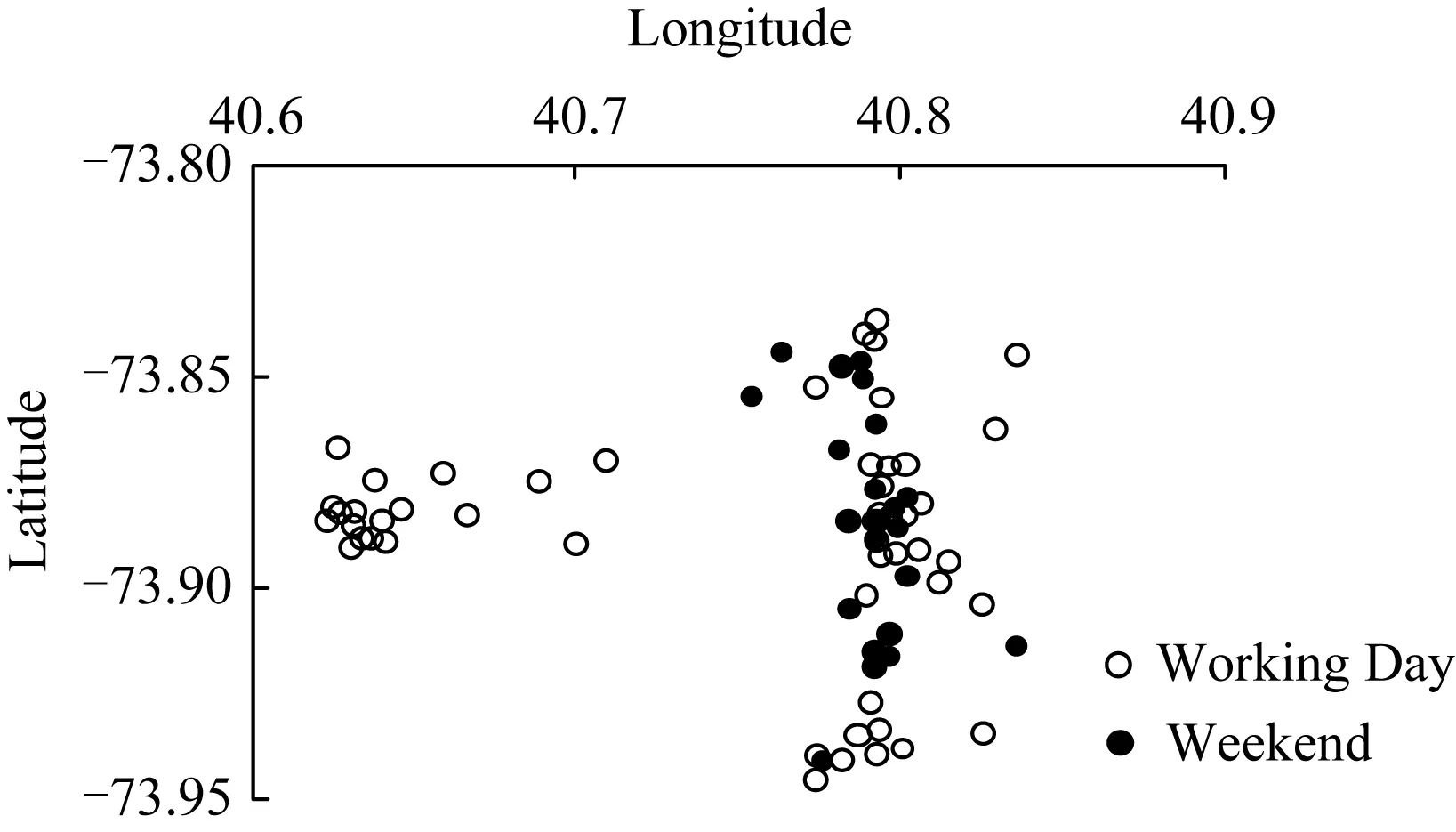
Fig. 3 Visited locations of a user圖3 某用戶訪問過的位置
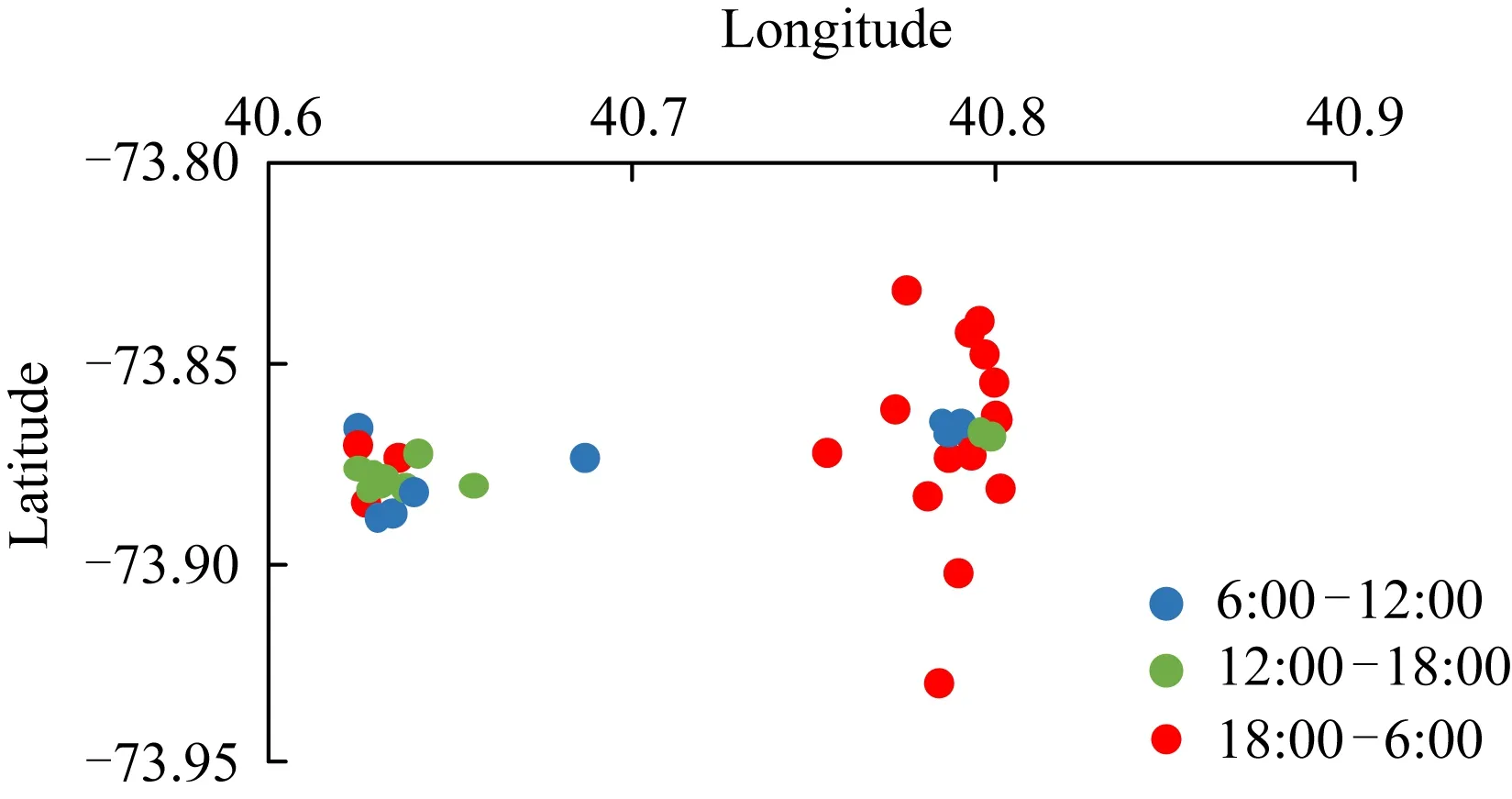
Fig. 4 Visited time of locations in weekdays圖4 某用戶在工作日訪問過的位置
根據上述分析,用戶、時間、行為、地理位置4個方面存在依賴關系,為此,本文提出了2種行為理解模型:1)用戶-時間-活動模型(user-time-activity model, UTAM);2)用戶-時間-區域模型(user-time-region model, UTRM).前者理解用戶的活動內容,后者主要理解用戶的活動區域.下面,分別對這2個模型加以詳細闡述.
3.1 用戶時間活動模型UTAM
3.1.1 UTAM結構
用戶活動內容與時間存在依賴關系.例如一個上班族周末可能會有更多的娛樂活動,看電影逛街等,而工作日更多的是與工作相關的行為如中午購買咖啡.所以,將用戶活動時間分成4類:T1(周末),T2(工作日06:00—12:00),T3(工作日12:00—18:00)和T4(工作日18:00—06:00).針對目標用戶數據集D,將相同用戶在相同時間段發布的tweets放到同一個文檔Du,t中.
LDA主題模型適合處理長文本,由于Du,t的長度較短,傳統LDA不再適用,因此本文對此進行改進,對于Du,t中的每1條tweet采樣自同一個主題,提出了UTAM行為理解模型,該模型的Du,t服從Dirchlet分布、其主題服從Multi分布,圖5給出了UATM的結構圖.其中,v是已知詞條,表示u在時間段t發布的第i條文本中的第n個詞語;Zu,t,j表示用戶u在時間段t的第j個主題;φm,θu,t分別表示潛在主題m的詞語分布和u在時間段t的主題分布.通過φm可以計算出u在Du,t中各個潛在主題的概率,通過θu,t可以計算出v在主題m下出現的概率.
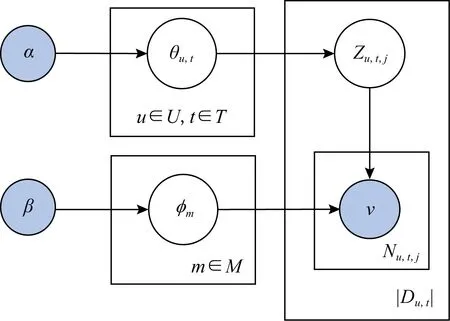
Fig. 5 The graphical model of UTAM圖5 用戶-時間-活動模型結構圖
3.1.2 參數估計
給定Du,s,并根據經驗設定Dirchlet分布、Multi分布的先驗參數α和β,則根據Gibbs采樣[11]可以計算出變Z,φ,θ:
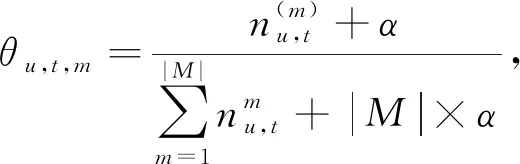
(3)
(4)
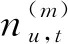
3.2 用戶時間區域模型(UTRM)
3.2.1 UTRM結構
用戶活動區域與時間存在依賴關系.與UTAM對時間處理的方式相同,將時間劃分成4類,將用戶u在時間段t訪問過的地理位置放到同一個Gu,t中.由于tweets中地理位置信息相對比較稀疏,因此Gu,t短文本特性更加明顯,不適合使用傳統主題模型解決,因此本文提出了基于位置對組合的用戶-時間-區域模型UTRM.
文獻[12]提出詞對主題模型(biterm topic model, BTM)用于文本單詞的主題挖掘,本文借鑒該模型對地理位置進行處理.UTRM的結構如圖6所示,該模型是3層結構,分別對應位置對、區域和位置,位置對-區域假設為Dirichlet分布,區域-位置假設為Multi分布.生成位置對的過程是將Gu,t中無序的2個位置作為一個共現位置對,|L|個位置共生成|LB|個共現位置對.li,lj是位置對中的2個不同位置,?是所有位置對共享的區域分布,φ是每個區域對應的位置分布,另外γ和λ都是Dirichlet先驗分布的超參數.
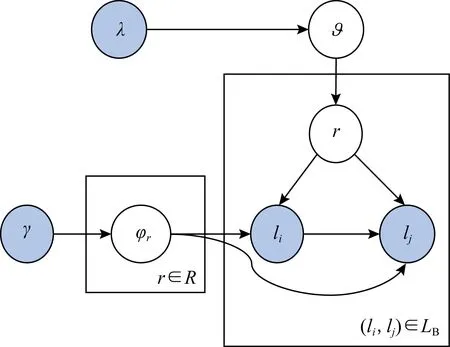
Fig. 6 The graphical model of UTRM圖6 用戶-時間-區域模型結構圖
UTRM模型生成位置對的過程:
1) 選擇?~Dir(λ);
2) 對于每一個區域r∈R:選擇φr~Dir(γ);
3) 對于每一個位置對l=(li,lj)∈LB:
① 選擇1個區域r~Multi(θ);
② 選擇2個位置li,lj~Multi(φr).
UTRM模型生成語料庫中位置對的過程如上所示.對于位置對集合Lb中的每一個位置對l=(li,lj),先從整個位置對集合共享的?中抽取1個區域r,r~Multi(θ),然后從區域r下抽取2個位置li,lj,即li,lj~Multi(φr).
由于該模型是對整個語料庫進行建模,所以不能直接得出Gu,t的區域概率分布.為了推理出該分布,假設Gu,t的區域概率分布等于從該文檔中生成位置對的區域概率的期望值.其中p(r|b,d)表示位置對b采樣自主題r的概率.
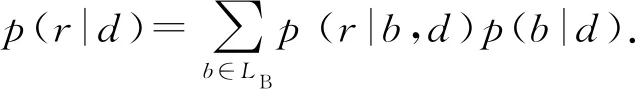
(5)
3.2.2 UTRM參數估計
給定Gu,t,根據經驗設定Dirchlet分布的先驗參數λ和γ,根據Gibbs采樣推斷隱含變量?和φ:
(6)
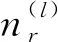
根據區域下位置對出現的次數,可以估計出區域-位置的分布和語料庫的區域分布:
(7)
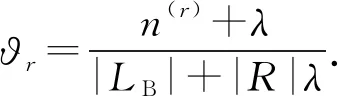
(8)
從大眾文本挖掘出來的活動內容能夠反映出大眾的興趣、需求,從而影響了服務的選擇[13].所以大眾活動與服務間存在對應關系,且這種對應關系具有客觀性[14].如活動是吃飯,與之對應的服務是餐館而不是商場,那么推薦的服務地點應是具體的餐館.通過分析大眾tweets文本及簽到地點數據,能夠挖掘出這種對應關系[14].
大眾發布的tweets詞語能組成語義相關的活動,服務能組成功能相關的主題.為了得到活動和服務地點間的對應關系,本文提出了活動-服務主題模型(activity-to-service topic model, ASTM).
4.1 ASTM結構
ASTM生成大眾文本、地點的過程:
對于集合Pu中的每一個用戶u:
1) 選擇ψu~Dir(ξ).
2) 對于Pd中的每一個詞w,選擇活動x~Mul(ψu),選擇詞分布χx~Dir(μ),選擇詞語w~Mul(χx).
3) 對于Pg中的每一個服務地點c,選擇活動y~Mul(ψu),選擇活動-主題分布πy~Dir(μ),選擇主題e~Mul(πy),選擇服務地點分布δe~Dir(ε),選擇服務地點c~Mul(δe).
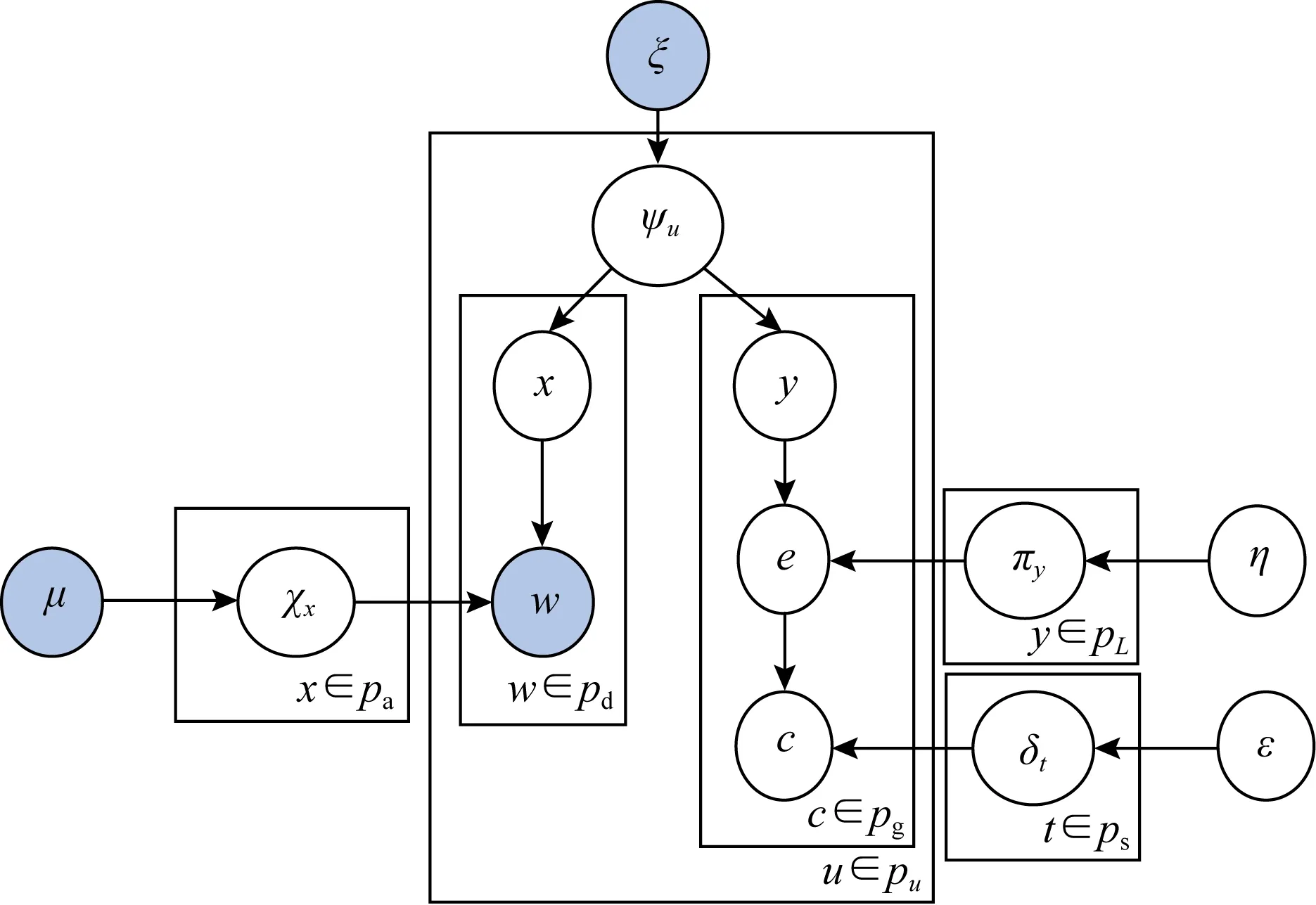
Fig. 7 The graphical model of ASTM圖7 活動服務主題模型結構圖
對大眾Pu發布的tweets數據集,將大眾u發布的所有tweets放到文檔Pd中,所有簽到地點c放到Pg中.ASTM結構圖如圖7所示.假設文檔Pd的活動服從Dirchlet分布,活動x的詞服從Dirchlet分布,主題z的服務服從Dirchlet分布.其中,w是Pd中已知詞條,c是Pg中已知服務地點,ψu表示Pd的活動分布,χx表示活動x的詞分布,πy表示活動y對應的主題分布,δt表示主題t的服務地點分布.μ,ξ,η,ε是模型的超參數.
對于大眾Pu發布的數據集,ASTM執行圖7所示的生成過程.對于Pd中的每一個詞條,從活動的多項式分布ψu中生成活動x,在x下采樣一個詞w;對于Pg中的每一個服務地點,先采樣一個活動y,根據πy采樣生成主題e,在e下采樣一個服務地點c.
4.2 ASTM參數估計
同樣采用Gibbs采樣進行模型參數估計.具體來說,由3個方程來更新主題x,y,t.首先:
p(xi=a|x,y,e,w,c)=
p(xi=a|x,y,wi=w)∝
(9)
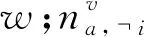
p(yj=a|y,x,e,w,c)=
p(yj=a|y,x,tj=d)∝
(10)
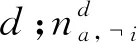
p(ej=d|e,x,y,w,c)=
p(ej=d|e,yj=a,cj=c)∝
(11)
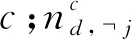
當Markov鏈得到收斂狀態之后,通過式(12)~(15)進行參數更新.
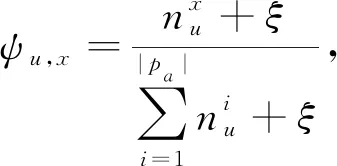
(12)
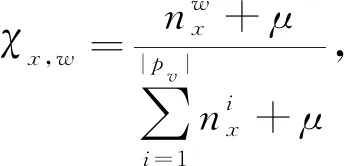
(13)
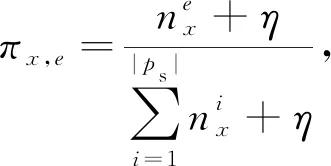
(14)
(15)
5 個性化服務推薦算法MFCD
在實際生活中,用戶更偏向于訪問與自己活動區域較近或在自己活動區域內的地點,所以服務地點與用戶活動區域的物理距離影響了用戶訪問該服務的可能性.另外,傳統推薦算法忽略了服務屬性內的耦合性,導致推薦結果不準確.基于此,本文將用戶活動區域與服務地點間物理距離、服務屬性內耦合性融合到推薦算法中,提出了MFCD推薦算法.首先利用UTAM和UTRM模型得到了用戶4W元組,其中包括某用戶在某個時間段的活動區域向量和活動內容向量;然后,利用ASTM模型得到的大眾活動內容向量和服務地點之間的關系,計算得到用戶在某個時間段的活動向量和服務地點之間的關系,構成用戶-服務地點矩陣;最后,在用戶-服務矩陣的基礎上,融合用戶活動區域與服務地點之間的距離以及服務地點屬性間的耦合性,形成了MFCD推薦算法.
5.1 用戶服務矩陣
通過UTAM和UTRM這2個模型可以得到用戶u的4W元組(u,s,z,r),其中u∈U,s∈S,z表示長度為|L|的活動向量,向量元素為u參加對應活動的概率;r表示長度為|R|的區域向量,向量元素為u在對應區域的概率.由于每個用戶不可能參加所有活動,因此給定一個閾值th,則z中活動其概率均≥th,由此構成用戶-活動矩陣A|U|×|L|.通過類似方法,還可以構成用戶-區域矩陣B|U|×|R|.
根據用戶活動和大眾活動的詞分布和φ,χ,使用JS(Jensen-Shannon)距離[15]和KL(Kullback-Leibler )距離[16]利用式(16)計算出|L|個用戶活動和|PL|個大眾活動間的相似度,并取概率值大于th的活動構成活動相似度矩陣C|L|×|PL|.
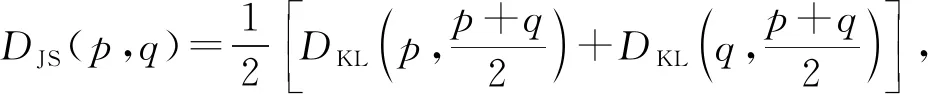
(16)
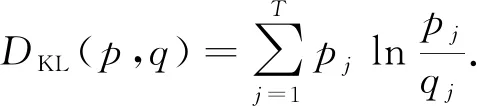
通過ASTM模型中的活動-主題分布πy及主題-服務分布δt,由于一個活動不能涵蓋所有主題,同樣一個主題不能涵蓋所有服務,因此取分布中概率大的構成活動-服務矩陣M.
通過上述4個矩陣A,B,C,M的乘積運算,最終得到稀疏的用戶-服務矩陣R.
5.2 服務活動區域間物理距離計算
用戶活動區域是由一系列地理位置組成,該活動區域與服務的物理距離D會影響用戶訪問該服務地點的可能性S.一般而言,D越大則S越小;反之,D越小S越大.基于此,將服務-活動區域距離D納入矩陣分解,于是S=|1-D|.
對于推薦服務地點集合Pl中的每一個地點,計算其與用戶區域中多個地點間的距離,并將其進行歸一化,得到距離差D.
5.3 服務屬性耦合相似性計算
大多數推薦算法假設用戶、項目的屬性服從獨立同分布,即屬性間以及屬性值間是相互獨立的,不存在互相影響的關系[8,17-19].但實際上大多屬性都是或多或少的互相影響,彼此間存在耦合性.
本文假設服務屬性服從非獨立同分布,屬性值存在相互影響的耦合關系,并將這種耦合關系整合到矩陣分解算法中,進而提高推薦質量.
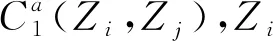
5.4 個性化服務推薦MFCD
矩陣分解模型常用形式是:N=PQT.將矩陣N轉化為了2個淺層因子P,Q的乘積,其中N|U|×|PL|,P|U|×d,Q|PL|×d,d是淺層因子的維度[20].
由于距離的影響以及耦合性的存在,為了提高推薦準確度,本文提出了MFCD方法.
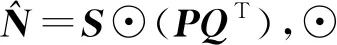
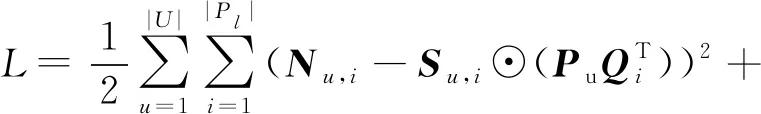
(17)
其中,Su i表示用戶u的活動區域與簽到地點i的距離1-Du i,N′(i)表示與簽到地點i相似度較高的前T個.該模型在優化過程中加入了另外2項規則化因子來篩選預測相似度較高的用戶和服務地點.采樣用梯度下降法進行優化更新,進而計算出最優的P和Q:
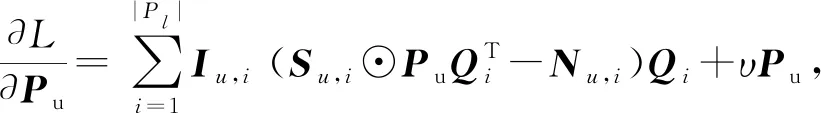
(18)
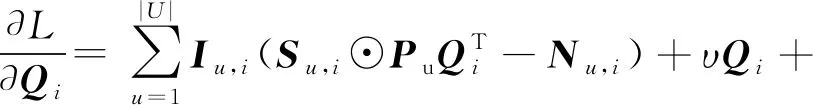
(19)
其中,Iu,i標識用戶u對簽到地點是否有過概率,Su,i表示用戶u和簽到地點i之間的距離,ECLS(i,j)表示簽到地點i和j的耦合相似度,N′(i)則表示與簽到地點i相似的地點集合,可通過設置閾值等方式選擇前T個.
最后,得到矩陣R,對于每一個用戶u,即矩陣R中的每一行,將結果排序,取值較大的前M個服務組成列表c推薦給該用戶.
6 實驗與分析
本節將在真實的Twitter數據集上驗證本次研究提出模型的參數敏感性、推薦有效性及推薦質量.介紹了實驗環境及實驗數據,介紹了實驗的評估標準,給出了相關實驗結果及對實驗結果的分析.
6.1 實驗環境及數據
本文采用真實的Twitter數據集,共6 058個用戶,137 830條文本.Twitter支持第3方的位置共享服務如Foursquare.Foursquare上的用戶可以在Twitter上分享簽到.利用Foursquare將在真實POI有過簽到且次數大于10次的用戶作為大眾用戶,進行數據清理,去除被訪問次數少于10次的POI及用戶,同時采集POI的屬性信息.其他用戶作為目標用戶,去除發布文本數量少于3次的用戶-數據的統計如表2所示:
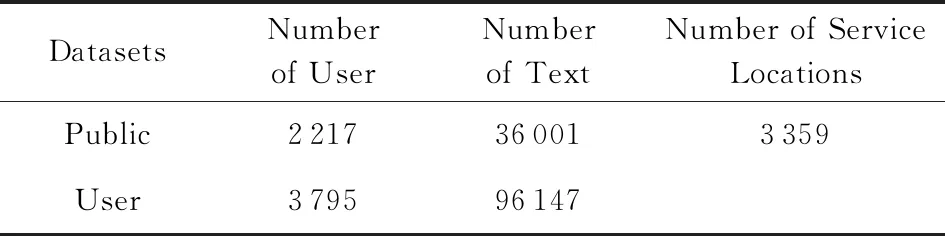
Table 2 Statistics of Twitter Datasets表2 Twitter數據集統計
6.2 評價指標
由于用戶行為理解模型UTAM,UTRM是基于LDA主題模型的,故采用2個常用的LDA評價指標,即困惑度(perplexity)和平均余弦相似性(average cosine similarity,ACS),分別記為per和QACS.
1) 困惑度[21].perplexity是當前最常用的度量語言模型性能好壞的評測指標,困惑度越小意味著模型效果越好.其中,p(wd)表示文檔d中的詞匯的生成概率,Nd表示為文檔d中所有的詞匯.
2) 平均余弦相似性ACS[22].ACS是所有主題向量之間的余弦相似性的平均值,該值越小,模型效果越好,其計算為
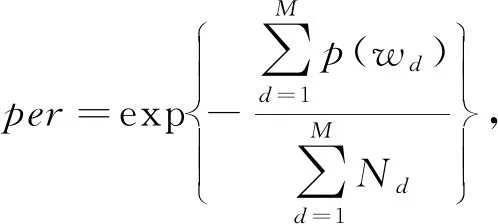
(20)
(21)
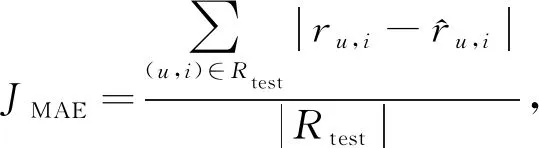
另外,為了評估MFCD算法的效果,本文采用推薦系統常用的2個指標[23]:平均絕對誤差(mean absolute error,MAE)和均方根誤差(root mean squared error,RMSE).其中MAE記為JMAE,RMSE記為IRMSE:
(22)
(23)
最后在我們的對比方法中,采用2種指標精確率Precision@K和召回率Recall@K來評估服務地點推薦的質量.其定義為:
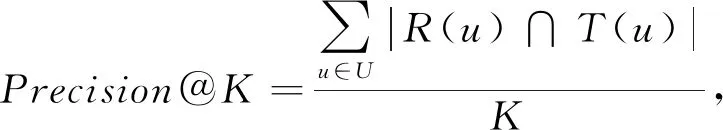
(24)
(25)
其中,U是用戶集合,K是推薦給用戶的服務地點的數量;R(u)是推薦給用戶的top-k列表;T(u)是用戶實際訪問的服務地點數量.
6.3 實驗結果
6.3.1節測試了UTAM,UTRM模型和MFCD算法的參數,確定了模型最優的參數.6.3.2節測試了MFCD模型推薦效果,實驗結果表明MFCD優于傳統的推薦算法.6.3.3節測試了本文提出推薦方法的質量.
6.3.1 參數敏感性測試
1) 用戶行為理解模型參數
采用困惑度和ACS兩個評價指標查找最優的活動數目K和區域數目R.
UTAM模型的困惑度和ACS隨活動數目選擇的變化趨勢如圖8所示:
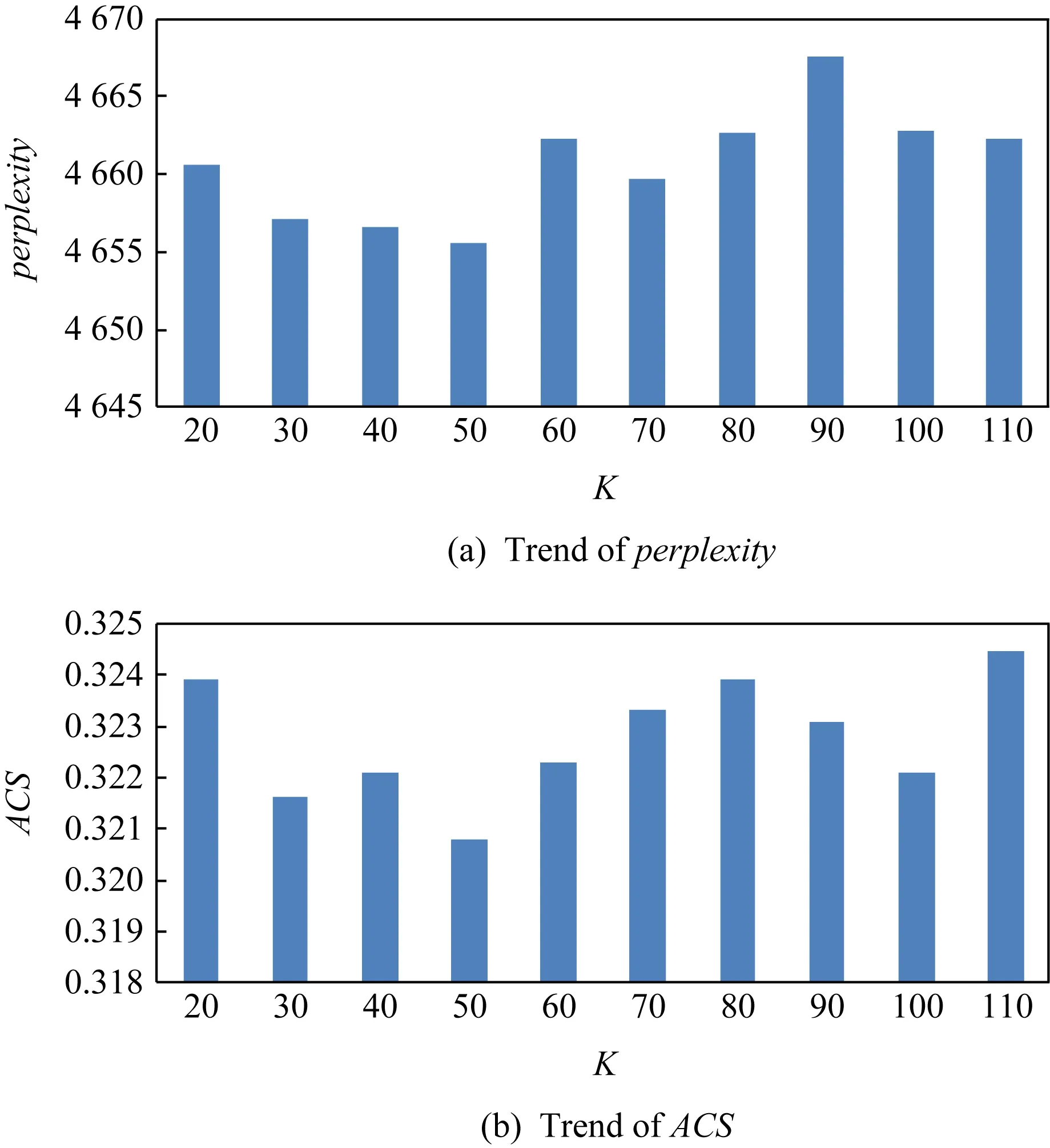
Fig. 8 The influence of activity number on USAM圖8 活動主題數目對USAM模型的影響
在圖8(a)中,隨著活動數目的增加,困惑度呈現先降低后升高的趨勢,在K=50時困惑度最低.產生這種現象的原因是:當活動數目較少時,很多潛在的活動并沒有挖掘出;當活動數目較大時,出現過擬合現象,即有一部分活動是重復的.在圖8(b)中剛開始ACS呈現下降的趨勢,當活動數k=50時,ACS達到最低,之后ACS呈現上升趨勢.綜合看圖8(a)和圖8(b),當活動數k=50時,USAM模型最穩定.
USRM模型的困惑度和ACS隨區域數目的變化趨勢如圖9所示.在圖9(a)中,開始困惑度較高,隨著區域數目的增加,困惑度下降較明顯,當R=150時,困惑度最低,之后緩慢增加.產生這種現象的原因是:當區域數目R<150時,很多潛在的區域并沒有發現;當R>150時,有一部分重合,出現過擬合現象.在圖9(b)中,ACS隨區域數目的增加,變化不明顯,但也呈現出先降后升的趨勢,當R=150時ACS最低.綜合考慮,當R=150時,困惑度和ACS都是最低的,這時UTRM模型的結構最穩定.
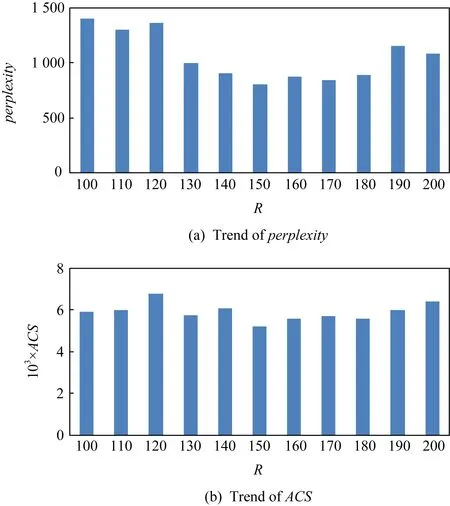
Fig. 9 The influence of regions number on USRM圖9 區域數目對USRM模型的影響
2) 活動-服務模型參數
為了得到最優的活動主題數和服務主題數,同樣采用perplexity和ACS指標.
圖10展示了主題數的變化對活動模型的影響,當活動主題數為70、服務主題數為130時,困惑度的值最低;當活動主題數為80,70,服務數為50,80,130,ACS的值較低,在圖10中使用了顏色最深的(紅色)柱形進行標注.圖11展示了主題數對服務模型的影響,當活動主題數為80,70且服務主題數為50,130時,困惑度值較低;當活動數為70時,ACS的值較低,如圖11中顏色最深的(紅色)柱形所示.綜合考慮,當活動主題數為60、服務主題數為130時模型效果較優.
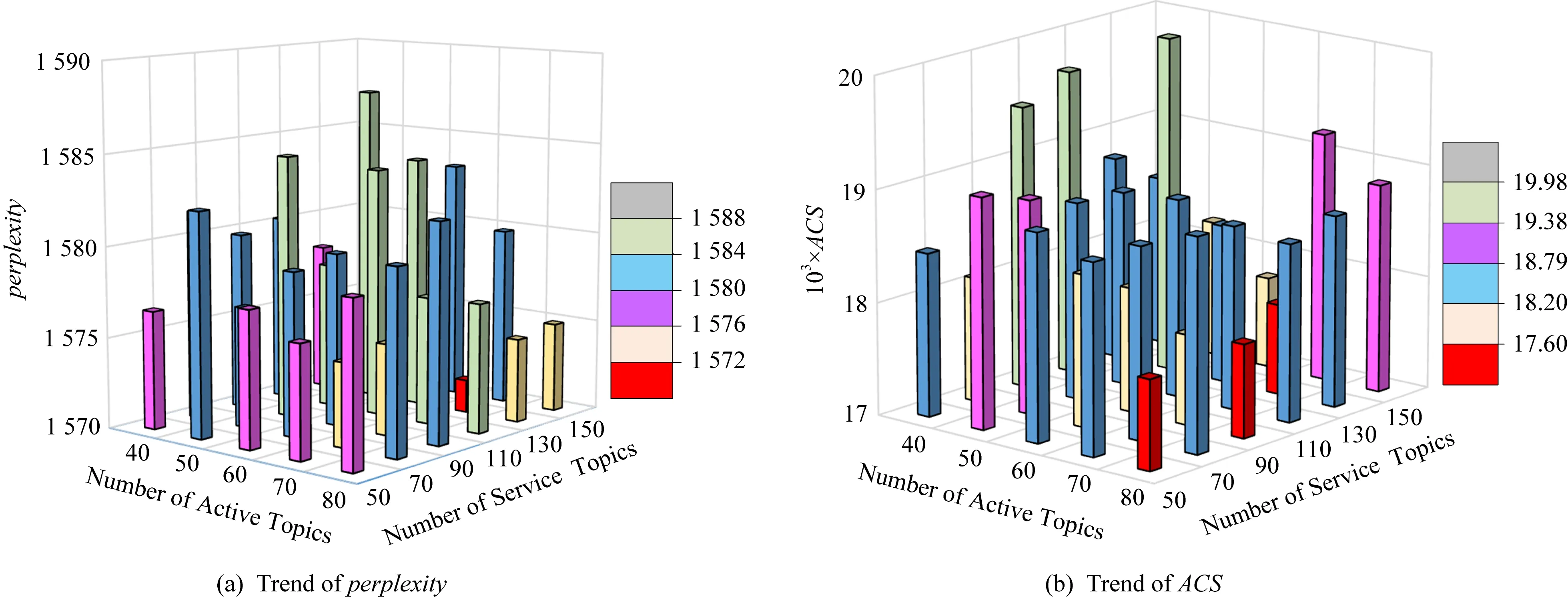
Fig. 10 The influence of topic number on behavior model圖10 活動、服務主題數對活動模型的影響
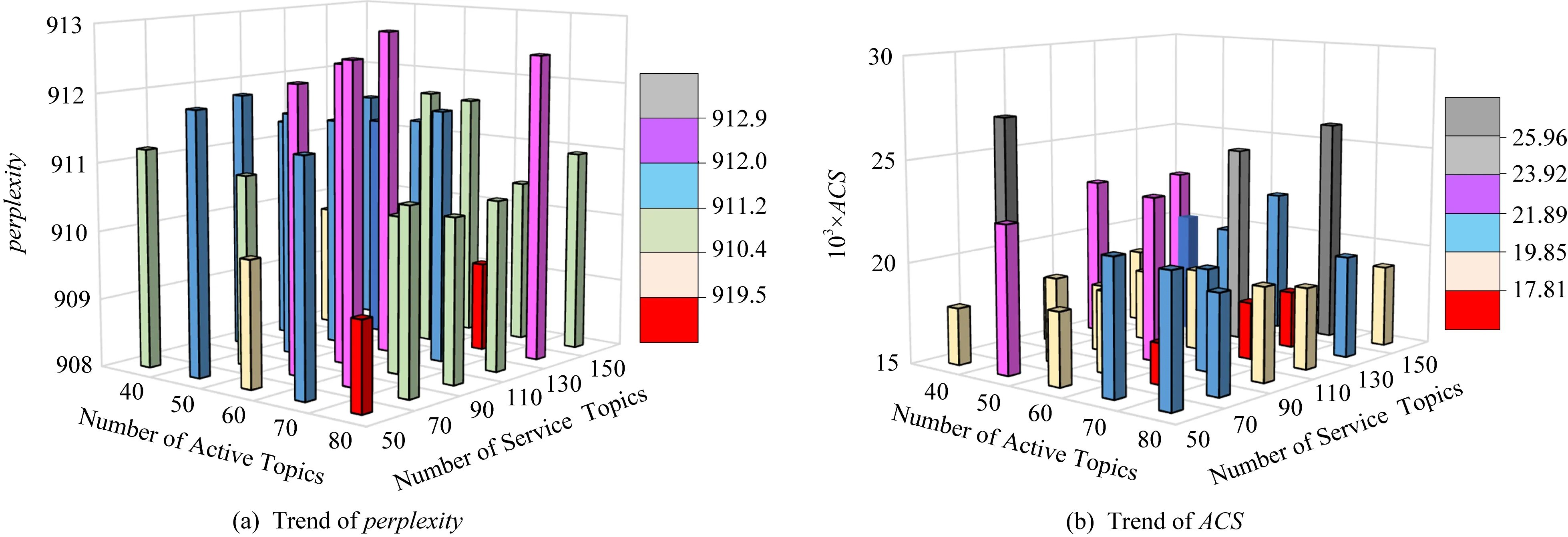
Fig. 11 The influence of topic number on service model圖11 活動、服務主題數對服務模型的影響
參數ρ是耦合項正則化權重,作用是調整地點間耦合性對預測結果的影響.為了選取合適的參數,觀察在不同取值下的推薦效果.這里僅展示ρ在0~1之間的變化.圖12展示了RMSE變化情況.由圖12可知,參數ρ的取值會影響矩陣分解的性能,在實際應用中要根據實際情況選擇合適的參數,因為當我們推薦一些服務地點給用戶后,用戶的主觀評價可能占據著主導的作用,也可能用戶更看重它近鄰的參考意見或者選擇跟自己需求最大的服務地點更相似的地點.
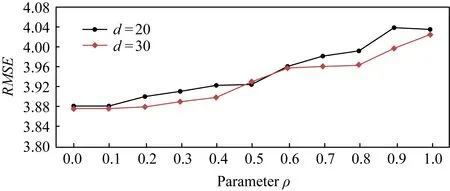
Fig. 12 RMSE of CDMF by changing parameter ρ圖12 調整ρ算法RMSE變化情況
另外一個參數是通過耦合相似度得到某地點的相似集合,選取相似度較高的前T個,參數T對算法有一定影響.圖13可以看出在當前數據集下,隨著T的數目增加,RMSE逐漸降低,當T=30時RMSE最小,之后達到飽和趨于平穩.
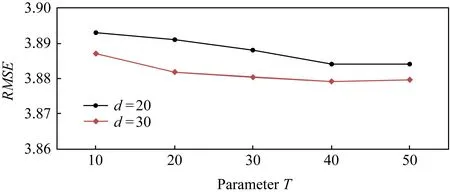
Fig. 13 RMSE of CDMF by changing parameter T圖13 調整T算法RMSE變化情況
6.3.2 推薦系統性能測試
本文使用了地理位置的類型特征,如Coffee Shop,Park,Restaurant等,利用用戶活動區域計算距離,地點屬性信息計算相似度,訓練MFCD完成推薦.
為了評價MFCD的有效性,將該模型和基礎矩陣分解(Basic MF)、帶偏差的矩陣分解(With Biases MF)模型進行比較.對于每個方法都設置了不同的淺層因子維度,分別是5,10,50,梯度下降步長因子設置為0.001,正則化權重ν=0.005,ρ=0.1.從圖14,15可以看出,隨著淺層因子維度d的增加,RMSE,MAE呈減小趨勢,且MFCD的結果優于Basic MF和With Biases MF.d并不是越大越好,過大容易產生過擬合現象.
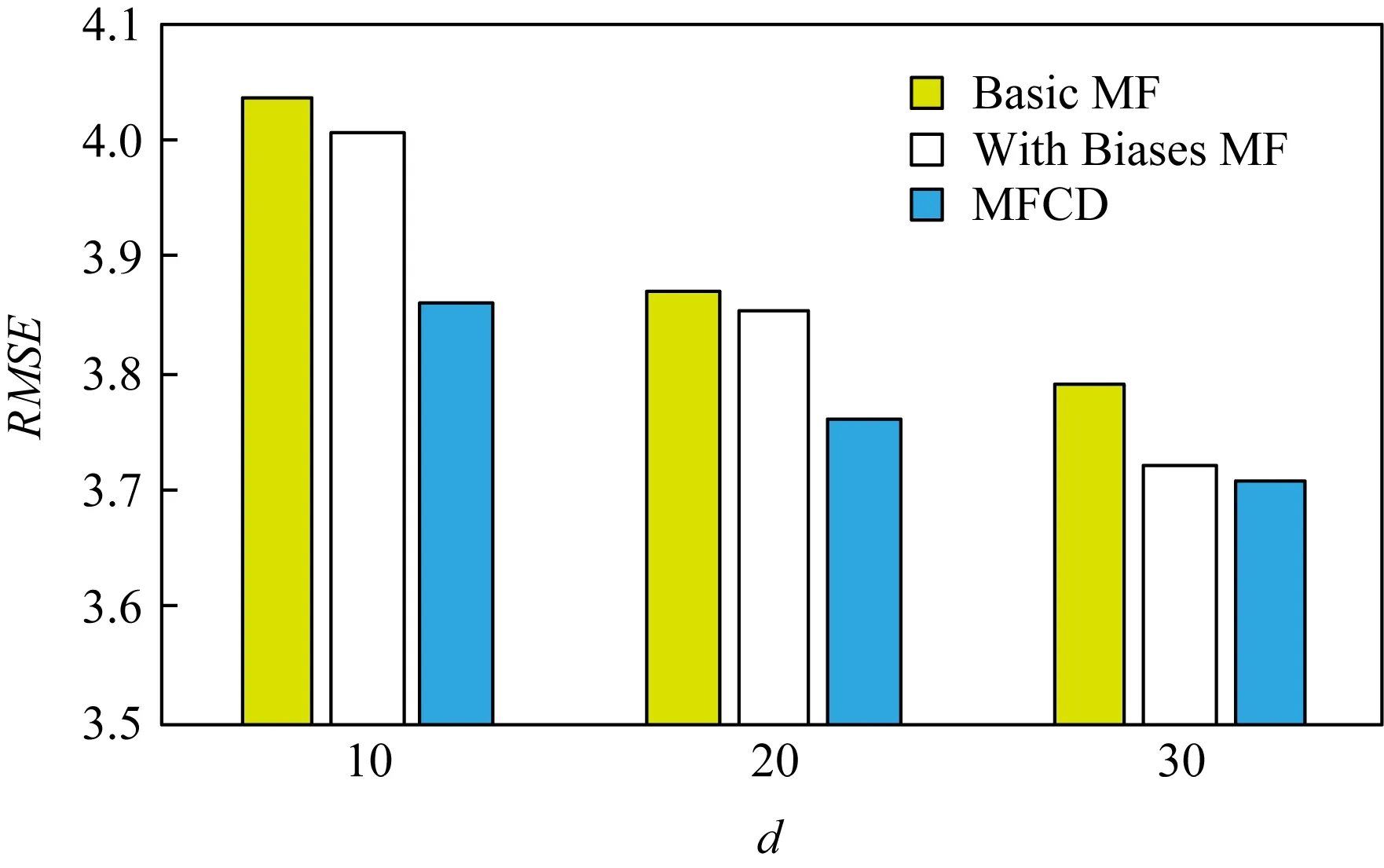
Fig. 14 The result of RMSE圖14 RMSE評價結果
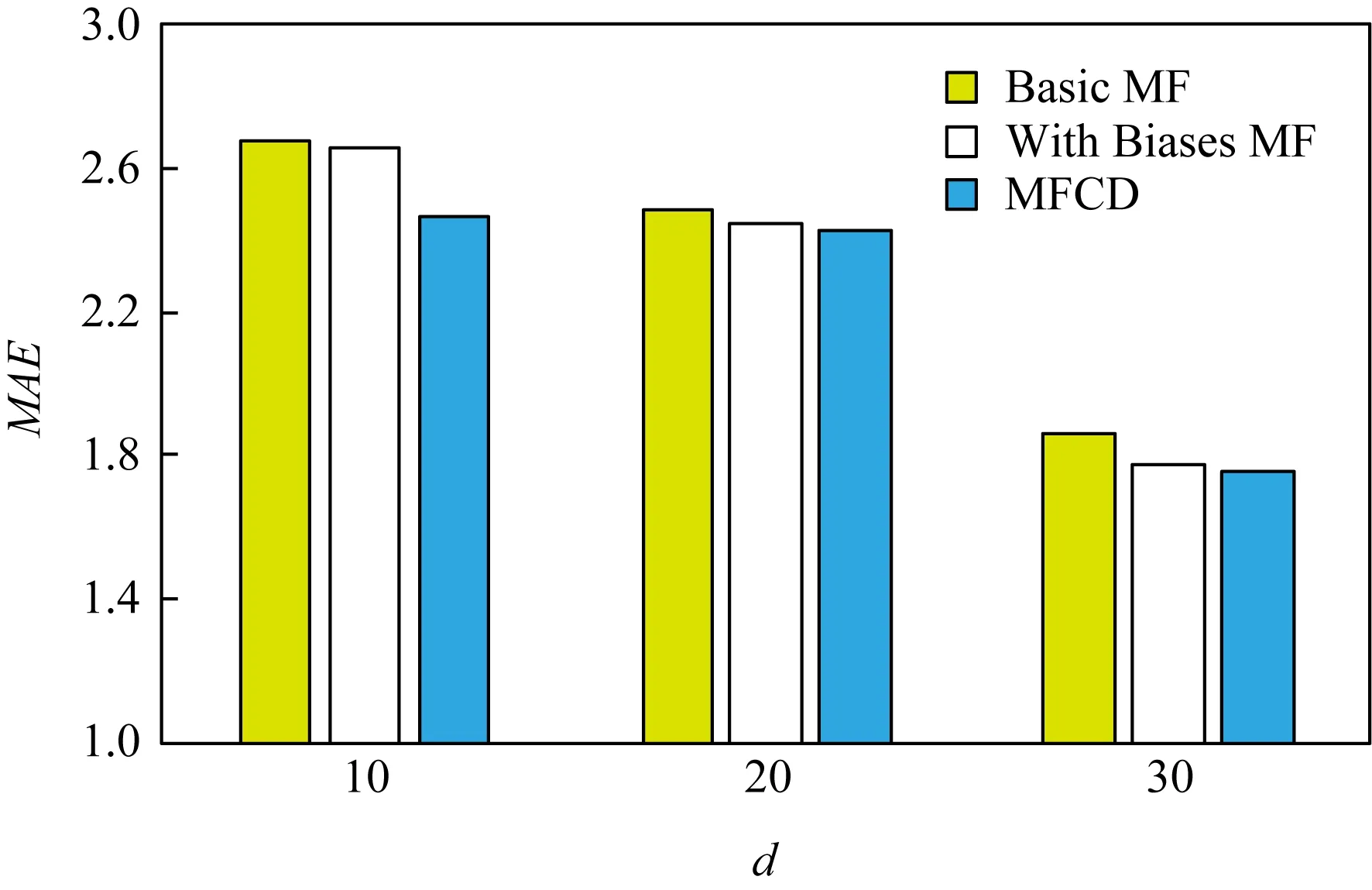
Fig. 15 The result of MAE圖15 MAE評價結果
6.3.3 推薦質量測試
本節采用準確率及召回率2個指標對推薦質量進行測試.分別測試了當為用戶推薦的服務地點數量為10,30,50這3種情況時,對應的準確率和召回率變化情況.圖16展示了隨著推薦數量d的增加,準確率呈現下降趨勢.由于用戶實際訪問的服務地點是固定的,所以隨著推薦數量的增加,準確率會呈現下降趨勢.圖17展示了隨著推薦數量的增加,召回率呈現上升趨勢.從圖16和圖17中可以看出,MFCD的推薦質量都是優于傳統的矩陣分解推薦算法.
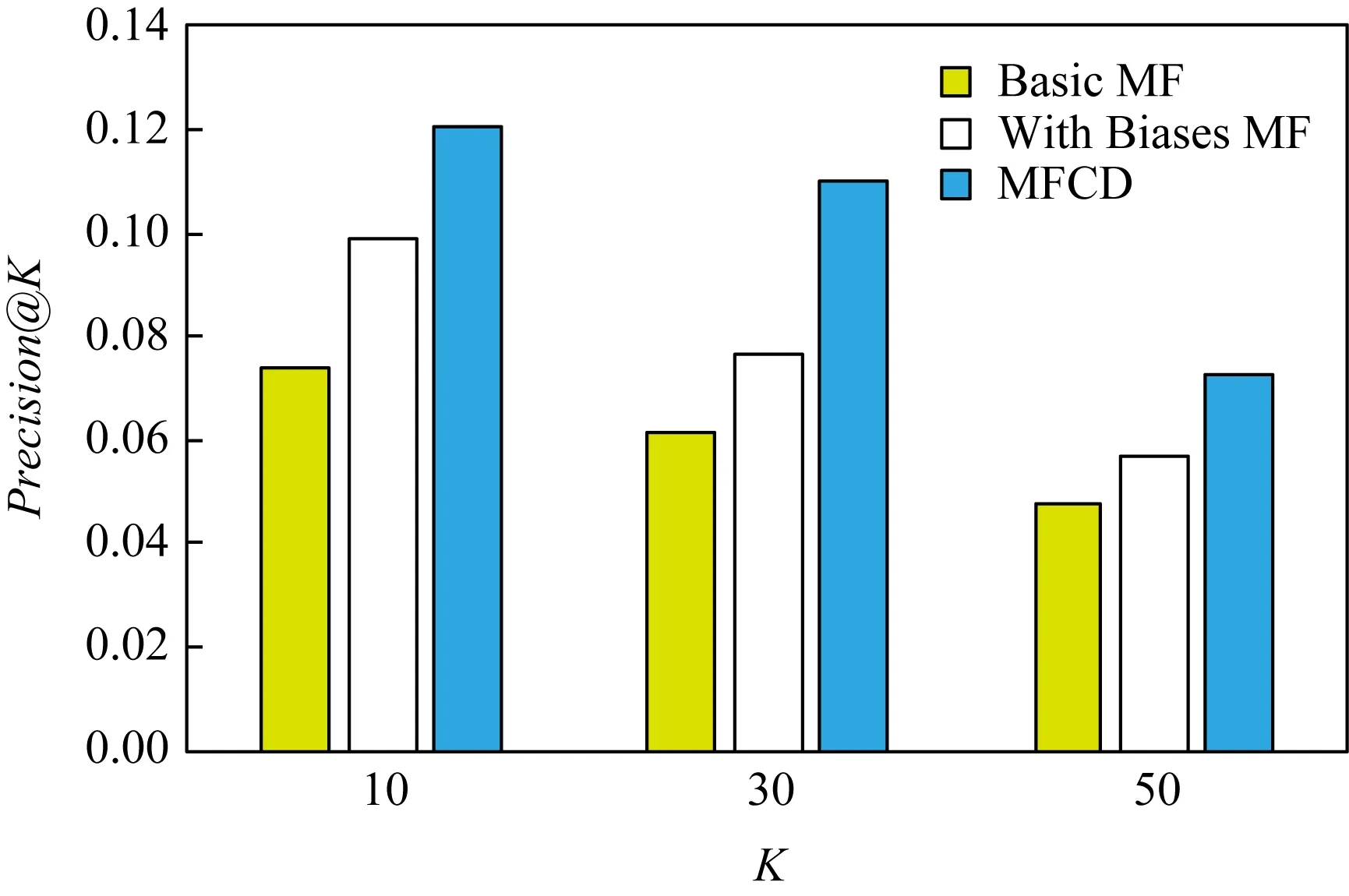
Fig. 16 The result of Precision@K圖16 Precision@K評價結果
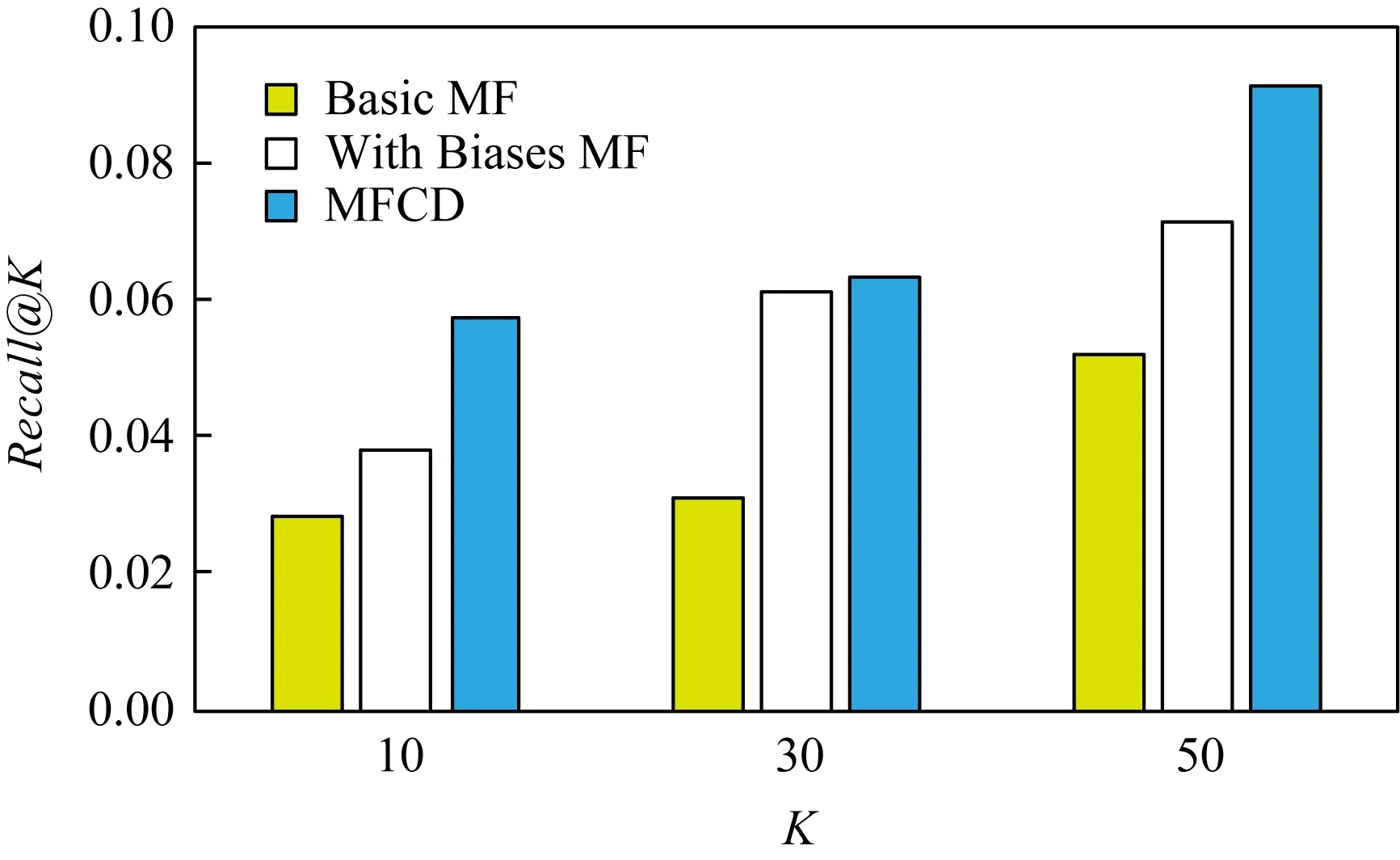
Fig. 17 The result of Recall@K圖17 Recall@K評價結果
7 結束語
為了理解用戶的行為規律,基于LDA主題模型,綜合考慮用戶行為發生的時間、活動內容、活動區域提出了UTAM,UTRM模型.其中UTAM解決了短文本導致的活動內容難于捕捉的問題;UTRM模型解決了地理位置稀疏導致的活動區域難于挖掘的問題.另外將距離和服務地點耦合性融合到矩陣分解算法中,改進目標函數,提高了推薦算法的有效性.下一步的研究工作中,我們將把用戶的屬性信息,如年齡、居住地等信息,融合到矩陣分解推薦算法中,考慮用戶屬性間的耦合相似性,進一步提高推薦質量.
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
海峽姐妹(2018年3期)2018-05-09 08:20:40
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
