實體關系抽取方法研究綜述
2020-07-18 04:13:12李冬梅李東遠林丹瓊
計算機研究與發展 2020年7期
李冬梅 張 揚 李東遠 林丹瓊
(北京林業大學信息學院 北京 100083)(國家林業草原林業智能信息處理工程技術研究中心 北京 100083)
在大數據時代,如何從海量的無結構或半結構數據中抽取出有價值的信息,引起了眾多研究者的關注,促使這一領域的研究者投入更多的精力進行研究,信息抽取技術應運而生.信息抽取主要包括3項子任務:實體抽取(entity extraction)、關系抽取(relation extraction)和事件抽取(event extraction).而關系抽取作為信息抽取中的關鍵一步,近年來也受到學術界和工業界的廣泛關注.關系抽取將文本中的無結構化的信息轉化為結構化的信息存儲在知識庫中,為之后的智能檢索和語義分析提供了一定的支持和幫助.研究人員利用關系抽取技術,從無結構化的自然語言文本中抽取出格式統一的實體關系,便于海量數據的處理;將分析出的多個實體之間的語義關系和實體進行關聯,促進了知識庫的自動構建;對用戶查詢意圖進行理解和分析,提高了搜索引擎的檢索效率等.綜上所述,關系抽取技術不僅具有理論意義,還具有十分廣闊的應用前景.
歷經MUC(Message Understanding Conference),ACE(Automatic Content Extraction),TAC(Text Analysis Conference),SemEval(Semantic Evaluation)會議和OpenIE(open information extraction)技術的20多年發展,關系抽取的理論和方法愈加完善.從最初的人工設計模式和詞典進行關系抽取,發展到目前借助傳統機器學習、深度學習技術進行關系抽取,從單一領域關系抽取發展到開放領域關系抽取.隨著關系抽取的正確率和召回率在不斷提高,關系抽取模型對不同領域的適應性也在不斷加強.
目前,關系抽取主要基于一種語言文本.事實上,人類知識蘊藏于不同模態和類型的信息源中,我們需要探索如何利用多語言文本、圖像和音頻信息進行關系抽取.這一領域仍然存在一些比較實際的問題阻礙了關系抽取在實際中的應用,這包括已標注數據集的獲取、關系抽取模型的構建、共指消解等問題.隨著這些問題的進一步解決,關系抽取技術必然會在增強檢索系統功能、語義標注、本體學習等領域得到廣泛應用.
1 實體關系抽取綜述
1.1 實體關系抽取的發展歷史
1998年在MUC-7[1]會議上第1次正式提出實體關系抽取任務.當時,這一任務主要利用模板的方式抽取出實體之間的關系,抽取的關系模板主要有location_of,employee_of,manufacture_of這三大類.在關系抽取方面,該會議主要以商業活動內容為主題,通過人工構建知識工程的方法,針對英語完成關系分類.研究人員利用Linguistic Data Consortium提供的New York Times News Service Corpus訓練集和測試集構建關系抽取模型,并完成模型的性能評估.
由于MUC會議停辦,ACE[2]評測會議替代MUC會議,繼續專門針對多源文本的自動抽取技術進行研究.ACE會議指出,實體關系定義的是實體之間顯式或者隱式的語義聯系,因此需要預先定義實體關系的類型,然后識別實體之間是否存在語義關系,進而判定屬于哪一種預定義的關系類型.該會議預先定義了位置、機構、成員、整體-部分、人-社會五大類關系,主要使用機器學習(有監督、半監督)的方法,針對英語、阿拉伯語、西班牙語等語言完成關系抽取任務.此外,會議提供了一定規模的標注語料(ACE04,ACE05)供大家研究,這為后續的研究提供了便利和支持.
此后,ACE會議于2009年并入TAC會議,同時將關系抽取任務并入KBP[3](Knowledge Base Population)會議.TAC是一系列評估研討會,旨在促進自然語言處理和相關應用的研究.KBP是人口知識庫,旨在提高從文本自動填充知識庫的能力.TAC和KBP會議提供的大規模開源知識庫(TAC-KBP),極大地推動了面向知識庫構建過程中的關系抽取技術的研究和發展.
繼MUC和ACE會議之后,SemEval會議[4]在自然語言處理領域受到了廣泛關注.SemEval會議的前身是在1997年由ACL-SIGLEX組織成立的Senseval.Senseval是國際權威的詞義消歧評測會議,其潛在的目標是增進人們對詞義與多義現象的理解.之后,除詞義消歧之外,由于其他有關語義分析的任務也越來越多,因此Senseval委員會決定把評測名稱改為SemEval,并于2007年組織了SemEval2007評測.該會議聚焦于句子級單元間的彼此聯系、語句間的聯系以及自然語言(情感分析、語義關系)等.SemEval會議定義了最初9種常見名詞及其關系(原因-影響、儀器-機構、產品-生產者、含量-包含者、實體-來源地、實體-目的地、部分-整體、成員-集合、行為-主題),采用傳統機器學習或者深度學習的方法完成英語、中文等語言的詞義、語義的消歧任務,最終對數據庫中的關系種類進行擴充.此外,該會議提供了SemEval-2010 Task 8數據集,逐漸掀起了研究人員對實體關系抽取研究的高潮,發展成為規模空前、極具影響力的評測會議.
權威評測會議MUC,ACE,TAC,SemEval為傳統的關系抽取提供了評測語料.這些領域由專家人工標注和構建的評測語料庫具有較高的質量和公認的評價方式,因此有力地引導和推進了傳統的關系抽取研究的發展,大幅度地提升了關系抽取性能.由于傳統關系抽取基于特定領域、特定關系進行抽取,導致關系抽取這一任務耗時耗力,成本極高,同時不利于擴展語料類型.近年來,針對開放領域的實體關系抽取方法逐漸受到人們的廣泛關注.
研究者利用Wikipedia,HowNet,WordNet,FreeBase等涵蓋大規模事實性信息的知識庫解決了語料獲取困難的問題,為關系抽取任務提供了有效的數據支持.與傳統的人工標注語料的方法相比較,基于Web開放語料的規模更宏大,涉及的領域更廣闊,涵蓋的關系類型也更豐富,并不需要事先對關系進行定義.為了解決互聯網海量數據的文本挖掘和分析任務,越來越多的研究者開始研究OpenIE技術[5].而開放領域的實體關系抽取作為其中的重要子任務和關鍵技術,自然也受到了研究者的廣泛關注.研究人員無需事先指定關系的定義方式,可以采用深度學習和模式匹配結合的方法,針對開放領域完成實體關系抽取任務.該類方法提高了關系模型的可移植性和擴展性,能夠通過遷移學習(transfer learning)等方式應用于其他領域.實體關系抽取的研究趨勢和關鍵會議如表1所示:
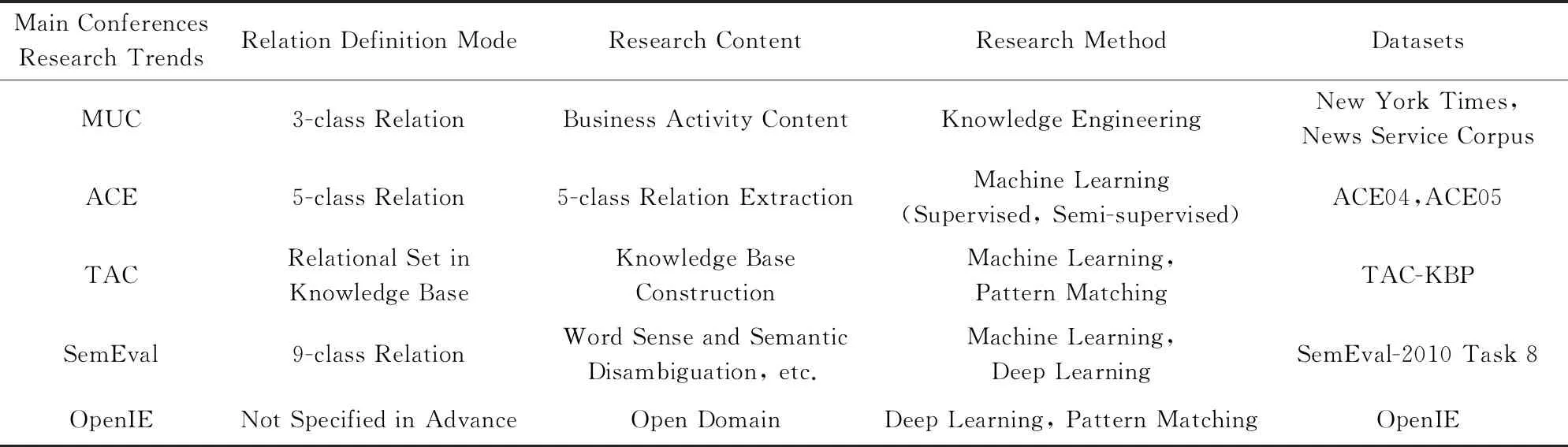
Table 1 History of Entity Relation Extraction表1 實體關系抽取的發展歷史
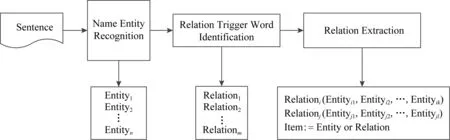
Fig. 1 The general framework of a relation extraction system圖1 關系抽取系統框架
1.2 關系抽取定義
在自然語言處理領域,關系通常主要指代文本中實體之間的聯系,如語法關系、語義關系等.通常將實體間的關系形式化地描述為關系三元組E1,R,E2,其中E1和E2指的是實體類型,R指的是關系描述類型.實體關系抽取的主要目的是從自然語言文本中識別并判定實體對之間存在的特定關系.文本經過命名實體識別、關系觸發詞識別2個數據預處理過程,將判定的三元組E1,R,E2存儲在數據庫中,供進一步的分析或查詢.
基于以上的定義,可以直觀地將關系抽取任務分成3個關鍵的模塊,即為命名實體識別和觸發詞識別2個預處理模塊以及關系抽取模塊.關系抽取系統框架如圖1所示[6]:
1) Name entity recognition,即命名實體識別,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等;
2) Relation trigger word identification,即關系觸發詞識別,是指對觸發實體關系的詞進行分類,識別出是觸發詞還是非觸發詞,判定抽取出的關系是正類還是負類;
3) Relation extraction,即關系抽取,是指從識別出的實體中抽取實體間的語義關系,如地點、雇員、產品等.
以句子“姚明出生于上海”為例,首先對句子進行預處理,識別出命名實體“姚明”和“上海”,然后“出生于”作為關系觸發詞表明這2種實體之間可能存在某種關系,最后通過關系抽取模型的判定,得出2個實體之間存在著“地點”這一關系.
1.3 關系抽取特點
關系抽取是一個文本分類問題,相比于情感分類、新聞分類等其他任務,關系抽取主要有3個特點.
1) 領域眾多,關系模型構建復雜.針對一個或者多個限定領域的關系抽取的研究時間較長,研究者投入的精力相對開發領域多,因此方法眾多,技術成熟.由于限定了關系類別,可采用基于規則[7-13]、詞典[14-17]以及本體[18-20]的方法,也可采用傳統機器學習的有監督[21-35]、半監督[36-48]以及無監督[49-57]方法,深度學習的有監督[58-89]、遠程監督[90-99]方法.這類方法的模型構建難度相對于開放領域難度較低,但是移植性和擴展性較差.而針對開放領域的關系抽取[100-117],由于關系類型多樣且不確定,可以采用無監督和遠程監督等方法.
2) 數據來源廣泛,主要有結構化、半結構化、無結構3類.針對表格文檔、數據庫數據等結構化數據,方法眾多,現通常采用深度學習相關[65]的方法等;針對純文本的無結構數據,由于無法預料全部關系類型,一般采用以聚類為核心的無監督方法[50-55]等;而針對維基百科、百度百科等半結構化數據,通常采用半監督[52-53]和遠程監督方法[92-93]等.
3) 關系種類繁多復雜,噪音數據無法避免.實體之間的關系多樣,有一種或多種關系,早期方法主要針對一種關系(忽略重疊關系)進行抽取,這類方法忽略了實體間的多種關系,對實體間的潛在關系難以處理.近年來,圖結構[73-77,88-89]逐漸應用于關系抽取領域,為關系重疊和實體重疊提供了新思路.而針對噪音數據,Bekoulis等人[86]發現少量對抗樣本會避免模型過擬合,提出使用對抗訓練提高模型的性能.
1.4 關系抽取常用工具
實體之間的關系一般用文本的句法特征和語義特征來表示,因此需要對文本進行分析.下面主要介紹國內外性能比較穩定且廣受關注的文本分析工具.
1.4.1 英文關系抽取常用工具
1) NLTK(natural language toolkit)[118]
2009年賓夕法尼亞大學計算機和信息科學系實驗室里開發了NLTK.NLTK是一個基于腳本語言Python開發的自然語言處理工具包,該工具包具有免費、開源等特點,并集成了中文分詞、詞形還原、文本分類以及語義推理等一系列文本處理技術,并涉及50多種語料庫和詞匯資源的交互界面,促進了研究人員對自然語言處理領域的開發和研究.
在關系抽取方面,研究人員通過該工具包提供的文本分析、文本分類等功能對文本進行預處理,進而對句子結構和語法特征進行分析,推斷句子中實體之間是否存在的語義聯系.
2) DeepDive[119]
2014年斯坦福大學發布了DeepDive.它是一種新型數據管理系統,可以在單個系統中解決提取、集成和預測問題.相對于其他關系抽取工具,DeepDive使研究者關注重點在實體關系之間的特征而不是具體的算法,這有效地減輕了研究者的工作負擔.此外,DeepDive是一個性能良好的系統,使用機器學習消除各種形式的噪音和不精確數據.在科學領域,DeepDive抽取復雜知識的表現優于人類志愿者,特別是在實體關系抽取比賽中取得了較好的成績.
3) Stanford CoreNLP[120]
2014年斯坦福大學自然語言處理研究小組在第52屆國際計算語言學協會(The Association for Computational Linguistics, ACL)發布了一系列較為成熟的自然語言處理工具包Stanford CoreNLP.該工具包由眾多語法分析工具集成,提供多種編程語言的接口,能實現對任意自然語言文本進行分析.該工具包為研究者提供了許多基礎性的工具,如詞性標記器(POS)、命名實體識別器(NER)、解析器、共參考分辨率系統、情感分析、自舉模式學習和開放信息提取等.研究者利用這些工具包,可以根據短語和語法依賴來標記句子的結構、發現實體之間的關系、分析出句子所表達的情感等.
1.4.2 中文關系抽取常用工具
1) 中文分詞工具
和英語等語言相比較,中文具有較大的差異,如中文詞語之間沒有空格,因此對中文的關系抽取任務首先需要進行中文分詞.結巴分詞(jieba)、清華分詞(THULAC)、中國科學院計算技術研究所分詞(NLPIR)、哈爾濱工業大學分詞(LTP)等是國內常見中文分詞的工具.這些工具對文本數據進行預處理,將字序列切分成具有語言含義的詞序列,便于對中文領域的文本進行關系抽取.
2) LTP-Cloud[121]
2014年哈爾濱工業大學聯合科大訊飛公司共同推出了LTP-Cloud.LTP-Cloud以哈工大社會計算與信息檢索研究中心研發的“語言技術平臺(LTP)”為基礎,為用戶提供高效精準的中文自然語言處理云服務.LTP-Cloud支持跨平臺、跨語言編程等,并提供了一整套自底向上的豐富、高效、高精度的中文自然語言處理模塊應用程序接口和可視化工具等.在實體關系抽取方面,研究人員利用該系統對中文文本進行分詞、詞性標注、命名實體識別等進行預處理,通過依存句法分析、語義角色標注和語義依存分析,抽取實體間存在的關系.
1.5 中文關系抽取的特殊性
面向中文文本的關系抽取起步較晚,而且中文與英文等語言相差較大.中文語料庫的建立需要經過中文分詞、詞性標注和句法分析等預處理,并且在處理的過程中會存在很多錯誤,這就導致中文實體關系抽取的效果也略差于英文關系抽取.因此,中文領域的實體關系抽取研究具有較大的挑戰性,主要存在3個特殊性:
1) 中文的單元詞匯邊界模糊,缺少英文文本中空格這樣明確的分隔符,也沒有明顯的詞形變換特征,因此容易造成許多邊界歧義,從而加大了關系抽取的難度.
2) 中文觸發詞抽取難度較大,且數目過多.中文自然語言處理底層技術研究還不夠成熟,導致錯誤的級聯.如在長句子的句法分析上,ACE語料中大量出現詞語個數大于30的長句子,句法分析效果較差.此外,中文觸發詞數目過多,導致關系抽取召回率較低.通過對語料的分析發現,由于中文詞匯表達的多義性,對同一類事件,中文觸發詞的個數要遠大于英文.文獻[123]統計表明在ACE語料里中文觸發詞個數比英文多30%.
3) 中文存在多義性、句式復雜表達靈活、多省略等特點.不同領域中的同一個詞語表示的意思并不一樣,或者同一種語義可能存在多種表達形式.此外,由于互聯網的快速發展,網絡文本中的文字描述更加個性化,許多詞語具有不同意義,中文命名實體在不同語境下被賦予了不同的意義(如高富帥、黑天鵝等),使得關系類型的識別更為困難.
1.6 關系抽取評價體系
針對特定領域的關系抽取的結果,一般通過計算對應的準確率(Precision)、召回率(Recall)和F1值來評價.其中,準確率是對于給定的測試數據集,分類器正確分類為正類的樣本數與全部正類樣本數之比;召回率則是對于給定的測試數據集,預測正確的正類與所有正類數據的比值;而F1值則是準確率和召回率的調和平均值,可以對系統的性能進行綜合性的評價.對應的計算為
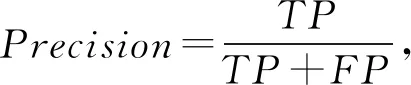
(1)
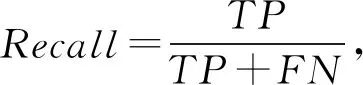
(2)
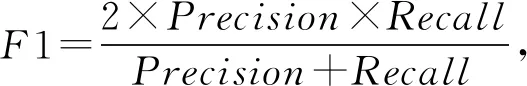
(3)
其中,數據有2種類型:測試集數據和預測結果數據.對一批測試數據進行預測,一般可以將關系抽取的結果分成4種:
1)TP(true positive ).原本是正類, 預測結果為正類(正確預測為正類).
2)FP(false positive).原本是負類,預測結果為正類(錯誤預測為正類).
3)TN(true negative).原本是負類,預測結果為負類(正確預測為負類).
4)FN(false negative).原本是正類,預測結果為負類(錯誤預測為負類).
針對開放領域的關系抽取,目前還缺少公認的評測體系,一般通過考查抽取關系的準確性以及綜合考慮算法的時間復雜度、空間復雜度等因素來評價關系抽取模型的性能.
2 實體關系抽取主要方法
本文以關系抽取的發展歷程為主線,經過總結和整理將關系抽取的方法主要分為四大類,接著根據處理特點細分為若干種不同的子方法,并簡要表示了各類方法之間的聯系和區別.具體分類方法如圖2所示:
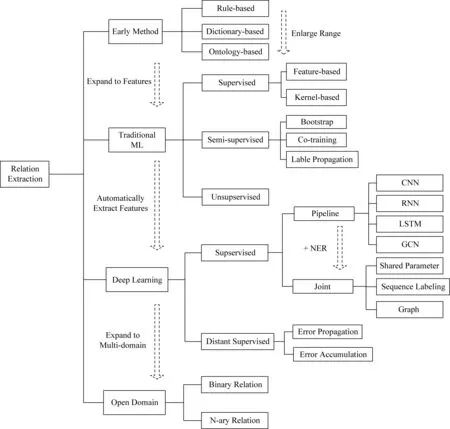
Fig. 2 The classification of relation extraction圖2 關系抽取分類
2.1 早期的關系抽取方法
2.1.1 基于規則的關系抽取方法
早期的關系抽取方法主要是通過人工構造語法和語義規則.基于規則的方法需要運用語言學知識提前定義能夠描述2個實體所在結構的規則,這些定義的規則主要由若干基于詞語、詞性或者語義的模式集合構成.在關系抽取的過程中,將已經預處理的語句片段與模式進行匹配判定,完成關系抽取的分類.
Aitken[7]借助自然語言數據并應用歸納邏輯編程(ILP)技術獲得了信息提取規則,在包含371個句子的數據集中,F1值可達66%.McDonald等人[8]利用語義過濾和專家評估顯示解析器在生物領域分別使用NE,MC,PC這3個系統進行生物相關的關系抽取,其中PC系統的平均F1值為69%,且相比使用最大斜率和枚舉的方法分別減少13%和31%的錯誤率.Aone等人[9]對語料文本的特點進行總結,邀請知識領域專家編寫文本關系描述規則,從而在文本中抽取與規則匹配的關系實例.Humphreys等人[10]首先對句子進行句法樹分析,將分析的結果作為輸入,并利用人工構造復雜的句法規則實現實體之間語義關系的識別.Fukumoto等人[11]提出了OKI信息抽取系統,可以進行命名實體、模板化元素、模板化關系,其中關系抽取采用實體之間的謂詞信息來判定2個實體之間的語義關系.中文領域基于規則的關系抽取起步較晚.鄧擘等人[12]發現,相比于英文直接用模板匹配句子的方式,中文關系抽取方法的準確率和召回率低很多.因此它們在模式匹配的基礎上引入了詞匯、語義匹配技術對中文領域的實體關系進行抽取.實驗結果表明,利用詞匯、語義模式匹配的方法更適合于處理中文實體關系抽取任務,詞匯語義模式匹配相比直接匹配模式F1值提高了近30%.溫春等人[13]提出一種擴展的關聯規則方法用于抽取中文非分類關系,在利用普通關聯規則抽取出非分類關系概念對后,通過語言學規則抽取相應的非分類關系名稱.該方法克服了普通關聯規則方法無法得出具體非分類關系名稱的缺點,能夠確定非分類關系的定義域和值域.
基于規則的關系抽取方法要求規則構建者(如語言學家等)對領域的背景和特點有深入的了解.在限定了領域以及語料的規模時,早期的關系抽取方法取得了一定的成就.而基于規則的關系抽取方法的缺點則是對跨領域的可移植性較差、人工標注成本較高以及召回率較低.這些基于規則的關系抽取方法所帶來的困擾驅使研究者嘗試跳出該方法的局限,轉而使用基于詞典等方法.
2.1.2 基于詞典驅動的關系抽取方法
在基于詞典驅動的關系抽取方法中,需要對詞典進行擴充,通常只需新增指示實體關系類型的動詞即可.該方法通過字符串匹配算法識別給定文本中的實體,并利用領域詞典中的動詞及其動詞的關系結構判別關系類型,最終完成關系抽取任務.該方法以其簡潔高效的特點曾經引起研究的熱潮.
Aone等人[14]基于大規模事件提出一種關系抽取方法,該方法具有開銷小、準確率高的特點,在39種關系類型構成的測試數據集中,實驗數據F1可達75.35%,相比于McDonald基于規則的方法提高6.35%,而在多類型的關系和事件共同抽取時F1值可達73.95%;Temkin等人[15]利用詞典表示2個蛋白質之間關系的關系詞,但是該關系詞抽取方法的性能完全依賴于詞典的質量和規模,而且需要耗費大量的人工;Neelakantan等人[16]嘗試利用包含18 546條標注句子的數據集來訓練二元分類器,從未標注的大規模語料的候選實體中選擇真實的實體,自動地構建相關實體類型的詞典;文獻[17]通過對文本分析發現,信息系統通常需要2個詞典:語義詞典和表示關系類型提取模式的詞典,該文獻提出了一種多級自舉(bootstrapping)的方法,可以同時生成語義詞典和提取模式.該方法將標注的文本和關系類別的種子詞作為輸入,采用多級自舉的算法交替選擇最佳的提取模式,通過不斷迭代的方式擴充語義詞典和關系抽取模板詞典.
由于構建的詞典均是以動詞為關系抽取的核心依據,難以解決其他詞的關系類型的抽取識別,而且靈活性較差.因此,研究者開始探索新的關系抽取方法.
2.1.3 基于本體的關系抽取方法
知識管理過程中,基于本體的方法利用信息抽取技術抽取出的實體以及實體間的關系來構建和豐富本體,借助己有的本體層次結構和其所描述的概念之間的關系來協助進行關系的抽取.
Iria[18]提出了可訓練關系抽取的框架(trainable relation extraction framework, T-Rex),該框架是一個基于本體的關系抽取通用軟件框架,可以自動靈活地對語義網進行語義標注,能夠將語料模型化到字符級、語詞級、短語級、語句級和文檔級層次,實現對本體的定義和擴充.在足球領域,Schutz 等人[19]結合DOLCE,SUMO,SEO等本體構建了Relext系統,該系統能自動識別實體和實體之間的關系.Sabou等人[20]提出自動選擇和查詢本體的SCARLET系統可以使用2種策略發現實體概念之間的關系:1)如果2個概念之間的關系已經被定義于單個本體中,則認為這2個概念之間有關系;2)以遞歸的方式跨實體發現2個概念之間的關系.
2.2 基于傳統機器學習的抽取方法
基于傳統機器學習的方法以統計語言模型為基礎,研究思路明確,并采用相對簡單的方法獲得較好的效果.基于機器學習的實體關系抽取方法以數據是否被標注作為標準進行分類,主要集中于3類方法:有監督的關系抽取算法、半監督的關系抽取算法、無監督的關系抽取算法.機器學習的方法優點明顯,能夠明顯提升結果的召回率,領域限制性弱于早期的3種關系抽取方法.
基于傳統機器學習的關系抽取算法主要分為學習過程和預測過程2個主要部分,一般流程如圖3所示.

Fig. 3 General flow of relation extraction algorithm based on traditional machine learning圖3 傳統機器學習的關系抽取算法的一般流程
1) 學習過程.采用訓練樣本,學習出關系抽取模型.
① Preprocessing,即預處理,將語料文本清洗成可以直接抽取的純文本格式;
② Textual analysis,即文本分析,對文本的表示及其特征(POS,NER等)進行選取;
③ Relation represention,即關系表示,即對實體之間的聯系進行語義表示;
④ Relation extraction models,即關系抽取模型,基于關系表示構建分類模型.
2) 預測過程.利用學習過程獲得的關系抽取模型對測試文本進行關系的預測和抽取.
一般預測過程和訓練過程中的Preprocessing,Textual analysis,Relation represention步驟相同,不同在于Relation decision,該步驟的具體工作為:
Relation decision,即關系判定,利用訓練過程中得到的關系抽取模型對測試集數據中的實體之間的關系進行判定.
2.2.1 有監督的關系抽取方法
有監督的關系抽取方法將關系抽取任務看作分類問題.通常需要預先了解語料庫中所有可能的目標關系的種類,并通過人工對數據進行標注,建立訓練語料庫.使用標注數據訓練的分類器對新的候選實體及其關系進行預測、判斷.
有監督的機器學習方法將一般的二元關系抽取視為分類問題:

(4)
其中,s=w1,w2,…,e1,…,wj,…,e2,…,wn,即為包含實體關系的文本,ei為實體類型,wj為關系觸發詞,F為關系分類器.基于特征向量抽取以及基于核函數的方法是實體關系抽取方面中最流行的有監督的抽取方法.
1) 基于特征向量的抽取方法
基于特征向量抽取的方法主要從關系實例中提取一系列特征向量,主要有3種特征類型:詞匯特征、句法特征、語義特征.研究者根據不同的特征類型,利用機器學習算法顯式地將語料構造成特征向量這一形式,以此建立不同的分類模型,例如最大熵(max intropy, MI)、支持向量機(support vector machine, SVM)、樸素貝葉斯(naive Bayes, NB)、條件隨機場(conditional random field, CRF)等.這一類機器學習算法相對簡單,方便實體關系抽取任務的順利完成.
基于特征向量的抽取方法的一般流程如下:
① 根據語料庫的文本信息,選擇合適的特征;
② 根據選取特征的重要程度,賦予特征不同的權重進行計算;
③ 選擇合適的分類器訓練特征向量,得到關系抽取模型.
Kambhatla[21]綜合實體上下文信息、句法分析樹、依存關系等多種特征,將詞匯、句法和語義特征與最大熵模型相結合進行關系分類.該方法利用實體上下文豐富的語言特征有利于擴展關系表達的規模和質量,為后續關系抽取奠定了基礎.Zhou等人[22]的研究更為深入,他們借鑒Kambhatla的經驗方法,融合了基本的文法分塊(chunking)信息、半自動地收集特征(如名稱列表、詞匯列表等),利用支持向量機進行關系分類,利用具有43種子類型的測試數據集ACE進行評測,F1值可達55.5%.
Sun等人[23]融合上下文特征和2個實體間的長期相關性特征、實體順序特征、實體間順序特征以及標點符號特征,并混合樸素貝葉斯模型和投票感知模型(voted perceptron, VP)兩種算法進行關系分類.
Jiang等人[24]為了進一步提高關系抽取的準確性,系統地研究和分析了從各種信息中的抽取特征并進行了描述.該方法綜合考慮了技術的復雜程度以及不同維度的特征,將特征劃分成不同的子空間,結合條件隨機場模型取得了較好的效果,利用包含97篇文檔的ACE測試數據集(1 386條句子約合5萬個單詞)進行評測,F1值可達54.0%.
在中文領域,車萬翔等人[25]結合實體類別、實體位置關系、前后詞信息等,利用Winnow和SVM 2種機器學習算法進行訓練和識別中文關系,實驗表明,相對于Winnow算法,SVM算法所需的運行時間較長,但當將窗口大小設置為2時,其平均召回率和平均F1值分別提高約2%和1%.郭喜躍等人[26]以詞法特征、實體原始特征為基礎,融合依存句法關系、核心謂詞和語義角色標柱等特征進行關系抽取,極大程度上提高了關系抽取方法的性能.高俊平等人[27]提出了一種基于關系推理模型的領域知識來演化關系抽取方法.實驗結果表明,該方法相對于傳統方法,考慮了深層句法特征,因此具有更高的準確性,更適合中文領域知識演化關系抽取.甘麗新等人[28]綜合詞法特征、實體特征、句法特征以及語義特征等,豐富了實體間的關系特征.將1998年1月份的《人民日報》所有版面內容的40 000多條中文句子作為語料庫,得到了3.6億個二元實體對,擴大了中文實體關系庫的規模.以“基本特征”和“基本特征+句法語義特征”2種方法進行關系抽取,實驗表明后者在準確率、召回率、F1值這3個評估指標中比前者分別提高2.21%,7.83%,4.98%,分別可達76.03%,79.85%,77.89%,提高效果十分明顯.
2) 基于核函數的抽取方法
基于特征向量抽取的方法是顯式地構造特征向量形式,而基于核函數的方法則是隱式地計算特征向量的內積.此類方法在輸入句法結構樹之后,直接利用核函數比較關系實例之間的結構相似性.基于核函數方法的關鍵在于設計出計算2個關系實例相似度的核函數.早期的核函數主要是序列核函數,這種方法綜合關系實例特征向量的順序和結構信息,具有較好的復合性能.基于核函數在一定程度上能提高分類的準確率,有利于指導和促進了實體關系抽取的研究和發展.
使用核函數方法來抽取實體關系一般流程如下:
① 合理選擇解析結構(如語法樹等)隱式地計算特征向量的內積;
② 合理選擇基礎核函數,之后考慮關系實例特征向量的順序和結構信息,分析關系實例的相似性;
③ 充分利用各種特征,可以對多個核函數進行復合,以提高關系抽取任務的分類精度.
近年來,研究者將多種不同的核函數運用在英文領域的關系抽取任務中.Zelenco等人[29]利用動態規劃算法,首次在淺層解析樹結構中應用核函數.該方法使用支持向量機和投票感知模型等方法進行關系抽取的分類任務;在Zelenco的基礎之上,Culotta等人[30]運用基于支持向量機的方法,融合依存樹函數和知識庫WordNet,提出了擴展子樹節點間的匹配算法,并使用數量少于15%正類關系實例進行訓練,相比Zelenco的方法F1提高了2%~3%;Zhou等人[31]融合最短路徑和卷積樹核函數進行實體關系抽取,該方法考慮不同層面的語義關系特征,定義了基于樹的卷積核,綜合考慮了謂詞上下文,最終完成了關系抽取任務;Zhang等人[32]首次提出融合多個單一核函數的方法,利用復合核函數進行關系抽取任務.實驗結果表明,復合核函數的表現比任何單一核函數實驗效果更佳,其準確率、召回率、F1分別達到了76.6%,67.0%,71.5%,但復合核函數容易產生過擬合現象,且計算復雜度較高.
在中文研究方面中,劉克彬[33]利用基于核函數的關系抽取方法自動地抽取中文實體關系.該方法在語義序列核函數的基礎之上,結合K-近鄰算法(KNN),構造了關系分類器進行關系抽取;郭劍毅等人[34]改進了徑向基核函數,并融合了多項式函數及卷積樹核函數,利用向量離散化的矩陣訓練關系抽取模型,實驗表明改良的多核融合方法性能更優;虞歡歡等人[35]在卷積樹核函數方法的基礎上,以實體的語義信息作為樹結構的結點進行擴展,使用ACE RDC 2005 中文基準數據集(預處理后挑選了532個文檔,總共有正類關系7 630個,負類關系83 063個)進行實驗,在大類抽取中最佳F1達到了67.0%,能有效地對中文文本進行關系抽取.
基于核函數的方法以語料本身的結構信息為基礎,比較結構化關系實例之間的相似性,完成關系抽取任務.該方法在一定程度上節省了構建高維特征的復雜工作,但在隱式計算的過程中容易產生噪聲,而且運算速度較慢.關于基于特征向量和基于核函數的比較如表2所示:
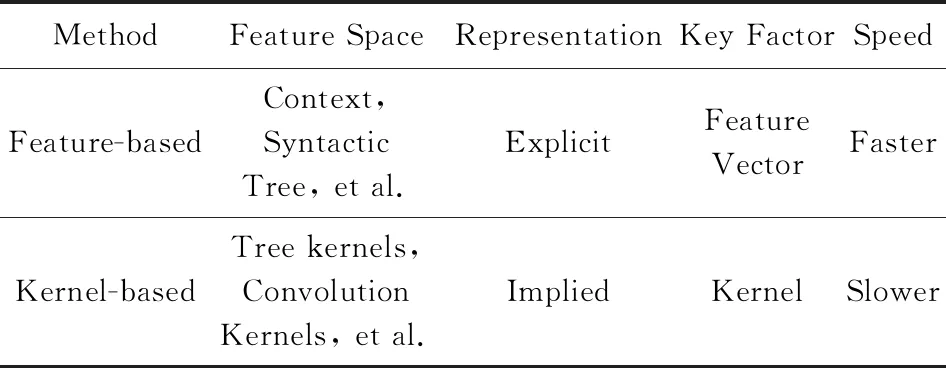
Table 2 Comparison of Relation Extraction Methods Based on Supervised Machine Learning
綜上所述,有監督的機器學習關系方法在關系抽取任務中取得了較好的效果.然而有監督的機器學習方法依賴標注的語料資源庫,必須進行大量的預處理工作,耗費大量人力,而且無法自動地進行關系抽取和擴展實體關系的類型.因此,越來越多的研究者開始利用較少的人工參與和標注語料資源的半監督方法進行關系抽取.
2.2.2 半監督的關系抽取方法
為了解決有監督的關系抽取方法在標注大量語料時所帶來的高成本問題,學者開始研究利用少量的標注語料或數據庫進行關系抽取任務,半監督的關系抽取方法應運而生.該方法利用少量標注數據和相關的學習算法,訓練大量未標記的測試文本的語料庫進行關系抽取.該方法不僅能有效地減少對標注語料的依賴和人工參與,而且性能較好,能自動擴展到大規模語料的關系抽取任務中,廣泛被研究者使用.半監督機器學習關系抽取的一般流程如圖4所示[123]:
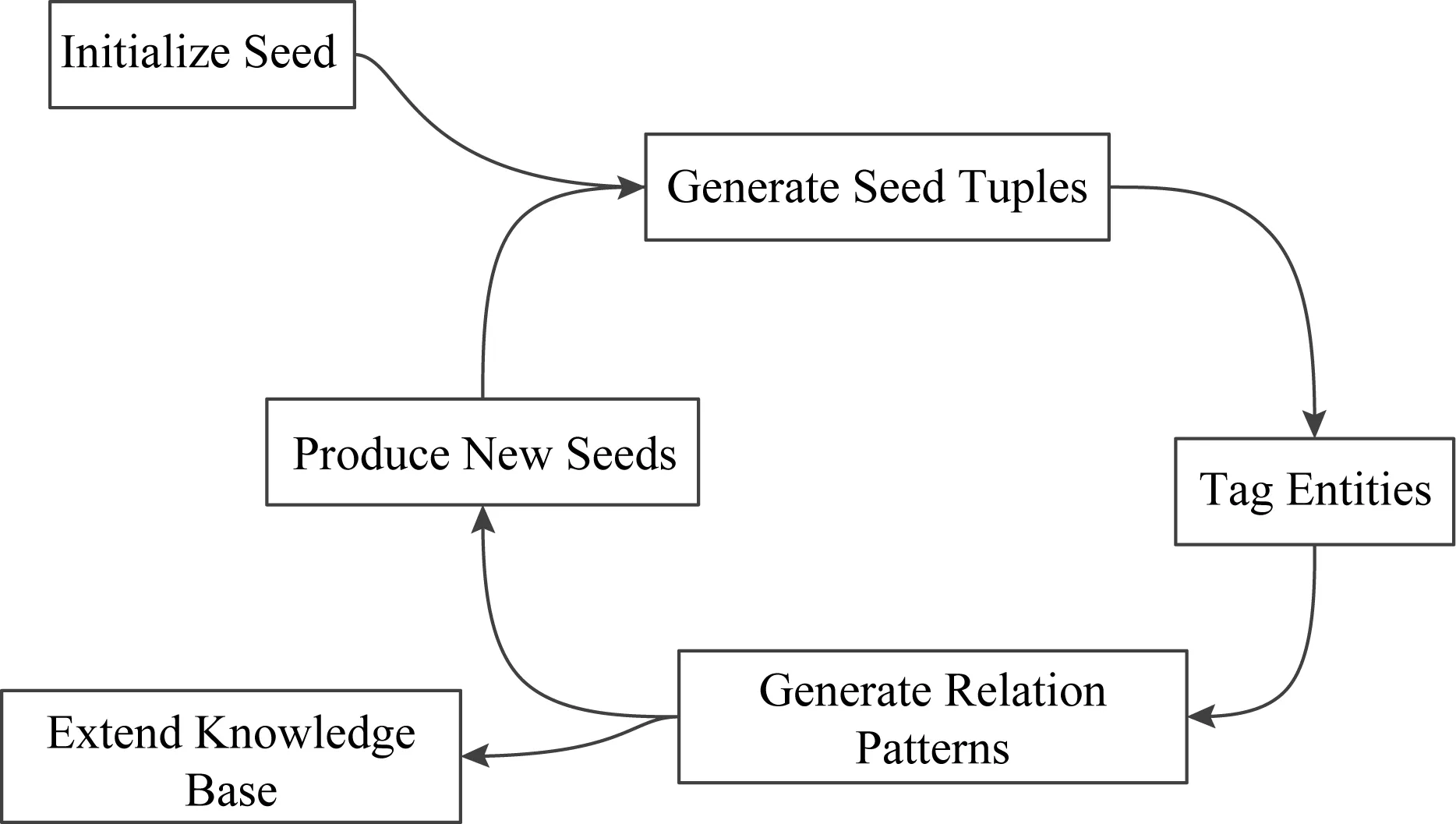
Fig. 4 The general process of semi-supervised relation extraction method圖4 半監督機器學習關系抽取方法一般流程
① Initialize seed,即初始種子,利用少量關系實例人工構造的初始種子集合.
② Generate seed tuples,即生成初始種子的關系三元組,由初始種子集合之間的實體關系產生,便于之后的實體的標識.
③ Tag entity,即標識實體,對文本進行預處理,利用知識庫中的初始關系三元組識別訓練文本中實體.
④ Generate relation patterns,即生成抽取模式,利用模式學習的方法,通過不斷迭代,產生新的關系實例.
⑤ Produce new seeds,即產生新的種子,根據新的關系實例增加新的種子,不斷擴充種子集合的規模.
⑥ Extend knowledge base,即擴展知識庫,將新的關系實例擴展到知識庫中.
目前,半監督的關系抽取方法主要有自舉方法、協同訓練(co-training)和標注傳播(label propaga-tion)等.
1) 自舉方法
Brin[36]首次利用自舉的方法構建了DIPRE系統進行關系抽取.他們首先確認少量的關系種子類型,通過不斷迭代的方法自動地從大量訓練語料庫中獲取抽取模板和新的關系實例;在Brin的基礎上,Agichtein等人[37]設計的Snowball抽取系統完善了關系的描述方法,在最佳情況下可提高6.0%,達到了96.0%,提高了對新獲取的關系實例評價方式的可信度;此外,Zhu等人[38]設計了StatSnowball抽取系統,用于識別人際關系,該系統基于Marka邏輯網絡(Markov logic networks,MLNs),不斷改進了Snowball系統的模板評價方式,在sent500數據集取得了86.9%的F1值,此外其準確率也相對Snowball系統提高了1.78%,達到了97.8%,進一步提高了關系抽取的性能;為減少產生錯誤模板,Carlson等人[39]約束了不同類別的抽取模板的范圍,以15個種子實例和5個種子模式為基礎,在3 570萬唯一的文本關系模式中不斷訓練模型,提高了模型的性能和錯誤輸出;語義漂移是自舉方法的重要挑戰之一,即將錯誤預測為正類的實體對加入到迭代過程中,最終影響關系抽取模型的性能,為此,Gupta等人[40]提出聯合使用實體和模板種子,在迭代的過程中以平行且相互制約的方式擴展實體和模板,并引入高質量的相似性算法來判別模板;Qin等人[41]利用搜索引擎中設置的大型新聞標題句子,通過描述詞與句子集之間的共現關系來評估實例的可靠性,然后通過模式歷史匹配中的正負實例數來評估模式的可靠性.實驗結果表明:迭代中使用的實例和模式的可靠性評估有效地提高了關系提取的準確性,其中CSEAL方法對130個實例的測試準確率率達到了97%,并提高了提取模式的質量.
在中文方面,何婷婷等人[42]提出了基于種子自擴展機制,利用自舉的方法抽取1998年上半年純文本《人民日報》語料的中文實體間的關系.實驗表明:當上下文窗口大小設置為6時,對2 615條候選命名實體對進行關系抽取,實驗結果性能最佳,準確率、召回率及F1分別達到了83.1%,79.6%,81.3%.在地理領域,余麗等人[43]利用自舉的方法,根據語料庫中詞語的特征來提取表示實體關系的關系指示詞,其中準確率和召回率分別提高了5%和23%.
基于自舉半監督式機器學習的方法借助高質量的初始關系種子,不依賴大規模的標注語料庫,可以自動挖掘自然語言的部分詞法特征.該方法有利于在缺乏大量標注語料中進行關系抽取任務.
2) 協同訓練
協同訓練是由Blum等人[44]提出的一種半監督機器學習算法,該方法利用2個分類器對同一個實例從不同角度進行關系分類.2個分類器相互學習、相互強化,不斷提高關系抽取的性能,它被廣泛應用在自然語言處理和信息檢索領域中.Abney[45]提出了一種對Yarowsky算法改進的協同訓練的評估方式,實驗表明在完全獨立的條件下,該算法能一定程度強化實體之間的較弱聯系的關系表示;Zhang[46]提出基于隨機特征的BootProject算法.該算法基于協同訓練的思想,用于對半監督的語義庫進行關系分類,并在包含5 260條標注關系的語料集ACE中發現關系,其結果F1均值可達到70.9%.
3) 標注傳播
標注傳播算法是由Zhu等人[47]提出的,這是一種基于圖的半監督機器學習方法,基本思路是用已標記節點的標簽信息去預測未標記節點的標簽信息.該算法將分類問題看作是標簽在圖上的傳播,所有實體看作圖中的節點,實體對之間的關系看作邊.但是該方法的不確定性較高,不適合關系類別特別復雜的文本數據.Hoffmann等人[48]采用多實例多標簽(multi-instance multi-label)的方法,考慮關系抽取系統的重疊問題,其中MULTIR方法的準確率為72.4%,召回率為51.9%,F1值為60.5%,進一步提高了關系抽取的性能.
對初始種子的選取,是半監督機器學習關系抽取算法的重點.此外,如何降低迭代過程中的噪聲問題困擾著研究者.為了進一步提高關系抽取方法的性能,針對半監督的機器學習關系抽取算法依舊吸引著眾多研究者的深入探索.然而在面向大規模的語料庫的條件下,無法全部預知所有關系類型,這促使一些學者將研究的目光轉向無監督的關系抽取方法.
2.2.3 無監督的關系抽取方法
事先確定關系類型是有監督和半監督機器學習的關系抽取方法的局限性之一,而在大規模的語料中無法預知所有的實體關系類型,研究者提出利用無監督機器學習的方法進行關系抽取.無監督的機器方法是自底向上從大規模的語料庫中抽取實體之間的關系.該方法首先通過基于聚類(cluster)的思想將上下文信息相似性的實體對聚成一類,然后選取合適的詞語標記關系,之后自動地抽取實體之間的語義關系.
2004年Hasegawa等人[49]基于相同語義實體對具有相似的上下文語境的假設,首次提出使用無監督的機器學習的方法進行關系抽取.無監督的機器學習關系抽取一般流程如下:
① 獲取命名實體識別及其上下文的信息;
② 聚類具有相似性的命名實體對;
③ 選擇核心詞匯標注各類的語義關系.
然而,該假設存在一些問題,如已經選取的聚類實體對之間可能包含多種關系.Rozenfeld等人[50]提出在同一語料庫中聚類實體對或者將具有多種關系的候選實體對剔除的方法完善了Hasegawa的假設,不僅如此,Rozenfeld利用基于上下文特征的模式極大地提高了關系抽取的性能;Shinyama等人[51]提出多層級聚類的方法抽取關系,該方法通過基礎模板映射新的次生聚類(主要包含相同關系的實體對),在美國12家主流報紙中挑選了2005-09-21—2005-11-21兩個月的文章,獲得了643 767個基礎模式和7 990中唯一的類型,不斷擴展了實體關系庫的規模;Davidov等人[52]限定了概念詞,利用Google搜索為知識背景,自動抽取與其相關的實體和語義關系.該方法無需提前預定義任何關系類型,在最佳的情況下準確率達到了81.0%,召回率達到了79%;Yan等人[53]融合依存特征和淺層語法模板,利用聚類方法在大規模的語料庫中抽取維基百科詞條中的實體所有的語義關系;此外,為了進一步提高單層次聚類算法的性能,Bollegala等人[54]分析聚類后的模板,發現了實體對之間的隱含語義關系,從候選的關系模板中篩選合適的抽取模板,擴展了實體關系的范圍,在一定程度上提高了準確率和召回率;在醫學專業領域,Rink等人[55]以產生式模型為基礎構建了無監督實體關系抽取框架,可以挖掘實體間的潛在關系信息,并在數據集2010 i2b2VA Challenge驗證了RDM方法的有效性,促進了無監督的機器學習方法在產業的應用.
在中文實體關系抽取方面,黃晨等人[56]基于卷積樹核,結合句法樹結構信息的特點,提出了一種新的無監督中文實體關系抽取方法.該方法采用最短路徑表示結構化的關系實例,利用卷積樹核函數實現關系的分層聚類;劉安安等人[57]首先使用實體之間的距離限制和關系指示詞的位置限制獲取候選關系三元組,然后采用全局排序和類型排序的方法來挖掘關系指示詞,最后使用關系指示詞和句式規則對關系三元組進行過濾.在獲取大量關系三元組的同時,還保證了80%以上平均準確率.
無監督的關系抽取方法無需事先人工定義實體關系的類型,可以方便地移植到別的領域,適合針對大規模地網絡文本數據進行實體間的關系抽取.雖然無監督的實體關系抽取方法有效地減少了對標注語料的依賴和人工參與,但是仍然依賴于初始種子和語料庫的質量,而且需要人工篩選低頻的實體對.目前,無監督的關系抽取方法的研究熱點之一是如何利用聚類的算法新增可信度較高的關系實例和抽取模板.
綜上所述,3種傳統機器學習關系抽取方法各有所長,也各有所短.研究者充分利用各種算法的優勢,進一步提升實體關系抽取的性能.3種方法的相關比較如表3所示:
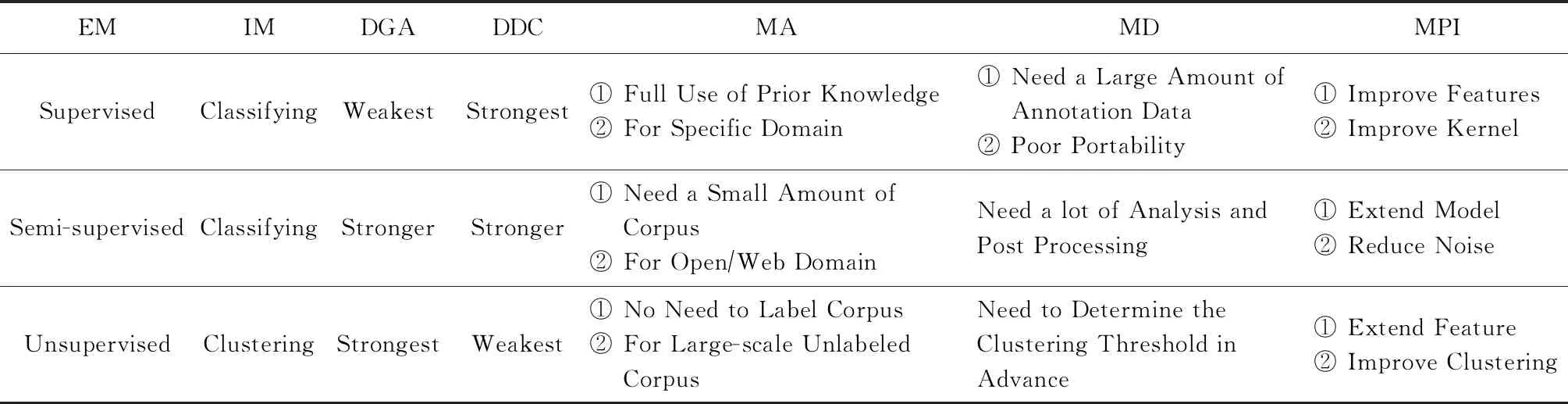
Table 3 Comparative Analysis of Relation Extraction Methods Based on Supervised, Semi-Supervised and Unsupervised表3 基于有監督、半監督、無監督關系抽取比較
2.3 基于深度學習的關系抽取方法
由于傳統機器學習的關系抽取方法選擇的特征向量依賴于人工完成,也需要大量領域專業知識,而深度學習的關系抽取方法通過訓練大量數據自動獲得模型,不需要人工提取特征.2006年Hinton等人[124]首次正式提出深度學習的概念.深度學習經過多年的發展,逐漸被研究者應用在實體關系抽取方面.目前,研究者大多對基于有監督和遠程監督2種深度學習的關系抽取方法進行深入研究.此外,預訓練模型Bert(bidirectional encoder representation from transformers)[125]自2018年提出以來就備受關注,廣泛應用于命名實體識別、關系抽取等多個領域.
2.3.1 有監督的關系抽取方法
有監督的深度學習關系抽取方法能解決經典方法中存在的人工特征選擇、特征提取誤差傳播2大主要問題,將低層特征進行組合,形成更加抽象的高層特征,用來尋找數據的分布式特征表示.目前,有監督的關系抽取方法主要有流水線學習(pipeline)和聯合學習(joint)兩種.
1) 流水線學習
流水線學習方法是指在實體識別已經完成的基礎上直接進行實體之間關系的抽取.早期的流水式學習方法主要采用卷積神經網絡(convolutional neural networks, CNNs)和循環神經網絡(recurrent neural networks, RNNs)兩大類結構.其中,CNNs多樣性卷積核的特性有利于識別目標的結構特征,而RNNs能充分考慮長距離詞之間的依賴性,其記憶功能有利于識別序列.隨著深度學習的不斷發展,研究者不斷改進和完善CNN和RNN的方法,并產生了許多變體,如長短期記憶網絡(long short-term memory, LSTM)、雙向長短期記憶網絡(bidirectional long short-term memory, Bi-LSTM)等,此外,隨著圖卷積神經網絡(graph convolutional network, GCN)在自然語言處理領域的應用,GCN也越來越多地用于挖掘和利用實體間的潛在信息,為解決關系重疊、實體重疊提供了新思路,從而進一步促進了關系抽取的發展.
① CNN
2014年Zeng等人[58]首次使用CNN提取詞級和句子級的特征,通過隱藏層和softmax層進行關系分類,提高了關系抽取模型的準確性;Liu等人[59]在實體關系抽取方面使用簡單的CNN模型,該模型主要由輸入層、卷積層、池化層和softmax層組成,輸入詞向量和距離向量等原始數據進行實體關系抽取;為了消除了文本大小的任意性所帶來的不便,Collobert等人[60]利用設置大小固定的滑動窗口和在輸入層和卷積層之上增添max層2種辦法,提出了一種基于CNN的自然語言處理模型,方便處理多種任務;Nguyen等人[61]設計了多種窗口尺寸的卷積核的CNN模型,能自動學習句子中的隱含特征,最大限度上減少了對外部工具包和資源的依賴;Santos等人[62]使用逐對排序這一新的損失函數,有效地區分了關系類別;Xu等人[63]融合卷積神經網絡和最短依存路徑的優勢進行實體關系抽取,在公有數據集SemEval-2010 Task 8的評估結果中,F1值為85.4%,相比于不使用最短依存路徑的方法提高了4.1%,驗證了卷積神經網絡和最短依存路徑結合的有效性;Ye等人[64]基于關系類別之間的語義聯系,利用3種級別的損失函數AVE,ATT,Extended ATT,在包含10 717條標注樣例的SemEval-2010 Task 8中進行模型評估,最佳情況下準確率、召回率、F1值分別達到了83.7%,84.7%,84.1%,有效地提高了關系抽取方法的性能;Fan等人[65]提出了一種最小監督關系提取的方法,該方法結合了學習表示和結構化學習的優點,并準確地預測了句子級別關系.通過在學習過程中明確推斷缺失的數據,該方法可以實現一維CNN的大規模訓練,同時緩解遠程監管中固有的標簽噪音問題.
在中文研究方面,孫建東等人[66]基于COAE 2016數據集的988條訓練數據和937條測試數據,提出有效結合SVM和CNN算法可以用于中文實體關系的抽取方法.傳統文本實體關系抽取算法多數是基于特征向量對單一實體對語句進行處理,缺少考慮文本語法結構及針對多對實體關系的抽取算法;基于此,高丹等人[67]提出一種基于CNN和改進核函數的多實體關系抽取技術,并在25 463份法律文書的實體關系抽取上,取得了較好的抽取效果和較高的計算效率.
② RNN
除CNN關系分類的方法外,Socher等人[68]首先采用RNN的方法進行實體關系抽取.該方法利用循環神經網絡對標注文本中的句子進行句法解析,經過不斷迭代得到了句子的向量表示,有效地考慮了句子的句法結構;面對純文本的實體關系抽取任務,Lin等人[69]使用了一種多種語言的神經網絡關系抽取框架,并在句子級別引入注意力機制(attention),極大地減少了噪音句子的影響,有效地提高了跨語言的一致性和互補性.由于神經網絡經常受到有限標記實例的限制,而且這些關系抽取模型是使用先進的架構和特征來實現最前沿的性能;Chen等人[70]提出一種自我訓練框架,并在該框架內構建具有多個語義異構嵌入的遞歸神經網絡.該框架利用標記的、未標記的社交媒體數據集THYME實現關系抽取,并且具有較好的可擴展性和可移植性.
為了解決RNN在自然語言處理任務中出現的梯度消失和梯度爆炸帶來的困擾,研究者使用性能更為強大的LSTM.LSTM是一種特殊的循環神經網絡,最早是Hochreiter,Schmidhuber提出.2015年Xu等人[71]提出基于LSTM的方法進行關系抽取,該方法以句法依存分析樹的最短路徑為基礎,融合詞向量、詞性、WordNet以及句法等特征,使用最大池化層、softmax層等用于關系分類;Zhang等人[72]使用了Bi-LSTM模型結合當前詞語之前和詞語之后的信息進行關系抽取,在最佳實驗結果中相比于文獻[58]的方法提高了14.6%,證實了Bi-LSTM在關系抽取上具有有效性.
④ GCN
圖神經網絡最早由Gori等人[127]提出,應用于圖結構數據的處理,經過不斷發展,逐漸應用于自然語言處理領域.而圖卷積神經網絡能有效地表示實體間的關系,挖掘實體間的潛在特征,近年來受到了越來越多的關注.
Schlichtkrull等人[73]提出使用關系圖卷積神經網絡(R-GCNs)在2個標準知識庫上分別完成了鏈接預測和實體分類,其中鏈接預測抽取出了缺失的關系,實體分類補全了實體缺失的屬性;為有效利用負類數據,Zhang等人[74]提出一種擴展的圖卷積神經網絡,可以有效地平行處理任意依賴結構,便于對實體關系進行抽取.通過在數據集TAC和SemVal-2010 Task 8上的評估,其最佳的實驗結果的準確率、召回率、F1值為71.3%,65.4%,68.2%,該方法的性能優于序列標注和依賴神經網絡.此外,作者還提出一種新的剪枝策略,對輸入的樹結構的信息,可以快速找到2個實體之間的最短路徑;圖神經網絡是最有效的多跳(multi-hop)關系推理方法之一,Zhu等人[75]提出一種基于自然語言語句生成圖神經網絡(GP-GNNs)參數的方法,使神經網絡能夠對無結構化文本輸入進行關系推理;針對多元關系的抽取,Song等人[76]提出了一種圖狀的LSTM模型,該模型使用并行狀態模擬每個單詞,通過消息的反復傳遞來豐富單詞的狀態值.該模型保留了原始圖形結構,而且可以通過并行化的方式加速計算.不僅提高了模型的計算效率,也實現了對多元關系的抽取;為有效利用依賴樹的有效信息,減少無用信息的干擾,Guo等人[77]提出一種直接以全依賴樹為輸入的、基于注意力機制的圖卷積網絡模型.該模型是一種軟剪枝(soft-pruning)的方法,能夠有選擇地自動學習對關系提取任務有用的相關子結構,支持跨句多元關系提取和大規模句級關系提取.
⑤ 混合抽取
為了進一步提高關系抽取模型的性能,一些研究者開始采取融合多種方法的方式進行關系抽取.2016年Miwa等人[78]使用聯合的方法,他們融合Bi-LSTM和TreeLSTM模型的優點對實體和句子同時構建模型,分別在3個公有數據集ACE04,ACE05,SemVal-2010 Task8對關系抽取模型進行評估,有效地提高了實體關系抽取的性能;Zhou等人[79]提出一種基于注意力的Bi-LSTM,著重考慮詞對關系分類的影響程度,該方法在只有單詞向量的情況下,優于大多數當時的方法;Li等人[80]融合Bi-LSTM和CNN的特點,利用softmax函數來模擬目標實體之間的最短依賴路徑(SDP),并用于臨床關系提取的句子序列,在數據集2010 i2b2VA的實驗結果F1為74.34%,相比于不使用語義特征的方法提高2.5%;陳宇等人[81]提出一種基于DBN(deep belief nets)的關系抽取方法,通過將DNB與SVM和傳統神經網絡2種方法在ACE04數據集(包含221篇消息文本、10 228個實體和5 240個關系實例)進行了比較,F1值分別提高了1.26%和2.17%,達到了73.28%;召回率分別提高了3.59%和2.92%,達到了70.86%,驗證了DBN方法的有效性.此外,DBN方法表明,字特征比詞特征更適用于中文關系抽取任務,非常適用于基于高維空間特征的信息抽取任務.
流水線方法的實驗結果相對良好,但容易產生錯誤傳播,影響關系分類的有效性;將命名實體識別和關系抽取分開處理,容易忽視這2個子任務之間的聯系,丟失的信息會影響抽取效果;另外,冗余信息也會對模型的性能產生較大的影響.為解決這些問題,研究人員嘗試將命名實體識別和關系抽取融合成一個任務,進行聯合學習.
2) 聯合學習
聯合學習方法有3種,包括基于參數共享的實體關系抽取方法、基于序列標注的實體關系抽取方法和基于圖的實體關系抽取方法.
① 基于共享參數的方法
命名實體識別和關系抽取通過共享編碼層在訓練過程中產生的共享參數相互依賴,最終訓練得到最佳的全局參數.因此,基于共享參數方法有效地改善了流水線方法中存在的錯誤累積傳播問題和忽視2個子任務間關系依賴的問題,提高模型的魯棒性.
2016年Miwa等人[82]首次利用循環神經網絡、詞序列以及依存樹將命名實體識別和關系抽取作為一個任務進行實驗,通過共享編碼層的LSTM的獲得最優的全局參數,在數據集ACE04,ACE05分別減少了5.7%和12.1%的錯誤率,在數據集SemEval-2010 Task 8 的F1達到了84.4%.然而Miwa忽略了實體標簽之間的長距離依賴關系,為此Zheng等人[83]將輸入句子通過公用的Embedding層和Bi-LSTM層,分別使用一個LSTM進行命名實體識別和一個CNN進行關系抽取,該方法的F1達到了85.3%,相對Miwa提高了近1%.
② 基于序列標注的方法
由于基于共性參數的方法容易產生信息冗余,因此Zheng等人[84]將命名實體識別和實體關系抽取融合成一個序列標注問題,可以同時識別出實體和關系.該方法利用一個端到端的神經網絡模型抽取出實體之間的關系三元組,減少了無效實體對模型的影響,提高了關系抽取的召回率和準確率,分別為72.4%和43.7%.為了充分利用實體間有多種關系,Bekoulis等人[85]將命名實體識別和關系抽取看作一個多頭選擇問題,可以表示實體間的多個關系;此外Bekoulis等人[86]還發現對模型加入輕微的擾動(對抗樣本)可以使得WordEmbedding的質量更好,不僅提高了置信度還避免了模型過擬合,模型的性能大大提升.因此首次將對抗學習(adversarial training, AT)加入聯合學習的過程中.實驗結果表明,在4個公有數據集ACE04,CoNLL04,DREC,ADE的F1提高了0.4%~0.9%.
③ 基于圖結構的方法
針對前2種方法無法解決的實體重疊、關系重疊問題,基于圖結構的方法能有效得解決.Wang等人[87]發現生成標記序列后的合并三元組標簽過程采用的就近組合無法解決關系重疊問題,因此提出一種新的基于圖架構的聯合學習模型.該方法不僅能有效解決關系重疊問題,而且使用偏執權重的損失函數強化了相關實體間的關聯,實驗結果的準確率、召回率及F1值分別為64.3%,42.1%,50.9%.此外,Fu等人[88]提出將圖卷積神經網絡用于聯合學習,利用圖的節點表示實體,邊表示關系,有效地解決了關系重疊和實體重疊問題,不僅如此,還對邊(關系)加入了權重,有效挖掘了實體對間的潛在特征,通過使用NYT和WebNLG數據集的評估,該方法在最佳情況下準確率、召回率及F1值可達63.9%,60.0%,61.9%,與文獻[87]相比,召回率和F1分別提高17.9%和11.0%.
本文選取了幾種經典的有監督關系抽取方法進行了綜合比較,具體如表4所示.
深度學習的有監督方法能夠自動地學習大量特征,避免人工選擇特征,但對大量沒有進行標記的數據,這種方法就顯出其弊端.為了減少對大數據的標注的人工成本,研究者嘗試使用遠程監督的方法進行關系抽取.
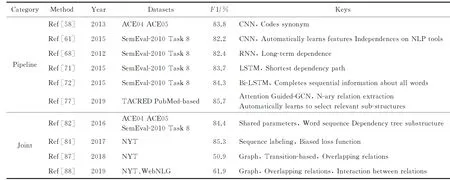
Table 4 Comparison of Relation Extraction Methods Based on Supervised Learing表4 有監督學習關系抽取方法對比
2.3.2 遠程監督的關系抽取方法
針對海量無標記數據的處理,遠程監督的實體關系抽取方法極大地減少了對人工的依賴,可以自動地抽取大量的實體對,從而擴大了知識庫的規模.此外,遠程監督的方法具有較強的可移植性,比較容易應用到其他領域.遠程監督的基本假設是如果2個實體在己知知識庫中存在著某種關系,那么涉及這2個實體的所有句子都會以某種方式表達這種關系.Mintz等人[89]首次在ACL會議上將遠程監督方法應用于實體關系抽取的任務中.他們將新聞文本與知識圖譜FreeBase進行中的實體進行對齊,并利用遠程監督標注的數據提取文本特征,訓練關系分類模型.
這類方法在數據標注過程會帶來2個問題:噪音數據和抽取特征的誤差傳播.基于遠程監督的基本假設,海量數據的實體對的關系會被錯誤標記,從而產生了噪音數據;由于利用自然語言處理工具抽取的特征也存在一定的誤差,會引起特征的傳播誤差和錯誤積累.本文主要針對減少錯誤標簽和錯誤傳播問題對遠程監督的關系抽取方法進行闡述.
1) 針對錯誤標簽
由于在不同語境下同一對實體關系可能存在不同含義,為了減少因此而產生的錯誤關系標簽,Alfonseca等人[90]利用FreeBase知識庫對關系進行分層處理,以啟發式的方式自動識別抽取表示關系的語義和詞匯;由于利用啟發式的規則標記實體關系時會產生一些錯誤標記,Takamatsu等人[91]提出一種產生式模型,用于模擬遠程監督的啟發式標記過程,使用903 000篇Wikipedia文章進行模型的訓練,并使用400 000篇文章進行測試,實驗結果的準確率、召回率和F1值分別為89.0%,83.2%,82.4%;為了解決Alfonseca提出的方法缺乏實體的知識背景問題,Ji等人[92]提出了一種在句子級別引入注意力機制的方法來抽取有效的實例,并通過FreeBase和Wikipedia不斷地擴充實體的知識背景;之前大多方法對負類數據的利用率較低,Yu等人[93]提出結合從句子級遠程監督和半監督集成學習的關系抽取方法,該方法減少了噪聲數據,充分利用了負類數據.該方法首先使用遠程監督對齊知識庫和語料庫,并生成關系實例集合,接著使用去噪算法消除關系實例集中的噪聲并構建數據集.為了充分利用負類數據,該方法將所有正類數據和部分負類數據組成標注數據集,其余的負類數據組成未標注數據集.通過改進的半監督集成學習算法訓練關系分類器的各項性能,然后進行關系實例的抽取.
此外,為了減少錯誤標簽產生的噪音數據對關系抽取模型的影響,Wang等人[94]提出了一種無標簽的遠程監督方法;該方法只是使用了知識庫中的關系類型,而由2個實體來具體確定關系類型,避免了知識庫中的先驗知識標簽對當前關系類型判別造成影響,也無需使用外部降噪工具包,大大提高了關系抽取的效率和性能;為了進一步提高對數據的使用效率,Ru等人[95]使用Jaccard算法計算知識庫中的關系短語與句子中2個實體之間的語義相似性,借此過濾錯誤的標簽.該方法在減少錯誤標簽的過程中,利用具有單詞嵌入語義的Jaccard算法選擇核心的依賴短語來表示句子中的候選關系,可以提取關系分類的特征,避免以前神經網絡模型關系提取的不相關術語序列引起的負面影響.在關系分類過程中,將CNN輸入的核心依賴短語用于關系分類.實驗結果表明,與使用原始遠程監督數據的方法相比,使用過濾遠程監督數據的方法在關系提取方面結果更佳,可以避免來自不相關術語的負面影響;為了突破距離對關系抽取模型性能的限制,Huang等人[96]提出一種融合門控循環單元(gated recurrent unit, GRU)和注意力機制的遠程監督關系抽取方法,該方法解決了傳統深度模型的實體在長距離依賴性差和遠程監督中容易產生錯誤標簽的問題;實驗結果表明,文獻[89]的方法召回率在大于0.2時就開始迅速下降,而該方法在整個過程中都相對穩定,保證了模型的魯棒性;此外,通過與文獻[69]的方法進行比較,該方法的召回率平均提高10%,能夠充分利用整個句子的序列信息,更適合自然語言任務的處理.
2) 針對誤差傳播
Fan等人[97]提出遠程監督關系提取的本質是一個具有稀疏和噪聲特征的不完整多標簽的分類問題.針對該問題,Fan使用特征標簽矩陣的稀疏性來恢復潛在的低秩矩陣進行實體關系抽取;為了解決自然語言處理工具包提取問題帶來的錯誤傳播和錯誤積累問題,Zeng等人[98]融合CNN和遠程監督的方法,提出分段卷積神經網絡(piecewise convolutional neural network, PCNN)用于實體關系抽取,并嘗試將基于CNN的關系抽取模型擴展到遠程監督數據上.該方法可以有效地減少了錯誤標簽的傳播和積累,在最佳情況下,準確率、召回率以及F1值達到了48.30%,29.52%,36.64%.
針對目前在中文領域實體-屬性提取中模型的低性能,He等人[99]提出了一種基于Bi-LSTM的遠程監督關系抽取方法.首先,該方法使用Infobox的關系三元組獲取百度百科的信息框,從互聯網獲取訓練語料庫,然后基于Bi-LSTM網絡訓練分類器.與經典方法相比,該方法在數據標注和特征提取方面是全自動的.該方法適用于高維空間的信息提取,與SVM算法相比,準確率提高了12.1%,召回率提高了1.21%,F1值提高了5.9%,準確率和F1值得到顯著提高.
有監督的關系抽取方法借助人工標注的方法提高了關系抽取的準確性,但是需要耗費大量人力,其領域泛化能力和遷移性較差.遠程監督的方法相對于有監督的方法極大地減少了人工成本,而且領域的遷移性較高.但是,遠程監督的方法通過自動標注獲得的數據集準確率較低,會影響整個關系抽取模型的性能.因此,目前的遠程關系抽取模型的性能仍然和有監督的關系抽取模型有一定的差距,有較大的提升空間[127].基于深度學習的監督和遠程監督方法抽取對比如表5所示:
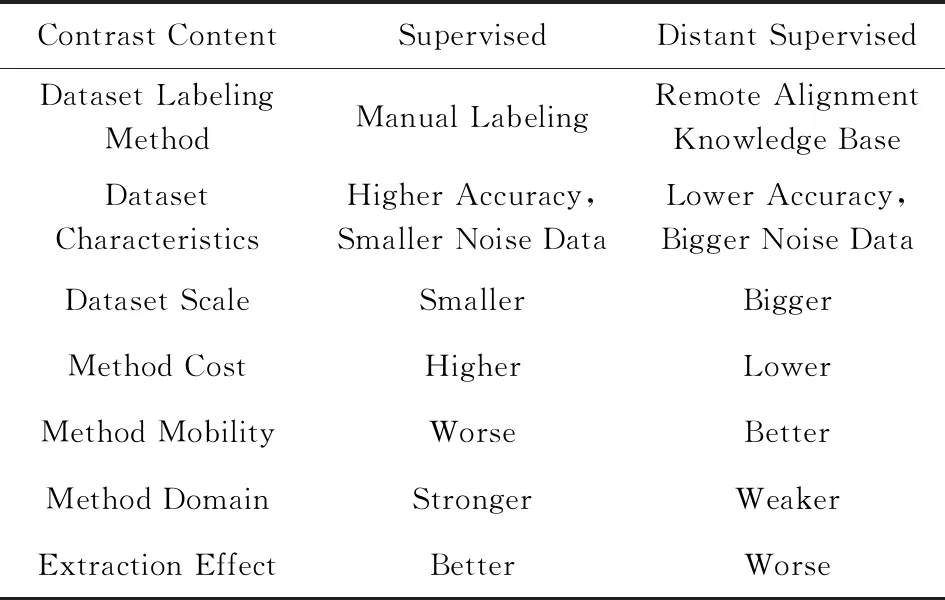
Table 5 Comparison of Supervised and Distant Supervised Relation Extraction Based on Deep Learning
2.3.3 BERT
2018年Google AI Language 發布了BERT模型,該模型在11個NLP任務上的表現刷新了記錄,在自然語言處理學界以及工業界都引起了不小的熱議.BERT的出現,徹底改變了預訓練產生詞向量和下游具體NLP任務的關系.
在關系抽取領域,應用BERT作預訓練的關系抽取模型越來越多,如Shi等人[128]提出了一種基于BERT的簡單模型,可用于關系抽取和語義角色標簽.在CoNLL05數據集中,準確率、召回率和F1值分別為88.6%,89.0%,88.8%,相比于baseline方法分別提高了1.0%,0.6%,0.7%;Shen等人[129]借助BERT的強大性能對人際關系進行關系抽取,減少了噪音數據對關系模型的影響.此外,又使用了遠程監督可以對大規模數據進行處理,在CCKS 2019 eval Task3 IPRE數據集的結果表明,該方法優于大多數人際關系抽取方法,F1值達到了57.4%.
BERT作為一個預訓練語言表示模型,通過上下文全向的方式理解整個語句的語義,并將訓練學到的知識(表示)用于關系抽取等領域.但BERT存在許多不足之處.
1) 不適合用于長文本.BERT以基于注意力機制的轉換器作為基礎,不便于處理長文本,而關系抽取領域的文本中經常出現超過30個單詞的長句,BERT會對關系抽取的性能產生影響.針對長句子的情況,可以另外設計一個深度的注意力機制,以便層級化的捕捉關系.
2) 易受到噪音數據的影響.BERT適用于短文本,而短文本中若出現不規則表示、錯別字等噪音數據,這不僅會對關系觸發詞的抽取造成一定的影響,而且在聯合學習時進行命名實體識別階段也會產生錯誤的積累和傳播,最終導致模型的性能下降.
3) 無法較好地處理一詞多義問題.雖然通過上下文能在一定程度上緩解一詞多義的影響,但一詞多義對BERT的原始輸入中的詞編碼影響極大.從而進行關系抽取時容易產生錯誤標簽,無法有效地使用關系標簽等進行關系分類,降低模型的準確率、召回率、F1值.這需要加以一定的機制來解決一詞多義的表示問題.
2.4 基于開放領域的關系抽取方法
由于傳統關系抽取基于特定領域、特定關系進行抽取,導致關系抽取這一任務耗時耗力,成本極高,同時不利于擴展語料類型.近年來,針對開放領域的實體關系抽取方法逐漸受到人們的廣泛關注.由于互聯網不斷發展,開放語料的規模不斷擴大,并且包含的關系類型愈加復雜,研究者直接面向大多未經人工標注的開放語料進行關系抽取,有利于促進實體關系抽取的發展,而且具有更大的實際意義.
開放領域關系抽取的方法是信息抽取領域的新的研究方向.該關系抽取方法主要分為半監督和無監督2種,并結合語形特征和語義特征自動地在大規模非限定類型的語料庫中進行關系抽取.開放領域關系抽取的方法無需事先人為制定關系類型,減輕了人工標注的負擔,而由此設計的系統可移植性較強,極大地促進關系抽取的發展.
開放領域的關系抽取方法主要有3個流程:
1) 深層解析小規模的語料集,自動抽取實體間關系三元組,利用樸素貝葉斯分類器訓練已標注可信和不可信的關系三元組構建關系表示模型;
2) 利用關系抽取模型并輸入詞性、序列等特征等數據,在訓練好的分類器上進行大量網絡文獻的關系抽取,獲取候選關系三元組;
3) 合并候選三元組,通過統計的方法計算各個關系三元組的可信度,并建立索引.
2.4.1 英文開放領域文本關系抽取方法
針對非限定領域的關系抽取,Sekine曾嘗試按需抽取的思路,利用淺層匹配的方法,自動構造簡單模板進行關系抽取,并為之后的面向開放領域的關系抽取提供了新思路.早期研究人員主要針對二元關系進行抽取,包括先識別實體詞和先識別關系詞2種主要方法.隨著人們對文本信息蘊含的深層次關系的研究,多元關系抽取也逐漸進入研究者的視野.
1) 二元關系抽取方法
① 先識別實體詞的二元抽取方法
在早期的開放式信息抽取領域主要是針對實體詞進行關系抽取.該階段利用無語義的特征,自動地學習實體之間的關系,并構建好表示文本關系的模型.主要的信息抽取系統包括TextRunner,WOE,PATTY等.
2007年Washington大學的人工智能研究組的Banko等人[5]正式提出了面向開放領域的信息抽取方法框架,并發布了開放領域的第1個信息抽取信息系統TextRunner.該系統依賴少量的人工標記數據,通過自監督的學習方式訓練了樸素貝葉斯模型,并進行實體關系分類.該系統在大規模開放的網頁進行實體關系分類測試,取得了當時較為優秀的效果.隨后,該系統融合線性條件隨機場和馬爾可夫邏輯模型,其性能不斷得到了提高,這對關系抽取領域的發展起到了促進作用.
在TextRunner的基礎之上,Wu等人[100]設計開發了一種新穎的自監督學習的信息抽取系統WOE.WOE系統利用啟發式規則訓練維基百科網頁信息框(Infobox)中的數據,自動地構建實體關系集.WOE有2種運行模式:1)以詞性標記為限制條件時,該系統的運行速度可比肩TextRunner;2)以解析依賴關系為限制條件時,雖然抽取的速度將會減慢,但在極大地程度上提高了實體關系抽取的準確率和召回率.同時WOE系統中充分考慮了依存關系特征,實驗結果表明:相對于TextRunner該方法的F1平均值提高了18%~34%,進一步大幅度提高了該系統的性能.
此外,Nakashole等人[101]基于頻繁項集挖掘算法提出了PATTY系統.該系統以模式為依據進行語義分類,構建了一個包容性的分類體系,在以350 569個模式構成的Wikipedia數據集中,對實體間的關系進行抽取,便于在大規模的語料庫中表示實體間的二元關系.
2010年Yao等人[102]充分結合了遠程監督以及Open IE的優勢提出了一種通用模型框架.該模型是一個涉及所有模式的并集,并且避免了對現有數據集的依賴.該模型利用矩陣分解的方法自學習到實體元組和關系的潛在特征,能有效地處理結構化和無結構化數據.相對傳統的分類方法,該模型的計算速度更快,學習效率更優,準確率更高,可擴展性更強.
② 先識別關系詞的二元抽取方法
由于早期的關系抽取系統存在抽取的關系詞不連貫以及關系詞無法提供有效信息的問題.因此,之后面向開放領域的關系抽取開始轉向先識別關系詞,并深入地解析句子的語言成分進行關系抽取.該階段比較引人注意的有ReVerb,OLLIE,C1ausIE等.其中,ReVerb主要以動詞為核心,OLLIE主要以名詞和副詞為核心,ClauseIE主要以從句為核心.
2011年Fader等人[103]深入分析了語法、詞匯、語義等特征,設計了ReVerb系統.該系統有效減少了TextRunner系統和WOE系統所產生的錯誤關系三元組和無信息關系三元組.該系統使用淺層句法抽取較短的語句,而對于較長的語句則采用先識別關系詞再識別實體的方法.實驗結果表明,ReVerb系統只需進行詞性標注,并結合匹配的方法就能完成關系抽取的任務,有效地提高了關系抽取的準確率,在極大地程度上提高了關系抽取的性能,有力地促進了關系抽取方面的發展.
此外,Xavier等人[104]提出了一種較為簡單的方法挖掘名詞與名詞之間的關系以及形容詞與形容詞之間的關系.該方法首先識別名詞或形容詞及其屬性,之后對識別的名詞或形容詞進行解析,接著自動地產生描述二元關系的三元組.該方法進一步增加了信息量,也提高了關系抽取的準確性.即對名詞的屬性進行抽取,使得信息量增多,抽取的準確性更高.Del等人[105]通過對句子的結構進行分析,提出了ClausIE系統.該系統融合了句法模式學習、自學習算法、句子分解技術等的優勢,將復雜語句分解成多個簡單的語句,通過計算關系短語的相似度來對關系短語進行整合.
另外,Faruqui等人[106]提出一種跨語言注釋映射的方法,無需依賴語言包和解析目標語言,借助機器翻譯就可以對多種語言進行關系抽取.在人工標注的3種語言(法語、印地語、俄語)進行關系抽取的實驗結果表明,該開放領域抽取方法能夠對維基百科61種語言進行關系抽取,具有較強的可移植性和擴展性;為了簡化當前眾多方法結構的復雜性,Song等人[107]將實體間的語義信息轉化成二進制結構,以便利用更少的時間提取更多的語義信息,高效地抽取關系三元組,并通過SENT500數據集測試,獲得了83.8%的F1值.
2) 多元關系抽取方法
上述的關系抽取系統主要是針對二元關系的,Akbik等人[108]提出針對多元關系進行抽取,設計開發了KRAKEN系統.該系統改進了OIE系統,可以對不同的關系類別進行多元關系抽取,挖掘了潛在的隱含關系,與傳統方法針對特定領域進行關系抽取相比較,面向開放領域的關系抽取方法所獲得準確率和召回率仍然比較低;Gamallo等人[109]針對英語、西班牙語、葡萄牙語、加利西亞語等語種,利用一些制定的規則,采用依存分析的技術完成了關系抽取任務,取得了較好的效果,相對于ReVerb需要27%的計算機RAM,該系統只需0.1%.Fossati等人[110]利用語言的語義理論框架,實現了同時利用T-Box和A-Box填充知識庫,完成了語義標注,最終對實體間的多元關系進行抽取.
2.4.2 中文開放領域文本關系抽取方法
1) 二元關系抽取方法
由于中文與英文存在較大的差距,因此針對英語的關系抽取系統無法直接對中文進行抽取.為了解決中文中缺省某些語言成分和倒序的問題,研究者發布了CORE,ZORE,UnCORE 這3個面向開放領域的信息抽取系統.
考慮到中英文之間的差異,在面向中文開放領域的文本時,Petroni等人[111]提出了CORE模型.該模型利用上下文信息進行矩陣分解可以獲得關系三元組.該方法首先完成對分句、詞性標注和特殊詞的處理,之后對給定的語句利用CKIP解析器進行語法解析,最后通過識別中心關系詞逐漸擴展去識別中心實體詞.該方法有力地促進了面向開放的中文領域的關系抽取的研究和發展.
此外,ZORE也是面向中文開放領域文本的關系抽取模型.ZORE是由Qiu等人[112]在2014年提出,通過利用依存解析樹識別候選實體關系三元組,采用雙向傳播算法迭代抽取實體關系三元組和語義模板.實驗表明,該模型在對5 MB大小的Wikipedia中文構成的數據集進行關系抽取時,準確率取得了較好的成績,達到了76.8%.
通過對大規模開放的網絡文本進行分析之后,哈爾濱工業大學的秦兵等人[113]發現實體之間的關系與實體之間的距離以及關系詞的位置有較大關系.2015年秦兵等人發布了以無監督的方式進行關系抽取的UnCORE系統.該系統首先對在網頁上獲得的大規模文本進行預處理,得到分詞和標注好的詞性等,接著通過約束實體之前的距離和關系詞的位置得到候選三元組,然后使用基于規則的排序(全局排序和類型排序)的算法獲取關系指示詞,最后采用構造好的規則和關系指示詞對候選關系三元組進行過濾得到準確率較高的關系三元組.實驗結果顯示,該方法的平均準確率達到80%,能有效地提取大量關系三元組,不斷地擴充實體關系庫.
除此之外,郭喜躍等人[114]采用半監督的方式在百科類的開放領域文本進行關系抽取,從不同方面對百度百科的信息框采用不同方法進行標注、篩選、整合,最終獲得了質量較高的實體間的二元關系.該方法有效地減少了人工參與,提高了關系抽取的效率.文獻[115]研究了基于無監督的中文開放領域的關系抽取,可以在沒有任何人工標記數據集的情況下自動發現任意關系,建立了大規模語料庫.通過將實體關系映射到依賴樹,考慮到獨特的中文語言特征,該文獻提出了一種基于依賴語義規范形式的新型無監督中文開放領域的關系抽取模型.該模型對實體和關系之間的相對位置沒有任何限制,通過抽取由動詞或名詞為媒介的關系,處理并行子句來提高關系抽取的性能.該方法在4個異構數據集上獲得了穩定的性能,并獲得了更好的準確率和召回率,分別為83.76%,58.68%.
2) 多元關系抽取方法
以上所述的方法主要是針對二元關系進行中文文本抽取,李穎等人[116]基于依存分析的方法,提出了面向中文開放領域文本的多元實體關系抽取模型N-COIE.該模型首先對中文文本進行詞性標注和依存關系標注,然后在一定的約束條件下識別基本的名詞短語,抽取候選實體關系多元組,最后通過過濾的方法擴充關系庫.實驗結果表明,該方法在面向大規模的中文領域開放的文本能夠取得81%的準確率.姚賢明等人[117]提出了中文領域多元實體關系抽取的方法.該方法以依存句法分析結果的根節點作為入口,迭代地獲取所有與謂語相關聯的主語、賓語及其定語成分,再利用依存句法分析結果來完善定語成分,最終獲取句子中的多個實體之間的語義關系.
目前,面向大規模開放領域的關系抽取方法仍與特定領域的方法存在一定的差距,留給研究者一定的研究空間.面向開放領域的關系抽取仍然存在著一些難點,亟待解決:
1) 如何繼續提高實體二元關系的準確率和召回率,進一步實現對實體間多元關系的抽取;
2) 如何繼續深度挖掘實體間的隱含關系,進一步提高實體間關系的信息的有效利用;
3) 如何提出公認的評價體系,制定統一的評測標準.
3 關系抽取總結和未來發展趨勢
3.1 關系抽取總結
關系抽取研究已歷經20多年的發展,關系抽出的方法不斷得到改進,關系抽取的模型性能不斷得以提升,逐漸應用于知識圖譜、文本摘要、機器翻譯等領域.
早期的方法主要通過尋找文本的規律,制定一系列規則抽取關系,如基于規則、詞典、本體的方法.該類抽取方法的準確率等評價指標較高,然而需要人工構造,其成本高昂,且處理的文本規模較小,為了突破早期方法的局限,研究人員將目光轉向以特征等為基礎的傳統機器學習方法,如有監督學習的基于特征和核函數的方法,半監督學習的自舉、協同訓練、標注傳播的方法以及無監督方法以聚類為核心的方法.但是傳統機器學習的模型性能十分依賴人工標注特征數據的規模和數量,因此需要一個能自動地抽取特征的方法.深度學習具有自學習的特點,能夠自動抽取特征,減少對人工的依賴,而且能抽取大規模文本數據.深度學習的方法主要有有監督和遠程監督2種方法,其中有監督主要有流水線學習(如CNN,RNN,LSTM,GCN及其變體)和聯合學習(如基于共享參數、序列標注、圖)2種,基于深度學習的方法極大地促進了關系抽取領域的發展.針對特定領域方法的模型性能良好,但其可擴展性和移植較差,因此針對開放領域的方法越來越吸引研究者的目光,但該類方法的模型性能還有待提高,此外還缺少公認的評價體系,需要進一步完善.
3.2 未來發展趨勢
目前,實體關系抽取技術日漸成熟,但依然需要研究人員投入大量精力進行不斷探索,通過對現有實體關系抽取研究工作進行總結,在以后的研究中可以從5個方面展開相關的研究.
1) 從二元關系抽取到多元關系抽取的轉化.當前的關系抽取系統主要集中在2個實體之間的二元關系抽取,但并非所有的關系都是二元的,如有些關系實例需要考慮時間和地點等信息,所以會考慮更多的論元.李穎等人[116]提出的關系抽取模型N-COIE針對多元關系抽取,但該方法與二元關系抽取模型的抽取相比,在準確率和召回率上仍有較大的差距.如何根據上下文信息,識別跨越句子的多元實體關系,提高關系抽取的準確率和智能化,這促使研究者不斷投入更多的精力.
2) 開放領域的實體關系抽取的深入研究.目前的研究工作大多面向特定的關系類型或者特定領域,而使用特定的語料庫,很難做到其他領域的自動遷移.雖然,一些研究者針對開放領域的關系抽取進行了研究,提出了一系列的方法用于實體關系抽取,然而這類方法和特定領域相比仍有一定的差距.如何不斷提高系統的準確率、可移植性以及可擴展性,這都激勵著研究人員投入更多的精力和時間,促進開放領域的實體關系抽取的發展.
3) 遠程監督關系抽取方法得到不斷改進.目前,由于遠程監督的方法仍然存在錯誤標簽和誤差傳播2個主要問題,研究者多是基于這些問題對深度學習的關系抽取模型加以改進.為了避免產生過多的錯誤標簽,人們主要采用多示例、注意力機制的方法等方法減少噪音數據.而Qin等人[130]融合增強學習和遠程監督方法的優點,不斷地減少錯誤標簽,進而降低負類數據對關系抽取模型的影響.針對誤差傳播的問題,研究者多是對句子的語義信息進行深入挖掘,而對句子語法信息卻少有涉及.如何有效地解決遠程監督產生的錯誤標簽和誤差傳播,如何有效地融合語法和語義信息,這些吸引著研究者不斷改進相關算法,不斷提高深度學習方法的性能.
4) 深度學習有監督方法的性能提升.近年來,越來越多的研究人員關注于聯合學習和基于圖結構的抽取方法.聯合學習將命名實體識別和關系抽取作為一個任務,減少了錯誤信息的積累和傳播,也減少了冗余信息對模型的影響.而針對關系重疊和實體間潛在特征等問題,基于圖結構的抽取方法提供了一些新的思路.然而這2種方法的性能還需進一步改進,不斷促進信息抽取領域的發展.
5)工業級實體關系抽取系統的繼續研發.關系抽取現已被廣泛應用于智能搜索、智能問答、個性化推薦、內容分發、權限管理,人力資源管理等領域.通過對學術研究和市場需求進行深入地融合,不斷提高實體關系抽取的可靠性、置信度、執行效率等,促進關系抽取模型的性能進一步得到提升,為人們的生活提供更多便利.
4 結束語
綜上所述,關系抽取是自然語言處理領域的重要研究方向之一,其研究內容已從限定領域、限定類型的關系分類轉變為面向互聯網開放領域的實體關系自動發現.隨著關系抽取技術進一步實現自動化,將對海量信息處理、智能問答、知識庫自動構建等領域產生積極推動,具有廣闊的應用前景.
猜你喜歡
人大建設(2020年4期)2020-09-21 03:39:12
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
浙江人大(2014年4期)2014-03-20 16:20:16
