基于主成分分析的PSO-ELM_Adaboost算法耦合模型在極震區泥石流物源動儲量計算中的應用
2020-06-29 08:57:46巨能攀王昌明
科學技術與工程 2020年15期
關鍵詞:模型
李 橋, 巨能攀, 黃 健, 王昌明
(成都理工大學地質災害防治與地質環境保護國家重點實驗室,成都 610059)
泥石流是一種在山區非常普遍的地質災害。中國山地面積分布廣泛且人口聚集,決定了泥石流災害的多發性和致災性[1]。尤其是在高強度高烈度地震后,極震區產生了大量的滑坡和崩塌,為泥石流的形成提供了充足的物源條件。故而極震區內泥石流活動呈現出頻率增高、規模增大,并具有區域群發性、雨季突發性和周期復發性等特點,成為了眾多專家和學者們重點關注的焦點[2]。
泥石流動儲量作為設計泥石流防治工程中不可或缺的參數,傳統的物源動儲量計算方法有:人工經驗法、比例統計法和遙感解譯法等[3-5]。但與普通泥石流相比,極震區泥石流的物源類型在規模、數量和分布方式上都有極大差別,更為重要的是,極震區泥石流物源在后期強降雨的作用下啟動方式發生了明顯改變,采用傳統方法獲取泥石流動儲量可信度不高。為此,相關學者在該領域提出了多種方法來解決這一問題,并取得了諸多成果。Dong等[6]通過收集1999年“9·21”集集地震后中國臺灣地區臺中縣區域內泥石流溝在兩次臺風影響下的物源量變化數據,提出了基于判別因素的多元回歸模型。喬建平等[7]調查統計汶川地震極震區內44條泥石流溝的物源信息,總結出了汶川地震災區泥石流物源的主要類型和啟動地質模式,基于數學統計的方法發現總物源量與動儲量呈線性相關。顧文韜等[8]以四川安縣高川鄉區域內多條泥石流溝為研究對象,提出了“地震高程指數放大經驗模型”,通過多元統計擬合法提出了極震區震后泥石流的動儲量計算公式。方群生等[9]基于震后泥石流調查踏勘資料,將泥石流流域內物源分解成崩滑體、溝道物源和坡面物源,分別進行單因子回歸分析再疊加,建立了新的泥石流動儲量計算模型。以上計算模型均取得了較好的效果,但具有一定的局限性,不利于推廣。
極震區泥石流物源動儲量影響因素眾多,屬于復雜的非線性問題,籠統的對其進行數學分析,無法達到理想的計算精度。而神經網絡具有很強的非線性信息處理能力、自適應學習能力和容錯性,可以很好地解決這一問題。極限學習機(extreme learning machine, ELM)作為一種單隱層前饋神經網絡算法,具有結構簡單、適應性強和訓練學習速度快的特點[10],在各工程領域取得了不錯的效果。廉城[11]運用經驗模態分解(ensemble empirical mode decomposition, EEMD)將滑坡位移曲線分解成多個子序列,分別運用ELM進行預測分析,預測結果精度較高。Xu等[12]基于生存分析模型和ELM從定量的角度對文家溝泥石流治理工程效果進行了分析評價。李驊錦等[13]通過巖移數據決策和ELM,提出了一中礦山開采最大下沉值的新方法。同時相關研究也表明使用智能優化算法對ELM進行參數選取可進一步提高預測精度并提升網絡穩定性[14-15]。因此,提出一種基于ELM的極震區泥石流物源動儲量計算方法,并且使用粒子群算法(particle swarm optimization, PSO)對ELM進行優化,并與AdaBoost算法進行耦合。
采集汶川極震區區內60條泥石流溝的物源信息作為樣本數據,從泥石流物源形成與啟動方式入手,提出了流域面積、相對高差、主溝長度、較發震斷裂帶距離、溝床平均縱比降和物源總儲量作為泥石流物源動儲量的影響因子,運用Person相關系數(Pearson correlation coefficient,PCC)、灰色關聯度(grey relational grade,GRG)和最大互信息系數(maximal information coefficient,MIC)對影響因子進行了敏感性分析;為了避免信息冗余,基于主成分分析(principal component analysis,PCA)對樣本數據進行處理,再采用AdaBoost算法和粒子群優化的極限學習機(PSO-ELM)相結合的PSO-ELM_AdaBoost耦合模型進行訓練和預測,并將結果與BP(back propagation)、支持向量機(SVM)、ELM、PSO-ELM模型和傳統計算 模型計算值進行比較;最后從每個子研究區中抽取一條泥石流溝和其他極震區的三條泥石流溝應用PSO-ELM_AdaBoost模型進行泥石流物源動儲量預測,驗證了本文模型的準確性和適宜性。
1 理論與方法
1.1 最大互信息系數
現實世界數據之間的不一定總是呈現線性關系,采用余弦相似度(cosine similarity,CS)和Person相關系數等線性相關性系數,可能會造成關聯度誤判。為此Reshef等[16]基于互信息理論提出一種具有普適性和公平性的新型變量關聯評價指標:最大互信息系數,有效地解決了變量間的非線性關聯分析。
對于給定的兩個變量A=(a1,a2,…,an)和B=(b1,b2,…,bn),n為樣本個數,構建一個二元數據集D,利用一個x×y的網格G將D進行網格化,那么關于D的MIC可定義為
(1)
式(1)中:B(n)為網格劃分x×y的最大值,一般取B(n)=n0.6;M(D)為D的特征矩陣,其計算公式為
(2)
式(2)中:MI*是D雙變量間的最大互信息,即
MI*(D,x,y)=max[MI(D|G)]
(3)
式(3)中:D|G為每個單元網格的概率分布。
換言之,MIC是一種歸一化的最大互信息,其取值區間為[0,1]。MIC越大,表明兩個變量的相關性越強;反之,則表明兩個變量間的相關想越弱[17]。通過計算各因子與極震區泥石流動儲量的MIC,綜合PCC和GRG,就是為了全面地了解不同因子的影響能力,進而進行敏感性分析。
1.2 主成分分析
主成分分析可以有效處理輸入因子間存在一定相關性,對問題的反應存在一定的信息重疊問題[18]。經PCA處理后生成的新變量可以包含原變量大部分的信息,且相互之間不存在相關性。對于有n個樣本,每個樣本含有p個變量的原始數據矩陣Xn×p,具體分析過程如下。
(1)為消除量綱影響,對樣本各數據進行歸一化處理,并作為輸出樣本數據Yn×p。
(2)計算相關系數矩陣R,Rij(i,j=1,2,…,p)為原始變量間的相關性系數:
(4)
(3)根據矩陣R求出其特征值λi和特征向量ui,并按照從大到小排列。
(4)計算主成分貢獻率em和累計方差貢獻率Em,從而確定主成分的個數。
(5)
(6)
式中:m取值標準是使Em達到設定閾值,一般要求Em≥90%。
(5)輸出主成分樣本值Z:
(7)
用主成分樣本值Z代替原來數據樣本X,消除了原始數據間的相關性,從而達到了簡化結構的效果。
1.3 極限學習機
極限學習機是由Huang等[19-20]提出的一種基于單隱層前向反饋型神經網絡(SLGNs)的監督型學習算法。相較于傳統的神經網絡,該算法隨機產生輸入層與隱含層的連接權值及隱含層神經元的閾值,且在訓練過程中只需要設置隱含層神經元的個數,便可以獲取唯一的最優解。
設有n個任意的樣本(xi,ti),其中xi=(xi1,xi2,…,xin)T∈Rn,ti=(ti1,ti2,…,tin)T∈Rn,Rn為n元矩陣。對于一個有L個隱層節點的單隱層神經網絡可以表示為
(8)
式(8)中:wi=(wi1,wi2,…,win)T為輸入權重;βi為輸出權重;bi為第i個隱層單元的偏置;Oj為網絡輸出值;g(x)為激活函數;激活函數均采用sigmoid方程,其形式如式(9)所示:
(9)
(10)
用矩陣表述為
Hβ=T
(11)
式(11)中:H為隱含層輸出矩陣;β為輸出權重矩陣;T為期望輸出矩陣。網絡訓練中,由于鎖定了隨機選擇的wi和bi,H為固定矩陣。此時β可通過求解式(11)最小二乘解進行求解,即:
(12)
此線性方程的最小二乘解為
(13)
式(13)中,H?是矩陣H的Moore-Penrose廣義逆[20]。
1.4 粒子群算法優化極限學習機
粒子群算法是一種全局優化算法[21]。其主要思想為將每個優化問題的潛在解設為一個粒子,在初始化階段每個粒子都被賦予初始位置和速度,并且為了衡量每個粒子的優越性,定義一個適應度函數,并設定迭代次數。在每次迭代中,所有粒子向全局最優解pbest(整個種群目前搜索到的最優解)與個體最優解qbest(個體自身所能達到的個體最優解)進行逼近,并比較適應度,以更新自己的速度和位置,最終獲得全空間搜索最優解。
因此在ELM預測模型中,基于PSO優化網絡參數w、β和b,可以避免參數的盲目試算,提高了預測模型的準確性。
1.5 PSO-ELM_AdaBoost耦合模型
AdaBoost算法是基于弱學習定理的一種Boosting應用算法[22],可以提高任意給定弱預測器的預測精度。模型采用PSO-ELM作為弱預測器,多次調用PSO-ELM,并根據每次訓練樣本預測的優劣,更新對應的權重,再將改變權重后的樣本重新對弱預測器進行訓練,最后采用AdaBoost算法對這些弱預測器訓練結果進行集成,輸出最終結果。建立基于PCA的PSO-ELM_AdaBoost模型的步驟如下。
(1)數據選擇與網絡初始化。首先將原始數據樣本集X進行歸一化處理得到數據集Y,再利用PCA將Y降維,得到了消除冗余信息的新數據樣本集Z。從Z中隨機選擇m組訓練數據,初始化測試數據的分布權值Dt(i)=m-1,并確定預測誤差閾值。
(2)弱分類器預測。利用訓練數據訓練PSO-ELM并且預測訓練數據輸出,得到預測序列g(t)的預測誤差和et:
(14)
式(14)中:Dt(i)為第t次迭代權值;g(t)為預測結果且g(t)≠y,其中y為預測期望誤差。
(3)計算預測序列權重。權重at的計算公式為
(15)
(4)更新樣本權重。根據權重at調整下一輪訓練樣本權重:
(16)
式(16)中:Bt為歸一化因子;g(t)為預測結果。
(5)強預測器函數。將訓練得到的多個弱分類函數集合成強預測函數h(x)。
(17)
式(17)中:ft(x)為弱分類函數。
根據上述步驟,基于PCA的PSO-ELM_AdaBoost預測模型算法流程如圖1所示。
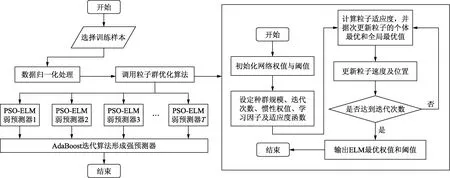
圖1 基于主成分分析的粒子群優化極限學習機和AdaBoost算法耦合模型流程圖Fig.1 Modeling flow chart of the PSO-ELM_AdaBoost based on PCA
2 研究區概況及影響因子選取
2.1 研究區概況
2008年“5·12”汶川地震發生后,極震區內泥石流呈現出頻率高、規模大和周期復發等特征,泥石流溝間物源類型、啟動方式也和發育特征各有不同,對該區域進行震后泥石流物源動儲量特征研究具有代表性。主要選取汶川地震極震區震后泥石流物源量較多、啟動條件較低、危險性較大的泥石流作為研究對象(部分樣本現場航拍圖如圖2所示)。泥石流樣本數據來源于汶川縣映秀鎮(13條)、G213公路沿線(5條)、都江堰市龍池鎮(10條)、綿竹市清平鄉(9條)、安州區高川鄉(20條)和北川縣縣城附近(3條),共計60條樣本,樣本分布如圖3所示。

圖2 部分樣本現場航拍圖Fig.2 Aerial photos of some sample sites
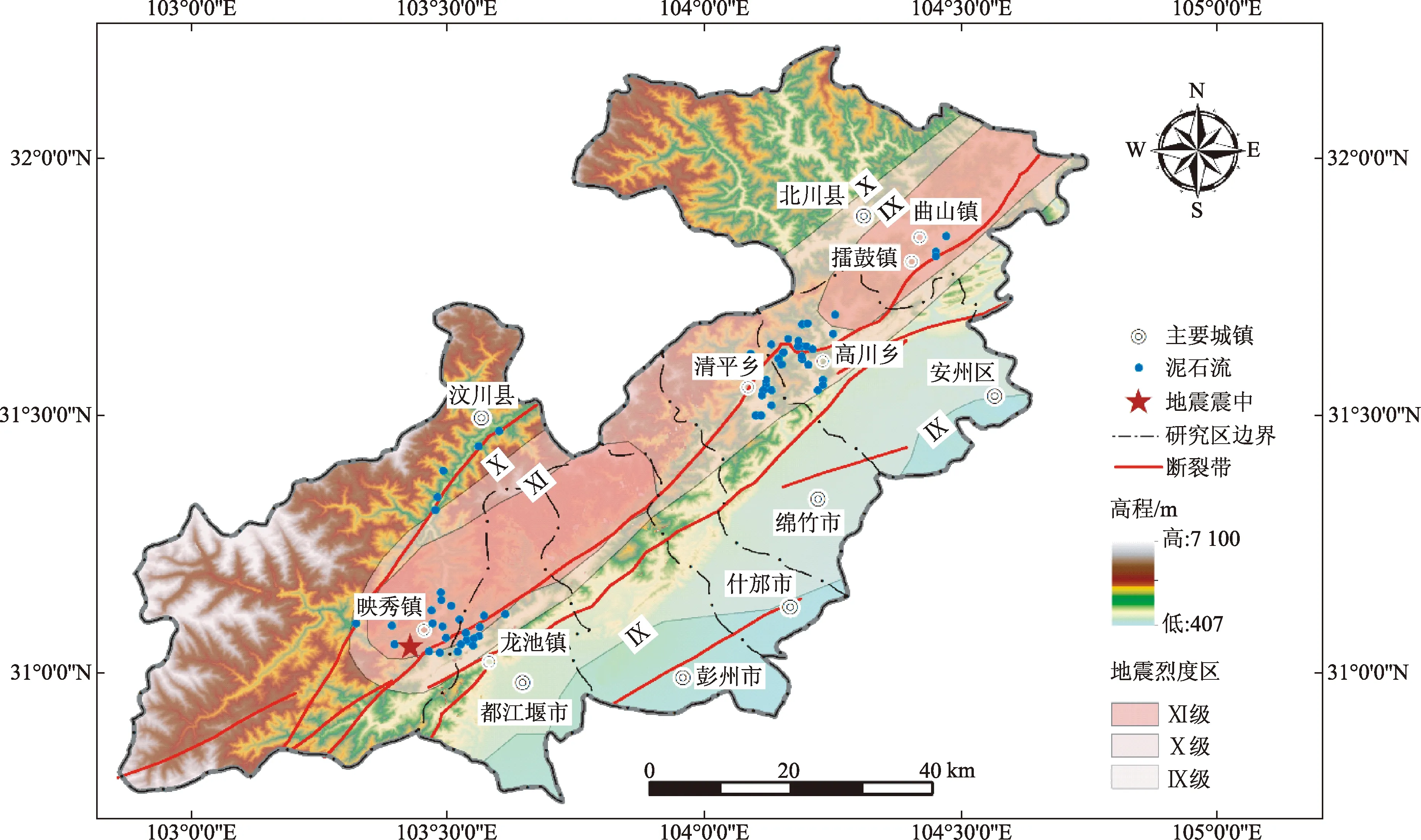
圖3 研究區地形地貌、地震烈度及泥石流溝分布Fig.3 Geomorphologic,seismicity and distribution of debris flow in research area
2.2 影響因子的選取與敏感性和響應分析
影響因子的選取既要考慮因子的是否具有代表性,也要確保各因子之間相互獨立且選取因子易量化。極震區震后泥石流動儲量主要來源有:①由強震效應誘發可參加泥石流活動的溝道崩滑堆積體;②先前溝內潛在物源及震后破碎不穩定山體經強降雨條件下導致的洪水沖刷以及侵蝕等作用累積產生的補給性和次生性物源。因此,綜合考慮泥石流溝的流域規模、地質環境背景和地震效應等條件下初步選取流域面積(A)、相對高差(h)、主溝長度(l)、距發震斷裂帶距離(d)、溝床平均縱比降(J)和物源靜儲量(V)作為泥石流物源動儲量(V0)的影響因子。為了進一步研究各影響因子對極震區震后泥石流物源動儲量的敏感程度,分別采用Person相關系數(PCC)、灰色關聯度(GRG)和最大信息系數(MIC),以收集到的汶川地震極震區區內60條泥石流溝的物源信息為樣本(表1),對各因子與極震區泥石流物源動儲量進行相關性分析。為消除量綱影響,對樣本各數據進行歸一化處理,灰色關聯度[23]計算中分辨系數取ζ=0.5,最大信息系數基礎參數取?=0.6,c=15,得到的計算結果,如表2所示。
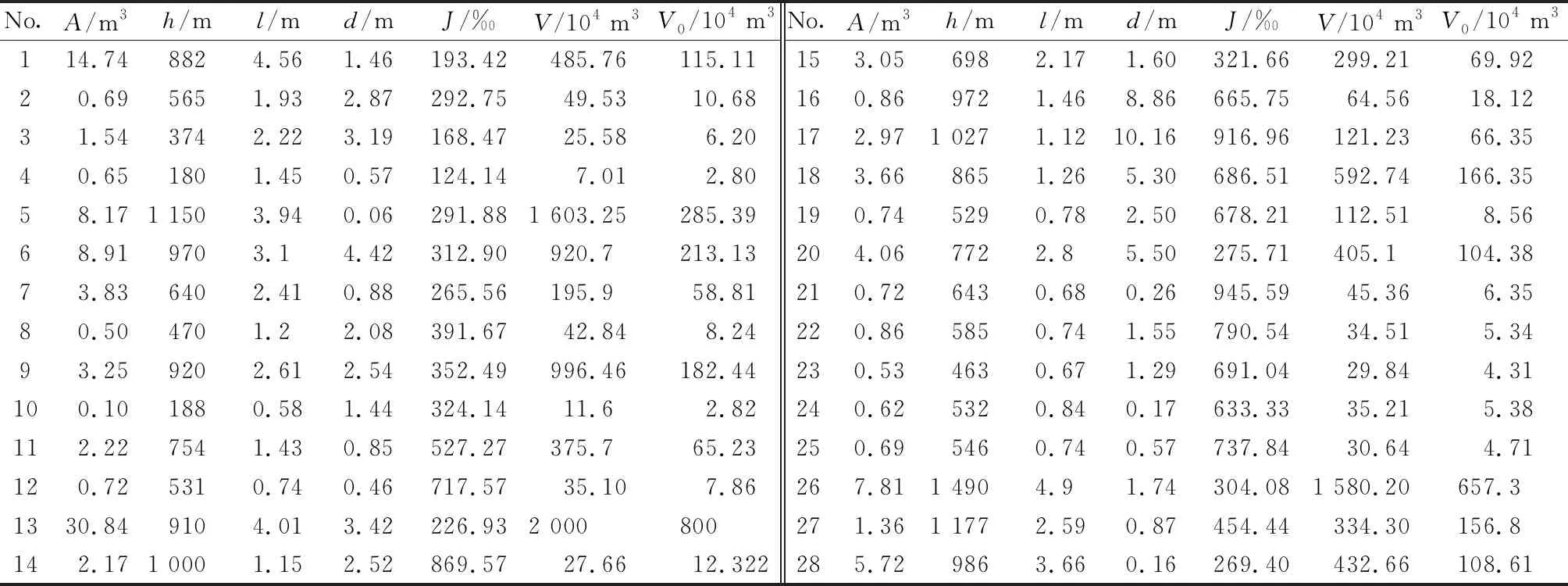
表1 汶川極震區泥石流溝物源信息樣本Table 1 Material source parameters of the debris flow gully sample in the Wenchuan meizoseismal area
續表1
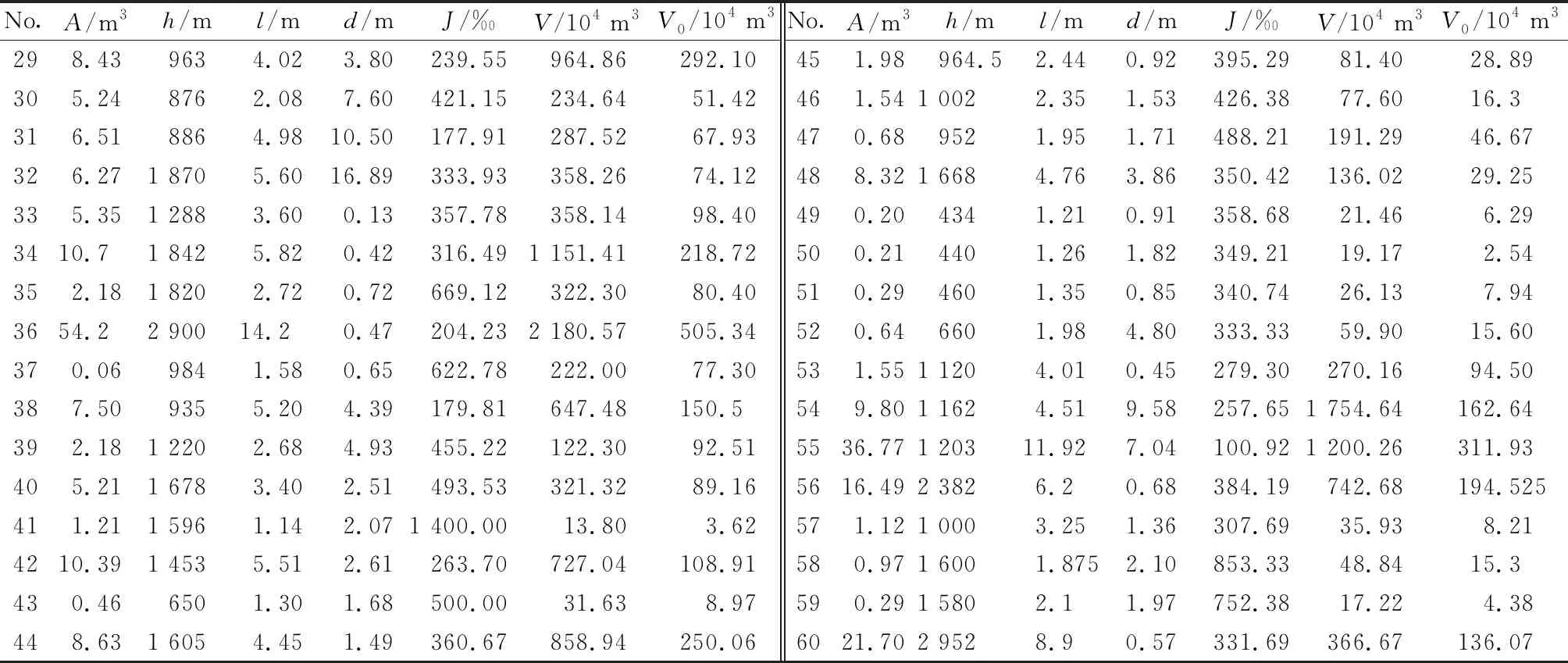
No.A/m3h/ml/md/mJ/‰V/104 m3V0/104 m3No.A/m3h/ml/md/mJ/‰V/104 m3V0/104 m3298.439634.023.80239.55964.86292.10305.248762.087.60421.15234.6451.42316.518864.9810.50177.91287.5267.93326.271 8705.6016.89333.93358.2674.12335.351 2883.600.13357.78358.1498.403410.71 8425.820.42316.491 151.41218.72352.181 8202.720.72669.12322.3080.403654.22 90014.20.47204.232 180.57505.34370.069841.580.65622.78222.0077.30387.509355.204.39179.81647.48150.5392.181 2202.684.93455.22122.3092.51405.211 6783.402.51493.53321.3289.16411.211 5961.142.071 400.0013.803.624210.391 4535.512.61263.70727.04108.91430.466501.301.68500.0031.638.97448.631 6054.451.49360.67858.94250.06451.98964.52.440.92395.2981.4028.89461.541 0022.351.53426.3877.6016.3470.689521.951.71488.21191.2946.67488.321 6684.763.86350.42136.0229.25490.204341.210.91358.6821.466.29500.214401.261.82349.2119.172.54510.294601.350.85340.7426.137.94520.646601.984.80333.3359.9015.60531.551 1204.010.45279.30270.1694.50549.801 1624.519.58257.651 754.64162.645536.771 20311.927.04100.921 200.26311.935616.492 3826.20.68384.19742.68194.525571.121 0003.251.36307.6935.938.21580.971 6001.8752.10853.3348.8415.3590.291 5802.11.97752.3817.224.386021.702 9528.90.57331.69366.67136.07
注:1~20為安州區高川鄉內泥石流溝;21~29為綿竹市清平鄉內泥石流溝;30~42為汶川縣映秀鎮內泥石流溝;43~52為都江堰市龍池鎮內泥石流溝;53~55為北川縣境內泥石流溝;56~60為汶川縣G213公路沿線泥石流溝。
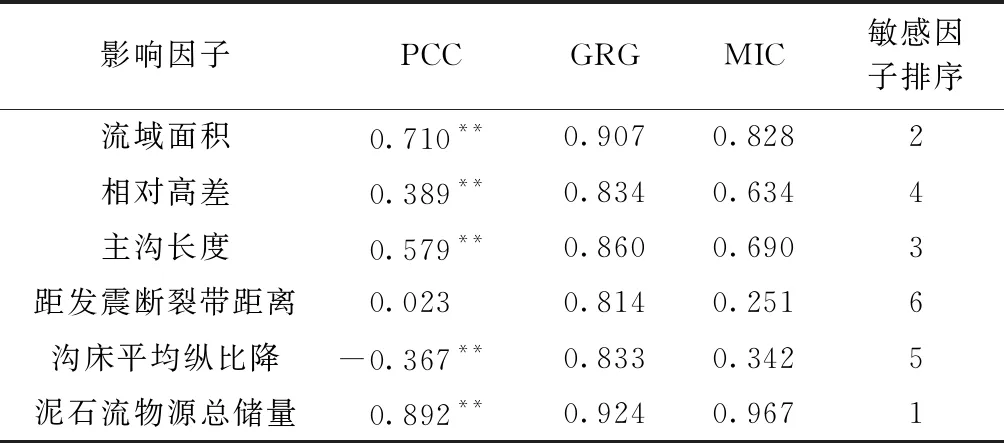
表2 影響因子與極震區泥石流物源動儲量敏感性分析Table 2 Sensibility analysis between impact factors and dynamic reserve of the debris flows
注:**表示在0.01水平(雙側)上顯著相關。
由表2可知,基于PCC的相關性分析中,只能判定泥石流物源總儲量和流域面積兩個因子與泥石流物源動儲量有明顯的線性關系。而在灰色關聯度計算中,各因子的GRG均大于0.6,可認為各影響因子與泥石流物源動儲量密切相關[23]。MIC相較于GRG區分度十分明顯,更能有效地反映極震區泥石流物源動儲量對各影響因子的敏感性。最終判定,泥石流物源總儲量因子最敏感,而距發震斷裂帶距離因子最末,選取的各因子均會在不同程度上影響極震區泥石流物源動儲量,驗證了影響因子選取的合理性。需要指出的是,通過對5個影響因子之間進行相關性系數計算,結果表明:流域面積與主溝長度、流域面積與相對高差和主溝長度與相對高差Person相關系數值分別為0.624、0.814和0.715,相關性較高,其他各影響因子之間Person相關系數值均小于0.419,相關性較弱。在此考慮使用PCA,對輸入因子進行降維,避免信息冗余。
3 泥石流物源動儲量計算
以汶川地震極震區區內60條泥石流溝的物源信息為樣本,從每個子研究區中抽取一條泥石流溝作為測試樣本,另外的所有樣本作為訓練樣本和驗證樣本,其中驗證樣本采用“留一法”交叉驗證方式得到。對樣本數據進行PCA降維處理后分別基于五種神經網絡算法對研究區內泥石流動儲量分別建立計算模型,樣本數據如表1所示。
3.1 PCA對原始數據進行預處理
利用PCA求得的原始樣本數據得出的特征值(從大到小)和累計貢獻率如表3所示。

表3 各主成分因子的特征值及累積貢獻率Table 3 Eigenvalues of each principal factor and its cumulative contribution rate
計算得到前4個主成分的累積貢獻率達到94.197%,因此可以選取第1主成分(PCA-1)、第2主成分(PCA-2)、第3主成分(PCA-3)和第4主成分(PCA- 4)作為神經網絡模型的輸入,這4個主成分因子特征根對應的特征向量如表4所示。將上述特征向量與原始樣本數據對應相乘,即可得到PCA處理后的樣本數據。
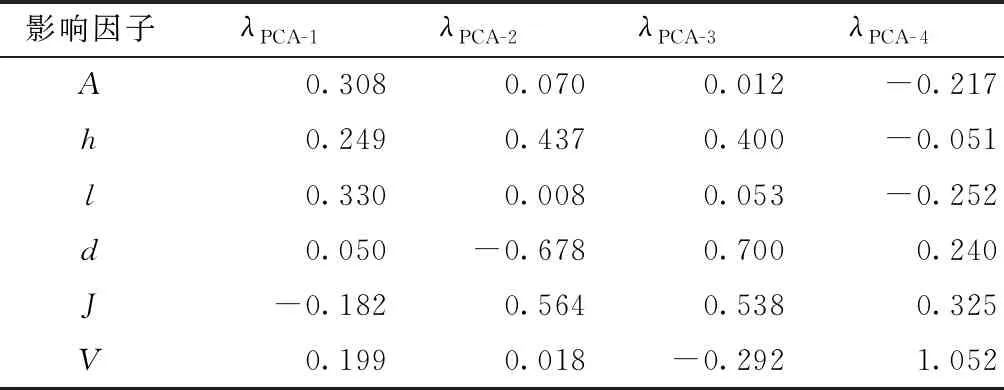
表4 前4個主成分因子特征值對應的特征向量Table 4 Eigenvectors of 4 big eigenvalues
3.2 各神經網絡模型參數的設置
3.2.1 BP神經網絡模型
網絡設置為4- 4-1三層結構,即輸入層節點為4,隱含層節點數按照經驗公式[24]確定取值范圍后經試算,設置為4,輸出層節點為1。在訓練過程中,學習率Lr=0.05,訓練精度Ggoal=0.01,最大訓練次數為5 000。
3.2.2 SVM模型
網絡核函數設置為RBF(radial basis function),基于五折交叉驗證法(5-cross validation)的參數選取結果如圖4所示。最終選取懲罰函參數c和核函數參數g分別為5.656 9、0.062 5。
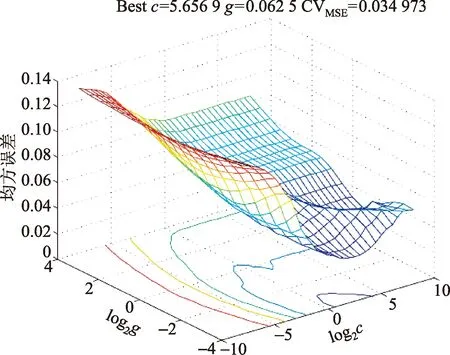
CvMES表示尋優過程中的均方誤差圖4 基于交叉驗證法的SVM參數選取結果Fig.4 The results of SVM parameters selection based on cross validation
3.2.3 ELM模型
網絡設置sigmoid為激活函數,設置隱含層節點個數為一個循環數列,在[1,100]中尋找最優隱含層節點數。選擇不同的隱含層節點數對ELM模型的計算準確性有較大影響,最終模型計算得到不同隱含層節點數下均方誤差(MSE)歸一化后的變化曲線。由圖5(a)可知,ELM模型隱含層節點數到達57后MSE(歸一化后)收斂到0.03以下,且隨著節點數的增多,節點數達到76后,MSE(歸一化后)呈振蕩趨勢。
3.2.4 PSO-ELM模型
同樣建立以sigmoid方程為激活函數的PSO-ELM計算模型,并在[1,100]中搜索最優隱含層節點數。模型MSE(歸一化后)隨著隱含層節點數變化曲線如圖5(b)所示。在PSO算法中:學習因子c1=1.5、c2=1.7,慣性權重w=1,種群規模Zsizepop=20,最大進化代數為Gmaxgan=100。由圖5(b)可知,PSO-ELM模型隱含層節點數達到40后MSE(歸一化后)收斂到0.03以下,之后趨于平穩。說明PSO算法減少了“無用的”隱含層節點,獲得了更為緊湊的網絡體系結構,提升了模型的穩定性。
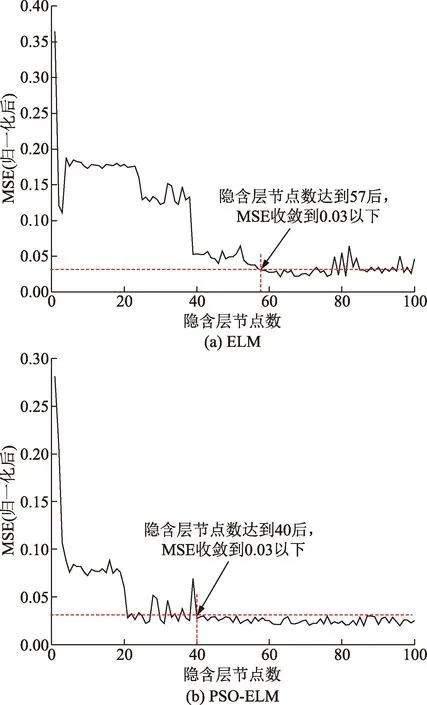
圖5 MSE與隱含層節點數關系圖Fig.5 Relationship diagram of the number of hidden neurons with MSE
3.2.5 PSO-ELM_Adaboost耦合模型
PSO-ELM參數設置與模型4相同,基分類器數經試算設置為10。
3.3 預測結果與誤差分析
各模型的訓練樣本擬合結果如圖6所示,測試樣本預測結果如圖7所示,各樣本間誤差比較如表5 所示。
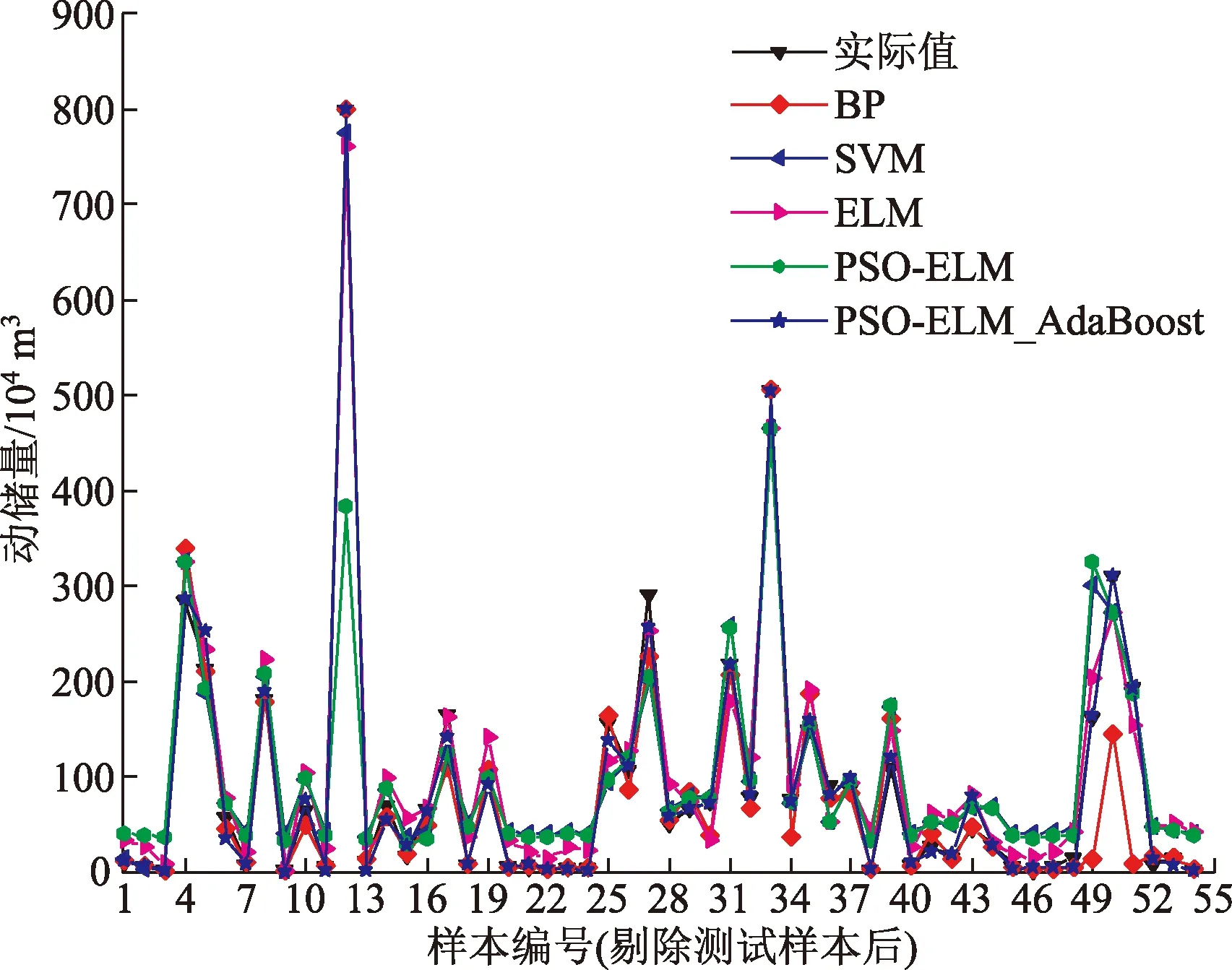
圖6 訓練樣本預測結果對比Fig.6 Comparison of test sample training results
為比較各模型之間的可靠性與準確性,模型誤差采用均方根誤差(RMSE)和平均絕對百分誤差(MAPE),計算公式為
(18)
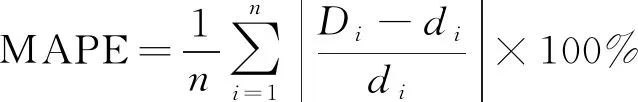
(19)
式中:di為實際值;Di為預測值;n為樣本個數。
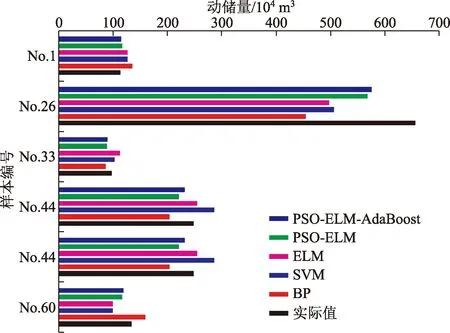
圖7 測試樣本預測結果對比Fig.7 Comparison of test sample prediction results

表5 各神經網絡模型誤差對比Table 5 Comparison of error of each neural network model
注:模型計算用時基于Intel i7-7700K、16GB DDR4內存和windows 7 64位系統的MATLAB R2016a 平臺。
由表5可知,在單一神經網絡模型中,ELM計算效果最好,優于BP和SVM。并且在模型用時方面,ELM計算用時為0.042 s,顯著低于BP和SVM(用時分別為3.024、1.431 s),說明了ELM方法具有耗時短,效率高的優點。接著將兩種耦合模型與單一神經網絡模型進行對比,發現在計算精度上PSO-ELM和PSO-ELM_AdaBoost具有顯著優勢,訓練樣本和測試樣本的誤差評價參數RMSE、MAPE均小于前兩者。在兩種耦合模型中,由于AdaBoost算法“能夠提高任意給定弱預測器的預測精度”的特點, 訓練樣本和測試樣本RMSE分別降低了4.17和4.43,MAPE分別降低了1.20%和1.86%,模型誤差有較大程度的減小,所以PSO-ELM_AdaBoost的計算精度優于PSO-ELM。但由于網絡結構復雜程度的提升,模型用時有不可避免的增加。最后將PSO-ELM_AdaBoost模型的精度與其他計算模型[4-9]相比,精度也相對更高,可以有效地對汶川極震區內泥石流物源動儲量進行計算。
對模型產生的誤差進行分析,可能的原因有:①由于儀器、方法或人為原因造成野外采集的樣本數據不準確,樣本數據的準確性直接影響模型的精度;②流域地質環境背景有所差異。例如,測試樣本中No.26和No.53在震時分別誘發了兩個巨型滑坡,從而影響了模型預測精度,總體上各模型計算值均小于實際動儲量,剔除后測試樣本的各模型的RMSE為23.02、21.59、16.79、13.63和9.91,MAPE為16.32%、14.31%、13.94%、9.73%和6.69%;③坡體結構和巖性組合方式的區別:地層巖性對形成崩滑體具有重要的作用,其主要影響基巖和堆積體的物理力學性質;同時,不同地層巖性中崩滑體發育的規模、類型特征也不盡相同,而崩滑體多寡正是動儲量形成的重要內部因素[25];④其他影響因素:物源組成顆粒的級配、密實度和泥石流溝坡向等。
3.4 模型在其他極震區的適宜性檢驗
為檢驗模型在其他極震區的適宜性,隨機選擇玉樹地震極震區結古鎮布慶隆溝、蘆山地震極震區冷木溝和中崗溝作為通用適宜性檢驗樣本,將數據進行PCA降維處理后,根據所得的PSO-ELM_AdaBoost耦合模型,進行動儲量計算及誤差分析。通用適宜性檢驗樣本具體參數及預測值如表6所示。

表6 通用適宜性樣本預測結果及誤差Table 6 Prediction results and errors of suitability samples outside the study area
由表6可知,預測精度依然較好,能夠滿足實際要求。但與汶川地震極震區內預測誤差相比,誤差相對較大,且計算動儲量均大于實際值。分析考慮是:玉樹地震和蘆山地震強度不及汶川地震且區域內平均降雨量較汶川地震極震區少[26-27]。因此,此處產生的誤差不僅與3.3節提出的誤差相關可能還與地震強度的高低和區域降雨條件的不同等因素有關。
4 結論
(1)以泥石流溝的流域面積、相對高差、主溝長度、溝床平均縱比降、較發震斷裂帶距離和物源總儲量作為泥石流物源動儲量的影響因素,對采集的汶川極震區區內的60條泥石流溝的物源信息數據,經PCA降維后,進行訓練與預測,建立的PSO-ELM_AdaBoost耦合模型具有精度高、可控性強和穩定性好的特點。計算精度顯著優于BP、SVM、ELM和PSO-ELM,與其他計算模型相比這些誤差也相對較小,并且對其他極震區泥石流物源動儲量的預測精度依然較高,滿足實際要求。因此該模型可以在極震區泥石流動儲量計算中發揮一定的作用,為設計泥石流防治工程提供有價值的參考。
(2)通過對模型誤差的分析,在同一極震區內考慮是地質環境背景、坡體結構、巖性組合、物源組成等因素的影響。 而在不同極震區內誤差的產生可能還與地震自身強度和區域降雨條件等因素有關。因此,下一步工作的重點就是如何對以上因素進行量化再分析,以繼續提升本模型的適宜性和精度。
(3)隨著神經網絡等機器學習技術的不斷發展,算法預測模型精度越來越高,但準確的泥石流實測數據是建立好的算法預測模型的基礎,因此建立泥石流多發區域的泥石流溝數據庫具有重要意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
