復雜化工系統的可靠性評估研究
2020-06-24 08:45:56趙凡銳趙元沛孫仲平
山東化工 2020年10期
關鍵詞:模型
趙凡銳,趙元沛,孫仲平,周 利,吉 旭
(1.四川大學 化學工程學院,四川 成都 610065;2.重慶大學輸配電裝備及系統安全與新技術國家重點實驗室,重慶 400044)
當前工業生產過程正日益向大型化和復雜化發展,HSE(Health,Safety,Environment)評估模型已成為企業通過智能化措施保持持續發展的重要模式[1-2]。系統可靠性(System reliability,)是評估企業HSE狀態的重要因素之一[3-4], Saleh和Marais研究了復雜系統的可靠性理論[5],Graves等人利用全貝葉斯方法根據多狀態及多層次信息傳遞特點構建系統故障樹[6],劉文等人建立了面向故障的可靠性模型,用于評估化學系統的安全性、環境性和經濟性[7],李總根總結了基于概率統計的常規可靠性評估進展,給出了基于信息理論的復雜系統可靠性多層次模型[8]。
然而對于具有多輸入、多輸出、非線性、數據高維等特點的復雜化工系統[9],傳統的基于物理模型的方法已經難以進行有效評估。隨著先進技術的逐步應用,計算機建模為開發更有效的系統可靠性評估方法提供了機會,神經網絡模型已成為此類復雜化工系統的研究重點。Liu等人提出了一種GRA-GA-BP-MCRC的混合算法[10],其中灰色關聯分析(GRA)用于指標體系的降維,GA-BP為模型的訓練及預測算法,馬爾科夫鏈殘差校正(MCRC)用于預測誤差的校正。神經網絡模型對于有足夠數據水平的復雜系統是可行的,但是化工系統通常僅在短時間內穩定,來自化工系統的數據通常是小樣本。小樣本的數據通過神經網絡方法難以達到較好的預測效果。近年來,智能算法逐漸應用于可靠性評估的問題。Nieto等人建立了一個基于PSO-SVM的混合模型,用于預測飛機發動機的剩余使用壽命并評估其可靠性,這是在可靠性領域的成功探索[11]。Benali等人比較了運用人工神經網絡和隨機森林算法預測太陽輻射組成,發現隨機森林算法的預測精度要好[12]。
基于此,本文建立了PCA-RF混合預測模型,利用隨機森林算法(RF)所需樣本小、泛化能力強的特點實現可靠性的預測,主成分分析法(PCA)主要用于指標體系的約簡,以達到簡化運算提高預測精度的目的。
1 背景理論簡介
1.1 主成分分析法
主成分分析法(Principal component analysis,PCA)是一種提取特征或提取有效信息的方法。在實際的問題研究中,為了全面的反映某一問題,必須考慮影響該問題的眾多因素,這些因素稱為指標,也叫變量。通常這些變量間存在著一定的相關性,因此反應的信息也有部分重疊,而且眾多的變量也會增加問題的復雜度,降低模型收斂速度等。因此在研究變量時,理想的方法就是用最少的指標來反映最多的信息,PCA方法就是研究此類問題的理想工具。PCA方法是在保證損失最少信息的前提下,將影響問題的變量線性組合為幾個綜合指標,即主成分,這些主成分不僅保留了原始變量的主要信息,而且相互之間不存在相關關系,避免了信息的冗余,達到簡化模型的作用。
1.2 隨機森林算法
隨機森林算法(Random forest,RF)是一種集成學習方法[13]。集成學習方法是一種將個體學習器通過某種策略集成為一個強學習器來完成學習任務的方法。隨機森林是一種以決策樹為基學習器Bagging集成方法的組合算法。
Bagging是并行式集成方法的典型代表。它通過自助采樣法(bootstrap)進行重采樣,設給定含有m個樣本的數據集,從樣本數據集中隨機抽取一個放入采樣器中,然后再把該樣本數據放回原數據集中,這樣下次抽取的時候該數據還有被抽中的可能,經過m次這樣有放回的抽取,得到了一個含有m個樣本的采樣集。這種抽樣的結果是,有的數據被多次抽中而有的數據則一次都沒被抽中,有數據表明,這種重采樣技術每個樣本被抽中的概率是63.2%。
按照上述方法抽取T個含有m個樣本的采樣集,針對每一個采樣集,訓練一個基學習器,然后把這些基學習器組合起來進行輸出,這就是Bagging集成方法的基本流程。對于分類問題,基學習器之間的組合方式就是簡單投票法,對于回歸問題,基學習器之間的組合方式是簡單平均法。
隨機森林是Bagging集成技術的一個變體。隨機森林在以決策樹為基學習器Bagging集成的基礎上,加入了隨機屬性的選擇。通常決策樹在選擇屬性劃分時是在當前結點所有的屬性中(假設有d個屬性)選擇一個最佳屬性,而隨機森林中的基決策樹在選擇屬性劃分時,從當前結點的屬性集合中隨機選擇k個屬性進行劃分。參數k決定了隨機屬性的引入程度,當k=d時,隨機森林中的基決策樹與普通決策樹一樣,進行全特征屬性的劃分;當k=1時,則是隨機選擇一個屬性進行劃分,一般情況下,。
隨機森林算法的流程圖如圖1所示:
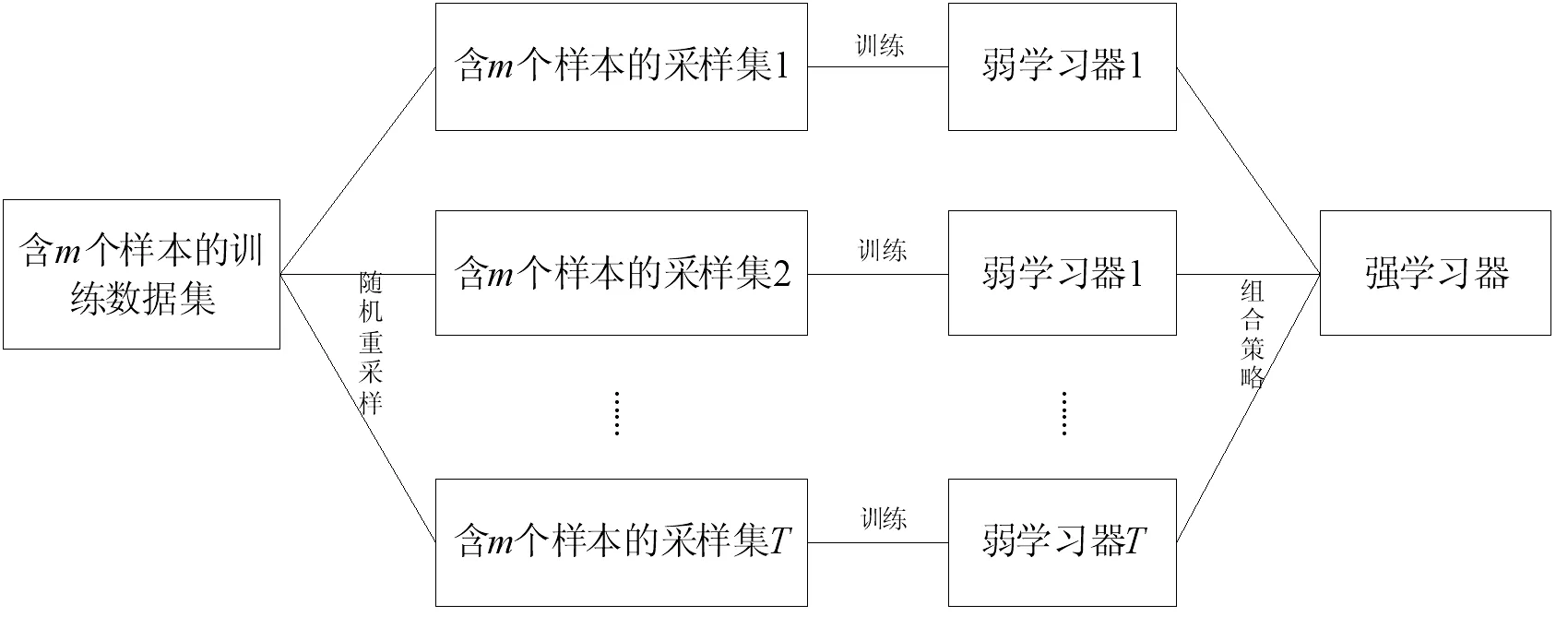
圖1 隨機森林流程圖
隨機森林具有算法簡單、容易實現、計算開銷小等特點。大量的研究和實踐表明,隨機森林算法具有很好的預測效果,泛化能力強,并且能夠適應異常值和噪聲值,即使是數據損失也能夠保持較高的預測效果。
2 基于PCA-RF混合算法的可靠性評估模型
以復雜化工系統為研究體系,以系統可靠度為研究對象,由影響系統可靠性的影響因素來預測化工系統的可靠度是本研究的主要內容。
2.1 可靠性評估指標體系的4M1E分類法
在進行化工系統可靠性評估模型構建前,首先要確立可靠性評估指標體系,影響化工系統可靠性的因素眾多,不僅要考慮設備發生故障的總頻次、造成停車的總時間,還涉及到環境因素、人為因素等,因此指標體系涉及到的因素眾多。本文將企業運行和現場管理的4M1E模型,即人員(Man),機器(Machine),物料(Material),管理方法(Management),環境(Environment)五個要素,應用于化工系統可靠性評估指標體系的構建,這五個方面基本涵蓋了化工生產的各個方面,能較全面且系統的反映化工生產的各個環節。具體指標如表1~表5。

表1 人員模塊相關指標
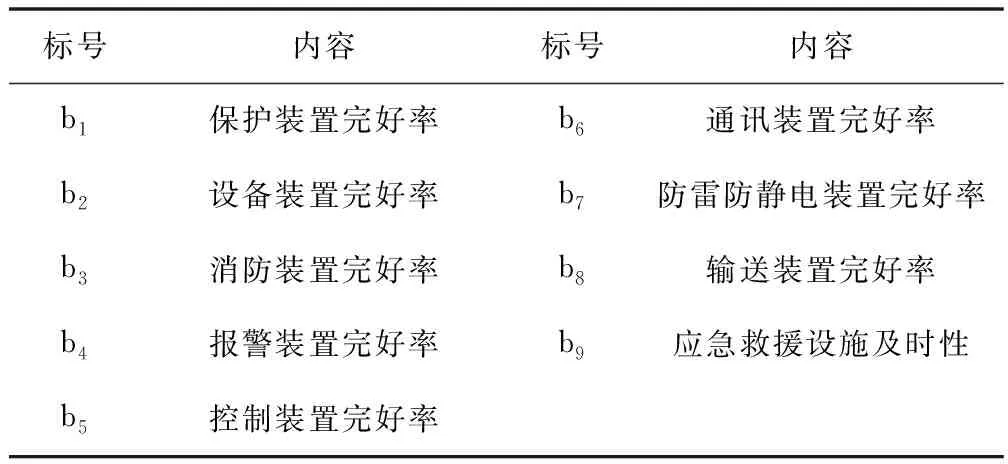
表2 機器模塊相關指標

表3 物料模塊相關指標
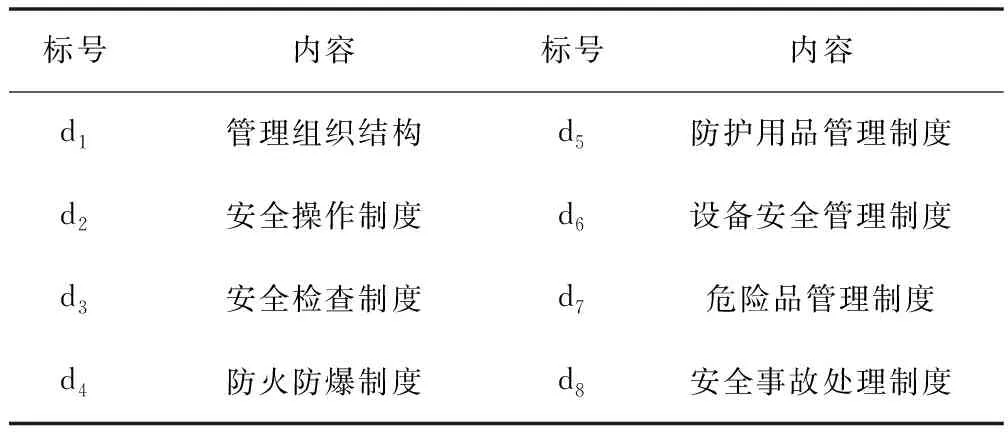
表4 管理方法模塊相關指標

表5 環境模塊相關指標
綜合人員,機器,物料,管理方法和環境因素,共產生37個影響因素指標,這37個指標基本涵蓋了復雜生產操作系統所有的環節。
2.2 兩步法PCA-RF混合算法預測模型
在構建了影響系統可靠性的指標體系后,接下來進行系統可靠度預測模型的構建,提出用兩步法PCA-RF混合算法模型來實現化工系統可靠度的預測。第一步,首先預測按照4M1E分類法得到的五個子系統的評價值;第二步由預測得到的五個子系統的評價值作為輸入來預測整個系統的可靠度。兩步法的拓撲圖如圖2所示。主成分分析法(PCA)用于對指標體系的降維,去除掉對系統可靠性影響小的指標,達到簡化運算,提高預測精度的目的。隨機森林算法(RF)作為模型的訓練及預測算法,主要用于第一步中各個子系統評價值的預測及第二步中整個系統可靠度的預測。兩步法PCA-RF混合算法模型的具體結構框圖如圖3所示。

圖2 兩步法拓撲結構圖
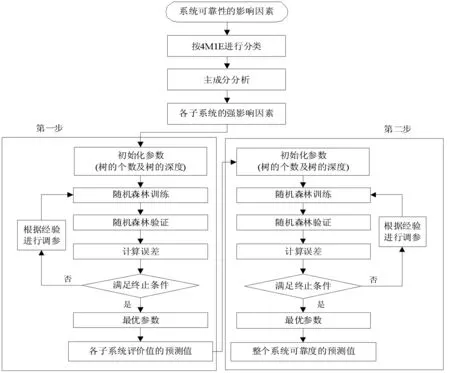
圖3 兩步法PCA-RF混合算法模型結構圖
3 案例應用分析
3.1 案例背景
本研究以我國某集團合成氨分廠提供的數據為例,進行模型的驗證[14]。圖4顯示的是該合成氨分廠部分工序的生產流程圖,包括脫除二氧化碳工序、空氣凈化分離工序、閃蒸工序、解吸工序、冷凝工序等15個工序。以建立的可靠性評估指標體系,即4M1E指標分類原則,獲取研究所需的數據樣本。
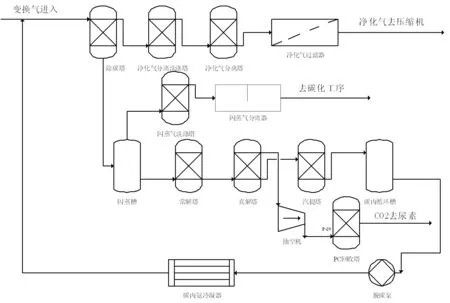
圖4 合成氨分廠部分工序生產流程圖
3.2 原始數據獲取
由于化工廠數據的采集和維護具有周期性,復雜系統的數據收集也較困難,獲得了該廠2013年穩定運行的100組數據進行研究,是典型的小樣本數據。將收集到的數據分為人,機,料,法,環五個方面,具體指標見表1~5。
化工系統的可靠性用系統可靠度進行表征,系統可靠性分五個等級,如表6所示,系統可靠度的取值為[1,5],具體評價值采用德爾菲法[15]由專家打分給出。德爾菲法是一種匿名函詢反饋法,具體步驟為:將要評估的問題匿名發放給各位專家,獲取專家的意見后,進行整理、歸類、統計、總結后,再匿名反饋給各位專家,再次獲取意見,再集中,再反饋,直到獲得一致的意見為止。

表6 系統可靠性的五個等級
化工系統可靠性評估的原始數據如表7所示。{1,0.9,0.8,0.7,0.5}代表定性指標定量化后的五個定量等級(例如a5,c1)。a,b,c,d,e表示五個子系統的評價值,表示整個化工系統的評價值。a,b,c,d,e,的評價值及其他定性評價指標(例如d2,e4)均由德爾菲法由專家打分給出。

表7 可靠性評估原始數據
3.3 結果分析
3.3.1 主成分分析
利用SPSS軟件分別對五個子系統進行主成分分析,以達到保留主要影響因素,去除冗余因素,簡化模型輸入指標的作用。下面以物料子系統為例進行結果分析。
由表8可以看出,各指標之間存在較強的相關性,有必要進行主成分分析。表9為總方差解釋,代表各個指標方差占總方差的比重,由表9可以看出,有一個最大貢獻率的主成分,即特征值為7.454,滿足特征值其貢獻率達到93.177%,這說明第一個主成分就提供了足夠多原始數據的信息,因此得到一個主成分。
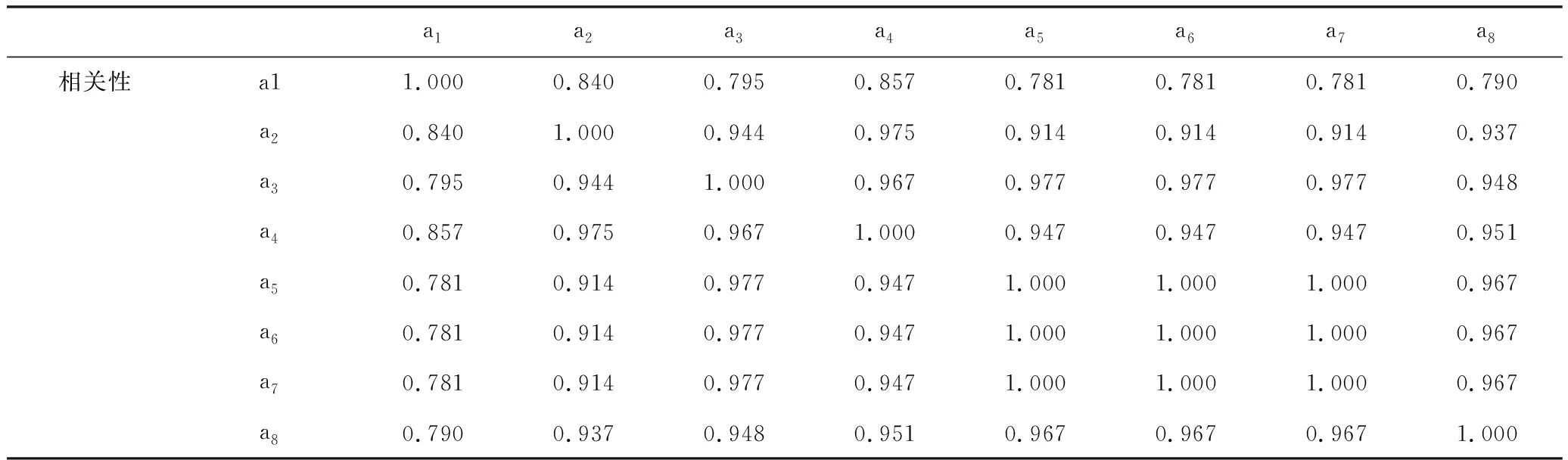
表8 相關性矩陣
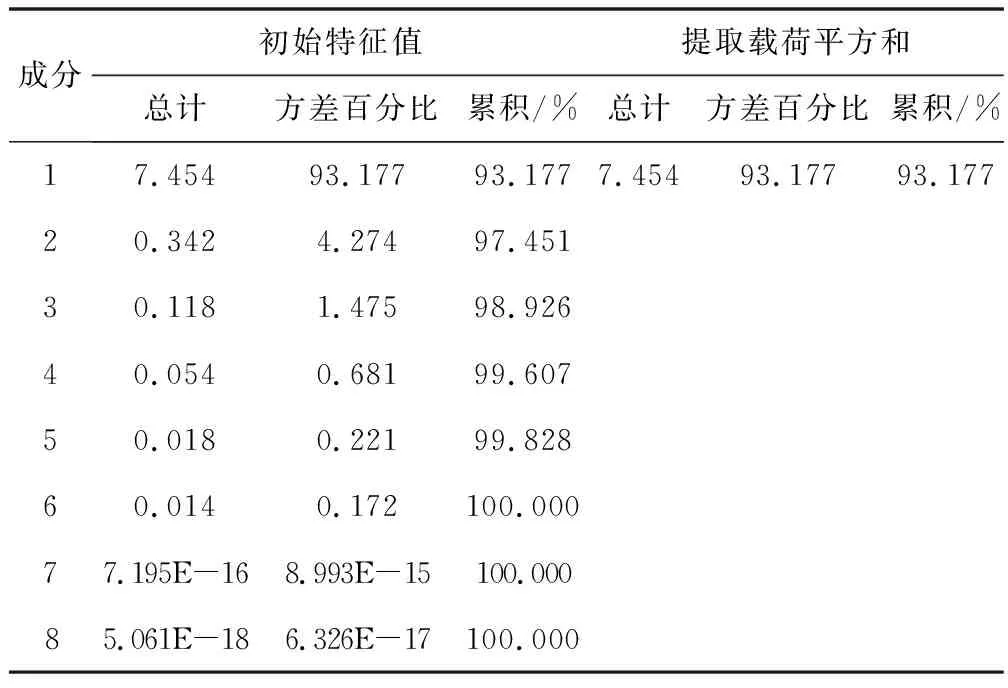
表9 總方差解釋
如圖5所示的碎石圖是根據SPSS軟件自動生成的,碎石圖也可以作為判斷主成分個數的依據。碎石圖橫坐標代表主成分的個數,縱坐標代表各個主成分的特征值,由圖可以看出,在第二個主成分處發生明顯偏折,且其之后的特征值都不滿足特征值λ≥1。
綜上,物料子系統的指標所提取到的主成分個數為一個。表10是由SPSS軟件得到的成分得分系數矩陣,該矩陣代表各個變量在主成分中對應的系數,可用下式進行表示:
Z1=0.115a1+0.129a2+0.132a3+0.132a4+0.132a5+0.132a6+0.132a7+0.131a8
(1)
由式(1)可以看出,a3,a4,a5,a6,a7,a8的系數遠大于a1,a2的系數,因此第一主成分Z1是由a3,a4,a5,a6,a7,a8所確定的,可將a1,a2剔除,達到簡化運算的目的。
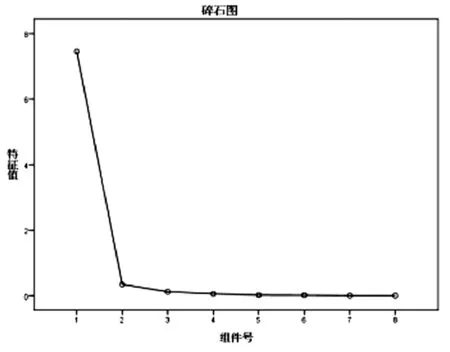
圖5 主成分分析法碎石圖
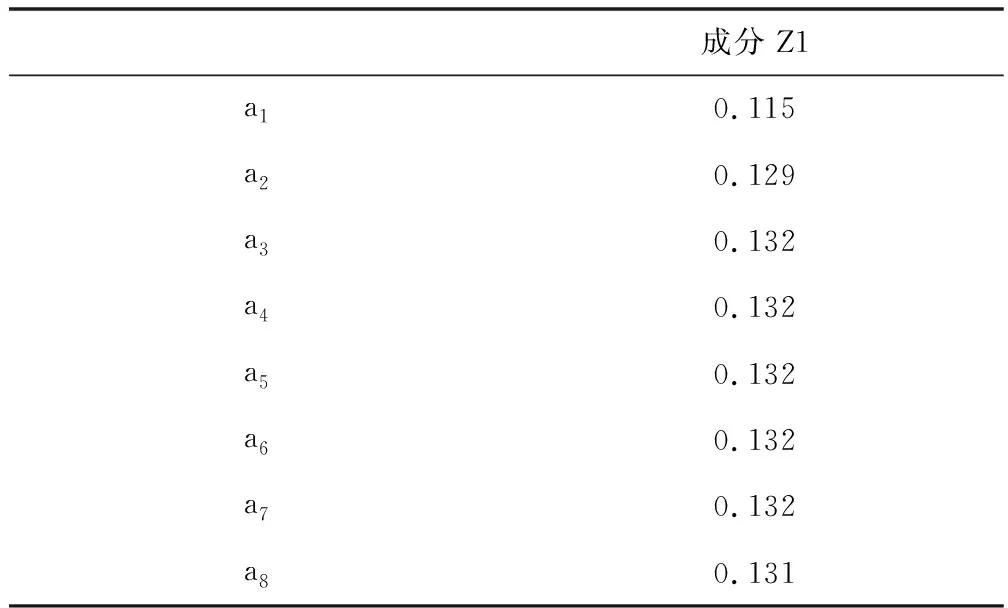
表10 成分得分系數矩陣
以同樣的方法對其他四個子系統進行主成分分析,得到如下結論:
機器子系統:
得到一個主成分Z2,各個變量在主成分中對應的系數如式(2):
Z2=0.068b1+0.120b2+0.12363+0.123b4+0.122b5+0.122b6+0.123b7+0.122b8+0.121b9
(2)
Z2由b2,b3,b4,b5,b6,b7,b8,b9所確定,可將b1剔除。
物料子系統:
得到一個主成分Z3,各個變量在主成分中對應的系數如式(3):
Z3=0.180c1+0.180c2+0.180c3+0.180c4-0.157c5-0.165c6
(3)
Z3由c1,c2,c3,c4所確定,可將c5,c6剔除。
管理方法子系統:
得到一個主成分Z4,各個變量在主成分中對應的系數如式(4):
Z4=0.125d1+0.130d2+0.130d3+0.126d4+0.125d5+0.130d6+0.130d7+0.130d8
(4)
Z4由d2,d3,d6,d7,d8所確定,可將d1,d4,d5剔除。
環境子系統:
得到一個主成分Z5,各個變量在主成分中對應的系數如式(5):
Z5=0.171e1+0.171e2+0.171e3-0.167e4-0.168e5-0.170e6
(5)
Z6由e1,e2,e3所確定,可將e4,e5,e6剔除。
這樣,經過主成分分析,將37個影響系統可靠性的因素簡化為26個。
3.3.2 隨機森林算法預測分析
如圖3所示的兩步法模型示意圖,在經過主成分分析法得到各個子系統的約簡指標后,第一步是針對人,機,料,法,環五個子系統,對每個子系統用隨機森林算法(RF)進行子系統評價值的預測。將收集到的100條數據(表7)分為兩個數據集,其中前50條數據(No.1~No.50)為訓練集,后50條數據(No.51~No.100)為測試集。模型的輸入為各子系統經主成分分析法簡化后的輸入節點,輸出為各子系統的評價值(即a,b,c,d,e)。
對于各個子系統,算法中的參數及訓練精度如表12所示,預測的各個子系統的評價值如表13所示。
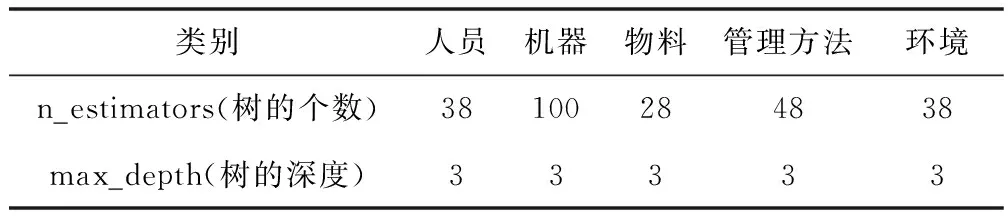
表11 第一步模型訓練參數
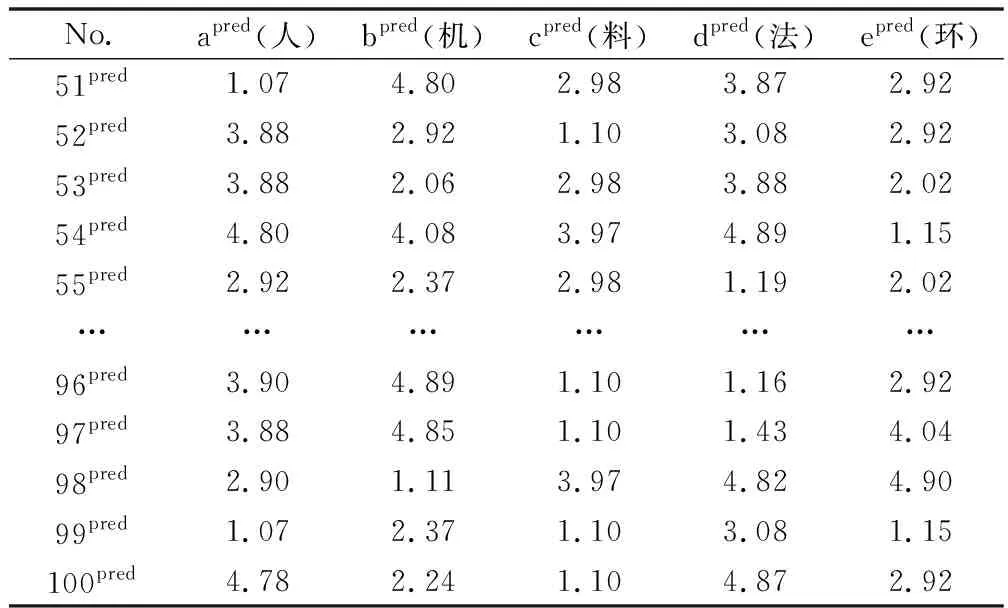
表12 各子系統評價值的預測值
將第一步得到的各個子系統評估值的50組數據,如表12所示,分為兩個數據集,其中前40條數據(51pred~90pred)作為第二步的訓練集,后10條數據(91pred~100pred)作為測試集,五個子系統評價值的預測值(即apred,bpred,cpred,dpred,epred)作為模型的輸入值,整個系統的可靠度為輸出值,采用隨機森林算法進行模型的訓練及預測。
第二步模型的參數及訓練精度如表13所示:

表13 第二步模型的訓練參數
為了進一步對比模型預測的準確性,劉文等人[10]提出的針對化工系統可靠性預測的兩步法GRA-GA-BP-MCRC模型將被用于對比研究。表14給出了兩種模型對系統可靠度預測值的對比分析。
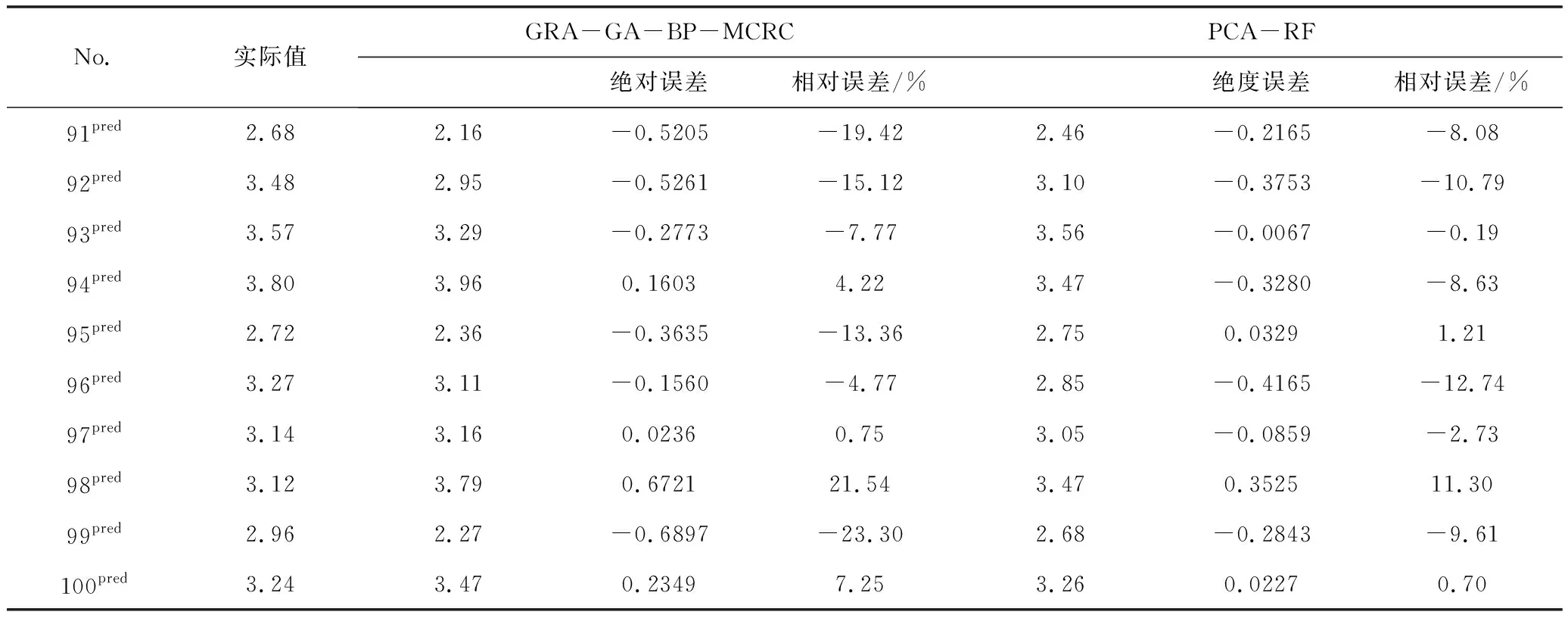
表14 兩種模型預測結果對比分析
根據表14可以看出,GRA-GA-BP-MCRC模型相對誤差絕對值的波動范圍為0~23.30%。PCA-RF模型相對誤差絕對值的波動范圍為0~12.74%,PCA-RF模型的相對誤差波動范圍要明顯小于GRA-GA-BP-MCRC模型的相對誤差波動范圍。將兩種模型的相對誤差繪制成折線圖,如圖6所示。由圖中也可以看出,兩步法PCA-RF模型相對誤差的波動范圍更小,模型具有更強的穩定性和預測精度。
為更進一步分析模型的預測結果,利用均方誤差(MSE)和平均相對誤差(MRE)來判斷結果的精確度。MSE和MRE越小,真實值和預測值相差越小,模型精確度越高。MSE和MRE的計算公式如下:
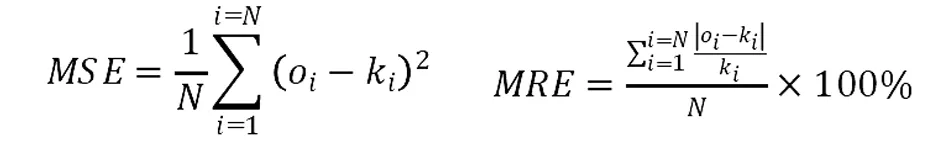
(6)
式中:ki實際值;oi是模擬值;N是數據總數。
表15~16分別給出了兩種模型對各個子系統和總系統的預測結果。
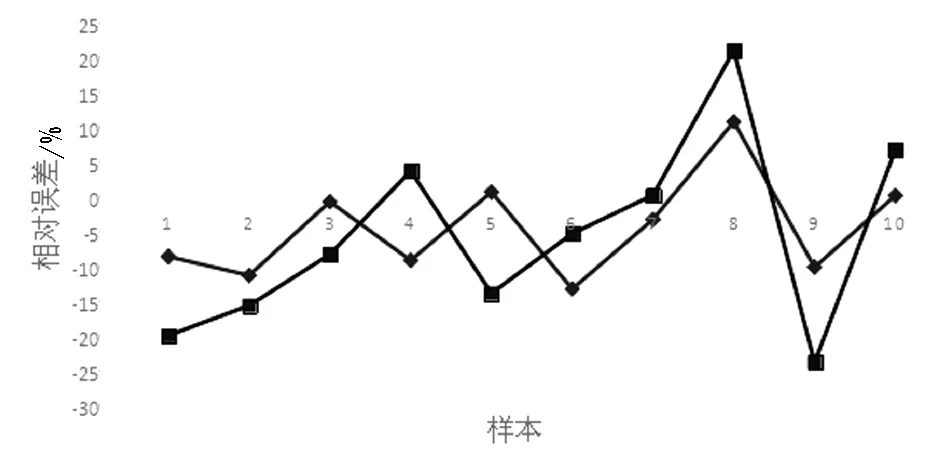
圖6 兩種模型的相對誤差折線圖

表15 GRA-GA-BP-MCRC模型預測精度分析

表16 PCA-RF模型預測精度分析
由表15~16可以看出,本文提出的兩步法PCA-RF模型比文獻中的GRA-GA-BP-MCRC模型具有更高的預測精度。對整個系統可靠度的預測,PCA-RF模型的MSE值為0.068,低于對比模型的MSE值0.131;PCA-RF模型的MRE值為6.60%,同樣低于對比模型的MRE值9.69%。因此,對于化工系統可靠性評估問題的研究,本文提出的模型不僅簡潔,而且具有更高的預測精度。
5 結論
本研究以復雜化工系統為研究對象,進行可靠性評估指標體系的分類和可靠性評估模型的構建,提出一種兩步法PCA-RF混合算法模型,該模型用于解決復雜化工系統的可靠性評估問題,并進行了案例的應用分析,主要結論如下:
(1)根據4M1E分類原則,將影響化工系統可靠性的因素分為五個方面,即人員、機器、材料、管理方法和環境,構建了化工系統可靠性評估的指標體系。
(2)利用主成分分析法進行數據預處理,除去影響因素小的指標,簡化模型,避免過擬合現象的發生。
(3)建立了兩步法PCA-RF模型。此模型在實例中較GRA-GA-BP-MCRC模型取得了良好的預測結果,平均相對誤差從9.69%下降到6.60%,均方誤差從0.131下降到0.068。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
