基于Python的BIC語音分割算法的實現與應用*
2020-06-18 09:07:34王方麗傅嘉俊
計算機與數字工程 2020年4期
王方麗 傅嘉俊
(華南理工大學廣州學院計算機工程學院 廣州 510800)
1 引言
目前,隨著網絡技術的發展,人們可以通過各種不同的途徑獲得各種視頻資源,但有些視頻資源少有翻譯版本,不利于學習和使用。因此,如果能夠對于視頻中的音頻進行直接翻譯并加載到視頻中,就能大大方便人們獲取和利用資源。要實現這一功能,主要是對于視頻中的音頻進行識別、分割和翻譯。語音分割是語音識別以及翻譯處理的基礎,很多語音分割技術都是基于BIC算法實現的,如運用改進型BIC算法對語音進行分割[1~3]、檢測說話人改變實現語音分割[4],綜合利用BIC及PSO[5]實現語音識別;文獻[6]以基于BIC的說話人分割系統作為基線系統,對比分析重疊語音檢測對說話人分割性能影響等。
本文主要采用基于貝葉斯信息準則的語音分割原理對于獲取的聲音資源進行分割,并運用Python技術實現相關的算法。在語音分割前,主要利用FFmpeg工具進行視頻的聲音提取;語音分割后,利用IBM接口實現語言識別和有道接口進行翻譯,最后字幕加載采用FFmpeg開源工具。
2 語音分割算法的研究
2.1 基于貝葉斯信息準則實現語音分割
音頻分割是指將音頻流分為若干片段,使得每個片段在內容類別上具有一致性[7]。基于BIC的分割方法不需要先驗知識,不需要設定門限閾值,且具有較好的準確度[8],因此被廣泛采用。貝葉斯信息準則作為一種常見的模型選擇準則[9],可用于判斷模型好壞。假設給定數據y={y1,y2,…yn},候選的模型集合為Mk={Mk1,Mk2,…MkL},并假設任一個候選的模型Mk都是有獨特的參數向量qk定義,定義如式(1)所示:

音頻分割也稱跳變點檢測[10~11],假設有一段語音對話,在第i時刻有一個跳變點,則可以把連續的高斯過程和有跳變點的高斯過程這兩個假設模型進行選擇的問題作為跳變點問題的等價問題,采用獨立多變量高斯分布描述這兩個模型的語音信號的特征序列,如式(2)和式(3)所示:

其中:xi∈Rd(i=1,2…N,是觀測數據),N是多變量高斯模型,m和S是該模型的參數,d是特征向量維數。使用貝葉斯信息準則進行判斷,如果第一個模型的概率比第二個模型概率大表明該語音在第i時刻無跳變點,反之則表明該語音在第i時刻存在跳變點。
假設跳變點存在,那么對應的對數最大似然比為式(4):
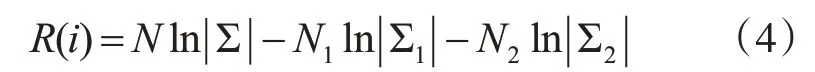
其中,Σ是所有數據的協方差矩陣,Σ1是開始時刻到第i時刻的數據集{x1…xi}的協方差矩陣,Σ2是第i時刻后的數據集{xi+1…xN}的協方差矩陣。符號 ||Σ代表矩陣Σ的行列式。
比較兩個模型:一個模型的數據符合兩個高斯過程,另一個模型的數據只符合一個高斯過程。它們之間的不同通過對貝葉斯信息準則添加懲罰項來修正,得到貝葉斯信息準則值的計算,見式(5):

其中,R(i)是上面定義的對數最大似然比,懲罰項的權重λ一般取為1,而P為式(6):

式(5)與式(1)相比,有一個-1/2的系數,因此問題解決的關鍵從求解貝葉斯信息準則值的極小值變為極大值,即式(7):

利用Python[14]實現貝葉斯信息準則計算主要采用語音的Mel頻率參數進行,該參數可以用矩陣表示。當獲得該參數時,先計算該段語音的Mel頻率矩陣的平均協方差矩陣和最小值。得到這些參數后,先對整個語音段進行遍歷,選出模型的分割點(可能不存在分割點),再將整個語音段按照一個步數進行劃分(如該語音段長50,以步數5進行劃分則分成10個部分)。對這些部分進行遍歷,假設遍歷到第i段,則將語音端分成part1和part2兩個部分,再分別計算它們的似然矩陣det1和det2,再計算貝葉斯信息準則量,最后將該貝葉斯信息準則量存到一個數組x中,Python實現如下:

遍歷完成,就得到一個根據指定步數對語音端劃分的貝葉斯信息準則量數組,由貝葉斯信息準則量越大則越大幾率符合該模型的定理可以知道,只需要對該數組求最大值就能判斷出語音端的說話人分割點。
2.2 語音多點分割
對語音進行多點分割時,先設置一段窗口范圍作為語音的檢測窗口,通過這個檢測窗口對語音進行貝葉斯信息準則量的計算。如果在這一段存在分割點,記錄分割點位置,移動檢測窗口檢測下一部分;如果不存在分割點,則調整檢測窗口的大小繼續檢測。一直重復上述過程直到這段語音檢查結束,最后輸出該語音段的分割點位置數組。該算法偽代碼如下:
輸入:該語音段的Mel頻率倒譜系數矩陣Mel=[mij]
輸出:通過貝葉斯信息準則計算的該語音段分割點數組[r1,r2,…,rn],
1)初始化檢測窗口,設置為[wStart,wEnd]。
2)在[wStart,wEnd]這個時間段內運用貝葉斯信息準則算法檢測是否有分割點。
3)根據2)計算的貝葉斯信息準則量進行判斷:
(1)如果值大于0,存在分割點,記錄該分割點位置wStart+BICioc,調整檢測窗口位置。
(2)如果值小于等于0,則不存在分割點,則增大檢測窗口。
重復2)、3)步直至語音段檢測完畢,算法結束,輸出該語音段的分割點位置數組。
2.3 使用語音活性檢測對分割點進行篩選
語音活性檢測(Voice Activity Detection,VAD)是對連續帶噪語音信號進行檢測,準確地定位語音的起止位置,其檢測結果直接影響著語音識別效果[15]。將語音進行分割后,可能會把一些靜音的語音端也切割處理,此時就可以運用語音活性檢測進行分割點的篩選。
假設一段由四個說話段組成的語音,使用貝葉斯信息準則計算語音分割點,結果如圖1所示。貝葉斯信息準則基本上可以將這段語音完美的分割,但是它把語音開頭的靜音部分也進行了切割,實際上不需要將該段靜音段切割開來,這樣反而增添了后續處理的復雜度。因此,就需要使用語音活性檢測對分割點進行篩選,將靜音的分割點去除,使貝葉斯信息準則計算出的分割數組更符合實際應用情況。

圖1 貝葉斯信息準則語音分割點示例

圖2 語音活性檢測處理過的語音分割點示例
語音活性檢測過程如下:先運用BIC計算分割點,再使用語音活性檢測檢測每段劃分的語音,如果語音活性檢測檢測不到有語音端點,則剔除該分割點;如果語音活性檢測檢測到有語音端點,則保存該分割點不做處理。對圖1中的語音經過語音活性檢測處理過的語音分割點數組如圖2所示,對比沒有進行語音活性檢測的分割點數據,進行了語音活性檢測的分割點數組更加貼近實際,更具有使用價值。
3 算法實現與應用
3.1 視頻語音翻譯流程
視頻語音翻譯流程如圖3所示,其中,視頻轉換是采用開源工具FFmpeg提取原視頻的語音文件;語音分割利用第二部分算法對于語音段分割;語音識別是將分割后的每一段小語音都采用IBM的語音轉文字接口進行語音的識別,將語音轉換成文本;語音翻譯則是把上一階段識別出來的語音文本采用有道的外文翻譯接口進行翻譯;字幕加載使用FFmpeg工具實現,字幕加載的時間長度取決于分割的語音段長度。

圖3 語音翻譯流程
3.2 語音分割實現
語音分割的核心是運用貝葉斯信息準則判斷說話人的語音分割點,該算法可以判斷說話人的停頓點并將一段長語音分割成多個完整的、短小的說話人語音,具體過程如下:首先對文件進行處理,通過librosa庫的load方法獲取音頻文件的時間級數和y,然后根據該級數和通過librosa庫來提取Mel頻率矩陣;接著使用speech_segmentation來獲取分割點數組seg_point;由于該數組是非時域的,再將數組乘以步長后進行適當的填充,最后的結果才是語音時間域上的分割點數組。
獲取最終分割點數組seg_point后,再對該數組進行語音活性檢測,代碼如下:
for i in range_loop://range_loop為數組長度-1
temp=y[seg_point[i]:seg_point[i+1]]//相鄰分割點之間的時間級數
#計算vad判斷是否為空白點
x1,x2= vad.vad(temp,sr=sr,frame_size=frame_size,frame_shift=frame_shift)
if len(x1)==0 or len(x2)==0:continue//靜音段不處理
else:output_segpoint.append(seg_point[i+1])
最后輸出的數組output_segpoint就是剔除靜音段后的語音分割點數組。
3.3 語音識別模塊
語音識別采用IBM接口實現,使用開源項目speech_recognition(集結了主流的語音識別接口并提供統一的Python調用方法),調用該接口算法的偽代碼如下:首先要實例化一個speech_recognition的對象;接著用speech_recognition框架里的Wav-File方法獲得文件的數據源;再通過speech_recognition的對象調用record方法將音頻文件的數據源轉換成audio類型對象;最后使用speech_recognition對象的recognize_ibm方法來調用IBM的接口方法即可。該接口會以字符串的格式直接返回翻譯好的譯文。
3.4 語音翻譯模塊
語音翻譯是采用有道接口實現的,Python實現如下:
data=get_url_encoded_data(query_text)//獲 取url編碼過的數據
target_url=url+‘?’+data//構造目標url
request=re.Request(target_url,headers=headers)//構造請求
response=urlopen(request)//發送請求
return parse_html(response.read())//解析,顯示翻譯結果
其中get_url_encoded_data方法是將待翻譯文本進行重新編碼,將編碼文本與接口路由拼接獲得target_url,之后使用request庫生成一個url訪問對象,然后使用urlopen方法通過該對象發送請求獲得接口的請求回復response,然后解析該結構就可以得到翻譯后的文本。
3.5 功能測試
對于該語音分割算法測試如下:
第一步,進入窗口界面,選擇需要識別的視頻(支持MP4、AVI格式),然后可以開始進行轉換。
第二步,轉換過程中,進度條會顯示轉換進度,等待一段時間后,系統完成工作。
第三步,查看視頻,即可看到已經將翻譯后的字幕加載到視頻中。
通過實際測試,該項功能能夠正常使用,字幕可以正常翻譯成中文,且字幕加載時長與實際說話人時長一致。根據實際的需要,運用其他的翻譯接口,可以對于其他種類的語音資源進行翻譯和字幕加載。
4 結語
本文主要研究了基于貝葉斯信息準則的語音分割算法。同時,結合語音識別、翻譯等技術,將該算法運用于具體的實踐中,用以解決視頻語音翻譯中語音分割和視頻字幕加載時間長度的確定。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
