基于優化聚類的IXGBoost短期電力負荷預測*
2020-06-18 09:07:20任利強張立民王海鵬
計算機與數字工程 2020年4期
任利強 張立民 王海鵬 郭 強
(海軍航空大學信息融合研究所 煙臺 264001)
1 引言
短期負荷預測(short-term load forecasting,STLF)是電力系統負荷預測的重要組成部分,也是智能電網建設的基本環節之一[1]。STLF的主要應用是為機組組合和經濟調度提供負荷預測[2]。例如,如果預先知道負荷需求,便可以用盡可能低的成本運行發電機,從而提高發電廠的經濟效益。STLF的第二個應用是電力系統的安全評估。此外,短期負荷預測結果有助于實現節能減排和環境保護的目標。
目前,STLF方法可分為經典方法、人工智能方法和機器學習方法三類。經典預測方法基于數學模型,包括時間序列方法、回歸分析方法等[3],經典預測法是一種簡單的線性方法,對于具有非線性特性的電力負荷預測精度不夠。人工智能方法主要有神經網絡、極限學習機等,文獻[4]提出一種利用主成分分析法簡化BP神經網絡結構的短期電力負荷預測方法,該方法具有較快的學習速度。機器學習方法主要有支持向量機、隨機森林等,文獻[5]提出一種利用小波變異果蠅算法優化支持向量機模型參數的短期負荷預測方法,預測精度得到了明顯提高;文獻[6]基于Spark平臺對隨機森林算法進行并行化處理,該算法在短期電力負荷預測時間上具有明顯的優勢,但無法保證預測的精度。隨著智能電網的發展,電網中可獲取的數據類型和數據量迅速增漲。上述方法在處理大規模、復雜多樣的數據時不能兼顧預測速度和精度,具有一定的局限性。近年來,新提出的極限梯度提升(XGBoost)機器學習算法計算速度快、準確性高。目前,在生物醫學工程和經濟金融等領域都有良好的性能[7~8]。文獻[9]使用XGBoost算法建立短期電力負荷預測模型,預測精度和速度均有明顯地提高。然而,該文獻未考慮實際應用對象,直接將XGBoost算法應用于短期電力負荷預測,且對負荷樣本集的預處理工作研究較少,預測精度有待進一步提高。
針對上述問題,提出一種基于優化K-means聚類的改進XGBoost短期電力負荷預測方法。采用改進模擬退火遺傳(Improved Simulated Annealing and Genetic Algorithm,IGASA)算 法 優 化 的K-means算法對電力負荷樣本進行分類,并利用改進的XGBoost(Improved Extreme Gradient Boosting,IXGBoost)算法對不同類別的負荷樣本建立短期電力負荷組合預測模型。使用某市實測電力負荷數據進行負荷預測實驗,以檢驗本文方法的有效性和準確性。
2 基于IGASA優化的K-m eans聚類
相似屬性因素下負荷曲線具有相似性,為了進一步提高負荷預測的準確性,利用K-means算法對電力負荷樣本進行聚類分析。由于K-means算法隨機地選擇初始聚類中心,容易陷入局部最優解,影響聚類質量[10]。因此,采用IGASA算法搜索K-means的全局最優初始聚類中心點。
2.1 K-means聚類算法原理
K-means算法根據聚類的個數c隨機地選擇c個樣本點作為初始聚類中心,通過計算剩余樣本和聚類中心的距離,將樣本劃分到距離其最近的類中,之后根據聚類的結果更新聚類的中心點[12]。
K-means的目標函數定義如下:

式中,xi是第i個樣本點,cj是第j個聚類的中心,d(xi,cj)是樣本點xi到其聚類中心cj的距離。
聚類中心的計算公式為

式中,c*j是更新后的第j個聚類的中心,nj是第j個聚類中的樣本數。
K-means算法通過不斷地迭代計算d(xi,cj)和cj,使得目標函數值趨向于最小。
2.2 IGASA優化K-means聚類算法設計
遺傳算法(Genetic Algorithm,GA)是一種結合生物進化與隨機交換理論的自適應搜索全局最優解的群體智能優化算法[12]。模擬退火(Simulated Annealing,SA)是一種通過模擬高溫物體退火過程,并利用Metropolis接受準則避免算法陷入局部最優陷阱的優化算法[13]。GA具有全局搜索能力強的特點,但其局部搜索能力弱,易于陷入局部最優解;SA局部搜索能力強,能夠避免陷入局部最優的解,但其全局搜索能力差[14]。IGASA方法結合了GA和SA各自的優勢,不僅可以克服遺傳算法易于陷入局部最優的缺點,而且能加快算法收斂到全局最優解的時間。
2.2.1 算法步驟
IGASA優化K-means聚類中心算法具體步驟如下。
1)初始化參數。
假設將m維負荷樣本聚類為c類,首先初始化種群大小為n=10,種群中個體染色體的長度為c×m,設置最大進化的代數gmax=100,退火溫度T0=100,終止溫度Tend=1,冷卻系數α=0.95。
2)定義適應度函數。
隨機產生c個聚類中心并生成初始種群,計算種群中個體的適應度值,其中,適應度函數定義如下:

式中,J為式(1)定義的K-means聚類算法的目標函數,Jmax為算法定義的目標函數最大值,T為當前溫度。
該適應度函數可使種群中個體之間的差異(適應度值的差異)隨退火溫度的減小而降低,從而增加溫度降低時選擇適應度較小個體的概率,確保了種群中個體的多樣性,有效地提高了算法從局部最優中跳出的能力。
3)初始化進化代數g=1。
4)通過選擇、交叉和變異操作,更新個體的染色體。
使用輪盤選擇方式對個體進行選擇,將適應度高的個體保留,適應度低的個體丟棄,使種群進化向適應度高的方向發展[15]。隨機地對選擇的個體進行組隊,以式(4)定義的交叉概率Pc對個體進行自適應的交叉操作,接著以式(5)定義的變異概率Pm對個體進行自適應的變異操作。

式(4)和式(5)中,fmax和favg分別是群體中的最大適應度值和平均適應度值,f′是交叉時較大適應度個體的適應度值。
上述自適應交叉變異策略可使Pc和Pm隨著適應度值的變化而變化,即適應度值較高的個體具有較低的Pc和Pm,從而將該個體得以保留,而適應度值較低的個體具有較高的Pc和Pm。該自適應方法確保了GA算法的收斂特性和種群的多樣性。
5)生成新的種群,計算新種群中子代個體適應度值。
6)對新種群的個體進行模擬退火操作。若新種群子代中第i個個體適應度值fi′大于父代中第i個個體的適應度值fi,則用子代個體替換父代個體;否則,以Metropolis規則,即式(6)定義的概率P接受子代個體,丟棄舊的個體。

7)循環。若g<gmax,則g=g+1,轉到步驟4);否則,轉到步驟8)。
8)若Ti<Tend,則算法結束,輸出全局最優解;否則,進行降溫處理,Ti+1=αTi,轉到步驟3),α為冷卻系數。
2.2.2 算法流程
IGASA優化K-means聚類中心算法詳細流程如圖1所示。
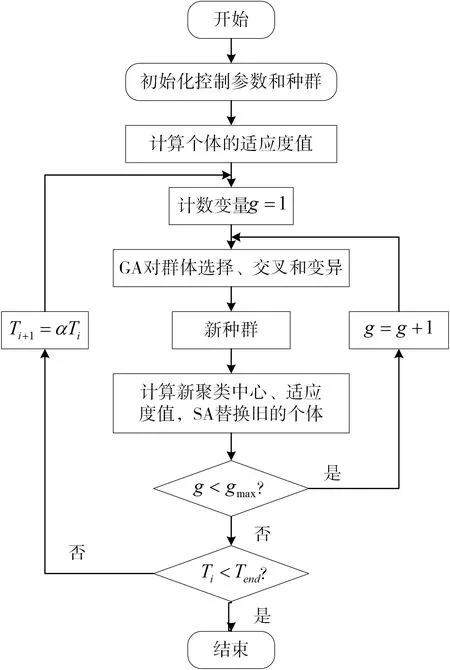
圖1 基于IGASA優化K-means聚類算法流程圖
3 優化XGBoost電力負荷預測
3.1 IXGBoost算法
XGBoost(extreme gradient boosting)是一種基于梯度提升回歸樹的改進算法[16]。該算法不僅具有傳統Boosting算法精度高的優點,而且能夠高效地處理稀疏數據,靈活地實現分布式并行計算。因此,XGBoost算法適用于大規模數據集。此外,XGBoost在損失函數中加入了正則項,用以控制模型的復雜度和降低模型的方差,使學習到的模型更簡單,防止了過度擬合風險。XGBoost在確保一定計算速度的情況下提高了算法精度。
XGBoost算法通過建立一系列決策樹并為每個葉節點分配一個量化權重來實現對目標變量的估計。對于具有n個樣本和m個特征的給定數據集,假設XGBoost模型有K個決策樹,則電力負荷預測模型為


式中,q(xi)表示將xi映射到對應葉子節點的第k個決策樹的結構函數,ω是葉子結點的量化權重向量(即葉子分數),T是樹中葉子節點的數量。
XGBoost算法在損失函數中加入正則化項,同時考慮了模型的準確性和復雜性。通過最小化公式(9)的損失函數來學習預測模型。

考慮到電網短期負荷變化特點和負荷預測中極值點預測誤差較大,可以用極大和極小值負荷來修正負荷的預測值。具體而言,根據電網負荷需求特點,當前負荷需求與前一天的負荷需求具有極大相似性和繼承性,此外,前一天負荷需求的極大與極小值對當前負荷的預測具有指導作用。因此,本文在XGBoost原有損失函數的基礎上引入式(10)懲罰函數,構建改進XGBoost(improved extreme gradientboosting)電力負荷預測模型:

式中,yi,min和yi,max是負荷對應的前一天的極大和極小值負荷,α1和α2是調節懲罰函數效應的系數。根據式(11),如果,的值小于1。此外,通過適當地調整參數α1和α2,當在區間(yi,min,yi,max)內,p的值可以被忽略。在區間(yi,min,yi,max)外時,p變得非常大。在此,設置α1和α2的值分別為2和0.0001。
IXGBoost算法通過最小化式(11)增加懲罰項的損失函數來學習負荷預測模型。

基于上述IXGBoost算法訓練短期電力負荷預測模型。
3.2 構建IXGBoost電力負荷預測模型
采用IXGBoost算法進行短期負荷預測,具體流程如圖2所示。
具體步驟如下。
1)數據采集及預處理。電力負荷受歷史負荷、氣象因素、日期類型等多種因素影響。本文采集歷史負荷因素,包括前一天負荷、前一天負荷極值;氣象因素,包括濕度、溫度、風速、降雨量、氣壓;日期類型因素,包括小時、星期、月份、節假日等數據集進行負荷預測。根據文獻[17],歷史負荷和氣象因素具有持續性效應,選擇與這些因素較相關的前四個時刻值以及日期類型,總計32維電力負荷屬性特征進行負荷預測。
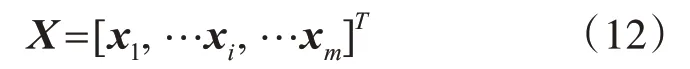
式中,X是電力負荷屬性特征集;xi是第i個屬性特征矩陣;m=32是屬性特征的數量。
為了避免由于數據采集誤差、設備的故障和干擾噪聲等因素引起的樣本數據缺失或者異常,在預測前對數據集進行預處理[18]。本文利用最近臨插補法對采集到的原始數據集中缺失和異常的數據點進行填補和糾正。
由于各屬性的物理單位不同,不同屬性的數值相差較大,影響預測結果的精度。因此,對數據集進行如下歸一化處理:

式中,xi為原始數據;x′為歸一化后的數據,其取值范圍是[0,1]。
2)特征選擇。負荷預測中使用過多的特征變量會增加模型的復雜度和訓練時間,從而影響預測結果的準確性。因此,參考文獻[19]使用最大相關最小冗余(maximum relevance minimum redundancy,MRMR)算法對步驟1)采集到的負荷屬性特征進行選擇,以減少數據中的冗余信息,提高預測精度。
3)負荷樣本聚類。根據第二節,利用IGASA優化的K-means聚類算法對負荷樣本進行聚類分析,將相似特征屬性的負荷樣本劃分為一類。
4)建立IXGBoost負荷預測模型。采用IXGBoost算法對每個類別的電力負荷樣本集建立負荷預測模型,得到組合預測模型。
5)負荷預測結果反歸一化處理。根據式(14)對該預測結果進行反歸一化處理:
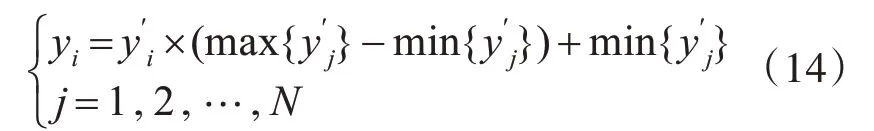
式中,y′i是i時刻的預測值;yi是i時刻反歸一化的預測值;N是預測樣本數量。

圖2 短期電力負荷預測流程圖
4 算例分析
本文數據集來源于某市2013-2017年實測電力負荷數據和相應時間的氣象數據,數據的采樣間隔為1小時。實驗選取2013年至2016年數據為訓練集,對35012個樣本進行分析,建立電力負荷預測模型,對應預測模型每次輸出未來一天24小時的負荷值。選取2017年數據為測試集,以測試模型的預測性能。本文經特征選擇后的輸入變量如表1所示。

表1 輸入變量描述
4.1 評價指標
采用平均絕對百分比誤差(MAPE)和平均絕對誤差(MAE)作為誤差評估標準來分析預測結果的準確性。

式中,Yi表示真實值,表示預測值,n為預測時間點數。MAPE越小,預測結果越準確。
4.2 實驗結果與分析
采用交叉驗證算法確定K-means算法的聚類個數c=4,利用IGASA優化的K-means算法對訓練樣本進行聚類分析,聚類劃分結果如表2所示。
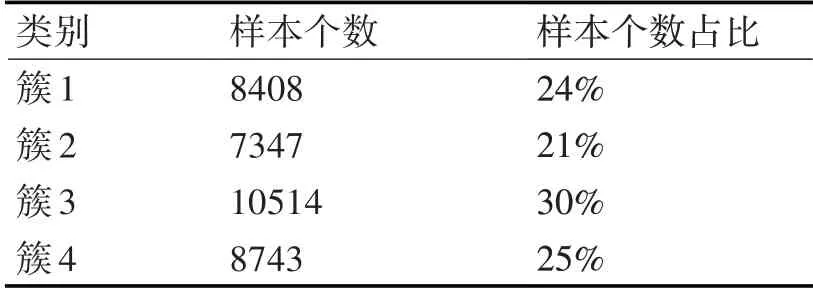
表2 聚類結果
為了測試IXGBoost模型的預測效果,在相同實驗條件下,采用梯度提升回歸樹(GBRT)模型和傳統XGBoost模型作為對比進行電力負荷預測,選取該市2017年2個具有代表性的日期進行實驗分析。圖3顯示了上述各模型的負荷預測結果。
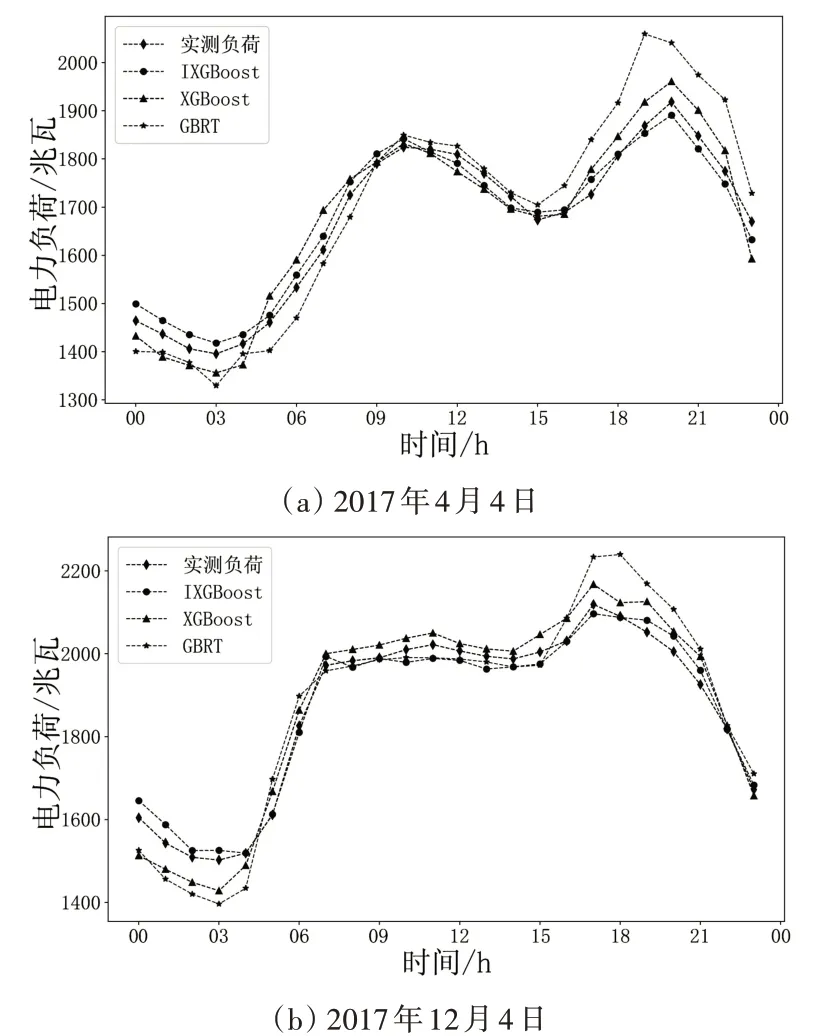
圖3 不同模型預測結果對比
從圖3可觀察到,當電力負荷的變化較平緩時,如圖3(a)的09:00-14:00與圖3(b)中的07:00-14:00,三種模型的預測曲線和實際負荷曲線較為接近。然而,在電力負荷波動較大的極值點附近,如圖3(a)的16:00-22:00與圖3(b)中的0:00-06:00、16:00-21:00,GBRT和XGBoost模型的負荷預測值與實際負荷值相差較大,而IXGBoost模型的預測結果更接近實際負荷值。
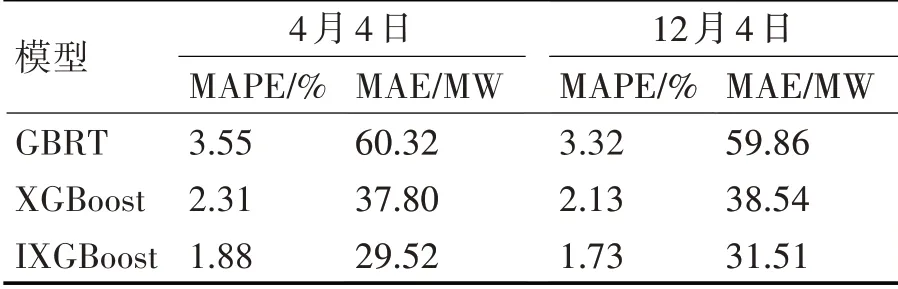
表3 不同模型預測結果誤差對比
表3顯示了上述各模型的預測誤差,從對比結果可以看出,與GBRT模型相比,XGBoost模型具有較小的預測誤差。IXGBoost在傳統XGBoost損失函數中加入懲罰項,提高了模型在負荷波動較大的極值點附近的預測性能。預測誤差結果表明,與XGBoost和GBRT模型相比,IXGBoost模型具有較高的預測精度。
分別采用聚類IXGBoost(KM+IXGBoost,方法1)、GA優化聚類IXGBoost(GA+KM+IXGBoost,方法2)和IGASA優化聚類IXGBoost(IGASA+KM+IXGBoost,方法3)進行電力負荷預測。上述三種法方法預測結果的曲線如圖4所示,預測結果的誤差見表4。

圖4 不同預測模型結果對比
從圖4可看出,在電力負荷變化不明顯期間,如圖4(a)的09:00-13:00與圖4(b)的07:00-15:00,三種方法負荷預測結果都可以較好地擬合實測負荷的變化趨勢。但在電力負荷變化比較劇烈的時期,如圖4(a)的15:00-21:00與圖4(b)中的16:00-21:00,方法3比方法1和方法2具有更好的預測性能。此外,從圖4與表4能夠看出,方法2的負荷預測準確度高于方法1。這是因為與方法2相比,方法1隨機地選擇K-means的初始聚類中心。方法3相較于方法2不僅改進了遺傳算法的適應度函數和交叉變異算子,而且引入模擬退火算法克服了遺傳算法易陷入局部最優的缺點,使算法快速收斂到全局最優解。實際預測結果表明方法3具有較低的預測誤差。

表4 不同模型預測結果誤差對比
利用方法3預測該市2017年小時用電負荷(以12月為例),結果如圖5所示。對2017全年電力負荷預測誤差進一步分析,MAPE為1.93%,MAE為34.13MW,結果表明本文提出的方法可以有效、準確地預測短期電力負荷的變化規律,能滿足實際應用需求。

圖5 12月份電力負荷預測值與實測值對比
5 結語
本文以電網實測大數據為基礎,提出一種基于優化K-means聚類的IXGBoost短期電力負荷預測方法。該方法采用改進適應度函數和交叉變異算子的模擬退火算法優化K-means的初始聚類中心,有效解決了遺傳算法局部尋優的問題,使算法快速收斂到K-means全局最優初始聚類中心。基于K-means聚類結果,利用改進XGBoost算法建立電力負荷組合預測模型,并根據不同的屬性特征使用不同的預測模型,提高了電力負荷預測模型的準確度。實驗結果證明了本文方法在短期電力負荷預測實際應用中的有效性和準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
