基于完備抓取構型和多階段網絡的軟體手抓取
2020-06-08 06:34:24劉文海王偉明
上海交通大學學報 2020年5期
關鍵詞:深度
劉文海,胡 潔,王偉明
(上海交通大學 機械與動力工程學院, 上海 200240)
機器人抓取是機器人操作的重要組成部分,也一直是機器人研究的重點.傳統剛性手爪的抓取已廣泛應用于各行各業,用來執行工業場景中重復的、笨重的和較為結構化的任務.而對于外形可變和表面易碎物體的分揀和抓取,軟體手顯現出了更高的柔順性[1].同時,這些工作環境往往是非結構化的,相比于固定的工業環境,具有更多不確定性,例如物體種類以及物體表面的柔軟程度.因此,如何提高軟體手抓取的自主性和智能性便成為一項極為重要的課題.
近年來,隨著深度學習的發展,越來越多的研究將深度學習應用在基于視覺的抓取規劃中[2].這種方法通過擬合從感知到抓取的直接映射來自動提取預示穩定抓取的特征,對未知物體同樣具有良好的泛化性,這一類方法的關鍵是將抓取規劃問題轉化成深度學習能解決的分類或者回歸問題,同時搜集大量與模型輸入輸出相對應的有標簽數據.Lenz等[3]首次將深度學習應用在二指手的抓取規劃中,并開源了其模型對應的抓取數據集.Redmon和Kumra等[4-5]在其開源數據集的基礎上分別通過改進網絡結構和采用具有更優異分類性能的深度殘差基網絡(ResNet-50),提高了抓取檢測的準確性和速度.Liu等[6]針對散堆多物體的機器人分揀提出用于吸盤的吸附點檢測網絡.Zeng等[7]則提出了與物體類別無關的全卷積抓取檢測網絡.以上研究主要針對二指夾手和吸盤等剛性手爪,而將深度學習應用在軟體手爪抓取規劃的研究則相對較少.多指軟體手的抓取大多停留在已知物體位姿抓取或者人工操作的水平[8].這是因為視覺引導的軟體手抓取需要視覺提供更多抓取預測量,例如軟體手的穩定抓取除了像吸盤需要準確的抓取位置預測.除此之外,還需要考慮軟體手的開合角度、抓取深度和寬度的影響,完備的抓取構型是實現軟體手抓取的關鍵.
本文針對視覺引導的4指軟體手的自主抓取,提出一種新的基于深度學習的抓取檢測方法,利用網絡結構VGG16上分別提取彩色圖和深度圖的卷積特征,并在融合層融合輸出多模特征圖,以多模特征圖為基礎設置預測錨點,并級聯抓取預測網絡,分別輸出抓取質量、抓取角度和抓取深度預測.最后,構建軟體手抓取數據集,對比分析影響抓取預測準確性的因素,并通過抓取實驗驗證本方法的有效性.
1 抓取規劃問題描述
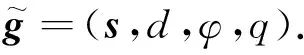
綜上,圖像空間的抓取表示可通過下式轉換到世界坐標系:
(1)
式中:RTC為攝像頭坐標系到機器人坐標系的坐標轉換,由攝像頭外參標定可得;f為2維圖像坐標到3維攝像頭坐標系的轉變,由攝像頭內參標定可得.
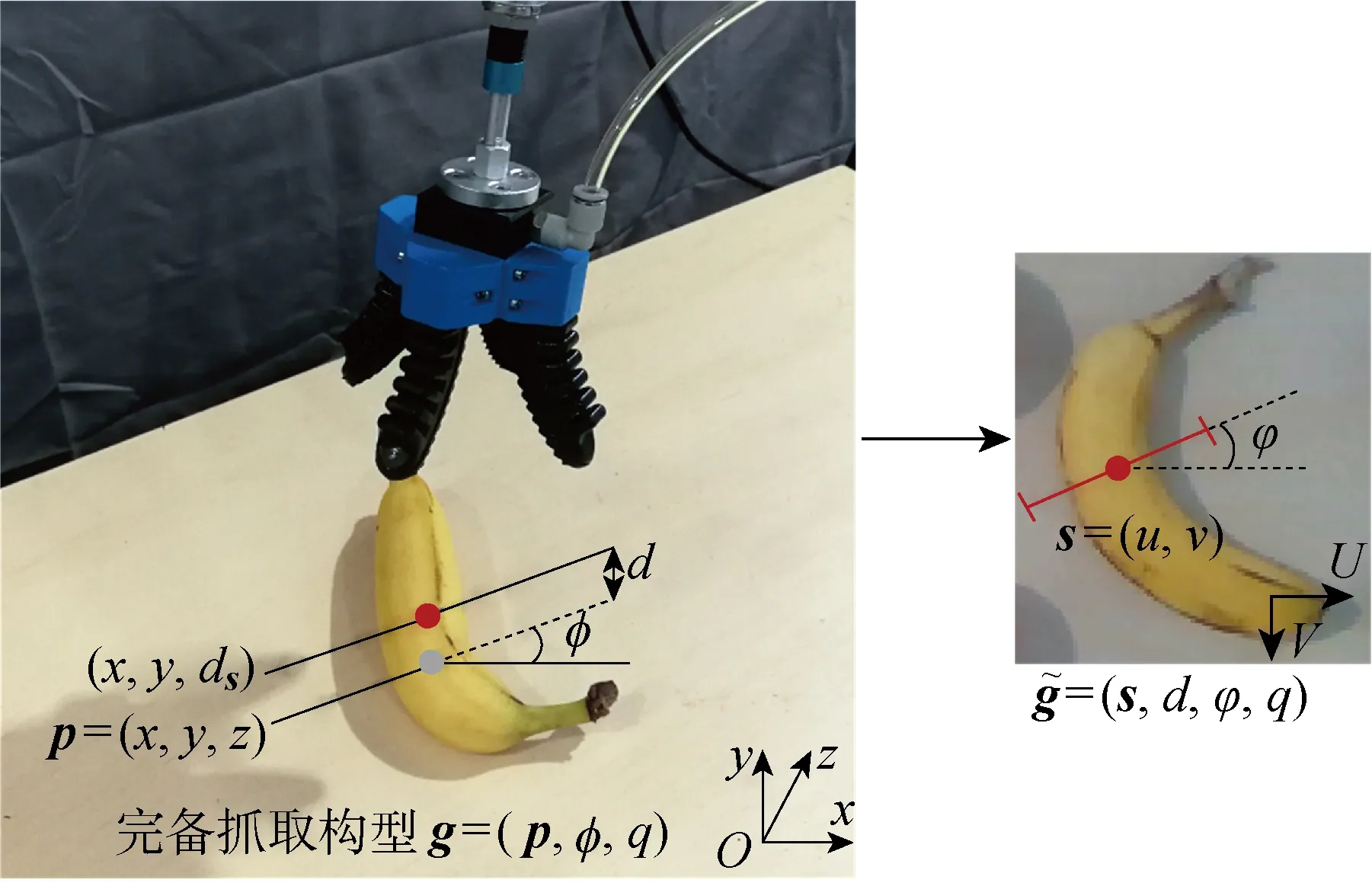
圖1 軟體手的4維抓取構型表示Fig.1 4-dimension grasp configuration of soft gripper
2 抓取規劃方法
圖像空間到抓取指令的映射需要滿足穩定抓取準則,這依賴于抓取標簽的有效構建,抓取標簽的標記過程見下文2.2.這種映射可直接采用深度網絡模型進行學習擬合,即Mθ:I→G,其中:Mθ為參數化的網絡模型;θ為網絡參數矩陣.學習的過程是基于有標簽抓取的數據S:IT→GT,以多任務損失函數L作為誤差函數的學習映射Mθ(I)=G的參數θ,即
(2)
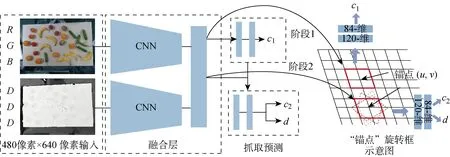
圖2 網絡模型與“錨點”旋轉框Fig.2 Network architecture and anchor based rotating block
2.1 “錨點”旋轉框與多階段網絡模型
根據上述完備抓取構型,為學習從圖像空間到抓取指令的映射,提出一種基于“錨點”旋轉框的多階段抓取檢測網絡,整體結如圖2所示.網絡組成包括卷積神經網絡(CNN)特征融合層和抓取預測層.特征融合層使用VGG16網絡作為特征提取網絡.網絡分別以480像素×640像素大小的彩色圖像和深度圖像作為單模態輸入網絡.其中,彩色圖像包含R、G、B3個通道,深度圖像擴展為D、D、D3個重復通道.特征提取網絡分別生成通道為512、大小為15像素×20像素的單模態特征圖,特征圖進行通道疊加后銜接3×3卷積層完成特征融合,最終形成512通道的融合特征圖.抓取預測層分為2個階段:第1階段進行抓取點的二值分類,預先選出可抓取的候選點;第2階段在候選點進行抓取角度分類和抓取深度回歸.受文獻[11]的啟發,特征融合層與抓取預測層的連接采用基于“錨點”的滑動網絡形式,如圖2右側所示.每個“錨點”是融合特征層滑窗的中心點,滑窗大小設置為2像素×2像素.因此,第1階段在每個“錨點”處判斷是否為可抓取點.第2階段以第1階段為基礎,選出第1階段預測概率最大的m個“錨點”(此處m取為5)進行角度分類和抓取深度回歸,即以“錨點”為中心,以90°/N的角度旋轉N次(N為角度旋轉次數,此處N取為9)獲得N個滑窗.這相當于將R、G、B和深度圖分別旋轉N次后送入融合卷積層得到N個對應“錨點”位置的特征窗.若抓取角度經過旋轉變為0° 或者180°,則此時特征窗的抓取角度類別為可抓取,其他特征窗為非可抓取.抓取預測網絡的2個階段均采用全卷積形式,這種滑動網絡相當于依次進行2×2以及 1×1 卷積操作,最后在階段1輸出15×20大小的抓取二值分類c1,階段2在階段1的基礎上計算m×N個滑窗的角度分類c2和抓取深度d回歸.所有的卷積激活函數采用Relu函數,抓取預測分類采用 Sigmoid 激活函數,回歸預測采用線性激活函數.
2.2 模型訓練與旋轉數據增強
由于卷積操作是一種參數共享的模型,可看作是15×20個全卷積小網絡的計算.所以其訓練過程可看作簡化模型的訓練,同樣分為2個階段的網絡訓練,如圖3所示.其中:Conv為卷積層;CB為卷積模塊.階段1是二分類,階段2是角度分類和抓取深度回歸,模型輸入為64像素×64像素圖像塊.
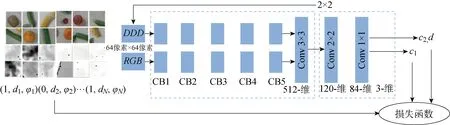
圖3 模型簡化與訓練Fig.3 Model simplification and training
抓取預測層的輸入是前層特征圖2×2滑窗的卷積,轉換到圖像空間即是64像素×64像素的圖像塊.因此,簡化模型的輸入變為64像素×64像素的圖像塊.這種轉變得益于特殊的抓取網絡設計,且有利于進行樣本增強,更容易訓練.整個多階段網絡模型參數個數為3.44×107.訓練采用Adam優化方法,基于Keras框架,訓練平臺包含2塊GTX 1080Ti GPU,整個訓練時間為0.5 h,15×20個錨點的整體預測時間為850 ms.
目前,有多個公開抓取數據集可用于抓取檢測網絡訓練,包括Connell二指手抓取數據集[3]和Dexnet系列數據集[12],這些數據集主要用于二指夾手或者吸盤.本文構建了用于軟體手抓取的機器人系統.抓取實驗以6類水果作為抓取對象,如圖4所示.采用 Intel 的RGB-D攝像頭D435,視野范圍是480像素×640像素.在數據搜集過程中,6類物體被隨機放置在桌子上,總共拍攝了18張圖片(包括深度圖和彩色圖,分辨率為480像素×640像素),其中一張圖片的密集程度如圖5所示.18張圖片共894個抓取標記,其中正標記474個,正樣本示例如圖5(a)所示,負樣本示例如圖5(b)所示.每個標記以標記位置為中心截取64像素×64像素的圖像塊作為簡化模型的輸入,如圖5(c)所示.數據集搜集過程可在30 min內完成,可快速應用在其他物體類別,這是該模型的優勢.
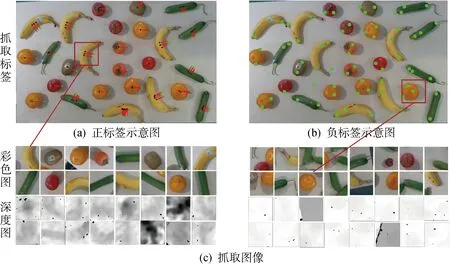
圖5 抓取數據集的建立Fig.5 Establishment of grasp dataset

圖4 抓取水果類別Fig.4 Fruit categories for grasping
圖5(a)上的紅線代表正樣本標記,黑點為手爪中心像素點s=(u,v),紅線(黑點到青點)的旋轉角度為抓取角度φ,考慮到軟體手4個手指的對稱性,抓取角度范圍為[-45°,45°],這是前文選擇90°/N的原因.藍點和黑點的深度差h標記為抓取深度d,若h≥0.8HGri,則d=0.8HGri,HGri為軟體手指的高度.圖5(b)為負樣本標記,負樣本的抓取位置標記為青色,主要為水果邊緣和桌面.正標記的抓取質量q統一記為1,負樣本的抓取質量記為0.
為擴大訓練樣本,提高樣本的利用效率,對采集的數據集進行數據增強.主要采用旋轉的方式進行數據增強,如圖6所示.一個64像素×64像素的抓取圖像塊可看作一個訓練樣本,以抓取位置點為中心,旋轉36次可將樣本擴大36倍.對于階段1的訓練,即擴大到 32 184 個樣本,樣本標簽不發生改變;階段2的標簽包含兩部分,抓取角度的二分類和抓取深度回歸,若抓取角度經過旋轉變為0°或者180°,則抓取角度預測為1,其他為0,抓取深度標簽不變.數據增強后的數據集按1∶4的比例分為訓練集和測試集.
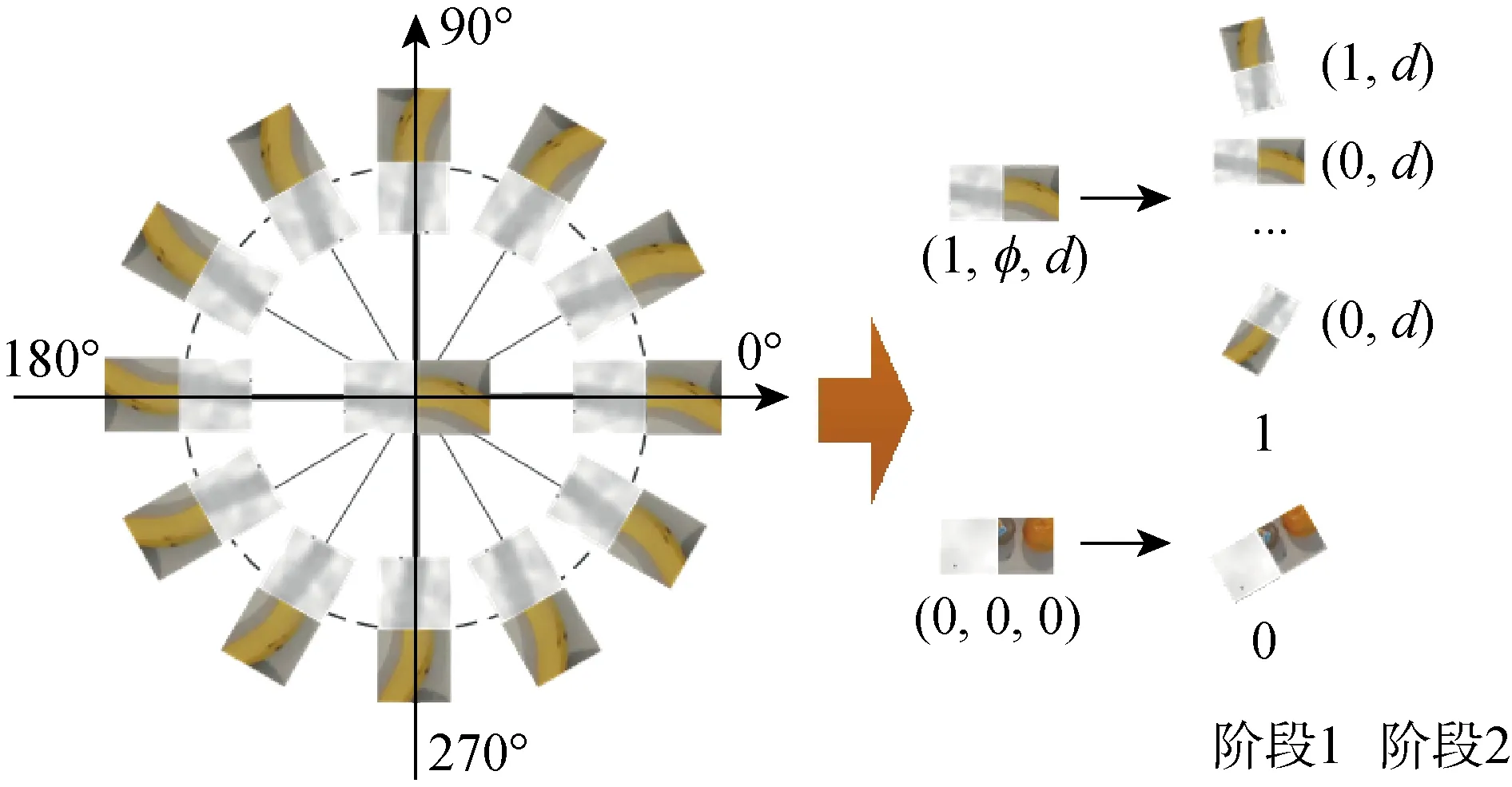
圖6 數據增強示意圖Fig.6 Data augmentation
2.3 多任務損失函數
不同于其他文獻采用單一損失函數的方式[13],不同階段采用不同的損失函數,階段1采用二元交叉熵,階段2采用多任務損失函數,角度分類同樣采用二元交叉熵,抓取深度回歸采用L2函數作為損失函數,對于參數化網絡Mθ,定義如下回歸損失:
(3)
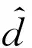
階段1抓取分類和階段2的角度分類,采用二元交叉熵作為損失函數,定義如下:
(4)
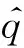
(5)
式中:平衡權重α是一個超參數,由實驗確定;B為訓練批大小.
3 實驗
為驗證本文所提算法的有效性,通過公開數據集和自建數據集對比驗證模型結構性能.公開數據采用Cornell 二指夾手數據集,與文獻[13]的單一均方誤差損失函數進行對比分析.在自建數據集上對比分析影響抓取檢測準確率的因素,同時通過實際機器人進行軟體手抓取實驗,以驗證所提方法的有效性.
3.1 損失函數對比
Cornell抓取數據集885張圖片,240個可抓物體,抓取標簽為5參數抓取矩形.文獻[13]對其中的抓取角度,抓取寬度和抓取質量3個標簽進行抓取回歸預測,采用的是單一均方誤差(MSE)損失函數,抓取構型的輸出量與本文預測量相似(抓取角度、抓取深度、抓取質量).作為對比,將其MSE單一損失函數與本文的多任務損失函數進行比較.同樣的,將Cornell數據集按4∶1∶1的比例分為訓練集、測試集和驗證集,在測試數據集對比損失函數的訓練效果.為全面衡量網絡的學習效果,采用均值平均精度(mAP)值作為網絡檢測結果的性能評價指標.抓取質量以不同閾值作為抓取成功的標準會有不同的mAP,超參數α也會影響網絡最后的mAP,給出了單一損失函數和不同α的多任務損失函數的閾值mAP變化圖,如圖7所示.其中:δ為閾值;M-L為多任務損失函數;MES-L為均方誤差損失函數.由圖7可知,多任務損失函數具有更優異的預測性能,抓取質量的判斷閾值設置為0.3,超參數α設置為2時,多任務損失函數獲得的最好預測結果為91.9,單一MSE損失函數的最好預測結果只有85.7.根據圖7,可以選出不同閾值設置下最合適的超參數α,從圖7中的曲線也可以看出,在不同閾值設置下,單一損失函數都不是最好的誤差函數.以閾值0.5為閾值時的各損失函數的mAP曲線如圖8所示.其中:ε為召回率;μ為精準率.由圖8可知,從mAP曲線中可具體知道多任務損失函數具有更高的預測精確率和召回率,相比單一MSE損失函數更適合作為多輸出抓取構型的損失函數.
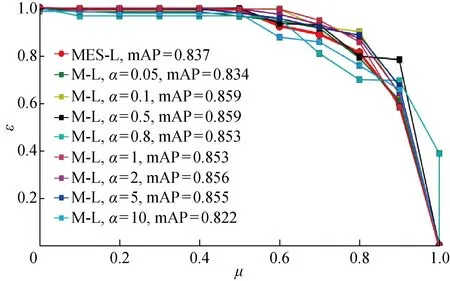
圖8 多任務和單一損失函數在δ=0.5時的mAP比較Fig.8 Comparison of mAP between multi-task and single loss function at δ=0.5
3.2 單階段與多階段網絡對比
本文的完備輸出包含抓取角度、抓取深度和抓取質量,只有這3項同時預測正確才能實現成功的抓取.本文設計了一個針對多輸出的評價指標,即對于預測結果,若抓取質量預測錯誤,則網絡判定為預測錯誤;若抓取質量預測正確,同時抓取角度與真值相差10° 以內,抓取深度與真值相差10 mm以內,預測結果判定為正確.作為對比,以單階段模型作為基準模型,即直接以階段2的模型對抓取進行預測.兩種模型在測試集上的對比結果如表1所示.其中:eac為網絡整體準確率;eer,a為抓取角度錯誤率;eer,d為深度預測錯誤率;eer,m為抓取質量錯誤率.
由表1可知,本文模型具有82.8%的整體預測準確率,明顯高于單階段模型.深度預測錯誤率給出了只有深度預測錯誤的比例,抓取角度錯誤率給出了階段2角度分類錯誤的比例,抓取質量錯誤率給出了階段1抓取質量分類的錯誤率.表1中的結果顯示,分為2個階段進行抓取檢測可以獲得更好的性能.2個階段模型的抓取角度錯誤率明顯低于單階段模型,這說明將抓取預測分為2個階段可以使角度預測主要集中于階段2進行,能夠獲得更好的角度預測.抓取深度回歸的錯誤率小于5%,說明網絡對抓取深度學到了相應的映射.

表1 單階段和多階段模型對比Tab.1 Comparison of single-stage and multi-stage models
3.3 機器人抓取實驗
以6自由度UR5機械臂、Intel RGB-D攝像頭D435和4指軟體手爪構建了機器人自主抓取實驗系統,D435固定在機械臂外部,視角朝下垂直桌面高度為800 mm,如圖9所示.
抓取檢測結果如圖10所示,圖10(a)為“錨點”步長為18像素的檢測結果,圖10(b)為“錨點”步長為9像素的檢測結果,藍點為抓取位置,“工字形”紅線代表抓取方向.從檢測結果來看,雖然步長18像素比9像素具有更稀疏的輸出點,但并沒有丟失對于水果的檢測結果,所以實驗采用“錨點”為18像素的步長.

圖9 機器人抓取系統Fig.9 Robotic grasping system
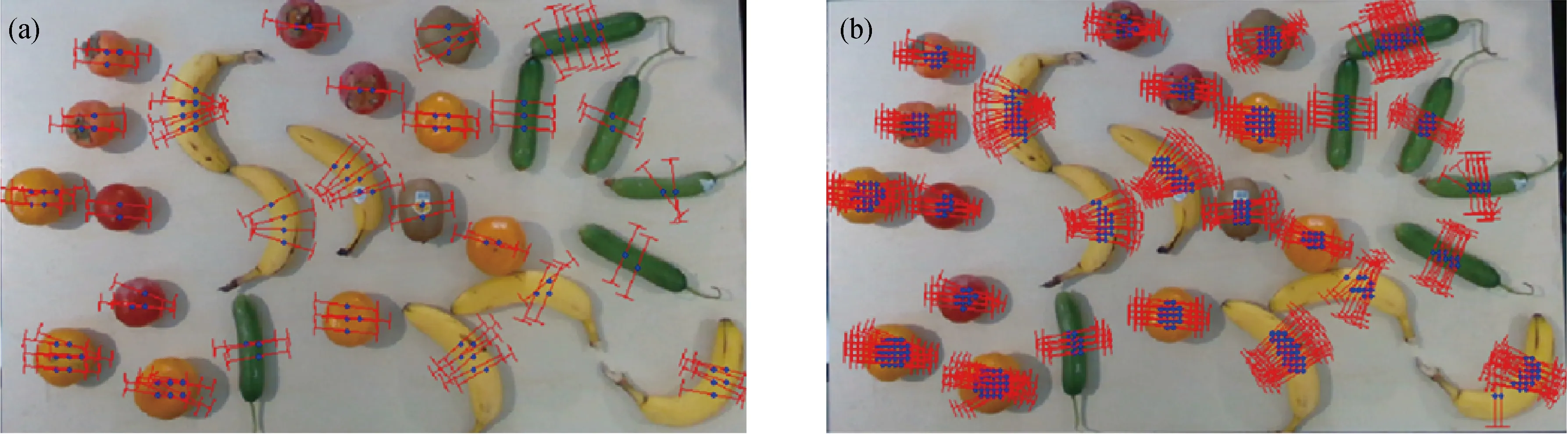
圖10 “錨點”步長為18和9像素的抓取檢測結果Fig.10 Grasp detection results with anchor step 18 and 9 pixels
輸入為480像素×640像素的情況下,步長為18像素的整體檢測時間為850 ms左右.各個水果的抓取結果如表2所示.由表2可知,整體抓取成功率達到96%.為便于定量分析各個水果抓取成功率的影響因素,在自建數據庫上(見表2)還比較了不同水果的網絡檢測結果.
表2 不同水果抓取成功率和網絡檢測準確率
Tab.2 Grasp success rate and model accuracy of different fruits
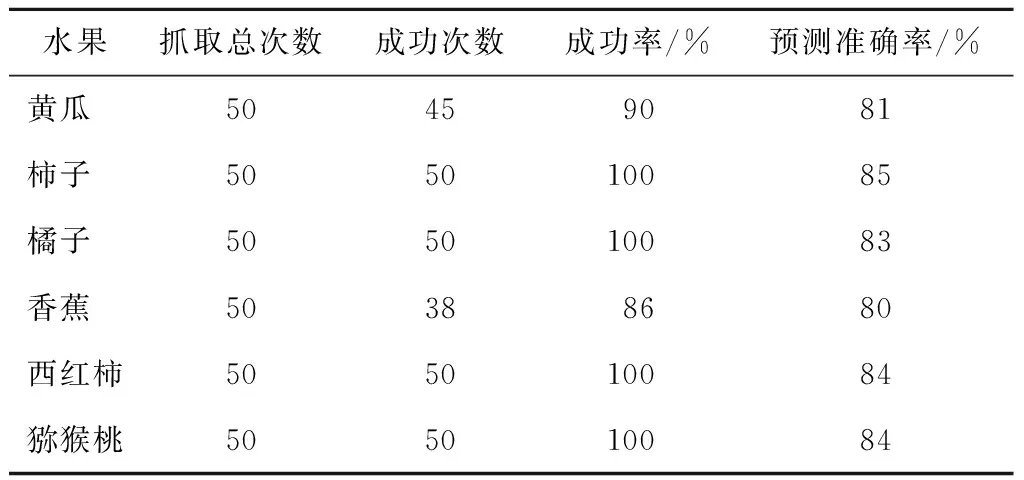
水果抓取總次數成功次數成功率/%預測準確率/%黃瓜 50459081柿子 505010085橘子 505010083香蕉 50388680西紅柿505010084獼猴桃505010084
從表2不同水果的抓取成功率來看,圓形水果的抓取成功率普遍比棒狀水果的成功率高,這是因為圓形水果對抓取角度分類的結果不敏感,并且對于位置定位誤差也具有較高的容差.表2中的抓取成功率普遍高于預測準確率,這是因為軟體手對預測結果具有一定容差,即使預測偏離正確值,仍然可以成功抓起水果.此外,數據標記主要根據人的經驗進行標注,和實際機器人的抓取略有不同.從預測準確率來看,圓形水果的準確率同樣高于棒狀水果,和抓取成功率結果吻合.不同水果的抓取結果如圖11所示(抓取視頻參見https:∥github.com/liuwenhai/softGrasping.git).如圖11(a)中的西紅柿抓取圖,顯示了在視覺定位存在誤差的情況下西紅柿依然可以被抓取.而棒狀水果,如黃瓜和香蕉,依賴網絡輸出正確的抓取角度和視覺定位的精度,只有抓取角度和抓取位置同時滿足一定準確度才可以被成功抓取.黃瓜和香蕉的預測準確率差異不大,黃瓜的抓取成功率卻明顯高于香蕉.這是因為,相較于黃瓜,香蕉的質量較大,抓取香蕉的中心具有更高的抓取成功率,而黃瓜質量較小,即使抓取到黃瓜兩側也能被成功抓取,所以黃瓜成功率比香蕉更高.試驗中還發現,對于大小不同的橘子,抓取網絡能夠輸出合適的抓取深度,有助于提高不同大小水果抓取的成功率,如圖11(b)所示.
實驗中發現,即使對于堆疊的水果皮,網絡也可以輸出正確的抓取檢測結果,并被成功抓取,如圖11(c)所示,這說明網絡對于水果皮同樣具有很好的泛化能力.

圖11 不同水果的抓取結果Fig.11 Grasp results for different fruits
4 結語
針對視覺引導的軟體手智能抓取,本文提出了基于“錨點”旋轉框的多階段抓取預測網絡,設計了針對4指軟體手的完備抓取構型,包含抓取質量、抓取角度和抓取深度,并采用多任務損失函數提高了多輸出抓取網絡的預測準確率.通過開源數據庫和自建數據庫驗證了所提抓取模型的有效性.最后,通過機器人抓取實驗驗證了所提方法可以有效地實現軟體手的智能抓取.實驗結果表明,所提方法對不同水果能夠達到平均96%的抓取成功率,此外,對于水果皮同樣具有很好的泛化效果,進一步提高了所提方法的應用范圍.
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
