基于種子變異潛力的模糊測試方法
2020-05-20 09:14:54宋禮鵬
科學技術與工程 2020年9期
關鍵詞:策略
王 喬,宋禮鵬
(中北大學大數據學院,太原 030051)
模糊測試是一種通過向目標系統或軟件提供大量自動生成的畸形數據來發現漏洞的軟件安全測試方法。模糊測試時,被測程序的代碼覆蓋率越高,發現漏洞的機會越大。自第一代模糊測試技術[1]出現以來,研究人員為提高代碼覆蓋率提出了覆蓋率導向策略,以覆蓋率信息指導測試進行。在收集覆蓋率信息方面,目前主要有兩種策略:第一種是收集已測試種子的覆蓋率信息,如AFL(American fuzzy loop)對覆蓋新路徑的種子進行變異[2];AFLfast[3]以覆蓋不被頻繁覆蓋的路徑數量作為判斷種子變異潛力高低的條件;AFLgo以種子覆蓋路徑和目標之間的距離來決定種子變異的優先級[4];FairFuzz則通過收集對分支的命中情況,選擇命中稀有分支的種子進行變異[5]。第二種策略則是利用程序分析技術,如CollAFL[6]和Vuzzer[7]使用了靜態分析技術[8]來提取控制流和數據流情況,而Driller[9]則通過利用符號執行[10]技術處理復雜約束。
覆蓋率導向策略的主要問題是如何得到更精確的覆蓋率信息以及如何判斷種子變異潛力的高低。在選擇優質種子時,變異潛力的高低應該是衡量種子優質程度的最主要標準,而諸如選擇覆蓋新分支的種子或選擇覆蓋稀有路徑的種子進行下一輪變異等策略往往會導致變異結果不夠理想,這是因為種子效果好和種子變異潛力高并不等價,新分支可能在下次變異后不被覆蓋而失去價值,或者新分支可能導向一個錯誤處理塊或程序終止塊,這種類型基本塊并不具有高的漏洞挖掘價值,因此覆蓋這種類型分支的種子價值較低、變異潛力也較低。
針對上述問題,提出了一種基于種子變異潛力分析的模糊測試方法,首先提取程序控制流圖,以基本塊入口地址作為其標記,考慮基本塊自身情況以及互相之間調用情況來賦予其權值。同時,在每一代種子運行結束后,根據種子覆蓋路徑附近未被覆蓋的基本塊權值情況以及種子運行時資源開銷情況來計算適應度,從而篩選優質種子,投入下一代變異。本文策略能體現種子變異潛力主要由于以下兩個方面。
(1)以種子覆蓋路徑附近未被覆蓋的基本塊數量作為衡量標準之一,這樣得到的高適應度種子通過變異到達未探索基本塊概率大,并且可能到達的未探索基本塊數量多。
(2)對基本塊進行賦權操作,將變異潛力體現在底層基本塊上。對于兩個不同的未覆蓋基本塊,后繼塊多的基本塊往往意味著如果通過變異實現對該基本塊的覆蓋,則通過該基本塊到達新基本塊的可能情況越多并且可能性越大,因此覆蓋該基本塊的價值就越大。
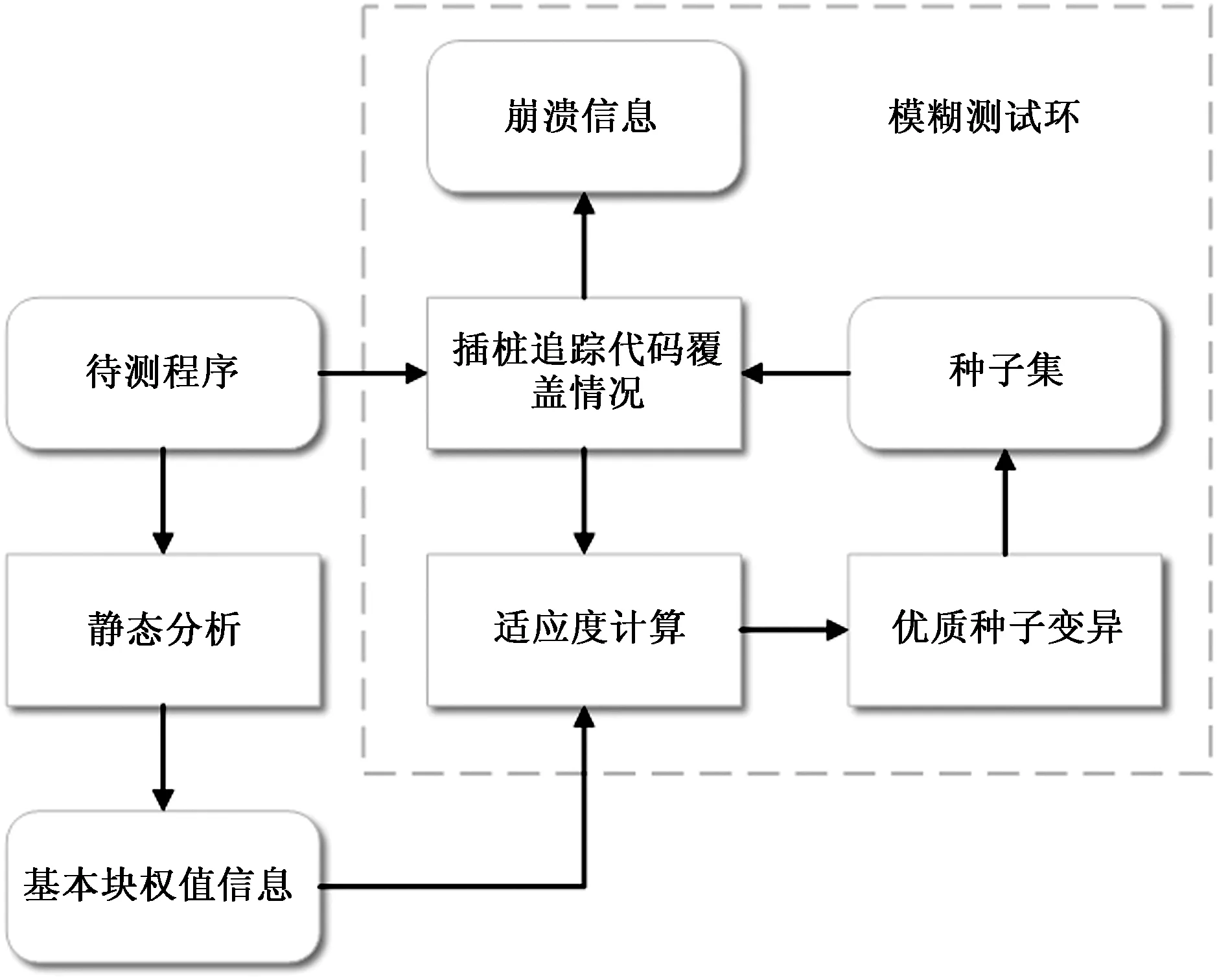
圖1 PAFuzz結構Fig.1 Structure of PAFuzz
1 基于種子變異潛力的模糊測試技術
模糊測試技術整體設計如圖1所示,首先在AFL的基礎上增加靜態分析模塊,提取該程序中不同基本塊信息和控制流圖,根據權值計算策略計算基本塊權值。其次對被測程序進行插樁,追蹤種子在測試期間的路徑信息以及覆蓋情況,結合基本塊權值,根據適應度函數計算種子適應度,選擇適應度大的部分種子投入變異池進行變異,利用生成的新一代種子進行下一輪測試,迭代上述過程,并基于以上策略設計了模糊測試工具PAFuzz。所用方案一方面在適應度計算時加入路徑潛力信息,提高了適應度函數的篩選效果,另一方面以入口地址標記基本塊,以前驅和后繼兩個基本塊的入口地址組成的元組標記分支,避免了傳統模糊測試策略標記分支時不同分支間的碰撞問題。
1.1 基本塊賦權
為了得到更有效更精確的路徑信息,在開始測試前先對被測程序進行靜態分析,提取控制流和數據流信息,以便在后續測試過程中能更有效地計算種子的覆蓋情況。在靜態分析方面,選擇使用IDA python插件對被測程序進行分析,提取函數基本塊的入口地址,出口地址和調用情況。

圖2 控制流圖Fig.2 Graph of Control flow
圖2為控制流圖,每個方塊代表一個基本塊,A代表主函數Main,箭頭表示調用關系。傳統的覆蓋率導向策略主要考慮種子的優質程度,例如,對于種子a,如果a覆蓋的路徑為(A、B、F、H)而分支{F->H}為新分支,則將a視為優質種子,分配更多變異機會。但一方面新分支{F->H}可能在變異之后不被覆蓋,另一方面H是一個程序終止塊,無后繼塊不具備任何變異潛力,因此這樣的篩選策略效果并不理想。權值計算方法綜合考慮兩個方面的信息。
(1)離根節點(孤立節點)越近的基本塊權值參數越高,而每遠一層,參數減半,在大多數情況下,處于越高層的基本塊往往意味著可能存在更多的子孫塊,例如基本塊B,對覆蓋B的種子進行變異,可能到達的基本塊有E、F、H、I、C、G、K,而對覆蓋G的種子進行變異則可能覆蓋的基本塊為K。雖然處于低層的基本塊F實際上比處于高層的C和D存在更多的子孫塊,但認為通常情況下高層的基本塊存在更大變異潛力。由于同一基本塊可能存在于不同路徑中導致其在程序中所處層次不同,本文以距離根塊最短的路徑作為基本塊位置;
(2)對于每一個基本塊來說,后繼塊的個數越多,則代表對覆蓋該基本塊的種子進行變異,可能到達的不同基本塊越多,而無后繼塊的基本塊,除該塊本身可能存在的漏洞以外,無任何變異潛力,因為無論如何變異,只要到達這個基本塊,則程序運行走到終點,這種基本塊的典型代表就是錯誤處理塊,當程序運行滿足不了既定條件時,轉向錯誤處理塊、報錯并終止程序,考慮到基本塊本身可能存在的漏洞可能使其存在一定價值,在計算基本塊后繼時進行了加1操作,可以有效提高適應度函數的效果。
此外,還考慮到孤立塊以及不在根塊的子孫集合中的基本塊的情況,如圖2所示的L、M、O、N,對于孤立塊,則賦予其和根塊一樣的權值參數,而對于既是根塊A的子孫塊,又是孤立塊L、O的子孫塊,以其在主函數下的位置情況賦予其權值。
定義入口地址的集合為Ast,基本塊的集合為BBAst,程序入口地址為ADD,基本塊權值參數集合為WHbb.Ast,基本塊權值集合為FWbb.Ast,考慮到要計算基本塊處于的最高層情況,采用層次遍歷的算法計算基本塊權值,具體算法描述如算法1所示。
算法1
for bb in BBAst:
if bb.Ast==ADD and len(list(bb.preds()))==0:
WHbb.Ast=n
FWbb.Ast=WHbb.Ast*(len(list(bb.succs()))+1)
V.append(bb.Ast)
T.append(bb)
while len(T)!=0:
cb=T.popleft
for cbb in cb.succs():
if cbb.Ast not in V:
WHcbb.Ast=WHcb.Ast/2
FWcbb.Ast=WHcbb.Ast*(len(list(cbb.succs()))+1)
V.Add(cbb.Ast)
T.Add(cbb)
而對于孤立塊和非根塊子孫集合中的基本塊,則執行算法2處理。
算法2
for bb in BBAst
if bb.Ast!=ADD and len(list(bb.preds()))==0:
WHbb.Ast=n
FWbb.Ast=WHbb.Ast*(len(list(bb.succs()))+1)
V.append(bb.Ast)
T.append(bb)
while len(T)!=0:
cb=T.popleft
for cbb in cb.succs():
if cbb.Ast not in V:
WHcbb.Ast=WHcb.Ast/2
FWcbb.Ast=WHcbb.Ast*(len(list(cbb.succs()))+1)
V.Add(cbb.Ast)
T.Add(cbb)
else:
pass
1.2 適應度函數
適應度函數的計算是最能體現種子潛力的部分,對于模糊測試環來說十分重要。一旦一個種子生成,那么該種子能否參與下一代變異取決于該種子的適應度函數大小。采用二進制插樁的方法,收集種子運行過程中對代碼塊的覆蓋情況。考慮圖2所示的例子,如果種子S1經過的路徑為(A、B、F、H),種子S2經過的路徑為(A、C、G、K),基礎權值參數為n,而測試過程中覆蓋過的基本塊為A、B、C、F、G、H、K,如果考慮種子覆蓋基本塊的權值,則S1權值和為(4+1.5+0.75+0.125)n=6.375n,S2權值和為(4+1+0.5+0.125)n=5.625n,因此S1覆蓋路徑比S2有更大變異潛力,但是對于這種策略,對于覆蓋較高權值基本塊的種子將不斷獲得變異機會,測試前期能夠實現對附近分支多的種子分配更多變異機會,實現覆蓋率的快速提高,但是由于所有基本塊權值固定,覆蓋較高權值的基本塊無論其附近基本塊覆蓋情況如何,將不斷獲得變異機會,導致測試后期種子多樣性降低,不利于測試持續高效進行。因此在該策略的基礎上提出收集種子覆蓋路徑附近基本塊情況,由其中未被覆蓋的基本塊權值和來體現路徑種子變異潛力,則S1覆蓋路徑周圍未探索基本塊為D、E、I,權值和為(1.5+0.25+0.25)n=2n,S2覆蓋路徑周圍未探索基本塊為D,權值和為1.5n,因此S1覆蓋路徑比S2有更大變異潛力。
除此之外,考慮到計算機資源開銷問題,處理時間和種子文件大小也是影響適應度的兩個因素,在處理效果相同時,處理時間較短和文件大小較小的種子往往意味著更高的處理效率和更小的資源開銷,因此對于一代種子S,將以下兩個參數加入到適應度函數計算中。
Tseed=time(s)/avet(S),s∈S
(1)
Lseed=length(s)/avel(S),s∈S
(2)
式(1)表示種子s在處理時間上的優質程度,式(2)表示種子s在大小上的優質程度,其中avet(S)和avel(S)代表所有種子平均時間開銷和平均長度。結合基本塊權值信息,可以計算得到種子的適應度函數,如式(3)所示:
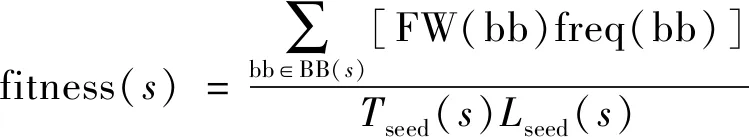
(3)
式(3)中:BB(s)代表s周圍未覆蓋的基本塊集合;FW(bb)為bb的權值;freq(bb)為bb出現在s周圍的次數,選擇每一代中適應度最高的部分種子進行下一代變異。
1.3 變異策略
AFL在種子變異方面主要采用了按位翻轉(將二進制位1變成0或0變成1)、整數加減、特殊內容替換、自動生成或用戶提供的token插入和文件拼接五種策略,主要結合遺傳算法[11]實現種子變異,主要策略如下。
1.3.1 交叉變異
如圖3所示,從優質種子中隨機選取兩個,對隨機選擇的一段比特位進行交換,得到兩個子代種子。
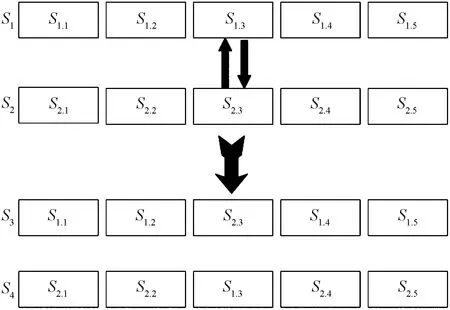
圖3 交叉變異Fig.3 Cross variation
1.3.2 替換變異
如圖4所示,對優質種子的隨機選擇的一段比特位,使用特殊數據或隨機數據進行替換。
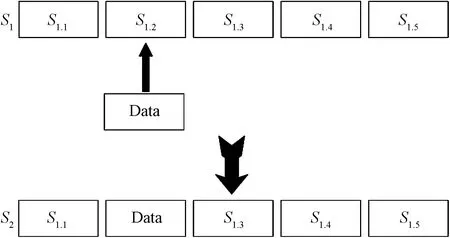
圖4 替換變異Fig.4 Replacement variation
1.3.3 大規模突變
適應度函數篩選優質種子不可避免會導致種子池在后期多樣性降低,無論交叉還是替換操作都不能再給種子質量帶來有效提高,因此當程序在一定輪數之后未發現新塊,則選擇執行大規模突變,提升種子池多樣性并一定程度恢復種子探索新路徑能力。
2 實驗
為了測試所用模糊測試方案的效果,將本文方案在LAVA-M數據集[12]和真實Linux程序上進行了測試,實驗結果與目前廣泛使用的模糊測試工具AFL(2.52b)在漏洞發現能力、覆蓋率、漏洞發現速度和輸入數據總大小方面進行了對比,測試環境為Ubuntu系統,并為其配置了4-core的CPU和4GB內存,測試初始種子集相同。
2.1 漏洞挖掘能力
發現漏洞的能力是模糊測試工具優劣的集中體現,因此比較了24 h內發現漏洞情況,AFL使用QEMU對二進制程序進行插樁,被測程序選擇LAVA-M數據集,漏洞發現情況結果如表1所示。同時,將本文方案和AFL在真實Linux應用進行了對比測試,結果如表2所示。
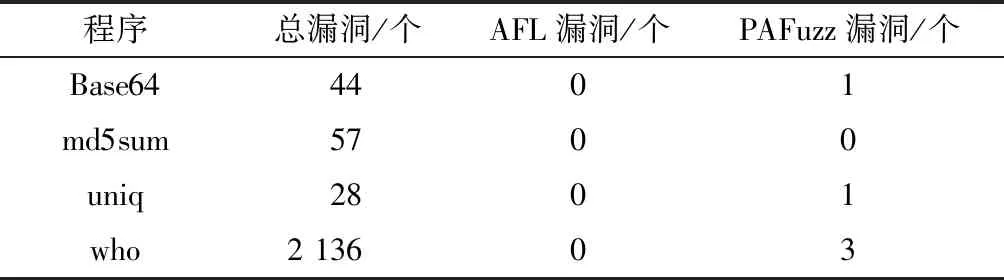
表1 LAVA-M上漏洞發現能力對比Table 1 Comparison of vulnerability discovery capabilities on LAVA-M
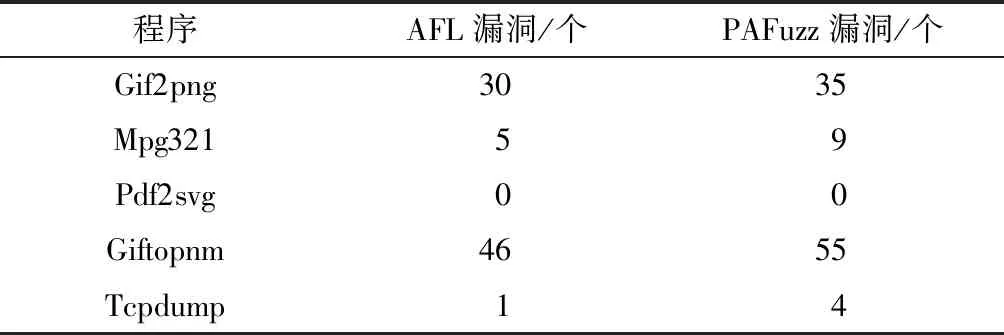
表2 真實程序上漏洞發現能力對比Table 2 Comparison of vulnerability detection capabilities on real programs
由表1、表2可知,在變異策略基本相同的情況下,基于本文策略的模糊測試工具在漏洞挖掘能力方面相比于以是否發現新分支作為種子優劣標準AFL有明顯提高,充分說明本文策略篩選出的種子變異后測試效果優于AFL。
2.2 覆蓋率情況
代碼覆蓋率情況是衡量技術性能的重要指標,一方面能反映篩選策略的優劣程度,另一方面體現變異策略的效率,在對上述程序進行測試時,收集并統計了本文方案和AFL在24 h內覆蓋的總路徑情況,結果如表3所示。
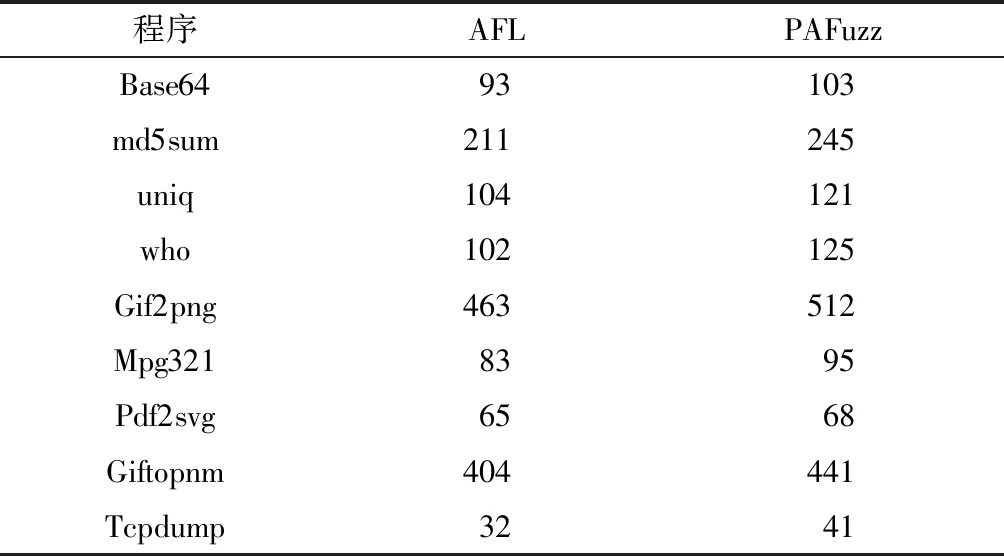
表3 覆蓋率情況對比Table 3 Comparison of coverage
由表3可知,被測程序的路徑覆蓋率平均提高了14.73%,這是由于所篩選策略將種子變異后可能到達的新基本塊情況作為衡量標準,變異后種子覆蓋新路徑的可能性比AFL更大,在變異策略基本相同的情況下,所篩選策略得到的覆蓋率情況明顯優于AFL。
2.3 輸入數據
對24 h內測試過的種子總大小進行統計,結果如表4所示。分析結果可知,相比于AFL,PAFuzz將種子大小和運行速度作為衡量標準之一,整個測試過程中生成的測試用例空間開銷更小,效率更高。
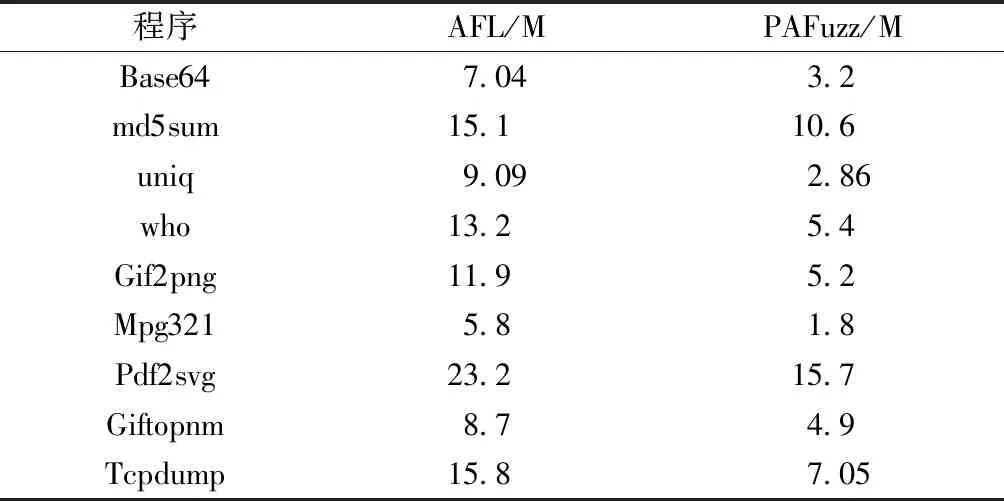
表4 測試用例總大小對比Table 4 Comparison of test case total size
2.4 漏洞發現速度
為了對比整個實驗過程中AFL和PAFuzz在24 h內各個時間段漏洞發現情況以及整體漏洞發現趨勢,以2 h為間隔對兩個方案漏洞發現情況進行采樣,對比了兩個方案的漏洞發現速度,對比結果如圖5所示。分析圖5可知,由于本文方案篩選出的優質種子執行速度快變異潛力大,變異后可能覆蓋的新路徑多,因此本文方案能夠快速提升代碼覆蓋率并在測試前期觸發更多漏洞。同時,AFL由于使用簡單的遺傳算法,導致種子在后期的差異性變小,替換變異和交叉變異的效果大幅度減弱,發現漏洞能力嚴重下滑,而本文方案則有效避免了這一情況,同時由于存在大規模突變機制,可以有效提高測試后期種子多樣性,因此在后期發現漏洞的能力也優于AFL,更加證明本文策略的有效性。
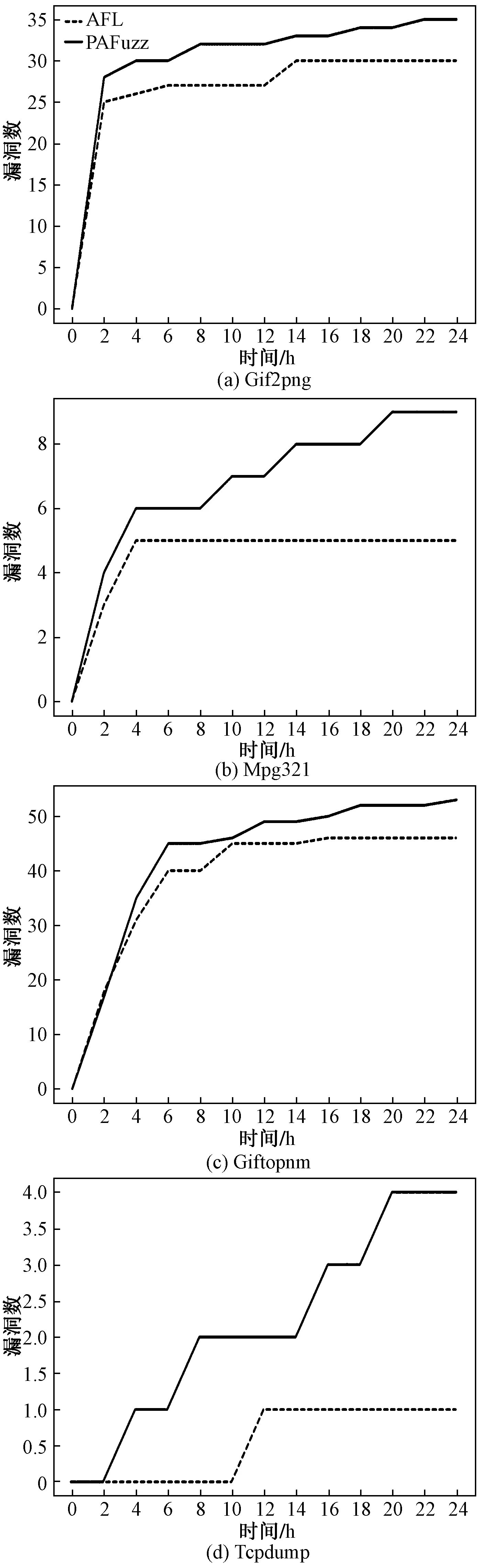
圖5 漏洞發現情況對比Fig.5 Comparison of vulnerability discovery
3 結論
針對傳統模糊測試在種子篩選時數據粗糙、算法簡單、無法真正分辨種子變異潛力的問題,提出一種改進方案,主要是結合基本塊的位置和后繼基本塊的數量分析基本塊的變異潛力,追蹤種子覆蓋路徑附近未被覆蓋的基本塊情況,綜合種子的處理速度和大小,給出其適應度函數值。實驗表明在相同時間內,本文方法在漏洞發現數量、漏洞發現速度和代碼覆蓋率方面都有所提高,同時還避免了覆蓋率導向技術中存在的碰撞問題。
在下一步的研究中,將結合諸如污點分析[13]、符號執行等技術對變異策略進行進一步優化以應對程序中的復雜約束,覆蓋程序深處代碼塊。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
