基于自注意力機制的中文標點符號預測模型
2020-05-18 11:08:28段大高梁少虎趙振東韓忠明
計算機工程 2020年5期
段大高,梁少虎,趙振東,韓忠明
(北京工商大學 計算機與信息工程學院,北京 100048)
0 概述
漢語是當今世界上最主要的語言之一,全球有超過15億人使用漢語。在漢語書面語中,標點符號是不可缺少的組成部分,是輔助文字記錄語言的符號,用來表示停頓、語氣以及詞語的性質和作用,它可以幫助人們確切地表達思想感情和理解書面語言。在語音轉化文本的過程中,沒有添加標點符號,或者只是依據時間停頓來添加特定的標點符號,這樣不符合標點符號規范,因此標點符號預測(Punctuation Prediction,PP)是一項重要的自然語言處理任務。標點符號預測指利用計算機對文本進行標點符號添加,使文本符合標點符號使用規范。
標點符號預測問題最初工作主要集中在語音識別領域,標準的語音識別系統識別出的序列既沒有將輸出正確地分割為句子,也沒有標點符號。經語音識別系統識別后的文本沒有標點符號和句子邊界,帶來許多理解上的問題,因此,在實際應用中,對長文本進行分割,添加標點符號是必要的。標點符號預測問題吸引了語音處理領域和自然語言處理領域學者的關注,研究人員利用統計模型中的局部特征進行預測,如詞匯、韻律特征和隱藏事件的語言模型(HELM)[1-2]。HELM對于輸入用一個較小窗口的采樣,這樣由于上下文信息有限而不能達到滿意的性能[3]。對于標點符號預測,研究全局的上下文信息是必要的,尤其是長期依賴關系,已有研究試圖合并語法特征拓寬標點符號預測的視野[4]。
基于循環神經網絡(Recurrent Neural Networks,RNN)的標點符號預測模型技術取得了一定的進展,但由于標點符號預測任務需要對輸入文本結構進行信息提取,而RNN不適用于處理樹狀結構的輸入。為解決該問題,本文提出一種基于自注意力機制的多層雙向LSTM標點符號預測模型DABLSTM。
1 相關研究
近年來,基于文本的標點符號預測逐漸獲得人們的關注,文本的標點預測不能提取聲學方面的信息,需要尋找其他的特征。文獻[5]基于英文文本特征,在斷句中將標點插入句子。文獻[6]將標點符號進行分類,提出了一種自動提取表示句末標點的線索詞方法。文獻[7]為了解決線索詞的“遠程依賴”問題,使用F-CRF模型,同時選取詞級別特征和句子級別特征。以上方法在英語文本中取得了較好的效果,但在中文文本中效果并不理想,部分原因在于中文標點符號種類更多,較為復雜多變,中文線索詞的提示性并不十分準確。只利用淺層的詞法特征并不能體現中文標點符號的應用特點,因此一些學者嘗試更深層次的句法特征。為了在標點預測中融合更深層的句法特征,文獻[8]以網絡文本為測試語料,融合多種特征,訓練CRF模型,缺點是局限于特征的設計,當特征維度大時,容易出現過擬合現象。以上基于規則、統計以及傳統機器學習模型的性能依賴于特征的選擇,模型的輸入是基于人為設定的特征。
神經網絡具有優異的建模能力,不需要人工構建特征工程,被廣泛地應用于序列標注問題上。文獻[9]將神經網絡模型應用到自然語言處理(NLP)。由于標點符號類別有限,中文分詞任務可以看作序列標注問題,因此中文分詞模型也可以應用于PP。文獻[10]提出了基于神經網絡的中文分詞模型。文獻[11]使用LSTM神經網絡來解決中文分詞任務,一定程度上解決了傳統神經網絡無法長期依賴信息的問題。傳統的單向LSTM神經網絡只能處理過去的上文信息,中文句子結構復雜多變,有時需要結合下文的信息才能做出判斷。文獻[12]提出了一種雙向LSTM-CRF模型,并用在序列標注問題上,取得了理想的效果。文獻[13]把中文分詞和標點符號預測任務用雙向LSTM網絡同時訓練,得到分詞和標點符號預測模型。但是由于分詞標注的數據集過小,難以擴展到實際文本應用中。
本文提出一種基于自注意力機制的多層雙向LSTM標點符號預測模型DABLSTM,模型基于自注意力機制,直接提取輸入的全局依賴關系,相比RNN,自注意力的優點是直接提取輸入文本任意兩個位置的關系。因此,遠程關系可以通過直接的路徑解決(自注意力機制中任意兩個詞的距離總是1),而遠程關系對于標點符號預測是有幫助的。自注意力還可以提供更靈活的方式選擇、表示和綜合輸入信息。雙向LSTM網絡增加了模型的表征能力,DABLSTM模型同時利用LSTM和自注意力機制,捕獲文本序列重要信息,聯合學習文本詞性與語法信息,實現準確的中文標點符號預測。
2 Bi-LSTM序列標注模型


圖1 Bi-LSTM序列標注模型結構
3 DABLSTM標點符號預測模型
本文基于Bi-LSTM,提出DABLSTM模型,即深度自注意力雙向LSTM模型,其框架如圖2所示。

圖2 DABLSTM神經網絡模型結構
DABLSTM主體堆疊N個相同的子層,每個子層由一個Bi-LSTM層和Self-Attention層堆疊。最上層是一個Softmax標簽預測層構成,如圖2所示,相比通用的Bi-LSTM模型,DABLSTM模型添加了自注意力層,可以跨位置提取詞之間的關系,有很強的表征句意信息。模型堆疊多次,網絡更深,充分提取了句意信息來預測標點符號,實驗結果表明了改進DABLSTM模型是有效的。
3.1 標點符號標注集
本文把標點符號標簽分為13個類別,如果一個詞的直接后繼是某個類別的標點符號,則把此詞標注為對應標點符號的標簽,如果一個詞的直接后繼不是標點符號,則把此詞標注為標簽“0”,標點符號標簽集如表1所示。
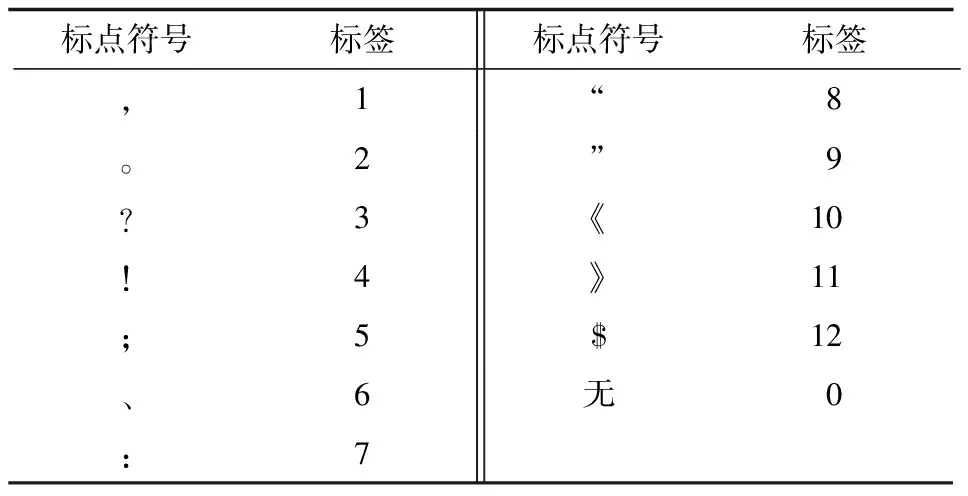
表1 標點符號標簽集
在表1中,標簽“1”表示逗號,標簽“2”表示句號,“無”表示無標點符號……“$”表示段落結束標志。
3.2 自注意力層
自注意力機制是Google團隊[14]在2017年提出的編碼序列方案,它與一般的RNN、CNN同樣都是一個序列編碼層。自注意力機制是一種特殊的注意力機制,它只需要單獨的序列來計算此序列的編碼,自注意力在很多NLP任務中表現優異。文獻[15]把自注意力機制應用在中文閱讀理解任務上取得了較好的效果。文獻[16]把注意力機制應用在方面級別情感分類問題上,實驗結果顯示了方面級別注意力機制的有效性。文獻[17]提出一種融合注意力機制對評論文本深度建模的推薦方法,通過仿真實驗驗證了注意力機制的有效性。
本文采用文獻[14]提出的多頭注意力機制,圖3所示為多頭注意力機制的計算過程。

圖3 多頭注意力機制計算過程
(1)
其中,d是網絡隱藏層神經元數,Softmax()為非線性激活函數。
(2)
最后,將所有并行計算出的頭拼接成一個矩陣。同樣一個線性映射用來從不同的頭混合不同的通道:
M=Concat(head1,head2,…,headn)
(3)
Y=MW
(4)
自注意力機制和RNN或CNN相比具有很多的優勢。首先,它從根本上解決了遠程依賴問題,任何位置的輸入和輸出的距離為1,而在RNN中可能是n(輸入序列長度)。與CNN相比,自注意力不局限于固定窗口的大小,它可以學習序列任意兩個位置的關系信息。其次,自注意力機制使用加權和計算產生輸出向量,它的梯度傳播比RNN或者CNN更容易,不會出現RNN梯度彌散或膨脹問題。最后,點乘注意力可以高度并行,矩陣乘法可以在GPU上優化,而RNN由于遞歸機制難以并行處理。
3.3 位置編碼層
自注意力機制不能處理序列位置信息,因此對輸入序列向量位置信息編碼是極為重要的。位置編碼有很多方式可以訓練得出位置向量,也可構造位置編碼得出位置向量,本文使用文獻[14]提出的位置編碼方式:
(5)
其中,表達式將編號為p位置映射為一個k維位置向量,向量的第i個元素數值為PEi(p)。
3.4 Bi-LSTM層
自注意力通過加權和得到輸出向量,有著很強的表征序列能力,但不能表示序列順序信息,循環神經網絡(RNN)[20]在近些年來被廣泛應用于語音識別和自然語言處理領域。文獻[21]使用循環神經網絡對天氣等時間序列進行預測,相比傳統方法預測準確度有很大提升。文獻[22]提出一種基于雙向LSTM的結構識別方法,對流式文檔進行結構識別,實驗結果表明雙向LSTM具有更好的識別效果。RNN這種基于時間序列的循環計算方式使得模型能夠捕捉輸入序列中長距離的特征信息,具有十分強大的信息記憶能力。由于RNN適用的時間序列與文本序列有著相同的特性,因此RNN網絡相對于其他深度學習模型更適用于文本處理。在RNN中,每個處理單元在t時刻的隱藏狀態均由其外部輸入xt和上一時刻的隱藏狀態ht-1共同決定,表示如下:
(6)
然而這種強大的記憶能力在模型的訓練過程中會導致梯度消失和梯度爆炸問題,一個簡單的RNN并不能有效處理序列的長距離依賴關系。為了解決該問題,一種RNN的變體長短時記憶網絡(LSTM)[23]應運而生。LSTM神經網絡模型通過引入門機制和細胞狀態來解決長期依賴問題。
LSTM網絡能夠按需要決定模型對于歷史信息所要記憶的長度,但該模型中默認序列最后元素所記憶的信息最多,因此序列最后元素占有較重要地位。而序列標注問題要求序列中每個單元都應是平等的,因此本文采用雙向LSTM(Bi-LSTM)作為基礎模型。Bi-LSTM包含了輸入序列中來自雙向的信息,正向LSTM捕獲了上文的特征信息,而反向LSTM捕獲了下文的特征信息,所以相對單向LSTM來說能夠獲取到更多的序列信息,因此在通常情況下,Bi-LSTM的表現比單向LSTM或者單向RNN要好。
給定輸入序列向量{xi},Bi-LSTM分別以正向、反向方向處理輸入序列,然后通過兩個方向表示的向量之和來得到輸出向量:
(7)
(8)
(9)
3.5 輸入層
本文采用三類特征作為模型輸入:詞向量,詞性向量,句法向量。通過對詞向量、詞性向量、句法向量聯合學習,可以得到多模態的語義句法信息,對標點符號預測有提高作用。
輸入層由三部分構成:
1)詞向量和位置編碼,詞向量是用word2vector工具在搜狗新聞語料庫上預訓練得到[24],詞向量包含當前詞的語義信息,本文中詞向量維度設置為300。按照上文給出的編碼方案把位置信息編碼為位置向量維度為300,然后將詞向量和位置向量加和作為網絡部分輸入。
2)詞性向量,表示當前詞在語義環境中的詞性,可以是名詞、動詞、形容詞與副詞等,由于標點符號大多出現在名詞后,因此將詞性作為模型的輸入特征之一。
3)句法向量,表示當前詞在語境中的句法作用,包括主語、謂語、賓語等,句法信息對提升標點符號預測有巨大提升作用。將詞向量和位置向量加和后的詞性向量、句法向量拼接在一起作為網絡的最終輸入。
4 實驗結果與分析
4.1 數據集
本文實驗采用以下兩個數據集:
1)搜狐新聞數據(SogouCS)版本,此數據集包含來自搜狐新聞 2012年6月—7月期間國內、國際、體育、社會、娛樂等18個頻道的新聞數據,數據集大小為648 MB。
2)當代文學作品50部,數據集大小為58 MB。首先對兩個數據集依據標點符號標注規則進行標注,過濾掉在標注集之外的標點,然后以去除標點符號得到純文本序列X和相對應的標簽序列Y作為訓練數據。按照8∶2的比例把數據集劃分為訓練集和測試集,實驗結果在測試集上得到。
在對中文標點符號預測任務中,使用分類問題的評價指標精確度(Precision)、召回率(Recall)和F1值來評價模型整體性能,以F1值作為主要評價指標。
4.2 實驗設計
在實驗中,使用分詞工具HanLP對文本進行分詞處理、DABLSTM神經網絡進行實現,使用python3.6和深度學習框架TensorFlow 1.50來構建深度網絡。所用工作站參數:CPU為Inter Core i7 6800K,GPU為Nvidia GTX1080Ti圖形處理卡,操作系統為Ubuntu16.04。
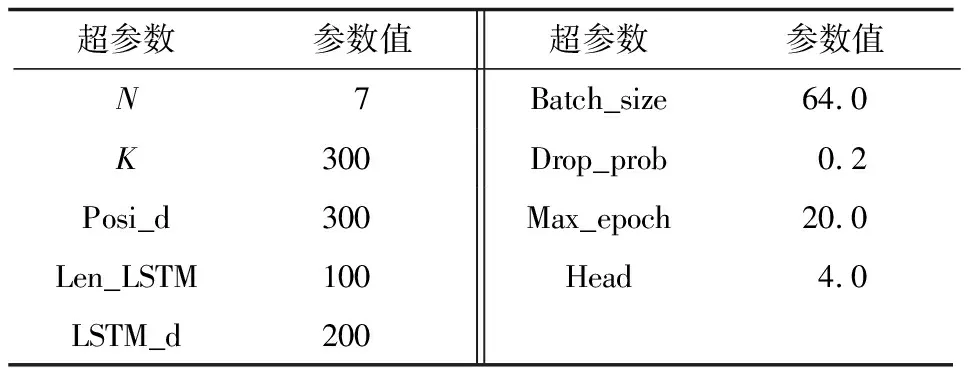
表2 實驗參數設置
將網絡深度N設置為7,即有7層重復的非線性子層,輸入詞向量維度K設置為300,位置編碼維度Posi_d設置為300,LSTM相關模型輸入長度Len_LSTM設定置為100,即在網絡輸入層有100個LSTM處理單元,LSTM輸出維度LSTM_d設置為200,多頭注意力Head設置為4。通過在詞嵌入層和自注意力層添加Dropout[25-26]層來使隱藏層節點不工作,增強網絡的泛化能力,丟棄率Drop_prob設置為0.2。采用隨機梯度下降法來優化網絡參數,訓練的Batch_size設置為64。具體地,本文采用Adadelta[27]作為參數優化器。
4.3 實驗結果
本文為探究網絡結構、自注意力機制對實驗結果的影響,分別進行兩個實驗。
實驗1為了驗證DABLSTM網絡模型的優越性,首先將本文模型與傳統CRF、LSTM、Bi-LSTM模型分別在搜狗新聞數據和當代文學數據兩個數據集上進行對比實驗,如表3所示。

表3 4種模型的識別性能對比
本文對比實驗模型介紹如下:
CRF:模型使用的特征包括線索詞、句型特征、句法特征及主題詞特征。
LSTM:傳統的LSTM網絡,將PP問題看作序列標注問題,模型的輸入包括詞向量和位置向量。
Bi-LSTM:雙向LSTM網絡,將PP問題看作序列標注問題,模型的輸入包括詞向量和位置向量。
DABLSTM:深度自注意力雙向LSTM網絡,有多個子層堆疊而成,每個子層包括一個雙向LSTM層一個自注意力層,模型的輸入包括詞向量和位置向量。
實驗2為了驗證自注意力機制在解決序列長期依賴的有效性,在DABLSTM網絡中用前饋網絡層代替自注意力層,前饋網絡層定義為:
FFN(X)=f(XW1)W2
(10)
其中,W1、W2為可學習的參數矩陣,f()為非線性激活函數,本文選用RELU。
為研究位置向量編碼對自注意力機制影響,本文做了對比實驗,在網絡結構超參數都相同的情況下,一組輸入為詞向量與位置向量的加和,另一組輸入僅為詞向量。為確定網絡深度是否能夠提高評價指標,設置了不同的網絡深度N,為探究隱藏層神經元個數即網絡寬度對評價指標的影響,進行了對照實驗。以上實驗都是在新聞數據集上,用搜狗新聞語料庫訓練的300維詞向量進行的對比實驗。不同參數對比結果如表4所示。

表4 不同參數對比結果
在表4中,√表示自注意力層可以捕獲序列的位置信息,×表示自注意力層不能捕獲序列的位置信息。
4.4 結果分析
通過表3可以看出,在兩個不同的數據集上,本文的DABLSTM網絡模型在精確度、召回率和F1值上均是最優的,尤其是召回率和F1值,這是由于深度神經網絡能夠編碼更多的潛在語義信息。縱觀深度模型,Bi-LSTM在兩個數據集上的F1值分別高于LSTM模型4.73%和4.87%,這是因為在LSTM網絡中添加雙向連接能夠使模型學習到句中雙向的語義信息,從而給模型帶來更佳的預測結果。
1)網絡深度的影響:通過表4的第1行~第5行可以看出,隨著網絡深度的增加,模型的效果增強顯著,這也驗證了文獻[28-29]的工作,即深度是網絡表征能力的關鍵。從第3層增加到第6層,效果提升9.6%比較顯著,從第6層增加到第9層效果有較小提升,而在增加到一定層數后,再增加層數反而效果下降,原因是當模型太深時反向傳播算法梯度難以傳導,使用隨機梯度優化參數的方法效果就要打折扣,另一部分原因是網絡參數量大,出現了過擬合現象。對于深度網絡難以訓練問題,可以采用添加殘差模塊[29],跨層傳導梯度來解決,這也是模型改進的方向,對于網絡過擬合問題,可以在損失函數中引入參數正則化,這也是模型另一個改進的方向。對比第1、6、7行可以看出,網絡寬度從200增加到400、600,網絡提升并不顯著。因此,網絡的深度比寬度對模型的提升更有效。
2)自注意力的影響:通過表4的第1、8行可以看出,當自注意力層替換為前饋網絡層時,模型F1相對下降13.2%,而當去掉自注意力層時,模型F1相對下降16%,這一結果充分證明了自注意力層的必要性和有效性,它是對Bi-LSTM的必要補充,從根本上解決了序列的長期依賴問題(任意兩個位置距離為1)。
3)位置編碼的影響:通過表4的第1行和9行看出,當輸入沒有編碼位置信息時,模型F1值相對下降5.1%,可以看到位置信息對模型的重要性,不難理解,自注意力層不能捕獲序列的位置信息,所以在詞向量中融合位置信息會有較大提升,位置編碼總是伴隨自注意力。
5 結束語
本文建立一種基于自注意力機制的中文標點符號預測模型DABLSTM。通過自注意力機制構建DABLSTM網絡,提取文本添加標點的信息,根據對詞的詞性信息和句法信息進行聯合學習,利用詞的詞法信息和句法信息預測標點符號。實驗結果表明,對比傳統的CRF模型和Bi-LSTM模型,DABLSTM模型在中文標點符號預測上取得了較好的效果,大幅提升了預測正確率。DABLSTM網絡是Bi-LSTM網絡的增強,對序列標注問題有較好的建模能力,下一步將對該模型進行泛化能力驗證,以避免出現過擬合現象。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
語文知識(2014年1期)2014-02-28 21:59:13
