有監督時間序列分割與狀態識別算法
2020-05-20 10:22:56史明陽
計算機工程 2020年5期
史明陽,王 鵬,汪 衛
(復旦大學 軟件學院,上海 201203)
0 概述
時間序列分割是獲取時間序列內在信息的重要方式,在數據挖掘領域備受關注。當前的時間序列分割算法多為無監督類型,相同的時間序列可以具有多種不同可解釋的分割模式。在實際情況中,每一個片段的監控數據通常對應于被監控對象不同的實際物理狀態。顯然,在通過不同分割方法獲得的大量分割結果中,并不是每一種分割模式都符合用戶的期望。因此,能夠選擇分割的模式在整個識別過程中就顯得尤為重要。
目前關于時間序列分割方式及其狀態判斷的研究較少,在此背景下,本文提出一種有監督的時間序列分割與狀態識別算法SSR。通過構建特征高斯概率分布模型設計相關序列的特征,在此基礎上,利用匹配損失計算和改進的貪心策略設定特征權重約束,并利用增加分割位置約束條件及增量計算2種優化方式進一步提高算法效率。
1 相關工作
關于時間序列分割及狀態識別問題的解決方法,目前研究成果較多。文獻[1]提出一種基于重要點的時間序列分割方法,將考察時間窗擴展到前一重要點、待考查點和下一指定時間窗之間,再通過考察時間窗口內待考察點兩邊模式和變化幅度來確定重要點,從而減小分割誤差。文獻[2]提出一種基于重要點與灰色GM(1,1)模型的時間序列分段算法,在保留全局特征的同時保持局部性質,能夠以較小的擬合誤差實現序列的壓縮。文獻[3]提出基于信息顆粒和模糊聚類的時間序列分割方法,使得時間序列的分割具有數據上的同質性,得到既有時間信息又具有同質性的時間序列分割結果。文獻[4]則提出一種基于Floyd算法的海溫時間序列分割方法。
隱馬爾科夫模型(Hidden Markov Model,HMM)是時間序列分割算法中一種常用的典型模型,其中SWAB[5]和pHMM[6]能夠從時間序列中進行線性分割。pHMM是基于模式的隱馬爾科夫模型[7]和SWAB的改進,旨在揭示生成時間序列數據的系統全局圖。AutoPlait[8]是另一種典型的時間序列分割算法,它使用最小描述長度(MDL)和多級鏈模型(MLCM)對時間序列的替代HMM評分從而進行分割。FLOSS[9]是一種基于Matrix Profile[10]構建的在線流媒體語義分割方法。
現有的時間序列狀態識別方法可分為兩大類[11],一類是基于形狀的方法,其通過相似性度量來測量原始數字數據中時間序列之間的距離,此類方法可以實現高精度,但計算昂貴,基于歐氏距離[12]或DTW距離[13]構建的傳統1NN分類器為其典型示例;另一類是基于結構的方法,其使用一些方法來描述類的特征,此類方法更能有效地抵抗噪聲,如SAX-VFSEQL[14]和SAX-VSM[15]在SAX[16]表示時間序列上構建分類器。
2 問題描述
為闡述方便,首先給出本文研究的相關概念和問題的基本定義。
2.1 相關定義
定義1(時間序列) 一條時間序列T={t1,t2,…,tn}是長度為n的相等間隔實際值的連續有序序列。
定義2(子序列) 一條時間序列T的子序列s是T的子集,其中s的長度小于或等于T。
通常,時間序列數據是從真實的物理環境中獲得的,這意味著其中包含真實的物理意義。根據用戶需求和序列的實際情況將時間序列分割為子序列,對于分割結果中分割的子序列和相應的語義描述,稱為片段和狀態。
定義3(片段) 一個時間序列T的第i個分割片段SEGi,是時間序列T分割后的第i個子序列。所以,時間序列T可以用分割片段表示為T={SEG1,SEG2,…,SEGm},其中m為此分割模式中子序列的數量。
定義4(狀態)子序列SEGi的狀態ci是指SEGi所屬的分類表示。
本文研究目標是將一條完整時間序列分成多個片段并對每一個子序列片段進行狀態識別。根據上文子序列和狀態的定義,一個時間序列的分割模式可以定義如下:
定義5(分割模式) 一個關于時間序列T的分割模式可以表示為S(T)={
SSR針對狀態類別已知的時間序列數據,使用有監督的方法建立分類模型。所需要的訓練集為帶有狀態標記的子序列集合。
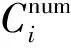
2.2 問題定義
根據上文描述,本文目標為尋找時間序列的一個分割模式,并根據已知限定信息找到每個段的狀態,使得這個分割模式能夠最大程度符合用戶的期望。此處給出一個形式化的問題定義如下:
定義7給定帶有狀態類別標記的訓練數據集TS和待分割時間序列T={t1,t2,…,tn},尋找T的最優分割模式S*(T)={
3 時間序列分割與狀態識別算法SSR
SSR基于特征高斯概率分布模型及概率最大化思想進行時間序列狀態識別,基于調整后的貪心策略進行時間序列分割,其中時間序列狀態識別主要分為2個過程,即建立特征高斯概率分布模型和計算匹配損失。
3.1 特征高斯概率分布模型
帶有良好標記的訓練集可以提供有價值的指導作用,基于有監督的方法可以獲得更符合用戶期望的分割模式,而能夠從訓練數據集中提取相關信息并合理利用是整個過程中的關鍵一步。本文通過對訓練集中同一類別的樣本數據提取相應特征,構建特征高斯概率分布模型。
3.1.1 特征選擇
首先應合理選擇需要從訓練集中提取的特征,從而更準確地描繪不同的序列。在綜合考慮各種特征指標之后,選定以下6個特征作為衡量標準,分別是樣本序列的長度、均值、標準差、過零率、擬合斜率以及根據擬合斜率所產生的均方誤差(Mean Squared Error,MSE)損失。
通過不同狀態類別樣本序列的平均值,結合序列的長度、標準偏差和過零率,可以得到該類別序列的近似振動程度。同時,通過斜率和MSE損失能夠對時間序列的趨勢進行大致判斷。通過上述6個特征,可以粗略描繪出不同狀態類別時間序列對應的特點。
3.1.2 特征高斯概率分布模型
特征模型是根據不同的狀態類別建立的。在訓練數據集中,每一個特征類別下都有多個樣本序列數據。在確定提取特征以后,對每一個狀態類別中樣本序列的每一個特征進行計算,同時記錄該特征值數值的均值和方差,以建立一個特征高斯概率分布模型,表示為M和Σ。Mi,j和Σi,j分別表示狀態類別i中的樣本序列集關于第j個特征值的均值和方差,計算公式為:
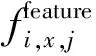
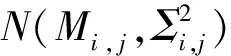
3.2 特征的權重約束設定
上文給出了特征選擇及特征高斯概率分布模型的建立過程。但是在真實場景的數據中時間序列的形態多樣,其特點屬性各異,在全部6個特征中,對于不同的時間序列,不同的特征對于狀態類別的區分度是不同的。所以,對于特征設定不同的權重約束是必要的。本文通過引入置信度分數來設定特征的權重約束,通過在訓練階段評估每個指標的分類性能來學習置信度分數。
在訓練階段,分別使用單一的特征進行類別區分,計算針對當前類型時間序列數據當前特征的分類準確度,再對6個對應的準確度分數進行歸一化處理,得到調整后的置信度分數w1,w2,…,w6作為每個特征的權重。
3.3 匹配概率及損失
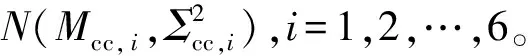
(1)
通過上述計算,可以得到對于一個T的分割模式S(T)={
(2)
其中,fSEGi,j表示SEGi第j個特征值。
在實際計算過程中,程序處理精度也是需要考慮的問題,由于1以內浮點數的運算會引入較大的誤差,因此需要對計算過程做進一步處理。在整體尋找最佳匹配狀態類別的過程中,關注的并不是概率的絕對數值,而是概率之間的相對關系,可以對匹配概率做如下處理:
對式(2)進行代數變換,得到:
(3)
定義匹配損失為:
(4)
將上文給出的權重約束引入損失計算,改寫式(4),可得到分割模式S的匹配損失為:
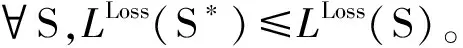
3.4 片段分割算法
SSR基于貪心的思想,通過迭代的方式進行時間序列的分割。
設對于時間序列T,當前已進行i-1輪分割過程,第i-1個分割片段的分割點為ri-1,第i輪的分割過程如下:
對于每一類別由下式進行匹配損失計算,得到ci,使得:
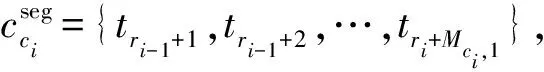
在確定當前分割片段的狀態ci以后,根據前一分割點ri-1、狀態ci長度特征的均值Mci,1和標準差Σci,1,對分割點ri的范圍進行限定,得到:
ri-1+Mci,1-3×Σc1,1≤ri≤ri-1+Mci,1+3×Σc1,1
最后,在限定范圍內逐點掃描,得到匹配損失最小的點ri作為具體分割點,使得:
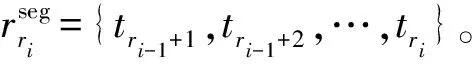
至此,得到
為避免單一類別匹配所產生的局部偏差造成全局的負面影響,本文對SSR的分割過程進行調整。在狀態類別匹配損失計算的過程中,不僅考慮當前分割片段SEGi的狀態類別,同時考慮下一序列片段SEGi+1的狀態類別,從而減小當前序列片段的影響程度。
在確定類別的過程中,每次使用2個狀態類別進行匹配損失計算,得到ci、ci+1,使得下式成立:
這種調整可減少當前片段的影響程度,從而減小局部偏差對全局的影響。
4 算法效率優化
為提升SSR的算法效率,本文提出了2種算法效率優化方式,即通過增加分割點的約束條件及采用增量計算的方式進行特征提取。
4.1 分割點約束條件
在上文介紹的算法過程中,對于分割片段SEGi具體分割點位置ri的選定,采用的是掃描并計算匹配損失的方式。顯然,在不靠近真實分割邊界的部分,相鄰點之間的匹配損失差值極小,逐點計算匹配損失會產生大量冗余的計算過程。
時間序列中狀態發生變化的位置,通常伴隨一個或多個特征大幅變化,稱時間序列中發生這樣巨大變化的點為特殊點。特殊點通常在時間序列上顯示為不一樣的形狀,例如拐點、峰值點等,而實際的分割點也更可能在這些特殊點中產生。因此,在算法過程開始之前首先預處理可能的候選分割點集,并在尋找具體分割點的過程中只掃描候選區間內的候選點,從中確定具體分割位置。具體求取方法為:以設定滑動窗口的方法求取窗口內各特征值的極值點,在對原始序列數值及每一個特征單獨判斷后,得到特殊點集合,即分割點候選集A。
那么,對于時間序列T的第i個分割片段SEGi,其狀態分類為ci,在尋找具體分割點ri時,約束條件為:1)ri∈[lci-3×dci,lci+3×dci];2)ri∈A。
這樣的處理方式,實際上是對掃描及對應的損失計算過程進行剪枝操作,從而在不影響精度的情況下降低運算量。
4.2 增量計算優化
在算法計算過程中,需要根據當前分割點截取序列并從子序列中提取特征,而如果每次均重新計算特征,顯然會帶來大量重復的計算。筆者通過分析選定的6個特征指標發現,平均值、標準偏差、斜率及過零率4個指標都可以通過預處理增量序列的方式減少冗余的計算過程。
在開始分割過程之前,計算待分割時間序列T的前綴和序列、平方前綴和序列及過零次數和序列。這樣在每次提取特征的過程中,不需要重復累加的過程,從而節省了大量的時間。同時采用文獻[17]的方法,將時間序列片段的擬合斜率及截距改寫為:
(5)
(6)
同理,在式(5)及式(6)中也可以使用前綴和序列進行增量計算,從而減少計算量。限于篇幅,此處不作展開說明。
4.3 時間復雜度估算
基于SSR的算法原理及2種優化方式,在整個分割及識別過程中,將大量的計算復雜度轉移到訓練階段,使預測階段的復雜度大幅減小。
由于整個時間序列分割及狀態識別過程的計算復雜度受分段模式選擇的影響較大,因此本文基于分段數量及子序列長度對預測過程進行計算復雜度的估算。
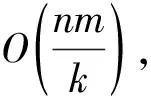
然而在實際情況中分割模式多樣,片段數量及片段長度都存在不同且差異巨大,并不能簡單地根據平均長度進行估算,且各特征特殊點常有重合或近似,也并不會對所有分割點都進行匹配。此處給出的復雜度僅為平均情況下的粗略估算值。
5 實驗及結果分析
針對本文算法SSR,在真實場景的數據集上進行多角度的實驗驗證。實驗主要從狀態識別的準確度、用戶意圖的匹配程度進行分析,并進一步對算法加以擴展,驗證其在多維數據上的效果,同時對優化方法的效果進行對比實驗。
5.1 實驗環境
實驗平臺基于Windows 10,64位操作系統,Intel?Core(TM) i7-7700K處理器,4.20 GHz主頻,帶有16 GB內存的臺式計算機。SSR算法使用Python語言實現。
5.2 數據集
本文實驗在以下3個真實場景的數據集上進行:
1)PAMAP行人運動數據集,下文簡稱運動數據集。PAMAP是一種有氧運動數據監測方案,用于記錄老年人身體的監測數據。此數據監測系統監測受試者的全球活動,識別基本的有氧活動并估計其強度水平[18-19]。整個數據集包含6個被試,每個科目有40多個維度的數據,主要包括4種類型的監測傳感器數據,即心率、IMU手部監測、IMU胸部監測和IMU足部監測數據,其中共7種運動狀態:步行非常慢,正常步行,越野行走,跑步,騎自行車,跳繩和踢足球,其中每個時間序列長度約180 000。
2)衛星桌面聯試試驗數據集,下文簡稱衛星數據集。此數據集源自于真實的衛星桌面在線試驗,記錄了衛星運行的指標。實驗主要關注電池電壓和姿態控制的變化。電池電壓序列包括3種不同的充電和放電過程,姿態控制包括2種不同的運動狀態,其中所有序列的長度均為207 908。
3)地鐵運行工況監測數據集,下文簡稱地鐵數據集。此數據集記錄了真實的地鐵運行的監測數據,通過安裝在內部托架上的傳感器監測地鐵運行過程。本文實驗主要關注速度和角速度序列。此數據集包括加速、減速、勻速和轉彎4種運行狀態,其中每個時間序列數據的長度均為94 221。
真實場景的數據對應于現實世界物理對象的活動。對于所有實驗,本文將數據集中約70%的數據設置為訓練集,其余作為測試集。
5.3 序列分割與狀態識別實驗
時間序列的分割及狀態識別是時間序列分析的經典主題。本文實驗中選用pHMM[6]和AutoPlait[8]作為對比算法。AutoPlait是一個無參數算法,pHMM由seg_error和rel_error 2個參數控制,實驗中將調整pHMM的參數以獲得更好的結果。
圖1和圖2展示了衛星數據集和地鐵數據集的實驗結果,每組結果的第一張圖為原始標簽的分割及狀態展示,后三組結果分別為SSR、AutoPlait和pHMM的實驗結果。由于pHMM運算規模的限制,在運動數據集上僅能使用1/4長度的序列進行實驗。圖1(d)中seg_error和rel_error分別為0.1和4.0,圖2(d)中則分別為0.1和0.8。
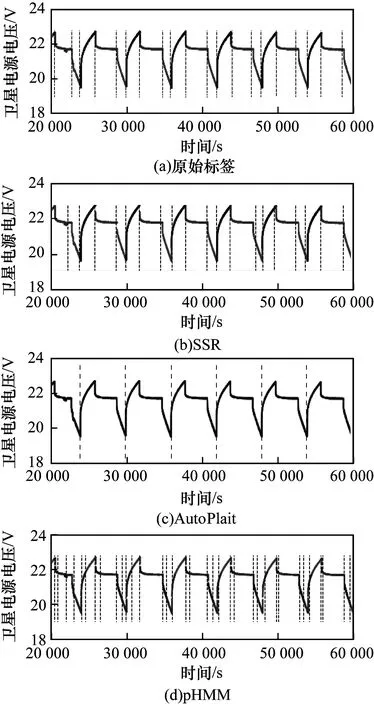
圖1 在衛星數據集上的實驗結果1
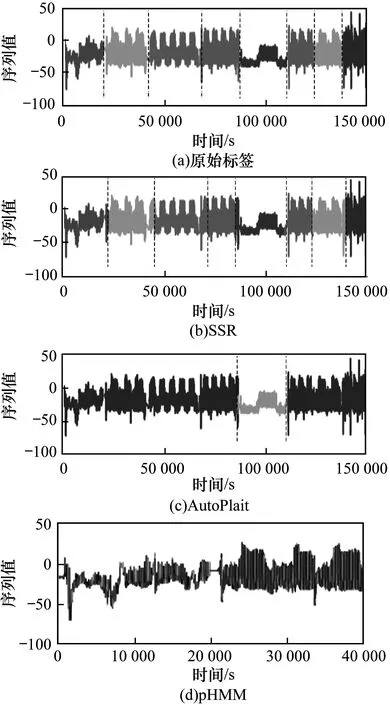
圖2 在地鐵數據集上的實驗結果1
在兩組實驗下,SSR都顯示了其優越性。pHMM使用長度和斜率來描述序列,AutoPlait通過平均值和方差來區分序列類別。SSR采用了6種特征對序列進行描繪,可以全面地表達狀態類別,展現了其在狀態類別區分的明顯優勢。從特征選擇上,AutoPlait很難對具有穩定均值和方差的序列進行分割。因此,AutoPlait在這類序列中效果并不理想。pHMM展現了對狀態的識別優勢。在衛星數據集上,pHMM所得到的狀態結果區分明顯,但是難以與實際電池充放電過程相關聯;而在運動數據集上,pHMM得到分類結果非常雜亂。這兩種算法的分割和狀態識別結果均不理想。SSR在這兩組實驗中都有著比較好的表現,可以很明顯地區分衛星數據的充放電過程及不同的運動狀態。這是因為使用了6個特征識別狀態類別,可以對序列進行更精細的描繪。在SSR的分割結果中,分割點仍然存在一定的偏差。這樣的誤差產生主要是由于被試者之間的個體差異非常大,例如被試的年齡、性別、身高和體重。相對于整個序列的長度和狀態類別的多樣性,這樣的誤差是可接受的。
此外,pHMM和AutoPlait均只能獲得單一的分割模式。經過參數調整后,pHMM的結果顯示了一定的周期性。然而,pHMM結果的周期性顯然不符合通常理解下對于周期性的要求。而SSR可以根據用戶意圖實現不同的分割模式。通過對比實驗結果可知,相比pHMM和AutoPlait,SSR在時間序列狀態識別和分割中性能更好。
表1中給出了本文算法在3種數據集上的實驗結果準確度,其中狀態分類準確率表示正確識別狀態的序列片段比例,最大分割點誤差表示在正確狀態識別的分割片段中的最大的誤差值占序列總長度的比例。所有的實驗均得到與用戶的意圖一致的分割模式。
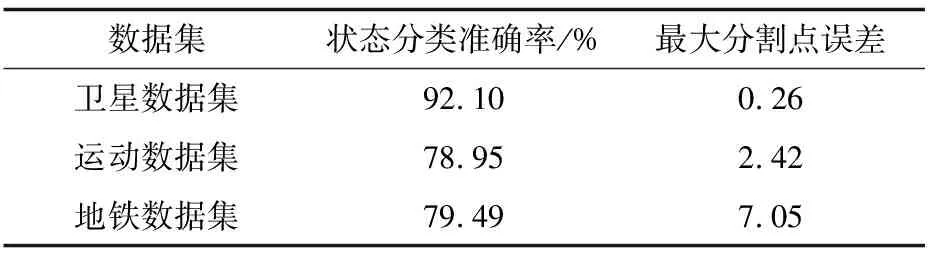
表1 實驗結果準確度統計
5.4 用戶意圖理解實驗
獲得與用戶意圖一致的分割模式是SSR主要期望實現的目標,用戶意圖理解實驗在衛星數據集上進行。
對于衛星數據集,主要關注每個指標的電壓和位置數據的狀態變化。通過圖3(a)上的標注,可以看到3個非常明顯的狀態變化點,圖3(b)中則顯示了一個衛星電源電池電壓變化過程中充電和放電3個階段:充電過程,緩慢放電過程及迅速放電過程。
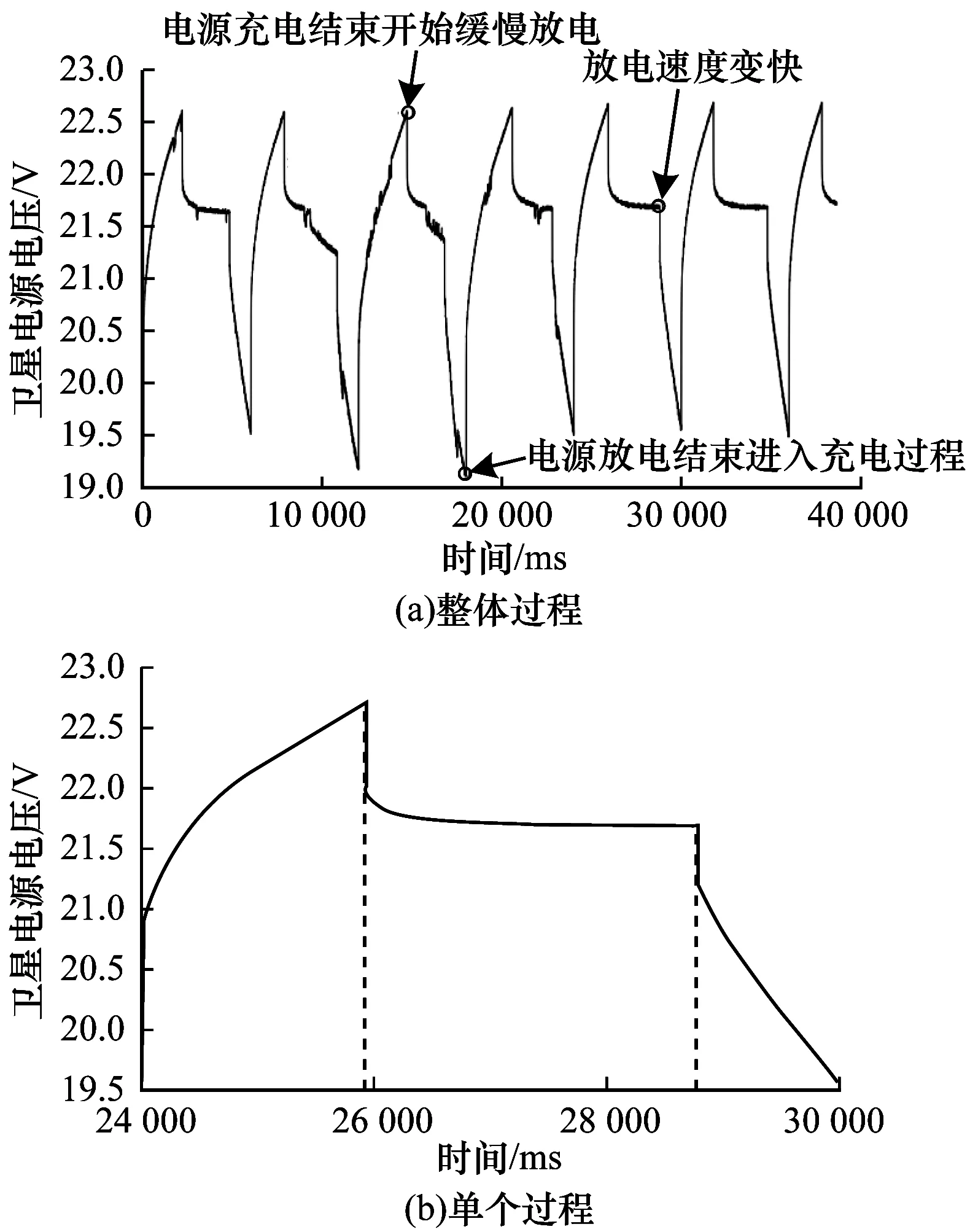
圖3 衛星電源電池數據形態示意圖
實驗針對整個過程設計了2種分割模式的訓練集:考慮單個充放電為一個狀態類別(模式1)以及考慮一個完整充放電周期為一個狀態類別(模式2)。同樣的模式分割方法也適用于姿態控制序列。圖4和圖5分別展示了本文算法針對2種分割模式的結果。其中,圖4為電池電壓序列上的實驗結果,圖5為姿態控制序列上的實驗結果。可以明顯看出,SSR可以根據用戶設定進行序列的分割及狀態識別,并得到2種不同分割模式的結果,而且分割位置的結果也比較準確。由此可知,SSR可以很好地理解用戶的意圖并獲得相應的分割模式。
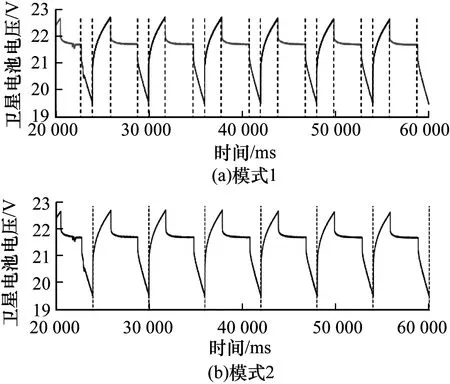
圖4 在衛星數據集上的實驗結果2
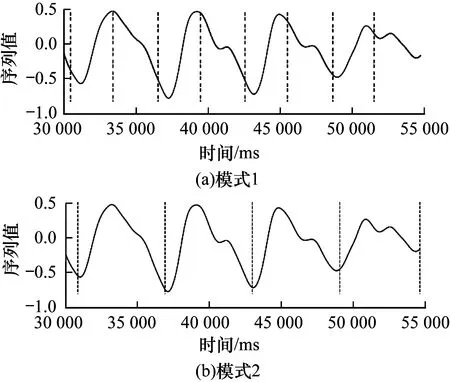
圖5 在衛星數據集上的實驗結果3
5.5 多維擴展實驗
在本文研究中,期望算法能夠具有更好的擴展性。多維擴展實驗在地鐵運行監測數據集上進行,實驗結果如圖6所示。
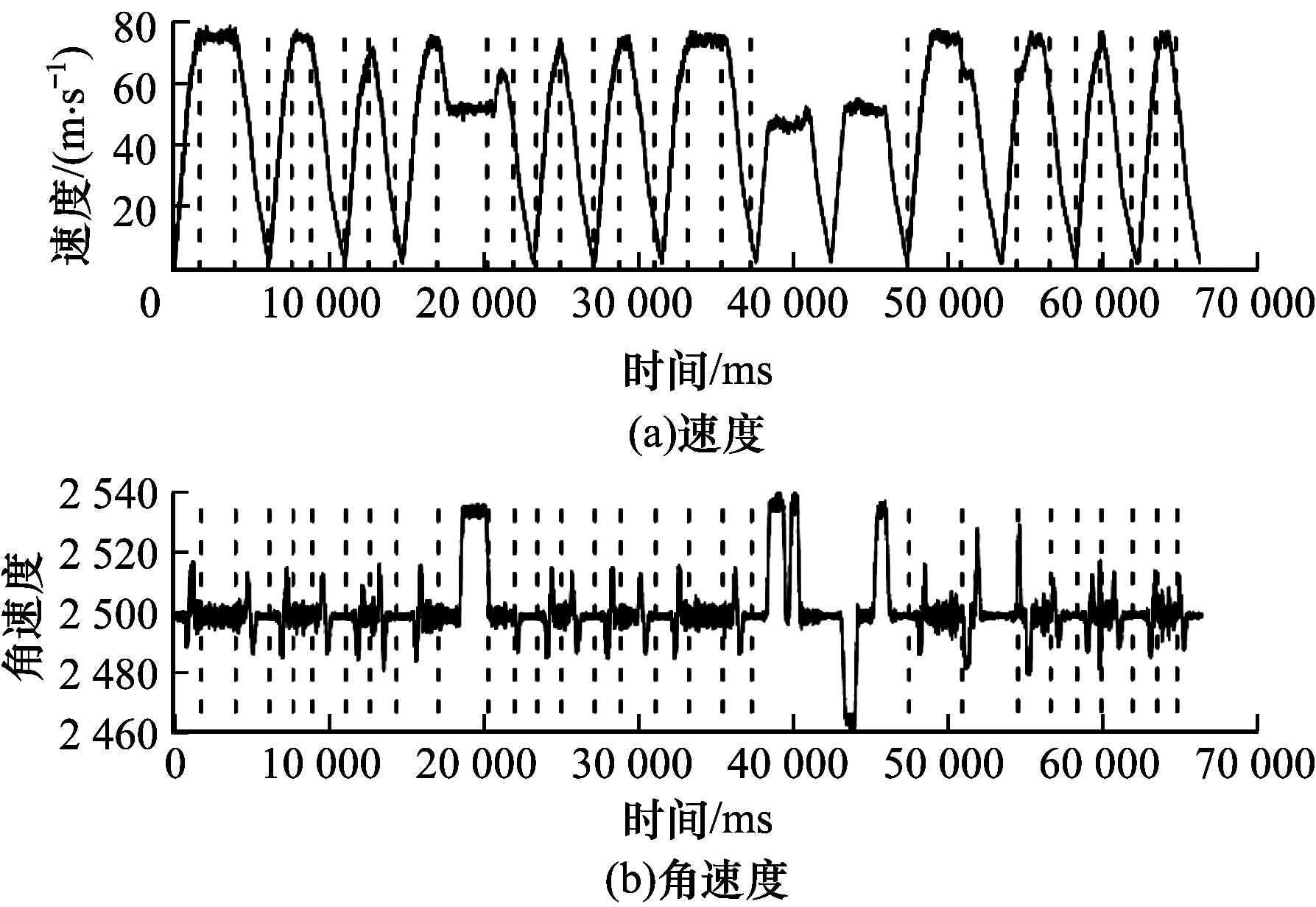
圖6 在地鐵數據集上的實驗結果2
從圖6可以看出,在速度序列中,SSR算法可以區分4種運行狀態,即加速、減速、勻速與轉彎;在角速度序列中,只關心是否處于轉彎狀態。可以看出,在角速度序列上,幾乎所有轉彎與非轉彎狀態都可以很好地區分。對于速度序列,在加速與減速過程中,斜率特征可以起到良好的區分作用。而針對于勻速與轉彎的狀態,在角速度序列上的均值特征有著明顯的不同,從而可對不同的狀態加以區分。
5.6 優化驗證實驗
優化驗證實驗在運動數據集上進行。在優化實驗中,對比了基礎版本的算法(basic-SSR)、增加了增量計算的基礎算法(incre-SSR)以及添加全部優化的最終算法(SSR)的效率。3個版本的算法在分割準確度上沒有明顯的區別。運行時間對比結果如圖7所示,可以看出,增加了優化策略以后,在實驗結果準確度幾乎沒有改變的情況下,時間效率獲得了大幅的提高。
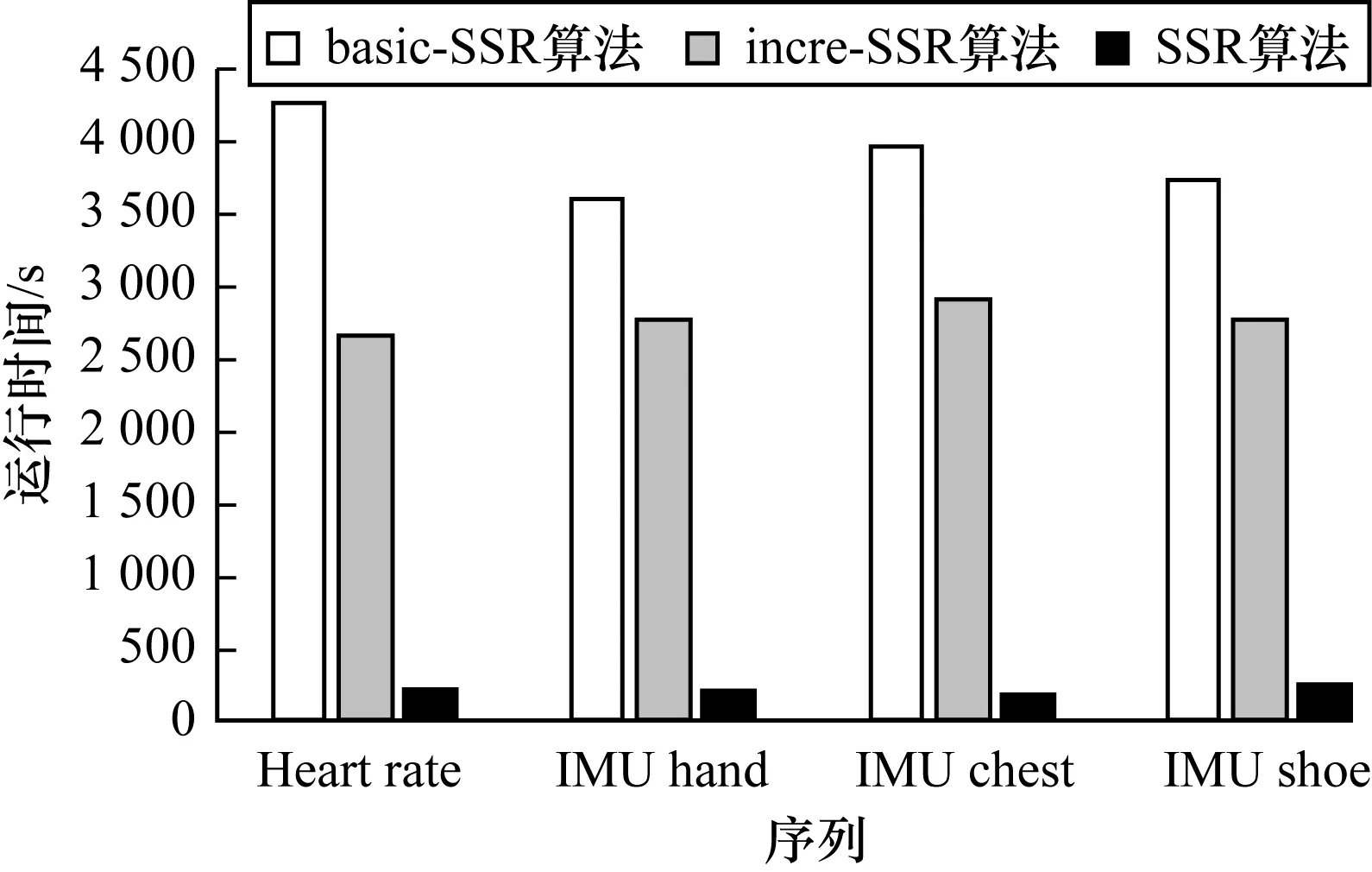
圖7 算法優化前后的運行時間比較
6 結束語
針對同一時間序列有多種可解釋分割模式的情況,本文提出一種有監督的時間序列狀態識別方法,以期獲得與用戶意圖一致的時間序列分割結果。通過建立特征高斯概率分布模型,設定特征的權重約束,利用概率最大化的思想判斷狀態類判別,基于調整后的貪心策略的進行序列分割,同時設計算法的效率優化策略與多維擴展方式。在真實場景數據集上的實驗結果驗證了本文研究的有效性與可擴展性。為進一步提高算法的可擴展性,后續將擴展有關優化策略,并基于Apache Spark[20]等分布式計算平臺實現本文算法及相應的優化剪枝策略,以應對分布式情景下更大數據規模和更高效率要求所帶來的技術挑戰。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
