一種分類型矩陣數據的初始聚類中心選擇算法
2020-05-20 10:22:48曹付元余麗琴
計算機工程 2020年5期
關鍵詞:定義
田 璐,曹付元,余麗琴
(1.山西大學 計算機與信息技術學院,太原 030006; 2.計算智能與中文信息處理教育部重點實驗室,太原 030006)
0 概述
在數據挖掘中,多數算法的輸入是由n個對象組成的一個集合,每一個對象對應一條記錄且被多個屬性所描述[1]。然而在實際應用中,一個對象的描述常常不止一條記錄,通常由多條記錄描述的對象稱為矩陣型對象,由矩陣型對象構成的數據集稱為矩陣數據集,即由包含多條記錄的對象組成的數據集。例如,在超市購物時,每個用戶購買的商品不僅種類不同,而且在購買同一種商品時,購買的商品數量和頻率也不相同。通常,可以根據人們購買一個商品的數量和頻率來預測該用戶是否喜歡這個商品。因此,矩陣數據蘊含了豐富的用戶行為特性,對于行為分析具有重要的價值[2]。
在實際生活中,矩陣數據廣泛存在于通信、超市、銀行、保險以及各大電子商務應用領域。為了給用戶提供更好的服務,需要挖掘這種數據中潛在的有用信息并加以利用。然而,在實際應用中大部分矩陣型數據沒有標記,如果給全部數據進行標記,需要耗費大量的人力物力,代價昂貴。通過無監督學習來對這類型數據進行分析是一種最直觀的方法,其中聚類是無監督學習中一種最廣泛的應用。文獻[3]提出了k-mw-modes聚類算法來處理分類型矩陣數據,該算法定義了一個新的相似性度量公式來計算兩個分類型矩陣對象之間的距離,并且給出了一種新的啟發式方法去選擇類中心。但是該算法是在隨機選取初始類中心之后,通過不斷地迭代更新聚類中心實現數據的劃分,容易受到不同初始類中心對聚類結果的影響。為了找到一個更好的解決方案,該類型算法需要多次使用不同的初始類中心來重新運行。此外,隨機初始化類中心的方法只有在類的個數較少且至少有一個隨機初始化結果接近于一個好的解決方案時才有效。因此,初始類中心的選擇對劃分聚類算法是非常重要的,有必要發展一種面向分類型矩陣數據的初始類中心選擇算法以獲得更好的聚類效果。
針對分類型矩陣數據,本文根據屬性值的頻率定義了矩陣對象的密度和矩陣對象間的距離,擴展了最大最小距離算法,在此基礎上,提出一種面向分類型矩陣數據的初始類中心選擇算法(An Initial Cluster Center Selection Algorithm for Categorical Matrix Data,IC2SACMD)。
1 相關工作
聚類是數據挖掘中一個非常重要的研究方向,也是無監督學習中使用最廣泛的一種方法[4]。聚類算法是基于數據的內部結構來尋找觀察樣本的自然集群。在實際應用中,聚類算法也是一種尋找不同用戶群最普遍的方法,使用案例主要包括細分客戶、新聞聚類、異常點檢測[5]和網絡識別等。在k-type聚類算法中,初始類中心的選擇至關重要。根據數據類型的不同,初始類中心的選擇算法可分為數值型數據和分類型數據初始類中心選擇算法。針對數值型數據,研究人員提出幾種解決初始化類中心問題的方法[6-8]。相應地,針對分類型數據,研究人員提出了多種解決初始類中心的方法[9-11]。最常見的方法是從數據集中選擇前k個不同的對象作為初始類中心。為了避免隨機選擇初始類中心對聚類結果的影響,文獻[9]將由每個屬性下頻率最高的屬性值組成的向量作為初始類中心。雖然文獻[9]提出的方法使初始中心多樣化,但是對于初始k個中心的選擇還沒有給出統一的準則。文獻[10]提出一種基于密度和距離的方法,通過計算對象自身的密度及對象間的距離來選取初始類中心。雖然該方法一定程度上避免了離群點、初始類中心過于密集的問題,但是在計算密度的過程中沒有考慮到不同屬性之間的差異、數據對象作為聚類中心的準確性以及第一個類中心的選取可能為全部數據集正中間的一個數據對象。文獻[11]提出了一種新的初始化類中心的方法,雖然考慮到數據對象作為類中心聚類的不精準性,并且避免了第一個類中心可能位于全部數據集正中間的一個密度最大值點的情況,但是在計算密度過程中,采用對象間的平均距離作為相似度,該算法也沒有考慮到不同屬性間的差異性。以上初始類中心算法都應用于每個對象僅由一個特征向量描述的數據集,目前筆者尚未發現針對分類型矩陣數據在選擇初始類中心方面的相關工作。
2 k-mw-modes算法
k-mw-modes算法是面向分類型矩陣數據的k-type聚類算法,主要由3個部分組成:1)聚類中心的表示;2)將對象分配到聚類中;3)更新聚類中心。該算法定義了兩個矩陣對象之間的距離公式,給出一種更新類中心的方法。
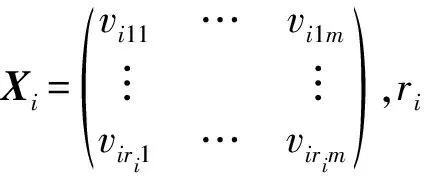
2.1 矩陣對象間的距離
給定兩個矩陣對象Xi和Xj,每個對象由m個分類型屬性{A1,A2,…,Am}來描述,則Xi和Xj的距離公式定義為:
(1)
其中:
(2)
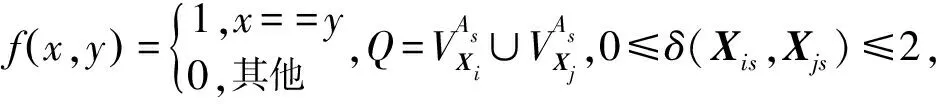
2.2 多加權模式聚類中心
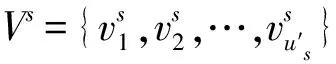
(3)
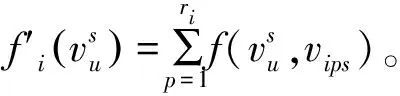
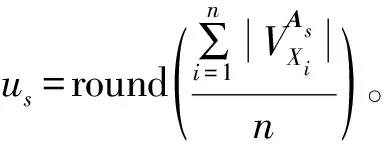
k-mw-modes算法對分類型矩陣數據進行了聚類,但是該算法隨機選取初始類中心,沒有考慮到隨機初始類中心的不穩定性以及必須至少存在一種較優的初始類中心選擇才會得到有效的聚類結果。
3 初始類中心選擇算法
目前許多專家學者提出了多種方法來度量數據對象間的內聚性[10-12]。最常見的一種方法是使用數據對象與全部數據對象之間的平均距離來測量數據對象的密度[12],因為其簡單且沒有參數。而對于矩陣數據集,對象Xi對應ri條記錄,并且每個對象在每條屬性上有多個屬性值,即vips表示對象Xi在As屬性上的第p個屬性值,則需要考慮到同一屬性上不同記錄之間的差異性。因此,本文根據屬性值的頻率來定義對象的平均密度。
3.1 基本定義
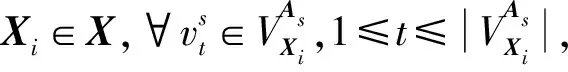
(4)
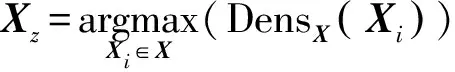
為便于理解,下文給出一個計算矩陣對象的平均密度示例,如表1所示。

表1 矩陣對象的平均密度
根據式(3)計算出在每個屬性上各個記錄值的權重。
在A1屬性上:

在A2屬性上:
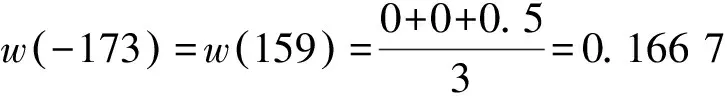
在A3屬性上:
根據式(4)計算每個對象的平均密度如下:
DensX(X1)=w(42)+w(-198)+w(-191)+
w(-109)+w(-142)+
w(-110)=2.333 3
DensX(X2)=w(42)+w(-198)+w(-191)+
w(-190)+w(-199)+
w(-142)+w(-102)=2.000 0
DensX(X3)=w(40)+w(42)+w(-191)+
w(-173)+w(-159)+
w(-142)+w(-63)=1.333 5
可得出對象X1的平均密度最大。
定義2給定數據對象Xi∈X(Xi≠Xz),Xi作為類中心的代表能力定義為:
Pro_Repre(Xi)=DensX(Xi)×d(Xi,Xz)
(5)
圖1中的數據集被分為兩類,Xz為密度最大值對象,其處于兩個類的邊界處,所以不能很好地代表一個類,則需尋找一個自身密度大的對象,且與Xz距離最遠,如圖1中E1,相對于一個虛擬類中心C1,E1并不能充分地表示類簇,因此不將E1作為初始類中心,而應該在E1周圍選擇一個合適的虛點C1作為初始類中心。
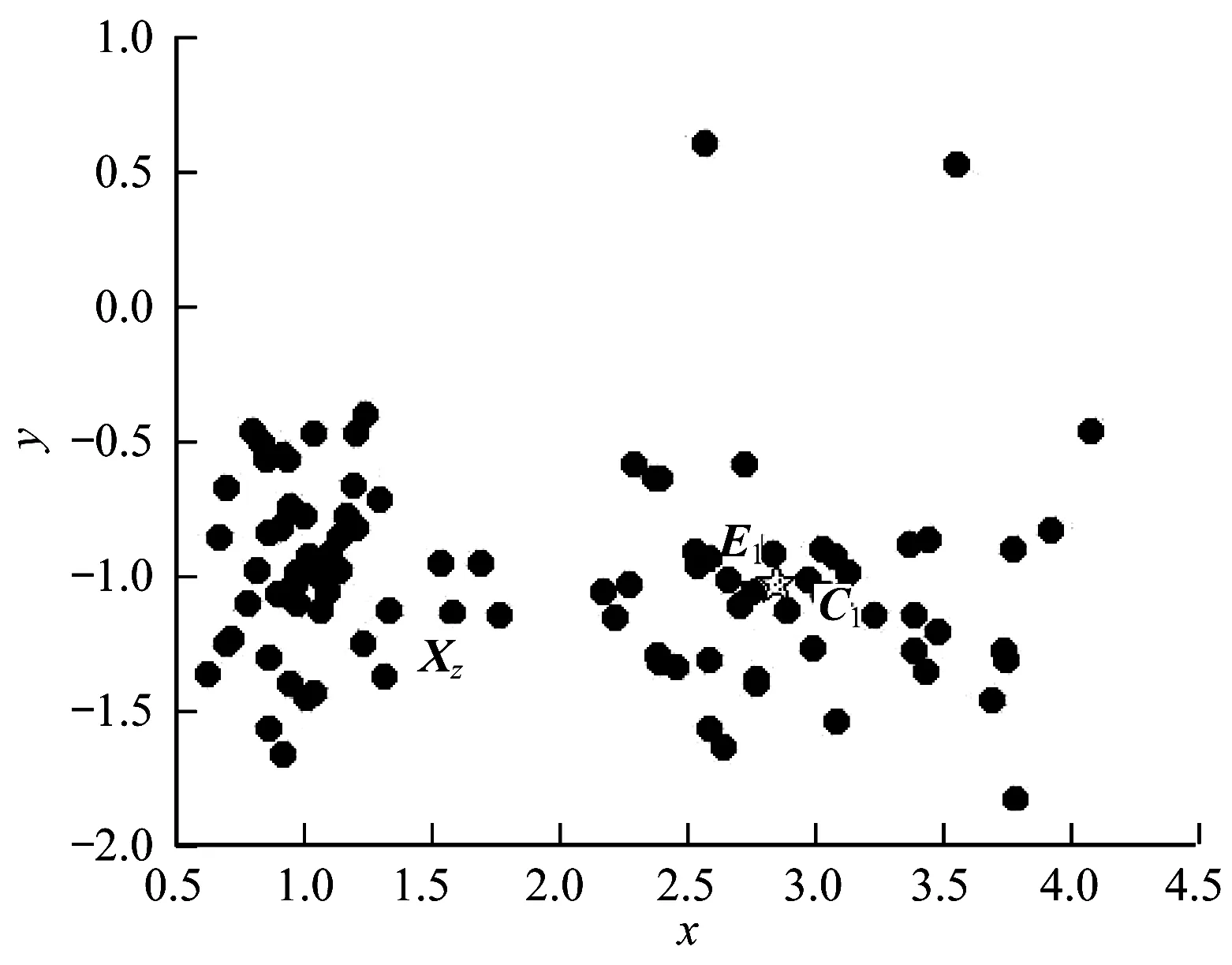
圖1 E1作為類中心差的情況
本文基于所選的類中心代表能力最強的點E1來構造多個候選對象集合,通過每個集合可以得到一個虛點作為候選類中心。下面給出候選對象集合的定義和求取候選類中心的定義。
定義3設Ca_Sets(1≤s≤m)是第s個候選對象集合,被定義為:
Ca_Sets={Xi∈X|d(Xi,E1)≤s}
(6)
根據式(3),可以計算出Ca_Sets的類中心cas。令Ca_Cluster1={ca1,ca2,…,cam}。
對于任意的兩個矩陣對象Xi和Xj,滿足0≤δ(Xis,Xjs)≤1,且0≤d(Xi,Xj)≤m。因此,可以根據對象與E1的距離得到m個候選對象集合,第s個集合Ca_Sets是由與E1的距離小于等于s的對象構成的。隨著屬性s的增加,Ca_Sets集合中的對象數也會逐漸增加。也就是說,cas+1會比cas包含更多的對象信息。因為當s=m時,Ca_Sets=X,此時cas是全部數據對象聚類得到的一個候選類中心。可見Ca_Sets包含過多的對象會削弱cas對第一個類的代表性。可見對于s的取值,并不是越大越好。
采用Microsoft Excel 2016軟件對實驗數據進行分析及制圖,并采用SPSS18.0和Design-Expert 8.0.5對數據進行統計分析,顯著水平p<0.05。
若只考慮DensX(cas)最大,則只能說明cas周圍鄰居對象數最多,但不能保證cas與E1距離最近以及不能避免cas是邊界點,因此還需要考慮到d(cas,E1),并且保證cas與密度最大值對象Xz距離最遠。
定義4令Xz(Xz∈X)為密度最大值對象,E1∈X(E1≠Xz)為第一個類中心代表能力最強的點,cas(cas∈Ca_Cluster1)為第一個類的第s個候選類中心,則cas作為類中心的能力為:
Pro_Center(cas)=DensX(cas)+d(cas,Xz)-d(cas,E1)
(7)
令C1=argmaxcas∈Ca_Cluster1Pro_Center(cas),則C1為第一個類中心,即在候選類中心集合中選擇一個離密度最大的對象Xz最遠、自身密度最高,且更接近于E1的候選類中心作為新的類中心。因為所選擇對象的密度越大意味著其周圍鄰居對象數越多,此外離密度最大值點越遠意味著其成為每個類邊界點的可能性越小,并且需更加接近于類中心代表能力最強的點。圖2為第一個類中心生成過程。
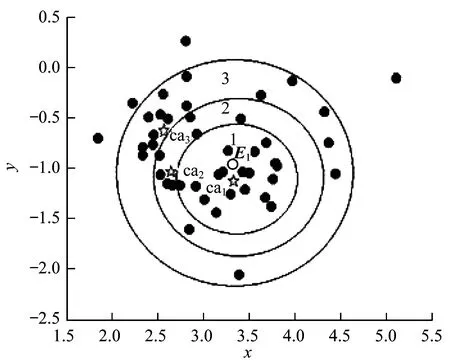
圖2 第一個類中心的生成過程
從圖2可以看出,空心點表示生成的第一個類中心代表點E1。根據式(6)生成多個候選集合Ca_Sets,其中圈1中的對象表示集合Ca_Set1中包含的對象,同理,圈2和圈3分別表示Ca_Set2和Ca_Set3中包含的對象,且Ca_Set3?Ca_Set2?Ca_Set1。圖2中的五角星是生成的3個候選類中心{ca1,ca2,ca3}。根據定義4得出第一個新的類中心為ca1,記為C1。
定義5給定Xi∈X,k′∈{2,3,…,K},則第k′個類中心代表能力定義為:
(8)
其中,Ck表示第k個類中心。取Pro_Repre(Xi)的最大值所對應的對象作為第k′個類中心代表能力最強點,即:
Ek′=argmaxXi∈X,Xi?{E1,E2,…,Ek′-1}Pro_Repre(Xi)
則cas(cas∈Ca_Clusterk′)作為第k′個類中心的能力為:
Pro_Center(cas)=DensX(cas)+
(9)
其中,Ck′=argmaxcas∈Ca_Clusterk′Pro_Center(cas)為第k′個類中心。對于其他類中心的選擇,本文考慮到對象與所選出的類中心之間的距離,距離越大說明該對象與選出的其他類中心差異越大,能很好地代表一個類中心,同時采用最大最小距離算法用于計算其他類中心。
3.2 算法流程
算法實現流程如下:
算法1IC2SACMD 算法
輸入X:由m個屬性描述的n個對象矩陣數據集;K:聚類個數
輸出數據集X的K個初始類中心C={C1,C2,…,CK}
1.初始化:C = φ;
2.fork′=1to K,do
3.if(k’==1)
4.根據式(3)和式(4)計算數據集X所有對象的平均密度,找出密度最大值的對象記為Xz;
5.對于除Xz之外的其他對象,根據式(5)計算每個對象的代表能力Pro_Repre(Xi)=d(Xz,Xi)×DensX(Xi);
6.獲得第一個類中心代表能力最強的點E1=argmaxXi∈X,Xi≠XzPro_Repre(Xi);
7.根據式(6)得出候選對象集合Ca_Sets(1≤s≤m);
8.通過候選對象集合得到候選類中心集合Ca_Cluster1;
9.對于集合Ca_Cluster1中的每個候選類中心,根據式(7)計算Pro_Center(cas)=DensX(Cas)+d(Cas,Xz)-d(Cas,E1);
10.獲得第一個類中心C1=argmaxcas∈Ca_Cluster1Pro_Center(cas);
11.else
12.for i=1to n,do
13.根據式(8)求得Xi作為第k′個類中心的代表能力Pro_Repre(Xi);
14.end for
15.獲得第k′個類中心代表能力最強的點Ek′=argmaxXi∈X,Xi?{E1,E2,…,Ek′-1}Pro_Repre(Xi);
16.for k=1to(k′-1),do
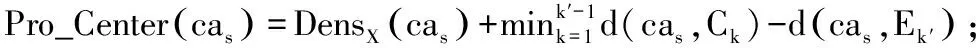
18.endfor
19.獲得第k′個類中心Ck′=argmaxcas∈Ca_Clusterk′Pro_Center(cas);
20.end if
21.C=C∪Ck′;
22.end for
23.return C.
4 實驗結果與分析
為驗證本文算法的有效性,在7個不同的真實數據集上進行實驗。對數據集進行簡單介紹,給出實驗所需評價指標,將算法與其他方法進行比較,并對實驗結果進行分析。
4.1 實驗數據
本文實驗使用了7個真實的數據集,其中musk[13]數據集是從UCI上下載,其余數據集是由Veronika Cheplygina整理[14]存放在(http://www.miproblems.org)網站上。mutagenesis[15]和musk是由藥物活性預測問題引起的,在這些數據集上,可將每個分子的每個形狀看作一個特征向量,由多個形狀構成的分子看作一個矩陣對象。mutagenesis根據難易程度分為兩種,即文中的mutagenesis1和mutagenesis2。ucsb_breast[16]是一個圖像數據集,可以從網址(http://www.bioimage.ucsb.edu/research/biosegmentation)上下載。elephant和tiger是從(http://www.cs.columbia.edu/~andrews/mil/datasets.html)下載的圖像數據集[17],可將每張圖片的一個分割部分看作一個特征向量,則多個分割部分合成的圖片就是一個矩陣對象。component[18]是從(http://www.biocreative.org/tasks/biocreative-i/task-2-functional-annotations/)下載的一個文本數據集,可以將每個段落看作一個特征向量,多個段落組成的一個文本就是一個矩陣對象。表3給出全部數據集的相關信息。

表3 實驗中使用的數據集
因為缺少公開的分類型矩陣數據集,且已有的分類型矩陣數據集的維度較低,對于計算屬性間距離有比較大的影響,所以本文用數值型矩陣數據集來驗證提出算法的有效性。由于數值型數據的屬性值是連續的,因此需要對其進行離散化處理。對于musk數據集,數據的屬性值是整數型,可以認為是離散型數據,則只需對除musk數據集之外的其余數據集進行歸一化處理,歸一化公式定義為:
(10)
然后將歸一化后的數據集進行均勻離散化處理,將其平均分成10份,相對應的值分別設置為{1,2,…,10}構成了實驗所需數據集。
4.2 評價指標
為評價本文提出的初始類中心算法的有效性,使用5個評價指標,即精度(AC)、查準率(PR)、召回率(RE)、標準互信息(NMI)[19]和調整蘭德指數(ARI)[20]評價算法的優劣[3]。
4.3 結果分析
為驗證本文提出的初始類中心選擇算法的有效性,將該算法與一種隨機初始化Random算法[3]進行了比較,并與另外兩種典型的初始類中心選擇算法CAOICACD算法[10]和BAIICACD算法[11]也進行了比較。對于初始類中心算法IC2SACMD、CAOICACD和BAIICACD,只需聚類一次即可。而對于實驗中的Random算法,由于該算法采取隨機初始化類中心,則需要對每個數據集進行50次聚類,將其均值作為最終的結果。由于目前在分類型矩陣數據上的相關工作較少,本文選用了針對普通分類型數據比較典型的兩種初始類中心選擇算法CAOICACD和BAIICACD來進行比較,因此需要將本文中的7個真實的數據集進行簡單處理,即先將矩陣數據集進行了壓縮,每個矩陣對象用頻率最高的屬性值來表示。在新生成的數據集中,一個對象只有一條記錄,然后將后兩種算法在新生成的數據集中進行實驗。本文實驗結果如表4所示,其中,表中加粗字體為不同算法針對每個數據集在不同評價指標上的最優結果。
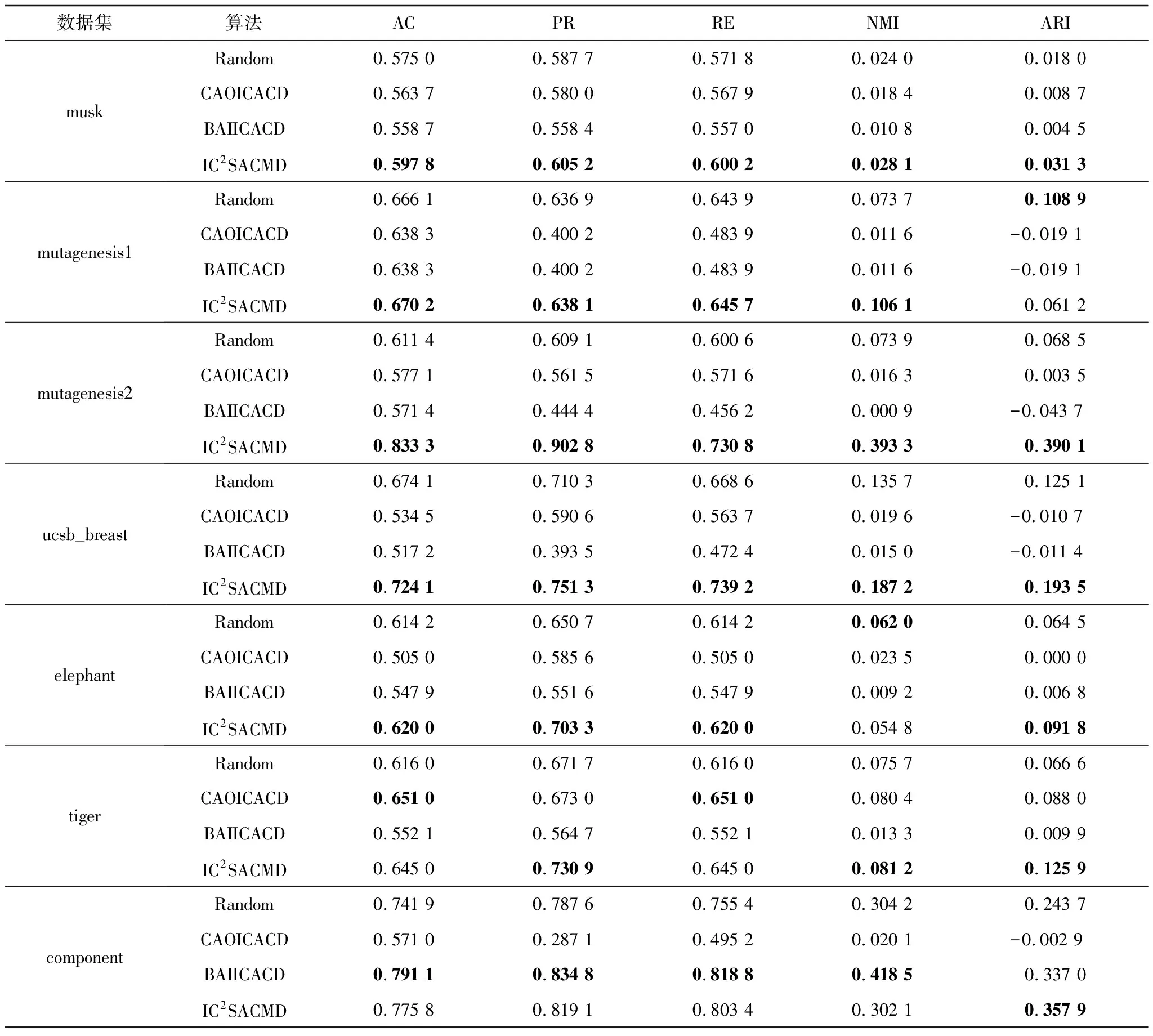
表4 不同算法在各數據集上的實驗結果
從實驗結果可以看出,在7個真實數據集上,本文IC2SACMD算法優于Random算法、CAOICACD算法和BAIICACD算法,并在5個評價指標上都產生了比較好的聚類效果,尤其是在mutagenesis2數據集上的聚類效果顯著,相比Random算法提高了22%的精度,相比ucsb_breast數據集提高了5%的精度。而CAOICACD算法和BAIICACD算法在不同數據集的5個評價指標上的效果相差不大,僅在tiger和component數據集上相差比較明顯,特別是BAIICACD算法在component數據集上達到相對最優,甚至超過了本文算法2%的精度,可見,BAIICACD算法在component數據集上效果更好。但是CAOICACD算法和BAIICACD算法因為數據集進行壓縮時,會導致許多信息的丟失,以至于精確度較低。
5 結束語
分類型矩陣數據在實際應用中廣泛存在。針對分類型矩陣數據,本文根據屬性值的頻率定義了矩陣對象的密度和矩陣對象間的距離,擴展了最大最小距離算法,從而實現初始類中心的選擇,在此基礎上,提出一種面向分類型矩陣數據的初始類中心選擇算法。實驗結果表明,與傳統初始類中心選擇算法相比,該算法具有較優的聚類效果。在未來的工作中將結合半監督學習來選擇初始類中心。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學生數理化(高中版.高考數學)(2021年3期)2021-06-09 06:09:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:38
中學生數理化(高中版.高二數學)(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護與修理(2015年6期)2015-02-28 12:16:55
當代修辭學(2014年3期)2014-01-21 02:30:44
