基于輕量級神經(jīng)網(wǎng)絡(luò)的人群計(jì)數(shù)模型設(shè)計(jì)
2020-05-18 07:30:58平嘉蓉張正華
無線電工程 2020年6期
關(guān)鍵詞:模型
平嘉蓉,張正華*,沈 逸,陳 豪,劉 源,楊 意,尤 倩,蘇 權(quán)
(1.揚(yáng)州大學(xué) 信息工程學(xué)院(人工智能學(xué)院),江蘇 揚(yáng)州 225127;2.揚(yáng)州蘇水科技有限公司,江蘇 揚(yáng)州 225000;3.揚(yáng)州國脈通信發(fā)展有限責(zé)任公司,江蘇 揚(yáng)州 225000)
0 引言
公共場所下密集人流量的實(shí)時統(tǒng)計(jì)對社會管理和公共安全具有重要意義[1]。人群計(jì)數(shù)可以用于商業(yè)管理,統(tǒng)計(jì)各個區(qū)域和出入口的行人流量,可以為商場的管理、服務(wù)和銷售等提供重要的參考指標(biāo)[2],進(jìn)一步研究、修改模型可以為智能交通車流量、智能水利下船數(shù)量的視頻統(tǒng)計(jì)輕量化打下基礎(chǔ)。
深度學(xué)習(xí)與傳統(tǒng)手工設(shè)計(jì)人群計(jì)數(shù)方法不同,深度學(xué)習(xí)利用端到端的方式訓(xùn)練神經(jīng)網(wǎng)絡(luò),自動提取目標(biāo)深度特征,避免主觀人為干擾,同時降低了手工設(shè)計(jì)的人力勞動成本[3]。人群計(jì)數(shù)是一項(xiàng)計(jì)算機(jī)視覺任務(wù),將人群圖像作為輸入,輸出相應(yīng)的人群密度圖,最后對密度圖進(jìn)行積分求和輸出最終結(jié)果[4]。隨著計(jì)算機(jī)視覺技術(shù)的逐步發(fā)展,大量的人群計(jì)數(shù)算法被提出,其中,深度學(xué)習(xí)領(lǐng)域核心的人群計(jì)數(shù)算法為Multi-CNN[5],Switch-CNN[6]和CSRNet[7]。本文采用VGG-16作為網(wǎng)絡(luò)框架進(jìn)行模型的搭建。
在實(shí)際的應(yīng)用場景中,不僅要求更高的檢測精度,為了達(dá)到實(shí)時性的要求,計(jì)算復(fù)雜度和模型大小也是重要的考慮因素,因此需要對網(wǎng)絡(luò)模型進(jìn)行壓縮,以減小網(wǎng)絡(luò)模型的參數(shù)量,同時保持網(wǎng)絡(luò)模型的檢測精度[8]。目前,精簡模型的主要方法為輕量級網(wǎng)絡(luò)的設(shè)計(jì),例如谷歌提出的MobileNet[9]、曠世科技的ShuffleNet[10]和SqueezeNet[11]等。本文利用Xilinx公司提供的神經(jīng)網(wǎng)絡(luò)量化工具DNNDK對網(wǎng)絡(luò)壓縮量化編碼,生成輕量級神經(jīng)網(wǎng)絡(luò),使人群計(jì)數(shù)得以在現(xiàn)場可編程門陣列(Field Programmable Gate Array,F(xiàn)PGA )上實(shí)現(xiàn)。
本文針對輕量級神經(jīng)網(wǎng)絡(luò)的生成及部署問題,選取FPGA的硬件加速器來提高計(jì)算效率,減小功耗。FPGA具有低功耗和可重構(gòu)性等特點(diǎn)[12],運(yùn)用Xilinx官方提供的神經(jīng)網(wǎng)絡(luò)量化工具,對訓(xùn)練好的網(wǎng)絡(luò)進(jìn)行量化壓縮編碼,生成適用于深度學(xué)習(xí)網(wǎng)絡(luò)的硬件加速器,最終在FPGA上實(shí)現(xiàn)人群計(jì)數(shù)。
1 基于VGG-16的卷積神經(jīng)網(wǎng)絡(luò)重構(gòu)
為了更好地實(shí)現(xiàn)人群計(jì)數(shù),同時考慮FPGA硬件計(jì)算能力有限,采用以結(jié)構(gòu)簡單著稱的VGG-16模型[13]。
VGG-16網(wǎng)絡(luò)模型共包含13個卷積層、3個全連接層以及5個池化層。在對VGG-16網(wǎng)絡(luò)的重構(gòu)中,考慮到硬件的計(jì)算能力,為實(shí)現(xiàn)縮小計(jì)算量的初衷,取VGG-16網(wǎng)絡(luò)中前10層卷積層作為基礎(chǔ)模型;以人群計(jì)數(shù)為目標(biāo),模型輸出應(yīng)為密度圖,為使輸出密度圖積分后得到人群數(shù)更準(zhǔn)確,在模型最后加入2層卷積層及1層上采樣層。該模型為生成輕量級神經(jīng)網(wǎng)絡(luò)奠定了基礎(chǔ),并確保了系統(tǒng)結(jié)果的精確性。VGG-16重構(gòu)后的網(wǎng)絡(luò)架構(gòu)如圖1所示。網(wǎng)絡(luò)中主要包含卷積層、池化層和上采樣層。
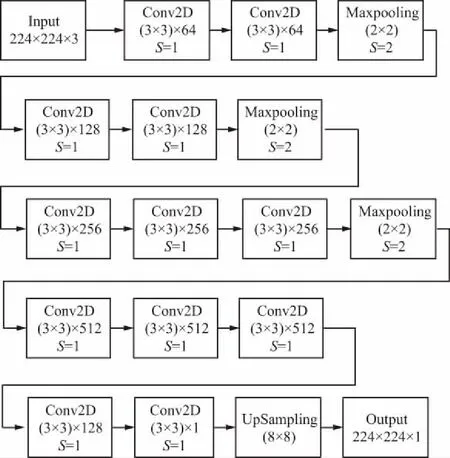
圖1 網(wǎng)絡(luò)架構(gòu)Fig.1 Network framework
卷積層主要用于提取特征。假設(shè)第q層為卷積層,第k-1層為輸入層,則第k層的卷積如下:
(1)
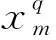
池化的主要作用是將特征圖分為多個區(qū)域,然后通過對各個區(qū)域求像素平均值或者最大值等來減小特征圖的尺寸,池化又稱為下采樣。本模型選取最大池化進(jìn)行池化操作。
假設(shè)第q層為池化層,第q-1層為輸入層,則第q層池化的計(jì)算如下:
(2)
式中,down為下采樣函數(shù);β為權(quán)重的參數(shù)。
上采樣層的主要目的是放大原圖像,從而獲取更高的圖像分辨率。由于對圖像的縮放操作并不能帶來更多關(guān)于該圖像的信息,因此圖像的質(zhì)量將不可避免地受到影響。
假設(shè)第q層為上采樣層,第q-1層為輸入層,則第q層上采樣的計(jì)算如下:
(3)
式中,up為上采樣函數(shù);β為權(quán)重的參數(shù)。
2 輕量級神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)及硬件部署
人工設(shè)計(jì)輕量級神經(jīng)網(wǎng)絡(luò)的主要思想在于設(shè)計(jì)更高效的網(wǎng)絡(luò)計(jì)算方式,主要是針對卷積的計(jì)算方法,通過合理減少卷積核的數(shù)量,減少目標(biāo)特征的通道數(shù),結(jié)合設(shè)計(jì)更高效的卷積操作等方式,從而構(gòu)造更加有效的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)[3]。本文為了對網(wǎng)絡(luò)模型輕量化,生成輕量級神經(jīng)網(wǎng)絡(luò),并將其部署到FPGA上,借助Xilinx?DNNDK量化工具進(jìn)行了容器化開發(fā)環(huán)境的搭建、模型的轉(zhuǎn)換、凍結(jié)與量化,生成輕量級神經(jīng)網(wǎng)絡(luò);借助Xilinx?深度學(xué)習(xí)處理器單元 (DPU)將其部署至FPGA上。
對改進(jìn)后的VGG-16人群計(jì)數(shù)模型進(jìn)行凍結(jié)操作,從而減少未參與推理的Op節(jié)點(diǎn);將原模型的權(quán)重文件與模型文件整合為一個文件,通過DNNDK工具,使模型權(quán)重由高精度范圍向低精度范圍直接進(jìn)行映射,從原有的FP32減少至INT8,得到的凍結(jié)模型縮小約2/3體積,完成模型的輕量化。模型體積對比如表1所示。
表1 模型體積對比 MB
Tab.1 Model size comparison

原模型凍結(jié)后的模型輕量化后的模型94.131.48.3
DPU是一個可配置的計(jì)算引擎,專用于網(wǎng)絡(luò)模型在FPGA上的部署。DPU需要指令來實(shí)現(xiàn)一個神經(jīng)網(wǎng)絡(luò)和可訪問的存儲位置,用于輸入圖像以及臨時輸出數(shù)據(jù),還需要在應(yīng)用程序處理單元(APU)上運(yùn)行的程序來服務(wù)中斷和協(xié)調(diào)數(shù)據(jù)傳輸。DPU頂層模塊如圖2所示,該單元包括一個高性能調(diào)度模塊,一個混合計(jì)算陣列模塊、指令獲取單元模塊和全局內(nèi)存池化模塊。
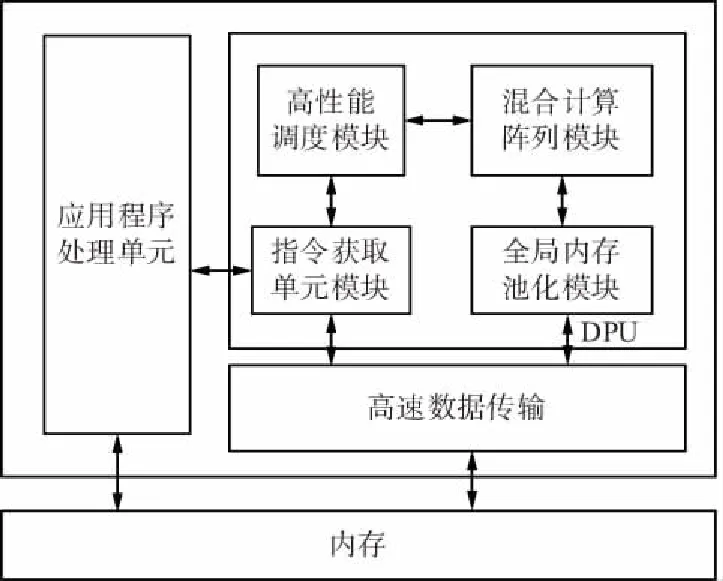
圖2 DPU頂層模塊Fig.2 Top-level module
為在PYNQ-Z2上進(jìn)行輕量級神經(jīng)網(wǎng)絡(luò)部署,配置完成DPU,實(shí)現(xiàn)FPGA人群計(jì)數(shù)的硬件系統(tǒng),通過系統(tǒng)時鐘的方式記錄了圖片加載時間以及任務(wù)執(zhí)行時間,配置基于X11協(xié)議的轉(zhuǎn)發(fā)及編寫計(jì)數(shù)顯示界面用以顯示運(yùn)算結(jié)果。利用X11協(xié)議編寫及轉(zhuǎn)發(fā)的計(jì)數(shù)顯示界面如圖3所示。
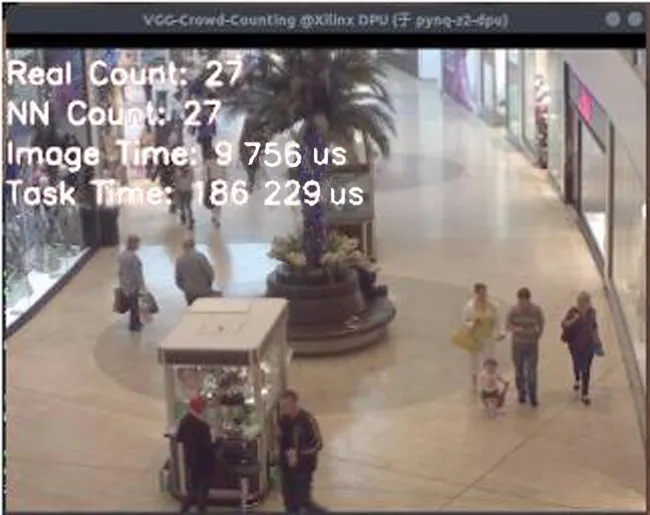
圖3 顯示界面Fig.3 Display interface
3 實(shí)驗(yàn)驗(yàn)證
本文基于如下平臺構(gòu)建:PC端CPU為E3 1231 v3,內(nèi)存容量16 GB,顯卡為Nvidia GTX980M,操作系統(tǒng)版本為Windows 10 LTSC 2019,以此作為網(wǎng)絡(luò)構(gòu)建、訓(xùn)練及量化環(huán)境。FPGA端采用Xilinx PYNQ-Z2開發(fā)平臺,平臺主要由2個Cortex A9內(nèi)核以及可編程邏輯設(shè)計(jì)單元構(gòu)成。
為了驗(yàn)證模型的有效性,本文進(jìn)行了數(shù)據(jù)集的選取、誤差函數(shù)的選取、網(wǎng)絡(luò)訓(xùn)練、經(jīng)過量化網(wǎng)絡(luò)生成輕量級神經(jīng)網(wǎng)絡(luò)以及硬件部署,得到關(guān)鍵性能指標(biāo)。
在人群計(jì)數(shù)利用方面,有許多帶有人工標(biāo)注的大型數(shù)據(jù)集,如UCF_CC_50[14],ShangHaiTech part A and B[15],Mall Dataset[16],WorldExpo’10[17]以及UCSD[18]。本文利用了香港中文大學(xué)提供的Mall Dataset數(shù)據(jù)集用以訓(xùn)練基于VGG的人群計(jì)數(shù)網(wǎng)絡(luò),該數(shù)據(jù)集包括了2 000張標(biāo)注好的人群數(shù)據(jù)圖像,同時尺寸統(tǒng)一為480×640×3。本文將Ground Truth的數(shù)量級提升100倍,便于網(wǎng)絡(luò)收斂。用FPGA的量化特性指導(dǎo)網(wǎng)絡(luò)優(yōu)化,提高準(zhǔn)確率,方便進(jìn)行訓(xùn)練。
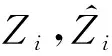
① 平均值絕對誤差(MAE)。通過計(jì)算測試集中估計(jì)人數(shù)與真實(shí)人數(shù)的平均絕對誤差獲得,反映了模型對于測繪及人數(shù)基數(shù)的準(zhǔn)確性,如下:
(4)
② 平均平方誤差(MSE)。通過計(jì)算測試集中估計(jì)人數(shù)與真實(shí)人數(shù)的MSE獲得,反映了模型對于測試集人群基數(shù)的準(zhǔn)確性和穩(wěn)定性,如下:
(5)
在PC端使用Keras構(gòu)建基本網(wǎng)絡(luò)結(jié)構(gòu),進(jìn)行了網(wǎng)絡(luò)模型的訓(xùn)練及參數(shù)的調(diào)整。網(wǎng)絡(luò)輸出的人群密度圖如圖4所示。
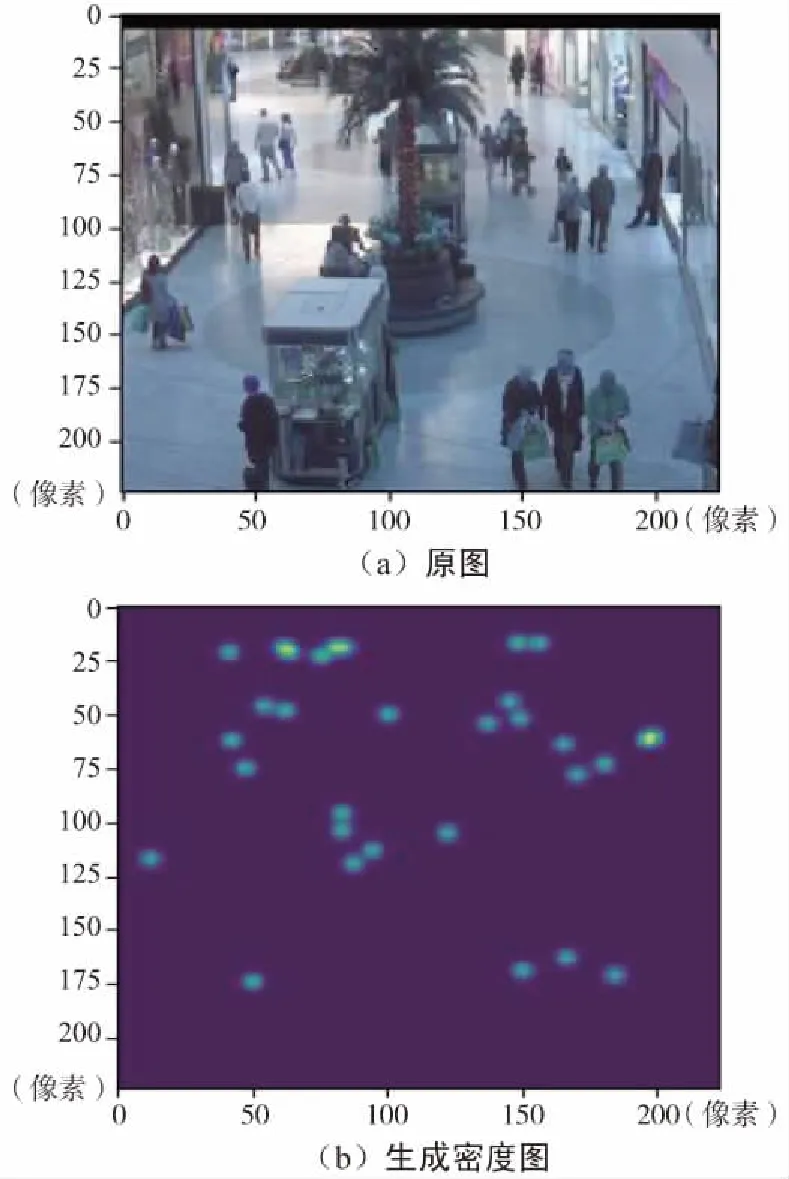
圖4 密度圖Fig.4 Density map
最后,將其量化生成輕量級神經(jīng)網(wǎng)絡(luò)后并部署在FPGA上,DSP利用率達(dá)到95.91%,并且分析得到如表2所示的關(guān)鍵性能指標(biāo)。
表2 性能對比
Tab.2 Performance comparison

PlatformPCPYNQ-Z2DeviceE3 1231 v3 GTX980Zynq Z7020Clock Freq.3.40 GHz150 MHz(DPU)Memory16 GB DDR3L512 MB DDR3FPS76.92幀/秒5.38幀/秒Power220 W4.763 WEfficiency0.35 FPS/W1.13 FPS/WMSE18.418.4
可見,PYNQ-Z2平臺相比于PC平臺的功耗比突出,而且在量化后,性能指標(biāo)也大致相同,由此可見,輕量級神經(jīng)網(wǎng)絡(luò)性能與卷積神經(jīng)網(wǎng)絡(luò)性能并無下降,同時,將輕量級神經(jīng)網(wǎng)絡(luò)部署于FPGA上大大提高了能效比,對未來的生產(chǎn)投入有重要意義。
4 結(jié)束語
通過對現(xiàn)有模型的改進(jìn)與密度圖的增量處理,使人群計(jì)數(shù)模型效果更好,該系統(tǒng)的均方誤差量化后可達(dá)到18.4。將卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行量化生成輕量級神經(jīng)網(wǎng)絡(luò),部署于FPGA中,并通過FPGA并行化操作處理運(yùn)算,實(shí)現(xiàn)對神經(jīng)網(wǎng)絡(luò)推斷的加速以及輕量級神經(jīng)網(wǎng)絡(luò)的準(zhǔn)確性及低功耗性。利用PYNQ-Z2特性,合理調(diào)度CPU和FPGA,使ARM端與FPGA端軟硬件協(xié)同工作,讓技術(shù)應(yīng)用落地,有效提高了人群計(jì)數(shù)網(wǎng)絡(luò)的能效比,對其應(yīng)用于便攜式設(shè)備提供了參考。本文仍需要擴(kuò)展訓(xùn)練集和訓(xùn)練次數(shù),增加準(zhǔn)確率;優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu),增加執(zhí)行效率,使其性能表現(xiàn)更優(yōu)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
