基于深度遷移學(xué)習(xí)的窄帶雷達(dá)群目標(biāo)識別方法
2020-05-18 02:36:22梁復(fù)臺李宏權(quán)張晨浩
兵器裝備工程學(xué)報 2020年4期
梁復(fù)臺,李宏權(quán),張晨浩
(1.空軍預(yù)警學(xué)院, 武漢 430014; 2.解放軍31121部隊, 南京 210000)
窄帶雷達(dá)由于體制落后,存在著分辨率低、測量誤差大等問題,但由于較大的裝備基數(shù)、較低的價格,目前在防空預(yù)警體系中尚有大量部署[1]。當(dāng)多個目標(biāo)位于雷達(dá)天線波束寬度內(nèi),稱為群目標(biāo)[2]。群目標(biāo)回波信號在時域或頻域都較難分辨。現(xiàn)代戰(zhàn)爭中戰(zhàn)機(jī)多采用編隊突防,開展窄帶雷達(dá)群目標(biāo)的研判識別具有重要的現(xiàn)實(shí)意義。
在不改變雷達(dá)工作體制的前提下,目前主要有根據(jù)目標(biāo)微多普勒特征的研判識別方法[3-4],根據(jù)目標(biāo)RCS的統(tǒng)計特性來研判識別的方法[5],根據(jù)目標(biāo)回波信號特征來研判識別的方法[1],以及采用人在回路的研判識別方法[6]。但文獻(xiàn)[3-4]中的方法存在著特征影響因素多且難準(zhǔn)確區(qū)分目標(biāo)的問題。文獻(xiàn)[5]中的方法存在著特征難準(zhǔn)確提取且難有效度量的問題。文獻(xiàn)[1]中的方法存在著需額外增加信號處理通道且難有效分辨的問題。文獻(xiàn)[6]雖然采用人工識別粗分類與自動識別細(xì)分類相結(jié)合的策略,但還是擺脫不了微多普勒特征識別方法的不足。目前窄帶雷達(dá)群目標(biāo)識別仍主要靠人工、憑經(jīng)驗,工程實(shí)踐中缺乏行之有效的技術(shù)方法。
由于深度學(xué)習(xí)技術(shù)圖像特征提取上的獨(dú)特優(yōu)勢,故從窄帶雷達(dá)回波顯影的視角,采用深度學(xué)習(xí)的方法對群目標(biāo)研判識別成為可能[7-8]。深度學(xué)習(xí)技術(shù)在特征提取上的效果雖然有目共睹,但它的缺點(diǎn)同樣突出,那就是需要大量數(shù)以萬計的標(biāo)計過的數(shù)據(jù)來訓(xùn)練模型[9]。在防空預(yù)警實(shí)踐中,只能得到少量群目標(biāo)顯影數(shù)據(jù),采用深度學(xué)習(xí)的方法對群目標(biāo)識別存在較大困難。而且深度學(xué)習(xí)模型訓(xùn)練過程耗時,對硬件要求較高,給實(shí)時性應(yīng)用帶來不便[10]。
針對以上問題,本文提出基于深度遷移學(xué)習(xí)的識別方法,為窄帶雷達(dá)群目標(biāo)識別提供了思路。
1 深度遷移學(xué)習(xí)
深度遷移學(xué)習(xí)是在深度學(xué)習(xí)的基礎(chǔ)上進(jìn)行優(yōu)化的一種深度學(xué)習(xí)架構(gòu)[11]。解決了深度學(xué)習(xí)過度依賴訓(xùn)練數(shù)據(jù)規(guī)模的問題,增強(qiáng)了深度學(xué)習(xí)的實(shí)時性與適用性。
1.1 深度學(xué)習(xí)及CNN模型
深度學(xué)習(xí)(Deep Learning,DL)是一種深層的神經(jīng)網(wǎng)絡(luò)[10],它在視音頻處理、自然語義處理等方面應(yīng)用已較為廣泛,取得了很好的效果。目前,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)作為深度學(xué)習(xí)的重要組成,因為其局部連接及權(quán)值共享的特性,使得網(wǎng)絡(luò)權(quán)值數(shù)量大為減少,模型復(fù)雜度大為降低,目前已成為圖像處理領(lǐng)域效果最好的方法之一[12],這給窄帶雷達(dá)群目標(biāo)研判識別帶來了深刻啟示。
典型卷積神經(jīng)網(wǎng)絡(luò)是由卷積層、池化層、全連接層及分類器構(gòu)成[13]。卷積層可逐層提取輸入圖像特征,池化層對特征圖進(jìn)行二次特征提取,全連接層將特征連接并送往分類器,最后實(shí)現(xiàn)分類。不同的網(wǎng)絡(luò)結(jié)構(gòu)產(chǎn)生不同的模型,帶來不同的分類效果。
目前成熟的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)已有很多,自最早的LeNet-5模型提出后,涌現(xiàn)出了比如 AlexNet、VGGNet 、Res Net、GoogleNet等諸多優(yōu)秀的CNN模型[8]。經(jīng)典的LeNet-5模型結(jié)構(gòu)如圖1所示。
深度學(xué)習(xí)技術(shù)雖然在圖像領(lǐng)域得到了廣泛的應(yīng)用,但對這類模型的訓(xùn)練,需要大量數(shù)據(jù)及硬件資源,使之較難滿足窄帶雷達(dá)對實(shí)用性和實(shí)時性的需求。
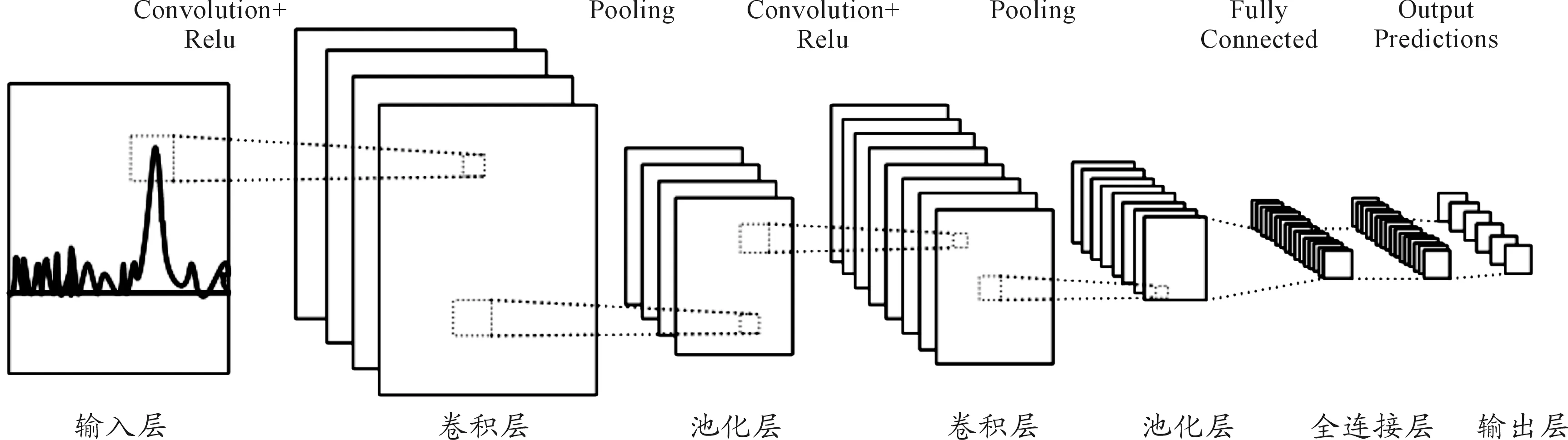
圖1 LeNet-5模型結(jié)構(gòu)
1.2 遷移學(xué)習(xí)
遷移學(xué)習(xí)(Transfer Learning,TL)是運(yùn)用已有的知識對不同但相關(guān)領(lǐng)域任務(wù)問題進(jìn)行求解的一種新的機(jī)器學(xué)習(xí)方法[14]。
遷移學(xué)習(xí)包括域和任務(wù)兩個概念。對于域D={X,P(x)},其中,X是一個特征空間,x={x1,x2…,xn}∈X,P(X)為特征空間上的邊緣概率分布。對于任務(wù)T={Y,P(Y|X)},其中Y為一個標(biāo)簽空間,P(Y|X)為條件概率分布,也可表示為目標(biāo)預(yù)測函數(shù)f(·),它可從由特征標(biāo)簽對(xi∈X,yi∈Y)組成的訓(xùn)練數(shù)據(jù)中學(xué)習(xí)得到。
給定一個源域Ds及對應(yīng)的源任務(wù)Ts、目標(biāo)域Dt及目標(biāo)任務(wù)Tt,遷移學(xué)習(xí)的目的就是:在Ds≠Dt,Ts≠Tt時,從Ds和Ts的信息中,學(xué)習(xí)得到目標(biāo)域Dt中的條件概率分布P(Yt|Xt)。深度遷移學(xué)習(xí)任務(wù)中ft(·)是表示深度神經(jīng)網(wǎng)絡(luò)的非線性函數(shù)[10]。
遷移學(xué)習(xí)不要求源域與目標(biāo)域同分布,模型在目標(biāo)域中訓(xùn)練時,可以借助從源域數(shù)據(jù)和特征中已經(jīng)提取的知識,實(shí)現(xiàn)在相似或相關(guān)領(lǐng)域間的復(fù)用和遷移,使傳統(tǒng)的零基礎(chǔ)學(xué)習(xí)變成有累積學(xué)習(xí),降低了模型訓(xùn)練開銷,提高了深度學(xué)習(xí)效果,使深度學(xué)習(xí)在缺乏充足可用的標(biāo)計數(shù)據(jù)時也能夠?qū)崿F(xiàn)規(guī)模化應(yīng)用,適合窄帶雷達(dá)群目標(biāo)識別的應(yīng)用場景。
1.3 基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)
深度遷移學(xué)習(xí)可分為基于實(shí)例的深度遷移學(xué)習(xí)、基于映射的深度遷移學(xué)習(xí)、基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)和基于對抗的深度遷移學(xué)習(xí)[15]。考慮到群目標(biāo)識別工作實(shí)際,本文采用基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)方法。
基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)是指復(fù)用在源域中預(yù)先訓(xùn)練好的部分網(wǎng)絡(luò),包括其網(wǎng)絡(luò)結(jié)構(gòu)和連接參數(shù),將其遷移到目標(biāo)域中使用的深度神經(jīng)網(wǎng)絡(luò)[15]。基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)示意圖如圖2所示。
從圖中可看到,首先,在源域中使用龐大的訓(xùn)練數(shù)據(jù)集訓(xùn)練深度學(xué)習(xí)網(wǎng)絡(luò)模型。然后,將源域中預(yù)訓(xùn)練的部分網(wǎng)絡(luò)遷移到目標(biāo)域,使其成為新的深度遷移學(xué)習(xí)網(wǎng)絡(luò)模型的一部分。最后,經(jīng)過訓(xùn)練調(diào)整,該網(wǎng)絡(luò)參數(shù)得到更新,深度遷移學(xué)習(xí)模型即訓(xùn)練完成。可以將深度遷移學(xué)習(xí)網(wǎng)絡(luò)看成兩部分,前面層可視為特征提取器,后面層可看作是分類器。
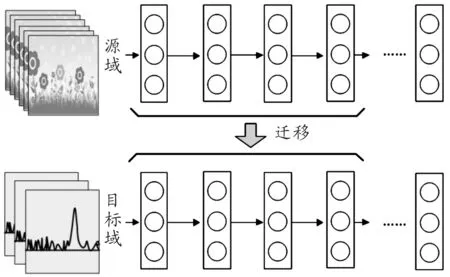
圖2 基于網(wǎng)絡(luò)的深度遷移學(xué)習(xí)
2 遷移學(xué)習(xí)數(shù)據(jù)集及模型
建立訓(xùn)練數(shù)據(jù)集、構(gòu)建網(wǎng)絡(luò)模型是深度學(xué)習(xí)的兩個重要環(huán)節(jié),深度遷移學(xué)習(xí)也不例外。
2.1 建立遷移學(xué)習(xí)數(shù)據(jù)集
深度遷移學(xué)習(xí)屬于監(jiān)督學(xué)習(xí),必須建立起訓(xùn)練數(shù)據(jù)集。群目標(biāo)遷移學(xué)習(xí)數(shù)據(jù)集的建立包括數(shù)據(jù)標(biāo)記和數(shù)據(jù)增強(qiáng)兩個步驟。
2.1.1數(shù)據(jù)標(biāo)記
建立群目標(biāo)遷移學(xué)習(xí)數(shù)據(jù)集面臨的第一個問題是數(shù)據(jù)標(biāo)記,也即將數(shù)據(jù)標(biāo)記為何種類型。對于群目標(biāo)識別來說,區(qū)分一批一架和一批多架(含二架)是有意義的,主要原因有以下幾點(diǎn):
首先,因為對群目標(biāo)與單目標(biāo)的區(qū)分有迫切的現(xiàn)實(shí)需求。編隊飛行的群目標(biāo)與一批一架目標(biāo)在雷達(dá)顯影上不易區(qū)分,容易混淆,因此會造成誤判乃至延誤戰(zhàn)機(jī)。其次,因為群目標(biāo)與單目標(biāo)在顯影特征上有一定差別。實(shí)踐經(jīng)驗表明:基于窄帶雷達(dá)A顯的飛機(jī)目標(biāo)回波特征是幅度較大、寬度較寬、波色較亮,單機(jī)波峰穩(wěn)定,而雙機(jī)以上編隊則波峰跳動或抖動,波內(nèi)組織復(fù)雜[16],經(jīng)驗豐富的操作員對這些差別可以有效辨別。最后,因為一批多架的群目標(biāo)顯影數(shù)據(jù)難以搜集,要實(shí)現(xiàn)群目標(biāo)的具體架數(shù)識別還缺少數(shù)據(jù)支持。
故此,本文根據(jù)防空預(yù)警工作實(shí)際,搜集并標(biāo)記某型窄帶雷達(dá)群目標(biāo)及非群目標(biāo)兩類回波顯影樣本數(shù)據(jù),給每類數(shù)據(jù)打上相同的數(shù)字標(biāo)簽,分別為0、1,以便深度學(xué)習(xí)網(wǎng)絡(luò)訓(xùn)練。 兩類樣本實(shí)例見圖3,其中左圖為一批兩架群目標(biāo),右圖為一批一架非群目標(biāo)。

圖3 兩類樣本實(shí)例
2.1.2數(shù)據(jù)增強(qiáng)
建立群目標(biāo)遷移學(xué)習(xí)數(shù)據(jù)集面臨的另一個問題是數(shù)據(jù)量偏少。雖然深度遷移學(xué)習(xí)對數(shù)據(jù)規(guī)模要求不高,但因為群目標(biāo)回波顯影數(shù)據(jù)較難獲取,為避免模型過擬合,必須對真實(shí)數(shù)據(jù)進(jìn)行數(shù)據(jù)增強(qiáng),以提高模型的泛化能力。
對于基于窄帶雷達(dá)A顯的回波顯影圖像,數(shù)據(jù)增強(qiáng)措施之一是對圖像適當(dāng)展寬與拉伸,以模擬目標(biāo)大小、距離及其他因素對窄帶雷達(dá)顯影的影響。不同型號雷達(dá)對回波信號的處理方式不一,回波顯影圖像數(shù)據(jù)增強(qiáng)幅度也有所不同,但展寬拉伸的范圍都應(yīng)在雷達(dá)探測范圍、門限范圍內(nèi)。數(shù)據(jù)增強(qiáng)措施之二是對圖形適度平移,以模擬目標(biāo)回波圖像截取位置偏差帶來的影響。根據(jù)某型雷達(dá)實(shí)際,本文中展寬范圍在1/2波寬內(nèi)取隨機(jī)值,拉伸范圍在1/3波峰高度內(nèi)取隨機(jī)值,平移偏移量在一個波寬內(nèi)取隨機(jī)值,通過Python語言調(diào)用Opencv庫來編程實(shí)現(xiàn)。考慮到遷移學(xué)習(xí)模型以Inception-v3為基礎(chǔ),而Inception-v3模型輸入必須為299像素彩色圖像,因而統(tǒng)一把所有顯影圖像縮放為299×299×3尺寸,然后進(jìn)行4種展寬變換、4種拉伸變換、4種平移變換,將原始數(shù)據(jù)的40張樣本圖像將擴(kuò)充到 2 560張。數(shù)據(jù)增強(qiáng)效果見圖4。其中,左圖為一批兩架群目標(biāo)增強(qiáng)效果,右圖為一批一架群目標(biāo)增強(qiáng)效果。

圖4 增強(qiáng)后的效果
2.2 構(gòu)建深度遷移學(xué)習(xí)模型
在遷移學(xué)習(xí)中,對于預(yù)訓(xùn)練模型的處理,主要有微調(diào)和特征提取兩種方式[17]。鑒于源域訓(xùn)練集數(shù)據(jù)與目標(biāo)域訓(xùn)練集數(shù)據(jù)種類不同的情況,這里采取特征提取的方式。特征提取是重新設(shè)計原模型的后面層,通過目標(biāo)域數(shù)據(jù)集訓(xùn)練得到與待解決問題相符的輸出層。該方式需要對深度學(xué)習(xí)模型進(jìn)行改進(jìn),重新構(gòu)建連接層、分類層或者部分卷積層。
深度遷移學(xué)習(xí)模型可以基于原有成熟模型構(gòu)建[18]。鑒于Google開源的Inception-v3模型均衡的性能、較少的參數(shù)、較快的的響應(yīng)速度,本文以該模型為基礎(chǔ)進(jìn)行構(gòu)建。保留模型所有隱層,以提取顯影圖像特征,重新構(gòu)建全連接層及分類層,把這些特征經(jīng)過全連接層進(jìn)行分類,實(shí)現(xiàn)對目標(biāo)回波顯影圖像的區(qū)分。圖5為該模型結(jié)構(gòu)。
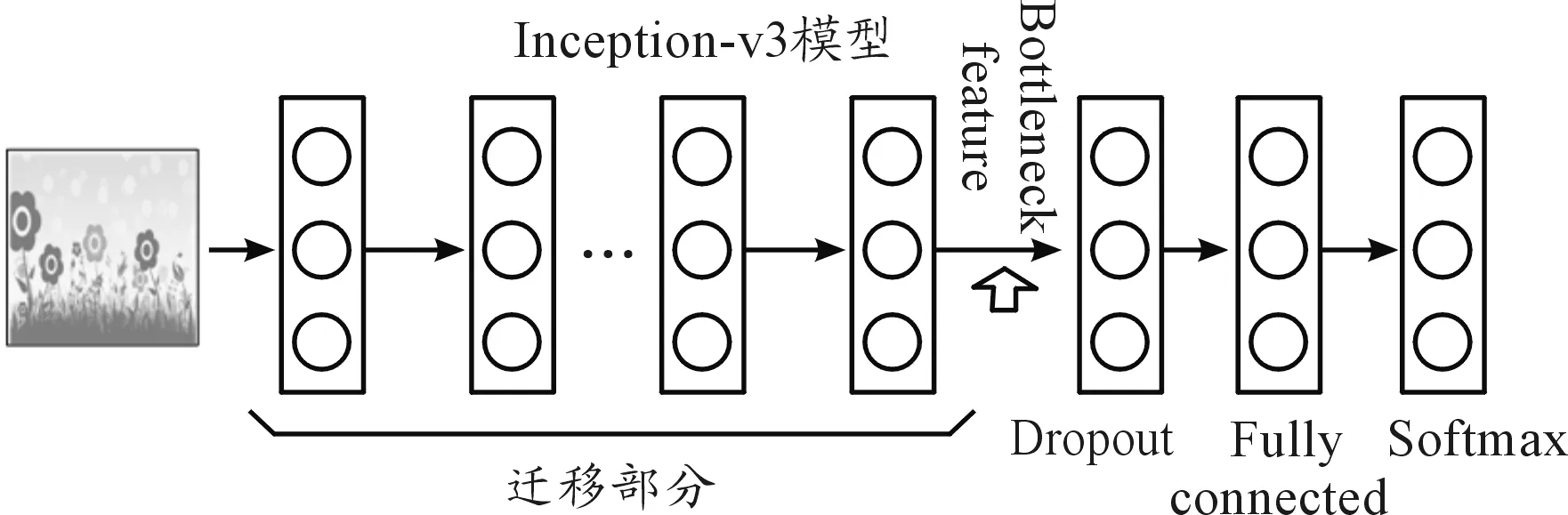
圖5 深度遷移學(xué)習(xí)模型結(jié)構(gòu)圖
如圖5所示,Inception-v3模型的后三層被丟棄,重新構(gòu)建了Dropout層、全連接層及輸出層,將分類結(jié)果設(shè)置為兩類。模型瓶頸層的結(jié)果輸出為新的遷移學(xué)習(xí)模型所提取的特征, Bottleneck feature 位置即為顯影圖像特征輸出位置,該結(jié)果是 2 048長度的特征向量。獲得該特征向量之后,經(jīng)Dropout后,將其輸入一個全連接層進(jìn)行分類,遷移學(xué)習(xí)模型全連接層的模型結(jié)構(gòu)示意圖見圖6。左側(cè)為 2 048個神經(jīng)元,對應(yīng)模型瓶頸層輸出的特征向量,右側(cè)輸出設(shè)置為n個。本文只選用2個輸出,對應(yīng)群目標(biāo)與非群目標(biāo)兩類結(jié)果,后期根據(jù)需要可選取多個輸出,對應(yīng)群目標(biāo)具體架數(shù)。
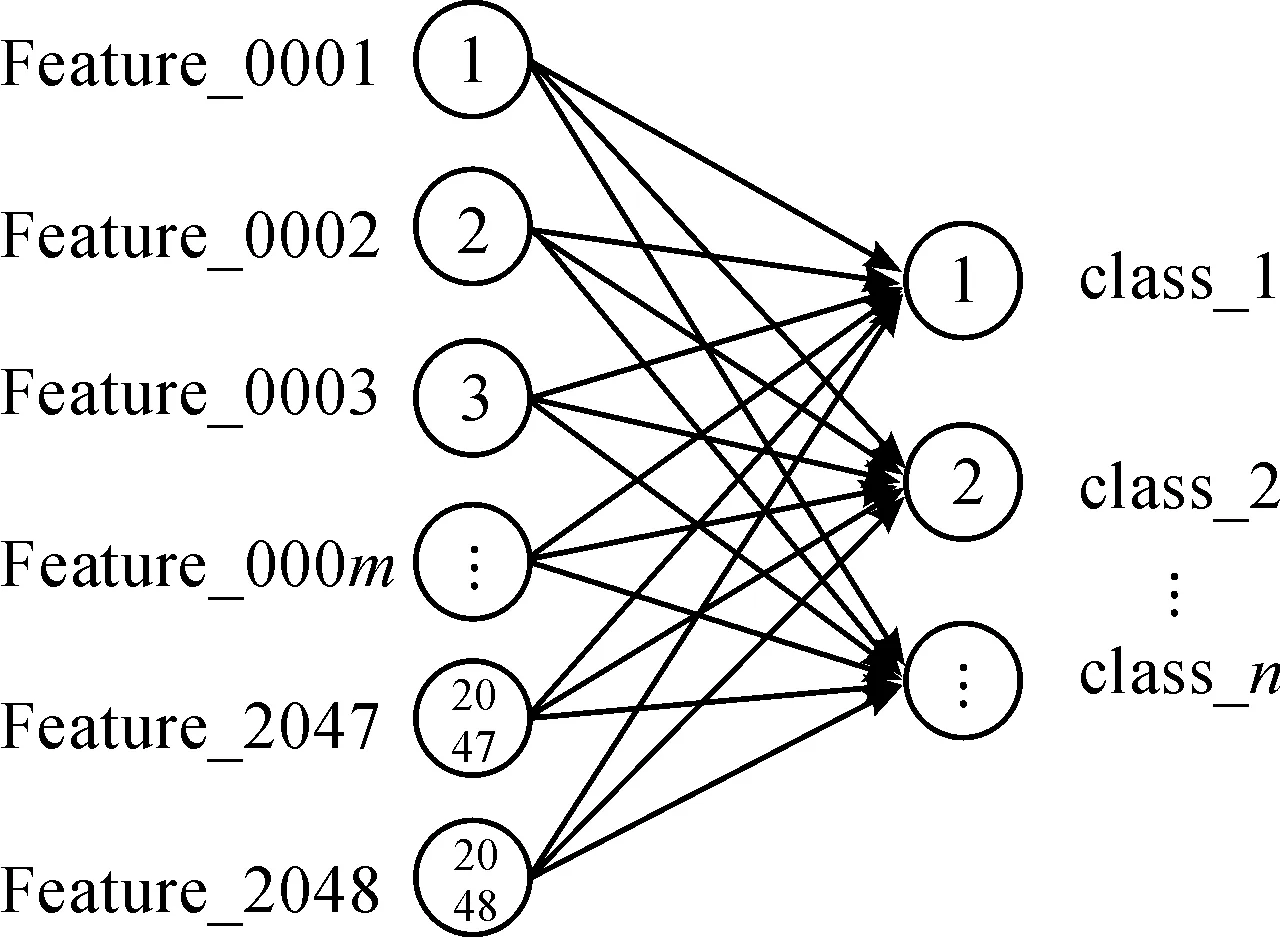
圖6 全連接層的模型結(jié)構(gòu)
3 實(shí)驗分析
為驗證算法的有效性及實(shí)用性,對零基礎(chǔ)深度學(xué)習(xí)與運(yùn)用深度遷移學(xué)習(xí)方法做了實(shí)驗對比。實(shí)驗平臺為32位Windows7系統(tǒng),CPU3.6 GHz,內(nèi)存8 GB,用Python語言編程,采用Tensorflow框架CPU版本實(shí)現(xiàn)。
3.1 零基礎(chǔ)深度學(xué)習(xí)效果
采用Inception-v3模型進(jìn)行零基礎(chǔ)訓(xùn)練時,必須建立規(guī)模龐大的數(shù)據(jù)集,這里對真實(shí)數(shù)據(jù)進(jìn)行更大范圍的數(shù)據(jù)增強(qiáng),形成每類樣本5萬張圖片的數(shù)據(jù)集,數(shù)據(jù)增強(qiáng)方法同2.1.2節(jié)所述。超參數(shù)設(shè)置為:學(xué)習(xí)率ξ=0.01,正則項f=0.1,批大小 (BatchSize) 選為 16,迭代步數(shù)設(shè)為7 500。將訓(xùn)練集數(shù)據(jù)輸入Inception-v3網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練,網(wǎng)絡(luò)模型的交叉熵?fù)p失值和識別準(zhǔn)確率隨著迭代次數(shù)的變化如圖7所示。

圖7 零基礎(chǔ)學(xué)習(xí)效果
可以看到隨著迭代步數(shù)的增大,識別準(zhǔn)確率在上升,在7 000 步之后數(shù)據(jù)集的識別正確率最終達(dá)到90.13%,并且還有進(jìn)一步提高的趨勢。交叉熵?fù)p失值也隨迭代步數(shù)的增加逐步變小。但同時也看到訓(xùn)練的過程中準(zhǔn)確率與損失值波動較大,訓(xùn)練時間偏長,到7 500步訓(xùn)練中斷時共用時186 h。
3.2 深度遷移學(xué)習(xí)效果
采用2.2節(jié)深度遷移學(xué)習(xí)模型,對2.1節(jié)所建立的數(shù)據(jù)集進(jìn)行訓(xùn)練,網(wǎng)絡(luò)超參數(shù)設(shè)置不變,網(wǎng)絡(luò)的識別準(zhǔn)確率和損失值隨著迭代次數(shù)的變化見圖8。
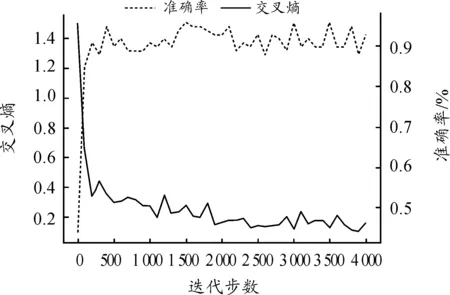
圖8 遷移學(xué)習(xí)效果圖
可以看到在1 500步時識別正確率就已達(dá)到97.73%,之后數(shù)據(jù)集的識別正確率和損失函數(shù)值已無較大波動。整體用時0.3 h。
由表1可知,不管是從訓(xùn)練耗時還是準(zhǔn)確率來看,很明顯基于深度遷移學(xué)習(xí)的方法都更具實(shí)用性。
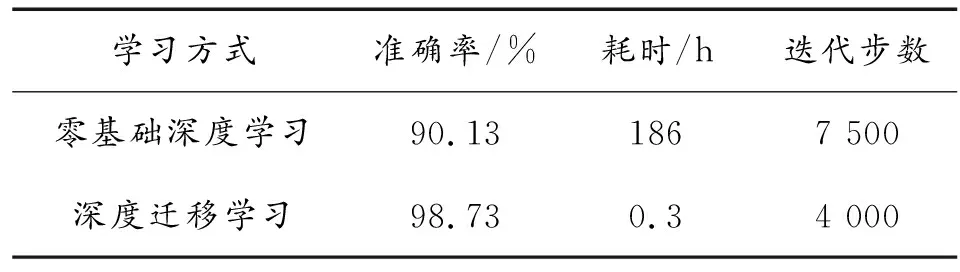
表1 學(xué)習(xí)效果
4 結(jié)論
通過建立群目標(biāo)顯影遷移學(xué)習(xí)數(shù)據(jù)集,使用基于Inception-v3模型構(gòu)建的遷移學(xué)習(xí)模型對數(shù)據(jù)集訓(xùn)練,得到群目標(biāo)識別模型。實(shí)測數(shù)據(jù)表明,該模型在窄帶雷達(dá)群目標(biāo)識別上效果較好,具備了一定的實(shí)用價值。在未來的工作中,將對模型進(jìn)行進(jìn)一步改進(jìn),使之在群目標(biāo)架數(shù)、目標(biāo)型別識別等方面發(fā)揮更好的作用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
