基于數據挖掘的輸油管道智能化研究
2020-05-08 03:37:40李傳憲李龍東鄭琬郁
天然氣與石油 2020年2期
于 濤 李傳憲 李龍東 鄭琬郁 于 瑤
1. 中國石油大學(華東)儲運與建筑工程學院, 山東 青島 266580;2. 中國石油北京油氣調控中心, 北京 100007;3. 中國石油西部管道公司, 新疆 烏魯木齊 830013
0 前言
長輸液體管道作為國家經濟發展動脈,目前多采用Supervisory Control And Data Acquisition(SCADA)系統進行遠程控制,日常運行中調度員通過分析壓力、流量等參數,結合設備狀態變化實現管道監控。近年來,隨著長輸液體管道的自控通訊技術發展,SCADA系統實時數據及歷史數據的分析應用,通過參數及設備的自動監測、調節保護、參數預測及工況實時捕捉的管道智能化,逐漸被生產部門重視并投入建設[1-3]。
管道智能化建設是一個綜合性工程,人員包括業務專家、數據挖掘專家及軟件開發人員等,涉及業務需求的提出、數學模型構建應用等工作。國內外的石油公司在物聯網、機器學習、人工智能等管道智能化方面持續開展了大量研究工作,并在管網負荷預測[4]、運營效率及業務優化等方面取得了一定成果[5]。國內石油公司目前多側重于數據采集與展示,對于數據挖掘和應用主要應用于管道完整性建設[6]、內檢測[7-9]、泄漏監測、管道安全識別等方面[10-11],但未打通不同業務之間的界限,信息孤島現象明顯,沒有形成統一的數據平臺[12]。本文研究并提出了長輸液體管道智能化架構,給出架構的核心為數據挖掘層及其相應的數據挖掘算法,通過HY原油管道應用案例,獲得基于數據挖掘技術建立的油溫預測模型,為未來管道不同業務的智能化應用探索道路。
1 管道智能化架構
長輸液體管道的智能化研究應用架構,從下到上分為物理層、數據層、數據挖掘層、應用層和用戶層五個[13],見圖1。在系統的總體架構中,需充分結合國家、行業及企業標準規范,形成系統需要的標準規范體系。同時考慮系統建設過程中的網絡、數據安全,建立安全保障體系,確保系統的安全性。
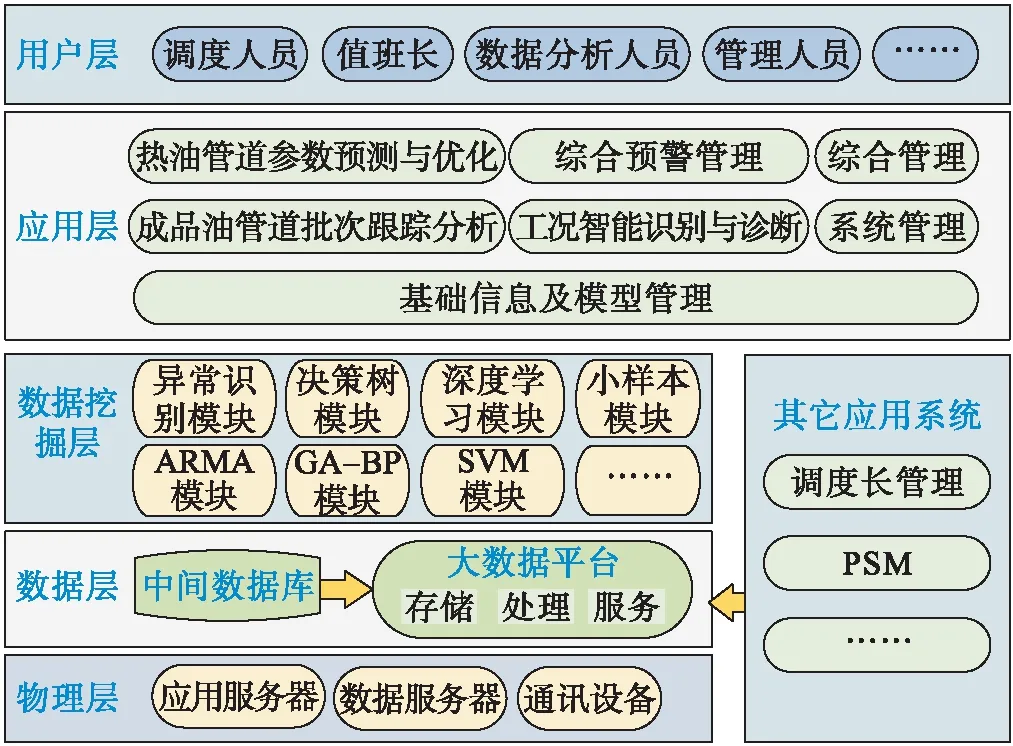
圖1 管道智能化系統架構圖Fig.1 Pipeline intelligent system architecture
1.1 物理層
物理層是系統運行的基礎硬件環境,主要包括硬件、軟件和通訊設備,其中硬件包括服務器,如:應用服務器、數據庫服務器、磁盤陣列等設備,通過這些硬件設備為系統提供物理設備支撐;軟件主要包括部署在服務器設備上的操作系統,通過軟件系統,實現人機界面的交互,為用戶提供方便快捷的操作界面;網絡通訊設備包括網絡交換機、防火墻等設備,為應用系統的運行提供通信保障。
1.2 數據層
主要對各類數據源的采集、存儲與管理,通過部署數據采集程序、手動錄入、數據上傳等多種方式,將生產數據、文檔數據、GPS數據等上傳到數據庫內,對各類數據進行統一管理,為系統應用、分析提供基礎數據源。
1.3 數據挖掘層
根據業務需求,利用理論公式、數據回歸、數據挖掘等方式,將基礎數據進行加工處理,變成可為系統提供支撐的數據或預測模型,如參數的趨勢預測,工況識別算法等模型。
1.4 應用層
利用數據挖掘層提供的技術與服務開展各項業務應用,包括:熱油管道參數預測與優化、成品油管道批次界面跟蹤、異常工況智能識別等。
1.5 用戶層
提供多種數據集成、圖形報表展現及多維數據分析,以滿足用戶分類匯總、統計分析、決策支持的需要,為管理人員以及相關業務人員提供決策依據。
2 數據挖掘方法與應用
管道智能化架構研究中,數據挖掘層是通過理論及數據挖掘算法,將業務需求理論化、模型化,是管道未來智能化管理控制的核心。由于長輸液體管道運行過程產生大量的實時數據,發生的事件工況、報警信息具有復雜多樣、變化快、多維度、多時域頻域等特點。以往理論研究方法在數據挖掘層的適用性較差,需采用更為實用的數據挖掘算法建立預測模型。與傳統實驗研究和數值分析不同,應用于大數據挖掘技術中的神經網絡、機器學習及深度學習等算法模型,能夠挖掘不同參數之間的隱性關系,實現參數的有效預測,如電網負荷預測、設備故障在線預測與診斷等[14-16]。數據挖掘方法與傳統理論研究方法相比,各自的特點,見圖2。

圖2 傳統理論研究方法與數據挖掘方法流程對比圖Fig.2 Process comparison between traditional theoreticalresearch method and data mining method
以熱油管道蘇霍夫油溫計算公式為例[17],因公式受影響因素較多,實際應用適應性較差。其主要局限性一是模型構建過程需要對參數進行理想假設和簡化,影響誤差;二是實際應用過程中,因影響參數的變化,導致模型適用性差;三是分析較片面,局部難以反映宏觀時空關聯特性。數據挖掘方法不依賴于機理,可將歷史和實時數據綜合分析,得到多維度宏觀時空關聯特性。數據挖掘方法與傳統理論研究方法并不矛盾,研究過程中數據挖掘方法通過使用傳統理論研究方法確定輸入參數,建立時空關聯特性,提升研究效率,同時也進一步完善科學研究體系,推動研究方法的發展。
3 應用實例分析
HY熱油管道主要外輸長慶油田高含蠟原油,油品物性見表1,管道全長132.4 km,管徑Φ 457 mm,設計壓力6.3 MPa(局部10 MPa),設計輸量500×104t/a,全線共設1#首站、2#熱站、3#熱站和4#末站共4座站場。根據沿線地溫和油品物性特點,管道采用綜合熱處理、熱處理、加熱和常溫輸送等不同工藝,保證全線油溫高于凝點3 ℃,具有運行工藝復雜,動力及燃料油費用高等特點。生產過程中管道油溫是重點關注參數。
表1 HY熱油管道外輸油品物性表
Tab.1 Oil properties of HY hot oil pipeline

原油名稱凝點/℃密度/(kg·m-3)含蠟量/(%)膠質瀝青質含量/(%)析蠟點/℃反常點/℃外輸油品18847.816.48.136.425
HY熱油管道下游站場進站油溫與輸量、地溫、上游站場出站油溫等參數是一種復雜且相互影響的內部關系,BP神經網絡具有實現任意復雜非線性映射的能力,適合于求解此類復雜問題。但BP神經網絡同時存在容易陷入局部極小值,網絡收斂速度慢,網絡結構及參數的選擇缺乏統一標準等問題。本文研究使用遺傳算法(Genetic Algorithm,GA)優化BP神經網絡的初始權值和閾值[18-19],主要包括種群初始化、適應度函數、選擇操作、交叉操作和變異操作等,提升模型的準確性和效率。
3.1 GA-BP油溫預測模型構建
GA具有自組織、自適應等特點,在運行過程中處理參數編碼集,而非參數本身,不受優化函數連續性、可導性約束,此外BP神經網絡擅長局部搜索,GA擅長全局搜索。模型構建過程中首先通過GA優化神經網絡初始權值,定位獲得較優搜索空間,再通過BP神經網絡在較優的搜索空間產生最優值,從而較好地確定輸入值與期望輸出值之間的非線性關系,提高模型預測精度[20]。GA優化程序見圖3。

圖3 GA優化程序框圖Fig.3 Genetic Algorithm Optimization Program
由圖3可知,GA優化的步驟如下:
第一步,網絡初始化與遺傳編碼。初始化BP神經網絡,隨機產生一個Xm×n種群,確定網絡輸入、輸出節點數s1、s2,訓練次數N和隱含層數H,訓練誤差ε等參數,個體長度即為神經網絡權值個數。確定種群規模m、最大迭代次數T、交叉概率Pc和變異概略Pm,其長度n為:
n=H×(s1+s2)+H+s2
(1)
第二步,遺傳進化。通過迭代求解最佳結構權值和閾值,包括選擇、交叉、變異等操作。若第i個個體的適應度值為fi,則選中概率為:
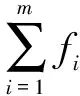
(2)
交叉由2個個體通過線性組合產生新個體。交叉概率產生新個體為:
Xi(k+1)=αXi(k)+(1-α)Xi+1(k)
(3)
Xi+1(k+1)=αXi+1(k)+(1-α)Xi(k)
(4)
式中:α為0~1之間的隨機值,由變異概率Pm所對應的取值范圍內,隨機值替換原值,即:
Xi=Xi(p)+s1×q+Xi(n-p-1)
(5)
式中:q為第p+1個基因所對應閾值范圍,通過遺傳進化,可利用父輩種群產生新一代子種群Xt。
第三步,適應度值計算。根據流程計算模型適應度值,判斷迭代次數和精度,確定是否返回計算。在遺傳結束后,通過解碼獲得最優個體作為BP神經網絡初始權值和閾值。
通過GA對BP神經網絡在權值和閾值的優化選擇,結合BP神經網絡算法特點,建立熱油管道GA-BP油溫預測模型,其架構見圖4。
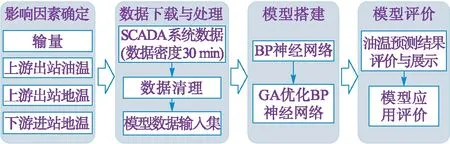
圖4 HY熱油管道油溫預測模型架構圖Fig.4 Oil temperature prediction architecture of HY hot oil pipeline
3.2 數據預處理
通過SCADA系統歷史數據庫下載相關數據,數據密度為30 min,剔除非穩態數據與錯誤數據,即對數據進行清洗、預處理,提升數據質量,將數據矩陣集成,以便 GA-BP 油溫預測模型學習使用。為了模型訓練和提高程序運行時收斂效率,對數據進行歸一化處理,把數據映射到0~1范圍內,本文采用min-max標準化(Min-Max Normalization)……,見式(6):
(6)
式中:X*為標準化后的數據;max為樣本數據最大值;min為樣本數據最小值。
3.3 模型驗證
本文使用均方根誤差RMSE、平均絕對誤差MAD和相關性系數R評估模型精度,見式(7)~(9)。使用絕對誤差和相對誤差分析油溫的預測值與真實值。
(7)
(8)
(9)

3.4 模型對比分析
梳理分析完成SCADA系統生產數據,選取70%樣本數據作為訓練集,30%作為測試集,利用建立的BP神經網絡模型,GA-BP油溫預測模型對數據集進行訓練和測試。模型均設5個隱藏層,迭代200次,各模型達到最低訓練誤差時的迭代次數和訓練時間,BP、GA-BP油溫模型測試結果對比見表2。
表2BP神經網絡模型、GA-BP油溫預測模型測試結果對比表
Tab.2 Comparison of test results of BP neural network model and GA-BP oil temperature prediction model

內容BP神經網絡模型GA-BP油溫預測模型訓練誤差/℃迭代次數/次訓練時間/s訓練誤差/℃迭代次數/次訓練時間/s1次0.004 37096.080.002 83687.04.02次0.003 58072.070.002 58265.03.03次0.006 77056.060.002 113107.05.04次0.693 61079.070.002 473110.05.05次0.005 45082.070.002 92987.04.06次0.004 47083.070.001 84348.03.07次0.037 63079.070.002 82326.02.08次0.003 530113.090.002 01971.03.09次0.004 29093.080.002 09280.04.010次0.853 75085.070.001 75172.03.0平均訓練誤差0.161 74583.87.30.002 34675.33.6MAD0.244 800——0.000 380——RMS0.324 880——0.000 440——
由表2可知,GA-BP油溫預測模型訓練時平均訓練誤差、迭代次數和訓練時間分別為0.002 346 ℃、75.3次、3.6 s。相比未優化前BP神經網絡模型,訓練過程精度、迭代次數和時間均有較大提升。GA-BP油溫預測模型訓練結果的RMS、MAD分別為0.000 38.0 ℃和0.000 440 ℃。在此基礎上利用BP神經網絡模型、GA-BP油溫預測模型,對油溫數據進行預測,預測結果見表3,輸出誤差趨勢和各模型預測結果與真實值相關性曲線見圖5~6。
表3 不同模型預測結果對比表
Tab.3 Comparison of prediction results of different models

內容誤差對比BP神經網絡模型GA-BP油溫預測模型誤差<0.5 ℃樣本/個819.00867.00誤差<0.5 ℃占比/(%)81.8286.61誤差<1 ℃樣本數/個925.00959.00誤差<1 ℃占比/(%)92.4195.80最大絕對誤差/℃5.443.08RMSE/℃0.890.48MAD/℃0.880.02R0.920.96
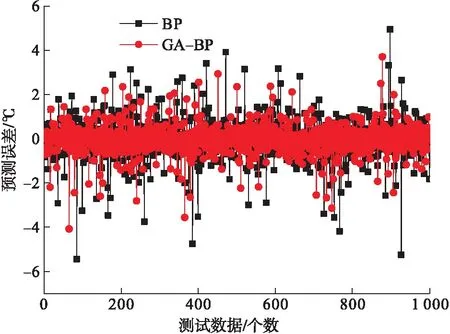
圖5 油溫預測誤差對比圖Fig.5 Comparison of oil temperature prediction errors

a)BP神經網絡模型的預測值與真實值a)Predictive values and true values of the BP neural network model

b)GA-BP油溫預測模型的預測值與真實值b)Predictive values and true values of GA-BP oil temperature prediction model
由表3和圖5可知,GA-BP油溫預測模型,預測誤差較小,誤差小于0.5 ℃和1 ℃的數據分別占總預測數據的86.61%和95.8%,最大絕對誤差、RMSE、MAD和R分別為3.08 MPa、0.48 ℃、0.02 ℃和0.96,相比BP神經網絡模型,預測結果的準確性和穩定性提高較大。由圖6可知,GA-BP油溫預測模型的預測值與實際值的離散度較小,預測結果與實際數據的相關性較好,滿足實際生產運行需要。
3.5 模型應用
將BP神經網絡模型和GA-BP油溫預測模型應用于HY熱油管道各站場的油溫預測,同時使用蘇霍夫公式反算油溫,將預測結果與實際工況數據進行誤差對比,計算結果及誤差對比見表4。
表4 BP神經網絡和GA-BP油溫預測模型預測值與真實值對比表
Tab.4 Comparison of predictive values and true values of BP neural network model and GA-BP oil temperature prediction model
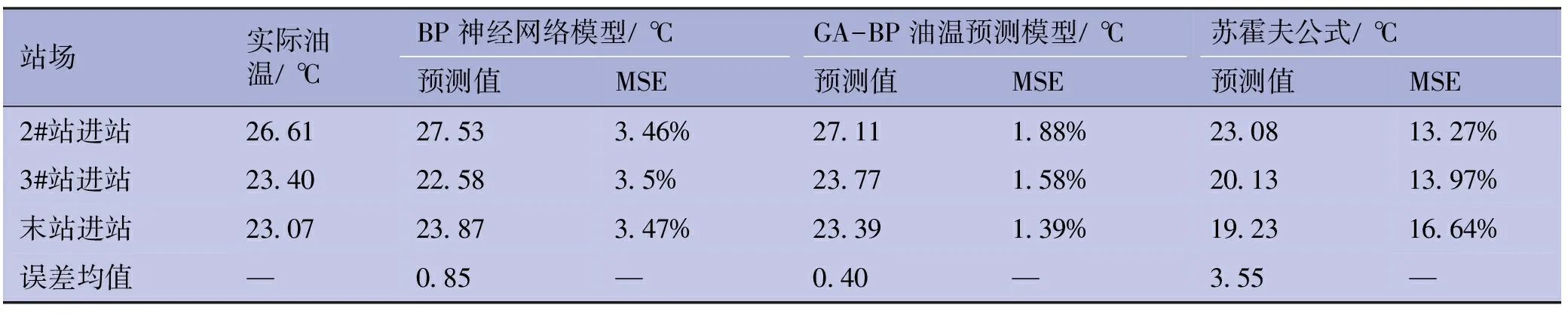
站場實際油溫/℃BP神經網絡模型/℃GA-BP油溫預測模型/℃蘇霍夫公式/℃預測值MSE預測值MSE預測值MSE2#站進站26.6127.533.46%27.111.88%23.0813.27%3#站進站23.4022.583.5%23.771.58%20.1313.97%末站進站23.0723.873.47%23.391.39%19.2316.64%誤差均值—0.85—0.40—3.55—
由表4可知,使用蘇霍夫公式反算油溫數值與真實值平均絕對誤差3.55 ℃,而BP神經網絡模型預測得到的絕對誤差平均值為0.85 ℃,經過GA優化后預測精度進一步提高,平均絕對誤差0.40 ℃,能夠滿足管道日常運行的使用要求。將GA-BP預測模型應用于管道智能化架構的數據挖掘層,可實現熱油管道油溫數據的實時在線預測,進而指導熱油管道加熱爐的優化調整等工作。
4 結論
1)通過研究建立管道智能化架構,架構包括物理層、數據層、數據挖掘層、應用層和用戶層,其中數據挖掘層是管道智能化的核心。數據挖掘層是將生產數據,通過業務專家和數據挖掘專家將數據算法模型理論化、模型化。
2)經實際應用和對比分析,傳統理論公式在數據挖掘層適用性較差,需通過基于數據挖掘算法,對實際生產數據建立相應的預測模型。
3)利用GA-BP油溫預測模型,可準確預測HY熱油管道油溫,指導工藝運行調整。即根據業務需求,基于數據挖掘算法建立的算法模型可滿足業務需求,并應用于未來管道智能化研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
軍事文摘(2022年19期)2022-10-18 02:41:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
印刷工業(2020年4期)2020-10-27 02:45:52
數學物理學報(2020年2期)2020-06-02 11:29:24
中國交通信息化(2017年4期)2017-06-06 07:21:52
電力與能源(2017年6期)2017-05-14 06:19:37
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
