面向CUDA程序的線程放置優化策略研究
2020-04-29 10:55:22謝根栓張偉哲
智能計算機與應用 2020年2期
謝根栓, 張偉哲
(哈爾濱工業大學 計算機科學與技術學院, 哈爾濱 150001)
0 引 言
近年來,基于強大的數據并行處理與浮點計算能力,GPU已廣泛應用于工程應用和科學計算領域,并且取得了長足的進步和可觀成績。在GPU程序中,程序員需要設置線程塊大小(block size)以明確程序的線程數量。不同的線程塊大小會帶來不同的線程的并發度。只有通過合理設置線程塊大小才能使程序運行的性能達到最好,因此線程塊大小是影響程序性能的關鍵因素。
本文中,使用機器學習完成性能最佳線程塊大小的自動設置,可以避免全局遍歷方法中多次反復運行程序的高耗時,相較于傳統啟發式搜索等方法,也避免了搜索結果陷入局部最優的問題。
1 相關工作
目前,CUDA線程塊放置優化方法主要有2類。一類是不運行程序、簡單地依靠經驗完成線程塊優化;另一類是基于性能模型驅動的優化。
用第一類方法進行線程塊優化的典型代表有Sorensen等人[1]提出的在Fermi架構GPU上對一系列BLAS程序設置線程塊大小等參數的方法。
基于性能模型驅動的優化研究成果相對多一些。Tran等人[2]開發了一個評估線程塊大小優化效果的調參模型,該模型會提出多個備選的線程塊大小,從而避免了大范圍窮舉線程塊大小。但該模型評估標準只是GPU利用率,并且忽略了決定線程塊大小更重要的kernel函數的信息。Gupta等人[3]設計了一款名為STAtuner的工具。該工具使用LLVM編譯CUDA核函數以從中收集kernel函數的多個靜態信息。在此基礎上,還使用支持向量機預測性能最佳的線程塊修正方向。Connors[4]提出了類似的思路,都是使用機器學習來獲得最佳線程規格調整方向,不同之處在于使用動態程序信息而不是靜態程序信息。
國內關于CUDA程序線程放置優化方面,鄭禎等人[5]設計實現了一套針對GPU程序性能的分析工具。該工具的編程接口采用CUPTI底層接口,在測試環節對部分Benchmark程序做性能瓶頸分析,并分析總結了常見性能瓶頸的原因,同時給出了一些開發高效CUDA應用的建議。
2 模型研究
2.1 整體設計
本文的模型研究基于機器學習的常規設計,主要包括訓練數據獲取、訓練模型、模型評估三個步驟。模型整體設計見圖1。
2.2 程序信息采集與處理
2.2.1 采集運行時信息
nvprof是NVIDIA官方提供的一款命令行形式的CUDA程序的性能分析工具,可以收集GPU的硬件計數器信息生成程序的運行時信息。本文參考鄭禎等人[5]對CUDA性能信息的提煉匯總,只采集這些信息中最具代表性的一部分。本文獲取的metric信息見表1。此外,本文訓練數據的標簽數據也通過nvprof采集CUDA程序執行時間獲得。

圖1 基于LLVM對CUDA程序線程分配優化模型的改進
Fig. 1 Improvement of thread allocation optimization model for CUDA program based on LLVM

表1 通過nvprof獲得的CUDA函數運行時信息
2.2.2 靜態信息替代運行時信息的方法
由于nvprof采集運行時信息會存在耗時過長的問題,研究提出了靜態信息替代運行時信息的方法。CUDA程序靜態信息對運行時信息的替代詳見表2。研究可得闡釋分述如下。
(1)浮點計算單元利用率。研究可以用靜態信息浮點指令數量Ninstr_float計算得到浮點計算單元利用率。設核函數的執行時間為Tkernel,GPU浮點計算理論峰值為Pmax,則GPU浮點計算單元利用率Ufloat_static可以表示為:
(1)
(2)線程分歧率。在CUDA程序的指令集中,影響線程分歧率的指令包括分支指令、同步指令,因此研究中用靜態信息分支指令數量Nbranch、同步指令數量Nsync、指令總數Ninstr等替代nvprof工具的信息branch_efficiency,計算公式為:
(2)
表2 CUDA程序靜態信息對運行時信息的替代
Tab. 2 Replacement of runtime information by static information of CUDA program

運行時信息用以替換的靜態信息branch_efficiencyNloop、Nbranch、Nsync、Ninstrgst_throughputNinstr_storegld_throughputNinstr_loadflop_dp_efficiencyflop_sp_efficiencyNinstr_float
2.2.3 基于LLVM的CUDA程序信息提取
LLVM項目是一個獲得廣泛使用的編譯工具框架,Pass是LLVM系統的重要組成部分,可以通過分析程序的模塊、函數、基本塊等信息以提供程序的高級的信息。本文中,使用LLVM完成CUDA程序靜態信息的采集。對此可做重點剖析如下。
在進入IR的Module后,分析pass會遍歷Module內的全部函數,進入kernel函數內部后,pass會遍歷函數的全部基本塊與指令,依據與CUDA程序性能指標關聯度,pass主要完成對int型數據操作指令、float型數據操作指令、存儲交互操作指令、程序分支操作指令、線程同步指令、函數內循環次數的統計。
分析pass的指令信息統計的實現流程如圖2所示。

圖2 分析pass的指令信息統計的實現
2.2.4 設置標簽
本文提出的添加標簽算法是針對每個核函數,按照執行時間排序,取執行時間較短的前20%設置標簽為1,剩余的信息設置標簽為0。添加標簽算法的過程設計具體如下。
算法1 設置標簽的算法
輸入:D為原始訓練數據;F為測試集中全體核函數集合
輸出:DL為添加標簽后的訓練數據
過程:
forfiinFdo
Tfi← 提取D中的核函數fi的全部執行時間信息
Dfi← 提取D中的核函數fi的全部信息
依據Tfi對Dfi快速排序:Dfi←QuickSort(Dfi)
排序后的Dfi的前20%標簽設置為1:前20%Dfi的DL← 1
剩余Dfi的標簽設置為0:剩余Dfi的DL← 0
end for
2.3 模型訓練
scikit-learn[6]工具為機器學習提供了良好的支持,本文通過其來建立優化模型。文中對此將給出如下研究論述。
2.3.1 參數組合
在小批量數據集下,支持向量機算法的可調參數包括懲罰系數和核函數參數。其中,懲罰系數表示了模型對誤差的寬容度;核函數參數σ決定了數據映射到新的特征空間后的分布。研究中分別對應scikit-learn中的C、gamma。本次實驗中SVC算法遍歷的參數見表3。

表3 SVC網格搜索的參數
2.3.2 交叉驗證
交叉驗證(Cross Validation)也稱作循環估計,指的是對原始數據分組,取大部分樣本做訓練集,留取剩余少部分數據做驗證集用來評價訓練出的模型效果,重復上述過程,直到全部數據都做過驗證集。最后,選取這些驗證評價的平均值作為最終的評價。
研究使用scikit-learn的網格搜索函數GridSearchCV遍歷2.3.1節的參數組合,通過交叉驗證確定最佳效果參數。GridSearchCV的參數cv是交叉驗證參數,該參數指定了fold數量,本文設置為10。接著,研究通過調用fit函數利用建立好的網格搜索對象訓練數據,得到最優的參數組合。
3 實驗
3.1 實驗條件
本次研究中的運行環境配置見表4。

表4 模型運行環境
全部代碼運行在python3.6.5環境。模型訓練選用的Benchmark為Rodinia[7]。
3.2 測試分析
在測試分析部分,本文與已有的Connors[4]模型進行了相同訓練數據下的訓練時間、訓練精度對比分析。2個模型運行時間的對比結果如圖3所示,2個模型在充足訓練集下的訓練準確率的對比結果則如圖4所示。
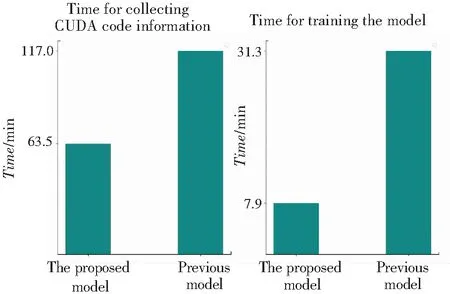
圖3 與已有模型的時間對比

圖4 與已有模型的訓練準確率對比
通過對比2個模型的訓練數據收集時間和模型訓練時間可以看到,本文的模型相較Connors等人提出的模型只花費了近一半的時間。究其原因則在于:首先,本文模型采集的CUDA程序信息較少,而Connors的模型未對nvprof采集的程序信息做篩選;其次,本文的模型部分信息轉為靜態信息提取,降低了采集運行時信息的種類。綜上分析可知,本文模型中nvprof潛在反復執行CUDA程序的次數減少,這使模型訓練時間也隨之減少。
由圖4可以看到,在相同機器學習算法下,本文的模型基于上述改進,訓練準確率獲得了提升。究其原因則在于:首先,研究采集篩選后程序信息使模型避免了冗余信息可能產生的噪點和過擬合問題;其次,研究的模型提出了全新的標簽設置算法,可以更真實地反映了不同線程配置下的程序運行性能間的差異。
4 結束語
本文提出了一個基于CUDA程序運行時信息與靜態信息結合的線程配置優化模型。研究的創新點包括:
(1)運行時信息采集環節中,對采集信息做篩選,只保留了其中與程序性能相關的核心信息。
(2)提出并實現了基于LLVM的靜態信息替代運行時信息的方法。
(3)提出了全新的標簽設置算法,使模型的標簽數據更真實地反映程序性能情況。
基于上述創新,將本文模型與已有研究中的模型在時間、準確率上進行對比分析,結果表明新模型在時間上獲得了更大優勢,準確率也有更高保證。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
人大建設(2019年12期)2019-05-21 02:55:44
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
中華手工(2017年2期)2017-06-06 23:00:31
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
中外會展(2014年4期)2014-11-27 07:46:46
機電信息(2014年27期)2014-02-27 15:53:56
