基于時(shí)間觸發(fā)機(jī)制的實(shí)時(shí)通信架構(gòu)研究與設(shè)計(jì)
2020-04-24 08:52:14蔣笑寒孫思杰馮逸駿
計(jì)算機(jī)工程與設(shè)計(jì) 2020年4期
關(guān)鍵詞:系統(tǒng)
蔣笑寒,李 牧,孫思杰,馮逸駿
(1.北京航空航天大學(xué) 中法工程師學(xué)院,北京 100191;2.北京工業(yè)大學(xué) 樊恭烋學(xué)院,北京 100124;3.北京航空航天大學(xué) 宇航學(xué)院,北京 100191)
0 引 言
信息-物理系統(tǒng)(cyber physical systems,CPS)[1]是集成計(jì)算、通信與控制于一體的下一代智能系統(tǒng),目前已廣泛應(yīng)用于各個(gè)安全攸關(guān)領(lǐng)域(safety-critical),為提升智能系統(tǒng)的計(jì)算能力、安全性以及可靠性,亟需建立一套能夠用于CPS系統(tǒng)的單節(jié)點(diǎn)多核心分布式實(shí)時(shí)操作系統(tǒng)。
時(shí)間觸發(fā)理論作為一種高確定性的實(shí)時(shí)理論,已經(jīng)在安全攸關(guān)領(lǐng)域[2,3]有了多年的應(yīng)用。Pont MJ提出時(shí)間觸發(fā)原理;Hermann Kopetz等設(shè)計(jì)了時(shí)間觸發(fā)架構(gòu),并提出了時(shí)間觸發(fā)協(xié)議TTP(time-triggered protocol);Yan[4]基于傳統(tǒng)TTP協(xié)議設(shè)計(jì)了C類時(shí)間觸發(fā)協(xié)議TTP/C。在傳統(tǒng)分布式實(shí)時(shí)操作系統(tǒng)領(lǐng)域,Kane Kim提出了基于NT和Linux的時(shí)間觸發(fā)支持的操作系統(tǒng)架構(gòu);Giotto把時(shí)間觸發(fā)架構(gòu)提升到了編程語言的層面。此后,有關(guān)時(shí)間觸發(fā)架構(gòu)的研究大量涌現(xiàn)[5,6]。隨著單機(jī)內(nèi)計(jì)算核心數(shù)目的增多,傳統(tǒng)操作系統(tǒng)會(huì)產(chǎn)生嚴(yán)重的性能下降,針對(duì)此,Andrew Baumann和Paul Barham等提出了Multikernel架構(gòu)。Barrelfish作為開源的Multikernel操作系統(tǒng),為分布式的多核異構(gòu)系統(tǒng)提供了更高效的操作系統(tǒng)基礎(chǔ)設(shè)施。
本文將時(shí)間觸發(fā)架構(gòu)的設(shè)計(jì)思想應(yīng)用于以Barrelfish為代表的Multikernel系統(tǒng)中,依靠SMT[7]理論,對(duì)Barrelfish的消息進(jìn)行建模,從而生成滿足所有約束的消息調(diào)度表,設(shè)計(jì)和實(shí)現(xiàn)時(shí)間觸發(fā)的任務(wù)調(diào)度模型、系統(tǒng)通信服務(wù)以及配套的時(shí)間觸發(fā)任務(wù)和通信的配置管理工具,形成可用的Multikernel架構(gòu)分布式硬實(shí)時(shí)系統(tǒng)。
1 基于Barrelfish的時(shí)間觸發(fā)實(shí)時(shí)通信框架設(shè)計(jì)
基于Barrelfish的時(shí)間觸發(fā)通信框架主要包含運(yùn)行時(shí)和離線兩部分,其中,運(yùn)行時(shí)部分的架構(gòu)如圖1所示。運(yùn)行時(shí)部分負(fù)責(zé)支撐Barrelfish在部署及啟動(dòng)后的時(shí)間觸發(fā)實(shí)時(shí)消息通信。圖1中描述了兩個(gè)通過實(shí)時(shí)交換機(jī)相連的SoC節(jié)點(diǎn),每個(gè)SoC節(jié)點(diǎn)共有兩塊通過TTNoC相連的多核CPU。每個(gè)多核CPU上需要抽調(diào)出一個(gè)單獨(dú)的核心以運(yùn)行時(shí)間觸發(fā)實(shí)時(shí)消息服務(wù),該消息服務(wù)是一個(gè)CPU上所有應(yīng)用程序與其它CPU上的應(yīng)用進(jìn)行通信的網(wǎng)關(guān)[8]。此外,一些實(shí)時(shí)應(yīng)用有并行多線程的需要,而Barrelfish本身并不支持同一個(gè)進(jìn)程中的線程在多個(gè)CPU核心上運(yùn)行,缺乏這種并行特性會(huì)導(dǎo)致一些消息無法及時(shí)生成,使得整個(gè)系統(tǒng)不可調(diào)度,因此,該運(yùn)行時(shí)還包含有一個(gè)以Group為核心組件的動(dòng)態(tài)SMP(symmetrical multi-processing)子系統(tǒng)。
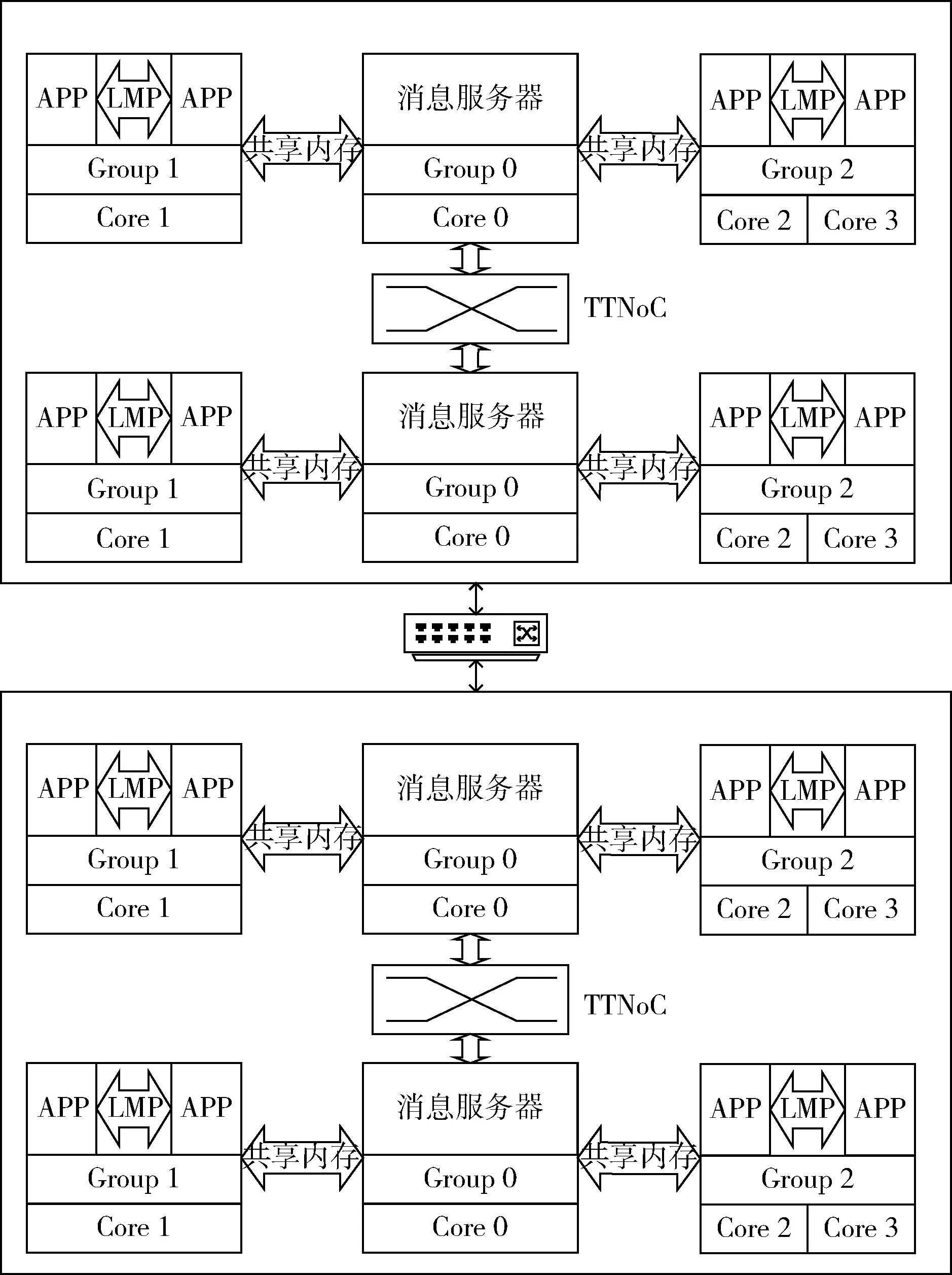
圖1 時(shí)間觸發(fā)通信框架-運(yùn)行時(shí)部分
消息服務(wù)是整個(gè)系統(tǒng)運(yùn)行時(shí)的基礎(chǔ)設(shè)施。該消息服務(wù)在系統(tǒng)啟動(dòng)時(shí)負(fù)責(zé)讓系統(tǒng)到達(dá)一致狀態(tài),在系統(tǒng)運(yùn)行期間,解析時(shí)間觸發(fā)消息調(diào)度表,提供消息在SoC內(nèi)部或跨SoC的消息轉(zhuǎn)發(fā)功能,并以API的形式為時(shí)間觸發(fā)實(shí)時(shí)應(yīng)用程序提供通信接口。此外,消息服務(wù)不僅需要在系統(tǒng)運(yùn)行期間進(jìn)行各個(gè)節(jié)點(diǎn)時(shí)間的同步,還需要維護(hù)各個(gè)節(jié)點(diǎn)的組籍狀態(tài),在節(jié)點(diǎn)失效時(shí),利用冗余備份機(jī)制恢復(fù)系統(tǒng)的可用性。以Group為核心的動(dòng)態(tài)SMP子系統(tǒng)可以在運(yùn)行時(shí)動(dòng)態(tài)地改變某一系統(tǒng)分區(qū)的計(jì)算能力,提高此分區(qū)的多核并行計(jì)算能力,防止過多的分區(qū)和單核有限的計(jì)算能力對(duì)系統(tǒng)的可調(diào)度性產(chǎn)生影響。
基于Barrelfish的時(shí)間觸發(fā)通信框架的離線部分包含一個(gè)時(shí)間觸發(fā)消息調(diào)度器,在對(duì)整個(gè)時(shí)間觸發(fā)系統(tǒng)完成設(shè)計(jì),得到應(yīng)用程序的消息規(guī)范之后,調(diào)度器可以根據(jù)硬件網(wǎng)絡(luò)約束和應(yīng)用程序約束得到一組滿足系統(tǒng)整體約束的消息調(diào)度表。該消息調(diào)度表規(guī)定了在何時(shí)有什么消息從何發(fā)送節(jié)點(diǎn)發(fā)送到哪些接收節(jié)點(diǎn)。運(yùn)行時(shí)中的消息服務(wù)會(huì)解析該調(diào)度表,并依據(jù)全局時(shí)間基,在調(diào)度表規(guī)定的時(shí)間槽執(zhí)行相應(yīng)的消息轉(zhuǎn)發(fā)動(dòng)作。圖2展示了基于Barrelfish的時(shí)間觸發(fā)通信框架的離線和運(yùn)行時(shí)部分的關(guān)系。

圖2 時(shí)間觸發(fā)通信框架-離線和運(yùn)行時(shí)部分的關(guān)系
下面分別從消息服務(wù)、動(dòng)態(tài)SMP子系統(tǒng)和時(shí)間觸發(fā)消息調(diào)度器等3個(gè)方面展開敘述。
1.1 消息服務(wù)設(shè)計(jì)
針對(duì)時(shí)間觸發(fā)的實(shí)時(shí)消息通信,本文設(shè)計(jì)了一套稱之為MDL(message description list)的領(lǐng)域特定的調(diào)度表格式。靜態(tài)消息調(diào)度器負(fù)責(zé)生成MDL,消息服務(wù)通過解析MDL語句,按照MDL描述的調(diào)度時(shí)機(jī)和要采取的動(dòng)作進(jìn)行消息的調(diào)度。消息調(diào)度器在解析MDL的過程中,會(huì)保證數(shù)據(jù)幀的完整性和正確性,同時(shí)也會(huì)保證數(shù)據(jù)傳輸?shù)臅r(shí)序正確。
MDL通過全局時(shí)間基給出的時(shí)間槽為最小時(shí)隙單位。MDL設(shè)計(jì)了一種多等級(jí)的結(jié)構(gòu):最上層為集群描述符,一個(gè)集群描述符可以包含多個(gè)節(jié)點(diǎn)描述符,一個(gè)節(jié)點(diǎn)描述符又由多個(gè)時(shí)隙描述符組成。為了保證MDL語言的二進(jìn)制兼容性,MDL在所有架構(gòu)上都采用小端模式儲(chǔ)存。
為了簡(jiǎn)化基本消息服務(wù)的設(shè)計(jì),保證整個(gè)系統(tǒng)的一致性,無論是SoC內(nèi)部還是SoC間的消息傳輸皆使用同一套數(shù)據(jù)幀格式。本節(jié)所采用的數(shù)據(jù)幀格式由幀頭和數(shù)據(jù)體構(gòu)成,其結(jié)構(gòu)如圖3所示。

圖3 實(shí)時(shí)消息幀格式
幀頭主要包含協(xié)議相關(guān)的語義屬性,數(shù)據(jù)校驗(yàn)位等。數(shù)據(jù)幀的類型由幀頭中的相關(guān)位確定。數(shù)據(jù)幀一共有兩種類型:一種稱為普通幀,搭載用戶數(shù)據(jù)的幀屬于此種類型;第二種幀稱為節(jié)點(diǎn)控制幀,用于節(jié)點(diǎn)間維護(hù)在線關(guān)系,同步時(shí)鐘等;此外,幀頭中還包括校驗(yàn)位,為了減少校驗(yàn)算法帶來的額外開銷,本框架采用CRC校驗(yàn)法作為消息完整性的檢查算法。
1.2 動(dòng)態(tài)SMP子系統(tǒng)設(shè)計(jì)
Barrelfish無法利用多核并行能力的原因是其CPU Driver與CPU Core的對(duì)應(yīng)關(guān)系高度耦合,在目前的實(shí)現(xiàn)中,CPU Driver與CPU Core為多對(duì)一關(guān)系。SpaceJMP[9]提出把虛擬地址空間當(dāng)作操作系統(tǒng)的一種頭等對(duì)象,允許一個(gè)進(jìn)程可以在多個(gè)地址空間中快速切換,從而實(shí)現(xiàn)共享大段內(nèi)存的目的。這種編程模型可以模擬出傳統(tǒng)的Unix線程,但是由于添加了特殊的編程語言,需要特殊的編譯器。頻繁的切換地址空間對(duì)TLB和Cache都不友好,軟硬件兼容性方面都不是非常優(yōu)秀。我們可以通過設(shè)計(jì)一種新的消息傳遞基礎(chǔ)設(shè)施,開發(fā)了一種基于任務(wù)派生—合并的并行任務(wù)模型(類似于MapReduce算法),但由于涉及了大量小任務(wù)的遷移、調(diào)度和同步,這種編程框架本身會(huì)產(chǎn)生較大的消息通信開銷和同步等待的開銷,此外,該編程模型只適用于解決分治算法,無法使用常規(guī)并行多線程算法。
為了解決這個(gè)問題,本文設(shè)計(jì)了一個(gè)稱為Group的核心系統(tǒng)組件,其架構(gòu)如圖4所示。

圖4 Barrelfish的Group架構(gòu)
為了減少對(duì)已有服務(wù)程序的更改,需要考慮到現(xiàn)有的服務(wù)程序都以線程不安全的方式實(shí)現(xiàn),無法并行執(zhí)行多線程,因此需要提供一種機(jī)制,在執(zhí)行線程不安全的服務(wù)程序時(shí),禁用并行的特性,只允許一個(gè)CPU Core串行的執(zhí)行程序。本文采用如下方案解決這個(gè)問題。當(dāng)Group中包含多個(gè)Core時(shí),選取其中一個(gè)核心為主核心,負(fù)責(zé)Group的合并和拆分以及系統(tǒng)進(jìn)程的運(yùn)行;其它的Core則成為成員核心,負(fù)責(zé)運(yùn)行其它的進(jìn)程。主核心不可以脫離當(dāng)前Group,成員核心則可以自由地附著到其它的核心。
1.3 時(shí)間觸發(fā)消息調(diào)度器設(shè)計(jì)
本文定義了一個(gè)時(shí)間觸發(fā)實(shí)時(shí)網(wǎng)絡(luò)中的所有約束條件。為了簡(jiǎn)化約束的書寫,本節(jié)做了如下假定:
(1)整個(gè)集群的超周期被劃分為長(zhǎng)度相等的時(shí)間片,該時(shí)間片的長(zhǎng)度為全局時(shí)間基的時(shí)間粒度的整數(shù)倍,稱之為集群超周期。超周期的值可用所有幀的周期的最小公倍數(shù)計(jì)算得到。
(2)每個(gè)節(jié)點(diǎn)在發(fā)送或者中繼消息時(shí),發(fā)送一個(gè)數(shù)據(jù)幀只占用一個(gè)時(shí)間槽。
(3)對(duì)于同一個(gè)應(yīng)用發(fā)送的消息,將以相同的路徑到達(dá)接收者。
在此基礎(chǔ)上,可以對(duì)約束條件進(jìn)行簡(jiǎn)化的表示。本文把約束條件分為硬件約束條件和軟件約束條件兩類進(jìn)行描述:
(1)硬件約束條件
硬件約束條件中最基礎(chǔ)的是發(fā)送端口獨(dú)占約束,即無競(jìng)爭(zhēng)約束。該條件意味著一個(gè)發(fā)送節(jié)點(diǎn)或者一個(gè)中繼節(jié)點(diǎn)只有在前一條數(shù)據(jù)幀完全發(fā)送完畢之后,才可以開始發(fā)送下一條數(shù)據(jù)幀。
(2)軟件約束條件
端到端消息傳輸約束描述了應(yīng)用程序要求的數(shù)據(jù)幀端到端傳輸?shù)淖畲髸r(shí)延,該最大延遲必須小于應(yīng)用發(fā)送幀的周期。對(duì)于多播傳輸,假設(shè)所有的接收者都具有相同的端到端傳輸時(shí)延要求。
求解最優(yōu)數(shù)據(jù)虛鏈路時(shí),本文采用以下目標(biāo)函數(shù)
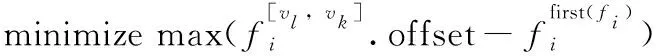
(1)

該目標(biāo)函數(shù)要求整個(gè)系統(tǒng)調(diào)度數(shù)據(jù)幀的最大延遲最小,最大數(shù)據(jù)幀延遲越小,總體延遲越小,系統(tǒng)利用率越高。
最優(yōu)解算法在面對(duì)較大規(guī)模數(shù)據(jù)集時(shí),無法在可以接受的時(shí)間內(nèi)得到一個(gè)解[10],因此本文不采用最優(yōu)解算法,而是使用目前比較成熟的近似算法(如Wang[11]、Lee[12]等),在多項(xiàng)式時(shí)間內(nèi),求出該問題的近似最優(yōu)解。
2 基于Barrelfish的時(shí)間觸發(fā)實(shí)時(shí)通信框架實(shí)現(xiàn)
2.1 消息服務(wù)實(shí)現(xiàn)
時(shí)間觸發(fā)實(shí)時(shí)通信框架提供的消息服務(wù)API接口見表1。

表1 Barrelfish實(shí)時(shí)通信框架操作接口
其中,最核心的功能是消息收發(fā)接口,時(shí)間觸發(fā)的實(shí)時(shí)應(yīng)用程序可以調(diào)用這兩個(gè)接口進(jìn)行消息的收發(fā)。當(dāng)發(fā)送消息時(shí),調(diào)用該接口后,應(yīng)用程序?qū)⒁l(fā)送的消息數(shù)據(jù)會(huì)被復(fù)制到相應(yīng)消息通道的緩沖區(qū)內(nèi),當(dāng)調(diào)度表規(guī)定的消息傳輸時(shí)刻到來時(shí),消息服務(wù)會(huì)把該消息從緩沖區(qū)中取出,并復(fù)制到目標(biāo)緩沖區(qū)中。當(dāng)接收消息時(shí),調(diào)用該接口后,會(huì)根據(jù)調(diào)度表的時(shí)刻,等待到消息到來的時(shí)刻。在此期間,消息服務(wù)會(huì)把要接收的消息從發(fā)送者的緩沖區(qū)復(fù)制到接收者消息通道緩沖區(qū)內(nèi),當(dāng)時(shí)刻到來后,該接口會(huì)將消息從消息通道中復(fù)制到應(yīng)用程序的數(shù)據(jù)緩沖區(qū),供應(yīng)用程序使用,然后喚醒應(yīng)用程序進(jìn)行后續(xù)的計(jì)算操作。
2.2 動(dòng)態(tài)SMP子系統(tǒng)實(shí)現(xiàn)
系統(tǒng)的實(shí)現(xiàn)主要可分為兩部分,一方面是對(duì)CPU Dri-ver 的更改,將CPU Driver對(duì)CPU Core的依賴,更改為對(duì)Group的依賴,并將CPU Driver修改為線程安全的實(shí)現(xiàn)。另一方面是對(duì)libbarrelfish的更改。libbarrelfish把各個(gè)系統(tǒng)服務(wù)提供的各項(xiàng)功能整合到了一起,封裝成為易用的API,應(yīng)用程序借助該庫能獲得完備的操作系統(tǒng)功能。
(1)針對(duì)CPU Driver的SMP實(shí)現(xiàn)
CPU Driver中的數(shù)據(jù)段,根據(jù)數(shù)據(jù)使用者的不同,可分為兩類。一類數(shù)據(jù)代表了CPU Core的狀態(tài),另一類數(shù)據(jù)則代表了該CPU Driver本身的狀態(tài)。
對(duì)于前者,代表CPU Core狀態(tài)的數(shù)據(jù)由Group組件統(tǒng)一管理,Group組件會(huì)將這些數(shù)據(jù)項(xiàng)復(fù)制多份,保證每個(gè)核心都有相對(duì)應(yīng)的唯一的數(shù)據(jù),并由Group組件為CPU Driver提供相關(guān)的讀取、寫入接口。
對(duì)于后者,考慮到需要保護(hù)的關(guān)鍵代碼段通常不是很大,可以使用自旋鎖對(duì)這部分?jǐn)?shù)據(jù)進(jìn)行保護(hù)。在多核并行場(chǎng)景下,自旋鎖可以保證核間臨界資源的正確性[13]。自旋鎖與互斥鎖、信號(hào)量類似,只是自旋鎖不會(huì)引起調(diào)用者阻塞。如果自旋鎖已經(jīng)被其它執(zhí)行體占有,調(diào)用者就一直循環(huán)檢測(cè)自旋鎖是否被釋放,是否處于空閑狀態(tài),這個(gè)循環(huán)過程就是自旋。自旋鎖的占有時(shí)間非常短,因此調(diào)用者不被阻塞而在那自旋,比上下文切換節(jié)省時(shí)間開銷,效率遠(yuǎn)高于互斥鎖、信號(hào)量。但普通自旋鎖具有隨機(jī)占有的特性,這帶來了調(diào)度上的不公平。為了避免這個(gè)不公平問題,本文使用了被稱為輪轉(zhuǎn)自旋鎖的技術(shù),與普通自旋鎖的隨機(jī)占有鎖的方式不同,每個(gè)核心采用排隊(duì)的方式獲取自旋鎖,這樣每個(gè)CPU核心都有相同的概率獲得鎖的使用權(quán)。
(2)針對(duì)libbarrelfish的SMP實(shí)現(xiàn)
本文采用一種稱為代理執(zhí)行的方法來解決libbarrelfish中存在的數(shù)據(jù)競(jìng)爭(zhēng)問題。這種方法的核心在于,在一個(gè)Group中,只允許主核心執(zhí)行Disabled狀態(tài)的Dispatcher。成員核心只允許執(zhí)行用戶創(chuàng)建的線程的代碼和線程調(diào)度器。當(dāng)成員核心上的線程需要切換到Disabled狀態(tài)時(shí),會(huì)首先將線程遷移到主核心上,其中,線程的遷移可以利用線程對(duì)處理器核心的親和性來完成。
另一個(gè)需要改動(dòng)的點(diǎn)是Barrelfish的消息機(jī)制,Barrelfish系統(tǒng)中的LMP消息是基于Upcall實(shí)現(xiàn)的,UMP消息則是通過輪詢實(shí)現(xiàn)。為了避免在消息處理相關(guān)的代碼中產(chǎn)生數(shù)據(jù)競(jìng)爭(zhēng),新的消息機(jī)制只允許Group內(nèi)的主核心執(zhí)行相關(guān)的代碼,負(fù)責(zé)所有消息的轉(zhuǎn)發(fā)和輪詢。
2.3 時(shí)間觸發(fā)消息調(diào)度器實(shí)現(xiàn)
本文設(shè)計(jì)了兩種實(shí)時(shí)調(diào)度器,一種是基礎(chǔ)時(shí)間觸發(fā)實(shí)時(shí)消息調(diào)度器,另一種是增量時(shí)間觸發(fā)實(shí)時(shí)消息調(diào)度器。SMT求解器選用微軟的開源求解器Z3,并使用它提供的Python API進(jìn)行編寫。增量時(shí)間觸發(fā)實(shí)時(shí)消息調(diào)度器會(huì)在兩個(gè)求解階段間多次切換,并使用Z3提供的回溯功能。
(1)基礎(chǔ)時(shí)間觸發(fā)實(shí)時(shí)消息調(diào)度器實(shí)現(xiàn)
基礎(chǔ)求解器的實(shí)現(xiàn)較為簡(jiǎn)單,在基礎(chǔ)求解器中,會(huì)首先把所有數(shù)據(jù)幀的約束條件添加到SMT求解器上下文中,然后調(diào)用SMT求解器的求解函數(shù),SMT求解器會(huì)首先檢查這些約束條件是否具有一致性,若滿足一致性,便可以計(jì)算得到本組約束的解。這組解可以通過SMT求解器提供的API函數(shù)得到。
(2)增量時(shí)間觸發(fā)實(shí)時(shí)消息調(diào)度器實(shí)現(xiàn)
由于SMT求解器對(duì)一次求解的約束條件數(shù)目有所限制,當(dāng)約束規(guī)模較大時(shí),無法將全部約束一次性全部添加到求解器中。為了解決這個(gè)問題,本文設(shè)計(jì)的增量調(diào)度器不會(huì)一次性生成全部的約束條件,而是逐次地將約束條件的子集加入到SMT求解器中并進(jìn)行多次求解。在每次子集的求解完成之后,會(huì)按照這一部分的求解結(jié)果,把數(shù)據(jù)幀的偏移固定下來,作為下一次求解的約束輸入。這樣的方案可能會(huì)導(dǎo)致求解器在中間某次求解過程中返回失敗,對(duì)于錯(cuò)誤的處理,本文采用回溯的方法,逐步增大之前的約束子集的數(shù)目。當(dāng)SMT求解器無法在規(guī)定的時(shí)間內(nèi)得到一組解,或是約束子集的數(shù)目超過了預(yù)先設(shè)定的閾值,則認(rèn)為調(diào)度失敗。
增量調(diào)度算法開始時(shí),首先生成這一數(shù)據(jù)幀范圍內(nèi)的約束,并檢查是否存在針對(duì)這一部分的可行解。若存在可行解,則從求解器中獲取解,并把這些解保存到本地變量中,作為新的常量約束并用于下一輪的約束。最后,把輸入的幀集合更新為下一輪的集合。
在最壞情況下,回溯過程有可能回溯到數(shù)據(jù)幀序列的第一幀。在這種情況下,增量調(diào)度器等價(jià)于基礎(chǔ)調(diào)度器。當(dāng)調(diào)度器沒有能在合理時(shí)間內(nèi)得到解時(shí),便會(huì)終止求解算法,回溯到前面得到部分解的步驟,并返回當(dāng)前已經(jīng)得到的時(shí)間表。調(diào)度算法求解的中斷可采用封裝好的信號(hào)中斷函數(shù)。
至此,基于Barrelfish的時(shí)間觸發(fā)實(shí)時(shí)通信框架的設(shè)計(jì)與實(shí)現(xiàn)已經(jīng)完成。
3 基于Barrelfish的時(shí)間觸發(fā)實(shí)時(shí)通信框架實(shí)驗(yàn)結(jié)果與分析
本文先分別針對(duì)如下3個(gè)部分做了驗(yàn)證和測(cè)試:消息通信服務(wù)的正確性及其功能實(shí)現(xiàn)的完整性、時(shí)間觸發(fā)通信消息調(diào)度算法及調(diào)度器的正確性、Barrelfish的動(dòng)態(tài)SMP子系統(tǒng)的性能,最后對(duì)整個(gè)框架進(jìn)行綜合測(cè)試。
為了對(duì)通信框架和動(dòng)態(tài)SMP子系統(tǒng)兩部分的結(jié)果進(jìn)行驗(yàn)證,本文采用了軟件模擬和真實(shí)硬件兩套環(huán)境開展實(shí)驗(yàn)。其中,軟件模擬部分使用QEMU,硬件部分使用NVIDIA Jetson TK1作為實(shí)驗(yàn)平臺(tái)。兩者皆以ARM為計(jì)算平臺(tái)架構(gòu)。具體的硬件參數(shù)見表2。

表2 實(shí)驗(yàn)平臺(tái)硬件參數(shù)
對(duì)于調(diào)度算法的驗(yàn)證,本文首先通過一定規(guī)則生成了一個(gè)測(cè)試集合,然后對(duì)調(diào)度算法的性能、正確性和調(diào)度結(jié)果的質(zhì)量做了評(píng)測(cè)。
(1)消息服務(wù)性能測(cè)試
本部分主要測(cè)量了時(shí)間觸發(fā)通信的延遲,該延遲是SMT調(diào)度表求解的重要參數(shù)。測(cè)試時(shí),在系統(tǒng)的兩個(gè)核心上分別建立服務(wù)端和客戶端兩個(gè)進(jìn)程,客戶端向服務(wù)端發(fā)送請(qǐng)求后,服務(wù)端立刻返回一條消息。通過消息的往返發(fā)送,可以測(cè)量出延遲。本次測(cè)試中,每經(jīng)過一萬個(gè)消息往返,記錄一次時(shí)延,測(cè)試結(jié)果如圖5所示。
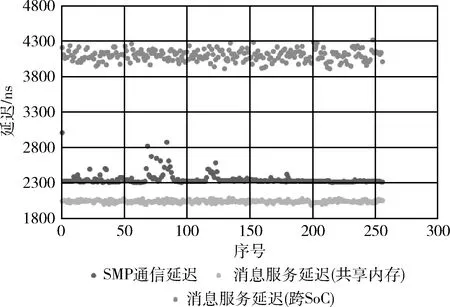
圖5 Barrelfish實(shí)時(shí)通信延遲
從圖5中可以看出,SMP通信機(jī)制容易受到內(nèi)核調(diào)度器和其它系統(tǒng)進(jìn)程的影響,消息的時(shí)延抖動(dòng)相對(duì)較大,但是依然滿足實(shí)時(shí)應(yīng)用的要求。對(duì)于通過消息轉(zhuǎn)發(fā)服務(wù)收發(fā)的SoC內(nèi)部消息,由于采取了輪詢機(jī)制,平均延遲較小,且抖動(dòng)較小。對(duì)于跨SoC的消息,由于目前采用普通TCP/IP網(wǎng)絡(luò)進(jìn)行測(cè)量,抖動(dòng)比較嚴(yán)重。
(2)調(diào)度算法性能測(cè)試
本文一共測(cè)試了3種網(wǎng)絡(luò)拓?fù)洌謩e是星狀網(wǎng)絡(luò),樹狀網(wǎng)絡(luò)和雪花狀網(wǎng)絡(luò)。針對(duì)每種網(wǎng)絡(luò)拓?fù)洌S機(jī)生成一系列的幀集合,并隨機(jī)生成一定比例的約束條件(本文使用幀數(shù)的20%作為應(yīng)用級(jí)約束),然后使用求解器進(jìn)行求解。調(diào)度器求解時(shí)間的統(tǒng)計(jì)結(jié)果如圖6所示。
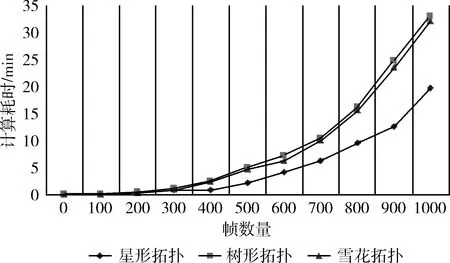
圖6 各種網(wǎng)絡(luò)拓?fù)鋽?shù)據(jù)幀調(diào)度耗時(shí)
(3)動(dòng)態(tài)SMP子系統(tǒng)測(cè)試
動(dòng)態(tài)SMP子系統(tǒng)本質(zhì)上是實(shí)現(xiàn)了共享地址空間的并行方案。共享內(nèi)存實(shí)際上是共享部分物理內(nèi)存,而動(dòng)態(tài)SMP子系統(tǒng)則是共享整個(gè)虛擬地址空間,本質(zhì)上來看兩者區(qū)別只是共享空間的大小不同,但是動(dòng)態(tài)SMP子系統(tǒng)提供了一個(gè)更友好的編程接口。為了驗(yàn)證兩種方案對(duì)性能的影響,本文通過矩陣相乘算法,對(duì)兩種方法的性能進(jìn)行了測(cè)試。
測(cè)試結(jié)果如圖7和圖8所示。

圖7 Qemu中共享內(nèi)存與動(dòng)態(tài)SMP子系統(tǒng)性能對(duì)比

圖8 Jetson TK1中共享內(nèi)存與動(dòng)態(tài)SMP子系統(tǒng)性能對(duì)比
由測(cè)試結(jié)果可以看出,共享內(nèi)存方案由于存在通信延遲,其性能比動(dòng)態(tài)SMP子系統(tǒng)方案要略微差一些。但是兩者都能起到并行執(zhí)行的效果,相比于單核心執(zhí)行,并行執(zhí)行能夠明顯地提高性能。
(4)綜合測(cè)試
為了對(duì)整個(gè)系統(tǒng)進(jìn)行驗(yàn)證,本文設(shè)計(jì)了如圖9所示的網(wǎng)絡(luò)結(jié)構(gòu),由于缺乏時(shí)間觸發(fā)實(shí)時(shí)網(wǎng)絡(luò)硬件的支撐,本節(jié)將使用Qemu搭建虛擬網(wǎng)絡(luò)進(jìn)行模擬驗(yàn)證。
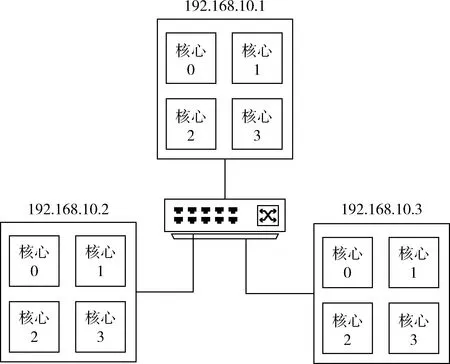
圖9 綜合實(shí)驗(yàn)組網(wǎng)
網(wǎng)絡(luò)中,每個(gè)節(jié)點(diǎn)上運(yùn)行有X64架構(gòu)的四核心處理器,節(jié)點(diǎn)間通過Qemu虛擬交換機(jī)相連。每個(gè)節(jié)點(diǎn)內(nèi)部的通信不受限制,相當(dāng)于CPU內(nèi)部的核心間有兩兩相連的通信鏈路,節(jié)點(diǎn)間產(chǎn)生通信時(shí),每個(gè)節(jié)點(diǎn)在一個(gè)時(shí)間槽只能發(fā)出一條消息。每個(gè)有依賴應(yīng)用的應(yīng)用,只有在接收到依賴應(yīng)用發(fā)來的消息之后間隔一個(gè)時(shí)間槽,才可以發(fā)送消息。
本文設(shè)計(jì)了如表3所示的綜合實(shí)驗(yàn)應(yīng)用。

表3 綜合實(shí)驗(yàn)應(yīng)用設(shè)計(jì)
由表3可知,集群的超周期為24。針對(duì)應(yīng)用的周期,調(diào)度器生成了實(shí)時(shí)調(diào)度表,如圖10所示。

圖10 實(shí)時(shí)調(diào)度器生成調(diào)度表
調(diào)度表的成功生成表明了基于Barrelfish的時(shí)間觸發(fā)實(shí)時(shí)通信框架的正確性與可行性。
4 結(jié)束語
本文在Barrelfish的基礎(chǔ)上設(shè)計(jì)與實(shí)現(xiàn)了一套基于時(shí)間觸發(fā)機(jī)制的實(shí)時(shí)通信架構(gòu),該架構(gòu)包括一套獨(dú)立的時(shí)間觸發(fā)實(shí)時(shí)消息服務(wù)、接口以及用于時(shí)間觸發(fā)實(shí)時(shí)系統(tǒng)消息調(diào)度的靜態(tài)離線調(diào)度算法和調(diào)度器。該通信架構(gòu)為Multikernel架構(gòu)在分布式CPS實(shí)時(shí)系統(tǒng)上的應(yīng)用打下了基礎(chǔ)。
該通信架構(gòu)仍有如下地方有待改進(jìn):
(1)每個(gè)SoC上都需要分出單獨(dú)核心運(yùn)行時(shí)間觸發(fā)實(shí)時(shí)消息服務(wù),對(duì)CPU資源產(chǎn)生了較大浪費(fèi)。
(2)目前尚未給出綜合消息調(diào)度與任務(wù)調(diào)度的完整解決方案。
(3)當(dāng)前測(cè)試所使用的硬件系統(tǒng)規(guī)模較小。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(hào)(2018年5期)2018-06-28 03:06:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
知識(shí)經(jīng)濟(jì)·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(shù)(2016年6期)2016-04-20 06:21:32
