基于半監督學習的命名實體識別的方法
2020-04-21 07:40:59劉一鳴
數字技術與應用 2020年1期
劉一鳴


摘要:命名實體識別是信息抽取中基礎且關鍵的一項子任務。本文根據不同領域文本的特性,設置了通用的特征模板,利用半監督學習的方法,對新聞文本和橋梁文本分別進行了命名實體識別。實驗表明,僅使用少量標注的語料也可以達到較好的識別效果。
關鍵詞:命名實體識別;自學習方法;半監督學習
中圖分類號:TP391.4 文獻標識碼:A 文章編號:1007-9416(2020)01-0207-02
命名實體識別概述
隨著信息技術的發展,網絡數據出現飛速增長的趨勢,并呈現出多源異構等大數據特征。對其進行信息抽取,獲得有效信息對于文本數據分析具有重要的研究意義。
命名實體識別是信息抽取過程中十分基礎且關鍵的一項子任務。命名實體識別是指識別出文本中例如人名,地名,時間或組織名等具有特定意義的實體。
大多數命名實體識別的方法都是基于規則[1]的方法或基于監督學習[2]的方法。其中基于規則的方法需要專業人員去設置規則模板,但是規則之間可能會出現沖突,且可移植性和擴展性差。基于監督學習的方法十分依靠大量的標注文本,在通常情況下標注文本是極難獲取的,且使用人工標注的成本較大。因此,只需要少量標注語料的基于半監督學習的命名實體識別方法成為了領域內研究的熱門。
2 研究現狀
命名實體識別一直是自然語言處理領域研究的基礎性問題,其本質可看作序列化數據標記問題[3]。
早期的命名實體方法是在限定文本領域、限定語義單元類型的條件下進行的,采用的是基于規則與詞典的方法。Rau等人采用啟發式算法與人工編寫規則相結合的方法,首次實現了從文本中自動抽取公司名,但擴展性差,規則制定費時費力。
Wang等人采用有監督的統計學習方法,針對于臨床醫學的記錄進行命名實體識別,利用大量的標注樣本進行條件隨機場模型(conditional random fields,CRF)的學習,并最終取得了F值81.48%的成績。
條件隨機場是Lafferty等人于在隱馬爾可夫模型(HMM)和最大熵模型(MEMM)的基礎上提出的一種概率式判別模型。它可以充分結合觀察序列中的多種特征信息,來克服HMM中嚴格的強獨立性假設問題。以上的方法都需要大量的標注語料作為數據支撐,僅需少量語料的半監督學習方法[4]也取得一定成就。Jonnalagadda等人在醫學領域采用了半監督CRF的方法對臨床醫學實體進行識別,并提出了分布式語義方法,最終實驗F值為0.823%。Ke等人在少量標注語料的情況下, 結合大量的未標注語料,應用協同訓練算法實現中文組織名的識別, 協同訓練CRF模型和SVM模型,最終模型F值比單個模型F值高出10%。
設X與Y為隨機變量,P(Y|X)是在給定X的條件下,Y的條件概率分布。設P(Y|X)為條件隨機場,X取值為x的條件下,Y取值為y的條件概率如下公式:
自學習方法是有監督和無監督學習相結合的統計機器學習方法,其可通過大量未標注語料與少量已標注語料自行進行訓練及分類,整個過程不需要人工來干預。而其中自舉法(Bootstrapping)是自學習中常用的一種方法,具體的流程如圖1所示。自學習算法流程如圖1所示,首先,利用獲得的少量標注語料L放入CRF模型中學習,用訓練好的CRF模型c0對大量的未標注預料U進行預測,將置信度高于80%的句子u加入到標注集L中并在未標注集U中刪除,重復此過程直到模型收斂,最終得到模型Cn。
在CRF模型的訓練中,選取合適的特征并創建特征模板是影響模型性能的關鍵[5]。為了設置適合于多領域的文本特征模板,我們選取了以下5個特征。
(1)上下文特征:本文選擇上下文2個詞作為上下文特征,例如,“造就一支穩定的基礎研究的隊伍”這句話中,“研究”一詞上文兩個詞特征為“的”和“基礎”兩個詞。(2)位置特征:詞語在句子的位置在命名實體識別中起到了關鍵的作用,在“開展各種形式的科學普及教育”一句中,“科學”一詞位置為5。(3)長度特征:本文選取詞語的長度作為基礎特征之一,例如,“新年”詞語的長度為2。(4)字符特征:在命名實體中,通常存在詞語中包含數字、符號或者英文字母的實體。例如,“3#人行天橋”和“1994年”兩詞語中都包含數字,前者還包含了特殊符號。(5)詞向量特征:利用詞向量工具Word2Vec對大量未標注數據進行詞向量訓練并進行聚類,類別作為特征的一部分加入到模板中。例如,“遼寧省”聚類類別為64。
為測試自學習方法在不同領域語料的效果,我們選擇了橋梁語料和新聞語料兩個領域的語料,分別為1998年人民日報語料庫和自標注的橋梁語料庫。
本文使用爬蟲技術,在網絡上爬取了兩個領域的大量未標注語料,利用分詞工具jieba對其分詞,并利用詞向量工具Word2Vec進行詞向量訓練和聚類。
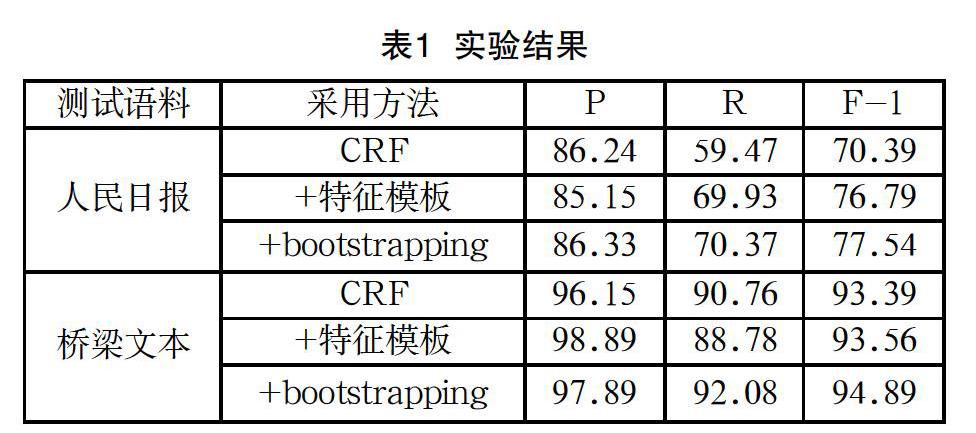
實驗結果如表1所示,在使用特征模板后,模型的效果獲得較大幅度提升,通過自學習算法,最終模型效果進一步加強,根據文本特性選取適合的特征和選取的學習方式同樣重要,在僅有少量語料的情況下使用自學習方法可以提高模型的質量。
本文針對不同領域語料,采用CRF模型,選取上下文特征、位置特征、長度特征、字符特征,同時利用大規模的未標注數據,通過詞向量訓練和聚類獲取詞向量特征,并進行了對比實驗。實驗表明,利用半監督學習的方式,無論在橋梁領域還是新聞領域效果都有所提升,詞向量特征能夠從大規模的未標注數據集中獲取詞的語義信息,并且相比于人工選取和設置的特征,無監督學習可以減少大量的工作量,提高命名實體識別的性能。
[1] 閆丹輝,畢玉德.基于規則的越南語命名實體識別研究[J].中文信息學報,2014,28(05):198-205+214.
[2] 潘清清,周楓,余正濤,等.基于條件隨機場的越南語命名實體識別方法[J].山東大學學報(理學版),2014,49(01):76-79.
[3] 張海楠,伍大勇,劉悅,等.基于深度神經網絡的中文命名實體識別[J].中文信息學報,2017,31(04):28-35.
[4] 蔡月紅,朱倩,程顯毅.基于Tri-training半監督學習的中文組織機構名識別[J].計算機應用研究,2010,27(01):193-195.
[5] 邱泉清,苗奪謙,張志飛.中文微博命名實體識別[J].計算機科學,2013,40(06):196-198.
