橋梁檢測領域命名實體識別
2020-04-21 07:40:59李童
數字技術與應用 2020年1期
李童
摘要:為了實現橋梁檢測領域文本命名實體的有效識別,本文提出了一種基于深度神經網絡的學習方法,首先利用卷積神經網絡中的卷積層可以有效的描述數據的局部特征,再用BiLSTM-CRF深度神經網絡模型進行命名實體標注。實驗結果表明與主流BiLSTM-CRF模型相比較,CNN-BiLSTM-CRF模型在各項指標上都有一定的提升效果。
關鍵詞:命名體識別;LSTM;CRF
中圖分類號:TP391.1;TP183 文獻標識碼:A 文章編號:1007-9416(2020)01-0235-02
0 引言
隨著交通基礎設施建設的快速發展,中國正在逐步從橋梁大國發展為橋梁強國。如何對橋梁運營期的服役狀況進行全面監管,保障橋梁的安全可靠性,及時發現重要結構病害,實施科學合理的維修加固等管理養護措施,一直是橋梁領域關注的重點,也是未來的發展方向[1]。
橋梁的定期檢查,會記錄橋梁的狀態,包括結構外觀病害觀測、材料性能劣化、重要構件變形等,評定其技術狀況等級,并提出后續養護維修建議,定期檢查已成為我國公路橋梁運營期業務體系中最重要的工作內容之一[2]。定期橋檢報告中包含了大量的結構和病害等細粒度信息,挖掘分析結構病害成因和結構狀態演化趨勢,采取相應的維護措施,能夠有效的保證橋梁的安全性,也是人工智能時代土木基礎設施管理創新發展的重要趨勢。
命名實體作為文本信息抽取、知識圖譜構建等任務的基礎性工作之一,在自然語言處理、統計機器學習、深度神經網絡等研究方向得到了廣泛關注和長足發展[3]。橋梁命名實體識別目的是從橋梁檢測報告中抽取橋梁的構件信息、病害信息和病害的位置信息,命名實體的識別是橋梁領域各項自然語言處理的基礎任務。對橋梁命名實體的有效識別能夠加快橋梁領域知識圖譜的構架,為構件與病害信息的關聯、推理等工作進行支持,對橋梁管理與養護工作具有重要的意義。
本文采用目前主流的深度神經網絡方法進行命名體的識別。主要工作內容:(1)實現了對構件信息,病害信息等領域實體的識別。(2)采用CNN-BiLSTM-CRF模型為訓練模型。(3)使用字符級向量輸入神經網絡進行訓練。
1 相關工作
命名實體識別任務過去主要采用基于機器學習的方法和基于規則的方法。特征工程的質量嚴重影響這些方法的效果,特征工程的選擇需要大量的人工來進行,還學要特定領域的知識,為了避免因為特征工程影響實體識別的精度,目前大多數研究都采用基于深度學習的方法,深度神經網絡是一個用于挖掘潛在有用特征的多層神經網絡,通過神經網絡自動抽取數據的特征,實現了端到端的訓練。張海楠等[4]提出了一種基于深度神經網絡的字詞聯合方法,將字向量和詞向量進行有效互補,提高了命名實體的識別性能。也有越來越多的學者開始關注少數民族語言的發展,王路路等[5]利用BiLSTM-CRF模型來識別維吾爾問命名實體的識別,也取得了較好效果。
2 模型介紹
2.1 CNN模型
卷積神經網絡中的卷積層能夠很好地描述數據的局部特征,令卷積核列數與詞向量列數保持一致,每次卷積都相當于卷積了一整行,保證了詞向量的完整性。再通過池化層可以進一步提取出局部特征中最具有代表性的部分。由CNN的輸出結果將作為BiLSTM的輸入。
2.2 LSTM神經網絡
LSTM神經網絡是一種特殊的循環神經網絡。LSTM在RNN的基礎上加入了門機制來解決循環神經網絡模型因為長序列而產生梯度爆炸的問題,能夠處理較長的語句信息問題,所以該模型在解決長序列標注問題上有一定的優勢。通過加入門和細胞狀態來控制傳遞給記憶單元的輸入比例,在解決梯度爆炸問題的同時也解決了學習長期依賴信息。
為了充分利用上下文信息,本文將采用BiLSTM模型。BiLSTM在LSTM的基礎上增加了反向傳播層,可以將信息序列從正反兩個方向輸入模型,然后由隱含層保存兩個方向的信息序列。
2.3 CRF
在BiLSTM網絡層之后接一個線形層,CRF層將BiLSTM層的輸出作為輸入,根據序列得分選擇全局最優的標簽序列。在CRF層可以可以對最終預測的預測標簽添加一些限制來確保結果是有效的。
整個序列的打分等于各個位置的打分之和,而各個位置的打分由得分矩陣和轉移矩陣組成。模型訓練時通過最大化得分函數,即可求得文本的最佳得分序列。
3 實驗
3.1 評價指標
實驗結果采用識別準確率(P)、召回率(R)和調和平均F1值作為評價指標。P是指正確實體在實體總數的百分比,R是指正確識別的實體棧測試集所有實體的百分比,F1是P和R的調和平均值,綜合考慮模型的性能。
3.2 實驗環境及參數設置
實驗所用的環境及參數設置如下,實驗主機采用8核16G內存的臺式機,顯卡型號為RTX 2060S,python版本為3.6.5,Tensorflow版本為1.12.0,數據樣本最大長度為100,學習率為0.01,迭代次數為100,遺忘率為0.1。
3.3 實驗結果與分析
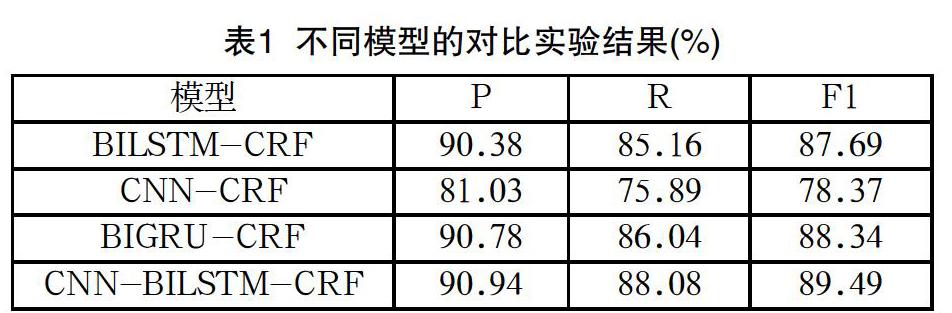
CNN-BiLSTM-CRF模型在自建語料上進行命名體識別,為了驗證基于神經網絡的命名體識別方法的有效性使用了多種網絡模型進行對比實驗,實驗結果如表1所示。
時間序列模型是基于深度神經網絡進行實體識別的主要模型,如BiLSTM-CRF模型,雙向LSTM模型可以從正反兩個方向建模,BiLSTM-CRF模型的精確率為90.38%,召回率為85.16%,F值為87.69。因為CNN模塊的卷積層能夠提取字符的上下文局部特征,為BiLSTM模型的輸入提供了有效的特征,使得準確率得到了有效的提升,CNN-BiLSTM-CRF模型精確率為90.94%,召回率為88.08%,F值為89.49%,與BiLSTM-CRF模型相比效果確實有一定的提升。
4 總結與展望
本文針對橋梁檢測文本的命名體識別任務,提出了CNN-BiLSTM-CRF模型在橋梁檢測報告語料上取得了最好效果。該模型通過CNN網絡來對文本的局部信息特征進行抽象化抽取和表示,使得模型在精確率和召回率上都有一定的提升,說明CNN確實能夠更有效的提取文本的上下文局部特征。
在未來的研究工作中,我們將繼續研究基于深度神經網絡的橋梁領域命名體識別工作,收集更多種類,更多數量的橋梁文本進行字向量和詞向量的訓練,進一步將字詞結合等特征表示機制運用到相應的模型中。
參考文獻
[1] 鮑躍全,李惠.人工智能時代的土木工程[J].土木工程學報,2019,52(05):1-11.
[2] 賀拴海,趙祥模,馬建,等.公路橋梁檢測及評價技術綜述[J].中國公路學報,2017,30(11):63-80.
[3] 侯夢薇,衛榮,陸亮,等.知識圖譜研究綜述及其在醫療領域的應用[J].計算機研究與發展,2018,55(12):2587-2599.
[4] 張海楠,伍大勇,劉悅,等.基于深度神經網絡的中文命名實體識別[J].中文信息學報,2017,31(04):28-35.
[5] 王路路,艾山·吾買爾,吐爾根·依布拉音,等.基于深度神經網絡的維吾爾文命名實體識別研究[J].中文信息學報,2019,33(03):64-70.
