基于泊松分布的加權(quán)樸素貝葉斯文本分類算法
2020-04-20 13:13:02趙博文王靈矯
計(jì)算機(jī)工程 2020年4期
趙博文,王靈矯,郭 華
(湘潭大學(xué) 信息工程學(xué)院,湖南 湘潭 411105)
0 概述
樸素貝葉斯(Naive Bayes,NB)算法作為目前研究者較為關(guān)注的一種機(jī)器學(xué)習(xí)算法[1-2],具有簡(jiǎn)易和高效的特點(diǎn),應(yīng)用于文本分類[3-4]、文字識(shí)別和圖像識(shí)別等諸多領(lǐng)域時(shí)表現(xiàn)出優(yōu)越的性能。但該算法以各個(gè)屬性獨(dú)立作為假設(shè),其在文本分類中的運(yùn)算精確度不及K-最近鄰(K-Nearest Neighbor,KNN)[5]算法和支持向量機(jī)(Support Vector Machine,SVM)[6]算法,因此,許多研究者嘗試改進(jìn)樸素貝葉斯算法,實(shí)現(xiàn)其在文本分類領(lǐng)域的成功應(yīng)用。
文獻(xiàn)[7]提出多項(xiàng)式樸素貝葉斯和貝葉斯網(wǎng)絡(luò)相結(jié)合的算法模型,通過考慮特征詞之間的屬性關(guān)聯(lián)提升了分類效果。文獻(xiàn)[8]提出一種基于全局特征提取的文本分類策略,通過新穎的特征提取方式改善了算法性能。文獻(xiàn)[9]提出在決策樹中每個(gè)葉節(jié)點(diǎn)加入樸素貝葉斯算法的一種構(gòu)建樸素貝葉斯樹的方法,提高了分類精確度,但同時(shí)增加了算法時(shí)間開銷。文獻(xiàn)[10]提出一種利用特征權(quán)重對(duì)樸素貝葉斯算法中的條件概率進(jìn)行相關(guān)評(píng)估的深度特征權(quán)重樸素貝葉斯算法,改善了分類器性能。文獻(xiàn)[11]提出了一種基于屬性頻率的樸素貝葉斯算法,利用可辨識(shí)矩陣對(duì)不同屬性賦予權(quán)值,取得了良好的分類效果。文獻(xiàn)[12]同樣依據(jù)特征提取的原則設(shè)計(jì)一種基于屬性刪除方法的選擇貝葉斯分類器。
綜合分析現(xiàn)有的研究成果可知,上述改進(jìn)的樸素貝葉斯算法可完成文本分類任務(wù),然而仍然有很多改進(jìn)方式未被挖掘,如泊松分布是一種具有良好預(yù)測(cè)效果的隨機(jī)過程,但目前較少有將其結(jié)合傳統(tǒng)樸素貝葉斯算法應(yīng)用于文本分類的研究。
由于泊松隨機(jī)變量對(duì)文本特征詞具有很好的兼容性,因此本文提出一種新型樸素貝葉斯文本分類算法。將泊松分布的概率函數(shù)引入樸素貝葉斯算法的推導(dǎo)過程中,達(dá)到對(duì)特征詞進(jìn)行加權(quán)的效果,同時(shí)應(yīng)用信息增益率作為特征詞權(quán)重,消除屬性重要程度相等的假設(shè)對(duì)最終分類效果的影響,從而實(shí)現(xiàn)文本分類精確度、召回率和F1值性能的提升。
1 樸素貝葉斯分類器
樸素貝葉斯分類器是一種基于概率統(tǒng)計(jì)的學(xué)習(xí)方法,應(yīng)用于文本分類需符合貝葉斯假設(shè),且假設(shè)各特征之間相互獨(dú)立[13]。在已知類別的先驗(yàn)概率和該類中每個(gè)特征取值條件概率的情況下,以貝葉斯全概率公式為基礎(chǔ),計(jì)算出待分類文本屬于某個(gè)類別的條件概率,并選擇條件概率最大的類別作為該文本的分類[14]。
假設(shè)共有m個(gè)類,類別集為C={C1,C2,…,Cm},根據(jù)貝葉斯理論,文本di的最佳類別屬于具有最大后驗(yàn)概率的類別Cmax:
(1)
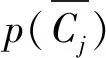
(2)
則式(1)可表示為:
(3)
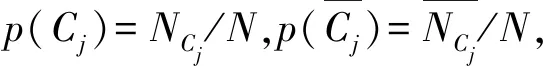
通過zjc的推導(dǎo)策略實(shí)現(xiàn)樸素貝葉斯文本分類,將每篇文本定義為一個(gè)|V|維向量{w1,w2,…,w|V|},其中,wk(k=1,2,…,|V|)表示文本的特征項(xiàng)。基于屬性獨(dú)立性假設(shè),zjc可以表示為:
(4)
在式(4)中,p(wk|Cj)可以通過下式得到:
(5)
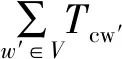
(6)
為避免式(5)、式(6)計(jì)算中出現(xiàn)零概率問題,進(jìn)行如下拉普拉斯平滑處理[15]:
(7)
(8)
其中,參數(shù)θ值取0.01,|V|為特征項(xiàng)個(gè)數(shù)。
在對(duì)樸素貝葉斯分類算法的改進(jìn)方面,文獻(xiàn)[16]提出一種基于卡方統(tǒng)計(jì)的屬性加權(quán)貝葉斯分類算法RW,C-MNB。通過引入RW,C進(jìn)行屬性評(píng)估,RW,C表示屬性和類別之間的正負(fù)依賴性,當(dāng)RW,C>1時(shí),屬性W和類別C為正依賴關(guān)系,否則為負(fù)依賴。同時(shí)只將具有正依賴關(guān)系的RW,C,作為該屬性條件概率的權(quán)重,否則權(quán)重為1。由此,正依賴屬性和負(fù)依賴屬性的分類貢獻(xiàn)拉開了差距,在一定程度上優(yōu)化了分類模型。
在對(duì)分類模型的改進(jìn)方面,文獻(xiàn)[17]提出一種基于CFS屬性加權(quán)的貝葉斯分類模型CFSNB,該文設(shè)計(jì)基于相關(guān)性的屬性選擇方法CFS,并認(rèn)為一個(gè)優(yōu)良的屬性子集S應(yīng)具備以下特點(diǎn):在屬性之間具有低相關(guān)性的同時(shí),屬性與類別之間具有高相關(guān)性。文獻(xiàn)[17]的設(shè)計(jì)思想是保留訓(xùn)練數(shù)據(jù)集的所有屬性,對(duì)于CFS選中的屬性集合賦予較大的權(quán)重,其余的屬性集合賦予較小的權(quán)重,將選中的屬性權(quán)重設(shè)為2,未被選中的屬性權(quán)重設(shè)為1。為充分利用權(quán)重信息,該文不僅將權(quán)重用于預(yù)測(cè)文本的類別公式中,同時(shí)還將權(quán)重運(yùn)用到條件概率的評(píng)估中,可以看出,將CFS屬性選擇方法變?yōu)镃FS屬性加權(quán)方法,可保證數(shù)據(jù)完整性,提升分類性能。
盡管上述樸素貝葉斯分類器較傳統(tǒng)分類器性能有所改善,但仍然不能滿足目前文本分類任務(wù)的需求。本文將泊松分布和信息增益率加權(quán)的方法應(yīng)用到樸素貝葉斯模型的推導(dǎo)過程中,使樸素貝葉斯算法性能得到進(jìn)一步提升。
2 改進(jìn)的樸素貝葉斯文本分類算法
泊松分布被廣泛應(yīng)用于較多領(lǐng)域[18-19],但較少應(yīng)用于文本分類,鑒于文檔中特定詞語的出現(xiàn)頻率可以用泊松模型來描述,本文提出基于泊松分布的特征加權(quán)樸素貝葉斯算法PWNB,將泊松分布與傳統(tǒng)樸素貝葉斯結(jié)合應(yīng)用于文本分類,根據(jù)泊松隨機(jī)變量k的物理意義,將k作為特征詞權(quán)值引入算法推導(dǎo)過程,并通過信息增益率對(duì)特征詞加權(quán),增強(qiáng)了算法的靈活性,一定程度上消除了屬性獨(dú)立性假設(shè)帶來的影響。
泊松分布的概率函數(shù)為:
(9)
其中,參數(shù)λ、k分別表示隨機(jī)事件單位時(shí)間(空間)內(nèi)的平均發(fā)生率和事件特定時(shí)間(空間)內(nèi)發(fā)生的次數(shù)。
假設(shè)文本di由多元泊松分布模型生成,表示為一個(gè)隨機(jī)分布的詞向量,則向量元素對(duì)應(yīng)于泊松分布中的隨機(jī)變量Xki,即將文本特征詞作為泊松隨機(jī)變量Xki,文檔中特定詞頻僅局限于某一文本,不能達(dá)到全局優(yōu)化的效果,由于將權(quán)重代入k值可避免文本特征詞屬性重要性一致的假設(shè),因此將文本di表示為如下泊松分布模型:
p(di)=p(X1i=f1i,X2i=f2i,…,X|V|i=f|V|i)
(10)
式(10)中各個(gè)變量Xki之間相互獨(dú)立,則文本di的先驗(yàn)概率可表示為:
(11)
根據(jù)式(10),p(Xki=fki)可表示為:
(12)
因此,式(2)中函數(shù)zjc可由式(11)、式(12)計(jì)算得到:
(13)
其中,λkc、μkc分別對(duì)應(yīng)于Cj類的泊松參數(shù)和除Cj類之外其他類別的泊松參數(shù)。根據(jù)泊松參數(shù)的定義,λkc、μkc分別表示Cj類別的文本中特征詞wk和其他類別的文本中特征詞wk出現(xiàn)的平均次數(shù)。
樸素貝葉斯文本分類算法認(rèn)為所有特征詞對(duì)文本分類的重要性相同,但每個(gè)特征詞的重要性實(shí)際上是不一致的。如果一個(gè)特征詞在某一類文本中頻繁出現(xiàn)而在其他類別中很少出現(xiàn),則認(rèn)為該特征詞區(qū)分度較高,對(duì)該類別重要程度也較高。信息增益率是表示特征詞在所有文本集中的信息增益[20],即該特征詞所包含的信息量,根據(jù)特征詞重要程度的不同,以信息增益率賦予其不同的權(quán)值,采用信息增益率加權(quán)的方法體現(xiàn)特征詞的全局重要程度,對(duì)文本分類將實(shí)現(xiàn)更高的精確度。
給定訓(xùn)練集D={d1,d2,…,dn},i=1,2,…,n,特征詞wk在訓(xùn)練集D中的信息增益率IIGR(C,wk)定義為:
(14)
其中,IIG(C,wk)表示特征詞wk在訓(xùn)練集中的信息增益,H(wk)表示wk在訓(xùn)練集中的信息熵。信息增益的計(jì)算公式如下:
IIG(C,wk)=H(C)-H(C|wk)=
(15)
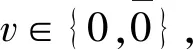
信息熵H(wk)計(jì)算公式如下:
(16)
通過計(jì)算所得的文本中各個(gè)特征詞的信息增益率IIGR(C,wk),可將特征詞wk的權(quán)重fki定義為:
(17)
結(jié)合上述過程,可得到式(3)的最佳分類類別。
針對(duì)傳統(tǒng)樸素貝葉斯算法在文本分類中準(zhǔn)確率較低的不足,本文提出新型樸素貝葉斯文本分類算法。在推導(dǎo)過程中融合泊松分布模型,由此引入特征權(quán)重項(xiàng),并通過信息增益率進(jìn)行特征加權(quán),從而改善傳統(tǒng)分類器性能。PWNB算法實(shí)現(xiàn)步驟如下:
步驟1定義泊松分布概率函數(shù)p(X=k)。概率函數(shù)的參數(shù)λ和k在物理意義上體現(xiàn)了隨機(jī)事件的發(fā)生率,文本中特征詞出現(xiàn)的隨機(jī)性和不確定性符合泊松分布這一隨機(jī)過程,用特征詞發(fā)生率代替概率函數(shù)的λ參數(shù)和k變量時(shí)引入特征詞權(quán)重,可以實(shí)現(xiàn)對(duì)算法性能的優(yōu)化。
步驟2將文本di表示為泊松分布模型。首先將文本表示為向量形式,根據(jù)樸素貝葉斯文本分類算法基于屬性獨(dú)立性假設(shè),文本中各個(gè)特征詞wk(k=1,2,…,|V|)相互獨(dú)立,將各個(gè)特征詞代入泊松模型的k項(xiàng),k值表示隨機(jī)事件特定時(shí)間或空間的發(fā)生次數(shù),映射為特征詞的出現(xiàn)頻率。為消除屬性獨(dú)立性假設(shè)對(duì)分類精度帶來的影響,將各個(gè)特征詞權(quán)重fwk作為k值嵌入泊松模型。
步驟3轉(zhuǎn)化函數(shù)zjc。要得到測(cè)試文本的最佳分類類別,函數(shù)zjc的取值是關(guān)鍵,因此,將泊松模型表示的文本代入函數(shù)zjc進(jìn)行運(yùn)算轉(zhuǎn)化,得到僅與泊松參數(shù)和特征詞權(quán)值相關(guān)的函數(shù)式。
步驟4以信息增益率對(duì)特征加權(quán)。特征詞信息增益率表示特征詞在整個(gè)文本集中包含信息量的相對(duì)比例,特征詞在訓(xùn)練集中信息增益率越高,表示其包含信息量越大,則該特征詞的權(quán)重就越高,定義信息增益率對(duì)文本中各個(gè)特征詞作加權(quán)處理,最后以式(17)中所得的平均信息增益率作為最終權(quán)值fk,將其代入步驟3得到的函數(shù)式zjc。
步驟5返回式(3)的最佳分類類別。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集
實(shí)驗(yàn)采用UCI KDD Archive的20-newsgroups英文文本數(shù)據(jù)集,該數(shù)據(jù)集是文本分類、文本挖掘和信息檢索研究的國(guó)際標(biāo)準(zhǔn)數(shù)據(jù)集之一,包含從20個(gè)不同新聞組中收集的19 997篇新聞文本,涉及政治、科學(xué)、體育、計(jì)算機(jī)等20個(gè)主題,每個(gè)主題包含約1 000篇文檔。實(shí)驗(yàn)選取其中10類數(shù)據(jù):alt.atheism,comp.graphics,comp.os.ms-windows.misc,comp.sys.ibm.pc.hardware,comp.sys.mac.hardware,comp.windows.x,misc.forsale,rec.autos,rec.motorcycles,rec.sport.baseball。為方便實(shí)驗(yàn)結(jié)果的記錄,將10類數(shù)據(jù)分別記為C1~C10,實(shí)驗(yàn)選取數(shù)據(jù)集的80%作為訓(xùn)練集、20%作為測(cè)試集,同時(shí)采用Python3.7編程,并在其開發(fā)平臺(tái)PyCharm上運(yùn)行測(cè)試。
3.2 分類性能評(píng)估
對(duì)文本分類效果的評(píng)估,通常使用3個(gè)性能指標(biāo),即準(zhǔn)確率P、召回率R和F1值:
(18)
(19)
(20)
其中,A表示實(shí)際與PWNB算法所得di∈Cj的文本數(shù)量;B表示實(shí)際di?Cj而PWNB算法所得di∈Cj的文本數(shù)量;C表示實(shí)際di∈Cj而PWNB算法所得di?Cj的文本數(shù)量。準(zhǔn)確率和召回率分別表示分類器分類的精確程度和分類器分類的完備程度,F1值為綜合準(zhǔn)確率和召回率之后的性能指標(biāo)。
3.3 實(shí)驗(yàn)步驟與結(jié)果
實(shí)驗(yàn)步驟如下:
步驟1數(shù)據(jù)預(yù)處理。文本包含大量對(duì)分類無用的信息,會(huì)對(duì)分類效果產(chǎn)生干擾,因此,對(duì)數(shù)據(jù)集所有文本進(jìn)行分詞、去除停用詞和標(biāo)點(diǎn)符號(hào)等。
步驟2文本向量化。將文本轉(zhuǎn)化為向量空間模型(Vector Space Model,VSM),將文本di表示為一個(gè)空間向量{w1,w2,…,w|V|},i=1,2,…,n,wk為特征詞(k=1,2,…,|V|),|V|為特征詞總個(gè)數(shù)。
步驟3特征選擇。由于文本中包含海量的特征詞,導(dǎo)致文本向量維度過大,也為運(yùn)算帶來不便,因此需要進(jìn)行特征選擇處理。計(jì)算每個(gè)特征詞wk在訓(xùn)練集中包含的信息增益IIG(C,wk),并根據(jù)IIG值進(jìn)行特征選擇。
步驟4分類器構(gòu)造。依據(jù)改進(jìn)算法構(gòu)造樸素貝葉斯文本分類器,并將通過K-fold交叉驗(yàn)證法測(cè)試分類器性能(K值取10),將測(cè)試結(jié)果與NB算法、KNN分類算法、SVM分類算法以及2種改進(jìn)樸素貝葉斯文本分類算法RW,C-MNB和CFSNB的效果進(jìn)行比較。
表1顯示了PWNB算法與NB算法性能指標(biāo)的詳細(xì)數(shù)據(jù)對(duì)比,其中NB算法的準(zhǔn)確率、召回率、F1值的均值分別為87.8%、87.7%、87.7%,PWNB算法的準(zhǔn)確率、召回率、F1值的均值分別為91.5%、91.4%、91.4%,較NB算法均提升了3.7個(gè)百分點(diǎn)。為直觀表達(dá),繪制如圖1所示的柱狀圖,顯示PWNB算法和NB算法在各個(gè)文本類別下的F1值對(duì)比。可以看出PWNB算法相比傳統(tǒng)算法在各類文本中的F1值均有所提升。由此可見,使用泊松分布和信息增益率加權(quán)結(jié)合樸素貝葉斯的PWNB算法,可使分類器性能得到大幅提升。
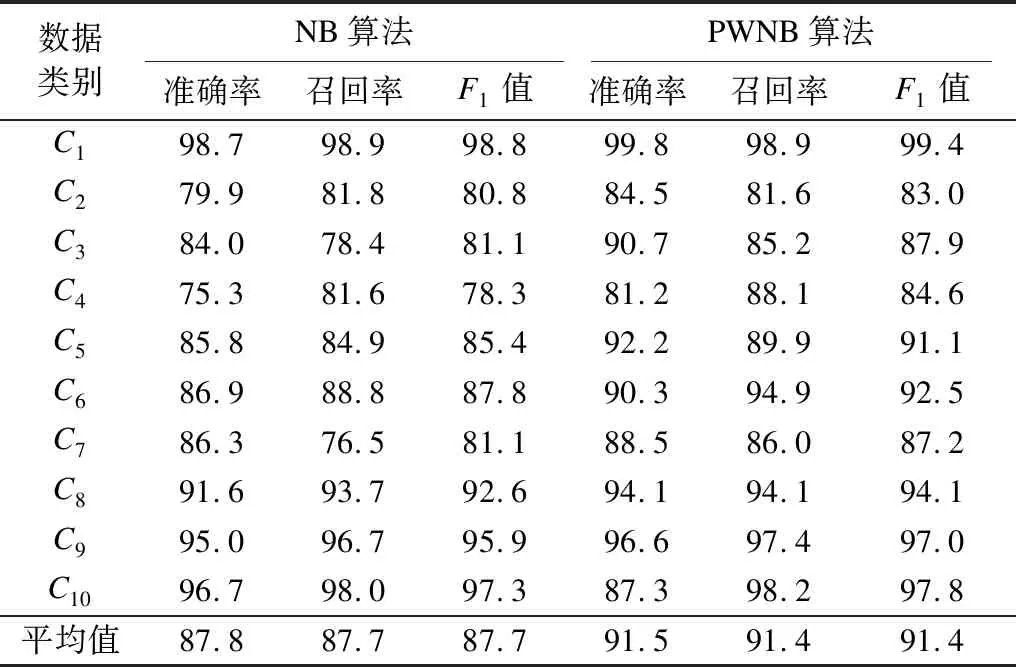
表1 PWNB算法與NB算法的分類性能對(duì)比
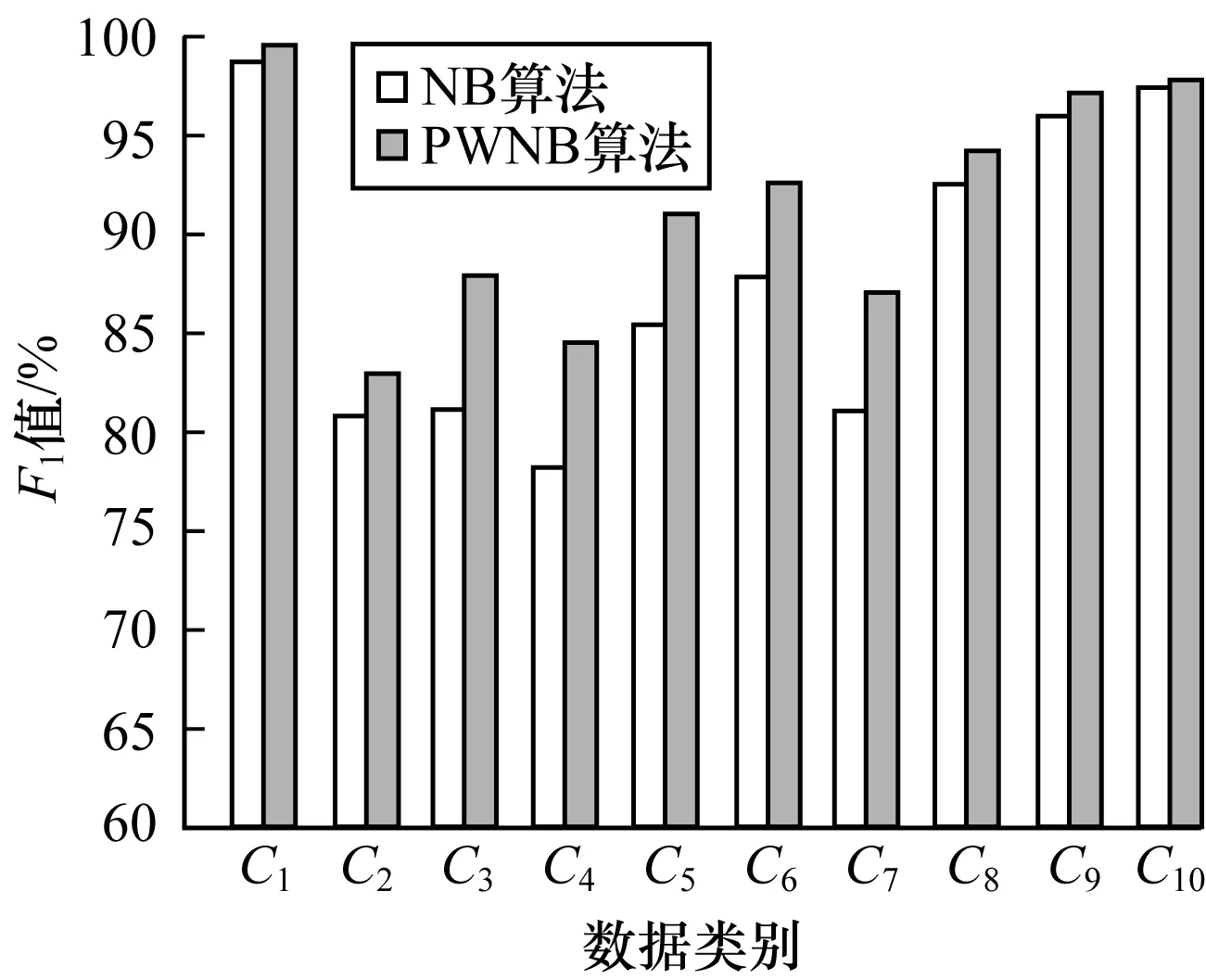
圖1 PWNB算法與NB算法的F1值對(duì)比
表2顯示了PWNB算法和其他多種算法的分類性能對(duì)比,包括NB、RW,C-MNB、CFSNB、KNN、SVM算法,其中:RW,C-MNB算法是基于卡方統(tǒng)計(jì)的屬性加權(quán)樸素貝葉斯算法,其通過評(píng)估特征詞和類別之間的正負(fù)依賴性改善分類器性能;CFSNB是基于CFS屬性選擇的屬性加權(quán)樸素貝葉斯算法,其通過度量特征詞和類別相關(guān)性的方法進(jìn)而對(duì)特征詞加權(quán),改善了分類器性能。可以看出,相比上述2種改進(jìn)算法,PWNB算法引入泊松隨機(jī)過程,通過泊松參數(shù)對(duì)隨機(jī)事件良好的預(yù)測(cè)效果優(yōu)化樸素貝葉斯文本分類算法,同時(shí)使用信息增益率進(jìn)行特征加權(quán),每個(gè)特征詞在文本中的重要程度都能在分類中體現(xiàn),達(dá)到全局優(yōu)化的效果。從實(shí)驗(yàn)結(jié)果可以看出,PWNB算法在準(zhǔn)確率上相比RW,C-MNB算法和CFSNB算法分別提升了2.3個(gè)百分點(diǎn)和0.9個(gè)百分點(diǎn),同時(shí)其分類性能接近KNN和SVM算法。
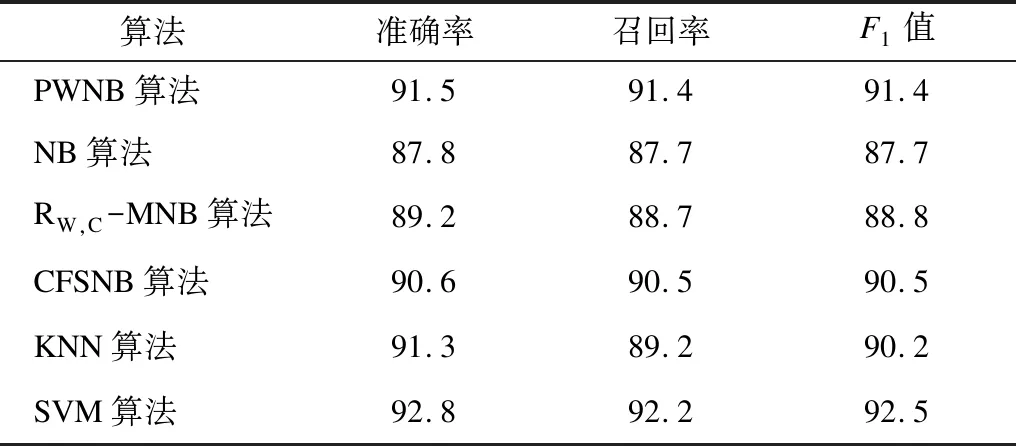
表2 6種算法與多種算法的分類性能對(duì)比
圖2顯示了各個(gè)算法的執(zhí)行效率對(duì)比,其中PWNB、NB、RW,C-MNB、CFSNB、KNN、SVM算法的執(zhí)行時(shí)間分別是24.8 s、21.3 s、24.4 s、25.8 s、103.1 s、118.2 s,可以看出,PWNB算法執(zhí)行效率相比NB算法、RW,C-MNB算法、CFSNB算法基本在同等水平,而遠(yuǎn)超KNN算法和SVM算法,這源于樸素貝葉斯算法本身的簡(jiǎn)易性和高效性。
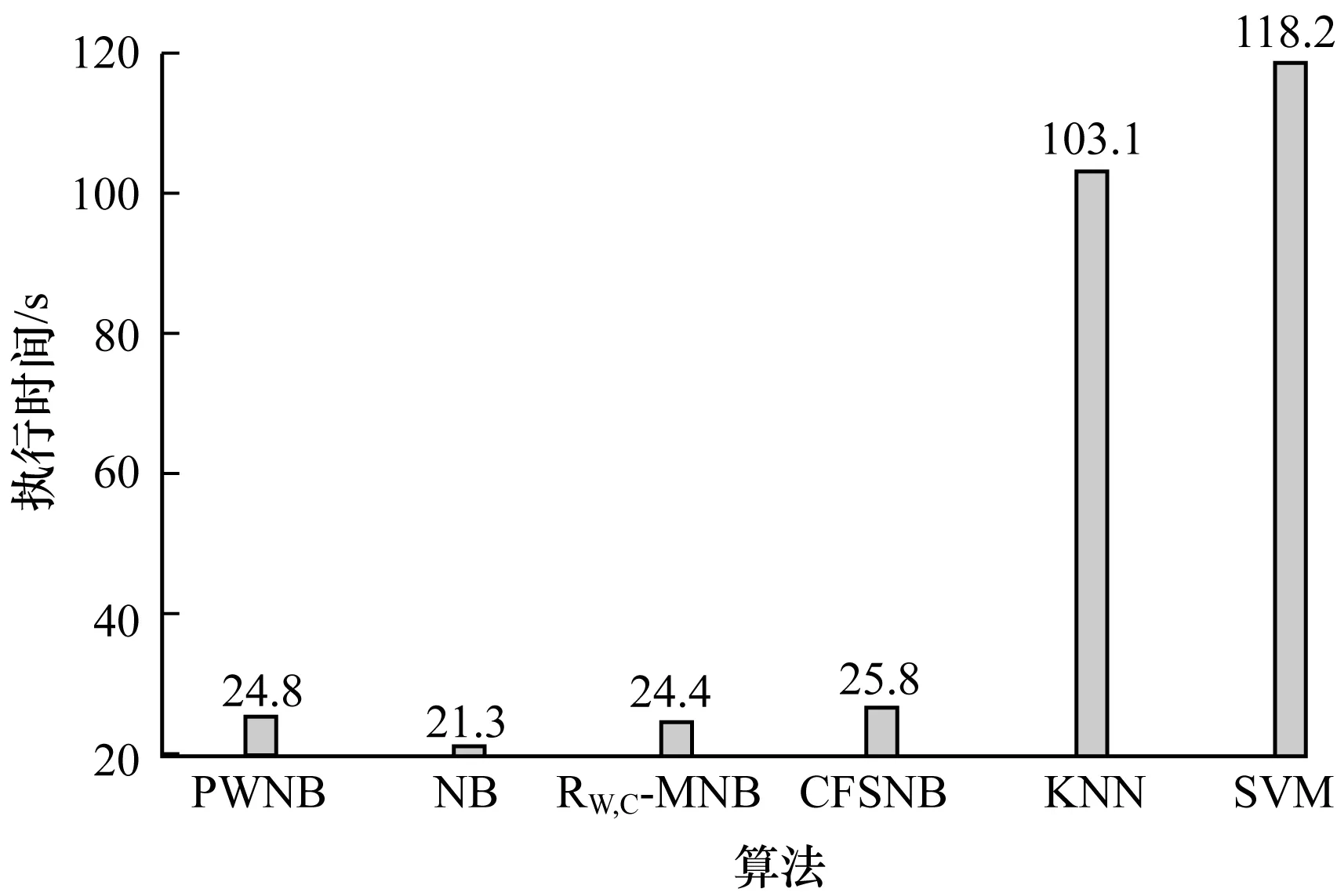
圖2 6種算法的執(zhí)行時(shí)間對(duì)比
綜合上述實(shí)驗(yàn)結(jié)果可知,本文改進(jìn)的樸素貝葉斯文本分類算法在保證原算法時(shí)間開銷的基礎(chǔ)上改善了分類器性能,可有效提高文本分類準(zhǔn)確率。
4 結(jié)束語
樸素貝葉斯算法是一種重要的文本分類算法,但其分類準(zhǔn)確率較低。針對(duì)此不足,本文提出基于泊松分布和信息增益率加權(quán)的文本分類算法。以泊松分布相關(guān)參數(shù)λ匹配特征詞在某一類別文檔中出現(xiàn)的平均次數(shù),以k值匹配特征詞在文本中出現(xiàn)的頻率,并將其轉(zhuǎn)換為由信息增益率計(jì)算而得的權(quán)值,即對(duì)特征詞做加權(quán)處理,從而消除樸素貝葉斯算法中屬性重要性一致假設(shè)造成的影響。實(shí)驗(yàn)結(jié)果表明,該算法能夠在保證簡(jiǎn)單性和高效性的同時(shí),提高文本分類的準(zhǔn)確率。雖然本文算法在時(shí)間復(fù)雜度方面具有較大優(yōu)勢(shì),但其準(zhǔn)確率仍有可提升的空間,后續(xù)將針對(duì)此問題對(duì)算法做進(jìn)一步改進(jìn)。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
